Table of Contents
Introduction: The Imperative for Parameter-Efficient Fine-Tuning
Large Language Models changed everything. Their capabilities across natural language tasks? Remarkable. But there's a catch—actually, several catches, each more daunting than the last.
The very scale that makes these models powerful creates a formidable barrier. Want to specialize a pre-trained model for your specific task? Standard practice says fine-tune it—update every single parameter. Sounds reasonable until you run the numbers.
The Challenge of Scaling: Computational and Memory Bottlenecks in Full Fine-Tuning
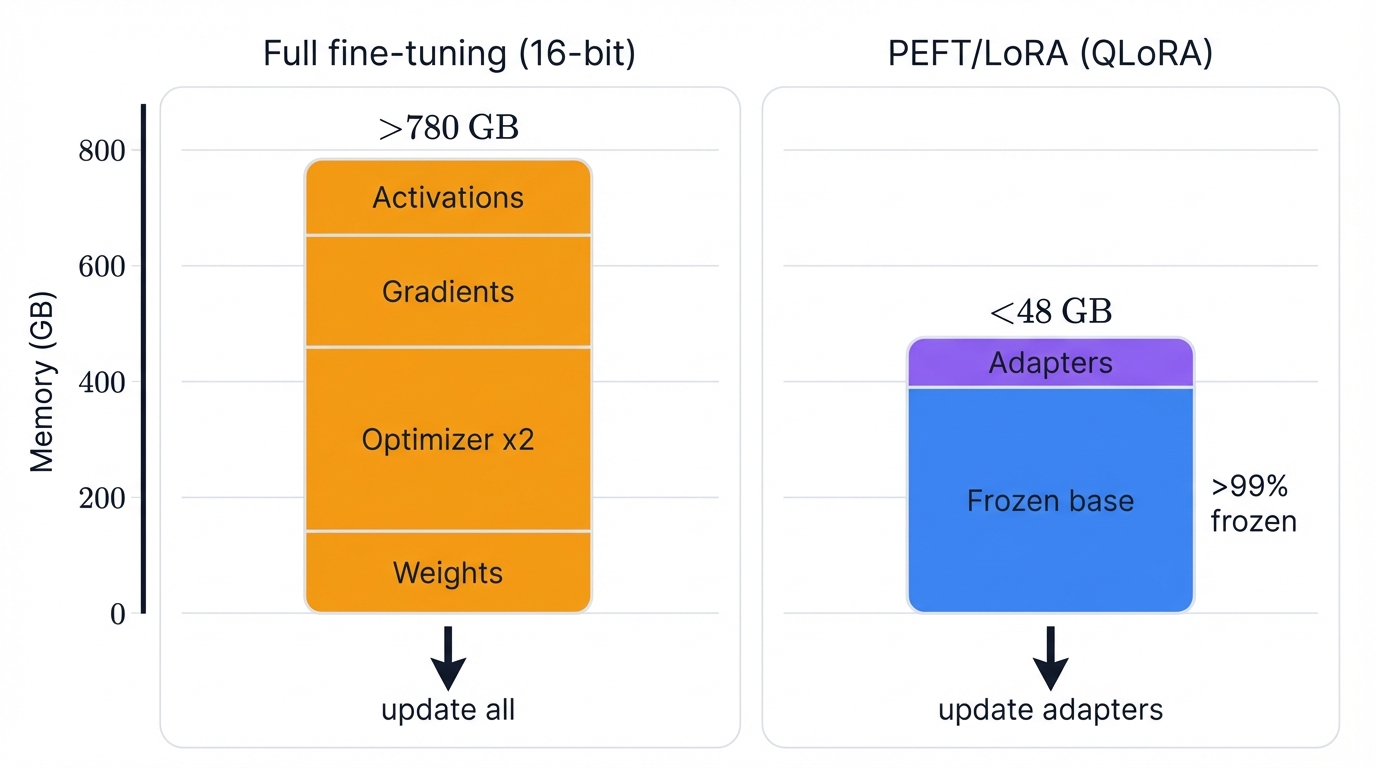
The requirements? Staggering. Fine-tuning a 65-billion-parameter model in standard 16-bit precision demands over 780 GB of GPU memory—a figure that exceeds even the most advanced single-GPU systems available today, and the memory burden extends far beyond storing the model's weights themselves into the dynamic allocations required during training that make the problem exponentially worse.
Consider the optimizer states. Popular optimizers like Adam store two additional floating-point values for each model parameter—momentum and variance estimates that enable sophisticated gradient descent. The activation gradients computed during the backward pass add another massive layer to the memory footprint. Net result? You're looking at triple or quadruple the memory needed compared to the model's static size alone.
Beyond hardware constraints lie methodological landmines. Catastrophic forgetting tops the list—a phenomenon where models, while specializing on narrow datasets, lose the vast general knowledge acquired during pre-training, and when your fine-tuning dataset lacks diversity, the model's high capacity becomes a liability, leading to overfitting and poor generalization on unseen data. These financial and technical barriers historically limited state-of-the-art customization to well-funded research labs and corporations.
The Emergence of Parameter-Efficient Fine-Tuning (PEFT) as a New Paradigm
Enter PEFT. Revolutionary concept. Freeze the vast majority of pre-trained parameters—often over 99% of the total—and focus training on a small, targeted subset of new or existing parameters.
The benefits multiply rapidly. Dramatically reduced trainable parameters translate to drastically lower computational and memory requirements, making fine-tuning feasible on commodity hardware. Costs plummet. Training times shrink. But the real genius lies in preserving the core pre-trained model intact, which inherently mitigates catastrophic forgetting and maintains general capabilities.
This enables a modular, scalable approach to model management that transforms the economics of AI deployment. Instead of storing complete multi-gigabyte copies for each task, you maintain a single frozen base model plus a collection of small, task-specific adapter modules that swap in and out as needed—a paradigm shift with profound implications for MLOps and product strategy.
