Table of Contents
- Introduction
- Part I: The Fundamental Choice
- Part II: Scale-Up Revolution
- Part III: Scale-Out Fabrics
- Part IV: The Science of Scaling
- Part V: Strategic Implications
Trillion-parameter models arrived. Everything changed. Your data center architecture now determines whether training succeeds or fails spectacularly. OpenAI faced this exact crossroads with GPT-4, staring down the same brutal choice that now confronts every organization pursuing AI at scale. Scale up within single racks, packing unprecedented density into liquid-cooled monsters? Or scale out across multiple racks, relying on high-performance networking to weave thousands of GPUs into coherent computational fabrics?
This isn't just technical housekeeping. The choice you make here will ripple through your organization for years, fundamentally shaping what you can build, how fast you can build it, and whether you'll lead or follow in the AI revolution that's rewriting every industry.
The Stakes Are Higher Than You Think
Picture this nightmare. Your GPUs sit idle. Data transfers crawl through millisecond delays when they should flash by in microseconds, and every tick of the clock burns thousands of dollars while your competition trains models faster, cheaper, better. That's not a hypothetical horror story—it's what happens when you choose the wrong architecture for trillion-parameter training, turning months of calendar time into wasted capital and missed market opportunities that compound into strategic disasters.
Scale-up versus scale-out determines everything. Breakthrough performance or mediocre results. Market leadership or playing catch-up. The difference between training a frontier model in weeks versus months translates directly to competitive advantage in markets where first-mover advantage means everything.
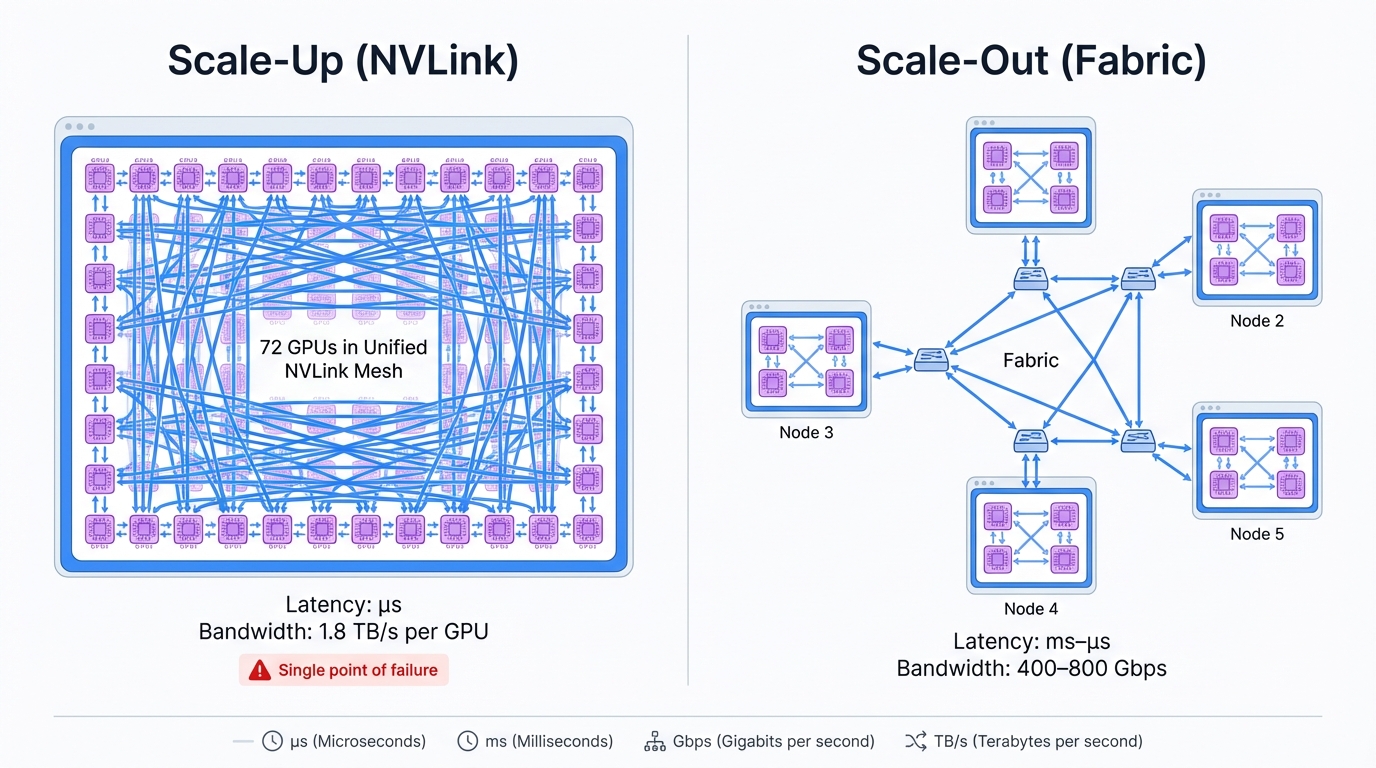
Two radically different philosophies battle for your infrastructure budget, each representing fundamentally opposed visions of how AI computing should evolve. NVIDIA's GB200 NVL72 embodies scale-up perfection taken to its logical extreme—seventy-two GPUs unified into one massive accelerator through fifth-generation NVLink switches that create a single, coherent computational fabric with bandwidth and latency characteristics that simply cannot be matched by any distributed approach.
The alternative? Scale-out. Hundreds of traditional nodes spread across data center racks, connected through InfiniBand or advanced Ethernet fabrics that must somehow coordinate these distributed resources into something that approaches the coherence of a monolithic system.
Your workload's C2C ratio holds the secret to this choice, cutting through vendor marketing to reveal the brutal truth about where your bottlenecks actually live. Communication-to-Computation ratios tell you how much time you're spending moving data versus computing results, and this single number determines whether you need the extreme bandwidth and microsecond latencies of rack-scale systems or whether robust scale-out fabrics will serve you perfectly well at a fraction of the cost.
Understanding the C2C Ratio: Your Decision-Making Compass
The C2C ratio slices through the noise. While vendors tout aggregate bandwidth numbers that look impressive on datasheets, Communication-to-Computation ratios reveal the actual bottlenecks strangling your training performance. When you're running massive Tensor Parallelism across frontier models where individual layers exceed GPU memory capacity, network performance becomes absolutely critical—the NVL72's 1.8 TB/s bandwidth transforms from impressive specification to essential requirement, and sub-microsecond latency stops being a luxury and becomes the difference between training success and expensive failure.
Most AI workloads don't need this. That's the dirty secret vendors won't tell you. Data parallelism keeps many workloads thoroughly compute-bound, with GPUs spending most of their time calculating rather than waiting for data. Smaller model inference stays happily compute-limited throughout. Well-designed 400G or 800G fabrics handle these workloads beautifully, delivering excellent performance while saving millions in upfront infrastructure costs that can be redirected toward actually useful things like more GPU nodes or better software optimization.
The security implications stagger the imagination when you really think through what concentration means in practice. Fifty million dollars of training infrastructure sitting in one rack creates an irresistible target for sophisticated attackers who now have a single point of attack for maximum impact. Scale-up architectures naturally create honeypots for model weight theft and malicious data injection, concentrating your most valuable AI assets in ways that make comprehensive security incredibly difficult. Scale-out architectures fragment attack surfaces by design, forcing adversaries to breach multiple independent systems if they want comprehensive access, dramatically raising the bar for successful attacks while creating natural isolation boundaries that can be leveraged for defense in depth.
The Fundamental Choice: Vertical Power vs. Horizontal Scale
Trillion-parameter models force you to confront computing's oldest architectural trade-off, the fundamental tension that's defined every major infrastructure decision since the mainframe era. Build massive monolithic systems packed with resources, creating vertical towers of computational power? Or distribute workloads across many smaller interconnected machines, scaling horizontally across commodity infrastructure?
This choice matters more now. Wrong decisions burn capital and make entire classes of AI models impossible to train effectively, closing off strategic opportunities before you even realize they existed.
The Monolithic Compute Revolution
Vertical scaling once meant stuffing servers with more RAM and faster CPUs, pushing individual machines to their physical limits. Simple. Straightforward. The AI revolution demolished these comfortable assumptions. NVIDIA's NVLink technology binds GPUs together so tightly they behave as single massive accelerators, creating what the industry calls "scale-up domains" that span from individual servers to entire racks, fundamentally redefining what a single computer can be.
The NVL72 creates one 72-GPU brain. Every neuron talks to every other neuron at speeds that make traditional networking look glacial. Network delays vanish. Packet loss becomes a non-issue. External bottlenecks between critical computations simply cease to exist when everything happens within a unified fabric that operates at memory speeds rather than network speeds.
Programming becomes beautifully simple within this unified computational space. Developers see one enormous compute resource instead of wrestling with 72 separate GPUs, each with its own memory and communication constraints. Memory appears unified across the entire domain. Communication happens at hardware speeds without software overhead slowing things down. All that distributed system complexity that normally dominates AI infrastructure design just vanishes within scale-up boundaries, letting developers focus on algorithms rather than fighting infrastructure.
But this simplicity demands brutal compromises that many organizations discover too late. Physical laws don't bend—you can only pack so much power and cooling into a single rack before thermodynamics says no, and component costs scale exponentially with performance as you push toward theoretical limits. A single system failure takes down massive compute capacity, creating availability risks that distributed systems naturally avoid through redundancy and graceful degradation.
Most critically for AI security: concentrating $50+ million of infrastructure in a single rack creates an irresistible target that's incredibly difficult to defend. One successful physical or cyber attack compromises enormous computational assets, model weights, training data, and intellectual property in a single breach that can devastate competitive position.
The Distributed Cluster Philosophy
Horizontal scaling takes the opposite path. Instead of building massive individual systems that push physical limits, you connect many smaller, independent nodes with high-performance networks, distributing computation across a fabric of commodity hardware. This philosophy powers every major cloud platform and enables the hyperscale data centers that trained today's largest models, proving itself through sheer ubiquity.
