Table of Contents
- 1. The New Interface Revolution
- 2. Zero-Shot Prompting: When AI Remembers Everything
- 3. Few-Shot Prompting: Learning Through Examples
- 4. Chain-of-Thought: Making Models Think Step-by-Step
- 5. Strategic Framework for Choosing Techniques
- 6. The Adversarial Frontier: When Prompts Become Weapons
- 7. Unintended Disclosures: When AI Leaks Secrets
- 8. The Bias in the Machine
- 9. Towards Responsible and Effective Prompting
The New Interface Revolution
Something fundamental shifted when Large Language Models arrived.
You no longer need Python or Java to make computers do complex work. Natural language became the interface. Talk to machines the way you talk to colleagues. This transformation created prompt engineering—the art and science of crafting inputs that guide AI toward accurate, safe outputs.
You're teaching machines through conversation. A dramatic departure from rigid syntax to nuanced instruction, mirroring the growing sophistication of these models themselves.
Your journey begins with Zero-Shot Prompting. Ask models to perform tasks based solely on existing knowledge. When that falls short, provide guidance through examples using Few-Shot Prompting. For the most complex challenges requiring multi-step logic, Chain-of-Thought (CoT) Prompting forces models to "think out loud," revealing reasoning step by step.
What You'll Learn: This comprehensive guide covers three foundational techniques that will transform how you work with AI. We start with basic strategies of Zero-Shot and Few-Shot prompting, examining their mechanics, applications, and trade-offs. Then we explore advanced reasoning capabilities of Chain-of-Thought prompting, followed by a practical framework to help you choose the right technique for each situation. Finally, we tackle critical security and ethical considerations—the vulnerabilities and biases that accompany these powerful tools.
Zero-Shot Prompting: When AI Remembers Everything
The "Ask, Don't Show" Approach
What is Zero-Shot prompting?
You present tasks to LLMs without providing examples of how to perform them. Models must rely entirely on vast pre-trained knowledge and their ability to generalize from that knowledge. You simply ask models to perform tasks, expecting them to understand and execute based on prior learning.
A pure test of adaptability and contextual understanding. No in-the-moment training. No guidance.
You bet on models connecting your requests to patterns they learned during training.
How Models Learn to Generalize at Scale
Zero-Shot performance isn't magic.
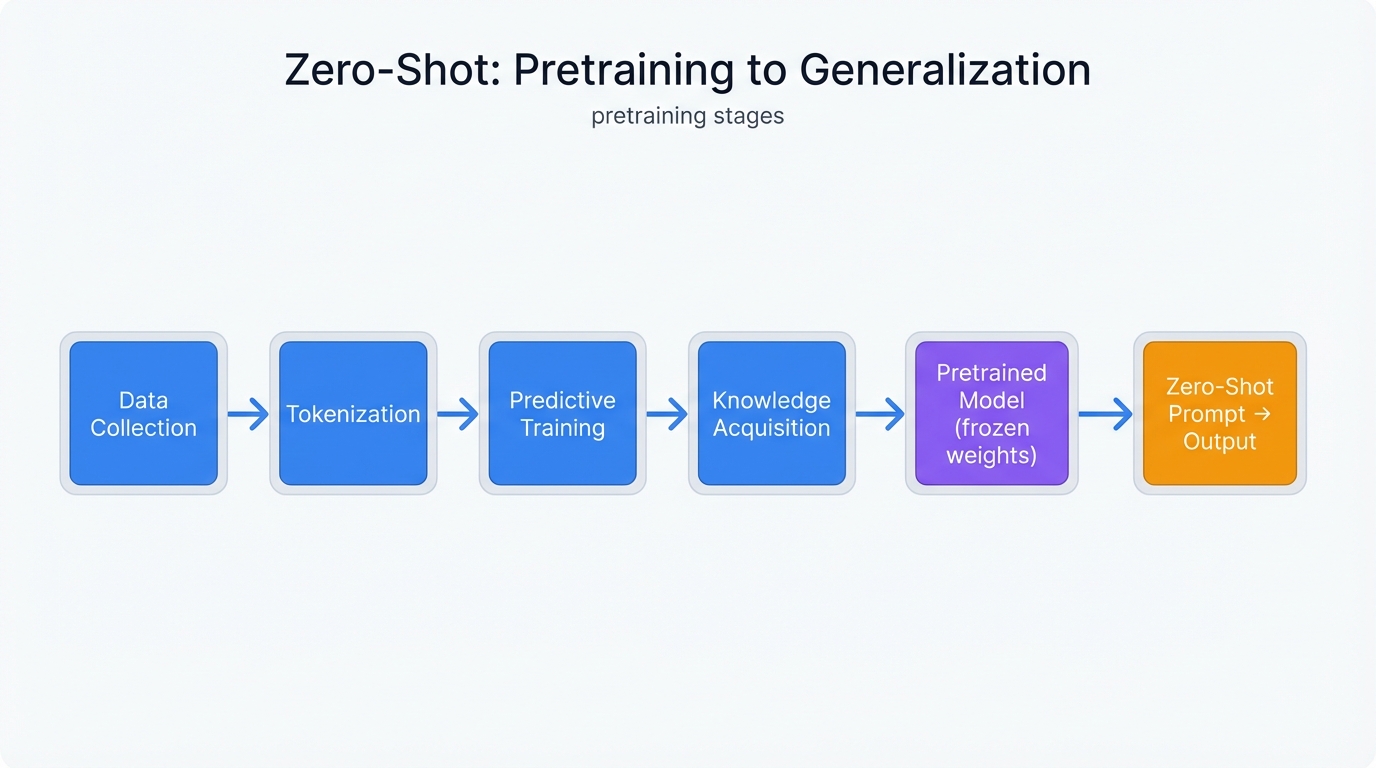
It emerges from intensive pre-training on massive, diverse datasets comprising hundreds of billions of words from the internet and other sources, and this training unfolds through several key stages that build the model's ability to understand and respond to new tasks without explicit instruction.