PEFT Categories: Several families exist. Additive methods like Adapter Tuning and Low-Rank Adaptation (LoRA) introduce new, trainable parameters into the architecture. Other approaches—Prompt Tuning and Prefix-Tuning—operate by learning continuous soft prompts prepended to the model's input or internal states, guiding behavior without modifying original weights.
Thesis Introduction: Positioning QLoRA as a Landmark Technique in Democratizing LLM Adaptation
QLoRA breaks new ground. Developed by researchers at the University of Washington, it combines an already efficient PEFT method—LoRA—with aggressive 4-bit quantization of the base model, pushing memory efficiency boundaries to unprecedented levels and democratizing the ability to fine-tune even the largest publicly available models.
The central achievement? Fine-tuning a 65-billion-parameter model on a single 48 GB GPU while preserving full 16-bit task performance. Previously considered infeasible. Now reality. This enables researchers, startups, and independent developers to build upon state-of-the-art foundation models without large-scale industrial infrastructure.
Economic Impact: QLoRA signifies more than technical optimization—it's a fundamental shift in the AI development lifecycle, moving from monolithic train-once-deploy-statically models to dynamic base-model-plus-specialization architecture. This decoupling of general knowledge from specialized skill has profound implications, enabling a marketplace of skills where a single centrally-hosted base model augments dynamically with different QLoRA adapters on-the-fly to serve diverse needs, dramatically reducing storage and serving costs.
But we must maintain critical perspective. While efficiency is undeniable, the claim of perfect performance equivalence with full fine-tuning deserves scrutiny. Subsequent research reveals that PEFT solutions exhibit subtle but important structural and behavioral differences, particularly concerning out-of-distribution generalization and catastrophic forgetting, which this report will examine exhaustively to provide balanced analysis of QLoRA's trade-offs in the broader context of LLM adaptation.
Foundational Principles: The Convergence of Quantization and Low-Rank Adaptation
QLoRA's ingenuity lies in clever integration. Not a single invention but the fusion of two powerful pre-existing concepts—quantization and low-rank adaptation—from model compression and efficient training fields.
Deep Dive into Quantization: Theory and Practice
Quantization compresses models. It reduces memory footprint and computational requirements by converting weights and activations from high-precision formats to lower-precision ones—conceptually analogous to image or audio compression where information uses fewer bits. In LLMs, this typically means moving from 32-bit floating-point (FP32) or 16-bit (FP16) to 8-bit or 4-bit integer formats (INT8 or INT4).
Mechanics of Quantization
At quantization's core sits a mapping function. It projects values from continuous, high-precision ranges to discrete, low-precision sets. Common affine quantization schemes express this elegantly:
x_q = round(x / S) + Z
# Where:
# x = original high-precision value (e.g., in FP32)
# S = floating-point scaling factor
# Z = zero-point (integer that maps 0.0 to quantized representation)
# Dequantization reverses this:
x = S * (x_q - Z)Outliers pose a significant challenge. A single large-magnitude weight drastically increases the absolute maximum value, skewing the scaling factor S and forcing the majority of weights—typically clustered around zero—into a tiny portion of the available low-precision range, leading to substantial information loss and severe performance degradation.
Block-wise quantization mitigates this. The input tensor flattens and divides into contiguous blocks of fixed size (64 or 128 values), with each block quantized independently using its own scaling factor and zero-point. This localizes outlier impact to specific blocks, preserving quantization precision for the rest.
The Inherent Trade-off
Quantization's primary advantage? Dramatic model size reduction. Moving from FP16 to INT4 theoretically offers 4x memory compression. Smaller size yields faster inference—less data movement from memory to processing units reduces bandwidth bottlenecks.
But efficiency costs accuracy. The conversion to lower-precision data types is inherently lossy—quantized values only approximate original weights, potentially degrading model accuracy and predictive performance. The central challenge: devise mapping schemes that minimize performance drops while maximizing compression.
Deep Dive into Low-Rank Adaptation (LoRA)
LoRA builds on a powerful observation. The change in model weights during task adaptation has low intrinsic rank. What does this mean? While the weight update matrix ΔW matches the original weight matrix W in high-dimensional shape, the information it contains compresses effectively into much lower-rank matrices—complex, high-dimensional adjustments decompose into simpler, low-dimensional representations without significant performance loss.
Mathematical Formulation and Operational Mechanics
Instead of learning the large ΔW matrix directly, LoRA represents updates as products of two smaller, low-rank matrices:
ΔW = B @ A
# Where:
# W ∈ R^(d×k) = original weight matrix
# B ∈ R^(d×r) = low-rank matrix 1
# A ∈ R^(r×k) = low-rank matrix 2
# r = rank (r ≪ min(d,k))
# During fine-tuning, the original pre-trained weights W₀ are frozen
# Only parameters of B and A are trainable
# Forward pass through LoRA-adapted layer:
y = W₀x + BAxThe parameter reduction is dramatic. Trainable parameters drop from d×k to (d+k)×r. Consider a typical transformer layer where d=1000 and k=5000—the original weight matrix contains 5 million parameters, but LoRA adaptation with rank r=8 requires training only (1000+5000)×8=48,000 parameters, a reduction exceeding 100x for that single layer.
A significant deployment advantage emerges: adapters merge back into original weights. Once training completes, compute the product BA to form the final ΔW matrix, add it to original weight matrix W₀ to produce a new fine-tuned weight matrix W' = W₀ + BA, and you have a merged model with identical architecture and parameter count as the original, introducing zero additional inference latency compared to fully fine-tuned models.
Theoretical Foundation: LoRA's effectiveness isn't merely empirical trickery—it appears fundamental to over-parameterized models. Initial pre-training guides models into parameter space regions highly effective for general language understanding. Task adaptation doesn't require drastic, arbitrary shifts to new regions but small, targeted adjustments along low-dimensional manifolds embedded within the larger parameter space. The low-rank matrices B and A effectively define bases for these adaptable subspaces.
