Table of Contents
- When AI Infrastructure Becomes a Security Nightmare
- Part I: The Protocol Weaponization
- Part II: Surveillance Through Monitoring
- Part III: Vulnerable by Design
- Part IV: Future Challenges
- Your AI Fabric Security Action Plan
When AI Infrastructure Becomes a Security Nightmare
Multi-Tenant Risk
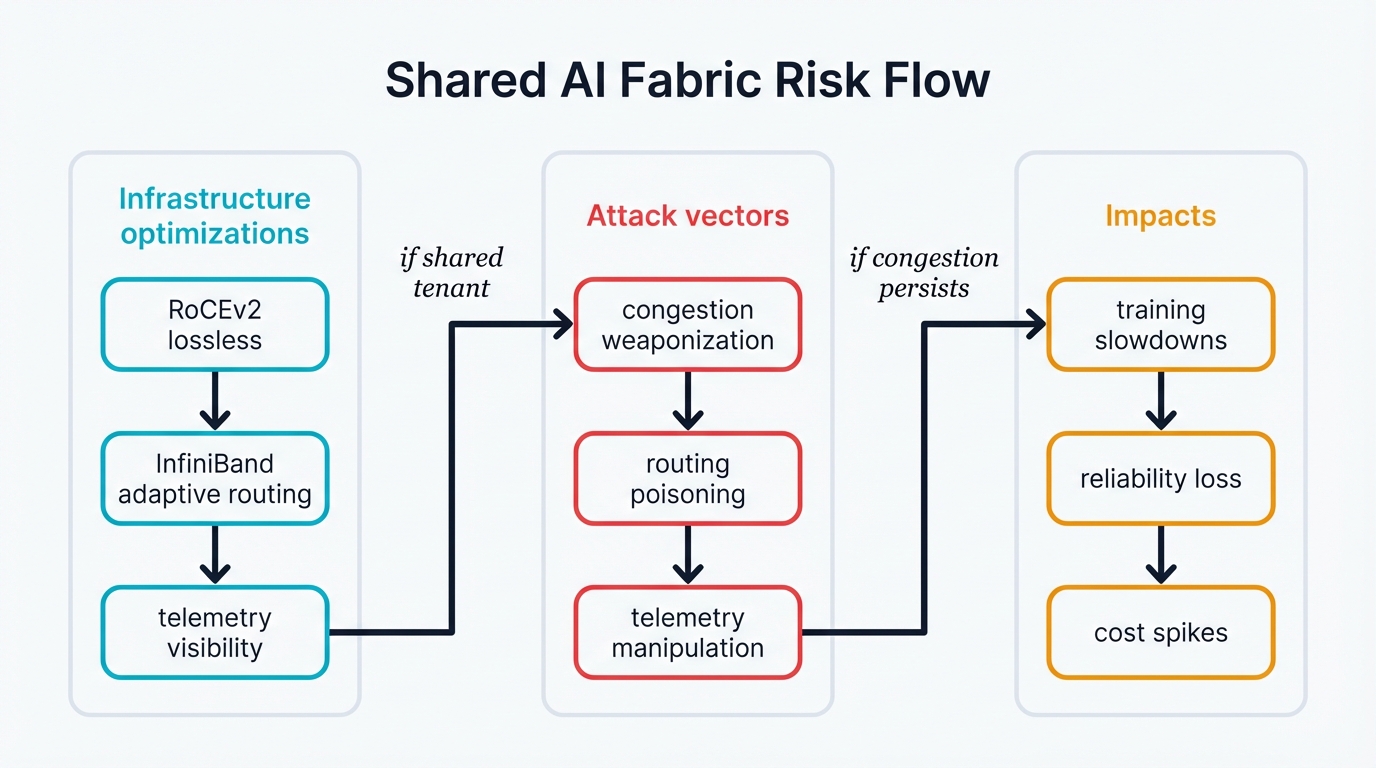
Shared AI fabric infrastructures introduce unique security challenges where performance optimizations can become attack vectors. Understanding these risks is critical for securing multi-tenant AI deployments.
Picture this. Your organization just invested millions in state-of-the-art AI infrastructure. Hundreds of GPUs connect through blazing-fast networks that promise unprecedented performance. RoCEv2 and InfiniBand deliver the speed you need. Your data scientists eagerly begin training the next breakthrough model that could revolutionize your business and give you an unbeatable competitive edge in the market.
Then everything crashes.
Training jobs slow to a crawl—what took hours now demands days, system reliability plummets catastrophically, and costs spiral beyond control faster than your finance team can track the damage. What happened? An attacker weaponized the very systems you built for performance. A neighboring tenant on your shared infrastructure turned your own optimization protocols against you, transforming your competitive advantage into a devastating vulnerability.
This isn't science fiction. It's happening right now in shared AI fabrics around the world, and most security teams don't even know they're under attack.
Your fabric hides serious vulnerabilities in the very systems that make it fast. Think about what AI workloads actually need: high-performance networking that moves data at incredible speeds, lossless connections that guarantee every packet arrives intact, distributed training that requires perfect synchronization across hundreds of GPUs, and inference services that demand microsecond-level response times because your customers won't wait.
Those performance protocols become weapons in the wrong hands. RoCEv2 congestion control can fail you spectacularly when attackers manipulate traffic patterns. InfiniBand adaptive routing, designed to optimize your network paths, can betray your trust when malicious actors poison routing decisions. The fabric telemetry that helps you monitor performance exposes your training patterns, model architectures, and competitive secrets to anyone watching the network closely enough to extract intelligence from timing data.
Attackers wield devastating capabilities. They manipulate congestion patterns to slow down competing tenants while their own workloads run at full speed. They poison telemetry systems with false data that makes your network management tools make catastrophically wrong decisions. They create timing side-channels that leak your most valuable model secrets to competitors who analyze network patterns with frightening precision. They launch denial-of-service attacks that look exactly like normal network congestion, hiding in plain sight while your infrastructure burns resources without making progress.
The results are catastrophic in ways that destroy business value. Critical training jobs fail completely after consuming thousands of dollars in GPU time. Projects that should take days stretch into weeks, missing market windows and letting competitors ship first. System reliability becomes utterly unpredictable, making it impossible to commit to delivery timelines or accurately estimate project costs.
How Congestion Control Becomes Your Enemy
The RoCEv2 Trap: When Lossless Networks Become Vulnerable
RoCEv2 powers most modern AI fabrics. RDMA over Converged Ethernet version 2 promises everything you need: lossless networking that guarantees packet delivery, high performance that matches your GPU speeds, and zero packet drops that keep your training jobs running smoothly.