- Data Collection exposes models to different styles, topics, and domains through vast text corpora.
- Tokenization breaks raw text into smaller units called tokens—words, subwords, or characters that models can process.
- Predictive Training uses neural network architecture (typically Transformer) to train models on one simple objective: predict the next token in a sequence given the preceding tokens.
- Knowledge Acquisition involves repeatedly performing this predictive task at massive scale, learning intricate patterns in language including grammar, syntax, semantic relationships, and factual information about the world.
This process creates broad knowledge bases and sophisticated understanding of context. Models generalize to new, unseen tasks presented through Zero-Shot prompts.
Your experience with Zero-Shot prompting feels deceptively simple. You provide low-effort instructions like "Summarize this article," and models execute by drawing on knowledge built from trillions of data points and billions of parameters. You see only input and output. An illusion of effortless machine comprehension.
Yet this simplicity masks deep dependency.
On a complex, opaque system. You can't inspect or easily modify underlying model knowledge. When models fail or exhibit bias, you have limited recourse beyond iteratively rephrasing prompts. Ease of use comes at the cost of control and predictability.
Applications: Where Zero-Shot Excels
Zero-Shot prompting works best for general-purpose tasks where required knowledge likely exists within the model's training data.
Translation works seamlessly between languages models encountered during training. When you prompt "Translate the following English sentence to French: 'I am learning how to code,'" you get "J'apprends à coder." No translation pairs needed.
Sentiment Analysis leverages model understanding of positive and negative language. "Classify the text into neutral, negative or positive. Text: I think the vacation is okay" returns "Neutral," as models draw on countless examples of emotional expression they learned during training.
Summarization succeeds for general-interest articles or documents. "Summarize this legal document in simple terms for a layperson" produces concise summaries by identifying key points, applying patterns models learned from millions of similar summarization tasks.
General Question Answering retrieves information from model knowledge bases. "What large, predatory feline is known for its roar and its distinctive mane?" gets you "A lion"—models connecting your question to factual knowledge absorbed during training.
Content Generation produces creative or informational text from simple instructions. "Write a short intro about renewable energy benefits" generates relevant content by combining patterns from countless similar texts models encountered.
The Appeal of Simplicity and Speed
Why use Zero-Shot prompting?
Primary advantages center on efficiency and ease of use.