Scale-out architectures offer near-limitless growth. Add nodes when you need capacity. Remove them when demand drops. Node failures don't cripple entire systems—workloads simply redistribute across remaining resources, maintaining service availability even as individual components fail underneath.
Security perspectives favor distribution from first principles. Compromising one node doesn't expose your entire training infrastructure, limiting blast radius and containing damage. Attackers must breach multiple independent systems to cause significant harm, dramatically increasing their effort and risk of detection while giving defenders multiple opportunities to catch intrusions before they spread.
The trade-off manifests in network complexity that grows exponentially with cluster size. As clusters expand, interconnect complexity explodes in ways that become genuinely difficult to manage. Applications need specific design for distributed environments, adding development complexity that can't be wished away. Ensuring data consistency across thousands of independent machines becomes an enormous engineering challenge that consumes significant resources just to maintain correctness.
For AI workloads specifically, inter-node network bandwidth and latency directly determine training efficiency in ways that are mathematically unavoidable. When GPUs spend more time waiting for network transfers than computing gradients, expensive hardware becomes severely underutilized, burning money on idle silicon while training timelines stretch beyond business viability.
The Blurring Architectural Boundaries
Modern AI supercomputing evolved beyond simplistic scale-up versus scale-out debates that dominated earlier infrastructure discussions. Today's most advanced systems employ sophisticated hybrid strategies—they scale up within carefully defined boundaries to create powerful building blocks, then scale out by connecting these blocks with high-performance networks, getting the best of both approaches when executed correctly.
The question shifted fundamentally. You're no longer choosing between scale-up or scale-out, but rather asking a more nuanced question: how large should your fundamental scale-up unit be, and how do you connect these units into larger systems?
Early implementations made the scale-up domain a single eight-GPU server, using NVLink technology to transform these servers into tightly-coupled compute units where all GPUs communicated faster than the server's PCIe bus could possibly handle. These 8-GPU nodes became standard building blocks for larger clusters, connected via InfiniBand or Ethernet fabrics that tied hundreds or thousands of nodes into training clusters.
The NVL72 represents a paradigm shift that fundamentally changes the economics and physics of AI infrastructure. It expands the scale-up boundary from an 8-GPU server to a 72-GPU rack, and this isn't just a quantitative change—it's qualitative. The entire rack functions as a single, non-blocking compute unit, essentially creating a data-center-sized GPU with unified memory and communication characteristics that were simply impossible before this generation.
This architectural decision carries profound implications that ripple through every aspect of deployment and operation. It concentrates immense computational power and equally immense communication demands within a single physical footprint before using scale-out fabrics to connect to other racks, fundamentally altering how you think about resource allocation, power delivery, cooling infrastructure, and failure domains. The security implications prove equally profound—protecting one rack becomes as critical as protecting an entire traditional cluster, requiring rethinking of physical security, access controls, monitoring, and incident response at rack granularity.
Inside the Scale-Up Revolution: NVLink's Technical Mastery
Understanding why scale-up architectures command premium pricing requires examining the technology that makes them possible in the first place. NVIDIA's NVLink interconnect and its switched fabric implementation create something genuinely unprecedented—a cohesive, high-bandwidth, low-latency domain that makes a rack of GPUs function as a single accelerator in ways that traditional networking could never achieve.
The Evolution of GPU-to-GPU Communication
NVIDIA created NVLink to solve a bottleneck that was throttling AI progress at its core. As models grew exponentially larger, GPUs needed to exchange massive amounts of data—model parameters, activations, gradients—at speeds that simply didn't exist. PCIe, the traditional system bus everyone relied on, couldn't keep up with the demands of tightly-coupled parallel processing where microseconds of latency or megabytes of bandwidth could determine success or failure.
NVLink provides direct, point-to-point connections between GPUs, creating dedicated data highways that bypass slower system buses entirely, fundamentally changing how GPUs communicate. Each generation delivered transformational improvements in bandwidth that enabled new classes of models:
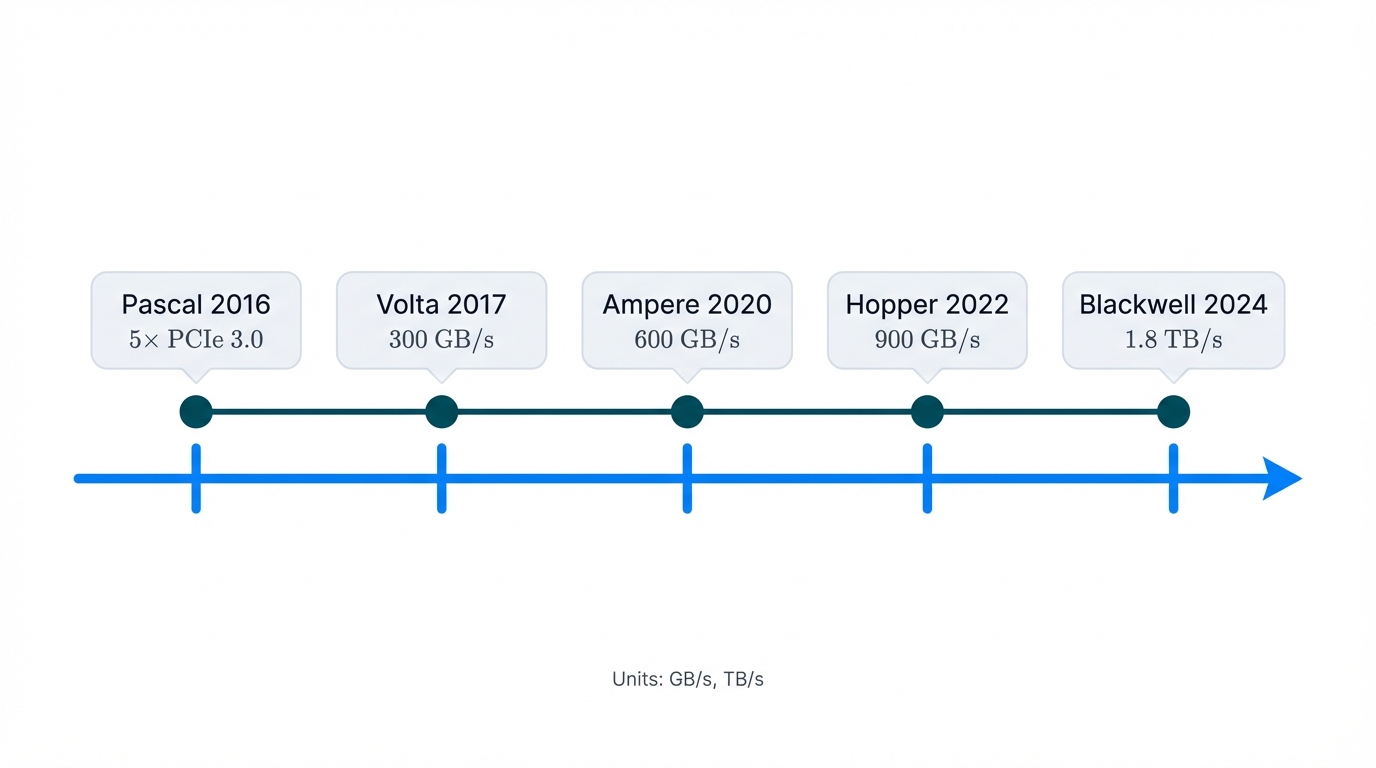
- Pascal (P100, 2016): First-generation NVLink offered bidirectional bandwidth five times faster than PCIe 3.0, establishing a new baseline for inter-GPU communication that made multi-GPU training practical for the first time.
- Volta (V100, 2017): NVLink 2.0 increased total bidirectional bandwidth to 300 GB/s per GPU, but the real breakthrough was introducing the game-changing NVSwitch in the DGX-2 system that enabled all-to-all GPU communication.
- Ampere (A100, 2020): Third-generation NVLink doubled bandwidth again to 600 GB/s per GPU, further cementing its advantage for large-scale training workloads and enabling the first models to cross 100 billion parameters.
- Hopper (H100, 2022): NVLink 4.0 delivered another 1.5x increase, providing 900 GB/s of bidirectional bandwidth per GPU and powering the current generation of frontier models.
- Blackwell (B200/GB200, 2024): Fifth-generation NVLink doubles bandwidth once more to a staggering 1.8 TB/s per GPU, representing over 14 times the bandwidth of contemporary PCIe Gen5 and enabling trillion-parameter models that were economically impossible before.
Beyond raw bandwidth numbers, NVLink's architectural sophistication truly sets it apart from anything that came before. Unlike traditional networking based on message passing where every communication involves software overhead, NVLink supports memory-semantic operations with cache coherence, fundamentally changing the programming model. GPUs within an NVLink domain access each other's memory directly and coherently, creating unified memory spaces that are absolutely essential for model parallelism on extremely large models where individual layers exceed single GPU memory capacity.
This isn't just faster networking. It's a fundamentally different computing paradigm where the distinction between local and remote memory becomes increasingly irrelevant within the scale-up domain.
The NVL72: Rack-Scale Computing Reaches Maturity
The NVIDIA GB200 NVL72 system embodies rack-scale computing philosophy taken to its logical extreme, representing the culmination of decades of research into how to pack maximum computational density into minimum physical space. This isn't just a powerful server that happens to be really fast—it's a completely integrated, liquid-cooled data center rack that functions as a single computational unit with characteristics that fundamentally differ from anything that came before.
