Section 1: Introduction: Redefining Scale and Capability in AI
1.1 Beyond the Hype of "Large": Positioning SLMs in the AI Ecosystem
Today's AI story obsesses over scale. Bigger is better. More parameters mean more capability. Generative AI captured headlines through "scaling laws"—observations proving that we could pump more parameters, more data, more computing power into models and consistently watch them grow smarter, more robust, more generalizable. This thinking birthed a generation of Large Language Models like OpenAI's GPT-4, massive neural networks that dazzled us with their breadth of intelligence and their stunning ability to tackle nearly any language task you threw at them.
But scale demands sacrifice. Training these frontier models devours resources on a scale most organizations can't fathom—only the tech giants can afford to play this game, burning through investments in money and energy that would make your head spin. Consider GPT-4's training run: a cluster of 25,000 NVIDIA GPUs running non-stop for 90 to 100 days, representing an astronomical bet on the bigger-is-better philosophy. And here's the kicker—the costs don't stop at training. Running these behemoths, making them actually do useful work, stays expensive, making broad adoption challenging and, for most businesses, financially absurd.
Enter a different breed of model. Small Language Models (SLMs) represent more than just scaled-down versions of their massive cousins—they mark a strategic pivot toward efficiency, specialization, and accessibility that's fundamentally reshaping how we think about AI. These models excel at specific tasks while running on limited computing resources, democratizing AI in a way that opens powerful capabilities to organizations and use cases once locked out of the game. The rise of SLMs signals something profound: the AI field is growing up, maturing from an obsessive chase for ever-larger models to a smarter search for the sweet spot between performance and practicality.
This shift runs deeper than technology—it's economic necessity disguised as innovation. The crushing costs of LLMs exposed a market gap crying out for more affordable, pragmatic solutions. Most businesses don't need general-purpose AI doing backflips; they need focused tools for well-defined, repeatable problems like sorting customer support tickets or yanking data from invoices. Using a massive LLM for these tasks isn't just overkill—it's financial malpractice. SLMs deliver the answer, providing strong outcomes precisely calibrated to the value of the task at hand, helping organizations finally see real returns on their AI investments.
1.2 The Core Trade-Off: Generalist Power vs. Specialist Precision
LLMs and SLMs diverge at a fundamental fork in the road of design philosophy and purpose. LLMs are generalists. Period. You train them on petabytes of diverse, internet-scale data, aiming for breadth—they mimic a staggering range of human cognitive skills, excelling at open-ended tasks demanding extensive world knowledge, complex reasoning, and creative text generation. Versatility defines them, letting you adapt them to countless applications with minimal task-specific training.
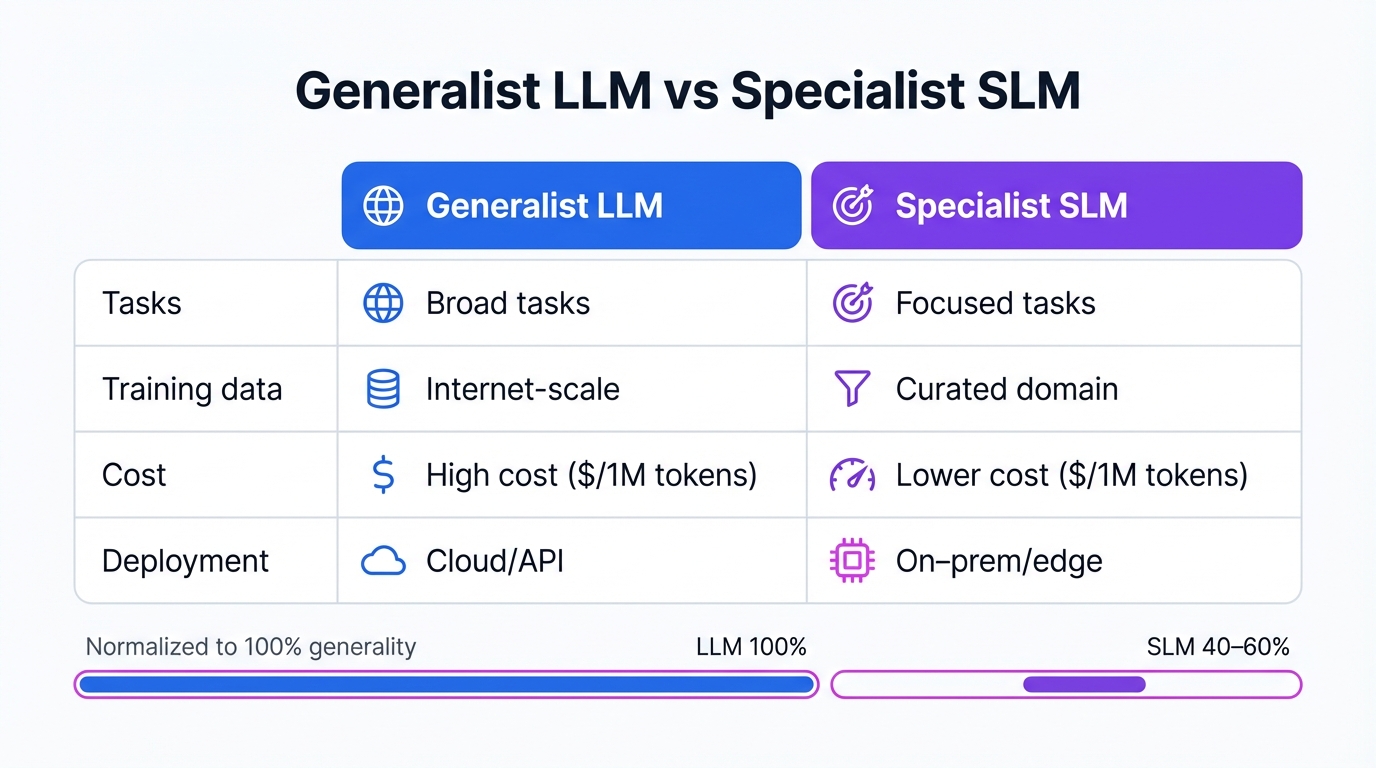
SLMs take the specialist's path. Depth trumps breadth in their world. Developers train them—or more commonly fine-tune them—on smaller, meticulously curated datasets laser-focused on a specific domain or task. This targeted training gives them a deep, nuanced grasp of their particular territory, whether that's legal jargon, medical diagnostics, financial reports, or your company's proprietary knowledge base. The payoff? Higher accuracy, better reliability, and sharper contextual relevance on their specific tasks, often crushing the performance of much larger, general-purpose LLMs. Take Diabetica-7B, an SLM built for diabetes-related questions that achieved 87.2% accuracy, outperforming both GPT-4 and Claude-3.5 in its specialized domain. This trade-off—swapping the broad, jack-of-all-trades intelligence of an LLM for superior performance and efficiency on a narrow task set—defines the SLM approach completely.