Time-Efficiency requires no time creating, curating, or formatting examples, making it the fastest way to interact with an LLM. You can test ideas, get quick answers, and prototype solutions immediately—switching seamlessly between translation, summarization, and analysis tasks without customization.
Flexibility and Versatility apply to vast arrays of general tasks. This makes Zero-Shot ideal for exploratory queries, rapid prototyping, and quick information retrieval.
Reduced Data Dependency eliminates the need for specialized, annotated datasets for each new task. This provides significant advantages for users with limited resources who want to leverage powerful AI capabilities immediately.
The Boundaries of General Knowledge
Despite its power, Zero-Shot prompting has significant limitations.
Particularly when tasks require precision or specialized knowledge.
Accuracy and Nuance suffer for complex or highly specific tasks. Zero-Shot prompts can produce less accurate or overly generalized results, as models may misinterpret request nuances without concrete examples to guide them. This makes Zero-Shot ill-suited for tasks demanding very specific output formats or structures.
Prompt Sensitivity creates unpredictable results. Model performance depends heavily on exact prompt phrasing—small, seemingly innocuous wording changes can lead to vastly different outputs. Finding the right prompt becomes trial and error.
Inherent Bias reflects training data directly. If that data contains societal biases, stereotypes, or misinformation, models reproduce them in Zero-Shot responses, as models have no external guidance to counter these embedded patterns.
Diagnostic Power: Zero-Shot prompts reveal model "instincts" because they provide no external guidance. This makes the technique a powerful diagnostic tool for developers and researchers who can probe baseline capabilities and inherent biases effectively.
Consider this example: "A CEO and their assistant walked into the room. She said..." If this consistently generates completions assuming the assistant is female, it reveals strong default gender bias from training data. You can assess model "out-of-the-box" safety and fairness before layering on more complex prompting strategies.
Few-Shot Prompting: Learning Through Examples
The "Show, Then Ask" Paradigm
Few-Shot prompting shifts the approach.
You guide LLM responses by providing a small number of examples—"shots"—of desired input-output patterns directly within prompts. This shifts from Zero-Shot's "ask, don't show" model to a "show, then ask" paradigm.
These examples serve as "in-context learning." Demonstrating expected format, style, tone, or logic. Models then emulate patterns to generate more accurate, appropriately structured responses for new, unseen inputs.
In-Context Learning Without Weight Updates
Understanding this point is critical.
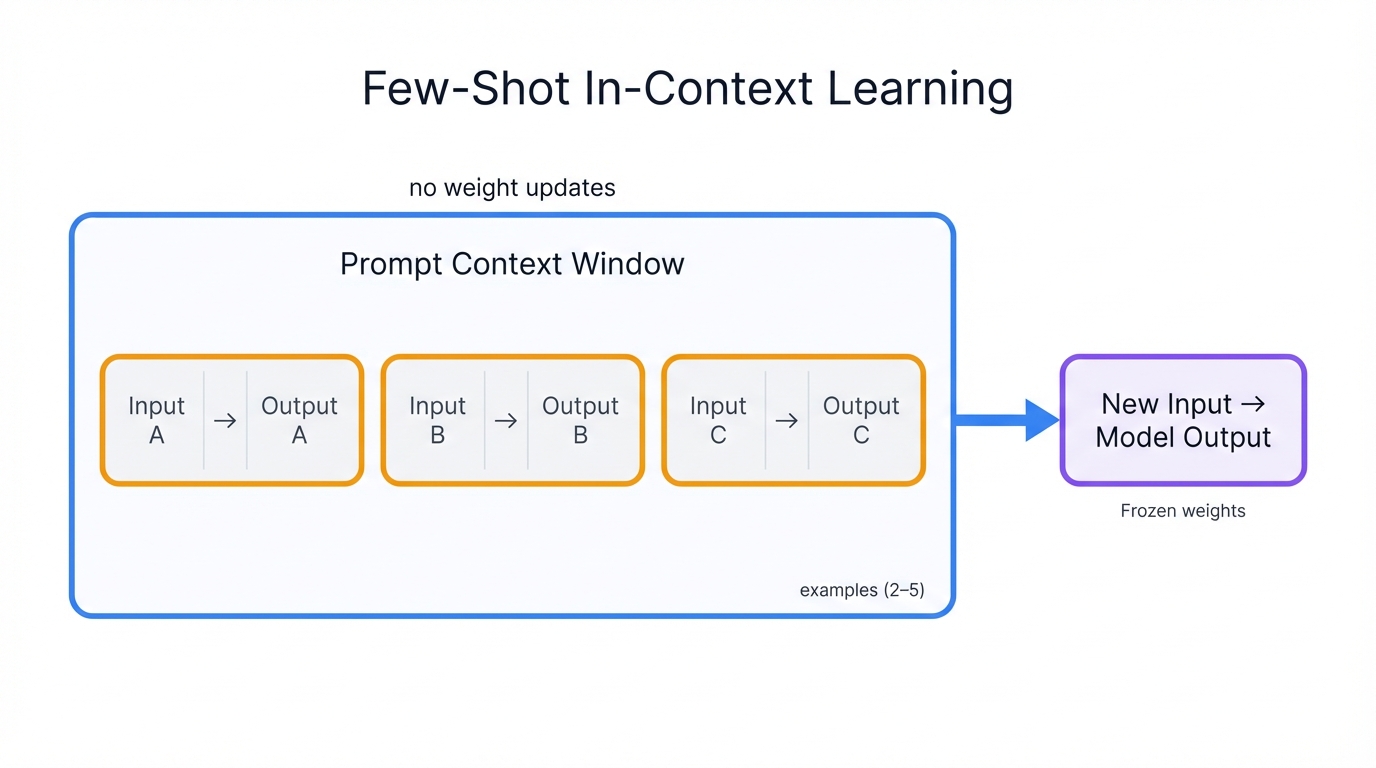
Few-Shot prompting is not model training or fine-tuning. The underlying parameters (weights) of LLMs never change during this process.