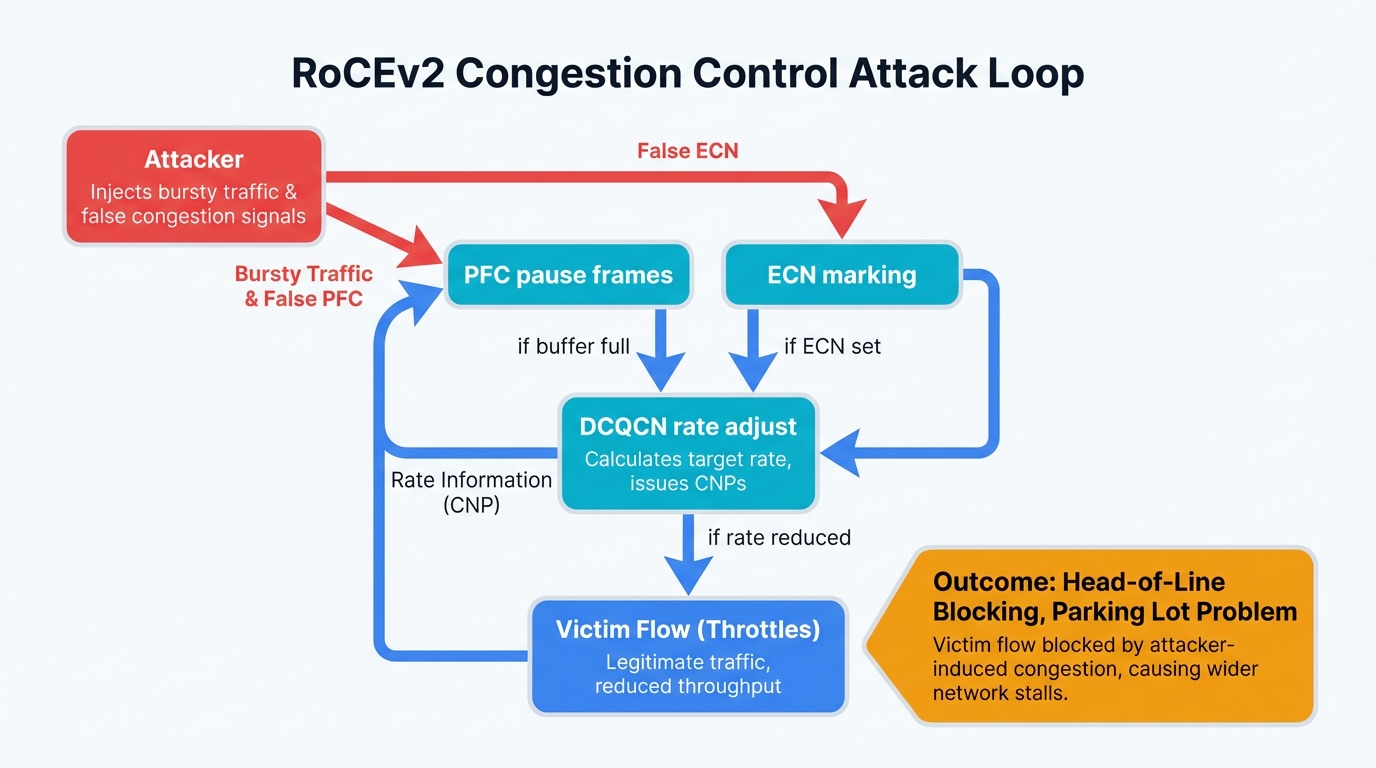
But that "lossless" guarantee creates chaos when attackers exploit it.
The protocol depends on critical mechanisms working in harmony. Priority Flow Control governs traffic flow by sending pause frames when buffers fill. Explicit Congestion Notification signals problems before they become catastrophic. The DCQCN algorithm orchestrates both systems, adjusting transmission rates based on congestion feedback to maintain that precious lossless guarantee.
Multi-tenant environments turn these elegant mechanisms into weapons. Wrong hands exploit them ruthlessly, transforming protective features into attack vectors that most security teams never anticipated.
The Vulnerability: The very lossless nature that makes RoCEv2 essential for AI workloads introduces critical security gaps that attackers exploit systematically, using the protocol's own protective mechanisms against it.
PFC Becomes a Cascade of Chaos
Malicious attacks unfold with terrifying predictability. Tenants trigger cascading pause frames that propagate upstream through your network like a virus. Each pause frame creates head-of-line blocking—legitimate traffic gets trapped behind congestion that attackers deliberately created. Innocent victim flows suffer completely while the attacker's traffic flows freely through paths they've carefully kept clear.
Picture aggressive "elephant flows" consuming every byte of available bandwidth. Smaller "mice flows" starve completely, unable to get even a tiny slice of network capacity. Network engineers call this disaster the "parking lot problem"—once your network gets full, nobody can move.
Attackers create something far worse. They weaponize this into congestion-based denial of service, deliberately overwhelming competing tenants with traffic patterns designed to trigger maximum disruption. Your critical gradient synchronization traffic—the heartbeat of your training job—gets trapped behind artificial bottlenecks that stop everything cold.
Training iterations that should require seconds now demand minutes, turning a job that should finish overnight into one that takes days and costs exponentially more in compute resources.
ECN Manipulation: False Signals, Real Damage
DCQCN depends on ECN marking to know when congestion threatens. This dependency becomes a weapon. Malicious tenants craft specific traffic patterns designed to trigger premature ECN marking on shared network infrastructure, sending false congestion signals that deceive your legitimate flows into slowing down unnecessarily.
Your legitimate flows see these false signals and reduce transmission rates to be good network citizens.
Meanwhile, attackers exploit the chaos they created by sending uncontrolled bursts everywhere, deliberately overflowing buffers despite the very congestion signals their own traffic generated in the first place. They ignore the rules while your traffic follows them religiously, giving attackers a massive and unfair advantage.
Attack Success: Your training job gets deceived into thinking the network is congested when it's actually clear. It throttles back automatically, being a good citizen, while attacker traffic flows at full speed because they simply ignore the congestion signals they created.
Buffer Exhaustion: The Ultimate Resource War
Shared buffer architectures become prime targets. Multi-tenant fabrics face deliberate flooding attacks where malicious actors generate precisely timed traffic with bursty patterns designed to exhaust switch buffers at critical moments—right when your training job needs them most.
Even your supposedly "lossless" configuration fails under this assault. Other tenants experience packet drops as buffers overflow despite all the promises, breaking the fundamental guarantee that made you choose RoCEv2 in the first place.
