Table of Contents
- What Fable 5 actually is
- Mechanism 1: the refusal-and-fallback flow
- Mechanism 2: the data-retention floor
- Mechanism 3: conservative classifiers and legitimate security work
- The auditability tradeoff: reasoning you cannot inspect
- A deployment checklist
- Who owns the safety decision
- The bigger picture
- Sources
Most coverage of Claude Fable 5 has focused on how capable it is. That is the wrong question for a security or compliance team. The question that matters for anyone putting this model into a regulated environment is narrower and more practical: what does its safety architecture do to your deployment design, your data-governance posture, and your incident handling?
Fable 5, released June 9, 2026, is the first publicly available model in what Anthropic calls its Mythos class, and Anthropic describes it as its most capable widely released model. The capability is real, but it ships wrapped in a safety architecture that is unusual enough to change how you integrate it. Three mechanisms in particular reach out of the model and into your systems: a refusal-and-fallback flow, a mandatory data-retention floor, and conservatively tuned classifiers that will trip on legitimate security work. None of these are reasons to avoid the model. All three are reasons to plan before you adopt it.
This piece is grounded in Anthropic's own documentation and in request traffic we captured directly from the Claude Code client. Where a claim is Anthropic's, it is cited. Where it is our observation or inference, it is labeled as such.
Companion piece: The wire-capture technique used for the observations below, and the full diff between Fable 5 and Opus 4.8's system prompts, is documented in Same Harness, Different Instructions: Diffing Claude Code's System Prompt Across Models.
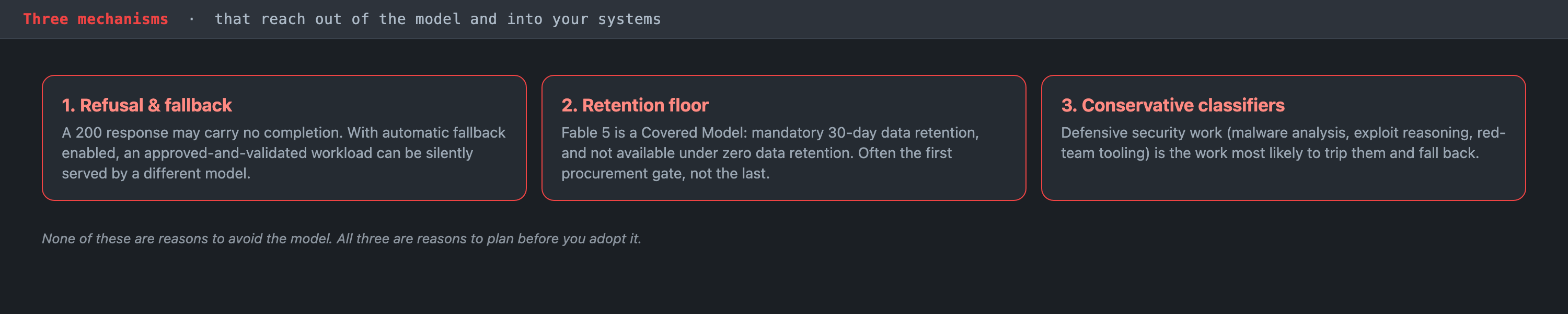
The three mechanisms that reach out of the model and into your systems. None is a reason to avoid Fable 5; all three are reasons to plan before adopting it.
What Fable 5 actually is
Fable 5 and its sibling, Mythos 5, share the same underlying capabilities. The difference is the safety layer. Fable 5 runs safety classifiers that can decline certain requests; Mythos 5 is the same capability without those classifiers, available only to vetted organizations through Anthropic's Project Glasswing program. For everyone else, Fable 5 is the generally available Mythos-class model.
Why the gating exists matters for threat modeling. Anthropic states that Mythos-class models are strong at discovering and exploiting software vulnerabilities, can make cyberattacks cheaper and easier, and show capability across multiple stages of an attack including reconnaissance, discovery, and lateral movement. The classifiers in Fable 5 are the mechanism Anthropic uses to make that capability publicly deployable. So when you adopt Fable 5, you are adopting a model whose own vendor considers its unmitigated form dangerous enough to restrict. The safety layer is not an add-on; it is a core component of how Fable is intended to be deployed.
Mechanism 1: the refusal-and-fallback flow
This is the change most likely to break an integration that was not designed for it.
