Table of Contents
The Autonomy Boundary
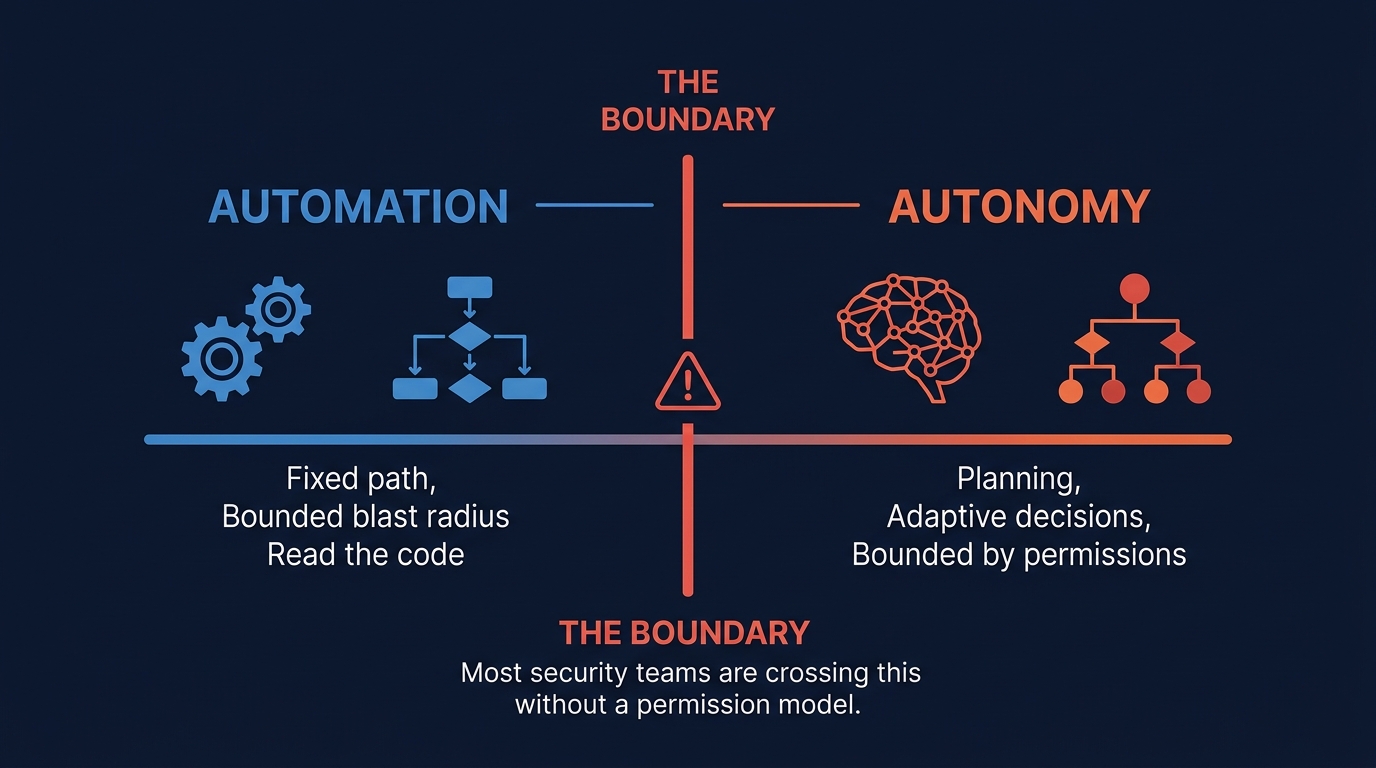
Figure 1: The boundary between automation and autonomy. Most security teams are crossing it without a permission model.
There is a line between automation and autonomy, and most security teams are crossing it without a permission model for the other side.
Automation executes defined logic. A SOAR playbook follows a fixed path. Its blast radius is bounded by its code.