System Architecture Deep Dive
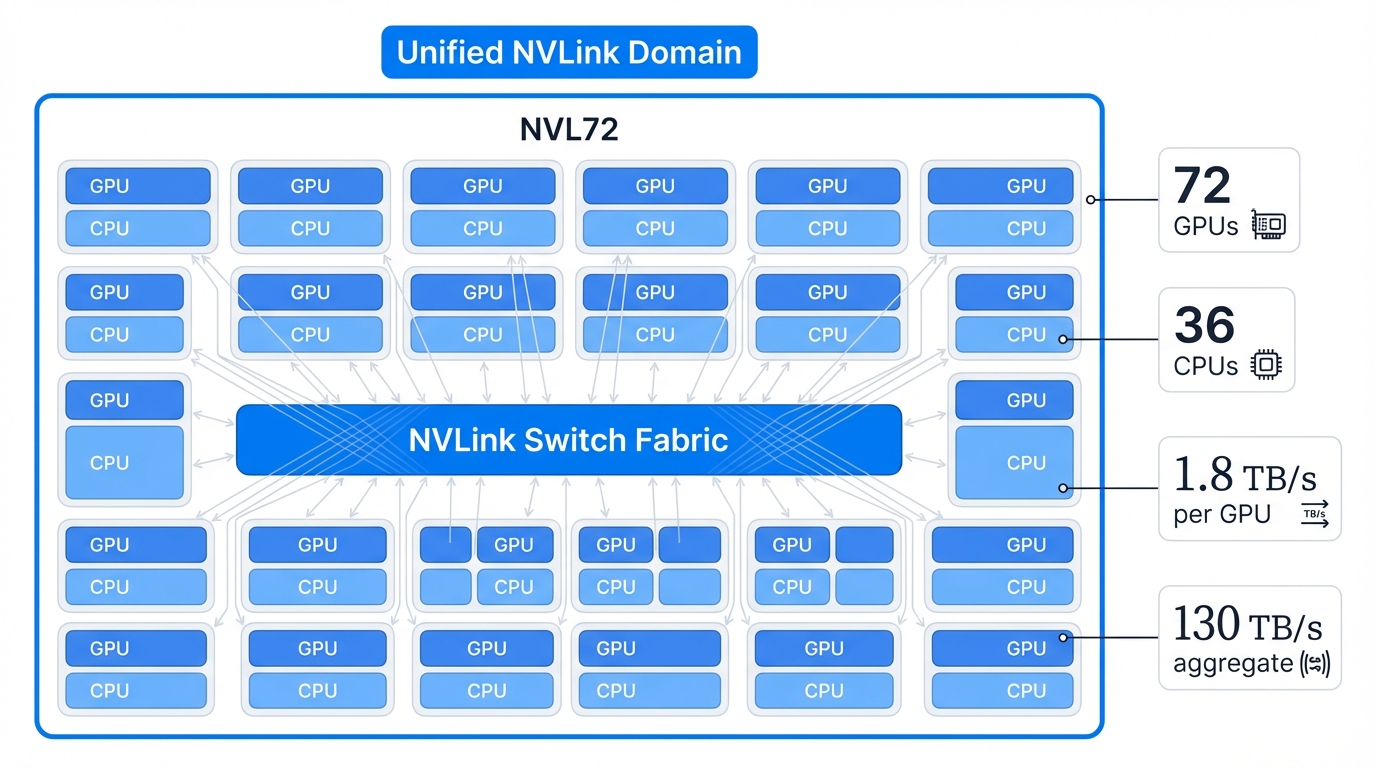
A single NVL72 houses 72 Blackwell Tensor Core GPUs and 36 NVIDIA Grace CPUs, all paired into 36 GB200 Grace Blackwell Superchips that combine cutting-edge GPU and CPU technology in single packages. This dense configuration maximizes compute power within a standard data center footprint while requiring fundamental changes to your facility infrastructure that extend far beyond the rack itself.
The Unified NVLink Domain
The defining feature is the single, cohesive NVLink domain connecting all 72 GPUs in a unified fabric that operates like shared memory rather than a network. Nine switch trays and a dense copper cable cartridge create a non-blocking, all-to-all fabric where any GPU can communicate with any other GPU at full 1.8 TB/s bandwidth simultaneously without contention. The total aggregate bidirectional GPU bandwidth within this domain reaches 130 TB/s—effectively creating a single, data-center-sized GPU with a massive, unified pool of fast memory that behaves like a single computer despite containing 72 separate processors.
The Thermal Reality Check
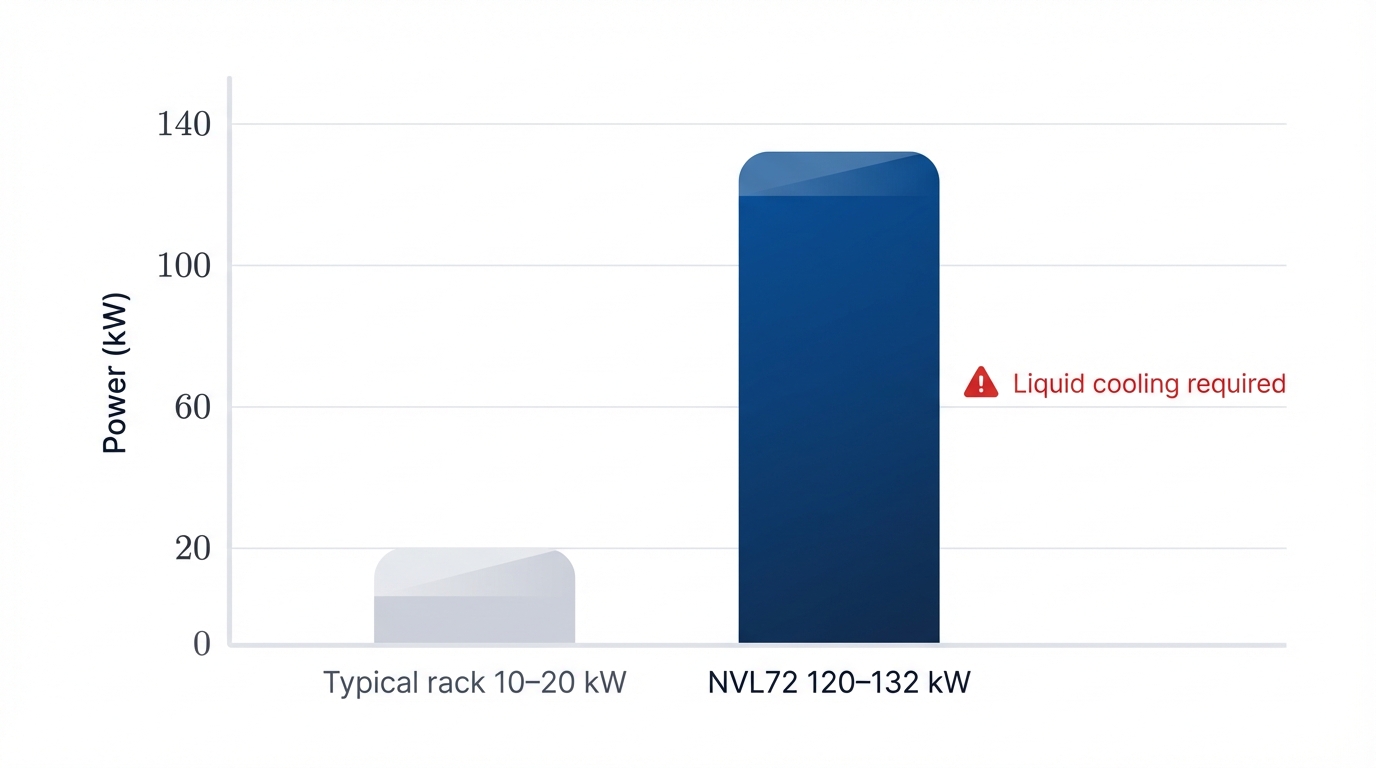
Such extreme density demands extreme solutions that most data centers simply aren't equipped to handle. The NVL72's thermal design point ranges from 120 kW to 132 kW per rack—an order of magnitude higher than typical data center equipment designed for 10-20 kW loads. Traditional air cooling becomes physically impossible at these power densities where you're basically trying to cool a small data center within a single rack. The system requires direct-to-chip liquid cooling infrastructure, representing a significant facility-level commitment that extends far beyond the hardware purchase to encompass entire cooling plants, specialized plumbing, monitoring systems, and operational expertise.
Performance Projections and Claims
NVIDIA projects dramatic performance gains that border on unbelievable until you understand the architectural advantages, particularly for the largest AI models that push the boundaries of what's possible. The company claims up to 30x performance increases for real-time trillion-parameter LLM inference compared to previous generation systems, and 4x increases in training speed compared to H100-based systems that currently power most frontier model training. The integrated liquid-cooled design allegedly delivers these gains with 25x greater energy efficiency, turning what would be an environmental disaster into something almost reasonable.
These aren't just impressive numbers on marketing slides. They represent the performance levels genuinely needed to make trillion-parameter model training economically viable rather than just technically possible.
Performance Characteristics: Where Theory Meets Reality
Understanding NVLink's true capabilities requires examining both bandwidth and latency characteristics under real-world conditions where software overhead and system complexity inevitably degrade theoretical maximums.
Bandwidth Excellence: The 1.8 TB/s of bidirectional bandwidth per GPU serves as the system's flagship specification that marketing loves to tout. This immense throughput proves essential for model parallelism strategies like Tensor Parallelism, where large tensors are sharded across GPUs and require constant, high-volume data exchange during both forward and backward passes—without this bandwidth, you simply can't run these models efficiently.
The Latency Story: Raw hardware latency for direct GPU-to-GPU communication ranges from 100 to 300 nanoseconds when you measure at the physical layer—this represents the best-case scenario that looks amazing on datasheets. However, real-world application-level latencies, which include unavoidable software stack overhead from operating systems, drivers, and communication libraries like NCCL that sit between your application and the hardware, typically range from 2 to 3 microseconds in production deployments.
Even with software overhead eating into theoretical performance, NVLink's application-level latency remains exceptionally competitive against any alternative. It matches or exceeds the hardware-level latency of the fastest inter-rack RDMA fabrics like InfiniBand, which typically deliver 1 to 5 microseconds at the application level once you account for the full stack. For latency-sensitive operations that can't tolerate delays, communication within an NVL72 domain operates an order of magnitude faster than communication between racks, and this difference compounds across millions of operations to create massive performance gaps.