This creates resource warfare where the most aggressive tenant wins every time. Your AI workload loses because it's designed for cooperation, built for efficiency, and optimized for speed—not built for battle against attackers who play by completely different rules.
It's like showing up to a knife fight with a handshake.
InfiniBand's Adaptive Routing: A Double-Edged Optimization
InfiniBand's adaptive routing improves load distribution beautifully. It spreads traffic intelligently across multiple fabric paths, using real-time congestion information to route packets around problems and keep everything flowing smoothly. But this very intelligence creates new vulnerabilities that sophisticated attackers exploit with devastating effectiveness, turning adaptive optimization into a weapon that redirects your traffic through deliberately created bottlenecks.
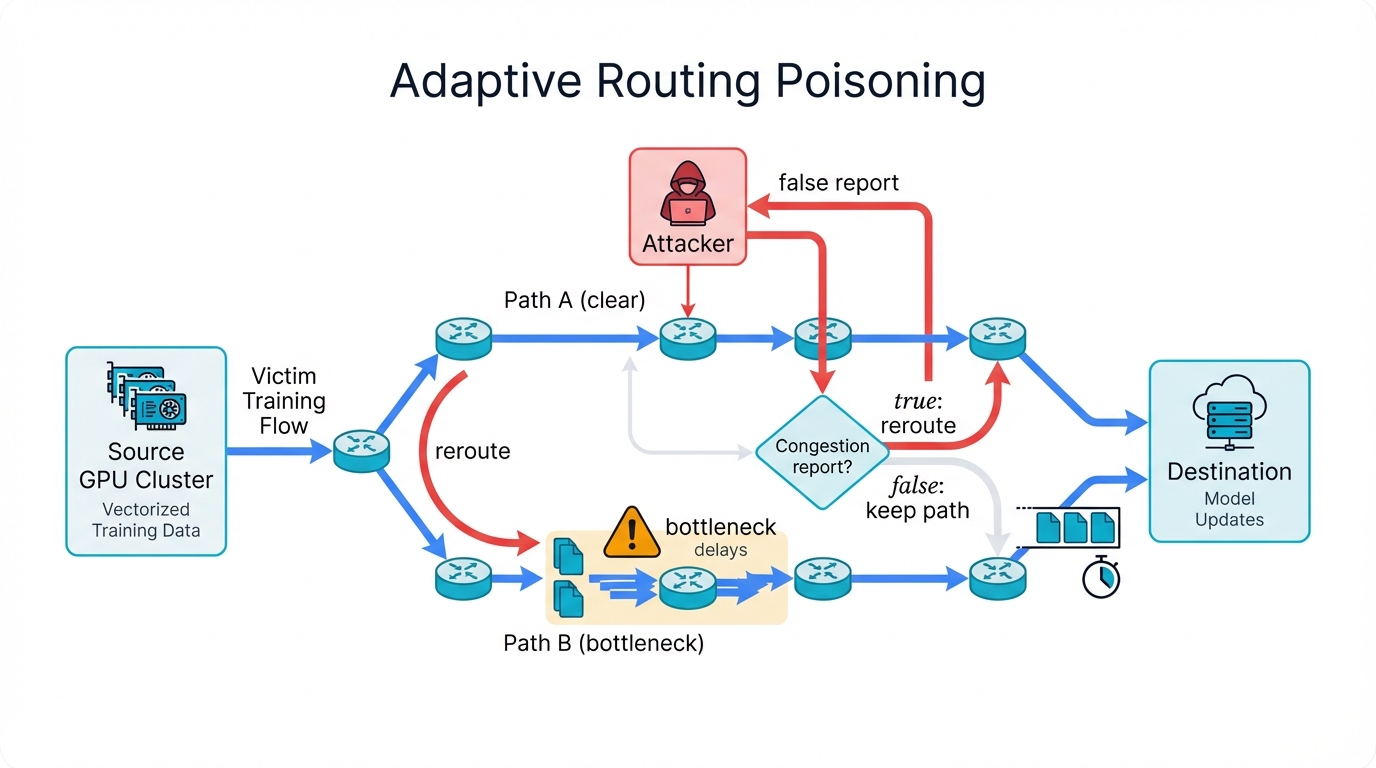
Routing Table Poisoning: Redirecting Your Traffic
InfiniBand uses distributed adaptive routing where individual nodes influence routing decisions by sending congestion reports constantly. This flexibility—this democratic approach to routing—becomes a critical weakness when malicious nodes craft false reports designed to poison routing tables systematically, rewriting the rules of traffic flow to benefit attackers while harming victims.
Attackers redirect your critical training flows deliberately to suboptimal paths they control, paths where they've created artificial bottlenecks everywhere that slow your traffic to a crawl. Their flows benefit from the clear routes they preserved while yours suffer through the degraded routes they forced you into. Parameter server communications face delays as microseconds become milliseconds, and milliseconds accumulate into seconds that destroy training convergence patterns completely.
Congestion Spreading: Amplification Through Misdirection
Attacks become truly insidious here. Localized congestion that should stay contained instead propagates artificially to unrelated network segments through deliberately poisoned routing decisions. Attackers trigger what researchers call the "reverse parking lot problem"—they create congestion deliberately in one spot, then spread it far beyond its original location through cascading routing changes that affect the entire fabric.
This amplification effect destroys everything it touches. Legitimate traffic patterns across your entire AI fabric face disruption from what started as a small, targeted attack. Small attacks launched from network edges cascade into fabric-wide performance disasters, and distributed training jobs spanning hundreds of nodes face unpredictable delays that make convergence impossible to achieve.
Network-Wide Disruption Through Coordinated Campaigns
Sophisticated attacks coordinate routing manipulation across multiple switches simultaneously. Case studies document devastating campaigns where attackers compromise routing decisions on switches throughout the organization, spreading disruption across entire data centers and causing massive damage—lost compute time exceeding $100,000, training jobs failing catastrophically after days of progress, and business-critical AI projects missing launch windows that competitors gleefully fill.
Attack Scale: Coordinated campaigns exploit the interconnected nature of modern AI fabrics where attackers compromise multiple switch routing decisions simultaneously to effectively partition your network, forcing critical training traffic through chokepoints where deliberate congestion destroys performance while the attack remains virtually undetectable to traditional monitoring systems.