Instead, provided examples become part of the model's "context window"—the short-term memory it uses to process your current query, and by analyzing the structure and relationships between inputs and outputs in your examples, the model leverages its powerful, pre-trained pattern-recognition capabilities to identify patterns and then applies this understanding to new queries that follow.
At its core, Few-Shot prompting is sophisticated imitation. Models mimic demonstrated behavior.
Your New Role: This process elevates your role from simple user to temporary, in-context trainer. While not altering fundamental model knowledge, you curate a "micro-dataset" within prompts that directly and powerfully shapes immediate model behavior. The quality, diversity, and potential biases of your few examples have outsized impact on results, placing significant responsibility on you for the immediate fairness and accuracy of model output.
The Craft of Example Selection
Success in Few-Shot prompting depends almost entirely on the quality and structure of your provided examples.
Crafting effective shots requires crucial skills.
Relevance and Diversity demand examples directly relevant to your target task. Irrelevant examples confuse models and degrade performance. Your set should be diverse, covering different aspects, potential inputs, and even edge cases to help models generalize better rather than simply memorizing narrow patterns.
Clarity and Consistency require clear, unambiguous examples that maintain consistent formatting. If one example uses "Input:... Output:..." and another uses "Text:... Classification:...," the inconsistent structure makes it difficult for models to recognize patterns.
Optimal Number of Examples involves balancing trade-offs. Too few may not provide enough signal for models to learn patterns effectively. Too many can lead to "overfitting," where models mimic examples too closely, or can exceed model context window limits.
The optimal number often falls between two and five examples. But experimentation is key to finding the sweet spot for your specific task and model.
Applications: Where Few-Shot Shines
When does Few-Shot prompting excel?
In scenarios where Zero-Shot prompting falls short—tasks requiring nuance, specific formatting, or domain-specific adaptation.
Nuanced Text Classification succeeds when categories are subtle or non-obvious. Examples provide necessary clarity:
Classify the sentiment of the following customer reviews.
Example 1:
Review: "The food was delicious and the service was excellent."
Sentiment: Positive
Example 2:
Review: "The hotel room was clean but the wifi didn't work."
Sentiment: Mixed
Now classify this review:
Review: "I waited an hour for my order and when it arrived it was cold."
Sentiment:Specific Output Formatting forces models to adhere to strict data structures like JSON schemas:
Extract the product specifications into a JSON object with lowercase keys.