The Core Architecture of QLoRA
QLoRA introduces three innovations working in concert. 4-bit NormalFloat (NF4), a specialized data type for model weights. Double Quantization (DQ), compressing quantization metadata itself. Paged Optimizers, managing dynamic memory during training. Together? Unprecedented memory efficiency.
4-bit NormalFloat (NF4): An Information-Theoretically Optimal Data Type
Motivation for a Specialized Data Type
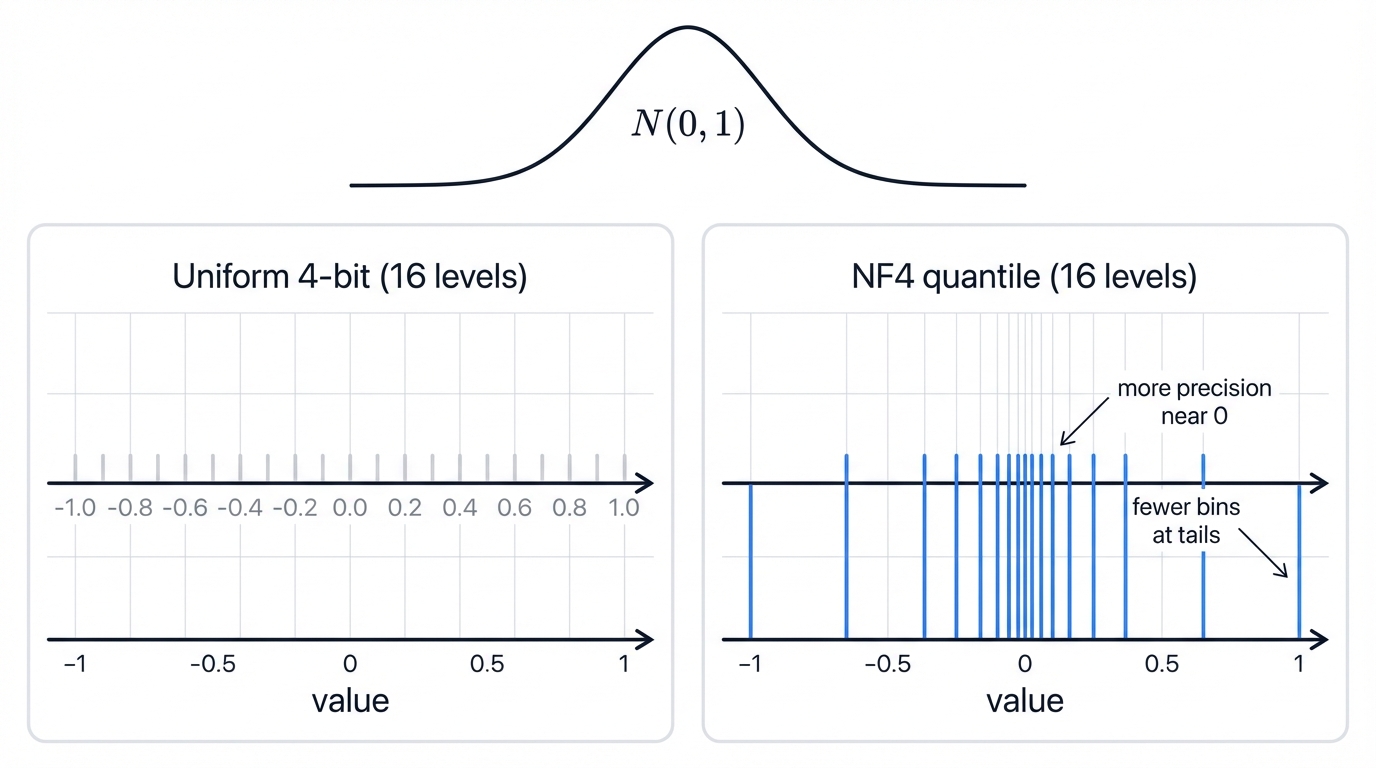
Pre-trained neural network weights aren't uniformly distributed. They follow zero-centered normal (Gaussian) distributions. Standard quantization methods using uniformly spaced quantization levels—standard 4-bit floats or integers—prove ill-suited for this data distribution.
Uniform quantization allocates representational capacity equally across the entire numerical range, wasting quantization levels on distribution tail ends where few weights exist while simultaneously lacking necessary precision around the dense center near zero where most weights concentrate—fundamentally inefficient for normally distributed data.
The NF4 Mechanism
QLoRA introduces 4-bit NormalFloat (NF4). Specifically designed for normally distributed data. Based on Quantile Quantization—define quantization bin boundaries such that each bin contains equal numbers of values from the target distribution. For NF4, that target is the standard normal distribution N(0,1).
The process takes theoretical quantiles of the standard normal distribution and uses them to define the 16 (2⁴) possible values the 4-bit data type can represent, resulting in an asymmetric set with more quantization levels clustered densely around zero and progressively fewer, more widely spaced levels towards the extremes of -1 and 1—providing higher precision exactly where neural network weights need it most, minimizing average quantization error.
Performance and Optimality
Empirical results demonstrate NF4's superiority. It significantly outperforms both 4-bit floating-point (FP4) and 4-bit integer (Int4) quantization schemes. On various academic benchmarks, NF4-quantized models matched 16-bit counterpart performance, whereas FP4 or Int4 models suffered noticeable degradation. The authors describe NF4 as information-theoretically optimal for normally distributed data because its structure purpose-builds to represent that specific probability distribution with minimum information loss for a given bit count.
