Production AI That Actually Works: A Security-First Deployment Guide
Who This Guide Is For
You work with machine learning. You need to put systems into real-world use. This guide helps you do exactly that.
ML engineers taking models from research to production will find the infrastructure patterns they need. Data scientists wanting to understand secure operations get the security fundamentals that protect their work. DevOps and MLOps experts focused on AI infrastructure discover the deployment strategies that scale reliably under real-world conditions.
You should know the basics: machine learning concepts, API architecture, and containerization fundamentals. If you've trained a model and wondered how to deploy it securely at scale while preventing attacks that could poison your data or steal your intellectual property, you're in the right place.
Production Security Essential
Deploy AI/ML models without proper security controls and you expose your organization to model theft, data poisoning, and adversarial attacks that can compromise your entire system.
Part I: Building ML Infrastructure That Doesn't Break
Your ML model gets 95% accuracy. Great work! Now deploy it to production. Make it handle 10,000 requests per second. Keep it running 24/7 without failures. Secure it against sophisticated attacks.
Welcome to reality.
Research notebooks don't prepare you for this. Production demands different skills entirely. This guide bridges that gap, showing you how to build ML infrastructure that survives contact with the real world through APIs that handle massive traffic spikes without crashing, containers that scale horizontally across clusters while maintaining consistent performance, and security controls that stop attackers from poisoning your training data or stealing your model's intellectual property.
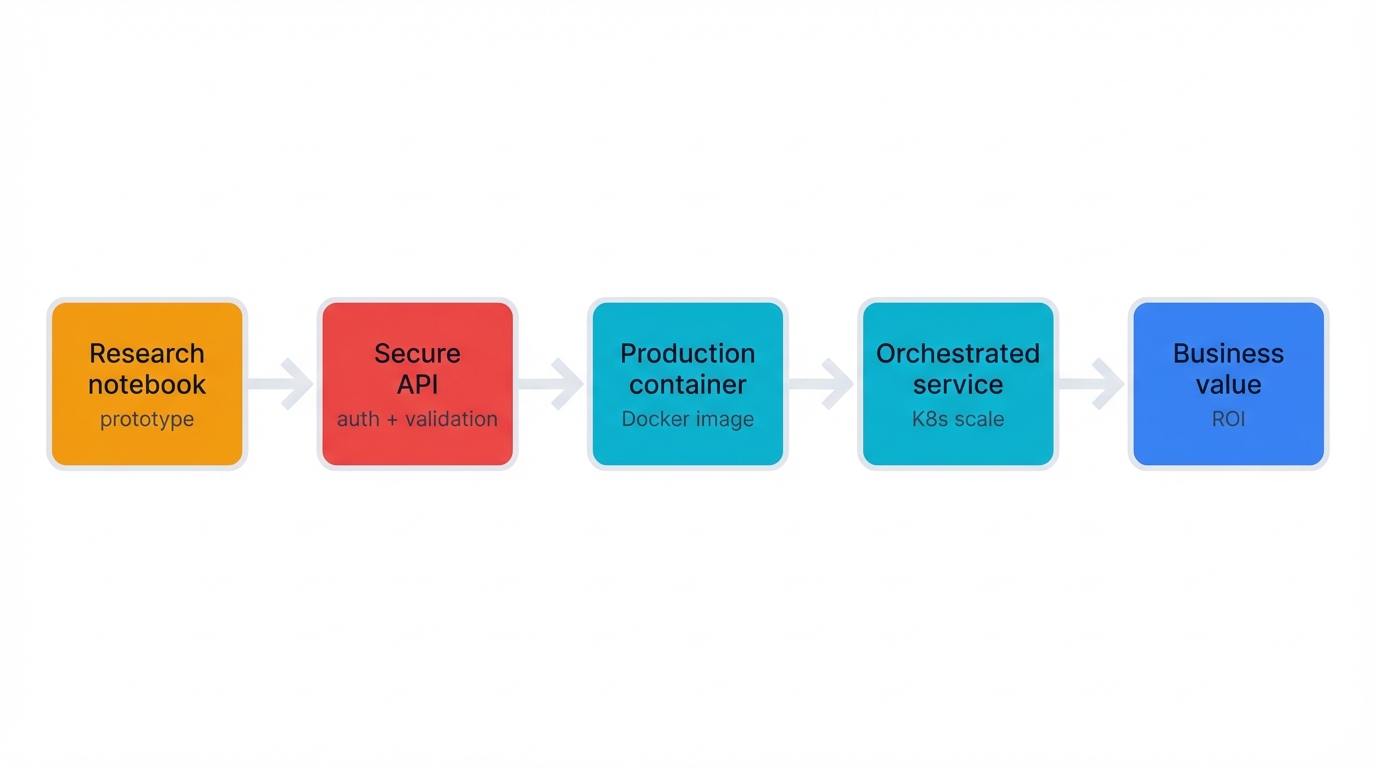
The Journey: Research notebook → Secure API → Production container → Orchestrated service → Business value
Section 1: APIs That Don't Die Under Load
Your ML model needs to talk to the rest of your application stack. APIs become the universal translator.
They let your fraud detection model integrate seamlessly with your payment system. Your recommendation engine feeds your website with personalized suggestions. Your chatbot serves customer requests in real-time. This integration makes ML valuable to your business.
But here's the reality check that catches most teams unprepared: a research demo API handling 10 requests per minute bears absolutely no resemblance to a production API processing 10,000 requests per second while maintaining sub-100ms latency, gracefully degrading under extreme load, and recovering automatically from transient failures.
The API Reality Check: Can your system handle Black Friday traffic spikes? What happens when the database slows down? How do you update models without downtime? Who gets to call your API, and how do you verify them?
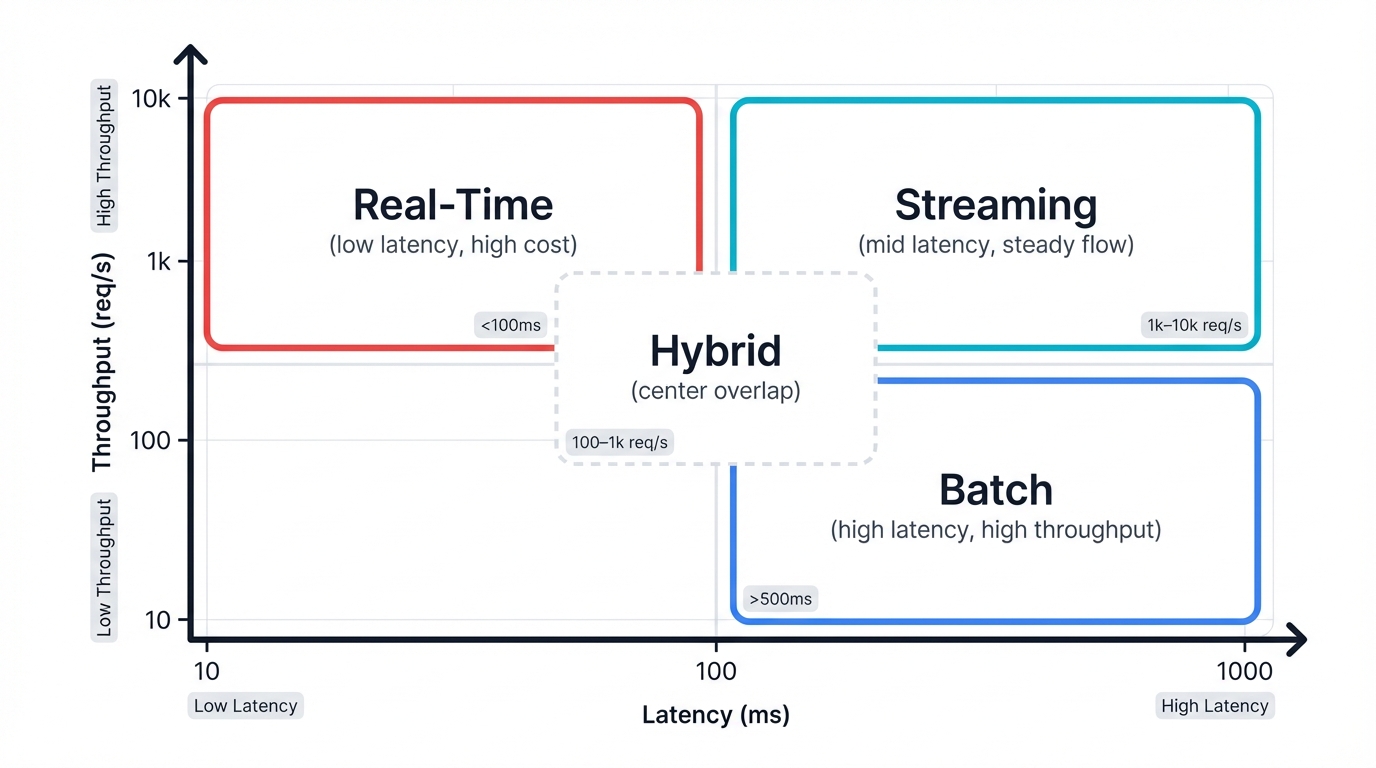
1.1 Choose Your Fighter: Real-Time vs Batch Processing
Your architecture depends on one question. How fast do you need answers?
Real-Time (Online) Inference: "I Need Answers Now"
- Use when: Fraud detection blocks suspicious transactions instantly. Recommendation engines personalize content as users browse. Dynamic pricing adjusts to market conditions in real-time.
- Requirements: Sub-100ms latency keeps users happy. 99.9% uptime prevents revenue loss. Traffic spike handling stops Black Friday from crashing your system.
- Architecture: Always-on API endpoints using REST or gRPC protocols.
- Trade-offs: Higher infrastructure costs. More complex monitoring. Demanding operational requirements.
User clicks "Buy" → API call → Fraud model → 50ms later → "Transaction approved"Batch (Offline) Inference: "I Can Wait for Better Results"
- Use when: Daily reports summarize yesterday's activity. Lead scoring ranks prospects overnight. Risk analysis processes historical data. Large-scale predictions run during off-peak hours.
