Table of Contents
- Why Agents Need Memory
- A Scaffold from Human Cognition
- The Four Types of Agent Memory
- Short-Term, Long-Term, and the Shape of a Session
- Memory Hierarchies
- Where Memory Lives: It Is Not All Vectors
- The Memory Lifecycle: Write, Manage, Read
- Anatomy of a Session
- Implementation Patterns
- The Frameworks Landscape
- Open Research Challenges
- Where Memory Research Is Going
- A Note on Memory Security
- Why Memory Is the Thing
Why Agents Need Memory
A large language model, on its own, remembers nothing. Each call to the model is a fresh start. You hand it a block of text, it produces a continuation, and then it forgets everything. The model that answered your last question is, mechanically, the same model that has never met you. There is no carry-over, no running notebook, no sense of "earlier." A transformer is a pure function: the same input produces the same distribution of outputs, every time, with no state in between.
This is easy to miss because chatbots feel like they remember. Ask a follow-up question and the assistant responds as if it recalls the conversation. But that illusion is manufactured. Under the hood, the application is re-sending the entire conversation back to the model on every turn. The "memory" you experience is just the transcript being replayed into the prompt, again and again, growing a little longer each time.
That replay trick works until it doesn't. The context window, the maximum number of tokens a model can read at once, is finite. Conversations outgrow it. Important facts from forty turns ago fall off the front. Costs climb linearly with every token you re-send. And nothing survives once the session ends: close the tab, come back tomorrow, and the agent has no idea who you are.
So when we talk about giving an AI agent "memory," we are really talking about engineering a system around the model that decides what to keep, where to put it, how to find it again, and when to let it go. An agent session is fundamentally a memory-management pipeline that happens to include reasoning. The model supplies the reasoning. Everything that makes that reasoning feel continuous, personalized, and cumulative is memory infrastructure built around it.
A crucial distinction before we go further: the context window is not memory. The context window is more like attention or short-term working space. Treating it as memory, by just stuffing more and more text into it, is the most common mistake in agent design, and it fails in two ways. It hits hard token limits, and, more insidiously, model performance degrades as the context fills with marginally relevant material. Real memory is selective. It decides what is worth keeping and surfaces only what is worth recalling right now.
A Scaffold from Human Cognition
The vocabulary the field uses for agent memory is borrowed directly from cognitive psychology, and the borrowing is deliberate. Decades of research on human memory produced a taxonomy that turns out to map surprisingly well onto the problems agent builders face.
Psychologists draw a few key distinctions. Endel Tulving separated episodic memory (memory of specific events you experienced, your first day at a job) from semantic memory (general facts you know, that Paris is the capital of France) within long-term declarative memory. A separate line of work distinguishes declarative memory (things you can state) from procedural memory (skills you perform without being able to fully articulate them, like riding a bike). And Alan Baddeley's model of working memory describes the small, active buffer where you manipulate information you are currently thinking about.
These four categories, working, episodic, semantic, and procedural, became the organizing framework for agent memory. Two influential sources arrived at nearly the same taxonomy from different directions. The academic framework CoALA (Cognitive Architectures for Language Agents) formalized the four-module view by drawing on the history of cognitive science and symbolic AI. Practitioner toolkits like LangChain's memory libraries landed on the same four through engineering necessity. When theory and practice converge independently, it is usually a sign the carving is real.
One honest caveat before we lean on the analogy. This is a scaffold, not a claim of equivalence. An agent's semantic memory is a vector database with a retrieval function, not a biological network of neurons, and we should not pretend the mechanisms are the same. But the analogy earns its place because it answers the right questions: What is worth storing? How long should it last? How do you find it again? Human cognition has been solving those exact problems for a very long time, and the categories it evolved are a good map for the categories an agent needs.
The Four Types of Agent Memory
To keep this concrete, picture a coding agent helping a developer fix a bug. As we walk through each type, notice where that agent's information lives:
- Working memory: the bug it is fixing right now
- Semantic memory: the company's coding standards
- Episodic memory: a similar bug it fixed last week
- Procedural memory: its standing rule to always open a pull request before merging
Four different questions, four different stores. Here is each in detail.