When Fable 5's classifiers decline a request, the Messages API does not return an error. It returns a successful HTTP 200 response with stop_reason: "refusal", and it reports which classifier declined. A request that Fable refuses can then be retried on a different model. Anthropic provides a fallbacks parameter (in beta) and SDK middleware to automate that retry, and a "fallback credit" that refunds the prompt-cache cost of switching models. You are not billed for a refused request that produced no output. Anthropic reports that fallback triggers in fewer than five percent of sessions on average, but that is a whole-population figure; a security-research workload, for reasons covered under Mechanism 3, will sit above it.
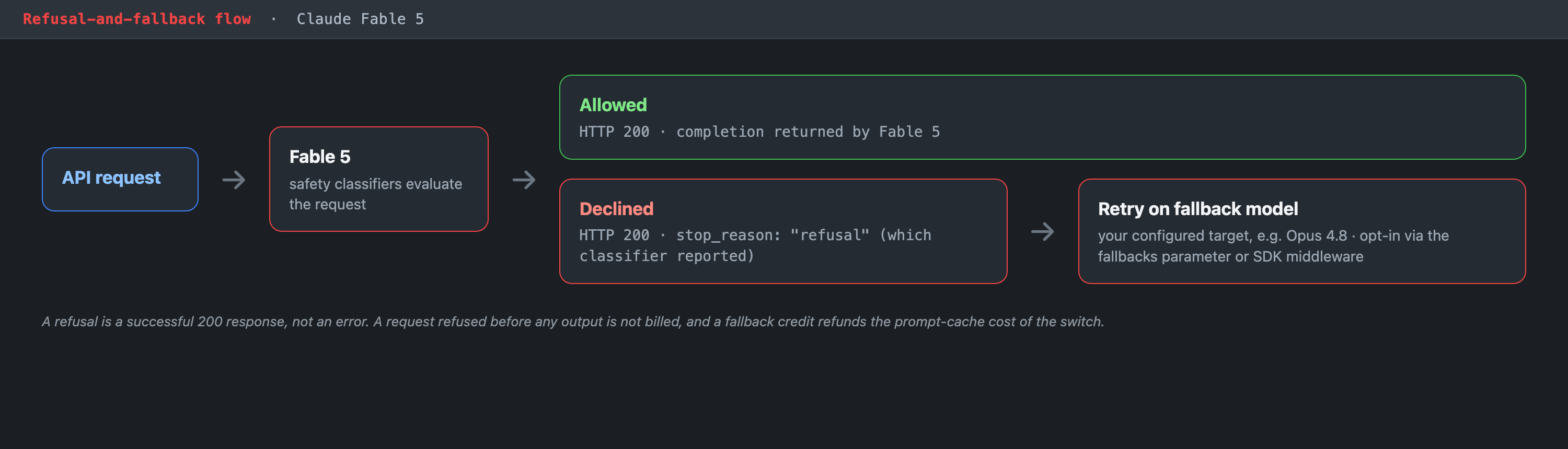
The refusal-and-fallback flow. A declined request returns a successful HTTP 200 with stop_reason "refusal", then retries on your configured fallback model.
We confirmed a piece of this directly on the wire, using the capture method described in the companion piece. Capturing the request headers the Claude Code client sends, the anthropic-beta header is identical between Fable 5 and Opus 4.8 except for a single flag that only Fable carries: fallback-credit-2026-06-01. Opus is one of the models Fable falls back to, so it has no need for the flag. The fallback architecture is not marketing language; it is advertised in the request, per model, and you can watch it happen.