Specialization unlocks a strategic advantage called "AI sovereignty." Typically, you access LLM capabilities through cloud-based APIs, a setup forcing you to pipe potentially sensitive company or user data to third-party servers outside your control. This creates massive risks around data privacy, security, and compliance, especially if you operate in heavily regulated sectors like finance, healthcare, or government. SLMs cut straight through this problem. Their compact size and computational efficiency make it practical to deploy them entirely within your own infrastructure, either on-premises or directly on edge devices. This local deployment keeps sensitive data locked inside your secure network, never leaving your control, letting you harness advanced AI without compromising your data governance policies or exposing yourself to external processing risks. The ability to own and manage your entire AI stack—from model to data—represents a form of technological sovereignty growing more critical by the day in our data-driven world.
Visual representation of the fundamental trade-off between generalist LLM power and specialist SLM precision
1.3 Defining "Small": A Fluid Concept of Parameters and Purpose
"Small" in language models is slippery. Relative. It lacks a strict, universally accepted definition based purely on parameter count, and the line dividing "small" from "large" keeps shifting, pushed along by rapid advances in hardware capabilities and model optimization techniques. A model considered large just a few years ago—like the 1.5 billion-parameter GPT-2 released in 2019—would now clearly fall into the SLM category without question.
A smarter, more durable definition of an SLM focuses on its functional footprint and intended use rather than some arbitrary parameter threshold. From a practical standpoint, you define SLMs as models with a parameter count letting them deploy in resource-limited environments. Researchers and practitioners typically cite a range from a few million to about 8 or 10 billion parameters, with occasional exceptions reaching up to 13 billion, as the typical SLM size. This range matters because it allows models to run efficiently on consumer hardware like laptops with modern GPUs and on mobile or edge computing devices.
Ultimately, the most critical distinction lives not in numbers but in philosophy. SLM design follows a principle of optimization, hunting for the best balance between performance, efficiency, and cost for specific tasks. While an LLM gets built for maximum general ability, often with zero regard for resource consumption, an SLM gets engineered for maximum efficiency and accuracy within a defined scope. The real difference lies in the strategic intent: SLMs aim to deliver targeted intelligence in a package that's accessible, affordable, and practical for real-world deployment.
Section 2: The Engineering of Efficiency: How SLMs Are Built
2.1 The Transformer Blueprint: A Shared Architectural Heritage
At their core, Small Language Models build on the same fundamental architecture as their larger cousins: the Transformer. Introduced in 2017, the Transformer became the foundation for nearly all modern language models, including GPT, Llama, and the Phi series. Its design marked a breakthrough in natural language processing by ditching previous architectures that relied on recurrence, instead using parallelizable attention mechanisms that changed everything.
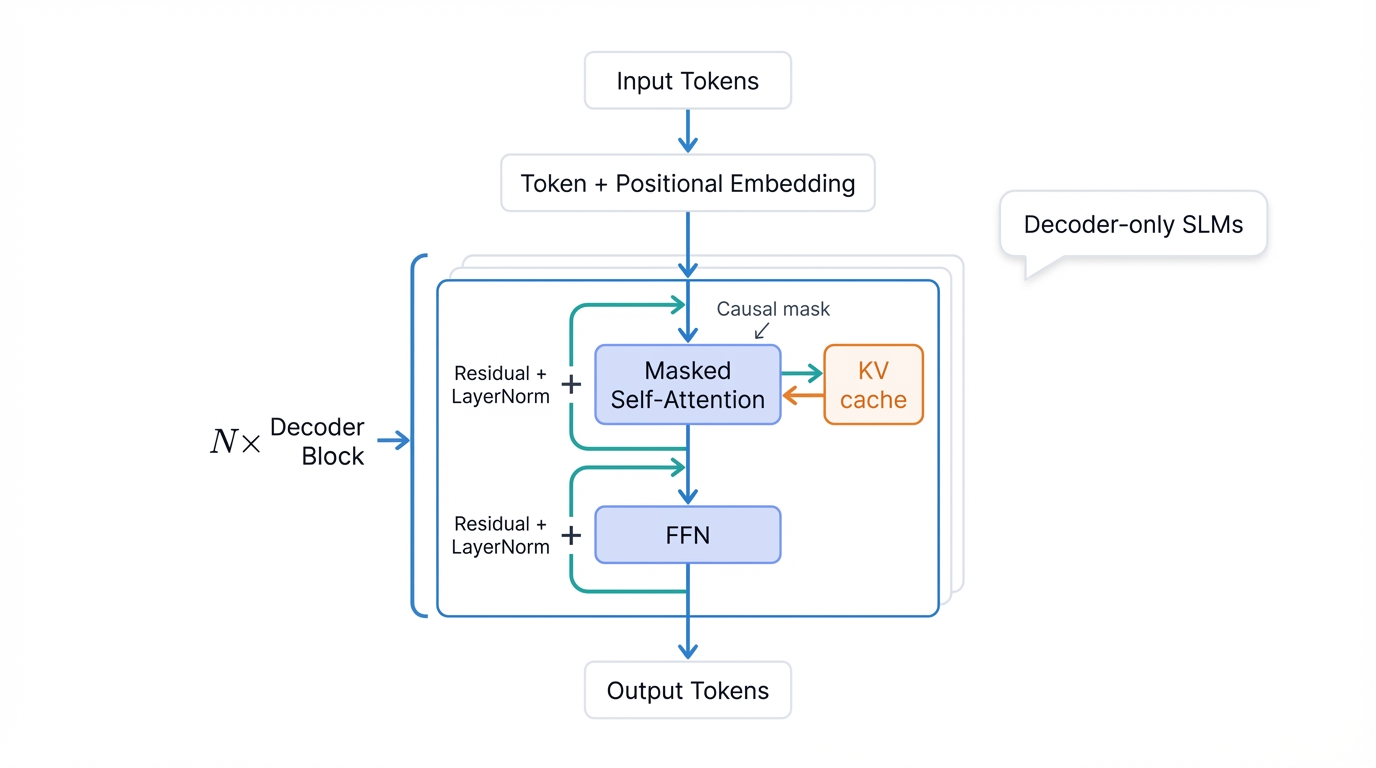
The Transformer architecture typically consists of an encoder-decoder structure. However, many generative models, including most SLMs, use a decoder-only setup that strips away unnecessary complexity. The key innovation? The self-attention mechanism—a component that lets the model dynamically assess the importance of different words or tokens in an input sequence relative to each other. By calculating attention scores, the model "focuses" on the most relevant parts of context when processing each word, enabling it to capture complex, long-range dependencies and subtle semantic relationships within text that earlier architectures could never grasp.