Double Quantization (DQ): Compressing the Compression Metadata
The Overhead of Block-wise Quantization
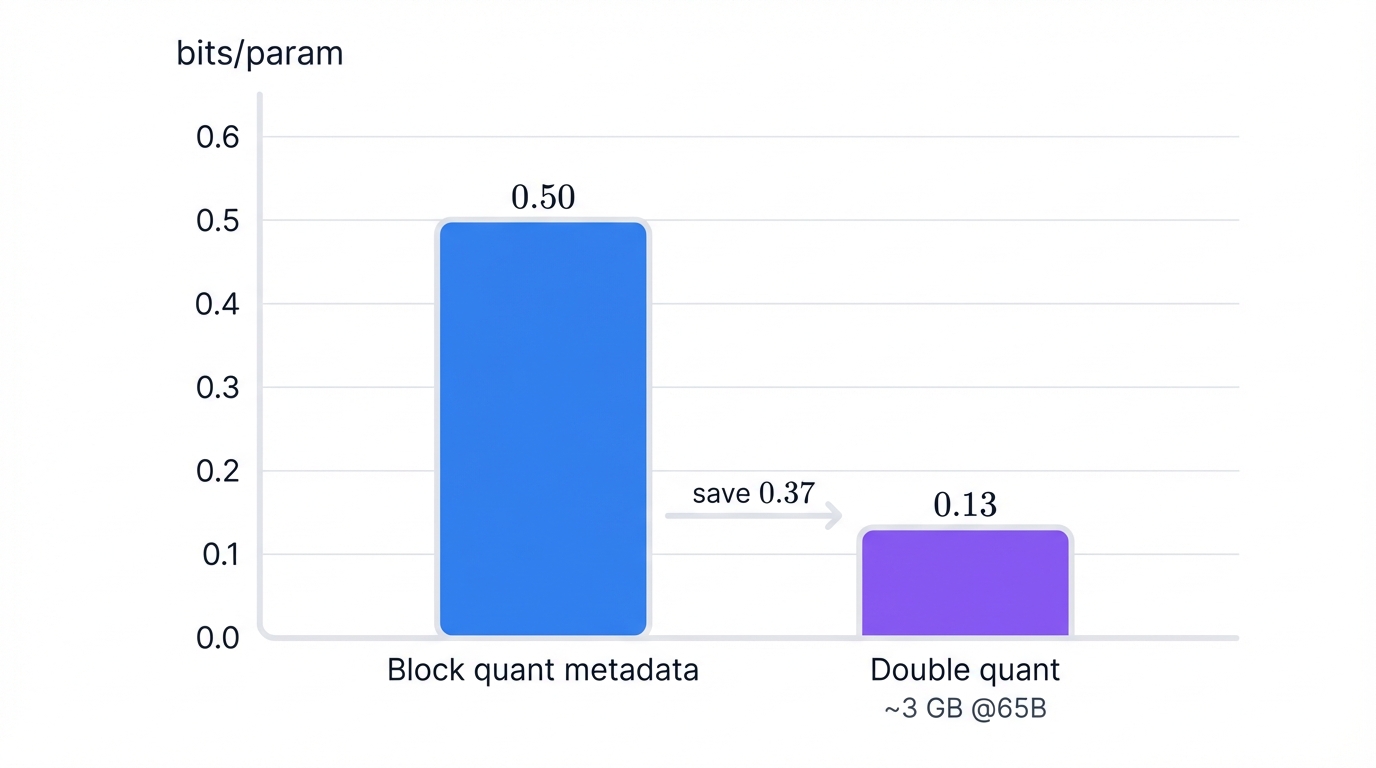
Block-wise quantization maintains precision but introduces non-trivial memory overhead. For each weight block (64 parameters), a corresponding quantization constant or scaling factor must be stored, typically in high-precision format like 32-bit float (FP32) to accurately reconstruct original weight values during dequantization.
This metadata accumulates. For a 65-billion-parameter model using block size 64, scaling factor memory calculates as (32 bits / 64) = 0.5 bits per parameter—for a 65B model, approximately 4 GB additional overhead, significant when operating at hardware limits.
The Double Quantization Solution
QLoRA introduces Double Quantization (DQ). Clever technique: quantize the quantization constants themselves. The process works as follows:
# First round of quantization on model weights
# produces c₁ scaling factors (let's call them s₁)
# Second round of quantization on s₁ scaling factors
# - Treat s₁ as a new input tensor
# - Quantize using 8-bit floats (FP8) with larger block size (e.g., 256)
# - Produces second-level scaling factors (c₂) and quantized first-level constants
# Memory savings:
# From: 0.5 bits/param
# To: (8/64) + (32/(64×256)) ≈ 0.127 bits/param
# Saves ~0.37 bits/param = ~3 GB for 65B modelThis second quantization pass significantly reduces quantization metadata memory footprint. QLoRA authors report this technique saves approximately 0.37 bits per parameter for 65B models, translating to roughly 3 GB memory reduction without measurable performance degradation.
Paged Optimizers: Managing Memory Spikes in Training
The Challenge of Dynamic Memory Usage
Even with heavily compressed base model weights, fine-tuning involves dynamic memory allocations causing sudden, large spikes in GPU memory usage. These spikes primarily occur during the backward pass when gradients compute for all trainable parameters, and during optimizer update steps when the optimizer (like Adam) accesses internal states—momentum and variance estimates. For long input sequences or larger batch sizes, these transient memory demands easily exceed available VRAM, triggering out-of-memory (OOM) errors that crash training processes.
The Paged Optimizer Mechanism
QLoRA introduces Paged Optimizers to handle memory spikes gracefully. This technique leverages NVIDIA's CUDA Unified Memory feature, allowing automatic data migration between CPU RAM and GPU VRAM.
Optimizer states allocate in special CPU memory known as pinned or paged memory—the operating system manages this memory in pages. When the GPU needs to perform optimizer updates, necessary pages automatically transfer from CPU RAM to GPU VRAM. If the GPU runs out of memory during spikes, the Unified Memory manager automatically evicts less-recently-used pages from GPU back to CPU RAM to make space, preventing OOM crashes—analogous to computers using hard drives as virtual memory when physical RAM fills.
Impact on Training Stability and Efficiency
Paged Optimizers make fine-tuning significantly more robust. They allow practitioners to utilize hardware resources to absolute limits, enabling larger batch sizes and longer sequence lengths than otherwise possible—critical for certain tasks. Recent profiling studies on consumer-grade GPUs found paged optimizers can improve training throughput up to 25% by enabling more efficient batching strategies.