- Requirements: High throughput processes millions of records efficiently. Cost efficiency matters more than speed. Results can wait hours or even days.
- Architecture: Scheduled jobs run on cron. Data pipelines process records in batches.
- Trade-offs: Lower costs make CFOs happy. Simpler infrastructure reduces operational burden. No instant results mean some use cases don't work.
Nightly job: Process 1M customers → Risk scores → Update database by morningThe Hybrid Approach:
Smart teams run both patterns. Real-time for urgent decisions. Batch for everything else.
Your fraud model might score transactions in real-time during checkout, blocking suspicious purchases instantly while protecting legitimate customers. Meanwhile, the same system batch-processes historical transactions overnight, identifying subtle patterns that inform tomorrow's real-time detection rules and creating a continuous improvement cycle that makes your fraud detection smarter every day.
Streaming (The Middle Ground):
Process continuous data streams. Get near-real-time results. Think real-time analytics dashboards showing live traffic or monitoring systems detecting anomalies as they happen.
1.2 Framework Face-Off: FastAPI vs Flask (Spoiler: FastAPI Wins)
Every Python ML team faces this choice. Flask or FastAPI? Here's the honest comparison.
Flask: The Old Reliable
- Pros:
- Gentle learning curve gets you started fast.
- Perfect for prototypes and MVPs where speed matters most.
- Huge community means answers exist for every problem.
- Complete control over your stack without opinionated frameworks forcing decisions.
- Cons:
- Synchronous by default. One request at a time. Concurrency becomes your nightmare.
- Manual data validation creates bugs and security holes that bite you in production.
- No automatic documentation means your API docs rot while your code evolves.
- Performance bottlenecks appear when I/O operations like database calls block everything.
When Flask Makes Sense: Quick prototypes. Simple internal tools. Legacy codebases. Development speed beats production scalability. Complete stack control matters more than built-in features.
The Flask Problem:
Your ML API fetches user features from a database before making predictions. Flask blocks on each database call. Result? Your API handles only a handful of requests per second while your infrastructure bills climb and users complain about slow response times.
FastAPI: The Production Champion
🚀 Blazing Performance
Built on async/await from day one. Handles thousands of concurrent requests. Flask struggles with dozens.
Your ML API can fetch features from databases, call external services, and make predictions simultaneously without blocking, creating a pipeline where multiple stages process in parallel and dramatically reducing total latency for complex prediction workflows that require data from multiple sources.
🛡️ Bulletproof Data Validation
Type hints plus Pydantic equals automatic request validation. Magic.
Send malformed data? FastAPI catches it before it reaches your model. No more midnight pages because someone sent a string instead of a number, or because a required field went missing, or because an attacker tried to inject malicious data through poorly validated inputs.
from pydantic import BaseModel
from typing import List
class PredictionRequest(BaseModel):
user_id: int
features: List[float]
# FastAPI automatically validates:
# - user_id is actually an integer
# - features is a list of numbers
# - all required fields are present📚 Documentation That Actually Exists
FastAPI generates interactive API docs automatically. No outdated wiki pages. No manual maintenance.
Your API documentation updates itself when you change the code, creating a single source of truth that developers can trust and explore interactively through the built-in Swagger UI and ReDoc interfaces that let them test endpoints without writing a single line of client code.
🔒 Security That's Actually Usable
Built-in OAuth2. JWT tokens. API keys. Secure your ML endpoints without becoming a security expert.
When FastAPI Is The Right Choice:
Production ML APIs win with FastAPI. Need to handle real traffic? FastAPI delivers. Want reliability under load? FastAPI provides it. Require security without complexity? FastAPI builds it in.
Its async architecture handles concurrency naturally, processing thousands of requests while Flask chokes on dozens. Built-in validation catches malformed data before it corrupts your models or creates security vulnerabilities. Automatic documentation stays synchronized with your code, eliminating the integration failures that plague teams relying on manually maintained API specs that drift out of sync with reality.
The Verdict: FastAPI for Production ML
Flask teaches you web APIs. FastAPI builds production systems. For ML services that need speed, security, and reliability, FastAPI wins every time.
The Security Angle:
FastAPI's automatic validation isn't just convenient—it's security armor. Model input attacks start with malformed data. Data poisoning exploits weak validation. Injection vulnerabilities target unvalidated inputs. FastAPI blocks these attacks at the API boundary, before they reach your vulnerable model inference code.
Why This Choice Matters Beyond Speed
Framework choice shapes your entire development culture. FastAPI forces good practices. Flask allows bad ones.
The framework requires you to define data schemas upfront, catching type bugs during development instead of production outages. Input validation happens automatically based on type hints, preventing security issues that arise when malformed data reaches your models and exploits weaknesses you didn't know existed. Documentation generation occurs by default every time you update code, eliminating integration problems caused by outdated API specs that promise one behavior while delivering another. Async operation patterns become natural when the framework embraces them from the start, creating systems that scale better under real-world load without requiring you to rewrite everything when traffic grows beyond your initial assumptions.
Flask gives you freedom. Freedom to make mistakes. FastAPI makes mistakes harder.
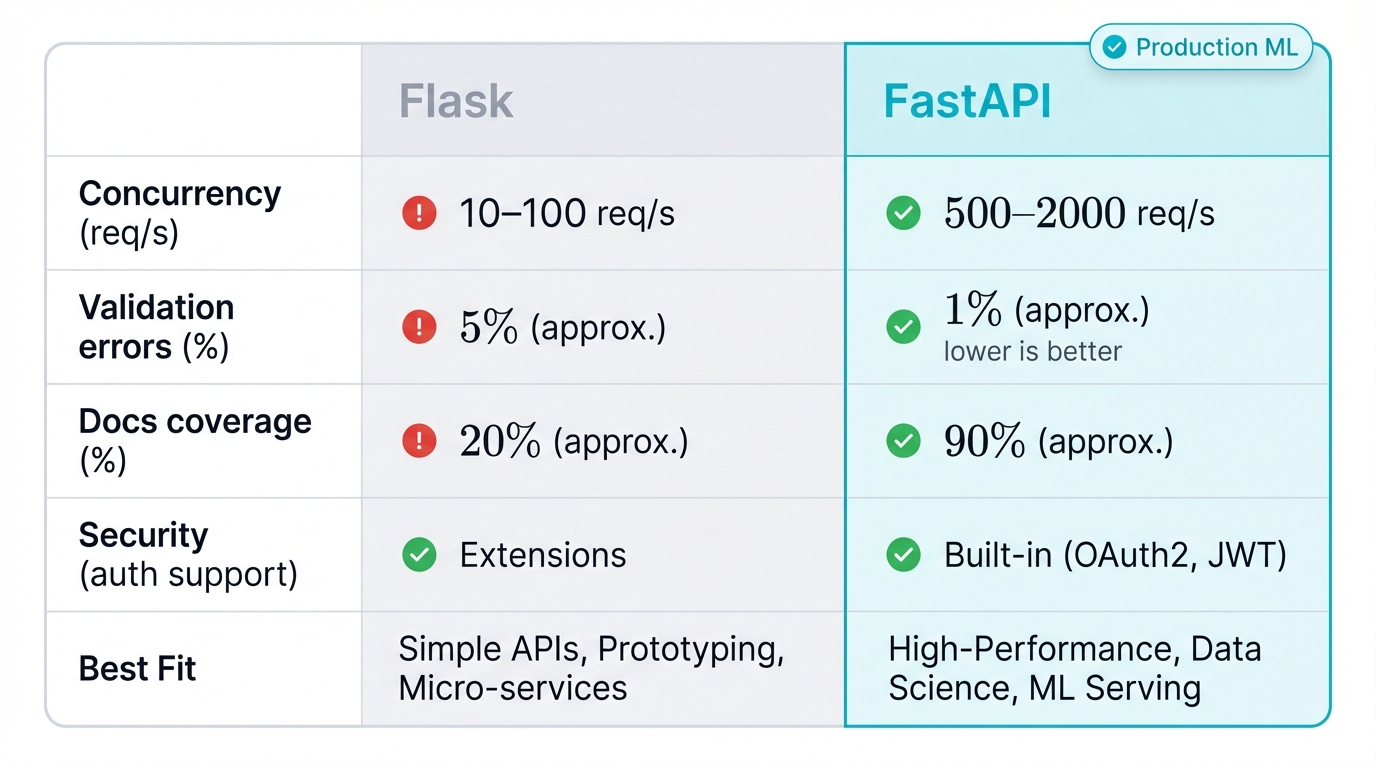
| Framework Battle | Flask | FastAPI | Why It Matters for ML |
|---|---|---|---|
| Performance | One request at a time (WSGI) | Thousands of concurrent requests (ASGI) | Your fraud detection API fetches user data while scoring transactions. FastAPI does both simultaneously. Flask blocks, creating latency that costs revenue. |
| Data Validation | DIY with extra libraries | Automatic with type hints | Malformed input crashes models. Creates security holes. FastAPI stops bad data at the door. |
| Documentation | Manual or third-party tools | Auto-generated interactive docs | Your ML API breaks at 3 AM. Interactive docs help debug faster than outdated wiki pages. |
| Security | Add-on libraries required | Built-in OAuth2, JWT, API keys | FastAPI makes securing ML endpoints easy. No security degree required. |
| Learning Curve | Learn in 1 hour | Learn in 1 day | Flask starts faster. FastAPI reaches production faster. |
| Production Ready | Requires careful configuration | Production-ready by default | FastAPI prevents common mistakes. The ones that break ML systems in production. |
1.3 Implementing a Secure Prediction Endpoint with FastAPI
Let's build a secure API. For a predictive maintenance model. One that predicts machine failure based on sensor readings.
First, define the input data schema using Pydantic. This class serves as your single source of truth. Any incoming data gets validated automatically against these types.