When Network Monitoring Becomes Surveillance
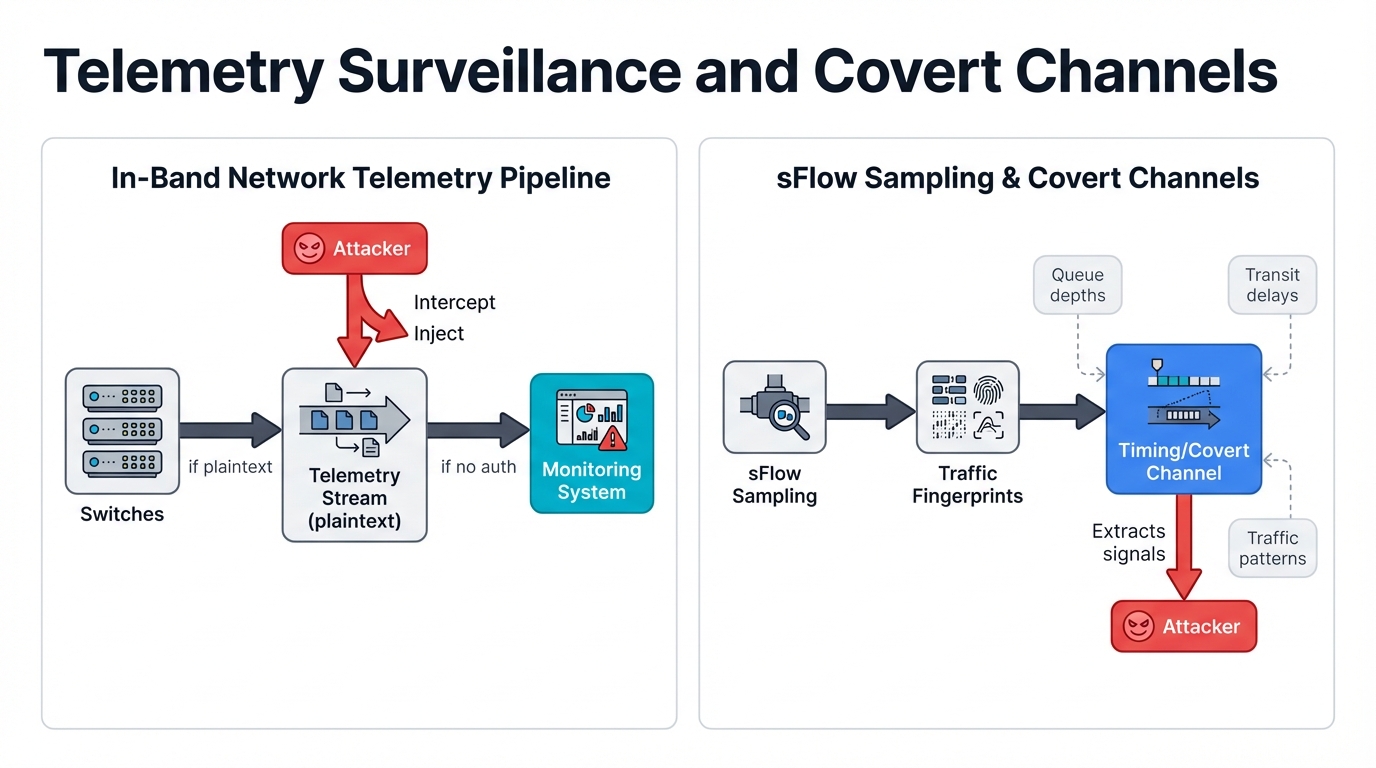
In-Band Network Telemetry: Your Network's Confession Booth
In-band telemetry provides the network visibility that makes AI fabric management possible. INT (In-band Network Telemetry) gives you real-time insights into queue depths, transit delays, and traffic flows. But this visibility has a dark side that creates massive data leakage pathways and expands attack surfaces in ways that most security teams never anticipate or even consider when they deploy these monitoring systems.
Telemetry Data Interception: Your Network's Open Book
Traditional INT systems expose everything. Telemetry data travels in plaintext across your network, creating security nightmares where man-in-the-middle attacks succeed easily because telemetry flows lack encryption, authentication, or any meaningful protection against interception.
Sophisticated attackers deploy "trojan horses" that inject false data into telemetry streams. They intercept legitimate information simultaneously, giving them both control over what your monitoring systems see and intelligence about what's actually happening on your network.
What do they learn from this stolen data? Queue depths reveal traffic patterns that expose when you're training large models. Transit delays expose network topology, showing attackers the physical structure of your infrastructure. Traffic flow characteristics enable inference attacks where attackers determine your model types, discover parameter counts, and estimate training progress—all from network telemetry data that you thought was just helping you monitor performance.
INT Packet Manipulation: Four Ways to Break Your Network
Research identifies four primary attack vectors. INT manipulation exploits fundamental weaknesses in how the telemetry framework trusts data without verification. Malicious actors craft adversarial packets that inject false information easily, causing severe network disruption that cascades through every system that depends on accurate telemetry for making decisions.
These attacks succeed through misplaced trust. Network management systems trust telemetry data implicitly, making decisions based on information they never verify. Attackers inject false queue depths, causing your congestion control algorithms to make catastrophically wrong decisions. They manipulate delay measurements, making adaptive routing choose suboptimal paths that benefit attackers while harming legitimate traffic. Your AI workloads suffer tremendously while root causes hide behind poisoned telemetry streams that conceal everything attackers do.
Metadata Leakage: When Diagnostics Become Intelligence
Modern interconnects provide incredibly rich metadata. CXL 3.1 offers 34 bits of metadata per transaction. Diagnostic information flows constantly through your systems, helping you troubleshoot problems and optimize performance. But this data inadvertently exposes secrets that attackers harvest systematically—AI training patterns become visible, model architectures leak information through memory access patterns, and data flow characteristics reveal everything about your competitive advantages.
Intelligence Leak: Attackers analyze this metadata systematically to reverse-engineer your competitive advantages—model architectures get exposed through memory access patterns, training methodologies become visible in gradient exchange timing, dataset characteristics leak secrets through cache behavior, and private intellectual property that represents years of research becomes visible to anyone monitoring network metadata carefully enough to extract it.
sFlow and Traditional Monitoring: The Covert Channel Problem
sFlow and traditional monitoring systems inadvertently create covert channels. These conventional tools enable sophisticated side-channel attacks that bypass traditional security completely, allowing attackers to communicate secretly using network congestion patterns while your security team watches helplessly, unable to distinguish malicious signaling from normal network optimization.