The Integrated QLoRA Process
QLoRA's three innovations aren't isolated components. They form a cohesive system designed for maximum memory efficiency. The overall process summarizes as follows:
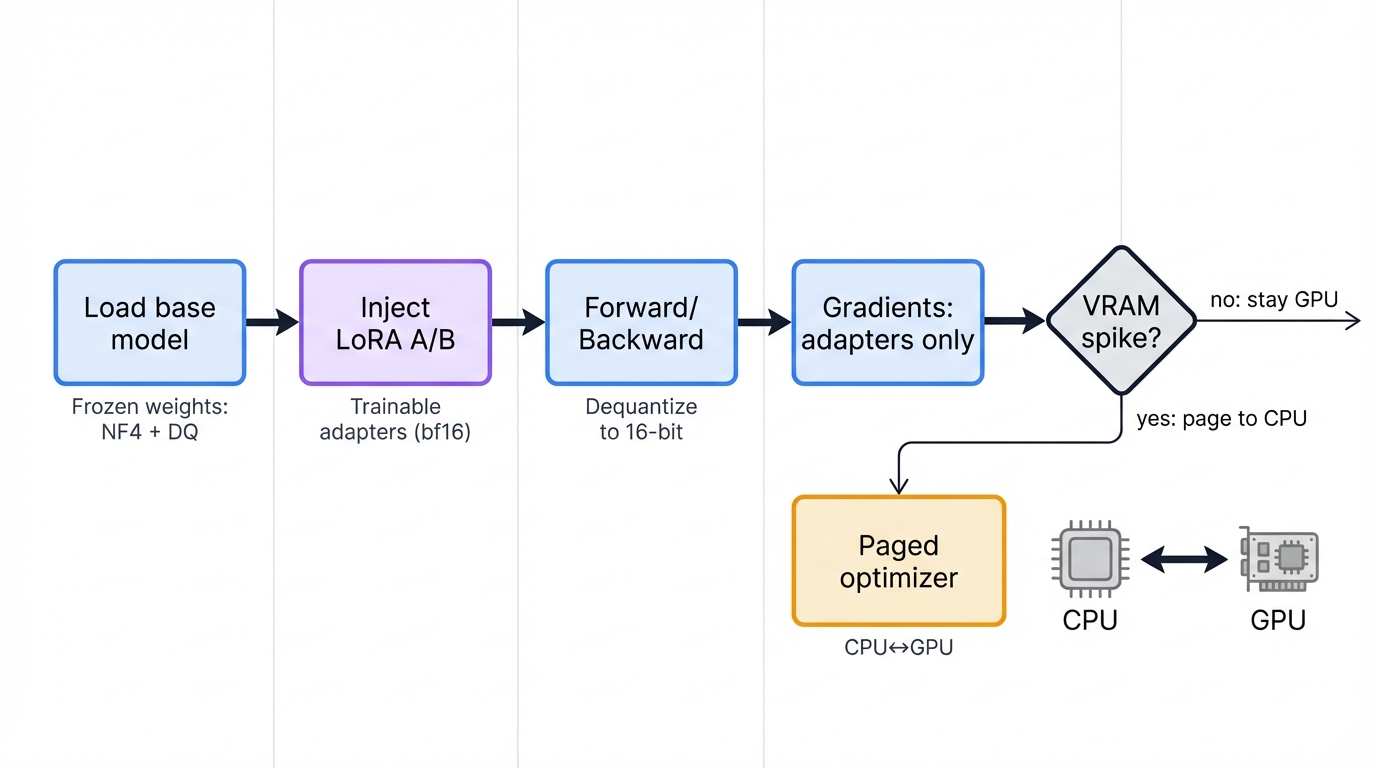
- Model Loading: A pre-trained LLM loads, but weights immediately quantize to 4-bit NormalFloat (NF4). Quantization constants themselves also quantize using Double Quantization. The entire base model then freezes
- Adapter Injection: Small, trainable LoRA adapter matrices (A and B) inject into desired layers—commonly attention layers. These adapters maintain higher-precision computation data types like 16-bit BrainFloat (bfloat16)
- Forward and Backward Pass: During training, for each forward and backward pass, 4-bit base model weights dequantize on-the-fly to 16-bit computation data type. Computations perform in this higher precision
- Gradient Update: Crucially, gradients only compute and backpropagate for LoRA adapter parameters. These gradients flow through dequantized 16-bit base model weights, allowing adapters to learn in full model context, but base model weights themselves never update
- Optimizer Step: The optimizer, managed by the Paged Optimizer system, updates only bfloat16 LoRA weights, paging states between CPU and GPU memory as needed to prevent OOM errors
Holistic Design: This integrated approach demonstrates holistic memory optimization strategy. It focuses not solely on reducing static model size but engineers management of the entire memory lifecycle of fine-tuning—from static storage to dynamic, transient allocations. This comprehensive design explains why QLoRA achieved efficiency breakthroughs surpassing previous methods that often focused on only one memory challenge aspect.
Empirical Performance and Applications
QLoRA's theoretical efficiency gains substance through extensive empirical results and rapidly growing practical applications. This section reviews benchmark performance from the original paper and surveys dominant use cases where QLoRA became standard.
Benchmark Analysis: Achieving Parity with 16-bit Performance
The Guanaco Model Family and State-of-the-Art Performance
To demonstrate method effectiveness, QLoRA authors trained Guanaco—a family of LLaMA models fine-tuned on the OpenAssistant (OASST1) dataset. The results? Striking. Guanaco-65B, trained using QLoRA, surpassed all previously available open-source models on the Vicuna benchmark, a standard for evaluating chatbot performance, achieving 99.3% of ChatGPT (GPT-3.5) performance at the time—establishing QLoRA as capable of producing state-of-the-art results.