This latency advantage becomes critical for security-sensitive applications where faster internal communication reduces the time window during which data remains vulnerable to interception or manipulation during transfers, shrinking the attack surface simply through speed.
The Data Center Transformation Imperative
Deploying NVL72-based systems extends far beyond simple hardware procurement where you order equipment and plug it in. It represents a fundamental strategic commitment to re-architecting your entire data center facility in ways that cascade through power delivery, cooling infrastructure, structural support, and operational processes.
A standard data center rack typically supports 10-20 kW of power load, managed through traditional air cooling with hot and cold aisles that evolved over decades of IT infrastructure. The NVL72's power draw exceeding 120 kW makes this traditional model completely obsolete—you physically cannot dissipate that much heat with air, no matter how many fans you install or how cleverly you design your airflow. The resulting thermal density cannot be managed by air cooling, mandating implementation of direct-to-chip liquid cooling systems that fundamentally change how your data center operates.
This isn't a simple upgrade where you swap components and move on. You need facility-level investment in coolant distribution units (CDUs), specialized plumbing infrastructure that meets stringent purity and pressure requirements, heat exchangers designed for high-density loads, and potentially cooling towers or chillers to reject heat to the environment. The complexity rivals that of high-performance computing facilities or manufacturing clean rooms, requiring expertise and operational procedures that most IT organizations simply don't possess.
Your organization cannot simply "add" NVL72 racks to existing air-cooled data halls without massive disruption and reconstruction. You must either build new, purpose-built facilities designed from the ground up for liquid cooling, or undertake costly, disruptive retrofits that may require taking entire data halls offline during construction. This reality dramatically reshapes Total Cost of Ownership calculations where the cost includes not just hardware pricing but substantial capital expenditure for supporting facility infrastructure that can easily match or exceed the hardware costs themselves.
From a security perspective, this infrastructure concentration creates new vulnerabilities that require fresh thinking. Liquid cooling systems introduce additional attack vectors that traditional air-cooled systems never had to consider—from contaminated coolant that could cause catastrophic hardware failures, to sabotage of cooling infrastructure that would destroy equipment within minutes. Physical security requirements escalate dramatically when a single rack contains tens of millions of dollars in AI training hardware that represents your organization's competitive future.
The NVL72 adoption transforms what should be a tactical IT decision into a long-term strategic bet on high-density, liquid-cooled computing infrastructure that will define your data center architecture for the next decade.
The Architecture of Inter-Rack Scale-Out: High-Performance Fabrics in the AI Era
While scale-up technologies push single-system performance to physical limits, the dominant paradigm for building truly massive AI supercomputers remains inter-rack scale-out where you achieve scale through networking rather than density. This approach relies on specialized, high-performance network fabrics to connect hundreds or thousands of individual compute nodes into cohesive clusters that can tackle problems no single system could handle.
The fabric's performance—bandwidth, latency, and congestion handling—becomes the single most critical factor determining overall cluster efficiency, and getting this wrong turns expensive GPU clusters into underutilized money pits. Two primary technologies compete in this space: InfiniBand, the long-standing HPC incumbent with decades of optimization, and high-speed Ethernet, the ubiquitous data center standard that has rapidly evolved to meet AI demands through sheer necessity.
InfiniBand: The High-Performance Computing Champion
InfiniBand was designed from inception as a high-performance interconnect for HPC and supercomputing environments where every nanosecond counts. Unlike Ethernet, which was created for general-purpose networking and evolved to support higher performance, InfiniBand's architecture prioritizes the highest possible bandwidth and lowest possible latency as fundamental design principles that shaped every technical decision.
Core Architecture Advantages: InfiniBand operates as a lossless, switched fabric topology where packet loss simply doesn't happen under normal operation. Its key architectural advantage is native support for Remote Direct Memory Access (RDMA), which isn't bolted on as an afterthought but built into the fabric from the beginning. RDMA allows network adapters in one server to directly read from or write to another server's memory, bypassing CPUs and operating system kernels on both sides to eliminate software overhead that typically dominates communication costs.
Performance Leadership: InfiniBand remains renowned for ultra-low latency that Ethernet still struggles to match consistently. The latest NVIDIA Quantum-2 NDR (Next Data Rate) platform achieves end-to-end latencies as low as 90 nanoseconds at the hardware level when everything is perfectly tuned, with typical application-level latencies in the 1-2 microsecond range that represent best-in-class performance for scale-out networking.
AI-Specific Optimizations: A significant InfiniBand advantage in AI clusters is support for advanced in-network computing features like NVIDIA's Scalable Hierarchical Aggregation and Reduction Protocol (SHARP), which isn't available on standard Ethernet. SHARP offloads parts of collective communication operations—such as the reductions in All-Reduce operations that dominate AI training—from GPUs to network switches themselves, reducing GPU idle time and improving overall efficiency in ways that can significantly impact training performance.
From a security perspective, InfiniBand's specialized nature creates both advantages and vulnerabilities that organizations must weigh carefully. The smaller ecosystem means fewer potential attack vectors compared to ubiquitous Ethernet, but also less security research, fewer security-focused tools, and smaller communities to draw expertise from compared to mainstream Ethernet environments where security tooling is mature and widely deployed.
Ethernet's Remarkable Ascent: RoCEv2 and the Ultra Ethernet Revolution
Ethernet, the dominant technology in enterprise and cloud data centers for decades, was traditionally considered unsuitable for demanding HPC and AI workloads due to its inherently lossy nature and higher latency compared to specialized fabrics. Recent advancements transformed it into a formidable InfiniBand competitor that's forcing serious reconsideration of long-held assumptions about what Ethernet can achieve.
Technological Breakthrough: The key innovation enabling high-performance Ethernet was RDMA over Converged Ethernet (RoCEv2), which wasn't obvious or easy to achieve. RoCEv2 encapsulates InfiniBand transport packets over Ethernet networks, allowing applications to leverage RDMA benefits on standard Ethernet hardware without requiring specialized fabrics—essentially bringing InfiniBand's killer feature to commodity networking.
Performance Trajectory: Ethernet's raw bandwidth kept pace with or even surpassed InfiniBand through aggressive development driven by cloud providers. High-density 800GbE switches are now available from multiple vendors, offering aggregate switching capacity of 51.2 Tb/s (102.4 Tb/s bidirectional) in single chassis—numbers that match or exceed InfiniBand while running on open standards.
The Ultra Ethernet Consortium Revolution: Recognizing the need for standardized, optimized Ethernet for AI that goes beyond what RoCEv2 could deliver, an industry consortium of heavyweight companies—including AMD, Broadcom, Cisco, Google, HPE, Intel, Meta, and Microsoft—formed the Ultra Ethernet Consortium (UEC) to finally solve Ethernet's AI challenges. Notably absent from this impressive list: NVIDIA, the primary InfiniBand vendor, whose exclusion speaks volumes about the competitive dynamics at play.
The UEC's goal is creating open, interoperable, Ethernet-based networking solutions delivering InfiniBand-comparable performance without vendor lock-in. The UEC 1.0 specification introduces a new transport layer designed specifically for AI traffic patterns, featuring advanced congestion control mechanisms that go beyond standard TCP, multi-rail architecture for redundancy and performance, and optimizations providing deterministic, low-latency performance that AI workloads absolutely require.
Security Implications: Ethernet's ubiquity creates both security advantages and challenges that require careful navigation. The massive ecosystem means extensive security tooling, monitoring capabilities, and expertise are readily available from countless vendors and open-source projects. However, this also means attackers have deeper knowledge of Ethernet vulnerabilities accumulated over decades and more readily available attack tools that can be deployed with minimal expertise.
The Congestion Challenge: Managing AI's Network Brutality
The most significant challenge in large-scale scale-out fabrics is managing network congestion and its effect on tail latency, which sounds technical but translates directly to wasted money and time. AI workloads are particularly brutal on networks in ways that traditional enterprise applications never were. The synchronous nature of distributed training means all GPUs often attempt to communicate simultaneously, creating massive, correlated traffic bursts—an "in-cast" scenario that traditional networks designed for asynchronous traffic simply cannot handle without sophisticated congestion control.
This traffic proves "low-entropy" in networking parlance, meaning many flows target the same few destinations, making traditional load-balancing mechanisms that assume distributed traffic patterns completely ineffective. The result is a phenomenon known as tail latency, where a small percentage of operations take dramatically longer than average, and this small percentage destroys overall performance.
The Straggler Problem
In collective operations involving thousands of GPUs working in lockstep, the entire operation can only proceed as fast as the single slowest participant—there's no way around this mathematical reality. If one GPU's packets are delayed due to congestion somewhere in the network fabric, all other GPUs must wait idle, twiddling their electronic thumbs while burning electricity and money. This "straggler" effect means 99th percentile latency, not average latency, often dictates overall Job Completion Time (JCT) in ways that make average performance numbers almost meaningless for AI workloads.
Studies show that in large AI clusters, network communication can account for 30-50% of total JCT, making tail latency a critical performance metric that directly impacts training costs and time-to-market for AI models in ways that cascade through business outcomes.
InfiniBand's Congestion Advantage
InfiniBand's design provides inherent advantages in managing congestion that are baked into its architecture. Its credit-based flow control mechanism is a native, link-level system that prevents packet loss by ensuring receivers have buffer space before senders transmit data—it's elegant and effective. This makes the fabric lossless by design rather than through complex protocols, and provides more predictable, deterministic performance under the heavy, synchronized loads typical of AI training where thousands of GPUs all decide to communicate at exactly the same instant.
Ethernet's Engineering Challenge
Ethernet must engineer losslessness using higher-level protocols because loss prevention wasn't part of its original design philosophy. While mechanisms like Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) prove effective when properly configured, they can be complex to configure and tune at scale in ways that require deep expertise and constant attention. The UEC's new transport layer directly attempts to address this fundamental architectural difference by creating more robust and AI-aware congestion control schemes for Ethernet that approach InfiniBand's deterministic behavior.