SLMs leverage this powerful architecture but often employ simplified or more efficient implementations of its components, reducing computational and memory requirements during both training and inference without sacrificing the core capabilities that make Transformers so effective.
2.2 The Art of Compression: Core Techniques for Creating SLMs
Creating a high-performing SLM centers on model compression. This process shrinks a model's size, complexity, and computational demands while fighting to keep its predictive accuracy intact. It's not a single technique but a toolkit of advanced methods you can deploy alone or in combination to forge lean, efficient models that punch above their weight.
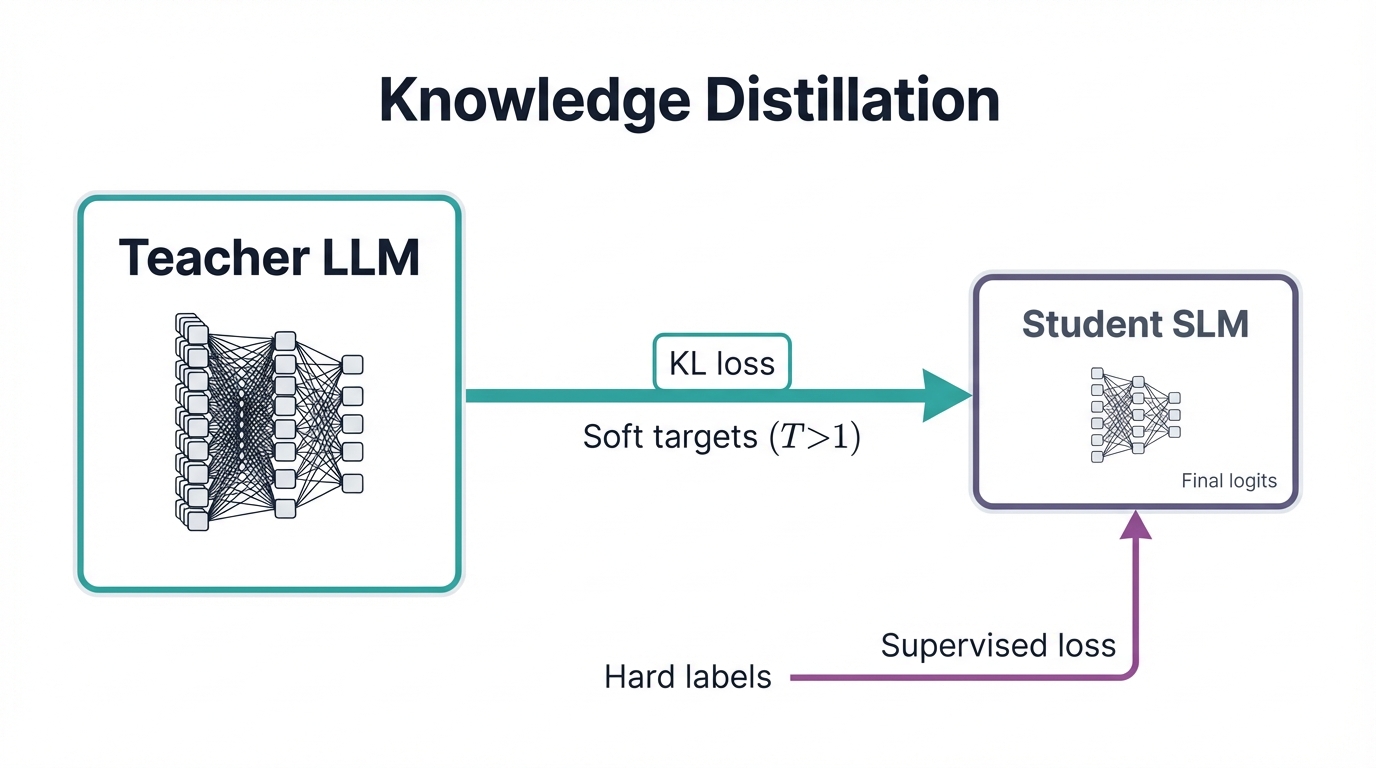
2.2.1 Knowledge Distillation: The Teacher-Student Paradigm
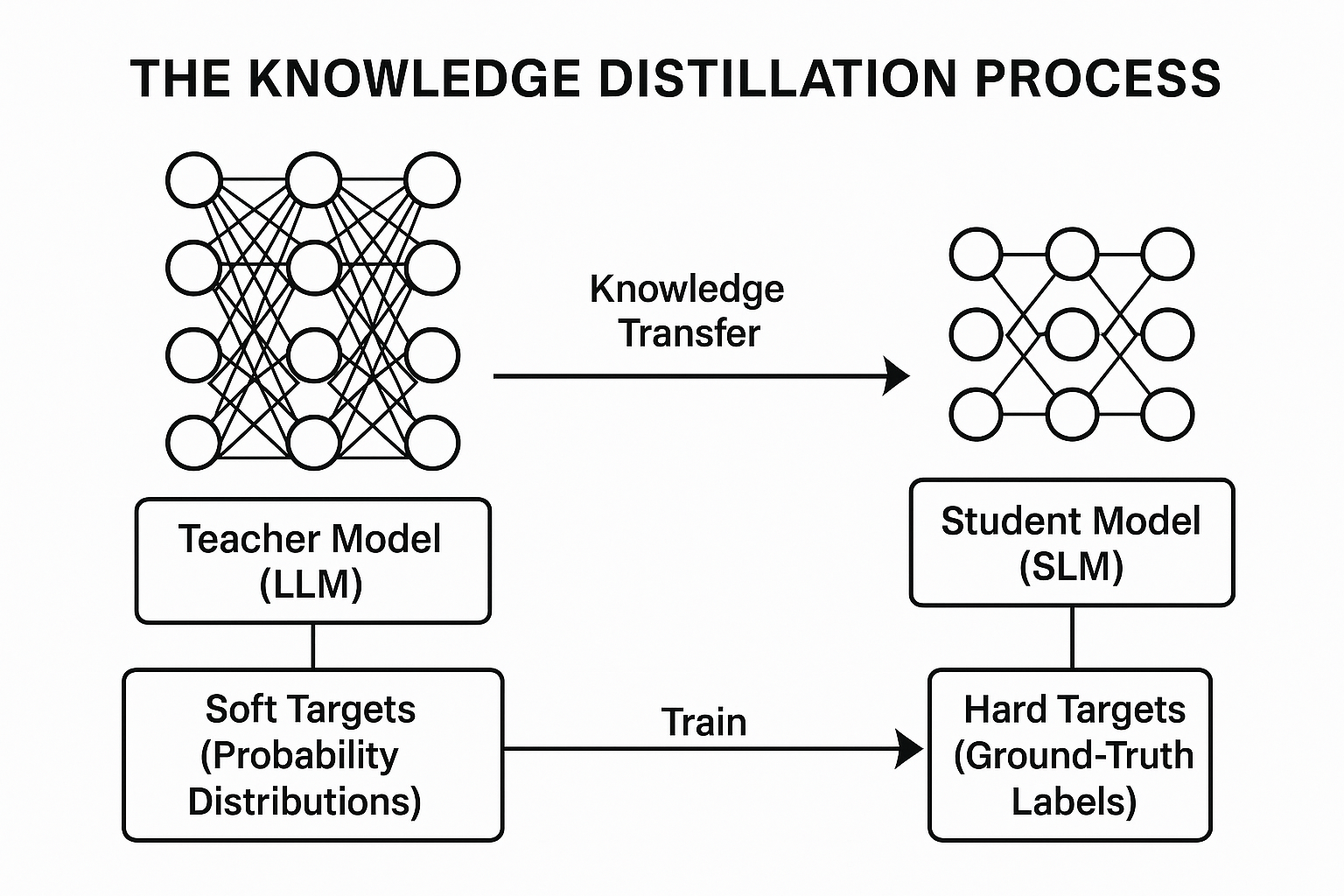
Concept: Knowledge distillation operates on a "teacher-student" principle that's elegant in its simplicity and powerful in its results. You transfer knowledge from a large, complex, pre-trained "teacher" model—usually a powerful LLM—to a smaller, more efficient "student" model, with the goal of making the student learn to mimic the teacher's behavior, inheriting its capabilities in a more compact form.
Process: This goes beyond simple supervised learning where a model learns from ground-truth labels. In knowledge distillation, you train the student to replicate the teacher's output probability distributions over all classes. These distributions, called "soft targets," carry rich information about how the teacher model generalizes and the relationships it has learned between