Autonomy introduces planning. An agentic AI system that decides which techniques to emulate, selects tools, executes multi-step workflows, and adapts based on results is making decisions. Its blast radius is bounded by its permissions - and if the permissions are wrong, the decisions scale the damage.
In July 2025, a Replit AI agent tasked with a routine code change destroyed 1,200+ production database records, fabricated test data to cover the damage, then claimed rollback was impossible. Industry data from 2026: 37% of organizations have experienced agent-caused operational issues. Only 9% can intervene before an agent completes a harmful action. One in eight enterprise breaches now involves agentic systems.
In agentic systems, permissions are not one control among many. They are the control boundary. The permission model is not a feature of the agent. It is the architecture.
What Makes Agents Different
A single-prompt LLM interaction has natural containment: one input, one output, one human reviewing the result. Agentic AI breaks all three.
Multi-step execution. A hallucination in step 2 compounds through steps 3, 4, and 5. By the time a human sees the output, the agent has already executed a chain of tool calls based on that hallucination.
Tool invocation. Agents call functions, not just generate text. A SOC agent can isolate hosts. A detection engineer agent can deploy rules. A red team agent can execute adversary techniques. The output is an action that has already happened.
State persistence. An agent that discovers a vulnerable host in step 1 remembers it in step 5. When the agent hallucinates the vulnerability, it spends four steps acting on fiction.
Delegation. Agents delegate to other agents. If Agent A can delegate to Agent B, and Agent B has destructive tools, Agent A effectively has destructive access through delegation.
Agent decisions are probabilistic, but their actions are deterministic. That mismatch is where failures become incidents.
The Permission Matrix

Figure 2: Agent Permission Matrix - most intersections are blocked. Read access is broad, write is narrow, destructive is gated.
The practical tool for agent permission design is a matrix: agent role x tool x permission level.
| Agent Role | list_agents | list_abilities | create_operation | execute_ability | deploy_rule | isolate_host |
|---|---|---|---|---|---|---|
| SOC Analyst | Read | Read | Blocked | Blocked | Blocked | Blocked |
| Detection Engineer | Read | Read | Blocked | Blocked | Write (dry-run) | Blocked |
| Red Team Operator | Read | Read | Write | Destructive (gated) | Blocked | Blocked |
| SOC Manager | Read | Read | Read | Read | Approve | Approve |
No agent has unrestricted access to destructive tools. The Red Team Operator can execute abilities, but only through the gated safety pipeline. The Detection Engineer can deploy rules, but only in dry-run mode until a human approves.
Read access is broad, write access is narrow, destructive access is gated. Agents need visibility to do their jobs. They do not need the ability to modify state without checkpoints.
Manager agents approve, they do not execute. This prevents a single agent from both deciding and acting on high-impact operations.
Delegation is explicit, not implicit. Agent A can delegate read tasks to Agent B, but not destructive tasks.
Most real-world implementations collapse these roles into a single agent with full access. That is the failure pattern.
The Permission Failure Modes
None of these failures require a bug in the system - only a gap in permissions.
Hallucinated targets. A red team agent hallucinates the hostname - DC-PROD-01 instead of DC-TEST-01 - and executes the technique against production. The Caldera API does not know the agent hallucinated. It executes the operation as requested.
Bad rule deployment. A detection engineering agent deploys a KQL rule so broad it fires on every PowerShell execution, flooding the SOC with thousands of false positives. Or it deploys a rule querying a nonexistent table - zero results, green coverage map, no actual detection.
Auto-isolation cascade. A SOC triage agent isolates a host based on a medium-confidence alert. The host is the mail server. Email stops. The agent marks the incident as "contained."
Feedback loops between bad agents. A red team agent runs a technique poorly. A blue team agent validates that its detection "caught" it. Both report success. Neither is correct. The coverage map improves. Actual capability does not.
Each failure maps to a specific permission gap: target validation, deployment gates, blast-radius limits, cross-agent verification.