<EXAMPLE>
INPUT: Google Nest Wifi, network speed up to 1200Mpbs, 2.4GHz and 5GHz frequencies, WP3 protocol
OUTPUT: { "product":"Google Nest Wifi", "speed":"1200Mpbs", "frequencies": ["2.4GHz", "5GHz"], "protocol":"WP3" }
</EXAMPLE>
INPUT: Google Pixel 7, 5G network, 8GB RAM, Tensor G2 processor, 128GB of storage, Lemongrass.
OUTPUT:Code Generation produces higher-quality code when examples demonstrate best practices like docstrings, type hints, and error handling:
# Example 1
# Description: A function that adds two numbers.
def add(a: int, b: int) -> int:
"""Adds two integers and returns the result."""
return a + b
# Example 2
# Description: A function that calculates the factorial of a number, with input validation.
def factorial(n: int) -> int:
"""Calculates the factorial of a non-negative integer."""
if not isinstance(n, int) or n < 0:
raise ValueError("Input must be a non-negative integer.")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return resultMatching Tone and Style enables businesses to use examples of existing marketing copy to guide LLMs toward generating new content aligned with their brand voice.
Precision, Control, and Adaptation
Few-Shot prompting's primary benefits?
Increased precision and control.
Enhanced Accuracy emerges when relevant examples help models better understand specific task requirements, leading to more accurate, relevant outputs—especially for complex problems where Zero-Shot falls short.
Task-Specific Adaptation allows general-purpose foundation models to rapidly adapt to specialized tasks without resource-intensive fine-tuning. This capability makes Few-Shot prompting a crucial bridge between general and specialized AI, letting you apply large models to vast arrays of niche problems where full fine-tuning isn't economically feasible.
Greater Control over Output gives you fine-grained control over output format, style, and structure—essential for integrating LLM outputs into automated workflows where consistency matters.
The Responsibility of the Prompt Engineer
While powerful, Few-Shot prompting introduces new challenges.
And responsibilities.
Time-Consuming Curation requires significant upfront effort and preparation to craft high-quality, diverse, well-formatted examples. You become responsible for creating effective training material.
Risk of Overfitting occurs when models overly mimic specific styles or quirks of your provided examples, limiting creativity and ability to generalize to new inputs that deviate from demonstrated patterns.
Bias Amplification makes models highly susceptible to biases present in your examples. This manifests in several dangerous ways:
- Majority Label Bias emerges when examples disproportionately feature one category or label. Models develop bias toward predicting that label, regardless of new input content.
- Recency Bias affects some models that give more weight to the last examples they see in prompts. If your final few examples are all of one type, this can skew model predictions toward that pattern.
Chain-of-Thought: Making Models Think Step-by-Step
Defining the Step-by-Step Reasoning Process
Chain-of-Thought (CoT) prompting is an advanced technique.
Designed to improve LLM reasoning capabilities on complex, multi-step problems. Instead of producing direct, final answers, CoT encourages models to break problems into sequential, intermediate reasoning steps that lead to solutions.
This method mirrors human cognitive processes, where we solve complex problems by decomposing them into smaller, manageable parts, and the model is prompted to "think out loud," articulating its logical progression from problem to answer.
Decomposing Complexity to Improve Accuracy
Standard prompting (both Zero-Shot and Few-Shot) asks models for direct answers.