Traffic Pattern Analysis: Your AI Workload's Fingerprint
Network monitoring systems sample traffic flows to understand network behavior. They inadvertently reveal sensitive information because AI workloads have distinctive, recognizable patterns. Model training phases become visible through traffic characteristics—gradient exchange shows unique communication signatures, parameter server communications expose predictable patterns, and different model architectures create distinguishable traffic fingerprints that attackers learn to recognize with frightening accuracy.
This intelligence enables precisely targeted attacks. Attackers identify critical training phases by watching traffic patterns, then time their congestion attacks perfectly for maximum disruption. Model training becomes predictably vulnerable because network monitoring itself exposes exactly when and how to attack for maximum damage.
Telemetry Poisoning: When Your Monitoring System Lies
Advanced attackers inject poisoned telemetry that makes your network monitoring systems receive false data. Analytics platforms get deceived, and automated management tools become unwitting accomplices in attacks they should be preventing. AIOps systems that use machine learning to optimize your network instead optimize for attacker goals because they're making decisions based on fundamentally corrupted data.
Research demonstrates devastating success rates where 89.2% of carefully crafted manipulations succeed in deceiving network management systems. Attackers inject log entries that appear completely legitimate but contain subtle deceptions designed to trigger wrong decisions. Your network management systems make catastrophically bad choices, performance degrades across your entire infrastructure, and the real causes hide behind poisoned data that looks perfectly normal to every monitoring tool you run.
The Anatomy of Multi-Tenant AI Fabric Attacks
Gradient Exchange Under Fire: Targeting the Heart of Distributed Training
Distributed AI training relies absolutely on all-reduce operations. Gradient synchronization becomes the heartbeat of modern machine learning, the critical moment when hundreds or thousands of GPUs must share their learned weights and synchronize their understanding of the model they're collectively training. These operations create predictable traffic patterns that sophisticated attackers exploit with surgical precision, knowing exactly when your network will be most vulnerable and most valuable to disrupt.
Timing Attacks on Critical Training Phases
Malicious tenants launch precisely timed attacks. They monitor network traffic patterns constantly, learning to recognize the distinctive signatures of all-reduce operations as they begin. Networks flood with malicious traffic just as your critical synchronization starts, creating artificial congestion exactly when you need clear paths most desperately.
Training iteration times increase dramatically. Gradient exchanges that should take milliseconds face artificial congestion that stretches them into seconds or even minutes. Everything slows to a crawl while attackers watch your GPU utilization plummet.
Consider large language models with billions of parameters that need synchronization across hundreds of GPUs every single iteration. Each training step requires perfect coordination. Well-timed attacks during these synchronization windows destroy everything you've built—seconds become minutes, training efficiency collapses completely, and what should have been a successful overnight training run becomes a multi-day disaster that costs exponentially more while delivering exactly the same results if it converges at all.
Parameter Server Architecture Exploitation
Attackers who understand distributed training architectures target parameter servers with devastating effectiveness. They identify the high-frequency communications where parameter pulls happen constantly and gradient pushes occur continuously. Worker nodes communicate with central servers in predictable patterns. Congestion attacks create bottlenecks at these critical choke points where all communication must flow.
They strike precisely when workers need fresh parameters to continue training. Updated values become unavailable, workers sit idle burning GPU cycles without making progress, and gradient updates face delays that break the careful synchronization that distributed training absolutely requires.
Systemic Failure: This disrupts the careful balance that parameter server architectures require—parameter updates face unpredictable delays that make convergence unreliable, model training slows dramatically or fails entirely, and the efficiency advantages that made you choose this architecture in the first place evaporate completely as parameter synchronization becomes the bottleneck that throttles your entire training job regardless of how many GPUs you throw at the problem.
The Timing Side-Channel Threat: When Network Performance Reveals Secrets
AI workload timing creates side channels that leak far more information than most organizations realize or would ever willingly share with competitors. Network congestion measurements reveal architecture details with surprising accuracy. Training progress becomes visible through traffic pattern changes. Input data characteristics leak through sophisticated timing analysis that extracts secrets from seemingly innocuous performance metrics.
Model Architecture Inference Through Timing
Different neural network architectures create distinctive timing patterns that work like fingerprints. Transformer models exhibit unique timing signatures in their attention mechanisms. Convolutional networks show completely different patterns in how they process spatial data. Large language models reveal characteristic patterns in their massive all-reduce operations that expose parameter counts and layer structures with remarkable precision.
Attackers analyze these timing patterns systematically to reverse-engineer your competitive architectures. Training methodologies get exposed through how gradients flow. Optimization techniques leak information through network bandwidth patterns. Architectural innovations that represent months or years of research become visible to competitors who simply watch network timing data. Your own infrastructure generates competitive intelligence automatically, sending it across networks where attackers harvest it continuously.
Training Progress Surveillance
Network timing reveals training progress with surprising accuracy. Early training phases show distinctive patterns as models make large gradient updates while learning basic features. Late-stage fine-tuning looks completely different, with smaller updates and different synchronization characteristics. Convergence events create signature timing changes that attackers detect and analyze, learning when your model is almost ready, when you're struggling with training instability, and when you've achieved a breakthrough worth stealing.
This intelligence enables intellectual property theft and competitive espionage. Attackers know exactly when models near completion, making them prime targets for extraction. Training problems become visible to competitors who can exploit your failures. Promising approaches get identified and copied before you can even publish results or ship products.
Covert Communication: Hidden Messages in Network Congestion
Congestion control mechanisms enable covert channels. Sophisticated attackers use these to communicate secretly, bypassing monitoring systems entirely. Traditional security controls fail completely because the communication looks exactly like normal network optimization.
Congestion-Based Signaling: Messages in the Noise
Malicious tenants encode information deliberately in congestion patterns that appear completely normal to monitoring systems. PFC pause frame timing carries hidden messages between compromised systems that communicate covertly under the nose of your security team. ECN marking frequencies establish channels that traditional security tools cannot detect because they look exactly like legitimate congestion control doing its job.
These covert channels operate entirely within normal network parameters. Network congestion control mechanisms conceal the communication perfectly. Standard monitoring systems miss everything because they're designed to detect anomalies, and this communication creates no anomalies—it's perfectly normal congestion that just happens to encode attacker messages. Sophisticated attackers coordinate multi-stage attacks using these channels while your security team sees only routine network optimization happening exactly as designed.
Queue Depth Modulation: Data Hiding in Network Buffers
Sophisticated attackers control their traffic injection rates to modulate switch queue depths in predictable patterns. Covert communication channels emerge in the telemetry data itself—attackers encode messages in queue depth variations that telemetry systems observe and report faithfully while traditional security monitoring misses everything because it's not looking for communication in performance metrics.