For security-conscious organizations, InfiniBand's deterministic behavior provides advantages in detecting anomalous network patterns that might indicate attacks or data exfiltration attempts, since deviations from expected behavior are easier to spot when baseline behavior is predictable.
The Strategic Battle: Vertical Integration vs. Open Ecosystems
The technical competition between InfiniBand and Ethernet serves as a proxy for a larger strategic battle shaping the AI industry's future in ways that extend far beyond networking protocols. NVIDIA's 2019 acquisition of Mellanox, the primary InfiniBand developer, was pivotal in ways that reshaped competitive dynamics across the industry. It allowed NVIDIA to create a deeply integrated, full-stack AI solution—from GPU silicon (Blackwell) and inside-rack interconnect (NVLink) to inter-rack fabric (Quantum InfiniBand)—all optimized by unified software layers (CUDA, NCCL) that work together seamlessly in ways that mixed-vendor solutions struggle to match.
This vertical integration offers highly performant, turnkey solutions where every component is designed to work seamlessly together, delivering performance that's genuinely difficult to achieve through component integration. However, it also creates a powerful proprietary ecosystem with significant potential for vendor lock-in and reduced negotiating leverage as organizations become dependent on a single supplier for critical infrastructure.
The Ultra Ethernet Consortium's formation by NVIDIA's largest customers (hyperscalers like Meta and Microsoft who buy GPUs by the tens of thousands) and direct competitors (AMD, Intel) represents a strategic push toward open, multi-vendor ecosystems that deliberately undermines NVIDIA's integrated advantage. These companies are motivated to foster competitive markets for high-performance networking to avoid single-supplier dependency and drive down costs through open standards and interoperability that makes vendors compete on merit rather than lock-in.
Your organization's choice of inter-rack fabric isn't merely a technical decision based on latency and bandwidth specifications that look good in comparison tables. It's strategic alignment with long-term implications for procurement flexibility, supply chain resilience, negotiating power in vendor relationships, and the ability to avoid being held hostage by a single supplier who controls your AI infrastructure destiny.
From a security perspective, this choice also determines your threat landscape in fundamental ways. Proprietary ecosystems limit your security vendor options but may offer more consistent security implementations that are easier to validate and maintain. Open ecosystems provide broader security tooling options and benefit from wider community scrutiny, but require more careful integration and validation efforts to ensure components work together securely.
Comparative Analysis: The Numbers That Matter
Here's how the three primary interconnect technologies stack up across critical performance dimensions that actually determine real-world training efficiency:
| Feature | NVLink 5.0 (NVL72) | Quantum-2 NDR InfiniBand | 800GbE (UEC-Class) |
|---|---|---|---|
| Scope | Inside-Rack (Scale-Up) | Inter-Rack (Scale-Out) | Inter-Rack (Scale-Out) |
| Per-Port/GPU Bandwidth | 1.8 TB/s | 400 Gb/s (50 GB/s) | 800 Gb/s (100 GB/s) |
| Aggregate Switch Bandwidth | 130 TB/s (72-GPU Domain) | 51.2 Tb/s | 102.4 Tb/s (51.2T switch) |
| Port-to-Port Latency | ~100-300 ns | ~90-600 ns | ~500-750 ns |
| RDMA Support | Native (Memory Semantics) | Native | RoCEv2 |
| Lossless Mechanism | N/A (Internal Fabric) | Credit-Based Flow Control | PFC/ECN; UEC-CC (future) |
| Power per Switch | N/A (Integrated in 120kW+ rack) | ~1.7 kW | ~2.2 kW |
| Ecosystem | Proprietary (NVIDIA) | Largely NVIDIA-led | Open Multi-Vendor (UEC) |
These specifications tell only part of the story that matters for your infrastructure decisions. Real-world performance depends heavily on workload characteristics that vary enormously across different AI models, software optimization that can make or break efficiency, and network configuration expertise that separates successful deployments from expensive disasters.
Parallelism Paradigms and the Communication-to-Computation Ratio: The Science of Scaling
The effectiveness of any interconnect technology isn't absolute—it depends entirely on your specific workload demands in ways that make generic performance comparisons almost meaningless. In distributed AI training, these demands are dictated by the parallelism strategy you use to distribute models and data across multiple GPUs, and getting this strategy wrong renders even the fastest networks inadequate.
Each strategy—Data Parallelism, Tensor Parallelism, Pipeline Parallelism, and Expert Parallelism—imposes unique communication patterns with varying requirements for bandwidth, latency, and collective operation efficiency that map differently onto available hardware. The Communication-to-Computation (C2C) ratio provides a powerful analytical framework for quantifying these demands and predicting network bottlenecks before you waste millions discovering them in production.
Deconstructing AI Parallelism Strategies
When models become too large to train on single GPUs or when training time needs dramatic reduction to meet business deadlines, various parallelism techniques distribute the computational work across multiple processors in fundamentally different ways.
Data Parallelism (DP): The Straightforward Approach
This is the most common and conceptually simplest parallelism form that most organizations start with. The model is replicated completely on each GPU—every GPU has the full model weights—and the global training batch is split into smaller "micro-batches," with each GPU processing one micro-batch concurrently and independently.
After each GPU computes gradients for its micro-batch during the backward pass, a communication step is required to average these gradients across all GPUs, ensuring model replicas remain synchronized and learn from the entire batch. This synchronization typically uses an All-Reduce collective operation that's well-studied and optimized.
The communication volume for this step is directly proportional to the model's parameter count and generally occurs once per training step, making it predictable and manageable. For most models up to 100 billion parameters, this communication pattern remains manageable even with moderate-performance networks, which is why many enterprise deployments succeed with cost-effective Ethernet fabrics.
Tensor Parallelism (TP): The Latency-Sensitive Approach
A sophisticated form of model parallelism, TP involves partitioning individual layers or specific tensors like weight matrices across multiple GPUs, fundamentally changing where computation happens. For example, a large matrix multiplication can be split into chunks, with each GPU computing a portion of the result that must then be assembled into the final output.
This requires frequent communication within the forward and backward passes of single layers to exchange partial results that other GPUs need to continue computation. These exchanges often involve All-Reduce or All-Gather collectives that run multiple times per layer. Because this communication happens multiple times within each network layer rather than just once per training step, TP is extremely sensitive to both communication bandwidth and, critically, latency in ways that Data Parallelism never experiences.
When you're running tensor parallelism across 8 or more GPUs, even microsecond latency differences compound into significant performance impacts that multiply across hundreds of layers. This is where NVLink's sub-microsecond latencies become essential rather than merely impressive numbers on a datasheet—they're the difference between models that train efficiently and models that spend most of their time waiting for data.
Pipeline Parallelism (PP): The Sequential Approach
Another form of model parallelism that takes a different angle, PP partitions models vertically, assigning contiguous blocks of layers to different GPUs arranged in a "pipeline" where data flows through stages. Data flows through the pipeline sequentially, with each GPU executing its assigned layers and passing resulting activations to the next GPU in the sequence, creating dependencies that constrain scheduling.
This primarily involves point-to-point Send/Recv operations between adjacent GPUs in the pipeline rather than global collectives. While PP reduces collective communication volume compared to DP or TP, it suffers from "pipeline bubbles"—periods where GPUs at the beginning or end of the pipeline remain idle while waiting for data to flow through earlier or later stages, wasting compute resources that you're paying for regardless of utilization.
Expert Parallelism (EP): The All-to-All Challenge
This specialized form of model parallelism is used for Mixture-of-Experts (MoE) architectures that are becoming increasingly popular for scaling models efficiently. In MoE models, the feed-forward network of transformer blocks is replaced by sets of smaller "expert" networks, with a gating mechanism determining which experts process each token. For each input token, a gating network selects a small subset of experts—typically 2 out of 128—to process it, creating sparse activation patterns.
To parallelize this effectively, experts are distributed across available GPUs, with each GPU hosting a subset of the total expert pool. This necessitates massive All-to-All communication steps where each GPU sends its tokens to specific GPUs housing the selected experts, then receives back the processed results. This All-to-All pattern is one of the most demanding communication collectives, stressing the bisection bandwidth of network fabrics in ways that expose architectural weaknesses.
When you're running large MoE models like GPT-4 (rumored to be MoE-based), the All-to-All communication can dominate training time, making bisection bandwidth your primary performance constraint that determines whether training is economically viable.
The C2C Ratio: Quantifying Network Bottlenecks
To move beyond qualitative descriptions of communication patterns that sound technical but don't help with decisions, you need a quantitative metric to assess when networks become bottlenecks that justify infrastructure investment. The Communication-to-Computation (C2C) ratio defines the ratio of total time spent on communication to total time spent on useful computation within a training iteration, providing a single number that captures the essential bottleneck.
Understanding C2C Thresholds:
- Low C2C ratio (<0.2): The workload is compute-bound, meaning GPUs spend most time performing calculations rather than waiting for data. The network has ample time to complete data transfers without GPUs going idle. Network performance isn't the primary bottleneck, so investing in extreme interconnects wastes money that could go toward more GPUs.
- High C2C ratio (>0.6): The workload is communication-bound, meaning GPUs spend significant time waiting for data transfers to complete before they can continue computation. This leads to low GPU utilization and extended Job Completion Time (JCT) where expensive hardware sits idle. The network becomes the critical performance limiter that must be addressed regardless of cost.