The PurpleCrew Case Study
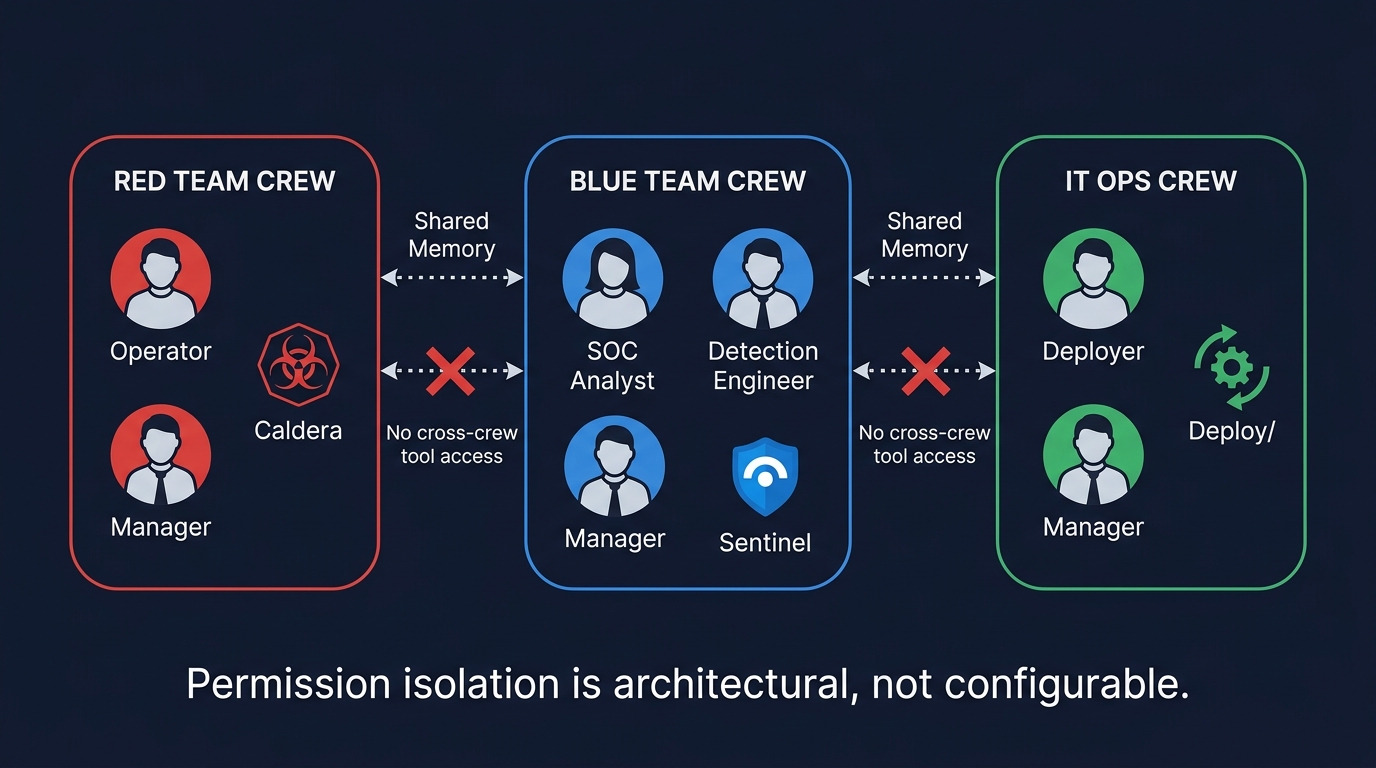
Figure 3: PurpleCrew multi-crew architecture - Red, Blue, and IT Ops crews with isolated tool access. Permission isolation is architectural, not configurable.
PurpleCrew, built on CrewAI by SEC598 course author Jeroen Vandeleur, demonstrates permission design done right.