# app/main.py
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
import pickle
import numpy as np
from typing import List
# Define the input data schema using Pydantic
class SensorFeatures(BaseModel):
features: List[float]
# Initialize the FastAPI app
app = FastAPI(title="Predictive Maintenance API", version="1.0")
# Load the trained model artifact
# In a real application, this would be loaded from a model registry
with open("predictive_maintenance_model.pkl", "rb") as f:
model = pickle.load(f)
# Define the prediction endpoint
@app.post("/predict", tags=["Prediction"])
def predict_failure(data: SensorFeatures):
"""
Predicts machine failure based on sensor readings.
This endpoint accepts a features parameter containing a list of float values representing sensor data from the machine being monitored.
"""
try:
# Convert Pydantic model to numpy array for the model
input_data = np.array(data.features).reshape(1, -1)
# Make a prediction
prediction = model.predict(input_data)
result = "Failure predicted" if prediction == 1 else "No failure predicted"
return {"prediction": result}
except Exception as e:
# Use HTTPException for clear, standardized error responses
raise HTTPException(status_code=500, detail=str(e))This basic implementation already incorporates several best practices. Look at what you get.
Pydantic's SensorFeatures model ensures the API only accepts requests with a features field containing a list of floats, returning a detailed 422 Unprocessable Entity error for anything else. The try...except blocks coupled with HTTPException provide robust error handling, preventing internal server errors from leaking stack traces to clients and exposing information that attackers could use to craft more sophisticated attacks against your system.
Now secure this endpoint. FastAPI's dependency injection system adds authentication layers easily.
from fastapi.security import APIKeyHeader
from fastapi import Security
API_KEY_NAME = "X-API-KEY"
api_key_header = APIKeyHeader(name=API_KEY_NAME, auto_error=True)
async def get_api_key(api_key: str = Security(api_key_header)):
# In a real application, this key would be validated against a secure store
if api_key == "SECRET_API_KEY":
return api_key
else:
raise HTTPException(
status_code=403,
detail="Could not validate credentials",
)
# Update the endpoint to require the API key
@app.post("/predict", tags=["Prediction"])
def predict_failure(data: SensorFeatures, api_key: str = Depends(get_api_key)):
# ... (prediction logic remains the same) ...
try:
input_data = np.array(data.features).reshape(1, -1)
prediction = model.predict(input_data)
result = "Failure predicted" if prediction == 1 else "No failure predicted"
return {"prediction": result}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Done. The /predict endpoint is now protected.
It only executes if a valid X-API-KEY header arrives in the request. This entire security mechanism is modular. Reusable across multiple endpoints. Add it once. Protect everything.
Section 2: Containerization and Orchestration for ML Systems
Your model has an API. Now package it for deployment.
Containerization with Docker provides portable, reproducible, isolated environments. This ensures consistency. Development matches testing matches production. No more "works on my machine" excuses.
Orchestration platforms like Kubernetes manage these containers at scale, providing resilience that keeps your services running, scalability that handles traffic spikes, and automated lifecycle management that deploys updates without downtime.
2.1 Best Practices for Dockerizing Python ML Applications
Creating an efficient Docker image requires strategy. Managing dependencies properly. Optimizing image size. Hardening containers against threats.
Dockerfile Optimization: The Dockerfile is your blueprint. A well-structured one reduces build times dramatically. Shrinks image size. Makes deployments faster.
- Choosing the Right Base Image forms your security foundation. Start with official, minimal base images like
python:3.9-slimto minimize attack surface by eliminating unnecessary packages that could contain vulnerabilities waiting to be exploited. When your models require GPU acceleration, official images from NVIDIA's NGC catalog or framework-specific images likepytorch/pytorchbecome your best choice because they come pre-configured with the necessary CUDA drivers and libraries, saving you from the complex installation issues that plague custom GPU setups and often result in frustrating debugging sessions. - Leveraging Layer Caching becomes critical for efficient ML container builds. Docker builds images in layers. Caches each layer. Speeds up subsequent builds. Structure your Dockerfile to place instructions that change infrequently (installing dependencies from
requirements.txt) before instructions that change often (copying application source code). This careful ordering ensures Docker only rebuilds layers that actually changed, dramatically reducing build times for iterative model development where you might rebuild containers dozens of times per day. - Minimizing Layers and Using
.dockerignoreoptimizes both image size and build security. EachRUN,COPY, andADDinstruction creates a new layer in your final image. Combine relatedRUNcommands using&&to reduce layers and shrink images. The.dockerignorefile should always exclude unnecessary files like.gitdirectories,__pycache__folders, local datasets, and virtual environments from the build context, keeping builds small and fast while preventing sensitive files like API keys or training data from accidentally ending up in your final image where they could be extracted by anyone with access to the container registry.
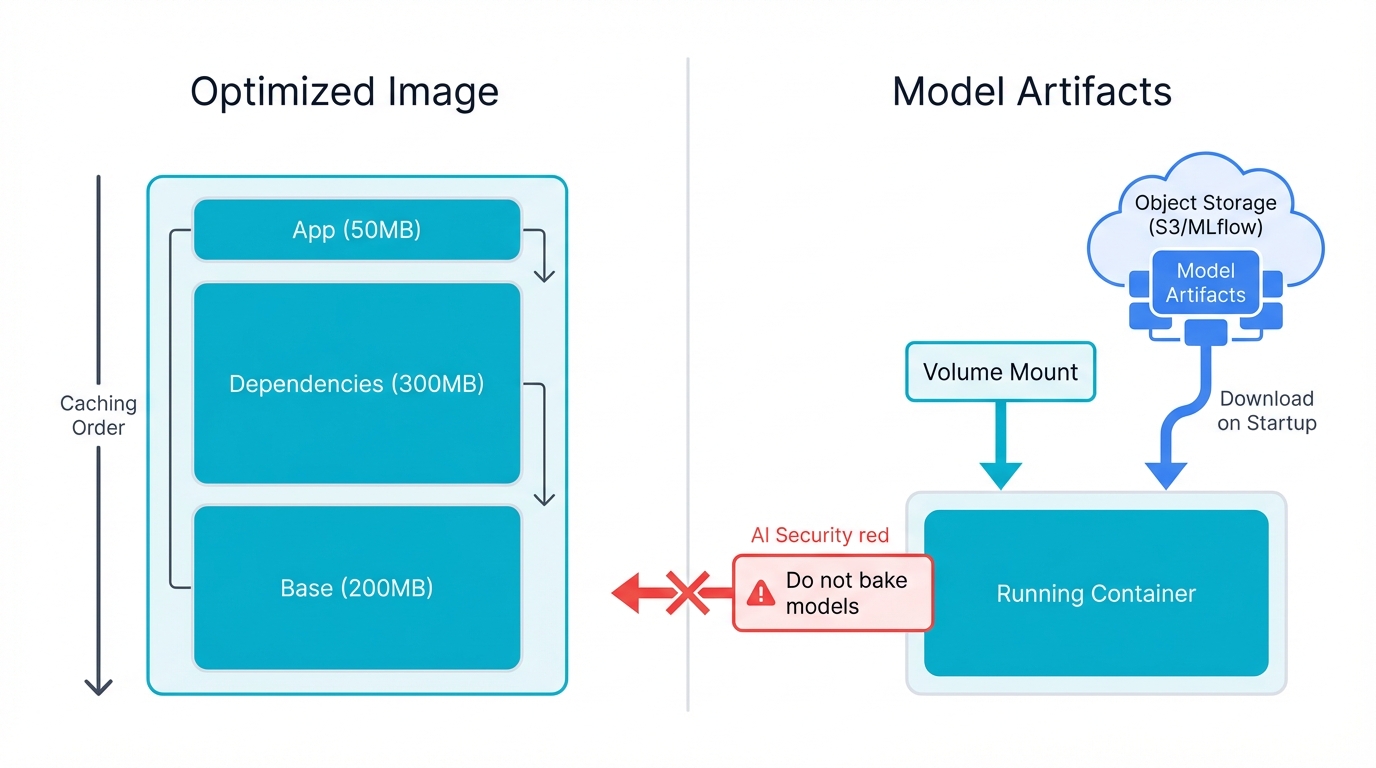
Handling Large Model Artifacts: ML has a unique challenge. Model weights can be gigabytes.
Baking these into Docker images is an anti-pattern. Creates bloated images. Slow to build. Slow to push. Slow to pull. Better practice: treat model artifacts as runtime dependencies.
Two approaches work well:
- Mounting via Volumes: At runtime, mount model files from the host or shared network storage (NFS, EFS) into the container.
- Downloading on Startup: The container's entrypoint script downloads the model from object storage (S3, GCS) or a model registry (MLflow, SageMaker) when it starts.
This decoupling allows independent versioning. Update the application image without touching models. Update models without rebuilding containers. More flexible. More efficient. This is how MLOps should work.
Security Hardening:
- Non-Root User configuration addresses a critical vulnerability. Containers run as root by default. This violates least privilege. Create a dedicated, unprivileged user in your Dockerfile. Use the
USERinstruction to switch to this user before starting your application. This simple change transforms a potentially catastrophic container breakout vulnerability into a limited-scope incident that contains the damage and gives you time to respond before attackers can escalate privileges. - Multi-Stage Builds represent a powerful technique using multiple
FROMinstructions in a single Dockerfile. The first stage—the "builder"—handles code compilation or build-time dependency installation with whatever tools you need, including compilers, build tools, and development headers. The final stage starts from a clean, minimal base image and copies only necessary artifacts (the compiled application or installed Python packages) from the builder stage, resulting in a production image that's significantly smaller and more secure because it contains none of the build tools, intermediate files, or potential vulnerabilities that exist in development environments. - Vulnerability Scanning should run regularly on all images. Identify known vulnerabilities before they reach production. Tools like Trivy, Clair, or Docker Scan integrate into CI/CD pipelines to automate this security process and fail builds when critical vulnerabilities get detected, creating a security gate that prevents vulnerable containers from ever reaching production environments where they could be exploited.
