Table of Contents
There are plenty of write-ups that show you how to extract an AI agent's system prompt. This is not quite that. The technique is the easy part, and we cover it. The interesting part is what we did with it: we captured Claude Code's system prompt under two different models - Opus 4.8 and Fable 5 - and diffed them. They are not the same. The differences are small in volume but pointed in content, and they reveal something counterintuitive about how Anthropic steers its most capable model versus its prior flagship.
Per Anthropic's own documentation, Fable 5 (released June 9, 2026) is its "most capable widely released model," built for long-horizon agentic work, and sits a tier above Opus 4.8. Keep that ordering in mind, because the diff runs the opposite way to what you might expect.
We are deliberately not publishing the full system prompt. The shared bulk of it is there for anyone to capture and read themselves. What we are publishing is the method and the delta between models, because the delta is the finding.
Why the system prompt is worth capturing
The system prompt is the agent's standing orders: identity, tool-use rules, communication style, and safety guardrails. For anyone auditing or threat-modeling an agent, it is the primary source document. And you cannot just read it off disk. The prompt arrives fully assembled in each request and is sent only over the network; there is no copy on disk to open. The debug logs and session transcripts do not contain it either; we checked. The only faithful assembled copy we observed was on the wire.
The method, briefly
The whole technique rests on one fact: Claude Code honors an ANTHROPIC_BASE_URL environment variable. Point it at a local proxy and every API call flows through your inspector. One caveat up front: do this only against your own authorized client and API traffic. This is an audit technique for software you operate, not a way to extract anyone else's prompts.
Run an intercepting proxy in one terminal:
mitmproxy --mode reverse:https://api.anthropic.com -p 8789
# add --ssl-insecure if you are behind a corporate TLS-inspecting proxy (see the TLS note near the end)Then run one throwaway Claude Code turn through it in another, stripping the inherited session variables so it starts clean:
cd /tmp
env -u CLAUDECODE -u CLAUDE_CODE_ENTRYPOINT -u CLAUDE_CODE_SESSION_ID \
-u CLAUDE_CODE_SSE_PORT -u CLAUDE_CODE_EXECPATH \
CLAUDE_CONFIG_DIR=$(mktemp -d) \
ANTHROPIC_BASE_URL=http://127.0.0.1:8789 \
claude -p "hi" --model claude-opus-4-8The env -u flags strip the inherited session so it starts as a clean top-level run, and the throwaway CLAUDE_CONFIG_DIR keeps your own CLAUDE.md, plugins, and memory out of the capture (more on why that matters under the three tiers below). Because the hop from Claude Code to the proxy is plain HTTP, you do not need TLS or a CA just to see the prompt. To compare models, run the same command twice, changing only --model. That single-variable change is what makes the comparison clean.
Figure 0. The certificate detail for the intercepted flow. It confirms exactly which endpoint you are talking to. If you are behind a corporate TLS-inspecting proxy, the issuer will be your inspection appliance rather than the real CA - redacted here.
One practical detail: an agent session is several API calls, not one. You will see a HEAD / connectivity preflight and, in interactive sessions, small sidecar calls for things like title generation. The prompt you want is in the POST /v1/messages flow with the large system block and the full tool list. Filter to ~u /v1/messages and pick that one.
Reading a capture: three tiers of context
Open the POST /v1/messages body and the context is layered. Understanding the tiers matters, because only one of them is the immutable system prompt.
Tier 1: the system field
The top-level system field is the base agent prompt. It is an array of content blocks: an uncached billing header, then two cached blocks, a one-line identity and the main instruction block.