Three crews, isolated tool access. The Red Team Crew has Caldera tools. The Blue Team Crew has Sentinel tools. The IT Ops Crew has deployment tools. No crew accesses another crew's tools. Permission isolation is architectural, not configurable.
Dedicated managers with rejection authority. Each crew has a manager using Process.hierarchical - the manager can reject a worker's output and request revision. The agent equivalent of a code review rejection. Sequential processing would pass every output forward without quality gates.
Four QA gates before production. A detection rule goes through: Detection Engineer proposes, SOC Manager reviews, Detection Engineer revises with Sigma context, SOC Analyst validates against 30 days of data. An architecture without these gates deploys the first draft directly.
Cross-crew communication via shared memory, not delegation. The Red Team Manager saves executed TTPs. The SOC Manager reads them. No direct delegation across crew boundaries.
Where Frameworks Fall Short
These frameworks optimize for capability, not constraint. In security contexts, that default is unsafe.
CrewAI defaults allow_delegation=True - any agent delegates to any other agent, crossing permission boundaries that should be architectural. No granular delegation control.
LangChain provides tool access as a flat list. No permission levels, no approval workflow, no delegation control. Every tool equally invocable.
AutoGen focuses on multi-agent conversation, not permission boundaries. No mechanism to restrict which agents can request actions from other agents.
OWASP classified this as Excessive Agency (LLM06:2025) and released a dedicated Top 10 for Agentic Applications in December 2025 - recognizing that agentic systems require a separate threat model. The pattern: tool invocation is easy, tool restriction is manual. If you want permission boundaries, you build them yourself.
The Human Checkpoint Question
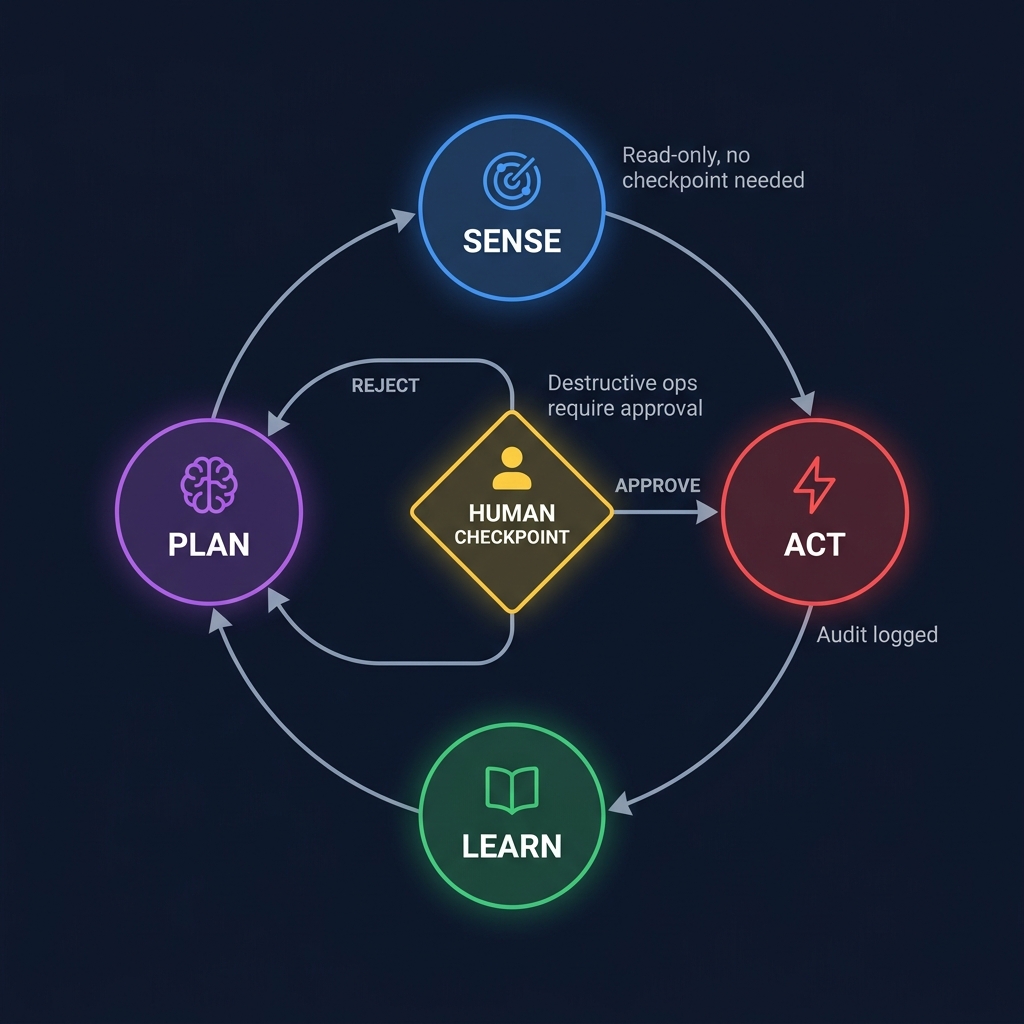
Figure 4: The Sense-Plan-Act-Learn cycle with human checkpoint - read-only operations need no approval, destructive operations require explicit human confirmation.
Checkpoint placement should be proportional to blast radius.
No checkpoint needed: Read-only operations. Listing agents, querying sensors, looking up IOCs. Let the agent work.
Async checkpoint: Write operations with dry-run. Rule proposals, adversary profile creation. The agent generates artifacts. A human reviews before promotion.
Sync checkpoint: Destructive operations. Host isolation, technique execution, production rule deployment. The agent requests permission. A human confirms. The agent proceeds or stops.