The Mathematical Foundation
You can use analytical modeling to estimate iteration time and its components for given model and hardware configurations, moving from intuition to engineering. Based on detailed performance modeling developed by researchers studying large-scale training, iteration time breaks down as:
T_iter = T_comp + T_comm + T_bubble
Where T_comm is the sum of communication times for each parallelism type you're employing:
T_comm = T_TP + T_PP + T_DP
Each component can be estimated based on model parameters, parallelism strategy, and effective hardware bandwidth that accounts for real-world inefficiencies:
# Computation Time (T_comp)
T_comp ≈ (p × t × μF) / (8m × N × b × s)
# Tensor Parallelism Communication Time (T_TP)
T_TP ≈ m × (l/p) × (6 × 2bsh × (2(t-1)/t)) / C_TP
# Data Parallelism Communication Time (T_DP)
T_DP ≈ (2N/(p×t)) × (2(d-1)/d) × (1/C_DP)
This analytical framework provides quantitative methods to predict how changes in model architecture or scaling strategy will impact the C2C ratio before you commit resources. It allows you to model performance of given workloads on different network fabrics and identify break-even points where more powerful interconnects become necessary rather than optional, transforming architecture decisions from guesswork into engineering.
NCCL: The Software Layer That Makes Hardware Sing
The performance of communication patterns in the real world isn't just a function of raw hardware specifications that look good on datasheets—it's heavily influenced by the software orchestrating data movement in ways that can make or break efficiency. The NVIDIA Collective Communications Library (NCCL) is the critical software layer providing highly optimized implementations of collective operations for NVIDIA GPUs, and understanding it is essential to understanding why some clusters perform well and others disappoint.
Core Functionality: NCCL offers simple APIs for operations like All-Reduce, All-Gather, and Reduce-Scatter, abstracting underlying complexity from application developers who shouldn't need to be networking experts. Deep learning frameworks like PyTorch and TensorFlow integrate deeply with NCCL to handle all multi-GPU communication transparently, letting data scientists focus on models rather than plumbing.
Topology Awareness: A key NCCL feature is automatic detection of system interconnect topology, understanding the physical reality of how GPUs actually connect. It understands which GPUs connect via ultra-fast NVLink, which share the same PCIe root complex, and which must communicate over inter-node networks like InfiniBand or Ethernet. Based on this topology understanding, NCCL selects the most efficient communication algorithms—ring-based algorithms to maximize bandwidth for large messages, or tree-based algorithms to minimize latency for small messages where overhead dominates.
This intelligence translates hardware's theoretical capabilities into high "effective bandwidth" in the C2C model rather than leaving performance on the table. Without sophisticated software orchestration that understands topology and workload characteristics, even the fastest hardware delivers disappointing real-world performance that wastes capital investment.
For security-conscious deployments, NCCL's topology awareness can be leveraged to implement communication policies that restrict cross-boundary data flows or ensure sensitive computations remain within trusted hardware domains, adding security without sacrificing performance.
Communication Complexity: Not All Traffic Is Created Equal
Sophisticated analysis requires moving beyond single, aggregate C2C ratios to recognize that different communication types impose different network stresses that map differently onto hardware capabilities. "Communication overhead" encompasses a spectrum of traffic patterns with varying sensitivities to bandwidth and latency that demand nuanced understanding.
Latency-Sensitive Communication: Tensor Parallelism generates frequent, often small-to-medium sized messages occurring directly within the critical path of layer computation where every microsecond counts. The latency of each All-Reduce or All-Gather operation directly adds to overall execution time in ways that compound across layers. High-latency networks force GPUs to stall frequently, crippling performance regardless of available bandwidth.
Bandwidth-Sensitive Communication: Data Parallelism's All-Reduce operation typically involves single, very large data transfers equivalent to model parameter sizes that can reach gigabytes. While low latency is always beneficial, the total time for this operation is primarily dominated by the sheer volume of data that must be moved across the network—you need bandwidth more than you need low latency.
Bisection Bandwidth-Sensitive Communication: The All-to-All collective required by Expert Parallelism in MoE models is uniquely stressful in ways that expose network architecture weaknesses. It requires every GPU in the group to send data to every other GPU simultaneously, creating a traffic pattern that looks like a distributed denial of service attack. This traffic pattern maximally stresses the bisection bandwidth—a measure of total bandwidth available between two halves of the network—and reveals whether your fabric is truly non-blocking or just marketing hype.
This nuanced understanding is critical for defining break-even points that actually reflect your workloads rather than theoretical benchmarks. You must design architectures not just for total communication volume, but for specific communication types your target workloads will generate based on their parallelism strategies. Models with high TP-induced C2C ratios have vastly different network requirements than models with equally high but DP-induced C2C ratios, even though both might show the same aggregate C2C number.
The Break-Even Point Analysis: Where Mathematics Meets Strategy
The culmination of this analysis is synthesizing hardware capabilities and workload characteristics to define a clear decision-making framework that cuts through vendor marketing. The "break-even point" is the threshold at which the significant TCO premium of large-scale, inside-rack scale-up systems like the NVL72 is justified by commensurate or greater reductions in Job Completion Time (JCT) that translate to business value.
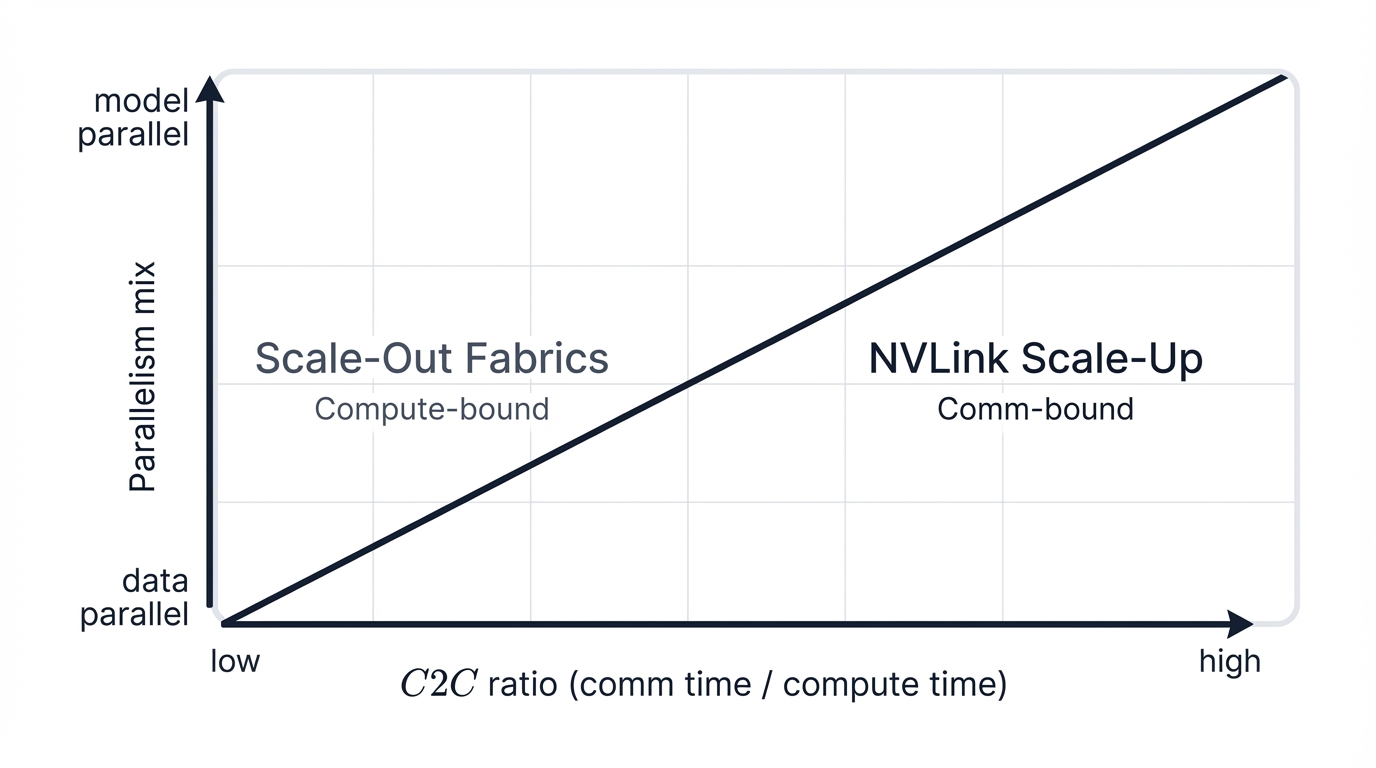
This inflection point is reached when workloads become so communication-bound that their performance on traditional scale-out fabrics collapses catastrophically, making more powerful interconnects not just performance enhancements that look nice but absolute necessities for training to be economically viable.
When NVLink Becomes Essential: Model Parallelism-Dominant Scenarios
The investment in massive, non-blocking NVLink domains is most clearly justified for workloads dominated by model parallelism, specifically Tensor Parallelism (TP) and Expert Parallelism (EP) where communication becomes the bottleneck that determines everything.
Scenario Profile: This category includes training and increasingly real-time inference of frontier-scale models—typically those with hundreds of billions or trillions of parameters that push the boundaries of what's possible. For these models, even single layers' weights and activations are too large to fit into individual GPU memory, making high degrees of TP and/or Pipeline Parallelism (PP) physical necessities rather than optional optimizations you can choose based on preference.
Bottleneck Analysis in Action: In these scenarios, the C2C ratio becomes extremely high—often exceeding 0.6 or even 0.8—and communication becomes acutely latency-sensitive in ways that make traditional fabrics completely inadequate. The analytical model demonstrates that TP communication time (T_TP) scales with layer counts and activation sizes, occurring multiple times within every training step's critical path where GPUs can't proceed until communication completes.
Consider this real-world example that illustrates the economics. Training a trillion-parameter dense model requires tensor parallelism across at least 8 GPUs just to fit the model in memory—there's no alternative. With traditional inter-rack fabrics delivering 5-10 microsecond latencies that seem small but compound brutally, each of the hundreds of TP communication steps per layer adds significant overhead that multiplies across the model. Multiply this across hundreds of layers and thousands of training steps, and the accumulated latency makes training economically infeasible, turning a project that should take weeks into one that takes months or years.