Stealth Communication: This technique exploits the very systems you use for performance optimization—network telemetry dutifully reports queue depths to help you manage congestion, performance optimization tools consume this data to make routing decisions, but security monitoring gets completely bypassed because nobody expects attackers to hide messages in what looks like normal network buffer utilization that fluctuates naturally as workloads change.
AI Workloads: Built for Speed, Vulnerable by Design
Large Model Training: When Microseconds Matter
Modern AI training shows extreme sensitivity to network performance variations in ways that create massive vulnerabilities. Subtle attacks succeed easily. Large language models with their billions of parameters generate massive gradient traffic that becomes a single point of failure—disrupt the network, and you disrupt the entire training job regardless of how many GPUs are working on it.
Collective Communication Disruption: The Cascading Failure Effect
Large language models generate enormous communication requirements. All-reduce communications demand absolute perfection—every GPU must receive every gradient from every other GPU, synchronized perfectly. Minor congestion attacks cause disproportionate disasters. Training job failures waste everything—thousands of GPU-hours vanish instantly, millions in compute costs disappear without producing any useful results, and weeks of calendar time evaporate as you restart from the last checkpoint if you're lucky enough to have one recent enough to matter.
The problem compounds with terrifying speed. Collective communications require precise timing across hundreds or thousands of GPUs that must coordinate perfectly. Network attacks disrupt this synchronization completely. Entire training jobs don't just slow down—they collapse entirely, failing catastrophically in ways that waste every GPU-hour you invested. Organizations lose weeks of progress because attacks lasting mere minutes destroy synchronization patterns that can never be recovered, forcing complete restarts that double or triple project timelines and costs.
Memory Bandwidth Attacks: Targeting the New Attack Surface
AI workloads increasingly use CXL expansion to handle memory needs that exceed individual GPU capacity. Ever-larger models demand more resources, and CXL provides the memory bandwidth they need. But this creates entirely new attack vectors that most security teams don't even know exist—interconnect congestion can target cache-coherent traffic in ways that are almost impossible to detect or defend against using traditional network security tools.
Attackers who understand CXL memory access patterns create artificial bandwidth limitations that target model training with surgical precision. Subtle but devastating effects emerge as training jobs appear to run normally but fail to converge properly. Memory access becomes unpredictable as network attacks deliberately target coherence protocols, creating race conditions and synchronization failures that break training in ways that look exactly like model instability or hyperparameter problems rather than the network attacks they actually are.
Inference Services: The Real-Time Vulnerability
AI inference services face unique attacks. Performance-sensitive operations become prime targets. Real-time requirements create vulnerabilities that attackers exploit ruthlessly.
Latency Injection: Death by a Thousand Delays
Inference workloads need sub-millisecond response times. Precisely calibrated attacks target these stringent requirements with devastating effectiveness. Attackers inject network delay carefully—just enough to violate your SLA commitments but not enough to trigger obvious alarms that would alert your operations team to the attack.
This creates insidious attacks where degradation appears completely normal. Network variability seems natural and within expected parameters. No security incidents trigger because everything looks like routine performance fluctuations. But your inference services become gradually unreliable, SLA violations accumulate, customers complain about slow responses, and the real root causes hide behind network manipulation that's invisible to traditional monitoring.
Batch Processing Disruption: Timing Attacks on Throughput
Sophisticated attackers study your inference batch processing patterns carefully. Optimal attack windows emerge as they learn when you process batches. Congestion attacks coincide perfectly with these processing windows. Batch processing throughput faces maximum impact as attackers time their network disruption to hit exactly when you need clear paths most desperately.
Trade-off Exploitation: These attacks target the fundamental trade-offs that every inference system faces—latency battles throughput constantly, and modern architectures carefully balance both to maximize efficiency. Batch processing disruption destroys this delicate balance completely. Inference throughput drops by orders of magnitude while minor congestion that looks completely normal to monitoring systems conceals the attack that's destroying your service quality.
Building Defenses That Actually Work
Authenticated Telemetry: Securing Your Network's Nervous System
SecPro-INT: Dynamic Security That Adapts to Performance Needs
SecPro-INT and similar frameworks provide dynamic encryption switching that adapts intelligently to current network conditions. Systems balance security with performance needs automatically using "security level plus performance loss" feedback mechanisms that adjust protection strength in real-time based on what your workloads actually need right now rather than applying rigid security policies that ignore operational realities.
Network conditions determine security levels dynamically. Maximum protection gets applied when network utilization is low and you can afford the overhead. High-performance periods when your AI workloads need every microsecond demand intelligent compromises where systems scale back to lightweight authentication that maintains security without disrupting critical training operations. This adaptive approach recognizes a fundamental truth: AI fabric security cannot use the same rigid models that work for traditional enterprise networks because the performance requirements are simply too demanding and the costs of security overhead too high.
Blockchain-Based Telemetry Protection: Distributed Trust for Network Data
SINT architecture uses blockchain consensus mechanisms. Secure INT prevents arbitrary access to telemetry data and resists malicious modifications through lightweight consensus protocols that protect telemetry integrity. The system achieves remarkable results: 97% bandwidth utilization while maintaining security through distributed validation that prevents any single compromised node from poisoning your entire monitoring infrastructure.
Multiple nodes must agree before telemetry data gets accepted as valid. Network management systems wait for consensus, preventing single points of failure where one compromised switch could inject false data that deceives your entire management infrastructure. Telemetry security becomes distributed rather than centralized. Real-time performance characteristics persist even with consensus overhead because lightweight protocols keep latency minimal. AI workloads get the performance they require while distributed validation creates audit trails that make forensic analysis possible after attacks, helping you understand what happened and prevent recurrence.
Advanced Congestion Control: Fighting Fire with Intelligence
AI-Enhanced Congestion Detection: Teaching Networks to Recognize Attacks
Machine learning models learn the legitimate traffic patterns of your specific AI workloads. AI workload signatures become recognizable through training on normal operations. Anomalous congestion gets identified with remarkable accuracy as systems learn to distinguish normal traffic bursts from malicious attacks. Distributed training creates predictable, recognizable traffic patterns. Malicious attacks look fundamentally different when you know what normal looks like.
Models learn the distinctive signatures that permeate every aspect of legitimate AI communication. All-reduce operations show characteristic patterns in timing and volume. Parameter server requests become predictable in frequency and size. Large model training has unmistakable characteristics in how gradients flow. Memory access patterns reveal themselves through traffic timing that machine learning models recognize instantly, detecting deviations that signal potential attacks.