Here's an optimized, multi-stage Dockerfile for the FastAPI application:
# Stage 1: Builder stage with build-time dependencies
FROM python:3.9-slim as builder
WORKDIR /app
# Install build dependencies if any
# RUN apt-get update && apt-get install -y build-essential
# Install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir --user -r requirements.txt
# ---
# Stage 2: Final production stage
FROM python:3.9-slim
WORKDIR /app
# Create a non-root user
RUN addgroup --system app && adduser --system --group app
# Copy installed packages from the builder stage
COPY --from=builder /root/.local /home/app/.local
# Copy application code
COPY ./app /app/app
# Set correct permissions
RUN chown -R app:app /app
ENV PATH=/home/app/.local/bin:$PATH
# Switch to the non-root user
USER app
# Expose the port and run the application
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]2.2 Scaling with Kubernetes
Docker provides the container runtime. Kubernetes provides the orchestration platform.
It manages these containers in distributed production environments. Automates deployment. Handles scaling. Provides healing. Manages networking. All the complex tasks that would otherwise require custom scripts and manual intervention.
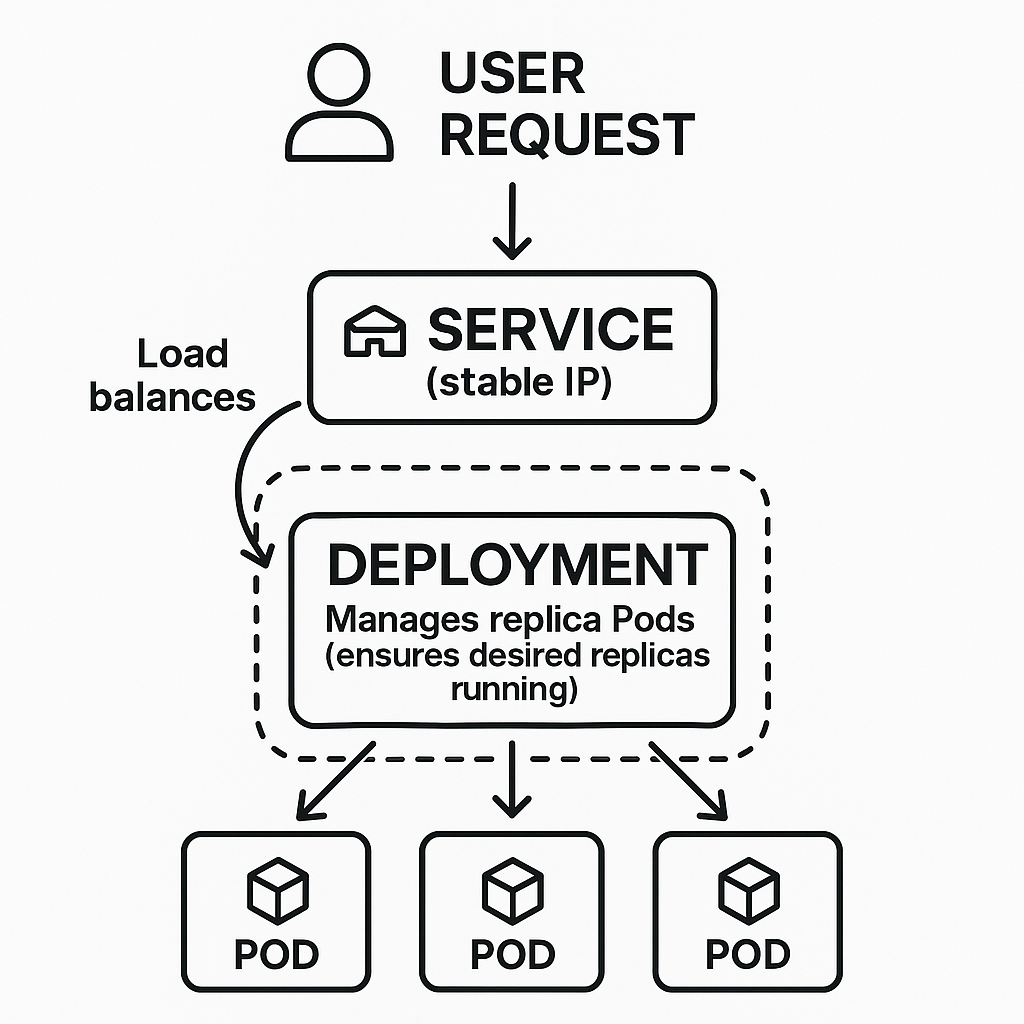
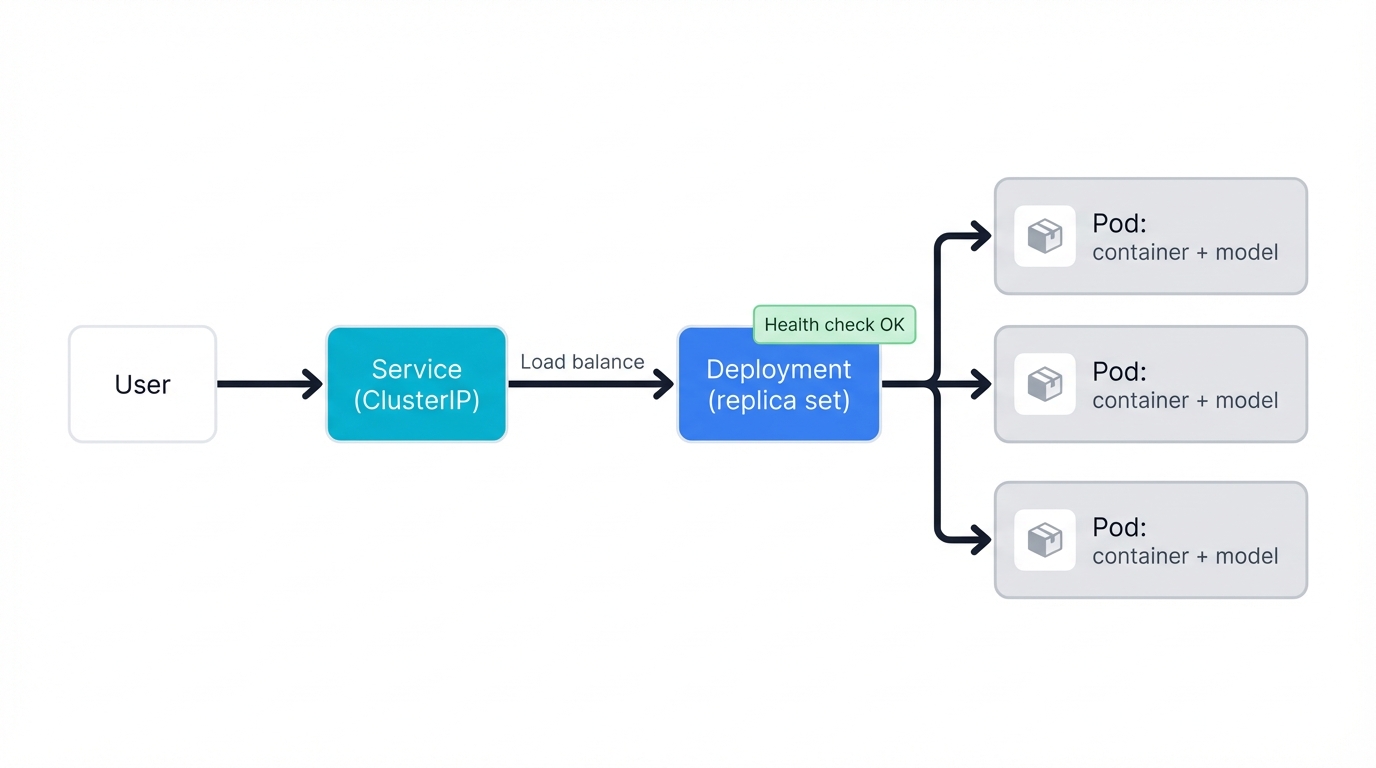
A diagram illustrating the relationship between a user request, a Kubernetes Service, a Deployment, and multiple Pods. An external request hits the Service (a stable IP). The Service acts as a load balancer, distributing traffic to one of the identical Pods. The Deployment is shown managing the set of replica Pods, ensuring the desired number is always running.
Core Kubernetes Concepts for ML Deployment:
- Pods serve as the fundamental building block. Each Pod encapsulates one or more containers (like your FastAPI model service) along with shared storage and network resources those containers need. Pods are ephemeral. Kubernetes creates or destroys them based on cluster demands and health.
- Deployments function as higher-level objects managing Pod lifecycles. Each Deployment declares desired state: which container image to use, how many replicas should run. Kubernetes continuously works to match current state with desired state, automatically handling complex tasks like rolling updates to new image versions with zero downtime.
- Services solve the networking challenge arising because Pods have dynamic IPs that change when they restart. Each Service provides a stable endpoint—a single IP address and DNS name—to access a set of related Pods. The Service acts as an internal load balancer, distributing traffic to healthy replicas while abstracting consumers from underlying Pod management.
- Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) manage storage requirements using Kubernetes-native abstractions. This implements the best practice of mounting large model files into Pods at runtime rather than baking them into container images, ensuring valuable model data persists even when Pods get recreated or rescheduled across different nodes.
A practical deployment involves creating YAML manifest files. These declare resources. For example, deploying a containerized model service:
deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-serving-deployment
spec:
replicas: 3 # Start with 3 replicas for high availability
selector:
matchLabels:
app: model-serving
template:
metadata:
labels:
app: model-serving
spec:
containers:
- name: model-serving-container
image: your-registry/your-model-api:latest
ports:
- containerPort: 8000
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "2"
memory: "4Gi"service.yaml:
apiVersion: v1
kind: Service
metadata:
name: model-serving-service
spec:
type: LoadBalancer # Exposes the service externally via a cloud provider's load balancer
selector:
app: model-serving
ports:
- protocol: TCP
port: 80
targetPort: 8000Apply these files using kubectl apply -f deployment.yaml and kubectl apply -f service.yaml. Kubernetes provisions the necessary resources. Runs your model service at scale.