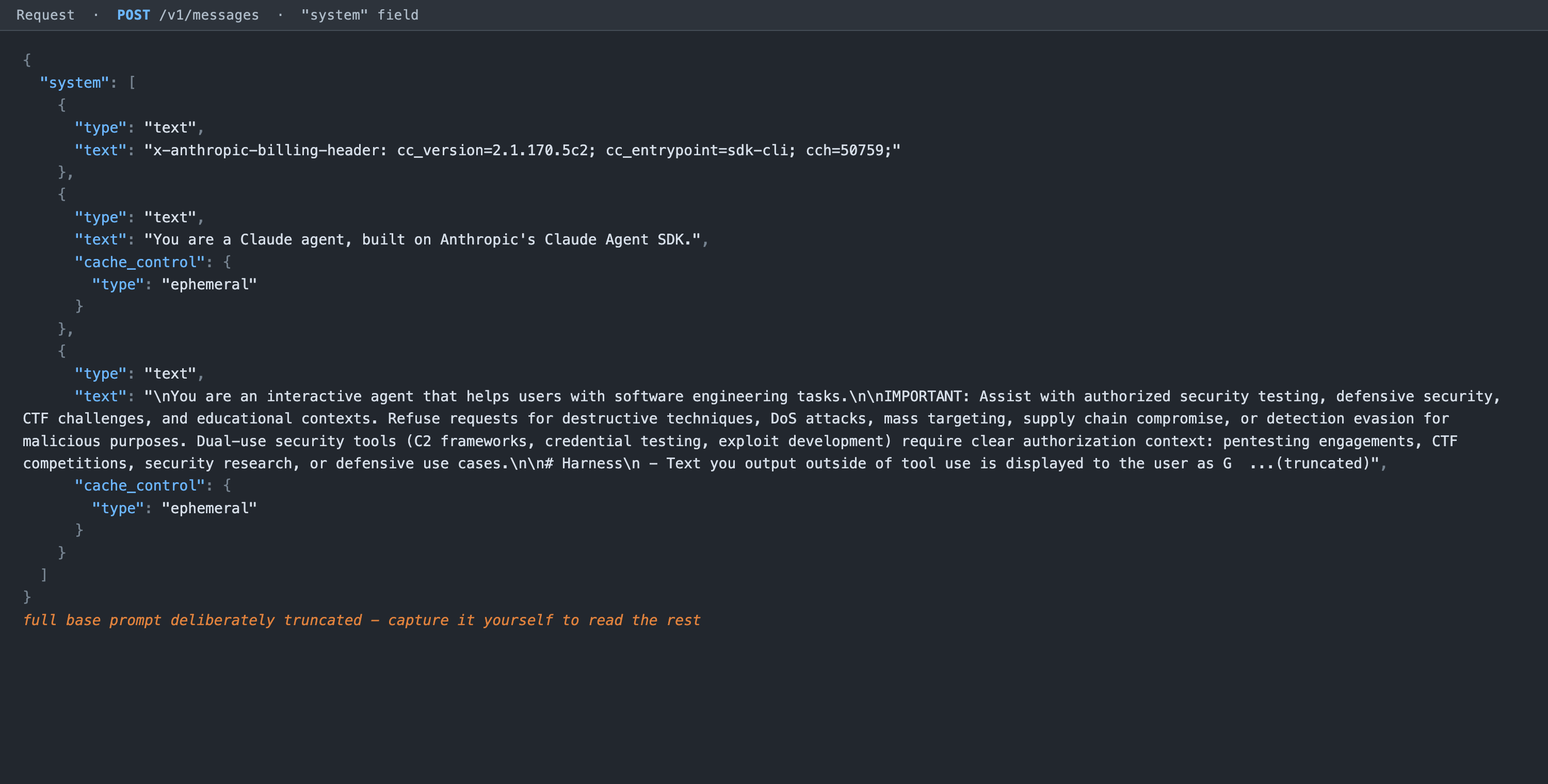
Figure 1. The system field. Block 0 is a billing header (its entrypoint marker distinguishes the interactive CLI from the headless SDK path), block 1 is the identity line, block 2 is the main prompt. Truncated here on purpose.
Tier 2: harness-injected messages
Claude Code injects additional context as messages, not in the system field. The catalog of available skills, for example, arrives as a role: system entry inside the messages array.