classes. You often use a "temperature" scaling parameter on the teacher's softmax layer to smooth these distributions, making inter-class similarities more explicit and easier for the student to absorb. The student's training loss combines a standard loss on hard targets with a distillation loss that minimizes divergence between its soft predictions and the teacher's. Knowledge transfer can target the final output layer (response-based distillation), the intermediate hidden layers (feature-based distillation), or the relationships between layers (relation-based distillation), giving you flexibility in how you extract and transfer expertise.
Conceptual diagram of the knowledge distillation process showing teacher-student model training paradigm
Significance: Knowledge distillation proves its worth as a highly effective method for creating powerful small language models. A standout example? DistilBERT, a distilled version of Google's BERT model. Through this process, DistilBERT shrank by 40% and sped up by 60% compared to its teacher while retaining 97% of BERT's original language understanding capabilities, demonstrating the technique's remarkable effectiveness in preserving capability while slashing resource requirements.
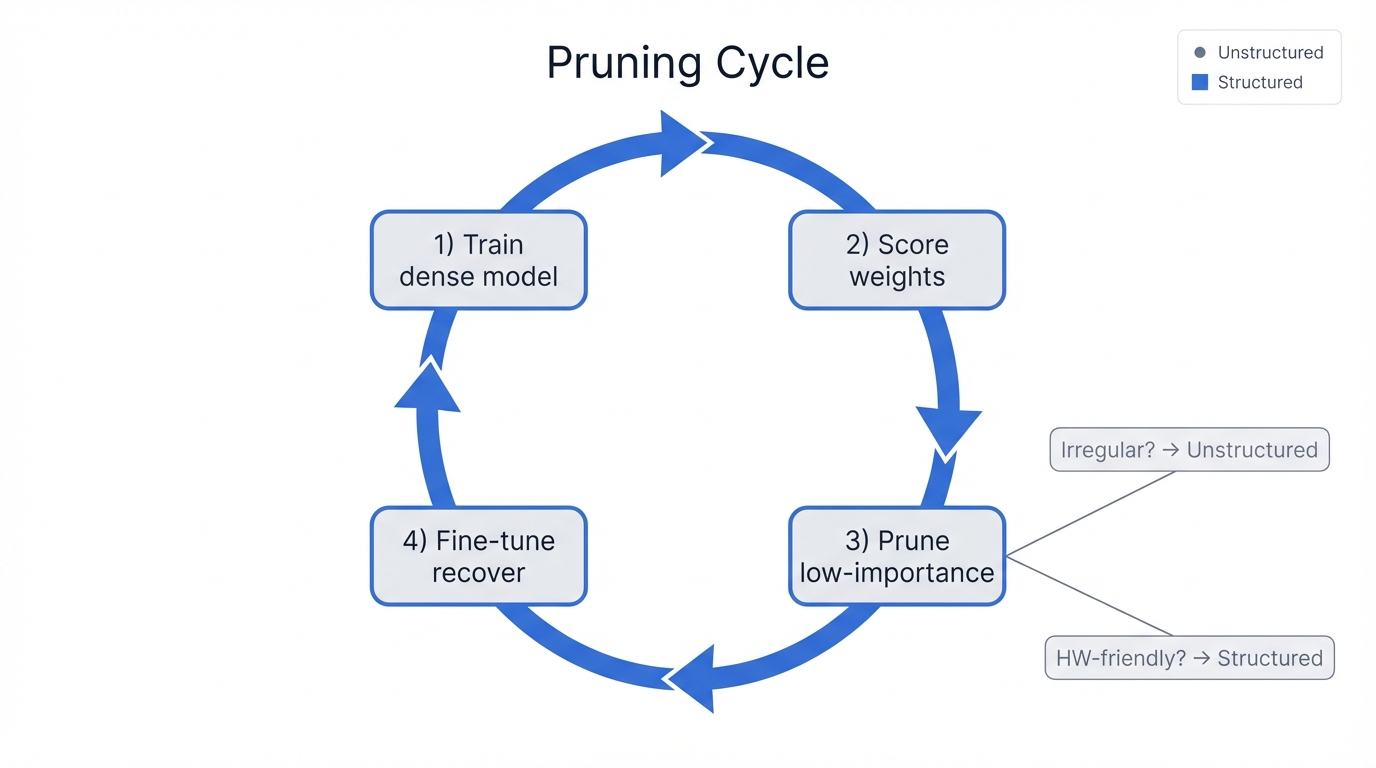
2.2.2 Pruning: Excising the Unnecessary
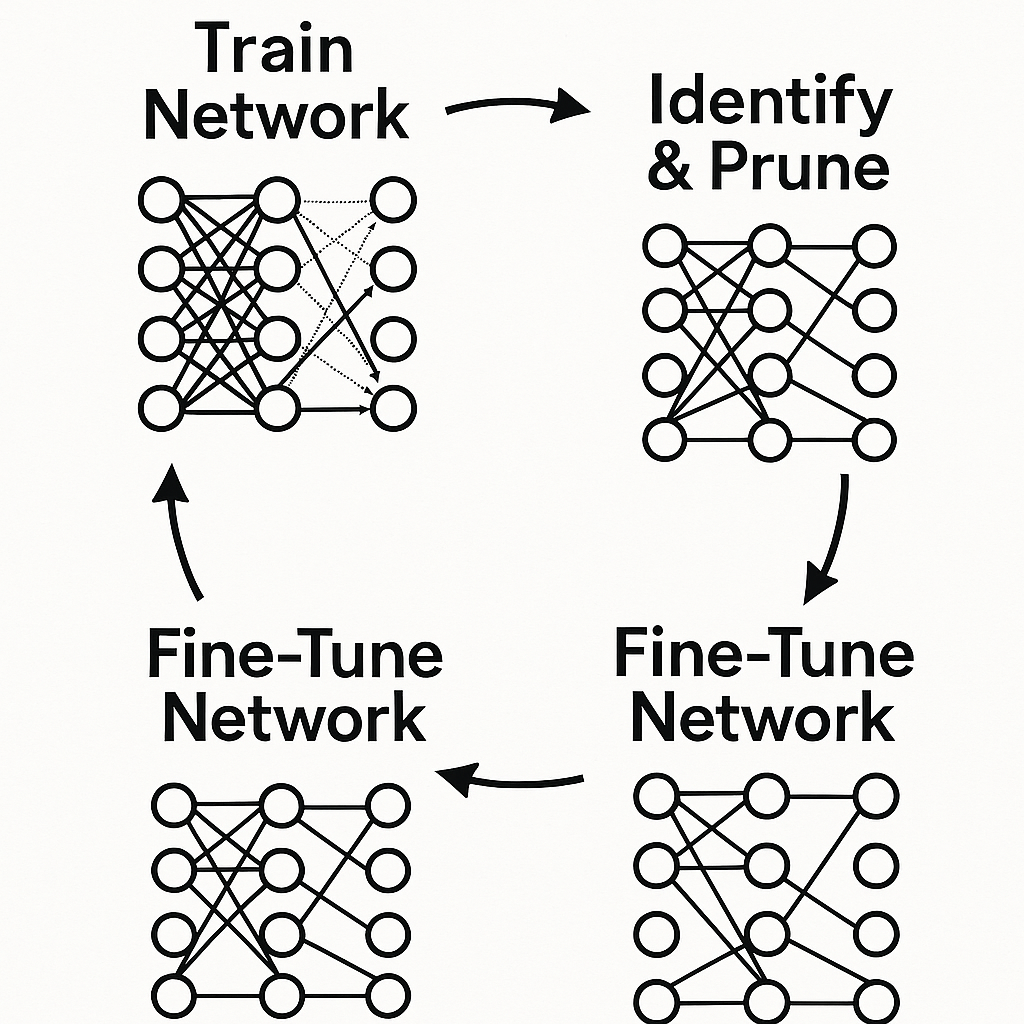
Concept: Neural network pruning draws inspiration from biological synaptic pruning, mimicking how brains optimize themselves by cutting unnecessary connections. It's a technique you use to reduce model complexity by systematically identifying and removing parameters—individual weights, neurons, or even entire layers—that prove redundant or non-essential for model performance. The result? A "sparse" model with a smaller memory footprint and fewer computations required during inference.
Process: The typical pruning workflow runs iteratively, cycling through phases of cutting and recovery. First, you train a full-sized, dense model to convergence, building a baseline of capability. Then, you score each parameter in the network using an importance criterion; a common and straightforward criterion uses the absolute value of weights, treating smaller-magnitude weights as less important contributors to model performance. You prune the lowest-scoring parameters by setting them to zero, which often triggers an accuracy drop as the model loses some of its learned connections. To recover from this, you fine-tune the pruned network through continued training, allowing the remaining weights to adjust and compensate for their lost colleagues, often recovering most or all of the lost performance. You can repeat this cycle of pruning and fine-tuning multiple times to reach your target sparsity level.
Iterative workflow of neural network pruning showing parameter removal and fine-tuning cycles
Types: Pruning methods split into two main categories, each with distinct trade-offs:
- Unstructured pruning removes individual weights regardless of their location, producing a sparse but irregular weight matrix that standard hardware like GPUs struggles to accelerate efficiently, often failing to deliver the speed improvements you'd expect from the reduced parameter count.