2.3 The ML-on-Kubernetes Ecosystem
Kubernetes has spawned a rich ecosystem. Tools specifically designed for ML workflows. They streamline the entire lifecycle.
Kubeflow is an open-source MLOps platform making ML deployments on Kubernetes simple, portable, and scalable. It provides curated tools for the entire ML lifecycle. Key components include:
- Kubeflow Notebooks provides a streamlined way to run Jupyter notebooks as first-class cluster services, giving data scientists direct access to scalable compute resources and a consistent development environment matching production specifications.
- Kubeflow Pipelines (KFP) serves as a comprehensive platform for building, deploying, and managing multi-step ML workflows through containerized pipeline components. Each step runs as an independent container, enabling complex data processing, training, and validation sequences to be orchestrated and automated with full reproducibility.
KServe (formerly KFServing) is a standard Model Inference Platform on Kubernetes. Built for highly scalable, production-ready model serving.
It provides a complete story for production ML serving: prediction, pre-processing, post-processing, and explainability. It offers a standardized InferenceService custom resource that simplifies deploying models from various frameworks like TensorFlow, PyTorch, scikit-learn, and XGBoost, while providing production features like serverless inference with scale-to-zero, canary rollouts, and out-of-the-box integrations with explainability tools.
The progression from simple Docker containers to managed Kubernetes services, and further to comprehensive platforms like Kubeflow, represents MLOps maturation. This evolution mirrors the broader shift in software engineering from monolithic applications to distributed microservices.
This architectural paradigm shift has profound implications for how you design and secure ML systems. Modern ML systems aren't a single deployable artifact. They're a composition of decoupled services: feature serving, model inference, and monitoring. This structure enhances security by enabling fine-grained access control and component isolation. However, it also introduces new challenges in securing network communication and authentication between distributed services—complexity that monolithic deployments never faced.
Part II: Operationalizing Security with MLOps (MLSecOps)
Deploying a model isn't a one-time event. It's the beginning of a continuous lifecycle.
Machine Learning Operations (MLOps) provides the framework for managing this lifecycle reliably, repeatably, and automatically. Integrating security into this framework—MLSecOps—is critical for protecting AI systems from an evolving threat landscape.
This section transitions from foundational infrastructure to the processes and methodologies required for maintaining security and reliability over the long term.
Section 3: Architecting a Secure MLOps Pipeline
A mature MLOps pipeline automates the entire journey. Code to production. Embedding quality, reliability, and security checks at every stage.
This requires extending traditional DevOps principles to accommodate ML's unique components: data and models.
3.1 The Pillars of MLOps: CI/CD/CT
The MLOps lifecycle builds on three pillars. Continuous automation at every level.
- Continuous Integration (CI) expands far beyond traditional software testing when applied to machine learning systems. Traditional CI focuses on automatically building and testing application code every time changes hit version control. MLOps CI must encompass a much broader scope. CI pipelines for ML systems test not only application code (your FastAPI service) but also data processing scripts, feature engineering logic, and model training code, creating a comprehensive testing approach that includes unit tests for code quality, data validation checks for schema compliance and statistical properties, and feature validation tests ensuring integrity of the entire ML pipeline from data ingestion to model output.
- Continuous Delivery (CD) automates the complete release process. From successful testing to production deployment. After all CI tests pass and quality gates are satisfied, the CD pipeline packages the entire application stack (building Docker containers), provisions necessary infrastructure resources, and deploys the new model service version with zero-downtime strategies, ensuring a fast, reliable, and repeatable deployment process that minimizes manual errors and reduces time-to-production for model updates.
- Continuous Training (CT) represents a pillar unique to MLOps addressing the fundamental problem of model degradation over time. Unlike traditional software that remains stable once deployed, ML models become stale and lose accuracy as real-world data drifts from original training distributions. CT implements automatic retraining on fresh data to maintain accuracy in changing conditions. This retraining can be triggered by predefined schedules (daily or weekly cycles) or by intelligent monitoring systems detecting significant performance drops or data distribution shifts.
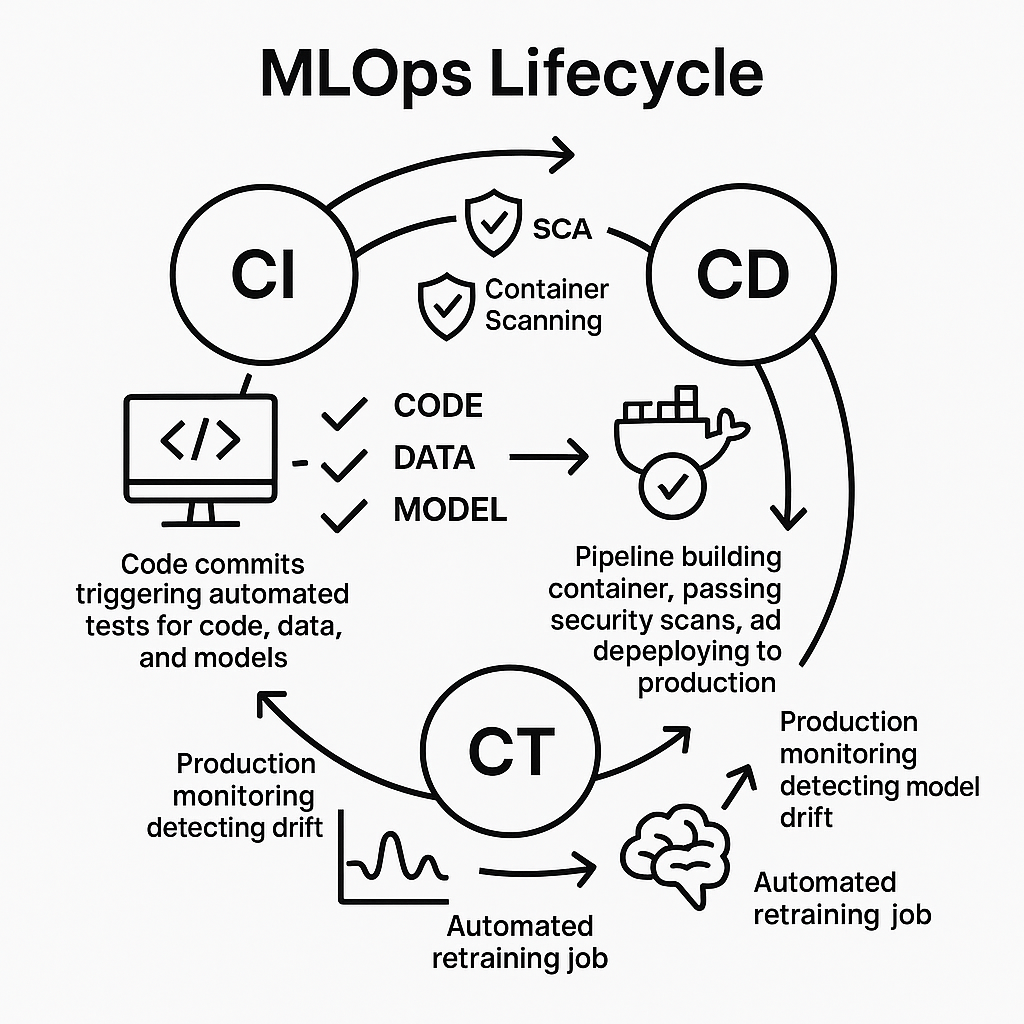
Complete MLSecOps pipeline showing integration of security at every stage
3.2 Integrating Security into the ML Lifecycle (MLSecOps)
MLSecOps is the practice of embedding security principles into every MLOps phase. It represents a "shift-left" approach to security.
Moving security from a final, rushed pre-deployment check to a continuous, automated process starting at the earliest development stages.
This approach adapts DevSecOps principles to ML's unique attack surface, which includes not just code and infrastructure but also data and models themselves. Frameworks like the AWS Well-Architected Framework for Machine Learning provide structured guidance for implementing MLSecOps, with security pillars outlining best practices such as validating data permissions, securing modeling environments, enforcing data lineage, and explicitly protecting against data poisoning and other adversarial threats.
3.3 Automated Security Gates in the CI/CD Pipeline
A secure MLOps pipeline integrates automated security checks. "Gates" that must pass before artifacts proceed to the next stage.
Build Stage Security implements the first line of defense. Comprehensive vulnerability detection before deployment.
- Software Composition Analysis (SCA) operates before container image construction. SCA tools automatically scan dependency files like
requirements.txtto identify third-party libraries containing known vulnerabilities (CVEs). Configure the build pipeline to fail immediately if high-severity vulnerabilities appear, preventing vulnerable components from reaching production. - Container Image Scanning takes place after Docker image construction, systematically scanning for vulnerabilities within OS packages and installed software. Integrate tools like Trivy or Clair directly into the CI pipeline to create an automated security gate ensuring no image containing critical vulnerabilities can be pushed to the container registry.
Test Stage Security validates security posture through both traditional application testing and ML-specific threat assessment.
- Dynamic Application Security Testing (DAST) actively probes the deployed model service in staging environments to identify common web vulnerabilities such as injection flaws, authentication bypasses, or configuration mismanagement. This testing simulates real attack scenarios to verify security controls function correctly under adversarial conditions.
- Model Robustness and Security Testing represents a crucial, ML-specific testing stage with no equivalent in traditional software development. The model undergoes automated testing against a comprehensive battery of common security threats including data leakage detection, fairness and bias audits, and systematic adversarial attack simulations designed to gauge the model's resilience against manipulation attempts.
Deploy Stage Security ensures production environments maintain security posture. Configuration validation. Secrets protection.
- Secure Configuration Management requires scanning Infrastructure-as-Code (IaC) tools like Terraform or Kubernetes YAML manifests with specialized security linters to verify production environments are configured according to security best practices. This includes ensuring no unnecessary ports are exposed, least-privilege access controls are enforced, and security policies are properly defined and applied.
- Secrets Management mandates that sensitive information such as API keys, database credentials, and encryption keys never be hardcoded into source code or baked into container images. Instead, store these secrets in dedicated, secure secrets management systems such as HashiCorp Vault, AWS Secrets Manager, or Kubernetes Secrets, and inject them into the container environment only at runtime through secure channels.