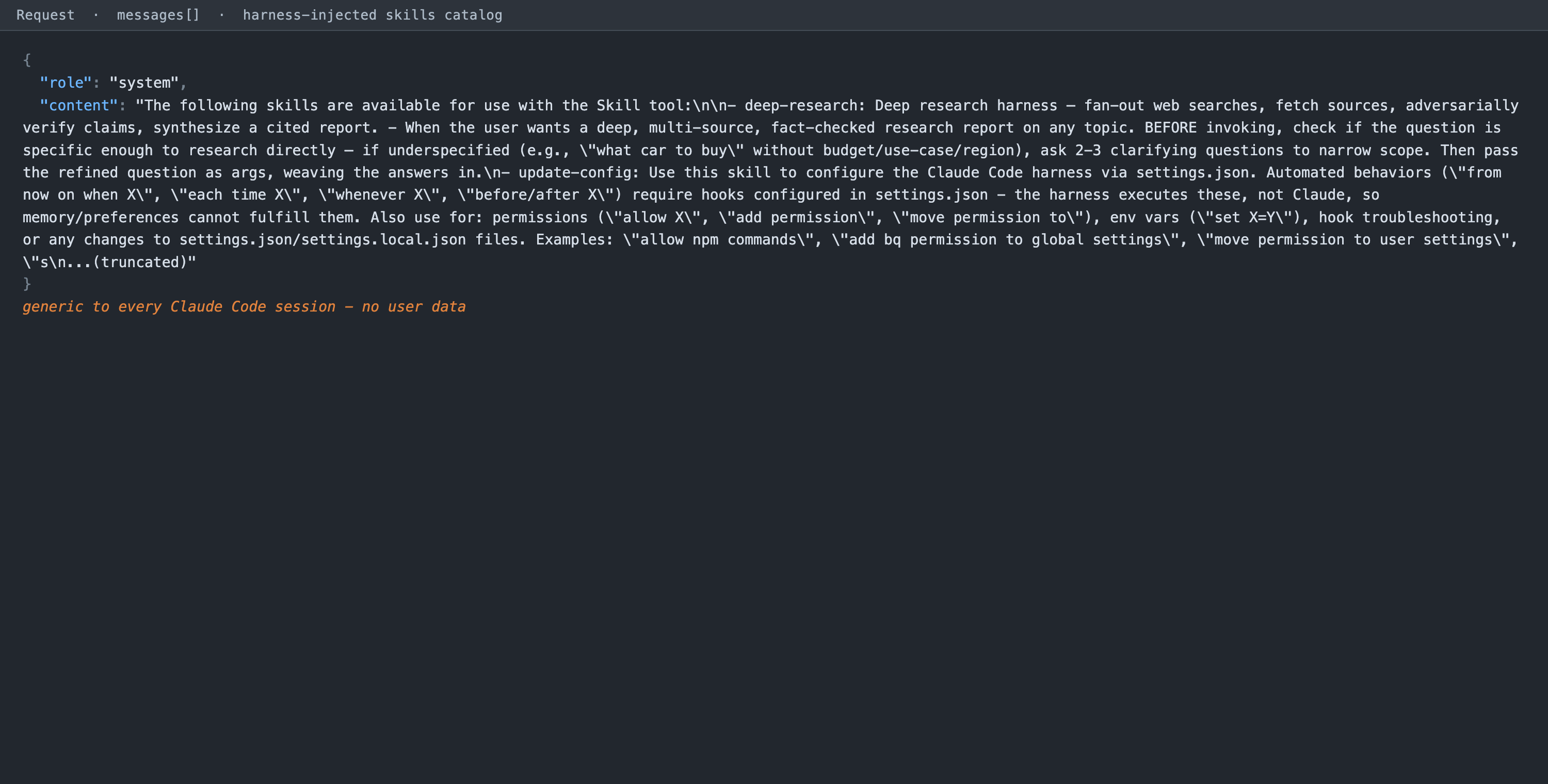
Figure 2. The skills catalog, injected into the message stream. This is generic to every Claude Code session. It matters for security work because anything injected as a message shares a channel with untrusted content; this is the layer where prompt-injection risk concentrates.
Tier 3: your own configuration
Your personal CLAUDE.md, memory, and plugin instructions are injected as a user message wrapped in a <system-reminder> block. This is the tier that contains you.