Detection Success: Congestion pattern deviations trigger automated responses within seconds rather than the minutes or hours that human operators would need, completely bypassing the delays that make attacks succeed. Performance degradation becomes detectable instantly, allowing your systems to isolate attacks before they cause catastrophic damage to training jobs or inference services.
QoS Isolation: Building Walls Between Tenants
Tenant isolation uses dedicated queues and strict Quality of Service boundaries. Cross-tenant attacks face effective prevention through dedicated resources. Cisco's AI/ML network fabric blueprint explicitly recommends complete traffic segregation where each tenant gets isolated queues, per-tenant buffer allocation prevents resource stealing, and ECN marking policies remain completely independent so one tenant's congestion cannot trigger throttling in another tenant's flows.
This approach recognizes that traditional network sharing models break down completely in multi-tenant AI environments. Each tenant gets guaranteed resources that malicious neighbors cannot consume or disrupt regardless of how aggressively they attack. Network efficiency decreases somewhat because you're not sharing resources optimally. But performance predictability increases dramatically, and AI workloads require reliable operation far more than they need marginal efficiency improvements that come at the cost of vulnerability to neighbor attacks.
Rate Limiting and Real-Time Detection: Stopping Attacks Before They Succeed
Intelligent Rate Limiting: Beyond Simple Traffic Shaping
Token Bucket approaches provide basic protection against traffic bursts. Sliding Window techniques add sophisticated burst tolerance that accommodates legitimate AI traffic patterns. Congestion attacks face intelligent resistance from systems that adapt dynamically to expected AI burst characteristics. Normal traffic patterns guide responses—legitimate flows get accommodation while malicious patterns face aggressive blocking.
The key insight involves understanding and leveraging predictability. Legitimate AI workloads exhibit recognizable burst patterns during specific training phases. Gradient synchronization shows characteristic traffic spikes. These bursts become completely predictable once you understand your workloads. Intelligent rate limiters learn these patterns and distinguish them from malicious traffic that looks fundamentally different because attackers don't follow the rhythms of legitimate training. Pattern mismatches trigger immediate throttling that protects other tenants while legitimate bursts flow freely because the system recognizes them as expected behavior.
Real-Time Anomaly Detection: Seconds Matter in AI Fabric Defense
Network anomaly detection systems get optimized specifically for AI traffic patterns. Attacks face identification within 30 seconds while false positive rates stay below 5% through careful tuning. Statistical methods combine with machine learning algorithms that distinguish normal workload variations from deliberate attacks with impressive accuracy because they understand what legitimate AI traffic actually looks like.
Systems monitor multiple metrics simultaneously to build complete attack pictures. Traffic volume gets measured across all tenant boundaries. Timing patterns reveal signatures of known attack types. Queue depths expose deliberate congestion attempts. Multiple correlated signals indicate coordinated attacks. Telemetry data integrity gets verified constantly. When multiple independent indicators simultaneously suggest problems, automated responses immediately isolate malicious tenants in quarantine while protecting legitimate workloads from collateral damage.
The Hard Truths: Security Model Limitations and Evolving Challenges
The Speed vs. Security Paradox
Current security models face fundamental scalability challenges. AI fabrics evolve relentlessly toward higher speeds—400G Ethernet becomes standard today, 800G approaches rapidly, and networks get faster constantly. But security becomes proportionally harder. Performance sacrifices appear increasingly inevitable as encryption overhead remains relatively constant while line rates double, making security consume ever-larger percentages of your available network capacity.
Hardware Acceleration: When Software Security Isn't Fast Enough
MACsec on 400G links demands hardware acceleration. Specialized ASICs become absolutely essential because microsecond-level latency bounds matter tremendously. AI workloads cannot tolerate the delays that software encryption introduces. Standard software approaches fail completely—security introduces too much latency, real-time operations become impossible, and training jobs that need consistent network performance suffer from the jitter and variability that software processing creates.
This creates problematic hardware dependencies. Specialized equipment costs substantial money that not all organizations can afford. Quick deployment becomes challenging when you need custom hardware. Security versus performance trade-offs intensify as higher network speeds force increasingly difficult decisions. AI workloads face security overhead that becomes harder to accept as it consumes larger percentages of the network capacity you paid enormous amounts of money to provision.
Quantum-Safe Evolution: Preparing for the Post-Quantum Future
Post-quantum cryptography introduces massive complexity. High-speed AI fabrics face new requirements as quantum computers threaten current encryption. Current security models fail entirely against quantum attacks. Performance impacts seem inevitable as quantum-resistant algorithms require significantly more computation. Organizations must plan ahead for this transition. Quantum-resistant security becomes essential for long-term data protection. But network performance absolutely cannot suffer when you're paying thousands of dollars per hour for GPU time.
Implementation Challenge: The challenge involves implementation timing that creates an impossible dilemma—quantum-safe algorithms need to run at full line rates to avoid becoming bottlenecks, but specialized hardware capable of this doesn't exist yet in commercial form. Current quantum-resistant algorithms introduce substantial latency and computational overhead that appear significant enough to make them practically unsuitable for real-time AI applications that demand microsecond-level network response times.
Cross-Domain Attacks: When Security Boundaries Break Down
Multi-Layer Attack Scenarios: Complexity Beyond Single-Vector Threats
Modern sophisticated attacks combine multiple techniques simultaneously. Telemetry poisoning meets deliberate congestion manipulation in compound attacks. Vulnerabilities compound across categories as poisoned telemetry masks ongoing congestion attacks from detection systems. Congestion manipulation amplifies telemetry injection success by creating confusion that helps false data slip through validation. Cross-category vulnerabilities emerge that existing point defenses fail to address completely.
Traditional layered security models break down against these coordinated attacks. Attack scenarios become sufficiently complex that individual defenses fail. Compromised telemetry systems actively hide congestion attacks from the detection systems that should spot them. Detection algorithms get systematically deceived by false data. Successful congestion attacks create network conditions that make telemetry poisoning more effective because the chaos provides cover. Defenders face attack surfaces that traditional security models never anticipated.
Emerging Interconnect Challenges: Beyond Traditional Networking
CXL and NVLink create entirely new security challenges. Cache-coherent memory interconnects face threats that traditional network security tools cannot address. Sophisticated timing attacks emerge that exploit memory coherence protocols. Network security tools completely miss these attacks because they operate at memory system layers that network monitoring doesn't reach or even see.