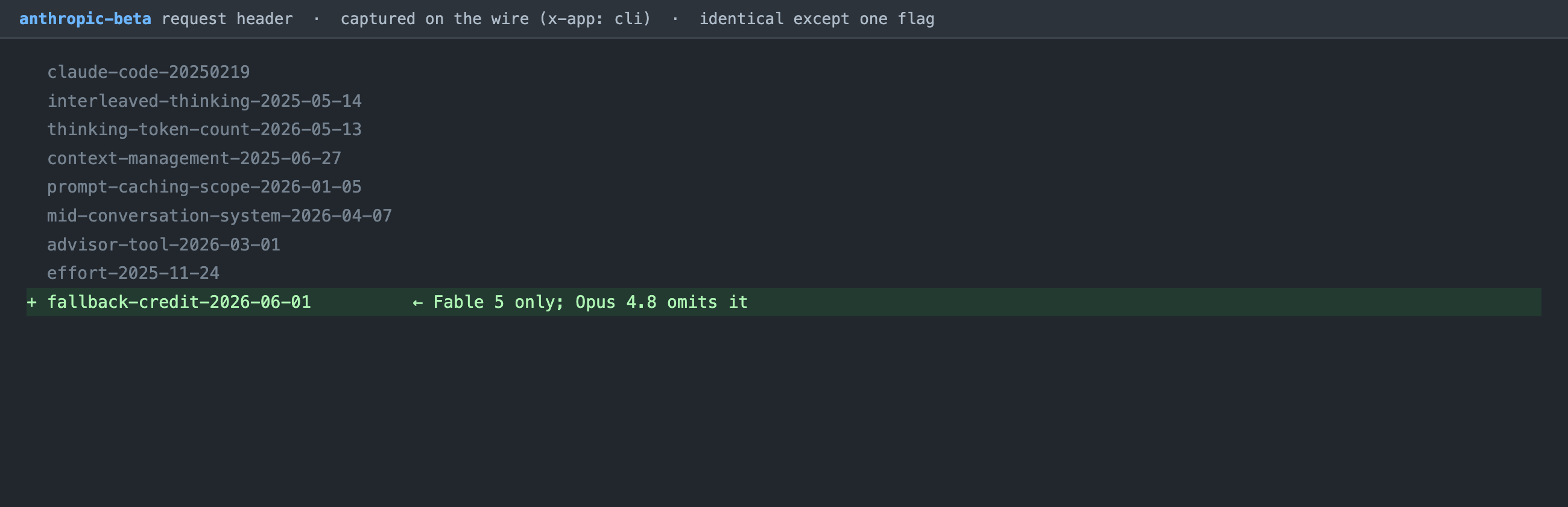
The anthropic-beta request header, captured from the Claude Code client. Eight feature flags are identical across both models; only Fable 5 carries fallback-credit-2026-06-01, the flag tied to its refusal-and-fallback billing flow.
The security implications are concrete:
- Silent model substitution. If you enable automatic fallback, a workload you provisioned, tested, and approved on Fable 5 will, for some fraction of requests, be served by a different model with different behavior and different output characteristics. For a regulated workflow that was validated against a specific model, that substitution is a change-control and validation question, not a convenience feature. Decide your fallback policy on purpose: a named fallback model you have also validated, or a hard stop.
- A new failure mode to handle explicitly. Any code that assumes a 200 response contains a completion will mishandle
stop_reason: "refusal". If your integration treats the empty completion as a model failure, retries blindly, or worse, fails open and proceeds as though the request succeeded, you have a defect that only surfaces on refused content. Test for it deliberately. - Provider-side moderation you do not control. The classifier decision is made inside Anthropic's stack, on weights and logic you cannot inspect, though operator system-prompt framing can influence outcomes at the margin. For some governance regimes, the inability to inspect or appeal an individual automated decision is itself a finding.
Mechanism 2: the data-retention floor
This one is a procurement gate, and it will stop some deployments cold. Fable 5 is not available under zero data retention. For a large segment of enterprise buyers that is not a preference, it is a contractual and regulatory floor: financial-services firms, healthcare organizations, and government deployments routinely operate AI under zero-retention agreements precisely so that prompts and outputs containing regulated data never persist on a vendor's systems.
The mechanism behind it: Anthropic designates Fable 5 and Mythos 5 as Covered Models, which carry a mandatory 30-day data retention period for safety monitoring and are not available under zero data retention. Anthropic states it will not use this data for training and retains it to defend against novel jailbreaks and to identify classifier false positives.
For those buyers, the practical consequences are immediate:
- A workload currently operating under a zero-retention agreement cannot automatically be migrated to Fable 5; the retention requirement would have to be reviewed against existing contractual, regulatory, and governance obligations first.
- The retention floor applies to the prompt and output content that reaches the model, which in an agentic deployment can include retrieved documents, tool outputs, your own operator system-prompt content, and customer data, not just the user's typed message. For many customers the operator system prompt is the most sensitive element, and it sits inside the retained window.
- The compliance conversation has to happen before the technical one. The model can be excellent and still be unusable for a given workload on retention grounds alone.
If you advise regulated customers: This is the first thing to surface, not the last. The capability discussion is moot if the data-governance gate is closed.
Mechanism 3: conservative classifiers and legitimate security work
This one matters specifically to security teams, because security work is the work most likely to trip the classifiers.
Anthropic describes the Fable 5 classifiers as conservatively tuned, which means some benign requests will trigger a refusal and fallback (Anthropic's own wording). The classifier domains include offensive cybersecurity, so the requests most likely to be declined are, by our reading, exactly the ones a defensive security team runs: analyzing malware behavior, reasoning about an exploit to build a detection for it, generating red-team tooling for an authorized engagement, or working through an attack chain to design a mitigation. These are legitimate, defensive, often contractually authorized activities, and they fall squarely within what the classifier is built to catch.