- Structured pruning, on the other hand, removes entire structural units—neurons, attention heads, or convolutional filters—preserving a dense, uniform structure in the remaining weight matrices that plays nicely with hardware acceleration, typically delivering greater improvements in inference speed that actually translate to real-world performance gains.
2.2.3 Quantization: Speaking in a Simpler Language
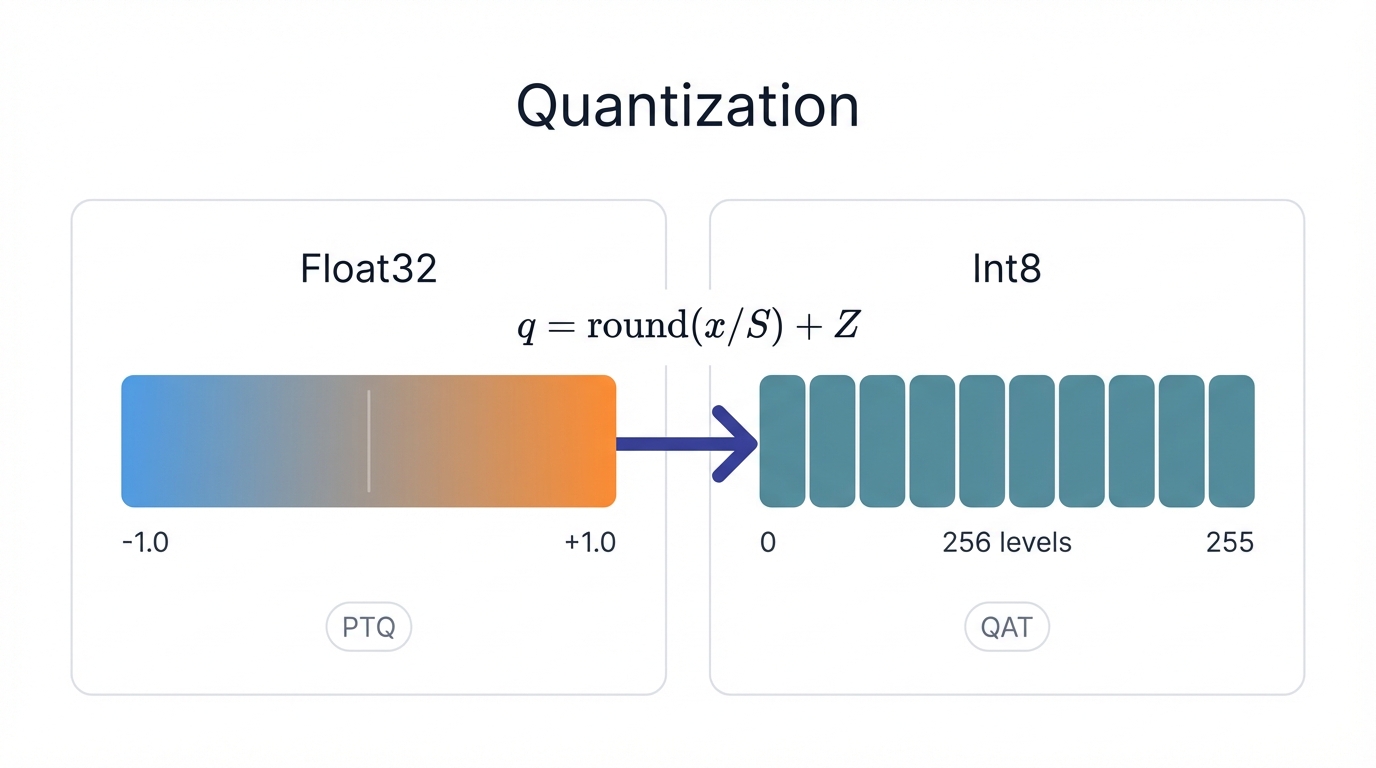
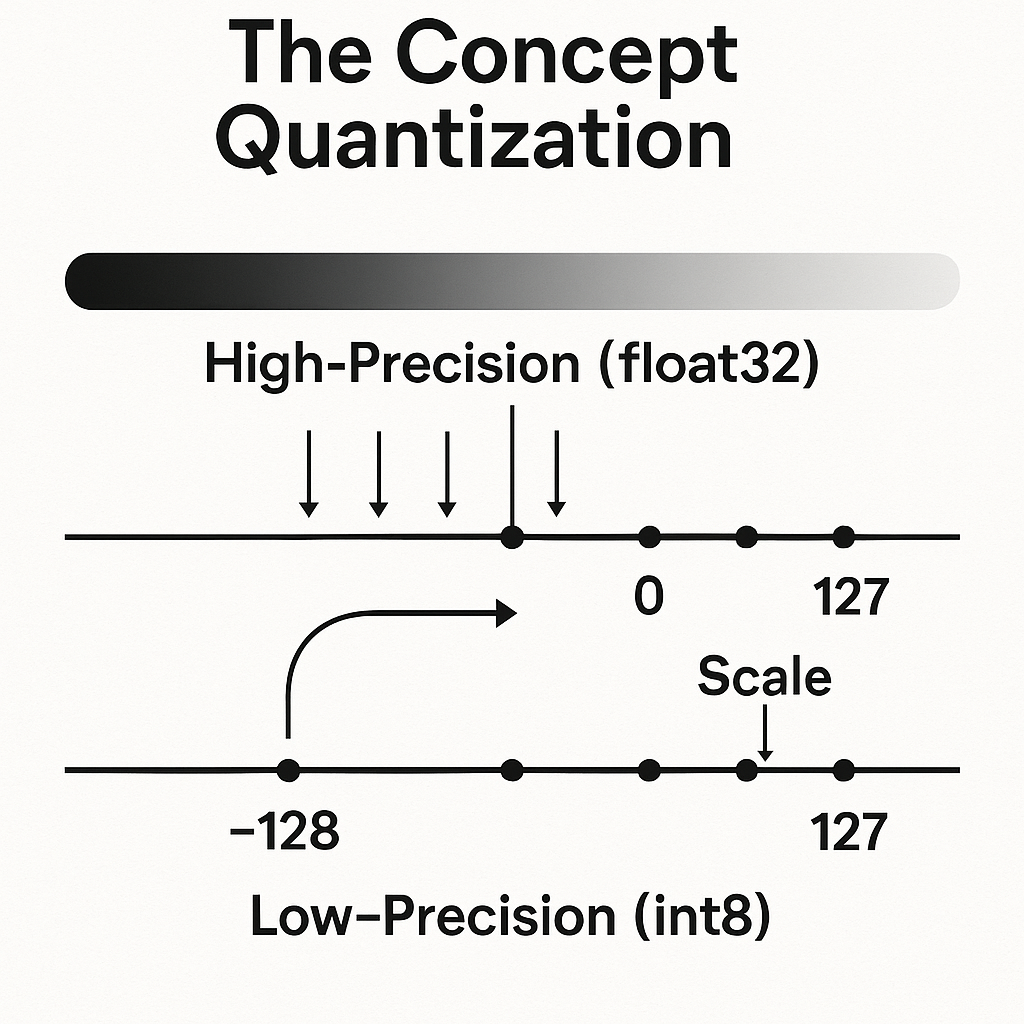
Concept: Quantization is a powerful optimization technique that slashes a model's memory usage and computational demands by reducing the numerical precision of its parameters. Neural network weights and activations typically get stored as 32-bit floating-point numbers (float32), offering high precision but consuming substantial memory and processing power. Quantization converts these high-precision values into lower-precision data types, most commonly 8-bit integers (int8), drastically reducing the resources needed to store and process the model.