Empirical Evidence: NVIDIA's performance claims and benchmark results underscore this point with data rather than marketing fluff. The MLPerf Training v5.0 submission showcased a 2,496-GPU cluster composed of GB200 NVL72 systems achieving 90% strong-scaling efficiency on large model workloads—this means adding GPUs almost linearly improved performance rather than hitting diminishing returns. This near-linear scaling at such massive scale is exceptionally difficult to achieve and was attributed directly to the synergistic effect of high-bandwidth NVLink fabric, optimized NCCL libraries that understand the hardware, and scale-out InfiniBand networks connecting racks efficiently.
From a security perspective, this architecture also creates clear security boundaries that can be leveraged defensively. The most sensitive model parameters and intermediate computations remain within the high-speed, tightly controlled NVLink domain where they're easier to protect, while only aggregated gradients and checkpoints traverse the inter-rack network where they're more exposed to potential interception but contain less sensitive information.
When Scale-Out Fabrics Excel: Data Parallelism-Dominant Workloads
For a broad class of AI workloads that represent the majority of real-world deployments, the extreme performance of full rack-scale NVLink domains is unnecessary and wastes money. Well-designed scale-out architectures provide much better balances of performance and cost that make business sense.
Scenario Profile: This category includes training of large but not frontier-scale models—typically those up to roughly 70 billion parameters that can comfortably fit within single 8-GPU nodes when using modern high-memory GPUs. For these workloads, scaling is achieved primarily through Data Parallelism (DP), where multiple nodes work on different dataset shards independently until gradient synchronization.
Most enterprise AI use cases fall squarely into this category. Fine-tuning existing models on proprietary data. Running inference on moderately sized models for production applications. Training custom models for specific business applications. These workloads represent the vast majority of real-world AI deployments outside of the largest tech companies with unlimited budgets, and they simply don't need exotic infrastructure.
Empirical Evidence: The increasing competitiveness of high-speed Ethernet with InfiniBand highlights the viability of scale-out fabrics for these workloads in ways that challenge conventional wisdom. Recent MLPerf benchmarks have shown that well-tuned Ethernet with RoCEv2 can match or even slightly outperform InfiniBand for certain models when configured by experts who understand the nuances, undermining the assumption that InfiniBand is always necessary for AI.
Security Considerations: Scale-out architectures also provide natural security advantages for many enterprise workloads that shouldn't be overlooked. Distributing computation across multiple independent nodes creates natural isolation boundaries that can be leveraged for security policies that would be difficult to implement in monolithic systems. Node-level isolation prevents single points of compromise from exposing entire training datasets or model parameters, containing breaches and limiting blast radius in ways that concentrated architectures cannot.
The Decision Framework: A Multi-Factor Model
The break-even point isn't a single, universal value that applies to everyone—it's an inflection point determined by your specific workload characteristics, budget constraints, and strategic priorities. The C2C ratio provides a robust framework for identifying this point across a spectrum of values corresponding directly to dominant parallelism strategies your models employ.
C2C-Based Decision Framework:
- Low C2C Ratio (<0.2) - Compute-Bound Workloads: Cost-effective Ethernet (RoCEv2) fabric optimal. Models spend most time computing, not communicating. Lower-risk security profile due to distributed architecture.
- Medium C2C Ratio (0.2 - 0.6) - Performance-Sensitive Workloads: High-performance InfiniBand fabric recommended. Communication starts impacting training time noticeably. Medium-risk security requirements with standard protections.
- High C2C Ratio (>0.6) - Communication-Bound Workloads: NVIDIA NVL72 rack-scale systems required. Communication dominates training time. High-risk security implications due to concentrated valuable assets.
By mapping your target model's architecture and required parallelism strategy onto this framework, your organization can make data-driven decisions rather than guessing based on vendor recommendations. For example, training a 175B parameter model requiring tensor parallel size of 8 to fit in memory would firmly place it in the "High C2C" category, mandating an NVLink Switch-based solution where the investment is justified by avoiding month-long delays.
Conversely, scaling out training of a 13B model across 64 nodes using only data parallelism would fall into the "Medium C2C" category, making InfiniBand the more appropriate and cost-effective choice that delivers performance without paying for capabilities you won't use.
The security implications of these choices are equally important and shouldn't be afterthoughts. High C2C workloads often involve the most valuable and sensitive AI models that represent competitive advantages, requiring infrastructure that can provide both extreme performance and robust security simultaneously. The concentrated architecture of NVL72 systems can actually simplify certain security requirements by reducing the number of network hops and potential interception points for critical data, though at the cost of creating higher-value targets that require more sophisticated protection.
Total Cost of Ownership and Strategic Ecosystem Implications: The Full Financial Picture
While performance metrics like Job Completion Time are paramount for technical decisions that engineers care about, your final infrastructure architecture choice must be grounded in comprehensive Total Cost of Ownership (TCO) analysis and long-term strategic implications of chosen technology ecosystems that CFOs and business leaders actually care about.
The financial and operational differences between scale-up NVL72 deployments and scale-out fabric-based clusters are substantial and extend far beyond initial hardware purchase prices that dominate vendor quotes, encompassing facility infrastructure, operational complexity, security requirements, and strategic flexibility that compound over years.
A Comprehensive TCO Model
A credible TCO analysis must account for both capital expenditures (CapEx) and operational expenditures (OpEx) over multi-year horizons that reflect actual ownership periods, while also considering less obvious costs like facility requirements, security infrastructure, and ecosystem lock-in risks that don't appear on initial purchase orders.
Capital Expenditures: The Upfront Investment Reality
NVL72 Scale-Up Architecture:
- Hardware Cost: The initial acquisition cost per rack is extremely high—estimated at $3-4 million per NVL72 system based on industry sources. This includes 72 high-end Blackwell GPUs, 36 Grace CPUs, the integrated NVLink Switch fabric, and the specialized chassis with liquid cooling infrastructure, representing a massive upfront capital commitment.
- Facility Infrastructure Cost: The 120kW+ power density necessitates direct-to-chip liquid cooling infrastructure that most data centers simply don't have. Deploying or retrofitting data centers with required Coolant Distribution Units (CDUs), specialized plumbing that meets purity and pressure requirements, high-density power distribution that can deliver 120kW to single racks, and potentially cooling towers or chillers to reject heat can add $500K-$1M per rack in facility costs that often get overlooked in initial budgets.
- Security Infrastructure: The concentrated value of NVL72 systems requires enhanced physical security with access controls and surveillance, environmental monitoring to detect cooling system issues or tampering, and potentially dedicated security operations capabilities that add significant deployment costs.
InfiniBand/Ethernet Scale-Out Architecture:
- Hardware Cost: Cost per server node (e.g., an 8-GPU HGX server) is significantly lower than a full NVL72 rack—typically $100K-200K depending on GPU generation. This allows more granular, pay-as-you-grow investment models that align better with many organizations' budgeting processes and cash flow constraints.
- Network Cost: This becomes a major CapEx component in scale-out designs that must be carefully planned. For a 512-node cluster requiring high-performance fabric, total network cost for InfiniBand fabric could reach $29.2M based on current NDR pricing, whereas comparable Ethernet fabric might cost $8.7M to $14.8M depending on topology and vendor, representing substantial differences in upfront investment.
- Security Infrastructure: Distributed architectures require more extensive network security infrastructure including firewalls and segmentation, comprehensive monitoring tools that can track traffic across complex topologies, and potentially more security personnel to manage larger attack surfaces with more potential breach points.
Operational Expenditures: The Hidden Ongoing Costs
NVL72 Scale-Up Architecture:
- Power and Cooling: OpEx is dominated by immense power consumption per rack that runs constantly. At 120 kW per rack operating at high utilization typical for AI workloads, annual electricity costs can exceed $100,000 per rack in many regions with typical commercial power rates, and this compounds over years of operation.
- Management: The integrated nature of NVL72 may simplify management at rack level since it's a single, cohesive system rather than dozens of independent servers. However, operating required liquid cooling infrastructure adds operational complexity requiring specialized expertise that most IT teams lack, potentially requiring new hires or expensive consultants.
- Security Operations: Concentrated high-value assets require more intensive security monitoring with specialized tools and potentially dedicated security operations capabilities that understand AI-specific threats, adding ongoing staffing and tooling costs.
InfiniBand/Ethernet Scale-Out Architecture:
- Power and Cooling: Power draw per rack is lower—typically 20-40 kW for air-cooled GPU servers—but large clusters have many more racks and switches, all contributing to total power bills that can equal or exceed scale-up approaches when you account for networking overhead.
- Management: Managing large, distributed network fabrics with thousands of nodes and cables connecting them can be complex and labor-intensive, increasing operational overhead through staffing requirements and management software licensing costs that add up over time.
- Security Operations: Distributed systems require more extensive monitoring to track activity across all nodes and incident response capabilities to quickly contain breaches that could spread across the cluster. However, they benefit from mature security tooling ecosystems with extensive vendor options and open-source tools.
The TCO Break-Even Analysis
The TCO break-even point is highly dependent on your specific use case and utilization patterns in ways that make generic ROI calculations misleading. For organizations that can keep NVL72 clusters fully utilized on communication-bound, frontier model training tasks that justify the hardware, dramatically reduced JCT could lead to lower TCO over time despite high initial CapEx, due to faster time-to-solution that accelerates business value and potentially lower total energy per job when you account for reduced training duration.
Consider this example that illustrates the economics. A research organization training a trillion-parameter model might complete training in 30 days on an NVL72 cluster versus 180 days on a traditional scale-out cluster—a 6x speedup that looks dramatic. Even accounting for the higher infrastructure costs that make CFOs nervous, the 6x reduction in training time could translate to significantly lower total costs when factoring in researcher salaries that burn throughout training, opportunity costs of delayed model deployment, and faster time-to-market for AI applications that can generate revenue months earlier.