Revolutionary Memory Footprint Reduction
QLoRA's most cited achievement: dramatic hardware requirements reduction. The paper demonstrated fine-tuning a 65-billion-parameter LLaMA model—normally requiring over 780 GB GPU VRAM with standard 16-bit fine-tuning—accomplished with less than 48 GB VRAM using QLoRA, bringing the task within reach of a single high-end professional GPU like an NVIDIA A100. Similarly, 33B parameter models could fine-tune on single 24 GB GPUs, common hardware in many research labs. This radical memory footprint reduction democratized access to large-scale model adaptation.
Performance Equivalence on Academic Benchmarks
A critical claim: this extreme memory saving came with no performance trade-off. Across academic benchmark suites including GLUE for natural language understanding and MMLU for multitask accuracy, 4-bit QLoRA using NF4 matched performance of both 16-bit full fine-tuning and standard 16-bit LoRA fine-tuning. Pivotal finding. It suggested any performance degradation from aggressive 4-bit quantization of the base model could be fully compensated for and recovered during adapter fine-tuning.
Feasibility on Consumer Hardware
QLoRA benefits extend beyond high-end professional hardware to consumer-grade GPUs. A recent systematic case study profiled QLoRA fine-tuning efficiency on a single NVIDIA RTX 4060 GPU with just 8 GB VRAM. The study found QLoRA makes fine-tuning not only possible but efficient on modest hardware. Paged optimizers proved particularly crucial, enabling training of models with long context lengths (2048 tokens)—impossible with standard optimizers due to memory spikes. This confirms QLoRA's role making LLM fine-tuning accessible to individual researchers, students, and hobbyists.
Dominant Use Cases and Implementation Patterns
QLoRA's accessibility and effectiveness led to rapid adoption across applications. Implementation is streamlined by mature open-source library ecosystems, primarily from Hugging Face—transformers for model access, peft (Parameter-Efficient Fine-Tuning) for configuring LoRA adapters, and bitsandbytes for underlying 4-bit quantization and computation kernels.
Instruction-Tuning and Chatbot Development
One of the most common QLoRA applications: instruction-tuning. This involves fine-tuning base LLMs on high-quality instruction-response pair datasets to create more helpful, responsive chatbots. Datasets like Alpaca, Dolly, and OASST1 are frequently used. Notable example: the CARE chatbot, a multi-domain assistant for healthcare, banking, and telecommunications, developed by fine-tuning a base model with QLoRA—it achieved strong performance on medical question-answering benchmarks, demonstrating the ability to create specialized, high-performing conversational agents with this technique.
Domain-Specific Adaptation
QLoRA excels at imbuing general-purpose LLMs with deep, specialized knowledge for professional domains—finance, law, medicine. By fine-tuning on domain-specific text corpora, organizations create models understanding unique terminology, context, and data. A practical case study demonstrated this by fine-tuning Falcon-7B on the Alpaca-Finance dataset—the resulting model provided nuanced, insightful answers to complex financial questions about retirement planning and portfolio diversification. This capability allows enterprises to build private GPT models trained on proprietary, confidential data without exposing that data to third-party APIs.
Specialized Task Fine-Tuning
Beyond general knowledge and conversation, QLoRA proves effective for training models to perform specific, structured generation tasks. Prominent example: text-to-SQL generation. Detailed tutorials show how fine-tuning Google's Gemma model on synthetic datasets of natural language questions and corresponding SQL queries enables QLoRA-tuned models to translate user requests into executable database queries—a valuable capability for data analysis tools.
Iterative Development: QLoRA's impact extends beyond making fine-tuning possible—it fundamentally makes it iterative. Prohibitive cost and time of full fine-tuning often make it a high-stakes, one-shot endeavor discouraging experimentation. QLoRA reduces training time for massive 65B models to just 24 hours on single GPUs, and for smaller models, mere hours or minutes. This dramatic acceleration enables fail-fast development culture. Practitioners can afford dozens of experiments, rapidly testing different datasets, architectures, and hyperparameters to discover optimal configurations for specific use cases.
The Illusion of Equivalence: A Critical Comparison with Full Fine-Tuning
Initial QLoRA findings celebrated matching 16-bit full fine-tuning (Full FT) performance. Subsequent research painted a more nuanced picture. The equivalence claim holds true primarily for in-distribution performance—on specific tasks and data distributions models were fine-tuned on. But examine out-of-distribution generalization, robustness, and underlying weight structure? Significant differences between LoRA-based methods and Full FT emerge. Some researchers label their equivalence an illusion.
The Phenomenon of "Intruder Dimensions"
A key finding from the paper "LoRA vs Full Fine-tuning: An Illusion of Equivalence" comes from spectral analysis of model weight matrices. Using singular value decomposition (SVD), researchers analyzed weight update structures learned by both LoRA and Full FT.
The analysis revealed structural differences. LoRA learns updates dramatically different from Full FT. Specifically, LoRA introduces new, high-ranking singular vectors into weight matrices approximately orthogonal to original, pre-trained model singular vectors—termed intruder dimensions. In contrast, Full FT weight updates remain spectrally similar to pre-trained models, refining existing singular vectors rather than creating new, orthogonal ones. This suggests LoRA's adaptation is a stark, low-rank shift in new directions, while Full FT performs subtle, high-rank adjustments across the model's entire existing feature space.
These structural differences have profound behavioral consequences. Strong intruder dimensions causally link to poorer out-of-distribution generalization. LoRA-tuned models with these dimensions tend to perform worse on pre-training distributions—indicating more forgotten original knowledge—and prove less robust in continual learning scenarios where tasks learn sequentially. Causal intervention experiments showed that manually scaling down singular values associated with intruder dimensions after training significantly improves model generalization and reduces forgetting, with only minimal drops in fine-tuning task performance.
A Nuanced View on Catastrophic Forgetting
Common wisdom held that PEFT methods like LoRA largely solve catastrophic forgetting by leaving vast majorities of base model weights frozen. Recent research indicates this oversimplifies.
The paper "Scaling Laws for Forgetting When Fine-Tuning Large Language Models" demonstrates LoRA still suffers from catastrophic forgetting. The study identified strong inverse linear relationships: the better LoRA-tuned models perform on new tasks, the more they forget pre-training knowledge. Forgetting amount scales as power laws with both trainable parameter numbers (LoRA rank) and training update steps.