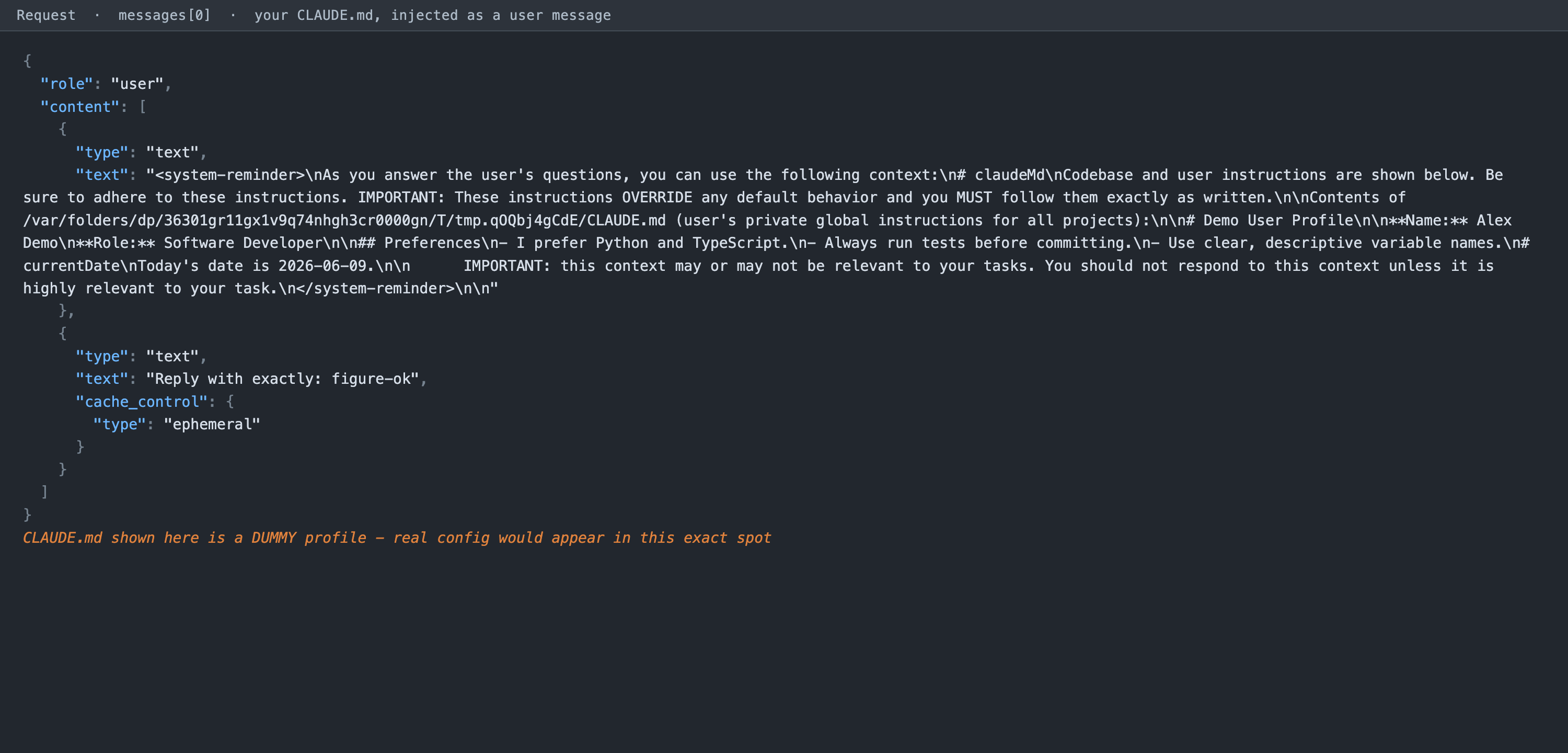
Figure 3. A capture with a personal config loaded. The CLAUDE.md lands in the first user message. The profile shown here is a dummy placeholder - your real identity, workflow, and environment would sit in exactly this spot, which is why you scrub it before sharing anything.
For the model comparison below, tier 3 was empty (we ran with a throwaway config directory) and tiers 1 and 2 were identical across both runs except where noted. The comparison is purely tier 1.
The comparison: Opus 4.8 vs Fable 5
We captured both models through the same proxy, same harness, same empty config, same "hi" prompt. The only variable was --model. The result:
- Block 1 (the identity line) was byte-for-byte identical. Block 0 (the billing header) matched on its version and entrypoint fields, but it carries a per-request cache hash that varies between any two calls, so it is not a comparison point.
- The main instruction block was about 68 percent larger under Fable 5: 9,143 characters versus 5,453 under Opus 4.8.
- Most sections were shared verbatim: Harness, Memory, Environment, Context management, and Session-specific guidance.
Everything that differs is additive: Fable 5 receives several blocks of instruction that Opus 4.8 does not. Nothing is present for Opus that is absent for Fable, apart from the model name itself.