Beyond Hardware: Vendor Lock-in and Open Standards Strategy
Your interconnect architecture choice is also a long-term strategic decision about ecosystem alignment with profound implications for your organization's flexibility and negotiating power that extend far beyond the immediate technical requirements.
NVIDIA's Vertically Integrated Ecosystem:
- Advantages: Tight integration and co-optimization of all components can deliver superior out-of-the-box performance that just works. Single-vendor responsibility simplifies support relationships and can accelerate problem resolution when issues arise, since finger-pointing between vendors is eliminated.
- Disadvantages: Deep dependency on a single vendor limits purchasing flexibility and reduces negotiating power in ways that compound over time. Pricing power becomes concentrated in one supplier who can dictate terms. Supply chain risks amplify when a single vendor controls your critical path.
- Security Implications: Vertically integrated systems can provide more consistent security implementations and single-point security management that simplifies compliance. However, they also create single points of failure for security vulnerabilities—if NVIDIA's stack has a critical flaw, your entire infrastructure is exposed simultaneously.
The Push for Open, Horizontal Ecosystems:
- Advantages: Open ecosystems foster competition, leading to lower prices as vendors fight for business, more rapid innovation driven by competitive pressure, and greater choice for customers who can select best-of-breed components. Organizations can mix and match components from different vendors to optimize for their specific needs.
- Disadvantages: Integration complexity increases when combining components from multiple vendors who may not test together. Performance optimization may be less than optimal compared to tightly integrated single-vendor solutions where every component is designed to work together.
- Security Implications: Open ecosystems provide broader security tooling options and can benefit from wider security research community attention that finds and fixes vulnerabilities faster. However, they also require more careful integration and validation efforts to ensure components work together securely without introducing gaps.
This strategic consideration is critical to your decision framework and shouldn't be relegated to technical committees alone. You must weigh performance advantages of proprietary, integrated systems that deliver maximum performance against long-term benefits of flexibility, cost control, and resilience offered by open standards that prevent vendor lock-in and maintain competitive options.
Strategic Recommendations and Future Outlook: Architecting for Tomorrow's AI
Based on comprehensive analysis of hardware capabilities, workload characteristics, and economic factors that shape real-world decisions, you can formulate strategic architectural blueprints tailored to different organizational profiles and missions. Furthermore, looking ahead at the technology roadmap for high-performance interconnects reveals a dynamic landscape where today's architectural boundaries are likely to be redefined by emerging technologies that will reshape what's possible.
Architectural Blueprints for Different Organization Types
The optimal architecture isn't one-size-fits-all—cookie-cutter approaches fail. It depends on your organization's primary mission, workload profile, budget constraints, risk tolerance, and strategic posture regarding technology ecosystems that reflect your competitive positioning.
For National Labs & Foundational Model Builders
Recommendation: Primary investment in NVIDIA NVL72-based pods is strategically sound and likely essential for mission success when building models that push scientific frontiers.
Rationale: The core mission of these organizations is pushing frontiers of scientific research and AI, involving training of the largest and most complex models possible that simply cannot be trained any other way. Their workloads are almost guaranteed to be in the "High C2C" category, dominated by model parallelism and fundamentally limited by communication performance in ways that make traditional fabrics completely inadequate.
Implementation Strategy:
- Deploy NVL72 pods as the core computational resource for frontier model training
- Supplement with scale-out fabric for data preprocessing and checkpointing that don't need extreme performance
- Invest heavily in facility infrastructure and security measures to protect these high-value assets
- Focus on hardware-level security features and comprehensive monitoring to detect threats early
For Hyperscale Cloud Providers
Recommendation: A hybrid, tiered strategy provides the most prudent approach for serving diverse customer bases while maintaining competitive advantages that justify premium pricing.
Rationale: Hyperscalers serve diverse customer bases with wide spectrums of AI needs ranging from simple inference to frontier model training. Hybrid architecture allows them to address entire markets efficiently while optimizing for different price points and performance requirements that different customer segments demand.
Tiered Strategy:
- Deploy significant numbers of NVL72 pods to serve the top tier of the market—customers engaged in foundational model training who are willing to pay premium prices for "supercomputing-as-a-service" that delivers unmatched performance.
- Build majority of AI capacity using large-scale, cost-effective, UEC-compliant Ethernet fabrics serving the bulk of enterprise AI market focused on fine-tuning, inference, and training models in "Low to Medium C2C" ranges where extreme performance is unnecessary.
For Enterprise AI Deployments
Recommendation: Scale-out architecture based on high-performance Ethernet (RoCEv2) or InfiniBand offers the best balance of performance, cost, and operational simplicity for most enterprise use cases that don't involve frontier research.
Rationale: Most enterprises are consumers, not creators, of foundational models—they're applying AI to business problems rather than pushing scientific boundaries. Their primary AI workloads involve fine-tuning models on proprietary data, deploying them for inference in production applications, and training custom models for specific business applications. These tasks typically fall into "Low to Medium C2C" categories that don't justify extreme infrastructure investments.
Enterprise Implementation Guidelines:
- Start with proven Ethernet-based scale-out architecture that can be deployed in existing data centers without facility overhauls
- Focus investment on software optimization, security tooling, and operational capabilities rather than exotic hardware that's hard to manage
- Plan for gradual scaling as AI adoption grows within the organization, avoiding massive upfront investments
- Leverage scale-out architectures for natural isolation boundaries and security policies that map to organizational structure
The Next Frontier: Converging Architectural Boundaries
The current debate between inside-rack scale-up and inter-rack scale-out represents a snapshot of an evolving technological landscape that's far from settled. The next wave of interconnect technologies promises to blur these boundaries in fundamental ways, potentially leading to data centers that function as single, disaggregated systems where the distinction between scale-up and scale-out becomes increasingly meaningless.
Emerging Interconnect Technologies Reshaping the Landscape
Compute Express Link (CXL): CXL is an open standard built on PCIe physical layer enabling cache-coherent interconnects between CPUs, GPUs, and memory devices in ways that weren't possible before. CXL 3.0 introduces switching and fabric capabilities, paving the way for memory disaggregation where large memory pools can be shared by multiple compute nodes, fundamentally changing how we think about memory hierarchies.
Ultra Accelerator Link (UALink): Promoted by a consortium of NVIDIA's competitors who are tired of vendor lock-in, UALink is an open standard designed as direct competitor to NVLink for scale-up accelerator-to-accelerator communication within pods. By providing open, high-bandwidth, low-latency interconnect specifications, UALink aims to enable creation of multi-vendor scale-up systems that break NVIDIA's stranglehold on high-performance AI infrastructure.
Co-Packaged and Optical Interconnects: The fundamental limitation of high-speed electrical interconnects like NVLink is their short reach, typically confined to single racks due to physical constraints of copper signaling. The future of scaling lies in optics that can carry data much farther. Technologies like co-packaged optics (CPO), integrating optical I/O directly onto processor packages, promise to deliver NVLink-level bandwidth over much longer distances measured in meters rather than centimeters.
The Data Center as Computer: Future Vision
The logical endpoint of these trends is complete disaggregation of compute, memory, and networking resources that transforms how we architect data centers. In this future vision, the "scale-up domain" could extend beyond racks to encompass entire data halls, connected by high-bandwidth, low-latency optical fabrics that make physical location increasingly irrelevant.
This would create truly fungible pools of resources that could be dynamically composed to meet needs of any given workload with unprecedented flexibility. Imagine being able to allocate exactly the right amount of compute, memory, and interconnect bandwidth for each training job, optimizing resource utilization to eliminate waste while providing performance characteristics previously available only in monolithic systems that cost millions.
Future Architecture Implications:
- Security Flexibility: Sensitive workloads could be allocated to physically isolated resource pools with enhanced monitoring, while less sensitive tasks utilize shared infrastructure, optimizing both security and efficiency.
- Economic Impact: Disaggregated architectures could significantly improve resource utilization efficiency by eliminating stranded capacity, reducing total infrastructure costs while maintaining performance.
- Dynamic Allocation: Security policies could automatically isolate compromised components while maintaining service availability by reallocating workloads to clean resources in real-time.
The architectural principles explored in this analysis—the critical importance of C2C ratios, the need to manage latency and congestion, and strategic tension between proprietary integration and open standards—won't become obsolete as technology evolves. Instead, they will remain central challenges that must be addressed in designing future data-center-scale computers, even as the specific technologies implementing these principles change.
Technologies will evolve. Hardware will improve. But fundamental trade-offs between performance, cost, security, and flexibility will endure because they're rooted in physics and economics rather than specific implementations. The organizations that understand these trade-offs deeply and make strategic architectural decisions aligned with their mission-critical workloads will be best positioned to leverage AI's transformative potential while competitors struggle with infrastructure that doesn't match their needs.
Conclusion
As we stand at the inflection point of AI infrastructure evolution where trillion-parameter models are becoming routine rather than exceptional, the decisions you make today about scale-up versus scale-out architectures will shape your organization's AI capabilities for years to come in ways that determine competitive positioning. Choose wisely, based on deep understanding of your workloads, clear analysis of trade-offs, and strategic vision for your organization's future in the AI-driven economy that's rewriting every industry.
The future belongs to organizations that can balance the extreme performance requirements of frontier AI models with the economic and security realities of large-scale infrastructure deployment. The architectural frameworks and analytical tools presented in this analysis provide the foundation for making those critical decisions with confidence rather than guesswork, transforming infrastructure choices from technical gambles into strategic advantages.
Key Strategic Takeaways:
- C2C Ratio is Your North Star: Use Communication-to-Computation ratios to determine when extreme interconnect performance justifies massive costs versus when it's just expensive overkill
- Security Through Architecture: Both scale-up and scale-out approaches offer unique security advantages that must be weighed against threat models and risk tolerance
- TCO Beyond Hardware: Factor in facility infrastructure, operational complexity, and ecosystem lock-in risks in your investment decisions, not just purchase prices
- Strategic Ecosystem Alignment: Choose between proprietary integration and open standards based on your organization's long-term flexibility requirements and competitive positioning