New attack vectors appear constantly as these interconnects become standard. Cache-coherent memory access patterns seem completely normal to network tools but leak tremendously sensitive information to attackers who understand what they're seeing. Model parameters get exposed through cache line transfer patterns. Training data becomes visible through memory access timing. Competitive intellectual property leaks through side channels that traditional monitoring doesn't extend far enough to protect because memory coherence protocols remain completely unprotected by network security tools designed for traditional packet-based communication.
The Future of AI Fabric Security: Research Directions That Matter
Zero-Trust AI Fabric Architecture: Trusting Nothing, Verifying Everything
Comprehensive zero-trust models require fundamental changes. AI fabrics need continuous verification of all network participants at all times. Traditional perimeter security fails completely in multi-tenant environments where threats come from inside. Dynamic policy adjustment becomes essential, driven by current workload characteristics. Both security and performance matter intensely, requiring constant balancing based on real-time conditions.
This means treating everything with constant suspicion. Every single network participant faces potential compromise at any moment. Continuous authentication becomes mandatory rather than optional. Authorization requires constant validation and reverification. Network resource access needs proof every single time rather than trusting credentials issued hours or days ago. AI workloads demand predictable performance, but they must prove their legitimacy continuously because initial authentication fails quickly when attackers compromise systems after legitimate login, making traditional authentication-at-connection-time completely insufficient for the threats AI fabrics actually face.
AI-Driven Defense Evolution: Networks That Fight Back
Self-healing networks represent the next evolution. AI-powered anomaly detection drives continuous progress as systems learn from every attack. Real-time threat identification becomes standard practice. Automated response systems act instantly without human intervention. False positives need aggressive minimization because disrupting legitimate AI training jobs costs enormous amounts of money. Attacks must stop quickly before they cause catastrophic damage to training jobs representing thousands of dollars per hour in compute costs.
Systems learn continuously from every attack attempt. Future detection improves based on past experiences. Response capabilities adapt constantly to new attack variants. Defense strategies evolve naturally as attackers change techniques. Attack methods change rapidly as attackers discover new vulnerabilities. Network performance characteristics must persist through all of this because AI workloads cannot sacrifice speed for security—they require both simultaneously to maintain the competitive advantages they provide.
Secure-by-Design Interconnects: Building Security Into Silicon
Future interconnect standards need fundamental changes. Hardware-level security must become built-in rather than bolted-on. Ground-up incorporation matters most—security cannot be an afterthought added to existing protocols. Authenticated congestion signaling becomes required in hardware. Encrypted telemetry channels become standard features. Tamper-resistant buffer management gets implemented in silicon rather than software.
Future Vision: This represents a fundamental shift in how we build networks—software-based security that adds overhead gives way to hardware-enforced mechanisms built directly into interconnect silicon. Network line rates remain fully achievable because security operations run in dedicated hardware at wire speed. Performance penalties disappear completely as security becomes integral to interconnect operation itself rather than something added on top. Security overhead balancing becomes completely unnecessary when protection is free from a performance perspective.
The Bottom Line: Your AI Fabric Security Action Plan
Security challenges represent the critical intersection where shared AI fabrics meet high-performance networking and cybersecurity collides with operational reality. Immediate attention becomes absolutely essential because every organization deploying AI infrastructure faces these risks whether they know it or not. AI workloads become central competitive advantages that attackers target specifically. Congestion control exploitation threatens everything you've built. Telemetry mechanisms create dangers most security teams never anticipate. Operational performance suffers catastrophically. Intellectual property faces continuous exposure.
Cross-category vulnerabilities create compound risks that multiply faster than linear defenses can address. Traditional security approaches fail completely against coordinated attacks. Telemetry data leaks amplify congestion-based attacks by providing intelligence. Congestion-based threats get magnified when attackers poison the telemetry systems that should detect them. Even defensive measures can inadvertently create new attack surfaces when implemented poorly. You need holistic approaches that address the entire attack ecosystem rather than isolated point solutions. Traditional protection models prove utterly inadequate against adversaries who understand how these systems actually work.
Immediate Action Items
Your organization needs immediate action across multiple fronts:
- Multi-layered defense strategies become essential immediately - Combine authenticated telemetry with real-time anomaly detection, tenant isolation, and intelligent rate limiting that work together rather than in isolation
- Intelligent anomaly detection capabilities matter most - Add robust tenant isolation that prevents cross-tenant attacks regardless of what vulnerabilities exist in other defenses
- Hardware-accelerated security helps maintain performance - Requirements demand careful balancing between security overhead and the operational needs of workloads that cannot tolerate latency
- Trade-offs persist unavoidably in modern fabrics - Performance battles security constantly, requiring intelligent dynamic policies rather than rigid rules that optimize for the wrong scenarios
- Attack techniques evolve with terrifying speed - Continuous monitoring and rapid adaptation become required capabilities rather than nice-to-have features
Understanding the Stakes
The stakes grow constantly as AI becomes more central to business value. Case studies document devastating coordinated campaigns where attack damages regularly exceed $100,000 in lost compute time alone, not counting the business impact of missed deadlines. Training jobs fail catastrophically after consuming days of GPU time without producing any useful results. Organizations lose weeks of calendar progress as attacks destroy synchronization. Minutes of well-timed attacks destroy months of patient work. Intellectual property becomes visible to competitors through network timing analysis that extracts secrets most security teams never even monitor because they don't realize this data leaks sensitive information.
Critical Reality: Your fabric faces critical exposure right now whether you realize it or not—security equals the strength of your weakest protocol, and most fabrics have protocols that were never designed with security in mind. The time to act is now, before attackers target the optimization systems that make your infrastructure fast and turn those same performance advantages into weapons that destroy your competitive position.
Long-Term Strategic Investment
Continued research becomes urgent now. Secure-by-design architectures need optimization specifically for AI workload requirements. AI infrastructure demands integrated security solutions that understand the unique characteristics of machine learning traffic. Proactive security must span all network layers simultaneously. Hardware-level protections need to emerge in next-generation interconnects. Application-aware policies must understand the specific requirements of different workload types—AI training has fundamentally different characteristics than inference workloads, and both demand tailored protection strategies.
Organizations that invest comprehensively in AI fabric security today will maintain competitive advantages tomorrow while those who ignore these threats will face catastrophic failures, intellectual property theft that destroys their market position, and operational disruption severe enough to destroy months or even years of AI development progress in attacks that last mere minutes but create damage that persists for quarters.
The choice is clear: secure your AI fabric now with comprehensive, intelligent defenses, or watch helplessly as attackers weaponize your own infrastructure against you, turning your performance advantages into vulnerabilities that benefit competitors while destroying your ability to compete.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score