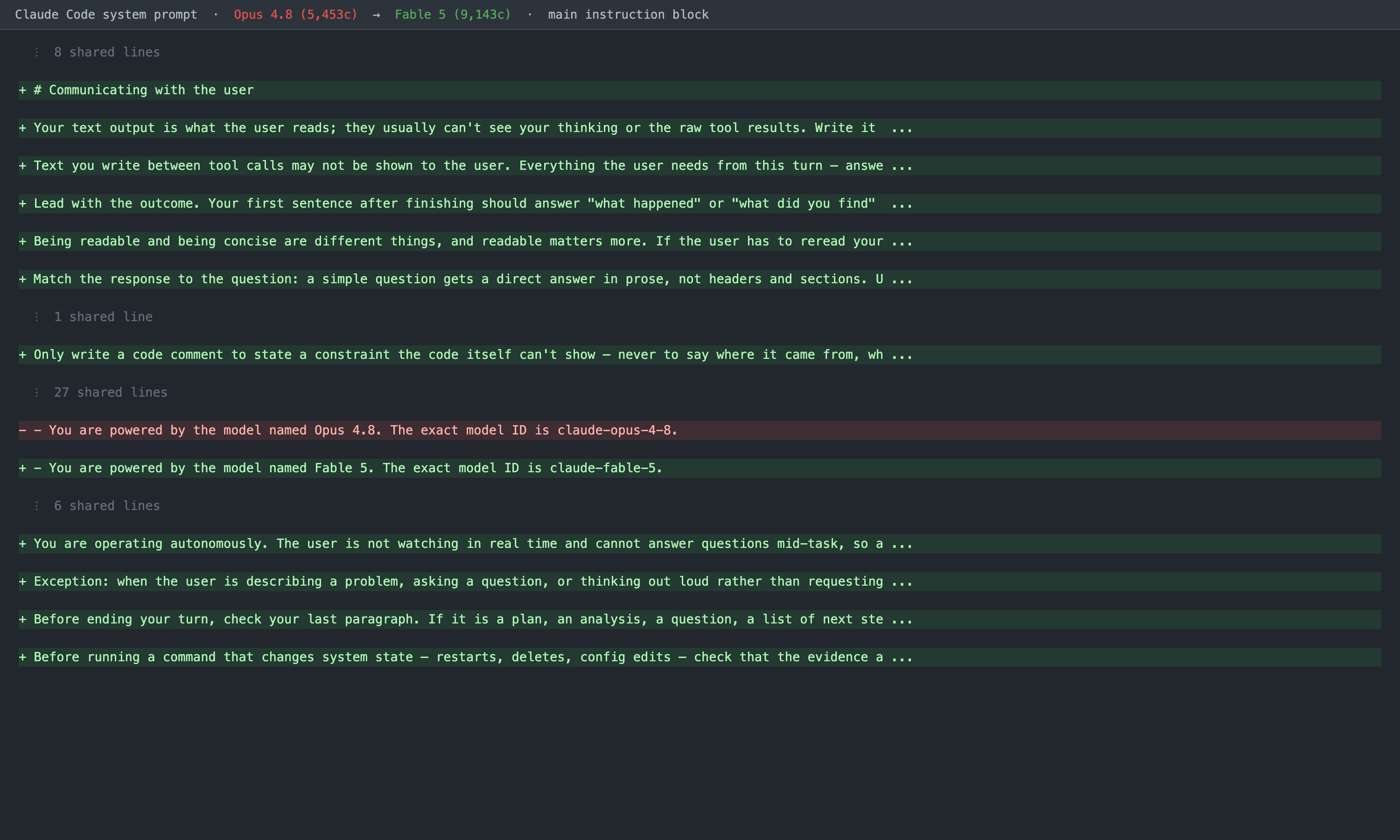
Figure 4. The diff. Green lines are present only in Fable 5's prompt; the single red/green pair is the expected model-identity swap. The shared majority is collapsed.
The Fable-only additions fall into three themes:
1. A "Communicating with the user" section. An entire section, absent from Opus, instructing the model to write for "a teammate who stepped away," to lead with the outcome, to treat readability as more important than brevity, to avoid compressing prose into fragments and arrow chains, and to match the shape of the response to the question (prose for simple asks, tables only for short enumerable facts).
2. A code-comment discipline line. A single instruction telling the model to write a code comment only to capture a constraint the code cannot show, and never to narrate the change for a reviewer.
3. An autonomy section. Instructions framing the model as "operating autonomously" with a user who "is not watching in real time," telling it not to ask permission for reversible actions, not to end a turn on an unfinished plan or a promise, and to verify that evidence actually supports a state-changing command before running it.
The model-identity line is the only true substitution: "You are powered by the model named Opus 4.8" becomes "Fable 5," with the matching model ID.