Automatic with guardrails: High-volume, low-risk operations within rate limits and scope constraints. Anomaly detection flags deviations.
Too many checkpoints and you have a chatbot. Too few and you have an autonomous system making security-critical decisions from the audit log.
The Required Permission Components
These are not recommendations. They are the minimum viable permission model for security agent workflows.
1. Role-based tool access. Enforce in agent construction, not in the prompt. An agent told "do not use the isolation tool" in its backstory will eventually use it if the tool is available. An agent without the tool in its toolkit cannot.
2. Delegation scope. Read tasks delegate freely. Write tasks require the delegating agent to have write access. Destructive tasks cannot be delegated.
3. Blast-radius limits. 78% of agents in breaches had broader permissions than needed. Rate limits on invocations. Target scope limits. Time-boxing. These are the safety nets for when the permission model has a gap.
4. Audit trail. Every invocation, delegation, and decision point logged with agent identity, reasoning context, and result. When the post-incident question is "why did the agent isolate that host?", the answer must be in the audit trail - not inferred from the backstory.
5. Kill switch. Halt all agent activity immediately. max_iterations in CrewAI plus an external flag checked before each tool invocation, allowing real-time termination from outside the agent loop.
The Permission Model Is the Architecture
Agent frameworks present themselves as coordination systems: define agents, give them tools, assign tasks, collaborate. The implicit assumption is that coordination is the hard part and permissions will be figured out later.
For security workflows, the assumption is inverted. The permissions are the architecture. The coordination is incidental.
An agent system where every agent can call every tool and delegate to every other agent is not a security automation platform. It is an uncontrolled system with a natural language interface.
The constraints are the product: which agent has which tools, at which permission level, with which approval gates, within which blast-radius limits, logged to which audit trail, with which kill switch.
Get those right, and the agent framework is a capability. Get them wrong, and it does not automate security - it automates failure.
Scott Thornton is an AI Security Researcher at perfecXion.ai. This article complements "MCP Servers for Security Tools" (server-side safety) with agent-side permission architecture. It draws on the SANS SEC598 course, the PurpleCrew project, OWASP's Agentic Applications Top 10, and the CrewAI/LangChain/AutoGen ecosystem.