A complementary, crucial perspective comes from the paper "LoRA Learns Less and Forgets Less" by Biderman et al., framing the comparison as fundamental trade-offs. In many scenarios, particularly data-rich ones like continued pre-training on code or math datasets, LoRA learns less on target tasks, substantially underperforming Full FT. However, this couples with forgetting less source domain knowledge. Full FT, by contrast, achieves higher performance on new tasks more sample-efficiently but does so at the cost of forgetting more original training. LoRA rank r acts as a control knob for this trade-off: lower ranks learn and forget less, while higher ranks close performance gaps with Full FT but start forgetting nearly as much.
What Is Lost: Trade-offs of QLoRA vs. Full Fine-Tuning
Choosing between QLoRA and Full FT isn't merely about available hardware. It's a strategic decision involving complex trade-off sets. Using QLoRA, while offering immense efficiency benefits, entails sacrificing certain performance and flexibility aspects that Full FT retains.
Conceptual Framework: This conceptualizes as trade-offs between deep knowledge integration (Full FT) and modular skill addition (QLoRA). Full fine-tuning resembles students deeply studying new subjects, integrating them into core world understanding—slow, effortful processes, but resulting knowledge is robust, flexible, and well-generalized. However, intense focus can cause forgetting or de-prioritizing older, less relevant knowledge. QLoRA, on the other hand, resembles giving students specialized calculators for specific problem types—students (frozen base models) don't change fundamental reasoning, but they can now use tools (LoRA adapters) to solve new problems perfectly.
| Feature | Full Fine-Tuning | LoRA | QLoRA |
|---|---|---|---|
| Mechanism | Updates all model weights | Freezes base model, adds low-rank updates | Quantizes base, adds low-rank updates |
| Trainable Parameters | ~100% | 0.1% - 5% | 0.1% - 5% |
| Memory Usage (VRAM) | Very High (16+ GB per 1B params) | Low (2+ GB per 1B params) | Very Low (0.5+ GB per 1B params) |
| Training Speed | Slow | Fast | Slightly slower than LoRA (dequantization) |
| Inference Latency | None | None (if adapter merged) | None (if adapter merged) |
| In-Distribution Performance | Highest potential for complex tasks | Near-parity with Full FT for many tasks | Near-parity with 16-bit methods |
| Out-of-Distribution Generalization | Strongest | Weaker (intruder dimensions) | Weaker, similar to LoRA |
| Catastrophic Forgetting | Highest risk | Lower risk ("forgets less") | Lower risk, similar to LoRA |
| Primary Advantage | Maximum performance, flexibility, generalization | High efficiency, no inference latency | Unparalleled memory efficiency, consumer hardware |
| Primary Disadvantage | Extremely high resource requirements | Can underperform Full FT on complex tasks | Potential minor precision loss, slower than LoRA |
The Broader PEFT Ecosystem: Alternatives and Evolutions
QLoRA, while highly influential, belongs to a broader Parameter-Efficient Fine-Tuning ecosystem. Understanding its position relative to other methods provides a more complete picture of available tools for LLM adaptation. These methods aren't direct competitors but different points on efficiency-versus-expressive-power spectrums, each intervening in Transformer architecture uniquely.
Comparative Analysis of Alternative PEFT Methods
Adapter Tuning
One of the earliest PEFT approaches. Adapter Tuning inserts small, trainable neural network modules—adapters—between frozen pre-trained model layers. These adapters typically have bottleneck architectures: down-projection layers, non-linear activation functions, and up-projection layers, reducing trainable parameters. During fine-tuning, only newly inserted adapter module weights update. Highly modular. Effectively preserves pre-trained knowledge. But a key drawback: additional layers introduce extra forward pass computational steps, increasing inference latency—critical for real-time applications. LoRA is often viewed as more modern, efficient evolution, as its adapters merge back into original weights to eliminate this latency.
Prefix-Tuning
Prefix-Tuning operates differently. It doesn't modify model weights but influences activation states. This method learns small, continuous, task-specific parameter vectors called prefixes, prepended to keys and values at each attention layer of Transformer architecture. The prefix acts as task-specific context steering the model's attention mechanism to focus on relevant information for downstream tasks, all while LLM original parameters remain completely frozen. Prefix-Tuning has proven very effective for natural language generation tasks, offering good balances between parameter efficiency and expressive power, though recent work suggests its effectiveness can diminish on modern LLMs without architectural modifications.
Prompt Tuning
Prompt Tuning simplifies and increases parameter efficiency beyond Prefix-Tuning. Instead of adding prefixes to every layer, Prompt Tuning learns soft prompt embedding sets prepended only once to input embeddings at model beginnings. The least invasive PEFT method, often requiring training only a few thousand parameters. Extremely efficient in memory and storage terms. But limited intervention scope means it may not be powerful enough to adapt models for complex tasks requiring deeper internal representation modifications.
Architectural Taxonomy: The PEFT landscape resembles a toolbox where each technique represents different model adaptation strategies, operating on distinct Transformer architecture parts. Prompt and Prefix Tuning manipulate inputs and activations, guiding model focus. Adapter Tuning modifies architecture by inserting new computational blocks. LoRA and QLoRA directly manipulate model weights by re-parameterizing updates. This reveals clear trade-offs: manipulating inputs is cheapest and least disruptive but offers limited control. Modifying architecture provides more control but can add inference latency. Modifying weights offers most powerful control and no latency post-merge but can cause most significant changes to learned behavior.