Working Memory: The Active Scratchpad
Working memory is the information the agent is actively using for the task right now. In CoALA's words, it "maintains active and readily available information as symbolic variables for the current decision cycle." In practice this is the live context window: the current user request, the agent's intermediate reasoning, the results of tool calls it just made, and the goals it is carrying from one step to the next.
Working memory is fast, small, and transient. It is where thinking happens. When an agent reasons through a multi-step problem, scratching out a plan, calling a tool, reading the result, and deciding what to do next, all of that lives in working memory. The moment the task ends, or the context window fills, this material has to either be discarded or promoted into longer-term storage. Working memory is short-term by definition.
The everyday analogy is holding a phone number in your head just long enough to dial it. You are not learning the number; you are holding it active for immediate use, and it is gone a minute later.
Episodic Memory: What Happened
Episodic memory stores specific past experiences. CoALA defines it as memory that "stores experience from earlier decision cycles," which can be "history event flows, game trajectories from previous episodes, or other representations of the agent's experiences." It is the record of particular events: this user asked for X last Tuesday and reacted well when the agent did Y; on this kind of task, this sequence of steps worked.
The defining feature of episodic memory is that it is grounded in specific instances. It is not "users generally prefer concise answers" (that is a fact, which is semantic). It is "in that conversation, this exact approach succeeded." Because it stores concrete examples, episodic memory is most naturally used through dynamic few-shot prompting: when a new task arrives, the agent retrieves a handful of similar past episodes and drops them into the prompt as examples of what to do. The agent learns from its own track record by example rather than by rule.
The human analogy is remembering a particular event, the specific meeting last week, with its specific details, rather than a general fact you have abstracted from many experiences.
Semantic Memory: What Is True
Semantic memory is the agent's store of facts, about the world, about the domain, and especially about the user. CoALA describes it as storing "an agent's knowledge about the world and itself," including both externally sourced information and knowledge the agent derives for itself over time.
This is the memory type most people picture when they imagine a "personalized" assistant. At the individual level, the user mentions they are vegetarian, that they prefer metric units, and those preferences get stored and reused. But the higher-value case is the enterprise one. Picture an internal engineering agent whose semantic memory holds the organization's standing facts:
- The company authenticates with OAuth2.
- Production runs on AWS.
- The coding standard requires async FastAPI.
- Redis is the approved cache.
The agent stores these once and acts on them in every future session, so engineers never have to restate the house rules. Those facts get extracted from conversation (or seeded from documentation), stored, and retrieved later to inject into the prompt on future turns. Retrieval-augmented generation (RAG) over a knowledge base is semantic memory too: a repository of facts the agent can look things up in.
It is worth flagging a common misconception here, one we will return to: semantic memory does not have to live in a vector database. Embeddings are the popular default, but facts can just as well live in a relational table, a key/value store, a document store, or a knowledge graph. The human analogy is the knowledge you carry without remembering where you learned it: you know Paris is in France, but you do not remember the specific moment you acquired that fact.
Procedural Memory: How to Act
Procedural memory is the agent's knowledge of how to do things, its skills and its operating instructions. This is the most subtle of the four because in a language agent it lives in several places at once. CoALA pins it down precisely: language agents hold "two forms of procedural memory: implicit knowledge stored in the LLM weights, and explicit knowledge written in the agent's code."
In other words, procedural memory is partly the model itself (everything it learned during training about how to write code, follow instructions, and structure an answer) and partly the scaffolding the engineer wrote (the agent's control flow, its tool definitions, and its system prompt). The system prompt is the most malleable slice: it is where an agent's standing instructions, its persona, and its learned operating procedures can be encoded and refined. "Always open a pull request before merging" is procedural memory.
In practice, procedural memory is the least frequently updated of the four. Almost no production system retrains the model's weights on the fly; that is expensive and risky. Most "procedural learning" today happens by editing the system prompt or a skills library, sometimes automatically, when an agent reflects on what worked and rewrites its own instructions. The human analogy is riding a bike: a skill you perform fluently without being able to fully articulate the steps, and one that, once learned, you rarely rethink.