The practical effect, we expect, is capability inconsistency. This is an inference from Anthropic's published classifier design and fallback architecture, not a measured result from production workloads. A security analyst using Fable 5 for exploit research should expect some share of queries to be refused; with fallback configured, those are served by whatever model you set as the target (Opus 4.8 is one option), not by Fable. If you are building or evaluating an AI-assisted security workflow on Fable 5, plan for this:
- Test your actual security workloads against the model before committing, and measure how often they fall back. The refusal response reports which classifier fired, so a representative pre-production sample is the right instrument. The average fallback rate Anthropic cites is a whole-population number; a security-research workload is likely to sit well above it.
- Decide whether falling back to a less capable model is acceptable for the task, or whether the inconsistency is itself a problem for reproducibility and audit.
- Do not assume a refusal indicates wrongdoing on the user's part. Conservative tuning means false positives are expected by design, and treating every refusal as a policy violation will generate noise and friction for legitimate analysts.
The auditability tradeoff: reasoning you cannot inspect
One more architectural difference has compliance weight. On Fable 5 and Mythos 5, adaptive thinking is always on and cannot be disabled, and the raw chain of thought is never returned. You can request a summarized version of the model's reasoning, but the unedited reasoning trace is not available.
Many organizations already avoid depending on chain-of-thought for governance controls, given its instability and vendor-specific behavior. For teams that nonetheless built reasoning traces into audit trails, explainability requirements, or forensic review of an AI-assisted decision, the raw trace is no longer available on this model tier. Summarized reasoning is returned through the API and can be logged, but it is a summary, not the unedited trace, and is not equivalent for forensic purposes. If your control framework assumes you can capture and review the model's full reasoning, that assumption needs revisiting before you move a regulated workflow onto Fable 5.
A deployment checklist
If you are evaluating Fable 5 for an enterprise or regulated environment, work through these before you commit:
- Handle the refusal path. Confirm your integration detects
stop_reason: "refusal"on a 200 response and does not fail open or misclassify it as an error. - Set a deliberate fallback policy. Choose a named, validated fallback model or a hard stop. Do not let silent substitution into an unvalidated model happen by default in a regulated workflow.
- Clear the retention gate first. Confirm whether your workload requires zero data retention. If it does, Fable 5 is off the table under current terms regardless of capability.
- Test security-adjacent workloads for fallback rate. Measure how often your real queries are declined, and decide whether the fallback model you have configured is acceptable for the task.
- Revisit reasoning-audit controls. If your framework depends on raw chain-of-thought, adapt it to summarized reasoning or keep that workload on a model tier that exposes it.
- Document the dual-use posture. You are deploying a model whose vendor restricts its unmitigated form. Make sure your own authorization, logging, and use-case boundaries are explicit.
Who owns the safety decision
Historically, organizations controlled most governance decisions through policy engines, application logic, and operational controls. Fable's classifier architecture moves part of that decision-making into Anthropic's service layer. The result is not necessarily weaker governance, but governance that is increasingly shared between customer and provider. That shift, from customer-controlled toward partly provider-controlled safety, is the deeper change underneath the three mechanisms above.

The control shift: part of the safety decision moves from customer-controlled governance into the provider's service layer.
The bigger picture
Fable 5's safety architecture is a preview of where frontier AI deployment is heading. Capability and access are decoupling: the same underlying model ships in two forms, one gated by classifiers for the public and one gated by vetting for approved organizations, with a refusal-and-fallback flow bridging the two. For defenders, the takeaway is not that this particular model is risky to use. It is that a model's safety layer is now part of your architecture, your compliance surface, and your incident response, whether you designed for it or not. The teams that treat the guardrails as something to plan around, rather than something that happens to them, will deploy these models faster, with fewer incidents, and with a defensible paper trail.
Sources
- Anthropic, "Introducing Claude Fable 5 and Claude Mythos 5"
- Anthropic, "Claude Fable 5 and Claude Mythos 5"
- The refusal mechanics (
stop_reason: "refusal"), fallback parameter and SDK middleware, fallback credit, always-on adaptive thinking, summarized-only reasoning, and Covered-Models 30-day retention are all documented in the model overview above and the pages it links. The "fewer than five percent of sessions" fallback figure is Anthropic's, from the announcement. - Primary observation:
anthropic-betarequest headers captured from the Claude Code client (x-app: cli) forclaude-fable-5andclaude-opus-4-8, June 2026.