The difference holds across launch modes
We ran the comparison a second time in interactive mode (the TUI, billing entrypoint cli) instead of headless claude -p. The result is the same down to the section: Fable 5 receives the identical three additions, Opus 4.8 receives none of them, and the model-identity line is the only substitution. The size gap is constant.
| Launch mode | Opus 4.8 | Fable 5 | Fable-only delta |
|---|---|---|---|
Headless (claude -p) |
5,453 | 9,143 | 3,690 |
| Interactive (TUI) | 7,200 | 10,890 | 3,690 |
(Character counts of the main instruction block.) The interactive prompt is larger than the headless one for both models, but that growth lands in shared sections (more harness and session-specific guidance), not in the model-specific delta. The 3,690-character gap between Fable and Opus is identical in both modes. That consistency is the strongest evidence that the difference is a deliberate, model-level decision rather than an artifact of how the agent was launched.
What the delta suggests
The observable facts are firm: Fable 5's prompt carries explicit guidance on communication style, autonomous-operation judgment, and comment discipline that Opus 4.8's prompt simply does not. The interpretation is inference, so treat it as hypothesis rather than fact.
Here is the counterintuitive part. Fable 5 is the more capable model, not the less capable one. You might expect the stronger model to need less hand-holding. The opposite is true: Anthropic's most capable model receives more explicit behavioral instruction, and the prior flagship receives less.
Look at what the additions actually are. They are not capability boosts; they are constraints. A section on communicating with restraint (lead with the outcome, favor readability, do not compress into fragments). A line on comment discipline. And an autonomy section that reads like an operating manual for an agent you are about to leave unsupervised: proceed on reversible actions without asking, do not end a turn on an unfinished plan, verify that the evidence supports a destructive command before running it. These read as the guardrails you would write for a model you intend to trust with long-horizon, autonomous work, which is precisely how Anthropic positions Fable. The more agentic and capable the model, the more explicit the operating constraints, not the fewer.
There is an alternative hypothesis to rule out: that these sections are simply the newest iteration of the Claude Code prompt, shipped with Fable's launch, and Opus 4.8's prompt predates them. It does not hold. Both models ran the same Claude Code build (2.1.170) in our captures and still received different prompts, so the divergence is keyed to the --model value, not to a rollout the older model missed. What we cannot see is Anthropic's server-side routing logic, so treat the motivation as hypothesis rather than confirmed intent. Either way the defensible reading is the same: the prompt is model-specific, and any analysis of "Claude Code's system prompt" that does not name the model is underspecified.
A second signal from the wire
The system prompt is not the only thing that differs by model on the wire. The anthropic-beta request header, captured the same way, is identical between the two models except for a single flag that Fable carries and Opus does not.
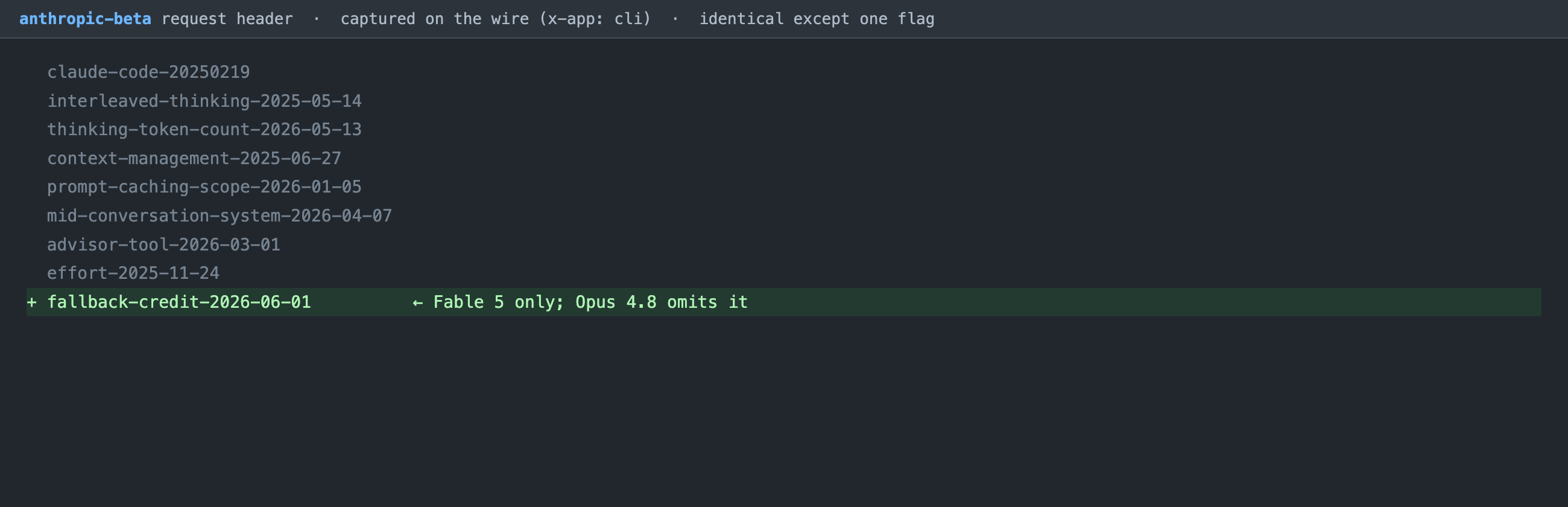
Figure 5. The anthropic-beta header. Eight feature flags are shared; only Fable 5 carries fallback-credit-2026-06-01.