How the Four Memory Types Work Together
| Memory type | Stores | Updated | Human analogy | Horizon |
|---|---|---|---|---|
| Working | Current task state, reasoning, tool results | Constantly, within the task | Holding a phone number to dial it | Short-term |
| Episodic | Specific past events and successful trajectories | When notable episodes occur | Remembering a particular meeting | Long-term |
| Semantic | Facts about the world and the user | When new durable facts appear | Knowing Paris is in France | Long-term |
| Procedural | Skills, weights, code, system prompt | Rarely (mostly via prompt edits) | Riding a bike | Mostly static |
A useful way to hold all four: working memory is what I am thinking about now, episodic is what happened before, semantic is what I know to be true, and procedural is how I do things.
These pieces are not independent boxes; they form a single loop around the model. The user's request lands in working memory, the long-term stores are retrieved into that same working memory, the assembled context goes to the model, and the model's output both answers the user and decides what new memories to write back. The diagram below is the schematic to keep in mind for the rest of this article:
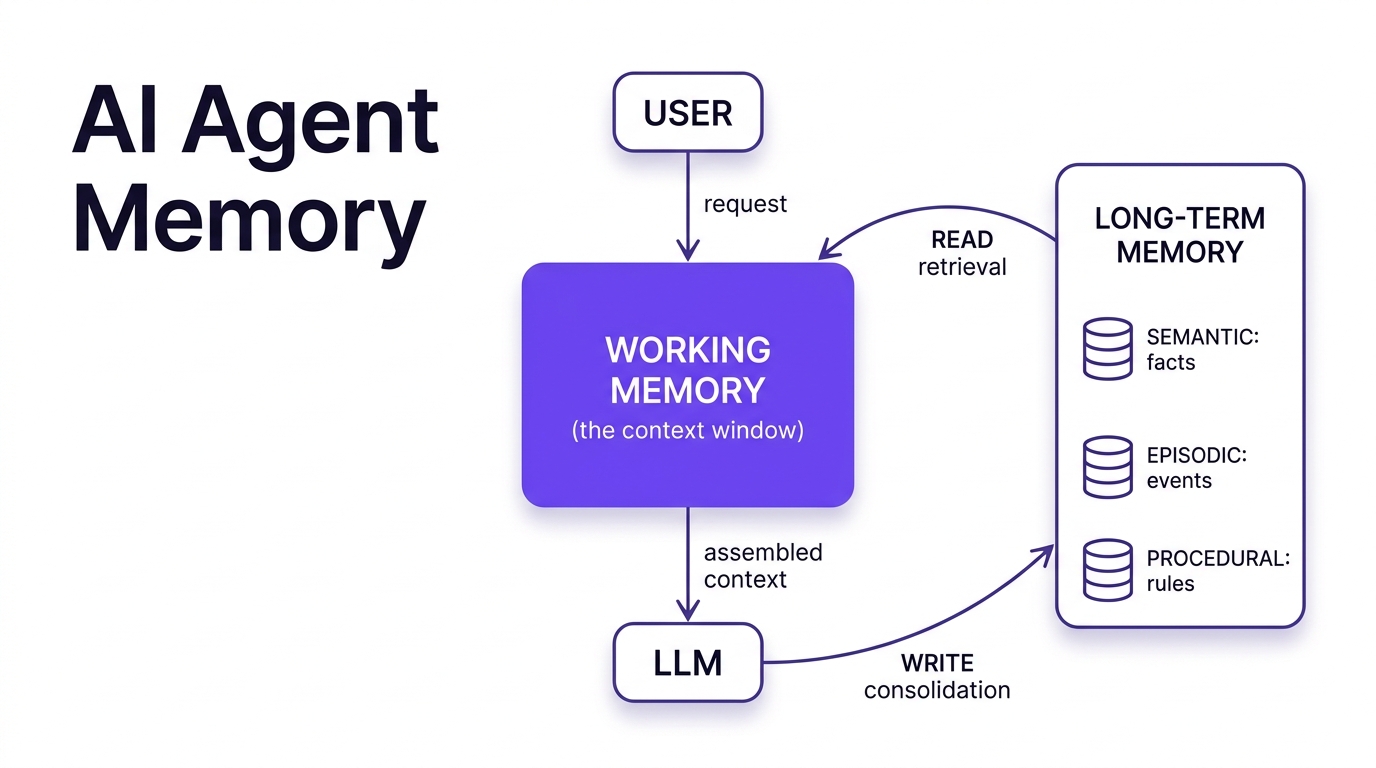
Figure 1: The agent memory loop. The model only ever sees working memory; long-term stores are read in and written back.