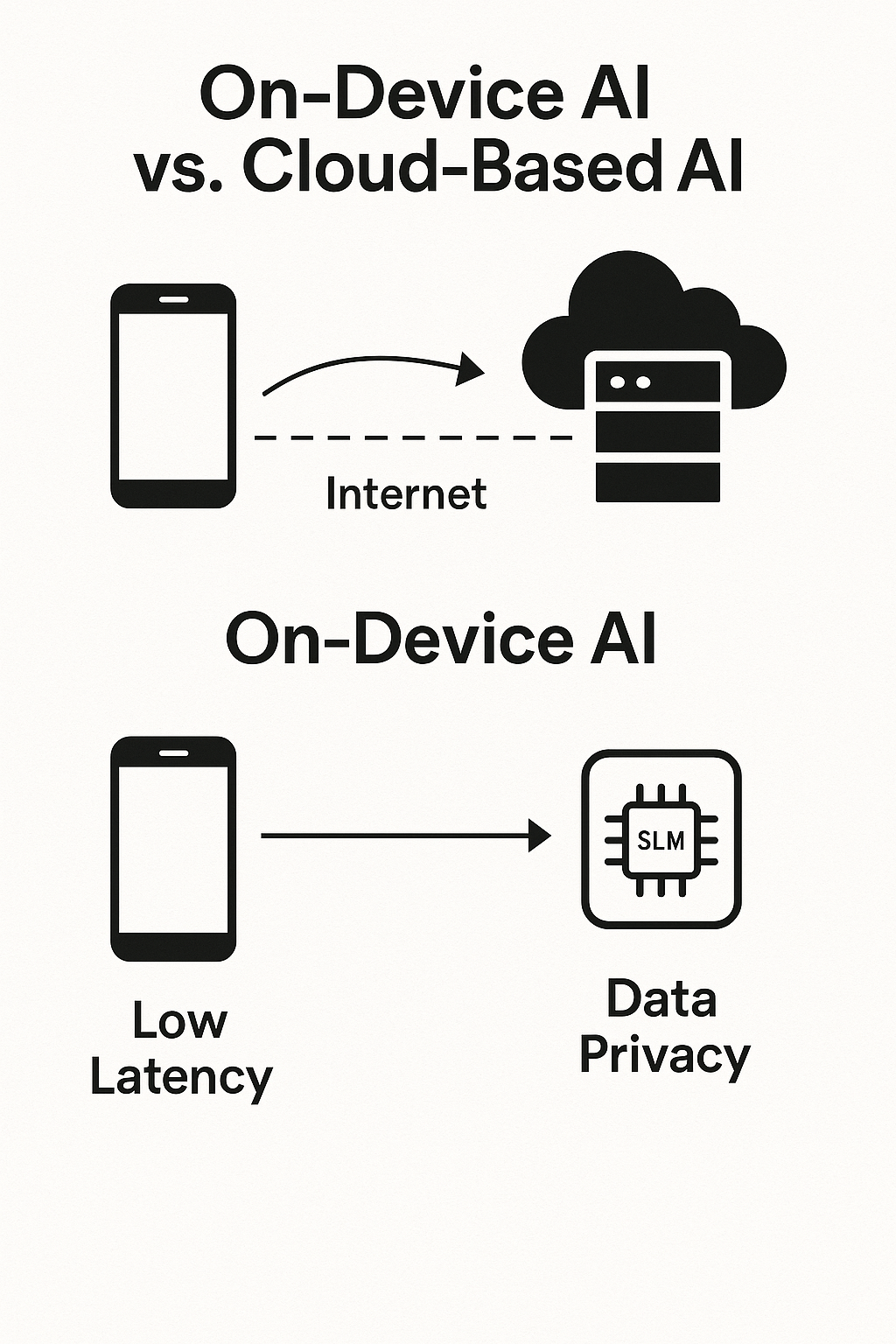
Illustration of the quantization process mapping high-precision float values to low-precision integers
Process: The transition from a continuous range of float32 values to a discrete set of 256 possible int8 values gets achieved through an affine quantization scheme using two parameters: a scale factor (S), which is a positive float, and a zero-point (Z), which is an integer that maps the quantized values to the original range. You can apply this conversion mainly in two ways, each with different trade-offs:
- Post-Training Quantization (PTQ): You train the model initially in full precision, then convert its weights to the lower-precision format after training completes. PTQ is quick and easy to implement, making it attractive for rapid deployment, but it can sometimes trigger a noticeable accuracy drop as the model adjusts to its reduced precision without the benefit of training to compensate.
- Quantization-Aware Training (QAT): You simulate the quantization process during training itself, exposing the model to precision constraints from the start. The model learns to adapt to precision loss during the training phase, generally producing a more accurate quantized model than PTQ, though it demands a more complex and resource-intensive training process that requires careful tuning.