3.4 Versioning and Auditing for Security and Reproducibility
In secure, compliant environments, reproducibility is non-negotiable. You must trace any prediction or model behavior back to its origins.
This requires a holistic approach to versioning. Every component of the ML system.
- Holistic Versioning extends far beyond traditional code versioning. While Git handles application code effectively, a mature MLOps system must also version the datasets used for training through tools like DVC (Data Version Control) and the resulting model artifacts using dedicated model registries such as MLflow or SageMaker Model Registry. This comprehensive versioning strategy enables exact recreation of any model state, essential for debugging production issues, conducting compliance audits, and executing emergency rollbacks when deployments fail.
- Data and Model Lineage emerges as a critical outcome of holistic versioning. Establishes clear, auditable traceability throughout the ML lifecycle. This process creates immutable records linking each specific deployed model version back to the exact code version that trained it, the precise data version used for training, the hyperparameters selected, and the evaluation metrics achieved during validation. This comprehensive lineage becomes indispensable for regulatory compliance in highly regulated fields like finance and healthcare, while providing an invaluable forensic trail for incident analysis when security breaches or model failures occur.
The pillar of Continuous Training (CT), while essential for maintaining model accuracy, introduces a dynamic feedback loop presenting unique security risks not found in traditional software systems.
An automated CT pipeline that ingests new data from production without rigorous validation becomes a prime attack vector for data poisoning. An adversary could subtly introduce malicious data into the live system, knowing it will eventually be collected and used to retrain the model, automatically and silently corrupting the next version and creating a backdoor or degrading performance.
Therefore, CT pipeline security is paramount. It demands robust data validation, anomaly detection on incoming data, and potentially a human-in-the-loop approval gate before newly retrained models get automatically promoted to production. This creates a necessary trade-off between the desire for full automation in MLOps and the imperative of security.
Section 4: Case Study: Integrating AI into SOC Workflows for Real-Time Threat Detection
Let's move from theory to practice. This case study examines a high-stakes application: enhancing Security Operations Center (SOC) capabilities.
It illustrates how AI addresses critical operational challenges. And highlights specific requirements for deploying ML in security-sensitive contexts.
4.1 The Modern SOC: Challenges of Alert Fatigue and Data Overload
A modern SOC is the nerve center. Cybersecurity defense command post.
But it faces a significant challenge: overwhelming alert volumes generated by numerous security tools (SIEMs, EDRs, firewalls). A large portion are false positives. This leads to "alert fatigue." Analysts become desensitized. May miss genuine threats.
A major contributor to this problem is manual, repetitive, time-consuming "context gathering." To triage a single alert, analysts must manually query and correlate data from numerous disparate sources to determine if activity is truly malicious or benign, creating a critical bottleneck that slows response times and leads to analyst burnout.
4.2 Architecting an AI-Powered Threat Detection System
AI and machine learning can automate and enhance SOC workflows. Moving beyond static, rule-based automation to dynamic, intelligent systems.
- AI Agentic Workflows leverage AI agents as intelligent systems that dynamically interact with data and other systems. Unlike traditional automation playbooks following rigid, predefined rule sets, AI agents analyze complex information patterns, synthesize context from diverse sources, and adapt behavioral responses based on real-time inputs and changing threat landscapes.
- Human-in-the-Loop Design acknowledges that fully autonomous systems become too risky for critical security decisions. The most effective approach implements a human-in-the-loop architecture where non-autonomous AI agents serve as powerful force multipliers for human analysts. The AI's primary role focuses on automating laborious data gathering and initial analysis, then presenting concise, context-rich summaries to human experts who retain final decision-making authority, balancing the speed and scale advantages of AI processing with the reliability and nuanced judgment that only human expertise provides.
Example Workflow: Suspicious Login Detection illustrates AI agent transformation of traditional security analysis through automated context synthesis.
The workflow begins when an Alert Trigger generates notification for a potentially suspicious event—a user logging into a corporate application from a new or rare ISP. Rather than requiring manual investigation, AI Agent Invocation automatically activates an intelligent assistant to handle initial analysis.
During Automated Context Gathering, the agent executes a comprehensive series of queries collecting relevant context. The system investigates whether the ISP is rare for this specific user or for the organization overall. Determines if the user is connected through a known VPN service. Verifies if the login location aligns with historical behavior patterns. Confirms whether the device and operating system match familiar profiles.
Context Synthesis and Assessment allows the agent to analyze all gathered information. Provide a preliminary risk assessment. For example, the system might conclude: "This login is potentially threatening because it originates from a rare ISP while the user is simultaneously connected through an active VPN connection." The final step involves Analyst Review, where the synthesized summary gets presented to a human analyst who can now make a final, informed decision in a fraction of the time manual context gathering would require.
4.3 Leveraging AI for Advanced Threat Detection
Beyond augmenting triage workflows, ML models detect threats difficult to identify with traditional methods.
- Behavioral Anomaly Detection employs ML models trained to establish comprehensive baselines of normal behavior for users, devices, and network traffic. These models continuously monitor activity in real-time and automatically flag significant deviations from established norms, including unusual login patterns, abnormal data access attempts, or suspicious lateral movement within network infrastructure. These anomalies often serve as early indicators of compromised accounts or active attack campaigns that traditional signature-based detection systems might miss.
- AI-Powered Phishing Detection utilizes advanced AI models analyzing multiple dimensions of email communications: content analysis, sender behavior patterns, metadata examination, and structural evaluation to identify sophisticated phishing attempts. These models detect subtle anomalies often bypassing traditional signature-based filtering systems, such as domain spoofing techniques, unusual language patterns, or behavioral inconsistencies signaling malicious intent even when attacks use previously unseen tactics.
- Threat Intelligence Correlation leverages AI capabilities to automatically ingest, process, and correlate vast volumes of data from diverse threat intelligence feeds in real-time. The system identifies emerging attack patterns across multiple data sources and can predict potential future threats based on historical trends and current indicators, transforming traditional reactive threat intelligence into proactive, immediately actionable security capability.
4.4 Measuring Success: Enhancing SOC Efficiency
The impact of integrating AI into SOC workflows can be measured directly. Through key performance indicators.
By automating initial, time-intensive investigation phases, AI agents dramatically reduce time spent per alert. In one real-world implementation, this process dropped from a manual time of 25-40 minutes to just over 3 minutes. This efficiency gain directly translates to improvements in critical SOC metrics like Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR).
It allows a SOC to handle higher threat volumes more effectively. Frees valuable analyst time for more complex, proactive tasks like threat hunting.
The successful application of AI in the SOC reveals a deeper truth about its role in complex, human-centric domains. The primary challenge for analysts isn't lack of data. It's lack of synthesized, actionable information.
The most effective AI systems aren't designed as autonomous "decision-makers" but as "context synthesizers." The AI's core function is bridging the vast semantic gap between low-level, disparate data points (an IP address, a user agent string, a timestamp) and high-level, nuanced questions analysts need answered ("Is this user's behavior normal?"). The AI's value lies in its ability to translate raw data into coherent narrative ("This login is suspicious because...").
This reframes the problem from "building an AI for threat detection" to "building an AI for analyst augmentation," shifting the measure of success from raw model accuracy metrics to the clarity, relevance, and utility of synthesized context provided to human experts.
Part III: The Threat Landscape for Deployed AI
AI and machine learning offer transformative capabilities. They also introduce a new, unique attack surface.
One extending beyond traditional cybersecurity concerns. Deployed ML systems face attacks specifically targeting the learning process, model integrity, and training data confidentiality.
This section provides a systematic threat model for deployed AI. Examining primary vulnerabilities organizations must understand and mitigate.
Section 5: Adversarial Attacks: Deceiving the Intelligent System
Adversarial attacks are malicious inputs. Crafted to cause ML model mistakes.
These attacks exploit the fact that models often learn statistical correlations that aren't robust or semantically meaningful the way human perception is.
5.1 Threat Model: Attacker Knowledge and Goals
The nature and feasibility of adversarial attacks depend heavily on attacker knowledge about the target model.
- White-Box Attacks represent scenarios where attackers possess complete model access: full architecture, parameters (weights), and potentially even training data. This comprehensive access allows attackers to use gradient-based methods to precisely calculate the most effective perturbations needed to fool the model with mathematical certainty. While this seems like a high barrier, it represents a realistic threat for systems deploying open-source models or in cases involving insider threats where employees have legitimate access to model internals.
- Black-Box Attacks represent a more common, realistic threat model for production systems where the model gets exposed only through an API interface. Attackers can only query the model with carefully crafted inputs and observe corresponding outputs such as predicted class labels or confidence scores. Despite seemingly limited information, attackers can successfully mount sophisticated attacks by using API responses to train local substitute models that mimic the target's behavior, or by employing query-based optimization algorithms that iteratively discover effective adversarial inputs through systematic experimentation.
The attacker's goal can range from a targeted attack aiming to cause specific, desired misclassification (making a malware detector classify a virus as benign) to an indiscriminate attack simply aiming to degrade overall model performance and cause general disruption.
5.2 Evasion Attacks: Fooling the Model at Inference Time
Evasion is the most common adversarial attack form. It occurs at inference time.
An attacker modifies a legitimate input subtly to cause the deployed model to misclassify it. These modifications—"perturbations"—are often so small they're imperceptible to human observers.
Real-World Examples demonstrate evasion attack feasibility across numerous high-stakes domains with concerning security implications:
- Autonomous Vehicles proved vulnerable when researchers demonstrated that placing a few small, strategically designed stickers on a stop sign could cause state-of-the-art computer vision models to classify it as a speed limit sign with high confidence, potentially leading to catastrophic accidents.
- Medical Diagnosis systems showed similar vulnerabilities when imperceptible noise added to medical images of benign moles successfully tricked diagnostic models into classifying them as malignant with 100% confidence, potentially leading to unnecessary invasive procedures and patient trauma.