The model only ever sees working memory. The long-term stores matter only insofar as the right pieces of them get read into working memory at the right moment, and the system only improves insofar as the right things get written back. That read path and that write path are where the next several sections, and most of the engineering, live.
Short-Term, Long-Term, and the Shape of a Session
Cutting across the four types is a simpler split: short-term versus long-term. Working memory is short-term; it lives inside a single session and a single context window. The other three are long-term; they are meant to outlive any one conversation, which means they must be stored somewhere outside the model and the context window, in a database, a vector store, or a file.
This is where two more terms matter for understanding sessions. Most agent frameworks organize conversations into threads (a single continuous conversation) and use checkpoints to save the state of a thread so it can be paused and resumed. Within a thread, short-term memory is just the thread's running state. Across threads, anything the agent should still know tomorrow has to be lifted out of the thread and written into long-term memory. The boundary between "within-session" and "across-session" memory is exactly the boundary between the context window and the external store.
This framing answers a question that confuses a lot of people: why does an assistant sometimes remember things across conversations and sometimes not? The answer is that within-session continuity is nearly free (it is just the replayed transcript), while across-session continuity requires deliberate engineering, extracting facts, storing them, and retrieving them next time. They are different mechanisms, and a system can have one without the other.
Memory Hierarchies
The short-term versus long-term split is really the two ends of a spectrum. Modern agent systems increasingly arrange memory as a tiered hierarchy, much like a computer arranges CPU registers, RAM, disk, and cold archive: each tier down is larger, cheaper, slower to reach, and longer-lived than the one above it.
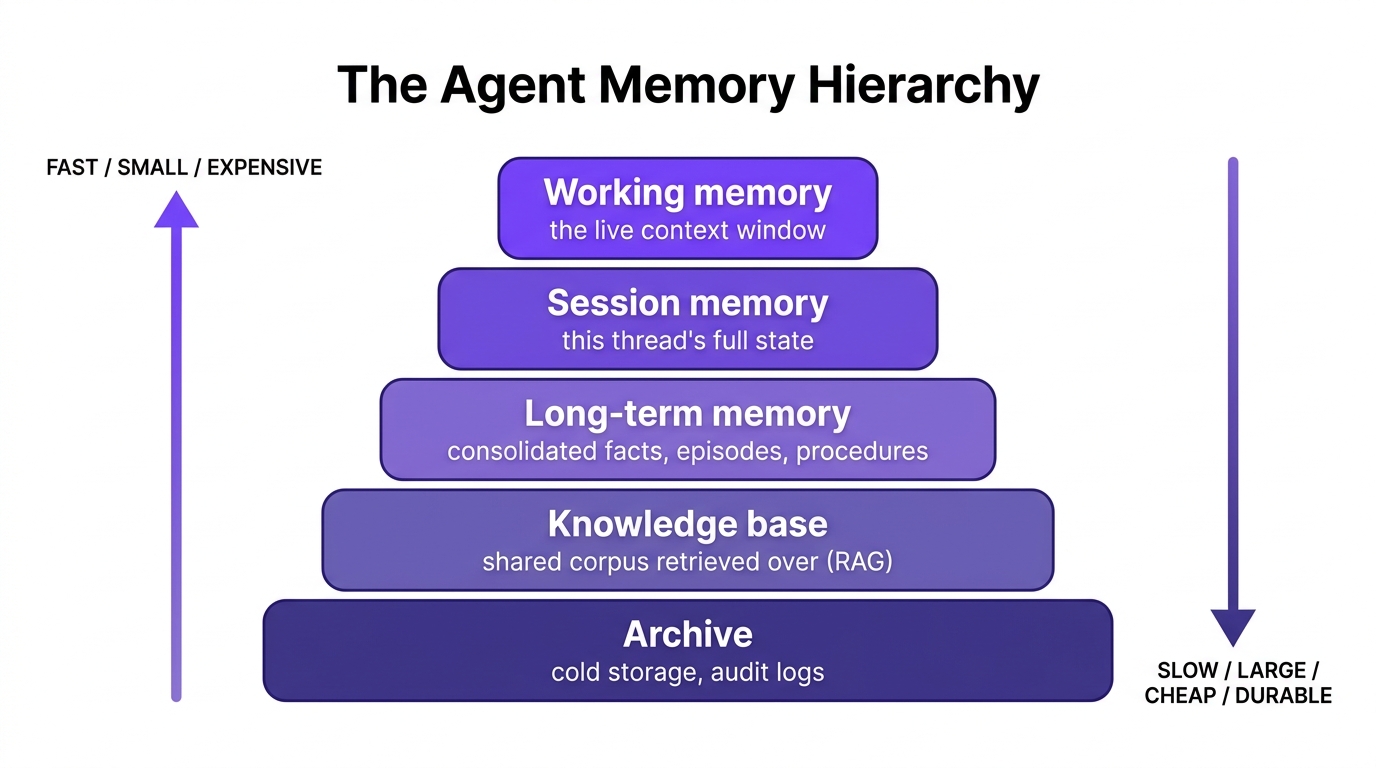
Figure 2: The memory hierarchy. Higher tiers are faster and smaller; lower tiers are larger, cheaper, and longer-lived.
The hierarchy matters because each tier has a different job and a different cost. Working memory is in front of the model on every single token, so it is the most expensive real estate and must be kept lean. Session memory captures a whole conversation but is scoped to one thread. Long-term memory is the consolidated, cross-session store of the three durable types. A knowledge base is the broad, often shared corpus the agent retrieves over rather than something it personally "learned." And the archive holds everything you are not actively using but cannot throw away, which, for a security-conscious team, is also where audit trails of what the agent stored and why end up living. Information flows down the hierarchy as it is consolidated and flows back up as it is retrieved.