| Method | Core Mechanism | Point of Intervention | Parameter Efficiency | Inference Latency Impact | Primary Advantage | Primary Disadvantage |
|---|---|---|---|---|---|---|
| Prompt Tuning | Learns soft prompt embeddings | Input Embedding Layer | Very High (<0.1%) | Minimal (longer input sequence) | Maximum parameter efficiency | Limited expressive power for complex tasks |
| Prefix-Tuning | Learns continuous prefixes for attention | All Self-Attention Layers | High (~0.1%) | Minimal (longer input sequence) | Good balance for generation tasks | May underperform on modern LLMs |
| Adapter Tuning | Inserts small bottleneck modules | Between Transformer Layers | High (~0.1-4%) | Moderate (adds sequential computation) | Highly modular; well-studied | Introduces inference latency |
| LoRA / QLoRA | Learns low-rank updates to weights | Weight Matrices (attention and FFN) | High (~0.1-5%) | None (if adapter merged) | High performance, no inference latency | Can alter behavior (intruder dimensions) |
The Next Generation: Variants and Improvements on QLoRA
QLoRA's groundbreaking success spurred subsequent research waves aimed at addressing limitations and further enhancing efficiency and performance. Several notable variants emerged:
- QDyLoRA (Quantized Dynamic LoRA): A key challenge when using LoRA: selecting optimal rank r. QDyLoRA addresses this by enabling efficient fine-tuning of models for ranges of pre-defined ranks simultaneously in single training passes. This allows practitioners to dynamically reconfigure models for lower or higher ranks after training without retraining
- IR-QLoRA (Information Retention QLoRA): This method focuses on improving quantized base model accuracy during LoRA fine-tuning. It introduces statistics-based Information Calibration Quantization to help quantized parameters better retain information from original weights, and finetuning-based Information Elastic Connection to improve interaction between frozen base models and trainable LoRA adapters
- QA-LoRA (Quantization-Aware LoRA): This approach seeks more synergistic relationships between quantization and adaptation processes. It addresses identified imbalances in degrees of freedom between quantization and adaptation by using group-wise operators, aiming to improve final performance of fine-tuned quantized models
- LQ-LoRA (Low-rank Plus Quantized LoRA): This technique proposes alternative decomposition. Instead of quantizing entire base weight matrices, it decomposes each matrix into high-precision low-rank components (which train, similar to LoRA) and fixed, memory-efficient quantized components. Authors claim this approach outperforms QLoRA, particularly at very aggressive, sub-3-bit quantization levels
These ongoing developments highlight clear field trends: moves towards making PEFT trade-offs more dynamic, controllable, and optimized for specific use cases, further refining tools available to practitioners.
Conclusion and Future Directions
Synthesizing the Role of QLoRA in the Modern LLM Landscape
Quantized Low-Rank Adaptation (QLoRA) stands as pivotal innovation in Large Language Model evolution. Its primary, most profound contribution? Radical democratization of LLM fine-tuning. By ingeniously combining 4-bit quantization with low-rank adaptation, QLoRA shattered prohibitive hardware barriers that once confined large-scale model customization to elite institutions. It made specializing multi-billion-parameter models computationally feasible on single, often consumer-grade GPUs, catalyzing innovation and experimentation surges across the entire AI community.
But QLoRA's journey illuminates a fundamental trade-off at model adaptation's heart. While delivering unparalleled memory efficiency and achieving performance on par with full fine-tuning for in-distribution tasks, this efficiency isn't costless. As this report detailed, solutions learned via LoRA-based methods are structurally different from full fine-tuning, potentially reducing out-of-distribution generalization, diminishing robustness in continual learning settings, and lowering expressive power ceilings for highly complex tasks. Choosing QLoRA isn't merely technical, dictated by hardware, but strategic, balancing efficiency against desired depth and robustness of model adaptation.
Practical Recommendations for Practitioners
Based on analysis presented, the following recommendations guide fine-tuning strategy choices:
Use QLoRA when:
- Resource constraints are paramount: The go-to choice for individuals, academic labs, or organizations with limited access to high-end, multi-GPU clusters
- The goal is rapid prototyping and iteration: QLoRA's speed and low cost enable extensive experimentation with different datasets, hyperparameters, and base models
- The task is well-defined and in-distribution: For adapting models to specific styles, formats (like JSON generation), or narrow domains with predictable inputs (customer service chatbots), QLoRA proves highly effective
- Multiple task-specific models are needed: QLoRA's small adapter footprint makes it ideal for creating and storing many specialized skills for single base models
Consider Full Fine-Tuning when:
- Maximum performance and robustness are non-negotiable: For mission-critical applications where out-of-distribution generalization is crucial, Full FT has potential to yield more robust, capable models
- The target domain is highly dissimilar to pre-training data: When adaptation requires fundamental shifts in model knowledge bases, updating all parameters' greater flexibility may be necessary
- Computational resources are not the primary constraint: If sufficient hardware access is available, Full FT remains the gold standard for deep knowledge integration
Explore other PEFT methods when:
- Extreme parameter efficiency is the only goal: For simplest tasks or most constrained environments, Prompt Tuning might suffice
- A balance for generative tasks is needed: Prefix-Tuning can offer compelling middle ground between Prompt Tuning simplicity and LoRA invasiveness
Future Research Trajectories
The parameter-efficient fine-tuning field continues evolving rapidly. Future research will likely focus on several key areas:
- Mitigating the Downsides of LoRA: A significant research thrust will be understanding and mitigating intruder dimensions' negative effects. This could involve developing new initialization strategies for LoRA matrices, introducing regularization techniques penalizing divergence from pre-trained model spectral properties, or designing methods to prune or dampen these dimensions post-training
- Dynamic and Hybrid PEFT Methods: The development of methods like QDyLoRA points towards futures of more dynamic, adaptive PEFT. Future techniques may allow models to automatically determine appropriate ranks or even switch between different PEFT strategies based on task complexity. Hybrid approaches combining different method strengths—for example, using soft prompts to provide high-level task context while using LoRA to adapt specific layers—may unlock new performance and efficiency levels
- Deepening Theoretical Understanding: While LoRA and QLoRA's empirical success is well-established, deeper theoretical foundations are still being built. Research will continue exploring why low-rank updates are so effective, the geometric properties of parameter spaces they navigate, and precise mathematical relationships between fine-tuning, forgetting, and generalization. More robust theory will enable design of more principled, effective PEFT methods in the future