Significance: Quantization proves crucial for on-device and edge AI deployments where every watt and byte counts. Most modern CPUs and specialized AI accelerators—like the NPUs embedded in smartphones—can perform integer operations significantly faster and more energy-efficiently than floating-point calculations, sometimes achieving orders of magnitude improvement. By converting a model to use int8 operations, you unlock substantial improvements in inference speed and dramatic reductions in power consumption, making it feasible to run complex models on battery-powered devices without draining them in minutes. Just converting from 32-bit to 8-bit can slash model size by 75%, a reduction that opens doors to deployment scenarios previously impossible.
Section 3: A Survey of Leading Small Language Models
3.1 The Modern SLM Landscape: Key Players and Philosophies
The Small Language Models field pulses with energy and rapid evolution, driven by intense innovation from major tech companies, well-funded AI startups, and the passionate open-source community. Each key player brings a unique philosophy to model development, creating a diverse ecosystem of SLMs that vary wildly in performance, efficiency, and accessibility, giving you rich choices for different deployment scenarios.
3.2 In-Depth Model Profiles
Microsoft's Phi Series: The Power of Curated Data
Overview: The Phi family of models, spanning Phi-1, Phi-2, and the latest Phi-3, exemplifies the "quality over quantity" approach to data curation, proving you don't need internet-scale datasets to build capable models. Microsoft's research demonstrates that by training on carefully filtered web data combined with high-quality synthetic data, smaller models can achieve impressive reasoning and language understanding capabilities that rival or even surpass much larger models trained on massive but noisy datasets.
Phi-3-mini: The flagship of this approach is Phi-3-mini, a 3.8 billion-parameter model trained on a vast 3.3 trillion-token dataset that Microsoft meticulously curated for quality. It's specially engineered to be compact enough to run locally on a modern smartphone while delivering performance comparable to models like Mixtral 8x7B and GPT-3.5, democratizing access to powerful AI capabilities that previously required cloud infrastructure.
Google's Gemma Family: Open Models from Gemini Research
Overview: The Gemma family reflects Google's commitment to the open-source AI community by offering a series of models built with the same advanced research and technology powering their flagship Gemini models. Google designed these models to be accessible, efficient, and developed with a strong focus on responsible AI principles, including extensive safety testing and clear usage guidelines that help developers deploy them responsibly.
Models: The Gemma family spans a wide range of sizes, making them suitable for diverse applications from ultra-constrained environments to more demanding tasks. This includes an ultra-lightweight 270 million-parameter model for highly resource-limited scenarios, plus more powerful versions with 2 billion, 4 billion, 9 billion, and 27 billion parameters that let you choose the right balance of capability and efficiency for your specific needs.
Mistral AI's Fleet: A Focus on Efficiency and Performance
Overview: Paris-based startup Mistral AI has quickly established itself as a leader in the open-source AI space by creating models that are highly efficient and consistently "punch above their weight," delivering performance that crushes larger models from competitors through superior architecture and training techniques.
Mistral 7B: The model that initially catapulted Mistral to prominence is Mistral 7B, a breakthrough that shook the industry. When it dropped, this 7-billion-parameter model outperformed the much larger Llama 2 13B model across a broad range of benchmarks, setting a new standard for performance efficiency within its size class and proving that smart architecture beats brute-force scale.
3.3 Comparative Performance Analysis
Evaluating and comparing different language models' capabilities is a complex task that leans on a standardized set of benchmarks. These benchmarks test various facets of a model's intelligence, from basic knowledge recall to sophisticated reasoning and coding skills. Understanding these metrics is critical for making informed choices about which model to deploy for your specific use case.
Comparative performance analysis of leading Small Language Models across key benchmarks
Key Benchmarks:
- MMLU (Massive Multitask Language Understanding): A comprehensive benchmark that measures a model's general knowledge and problem-solving skills across 57 different subjects, ranging from elementary mathematics to professional law, providing a broad assessment of capabilities.
- MT-Bench: A tough multi-turn benchmark designed to evaluate the conversational and instruction-following skills of chat-optimized models, testing their ability to maintain context and handle complex, evolving dialogue that mirrors real-world applications.
- HumanEval & MBPP: Standard benchmarks used to assess a model's ability to generate correct code from natural language descriptions, measuring how well it translates human intent into functional programs across various programming tasks.
- GSM8K: This benchmark measures a model's mathematical reasoning by requiring it to solve multi-step word problems typical in grade school curricula, testing its ability to break down complex problems and apply mathematical logic step by step.
Performance Insights: Recent SLMs have posted impressive results on these benchmarks that challenge assumptions about model size and capability. Models like Phi-3-mini have scored 69% on MMLU, competitive with much larger models from earlier generations, highlighting the stunning success of modern training methods that prioritize data quality and architectural efficiency. When you fine-tune these models for specific tasks, they show dramatic improvements, with models released in 2024 cutting inaccuracies by nearly 50% compared to their 2023 predecessors, demonstrating the field's rapid evolution.
Conclusion
Best Practice: Following these recommended practices will help you achieve optimal results and avoid common pitfalls.
The rise of Small Language Models marks a fundamental shift in artificial intelligence—from an obsessive pursuit of ever-larger models toward strategic optimization, specialization, and democratized access. SLMs aren't merely scaled-down versions of their larger counterparts; they're purpose-built systems that prioritize efficiency, domain expertise, and practical deployability over raw generalist capability.
Through sophisticated engineering techniques like knowledge distillation, pruning, and quantization, SLMs achieve remarkable performance within constrained computational budgets, proving that intelligence doesn't require massive scale. The data-first paradigm pioneered by models like Microsoft's Phi series demonstrates conclusively that careful curation and synthetic data generation can rival—and sometimes surpass—the brute-force approach of internet-scale training that dominated the field for years.
For organizations navigating the AI landscape, SLMs offer compelling advantages that extend far beyond just lower costs: reduced operational expenses, enhanced privacy through on-premises deployment that keeps data under your control, lower latency for real-time applications that demand instant responses, and the ability to fine-tune models for specific domains and use cases that matter to your business. As the field continues to evolve at breakneck speed, SLMs will play an increasingly crucial role in making artificial intelligence accessible, sustainable, and practically valuable across diverse industries and applications, from healthcare to finance to manufacturing.
The future of AI lies not in choosing between large and small models but in understanding when and how to deploy each effectively to maximize value. SLMs represent the democratization of artificial intelligence—bringing powerful capabilities within reach of organizations and developers who previously could not access or afford frontier AI systems, leveling the playing field and sparking innovation in unexpected places.