Where Memory Lives: It Is Not All Vectors
Because vector databases dominate the conversation, it is easy to walk away thinking "agent memory = embeddings in Pinecone." That is one option, not the definition. The storage layer is an engineering choice, and different stores suit different memory types:
- Vector databases (similarity search over embeddings): good for fuzzy semantic recall and dynamic few-shot retrieval.
- Relational / SQL databases: good for structured facts, user profiles, and anything you need to query exactly or join.
- Key/value stores: good for fast lookups of well-identified items (a user's settings, a session blob).
- Document stores: good for semi-structured records and whole-episode payloads.
- Knowledge graphs and graph databases: good for relationships between entities and for reasoning over how facts connect, which flat retrieval cannot express.
Real systems mix these. A single agent might keep working memory in process, session state in Redis, durable facts in Postgres, embeddings in a vector index, and entity relationships in a graph. Choosing the right substrate per memory type is half the design work, and, as the security article will show, each substrate comes with a different access-control and tamper-resistance profile.
The Memory Lifecycle: Write, Manage, Read
Every long-term memory system, regardless of framework or storage choice, implements the same three-stage loop. Understanding this loop is the single most transferable idea in this article, because it generalizes across every tool and reappears, unchanged, when we look at memory security.
Write. The agent decides what is worth committing to long-term memory and from where. The source might be the user's own words, the output of a tool, a retrieved document, or a message from another agent. Not everything should be written; a good memory system is selective about what crosses the threshold from transient to durable.
Manage. Stored memory is not static. It gets consolidated (many small observations summarized into a durable fact), deduplicated, and sometimes promoted (a repeated episodic pattern abstracted into a semantic rule). It also gets forgotten: old or low-value entries are evicted or allowed to decay so the store does not grow without bound and retrieval does not drown in noise. Forgetting is a feature, not a bug. A memory system that never forgets eventually retrieves so much marginal material that it degrades the very reasoning it was meant to support.
Read. When the agent needs context, it retrieves the relevant memories, usually by embedding the current situation and finding the nearest stored entries by similarity, ranks them, and inserts the best ones into the working context. Retrieval quality is where many systems live or die: retrieve too little and the agent forgets; retrieve too much and you reintroduce the context-bloat problem you were trying to escape.