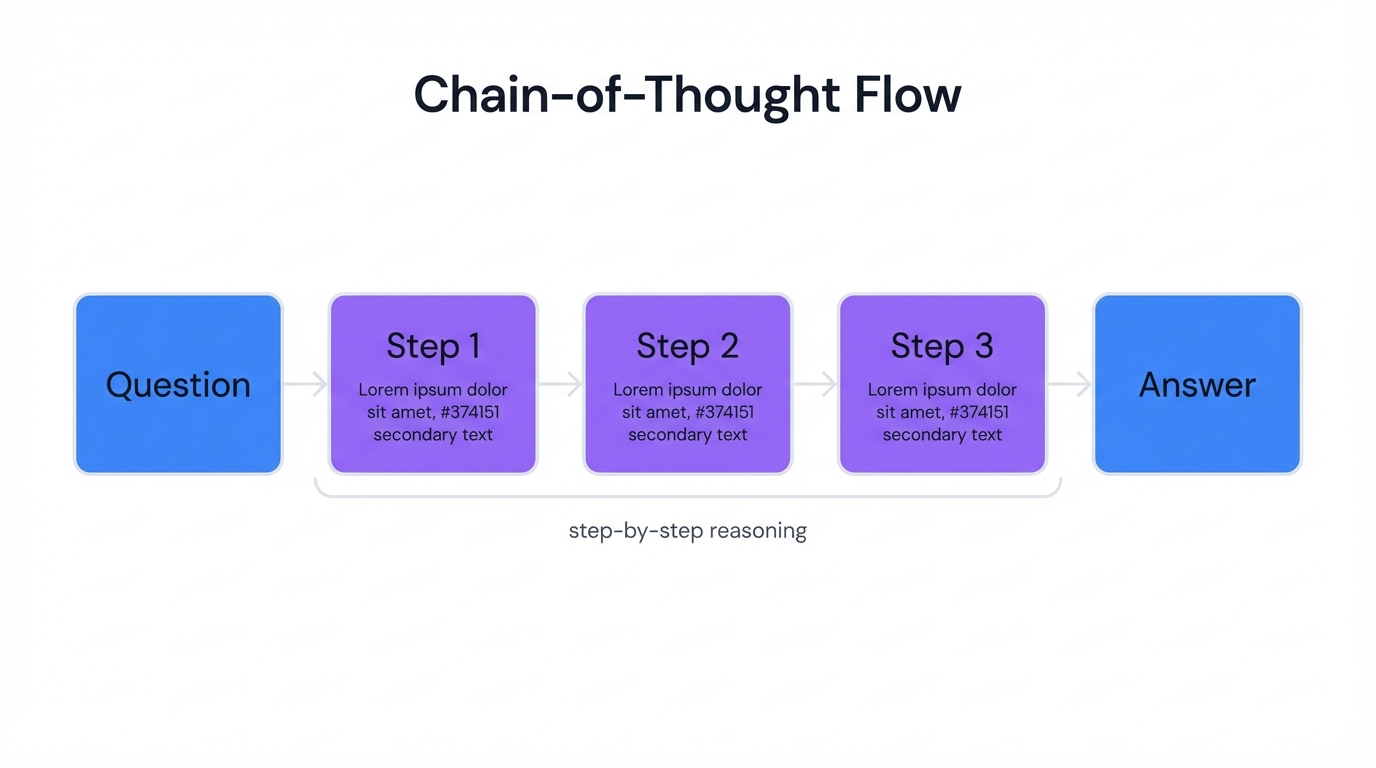
Question leads to Answer. This encourages models to find the most probable, single-step completion based on training data patterns. For simple tasks, this proves efficient. For complex reasoning tasks, this can lead models to generate plausible but incorrect answers because they lack intermediate steps to verify logic.
CoT prompting fundamentally alters this computational process.
By forcing models to generate step sequences (Question leads to Step 1 leads to Step 2 leads to Answer), it compels models to allocate more computational resources and inference time to problems, and each step becomes its own token-generation sequence, effectively breaking one large, complex task into multiple smaller, simpler ones.
Cognitive Forcing Function: This sequential generation acts as a "cognitive forcing function," preventing models from jumping to conclusions. Instead, it forces them to build logical arguments step-by-step—explaining why CoT dramatically improves performance on tasks like arithmetic and logic puzzles, where single missteps can invalidate entire results.
The resulting reasoning chain provides a transparent path to solutions. Invaluable for accuracy, interpretability, and debugging.
A Spectrum of Guidance
CoT can be implemented with varying levels of guidance.
Depending on task complexity and model capability.
Zero-Shot CoT represents the simplest and most common form. It involves appending simple trigger phrases to prompt ends, without providing reasoning examples. The most famous phrase is "Let's think step-by-step." For highly capable models, this simple instruction often suffices to elicit detailed reasoning chains.
Few-Shot CoT offers a more robust and explicit method. The prompt includes one or more examples demonstrating entire reasoning processes, from initial questions through intermediate steps to final answers. Models then learn to replicate this detailed, step-by-step format for new queries—generally proving more effective than Zero-Shot CoT, especially for very complex tasks.