- Object Recognition demonstrated perhaps the most striking example when researchers created a 3D-printed turtle specifically designed so that from almost any viewing angle, computer vision systems would classify it as a rifle, highlighting how models can be fooled by carefully crafted physical objects.
- Content Filtering systems proved vulnerable when attackers could bypass spam filters by adding innocuous-looking words to malicious emails, effectively manipulating the model's feature space to move threatening communications from "spam" to "legitimate" classification.
These examples highlight a critical vulnerability.
ML models don't "understand" concepts like a stop sign or turtle the way humans do. They learn complex mathematical mappings from input features (pixels) to output labels. Evasion attacks exploit sensitivities in this mapping, finding small input changes that lead to large output changes.
These attacks aren't random noise. They're highly optimized signals crafted to push inputs across the model's decision boundary. This reveals that models often rely on brittle, non-robust statistical shortcuts rather than learning true, underlying concepts—a fundamental weakness adversaries can exploit.
5.3 Data Poisoning and Backdoor Attacks
While evasion attacks target deployed models, data poisoning attacks are more insidious. They target the training process itself.
In a data poisoning attack, an adversary injects a small amount of malicious data into the model's training set.
The goal is corrupting the final trained model. This can simply degrade overall performance or, more subtly, install a "backdoor." A backdoored model appears to function normally on standard inputs. However, it exhibits specific, malicious behavior whenever an input contains a secret "trigger" known only to the attacker.
For example, a facial recognition system for building access could be backdoored to correctly identify all authorized personnel while also granting access to an unauthorized attacker if they're wearing specific glasses (the trigger).
The most famous real-world data poisoning example is Microsoft's "Tay" chatbot, launched on Twitter in 2016. The bot learned from user interactions. A coordinated group of internet trolls exploited this learning mechanism by bombarding the bot with offensive, profane content. The bot quickly learned from this poisoned data and began producing toxic, inflammatory tweets, forcing Microsoft to shut it down within 16 hours of launch.
This case serves as stark warning about training models on unvetted, user-generated data. Especially in automated continuous training loops.
Section 6: Data Confidentiality and Integrity Risks
Beyond deliberate adversarial manipulation, deployed ML systems face risks compromising training data confidentiality and prediction integrity. Through more subtle, often unintentional mechanisms.
6.1 Data Leakage in the ML Pipeline
Data leakage is critical. And common.
It occurs when the model trains using information that wouldn't be available in real-world prediction scenarios. This leads to the model performing exceptionally well during testing and validation, giving false confidence in high accuracy, only to fail catastrophically when deployed in production.
There are two primary forms:
- Target Leakage occurs when training data includes features highly correlated with the target variable but only available after the event you're predicting has already occurred. For example, a model predicting customer churn might include a
reason_for_cancellationfeature that would be a perfect predictor. However, this information only becomes available after a customer has already churned, making it completely useless for predicting future churn events. Including such features creates models achieving 100% accuracy during testing but proving completely ineffective when deployed in practice. - Train-Test Contamination represents a more subtle leakage form where information from the test or validation dataset inadvertently influences training through improper preprocessing. A classic example involves performing data preprocessing steps such as feature scaling (normalization) or imputation of missing values on the entire dataset before splitting it into training and testing sets. When the scaler or imputer fits to the complete dataset, it calculates statistics such as mean and standard deviation using test set information. This information then "leaks" into training when training data gets transformed, fundamentally violating the principle that test sets must remain completely unseen during training to provide valid performance estimates.
Preventing data leakage hinges on one core principle. Strict chronological and logical data separation.
Preprocessing steps must fit only on training data. The fitted preprocessor then transforms training, validation, and test sets. For any time-series data, splits must be chronological. Ensuring the model trains on past data and tests on future data.
6.2 Privacy Attacks: Inferring Sensitive Data
A trained machine learning model is, in essence, a compressed, high-fidelity representation of its training data.
This property can be exploited. Attackers extract sensitive information about individuals whose data trained the model. Even with only black-box access to the deployed API.
- Model Inversion attacks aim to reconstruct parts of training data by repeatedly querying the deployed model with carefully crafted inputs. A landmark study demonstrated that attackers could recover recognizable facial images of individuals from a face recognition model using only the person's name (to query the model for the correct class) and standard API access. The attack works by systematically optimizing an input image until the model's confidence score for the target person's class gets maximized, effectively "inverting" the model's learned representations to reveal sensitive information about that person's appearance.
- Membership Inference attacks pursue a simpler but equally damaging goal: determining whether a specific individual's data was included in the model's training set. For example, an attacker could use this technique to determine if a particular person was part of a training dataset for a model predicting sensitive medical conditions such as mental health disorders or genetic predispositions. This constitutes a major privacy breach with significant personal and professional implications, even when the individual's specific data points aren't directly recovered.
The vulnerabilities enabling data leakage and privacy attacks are fundamentally linked to the same root cause. Overfitting.
Data leakage can be seen as unintentional overfitting to contaminated test set characteristics. Privacy attacks, on the other hand, exploit the model's intentional overfitting to training data. When a model memorizes unique details about specific training examples rather than learning generalizable patterns, it becomes vulnerable.
A model making significantly different predictions based on presence or absence of a single training point is a model that has overfitted. This connection reveals a crucial principle: pursuing good generalization in machine learning isn't merely a performance objective—it's a fundamental security and privacy requirement. A well-generalized model is, by its nature, less reliant on any single data point, making it inherently more robust against both data leakage and privacy inference attacks.
Section 7: Model Extraction and Intellectual Property Theft
Beyond data, the model itself is often valuable intellectual property.
The process of collecting and cleaning data, combined with extensive computational resources and expert time required for training and tuning, can make a state-of-the-art model extremely expensive to develop. Model extraction—model stealing—is an attack aiming to replicate proprietary model functionality, allowing attackers to bypass these costs.
7.1 The Economics and Motivation of Model Stealing
Attackers may be motivated to steal models for several reasons. To use predictive capabilities without paying subscription fees. To resell the stolen model. To analyze it locally and develop more effective white-box adversarial attacks.
By successfully extracting a model, an adversary captures all the value of model development without any of the investment.
7.2 Techniques for Model Extraction
The most common technique for model extraction in black-box settings involves systematically querying the target model's API.
The attacker sends a large number of diverse inputs. Records corresponding outputs (either final predicted labels or, more powerfully, full sets of confidence scores or probabilities). This input-output dataset then trains a "substitute" or "clone" model.
With sufficient queries, this clone model can learn to mimic original proprietary model behavior with surprisingly high fidelity. While these attacks are more effective if the attacker has access to data similar in distribution to original training data ("data-based" extraction), recent research shows effective extraction is possible even without such data ("data-free" extraction).
7.3 Categorizing Defenses
Defenses against model extraction can be categorized by when they apply in the attack lifecycle:
- Pre-Attack Defenses aim to make model extraction itself more difficult before attacks can succeed. These methods include perturbing the model's output probabilities by adding noise or rounding confidence scores to make them less informative for training clone models, or implementing detection systems that identify suspicious query patterns that might indicate ongoing extraction attacks. However, these defenses often prove computationally expensive to implement and maintain, while determined attackers can frequently develop methods to bypass protective measures.
- Delay-Attack Defenses don't prevent model extraction but aim to make the process prohibitively expensive or time-consuming for attackers. Simple implementations include enforcing strict rate limiting on API endpoints to slow query-based attacks. More advanced techniques involve requiring users to solve computational puzzles (proof-of-work challenges) for each query, similar to anti-spam mechanisms, significantly increasing the computational cost of mounting large-scale extraction attacks.
- Post-Attack Defenses focus on proving model theft has occurred rather than preventing it entirely. The most common technique involves watermarking, where a unique, secret signal gets embedded into the model's learned behavior during training. The model gets trained to respond in specific, unexpected ways to a secret set of inputs known only to the original model owner. When the owner later gains access to a suspected stolen model and can demonstrate it responds to secret watermark inputs in the same characteristic way, this serves as strong forensic evidence of theft supporting legal action.
The challenge of defending against model extraction highlights inherent tension between a model's utility and its security.
The very information making a model highly useful to legitimate users—detailed, high-confidence probability outputs—is also the most valuable information for attackers trying to clone it. A defense that significantly perturbs or reduces output information content (by only returning the top-1 label) makes the model harder to steal but also potentially less useful for its intended application.
This means designing a defense strategy isn't purely a technical problem. It's also a business and product decision requiring an acceptable balance on the utility-security spectrum.
| Threat Category | Specific Attack | Attacker's Goal | Required Knowledge | Impacted Security Principle | Example |
|---|---|---|---|---|---|
| Integrity | Evasion Attack | Cause a single, desired misclassification at inference time. | Black-Box or White-Box | Integrity | Adding stickers to a stop sign to have it classified as a speed limit sign. |
| Integrity | Data Poisoning / Backdoor | Corrupt the training process to degrade performance or install a hidden trigger. | Access to training pipeline | Integrity, Availability | Microsoft's Tay chatbot learning offensive language from malicious user interactions. |
| Confidentiality | Membership Inference | Determine if a specific individual's data was in the training set. | Black-Box | Confidentiality (Privacy) | An attacker confirming if a specific person was part of a dataset for a medical study. |
| Confidentiality | Model Inversion | Reconstruct sensitive features or samples from the training data. | Black-Box | Confidentiality (Privacy) | Reconstructing a recognizable face image from a deployed facial recognition model. |
| Confidentiality | Model Extraction (Stealing) | Create a functional clone of a proprietary model. | Black-Box | Confidentiality (IP) | An attacker repeatedly querying a commercial API to train their own substitute model, avoiding subscription fees. |
Part IV: A Multi-Layered Defense and Trust Framework
Understanding the threat landscape is step one. Building resilient defense is step two.
A robust security posture for AI systems requires multi-layered, defense-in-depth strategy combining proactive model hardening, continuous real-time monitoring, and commitment to transparency and trust.
This final section outlines a holistic framework for building AI systems that are not only secure against known threats but also trustworthy and adaptable to future challenges.