A second axis governs when the write happens. Memory can be updated in the hot path, where the agent explicitly decides to store something (typically via a tool call) before it finishes responding. This is how ChatGPT's memory feature works. It is immediate and transparent, but it adds latency to every response and tangles memory logic into the agent's main reasoning. The alternative is updating in the background, where a separate process consolidates memory during or after the conversation. This keeps responses fast and separates concerns cleanly, at the cost of a delay before new information becomes available and the added complexity of deciding when the background job should run.
Anatomy of a Session
Let us make this concrete with a short walk-through. Imagine a developer returning to a coding assistant for the third time this week.
The user types: "Add rate limiting to the payments endpoint." Several memory systems engage at once.
- Working memory loads with the request, and the agent begins reasoning: which endpoint, what limit, which library.
- Semantic memory is queried and returns durable facts about this project: the codebase uses async FastAPI, the team standard is Redis-backed rate limiting, production runs on AWS.
- Episodic memory is queried and surfaces a similar past episode: last week the agent added rate limiting to the auth endpoint, the user approved the approach, and that successful trajectory is retrieved as a worked example.
- Procedural memory, the system prompt and the agent's tool-using code, governs how it goes about the task: it proposes a plan, edits files, and always opens a pull request before merging.
The agent proposes a solution consistent with all of this, the user approves, and now the write stage fires: the new successful episode is recorded, and if the user revealed anything durable ("actually, standardize on 100 requests per minute across all endpoints"), that becomes a new semantic fact. Tomorrow, in a fresh session with an empty context window, the agent will still know the project's conventions and its own track record, because they were lifted out of the thread and into long-term stores. That continuity, assembled deliberately from four different memory systems, is what makes it feel like an agent rather than an autocomplete.
Implementation Patterns
The following sketches show the shape of each memory type in code. They are illustrative rather than production-ready, meant to make the mechanics concrete.
Working memory is usually a managed buffer over the conversation. The key operation is keeping it within budget, often by summarizing older turns rather than dropping them outright:
class WorkingMemory:
def __init__(self, max_tokens=8000):
self.messages = []
self.max_tokens = max_tokens
def add(self, message):
self.messages.append(message)
if self.token_count() > self.max_tokens:
self.compress()
def compress(self):
# Summarize the oldest turns into a single note,
# preserving recent turns verbatim.
old, recent = self.messages[:-6], self.messages[-6:]
summary = llm.summarize(old)
self.messages = [{"role": "system", "content": summary}] + recentSemantic memory extracts durable facts and stores them for retrieval. Note the store could be a vector index, a SQL table, or a graph; the interface is what matters:
def write_semantic(conversation, store):
facts = llm.extract_facts(conversation) # "Team standard: async FastAPI"
for fact in facts:
store.upsert(text=fact, embedding=embed(fact), kind="semantic")
def read_semantic(query, store, k=5):
return store.search(embedding=embed(query), kind="semantic", top_k=k)Episodic memory stores whole trajectories and retrieves them as few-shot examples:
def write_episode(task, steps, outcome, store):
if outcome == "success":
store.upsert(text=task, embedding=embed(task),
payload={"steps": steps}, kind="episodic")
def read_episodes(task, store, k=3):
hits = store.search(embedding=embed(task), kind="episodic", top_k=k)
return [h.payload["steps"] for h in hits] # used as worked examplesProcedural memory, when it updates at all, usually does so by reflecting on outcomes and rewriting the system prompt or a skills entry:
def reflect_and_update(system_prompt, recent_failures):
revision = llm.complete(
f"Given these failures: {recent_failures}\n"
f"Improve these standing instructions:\n{system_prompt}"
)
return revision # becomes the agent's new procedural baselineThe Frameworks Landscape
You rarely build all of this from scratch. A small ecosystem of memory tooling has grown up, each with a one-line philosophy worth knowing:
- LangGraph / LangMem - composable orchestration with explicit state management. Low-level store primitives and templates for semantic, episodic, and procedural memory, supporting both hot-path and background updates. You assemble the pieces yourself.