This lines up with Anthropic's documented design for Fable (see Anthropic's "Introducing Claude Fable 5 and Claude Mythos 5" and its refusals-and-fallback guide). Fable 5 includes safety classifiers that can decline a request with stop_reason: "refusal"; a refused request is then retried on another model (Opus 4.8 among them), and a "fallback credit" refunds the prompt-cache cost of that switch. Opus is one of the models Fable falls back to, so it has no need for the flag. We did not have to take that architecture on faith from a press write-up; we watched the client advertise it, on the wire, for Fable alone. It is a small, clean example of the broader point: the same harness sends materially different requests depending on which model is behind it, and you can see the seams if you look at the bytes.
Companion piece: The enterprise-deployment side of this refusal-and-fallback design - what the retention floor, silent model substitution, and classifier false positives mean for a regulated rollout - is covered in Refusals, Fallback, and Retention: What Claude Fable 5 Changes for Enterprise AI Security.
A note on corporate TLS interception
If your machine sits behind a TLS-inspecting proxy, mitmproxy's upstream leg will fail certificate verification, because the certificate presented for the API is reissued by the inspection appliance rather than the real CA. You can see this directly in the certificate detail: the issuer is your corporate decryption appliance. Add --ssl-insecure to skip upstream verification (acceptable, since the upstream is already inspected and the real trust boundary is the corporate proxy), or run the capture from an environment that is not behind inspection. Either way, the prompt capture itself is unaffected; this only changes whether the test call gets a real reply.
Credential hygiene and responsible disclosure
Non-negotiables, especially if any of this goes into a document:
- The API key is in every request header (
x-api-key). Any raw capture writes it to disk. Frame screenshots on the JSON body, keep headers out of frame, and treat any key that appears in an image as burned. Rotate it. - We are not publishing the full system prompt. Showing the method and the cross-model delta is useful; dumping the entire payload is a separate decision each reader can make for themselves.
- Scrub tier 3. Run captures with a throwaway
CLAUDE_CONFIG_DIRso your ownCLAUDE.mdnever enters the capture. Every figure in this article was produced that way; the personal profile in Figure 3 is a dummy.
Recap
- The system prompt lives only on the wire, assembled per request.
- Put an intercepting proxy in front of Claude Code with
ANTHROPIC_BASE_URL, and pick thePOST /v1/messagesflow. - Read it in three tiers: the immutable system field, harness-injected messages, and your own config.
- Change only
--modeland the prompt itself changes: Fable 5 gets explicit communication, autonomy, and comment-discipline instructions that Opus 4.8 does not. - Counterintuitively, the more capable model (Fable 5) gets more explicit constraint, not less. The additions are restraint, communication, and autonomy guardrails for long-horizon agentic work, and a separate wire signal (the
fallback-creditbeta flag, Fable-only) lines up with Fable's documented refusal-and-fallback design.
The technique is simple and the tooling is free. The finding is the part that lasts: "Claude Code's system prompt" is not a single artifact. It is an assembled, model-specific control surface, and the model-specific parts may be the most revealing part of the whole request.
Sources
- Anthropic, "Introducing Claude Fable 5 and Claude Mythos 5"
- The "most capable widely released model" and tier-above-Opus framing is Anthropic's own, from the document above.
- All system-prompt and
anthropic-betaheader captures are primary observations from the Claude Code client (build 2.1.170), captured June 2026. The full system-prompt text is intentionally not reproduced.