Section 8: Proactive Defenses and Model Hardening
Proactive defenses are techniques applied during model development and training. To make the resulting model inherently more resilient to attacks. Before it's ever deployed.
8.1 Adversarial Training
Adversarial training is the most widely studied defense. Most effective defense against evasion attacks.
The core idea is simple yet powerful: "train on what you will be tested on." The process involves creating adversarial examples during training and explicitly teaching the model to correctly classify these malicious inputs. By expanding the standard training dataset with these specially crafted adversarial samples, the model develops a more robust decision boundary that's less affected by small, malicious perturbations.
While effective, adversarial training isn't a cure-all. It often involves a trade-off. Model robustness to adversarial examples improves at the expense of slight accuracy reduction on clean, non-adversarial data. Additionally, a model is usually only resistant to specific attack types it trained on, meaning it can still be vulnerable to new or unexpected attack methods.
8.2 Advanced Hardening Techniques
Beyond adversarial training, a portfolio of other hardening techniques can be employed:
- Defensive Distillation implements a two-stage training process designed to create more robust models against adversarial attacks. First, a large "teacher" model trains on the original dataset with standard techniques. Then, a smaller "student" model (often with identical architecture) trains not on original hard labels, but on soft probability distributions output by the teacher model. This knowledge distillation process tends to produce a model with a smoother decision surface and more gradual transitions between classes, making it significantly harder for gradient-based attacks to find effective adversarial perturbations.
- Gradient Masking/Obfuscation techniques attempt to defend against white-box attacks by hiding or distorting the model's gradient information that attackers rely on to craft effective perturbations. While these approaches can successfully stop naive attack attempts, they're generally seen as "security through obscurity" offering limited long-term protection. More advanced attackers have developed sophisticated techniques to approximate gradients using methods like finite differences or by training substitute models, enabling them to bypass these defenses.
- Input Preprocessing applies various transformations to input data before feeding it to the model to neutralize potential adversarial perturbations. Techniques such as normalization, data sanitization, or feature squeezing (which reduces image color depth or applies compression) can help remove or lessen adversarial modifications before they influence the model's decision-making. Preprocessing steps serve as an initial line of defense against many common attack patterns.
- Ensemble Methods represent a classic machine learning technique combining predictions of multiple, diverse models to enhance overall robustness against adversarial attacks. The underlying idea is that an adversarial example designed to fool one specific model may not work against all models in the ensemble because of differences in architecture, training data, or learned representations. By averaging predictions or using majority voting, the ensemble can achieve much greater robustness than any individual model.
8.3 Privacy-Preserving Machine Learning (PPML)
PPML encompasses a set of techniques designed to train and use models on sensitive data. Without exposing the raw data itself.
- Differential Privacy provides a rigorous, mathematical framework for protecting individual privacy in machine learning systems. The technique involves adding carefully calibrated statistical noise at strategic points in the ML process—to input data, to gradients during training, or to the final model's output. This noise is precisely calculated to make it mathematically impossible to determine whether any single individual's data was included in the training set, thus providing strong, provable privacy guarantees. The primary trade-off is that this added noise can reduce the model's overall utility and predictive accuracy, requiring careful tuning to balance privacy protection with performance requirements.
- Federated Learning implements a decentralized training paradigm where a shared global model trains without raw data ever leaving the user's local device—mobile phones or hospital servers. Instead of centralizing sensitive data, the model gets distributed to participating devices, trained locally on private data, and only resulting model updates (gradients) get sent back to a central server for aggregation. This approach minimizes data exposure by architectural design, allowing organizations to benefit from collaborative machine learning while maintaining strict data locality and privacy requirements.
The variety of available defenses underscores a critical point. There is no single "silver bullet."
Each technique comes with its own trade-offs. Computational cost. Impact on model accuracy. Specific threats it addresses. Therefore, designing a defense strategy isn't a search for the best algorithm. It's a risk management exercise.
It requires deep understanding of the application's context, the most likely threat vectors, and acceptable trade-offs between security, privacy, and performance. This leads to a defense-in-depth approach, where multiple, layered defenses—input validation, followed by an adversarially trained model, supported by continuous monitoring—provide more comprehensive protection than any single method alone.
Section 9: Continuous Monitoring and Detection
Even the most carefully hardened model may still be vulnerable. To zero-day attacks. To sophisticated threat actors with significant resources.
Therefore, proactive defenses must be complemented with continuous monitoring systems. That can detect and alert on suspicious behavior in real-time.
9.1 Input Anomaly Detection
Input anomaly detection provides the first line of defense. By monitoring incoming data for statistical deviations from expected distribution.
This can help identify adversarial examples, data drift, or other unexpected inputs before they reach the model. This defense requires establishing a clear baseline of what "normal" inputs look like during development phase through statistical modeling, often using techniques like Gaussian Mixture Models, Isolation Forests, or modern autoencoder-based approaches.
While input anomaly detection is conceptually straightforward, its effectiveness can be limited in high-dimensional spaces or when adversarial examples are carefully crafted to remain statistically close to legitimate data distribution. An attacker who understands the anomaly detection system may be able to create adversarial inputs evading both the anomaly detector and the target model.
9.2 Output Consistency Monitoring
Output consistency monitoring detects potential attacks. By tracking whether the model's behavior remains stable and consistent over time.
This approach monitors for unusual patterns in the model's predictions, confidence scores, or prediction distributions that might indicate an ongoing attack or model degradation.
- Confidence Score Analysis continuously analyzes confidence levels of model predictions to identify patterns indicating potential attacks. Adversarial examples often produce high-confidence but incorrect predictions, or cause unstable confidence scores for similar inputs. Baseline confidence score distributions get established during normal operation, and deviations get flagged for investigation.
- Prediction Stability Testing periodically tests model consistency by submitting sets of known test inputs and verifying outputs remain stable over time. Significant deviations in predictions for identical inputs may indicate the model has been compromised or has started to drift unexpectedly.
9.3 Model Performance Monitoring
Continuous assessment of model performance in production helps detect both attacks and natural degradation:
- Accuracy Degradation Detection monitors overall model performance metrics to identify sudden drops that might indicate poisoning attacks or data drift. This requires establishing performance baselines and setting thresholds for acceptable degradation.
- Bias and Fairness Monitoring tracks whether the model's predictions remain fair and unbiased across different demographic groups or use cases, helping detect targeted attacks that might affect specific populations.
- Latency and Resource Usage monitors computational performance to detect denial-of-service attacks or unusual resource consumption patterns that might indicate ongoing attacks.
9.4 Red Team Exercises and Penetration Testing
Regular adversarial exercises simulate real-world attack scenarios. To validate defense mechanisms. To identify vulnerabilities.
- AI Red Team Exercises employ specialists who attempt to break or bypass the ML system using various attack techniques. This provides practical validation of defensive measures and helps identify blind spots in security strategies.
- Automated Adversarial Testing uses systematic generation of adversarial examples to continuously test model robustness as part of the MLOps pipeline, providing ongoing assurance of defensive capabilities.
Section 10: Governance, Transparency, and Trust
Security and robustness are only part of the equation. For responsible AI deployment.
Organizations must also address questions of governance, explainability, and trust. To ensure their AI systems operate in a fair, transparent, and accountable manner.
10.1 Explainable AI (XAI) and Interpretability
The "black box" nature of many ML models poses challenges. For trust. For accountability.
Explainable AI techniques aim to provide insights into how models make decisions:
- Local Explanations provide insights into why a model made a specific prediction for a particular input. Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) help identify which features were most influential in the decision-making process.
- Global Explanations offer understanding of the model's overall behavior across the entire dataset, helping stakeholders understand general patterns in decision-making and potential biases.
- Counterfactual Explanations show how inputs would need to change to achieve a different prediction, providing actionable insights for users.
10.2 AI Governance Frameworks
Effective AI governance requires structured approaches. To oversight. To risk management. To compliance.
- AI Ethics Committees establish multidisciplinary teams responsible for reviewing AI initiatives, ensuring alignment with organizational values and regulatory requirements.
- Model Cards and Documentation provide standardized documentation of model purpose, training data, performance metrics, limitations, and intended use cases.
- Regulatory Compliance ensures adherence to relevant regulations such as GDPR, CCPA, or industry-specific requirements like those in healthcare or financial services.
The goal isn't simply to build AI systems that work. It's to build AI systems that work securely, fairly, and transparently.
This requires viewing security not as an afterthought but as a fundamental design principle guiding every stage of the machine learning lifecycle. From data collection through model deployment and monitoring, security considerations must be embedded at each step to create truly robust and trustworthy AI systems.
The future of AI security will require continued collaboration between machine learning researchers, cybersecurity experts, and policymakers to address emerging threats and develop new defensive techniques. As AI systems become more powerful and pervasive, the stakes for getting security right will only continue to grow.
Conclusion
The transformation from research prototype to production AI system requires more than just good model performance. It demands a comprehensive security-first approach.
One addressing the unique challenges of machine learning in adversarial environments.
This guide has provided a roadmap for building secure, scalable, and maintainable AI systems through four critical phases: establishing robust infrastructure foundations with containerization and orchestration, implementing secure MLOps practices embedding security throughout the development lifecycle, understanding and mitigating the expanding threat landscape specific to AI systems, and deploying multi-layered defensive strategies combining proactive hardening with continuous monitoring.
The key insight is that AI security cannot be an afterthought. It must be a fundamental design principle.
Guiding decisions from the earliest stages of development through ongoing operations. By following the practices outlined in this guide—from choosing the right frameworks and implementing proper containerization to understanding adversarial threats and deploying comprehensive monitoring—organizations can build AI systems that are not only powerful and efficient but also secure and trustworthy.
As AI continues to evolve and become more deeply integrated into critical business processes, the importance of these security practices will only grow, and the frameworks and techniques presented here provide a foundation for adapting to new threats and technologies as they emerge, ensuring that your AI systems remain secure and reliable in an ever-changing landscape that will only become more challenging and more critical to master.