- Letta (formerly MemGPT) - the operating-system approach, with paging. The agent self-edits its memory and moves information between the active context and external storage when the context fills, treating the context window like RAM and the store like disk.
- Mem0 - automatic extraction of durable facts. An extraction-focused memory layer designed to drop into an existing application with minimal ceremony.
- Zep - a temporal knowledge graph. Memory that tracks how facts change over time rather than storing them as flat, timeless entries.
- Cognee - relationship-centric graph memory. Combines graph structure with semantic memory to capture how stored items connect.
The right choice depends on what you are optimizing for: composability, self-managing agents, drop-in simplicity, or structured, time-aware knowledge. The underlying write-manage-read loop is the same in all of them.
Open Research Challenges
Memory is not a solved problem, and an honest treatment has to name the unsolved parts.
Context rot. Adding more context does not monotonically improve performance. Beyond a point, a longer, busier context degrades the model's reasoning even when the relevant fact is present, because the signal is diluted by surrounding noise. This is the deepest reason memory has to be selective rather than accumulative.
Knowing what to forget. Eviction and decay policies are genuinely hard. Forget too aggressively and the agent loses things it needed; forget too little and retrieval quality rots. Most systems use heuristics (recency, frequency, an importance score) that are easy to get wrong.
Retrieval quality and structure. Flat similarity search over embeddings is the default, and it is weak at capturing relationships and event structure. This is why a wave of recent work moves toward graph-structured and explicitly episodic memory.
Drift. Over long horizons, an agent's accumulated memory can slowly pull its behavior off course, a phenomenon variously called semantic drift or "soul erosion." Small consolidation errors compound, and maintaining behavioral consistency across hundreds of sessions is an active research problem.
Where Memory Research Is Going
If the challenges above are the open problems, here is where the field is actively pushing. Expect the next year of agent-memory work to cluster around these themes:
- Graph and structured memory: moving past flat vector stores toward graphs that preserve how facts and events relate.
- Hierarchical memory: formalizing the tiered architecture above, with principled promotion and eviction between tiers.
- Reflection and self-editing agents: agents that periodically review their own history and rewrite their semantic and procedural memory, learning without retraining.
- Memory compression: smarter consolidation that keeps the signal while shrinking the footprint, directly attacking context rot.
- Long-context models versus external memory: as context windows reach millions of tokens, an open debate over how much memory machinery you still need, and the emerging answer that bigger context complements rather than replaces selective memory.
- Memory benchmarks: standardized evaluations (long-conversation QA, retention over many sessions) so claims about memory systems can be compared rather than asserted.
- Memory safety: treating the memory store as a security boundary, which is exactly where the next article picks up.
A Note on Memory Security
There is a flip side to everything above that deserves its own treatment. Memory is also a new attack surface. Every persistent memory system raises questions about poisoning (planting false or malicious content), unauthorized writes, retrieval manipulation, privacy leakage across users, and slow long-term corruption of an agent's behavior. The very property that makes memory valuable, that it survives the session, is the property an attacker most wants to abuse, because a single poisoned entry can influence an agent's behavior for weeks. We will return to those topics in a dedicated future article on agent memory as an attack surface.
Why Memory Is the Thing
Strip the memory infrastructure away and you are left with a very capable text predictor that resets every few thousand tokens. Add it back, the working scratchpad, the episodic record of what worked, the semantic store of what is true, the procedural sense of how to act, and the same model becomes something that accumulates, personalizes, and improves. Memory is the substrate that turns a stateless model into an agent with continuity.
It is also why agents behave the way they do across a session: the continuity you feel is assembled, turn by turn, from four distinct systems writing, managing, and reading a shared store. Understanding those systems, and the single loop that connects them, is the difference between an agent that mysteriously forgets the thing you told it twice and one that quietly remembers exactly what it should.
Sources and further reading: CoALA, "Cognitive Architectures for Language Agents" (arXiv:2309.02427); LangChain, "Memory for agents"; surveys on memory for autonomous LLM agents (arXiv:2603.07670, 2509.18868). Frameworks: LangGraph/LangMem, Letta/MemGPT, Mem0, Zep, Cognee.