Automatic CoT (Auto-CoT) addresses Few-Shot CoT's primary drawback: manual effort required to write high-quality reasoning examples. Auto-CoT automates this process through two main steps:
- Question Clustering groups diverse questions by similarity
- Demonstration Sampling selects one question from each cluster and generates reasoning chains using Zero-Shot CoT
These automatically generated examples then form Few-Shot CoT prompts for new questions.
Tackling the Hard Problems
When does CoT prompting prove most impactful?
For tasks that are difficult or impossible for LLMs to solve with standard prompting methods. These typically involve arithmetic, commonsense, and symbolic reasoning.
Arithmetic Word Problems represent the classic use case where CoT shines. Standard prompts often fail at multi-step calculations:
Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Originally, Leah had 32 chocolates. Her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39. The answer is 39.
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?
A:Logical Reasoning Puzzles enable models to track constraints and deduce logical conclusions:
Q: The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
Q: The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:Multi-Step Planning and Analysis can be applied to complex business problems, such as supply chain optimization, by breaking problems down into constituent parts like sourcing, shipping, and delivery analysis. It also proves effective for legal analysis and interpreting complex regulations.
The Power of Transparency and Deliberation
Using CoT for appropriate tasks provides significant benefits.
Improved Accuracy on Complex Tasks has been demonstrated dramatically across reasoning benchmarks. CoT turns problems that models consistently fail at into solvable ones—performance improvements often exceed 50% on mathematical reasoning tasks.
Transparency and Interpretability provide clear windows into model "thought processes." Explicit reasoning steps allow you to understand how answers were derived, not just what the answers are. This builds trust and confidence in outputs.
Debuggability emerges when CoT-prompted models produce incorrect answers. The reasoning chain makes it much easier to diagnose errors—you can pinpoint exact steps where logic failed, which proves invaluable for refining prompts or correcting model processes.
An Emergent Ability with Caveats
Despite its power, CoT is not a universal solution.
It comes with important limitations.
An Emergent Ability of Scale means CoT reasoning isn't present in all LLMs. It's considered an "emergent ability," appearing only once models reach certain, very large scales (around 100 billion parameters). Smaller models, when prompted with CoT, may struggle to produce coherent reasoning and can even perform worse than with standard prompting. They may generate flawed logic that leads them astray.
Faithfulness vs. Plausibility represents a critical limitation. Generated reasoning chains are not direct transcripts of model internal computations—they are rationalizations, plausible-sounding text sequences that lead to final answers. While often correct, reasoning can sometimes be flawed even if final answers are correct. The chain may not accurately reflect how models truly arrived at conclusions.
Implications of Scale: The emergence of CoT as a capability of scale carries profound implications. It suggests that scaling up models doesn't just lead to quantitative improvements (like better grammar) but to qualitative shifts in fundamental reasoning capabilities.
Small models lack parametric complexity to represent and execute multi-step logical chains. Large models, having learned from vast data, have internalized more complex patterns of logic and problem decomposition that CoT prompts can trigger. This suggests continued scaling may unlock entirely new, currently unforeseen cognitive abilities—though access to these advanced capabilities may be limited to those with resources to train and operate massive models.
A Strategic Framework for Choosing Prompting Techniques
Analyzing the Trade-offs
How do you choose between Zero-Shot, Few-Shot, and Chain-of-Thought prompting?
Trade-offs between user effort, desired performance, and control over model output.
Zero-Shot Prompting prioritizes simplicity and speed. It requires lowest user effort but offers least control, with reliability depending on tasks being general enough to fall within model pre-trained knowledge bases.
Few-Shot Prompting balances effort and performance. It demands moderate-to-high effort to curate high-quality examples but provides significant control over output format and substantial accuracy boosts for specific, nuanced tasks.
Chain-of-Thought Prompting targets maximum reasoning performance on complex problems. It requires either very large models capable of Zero-Shot CoT or high effort crafting Few-Shot CoT examples, with primary benefits being superior accuracy in logical tasks and transparency of reasoning processes.
A Practical Decision Guide
What's the most efficient methodology for developing LLM applications?
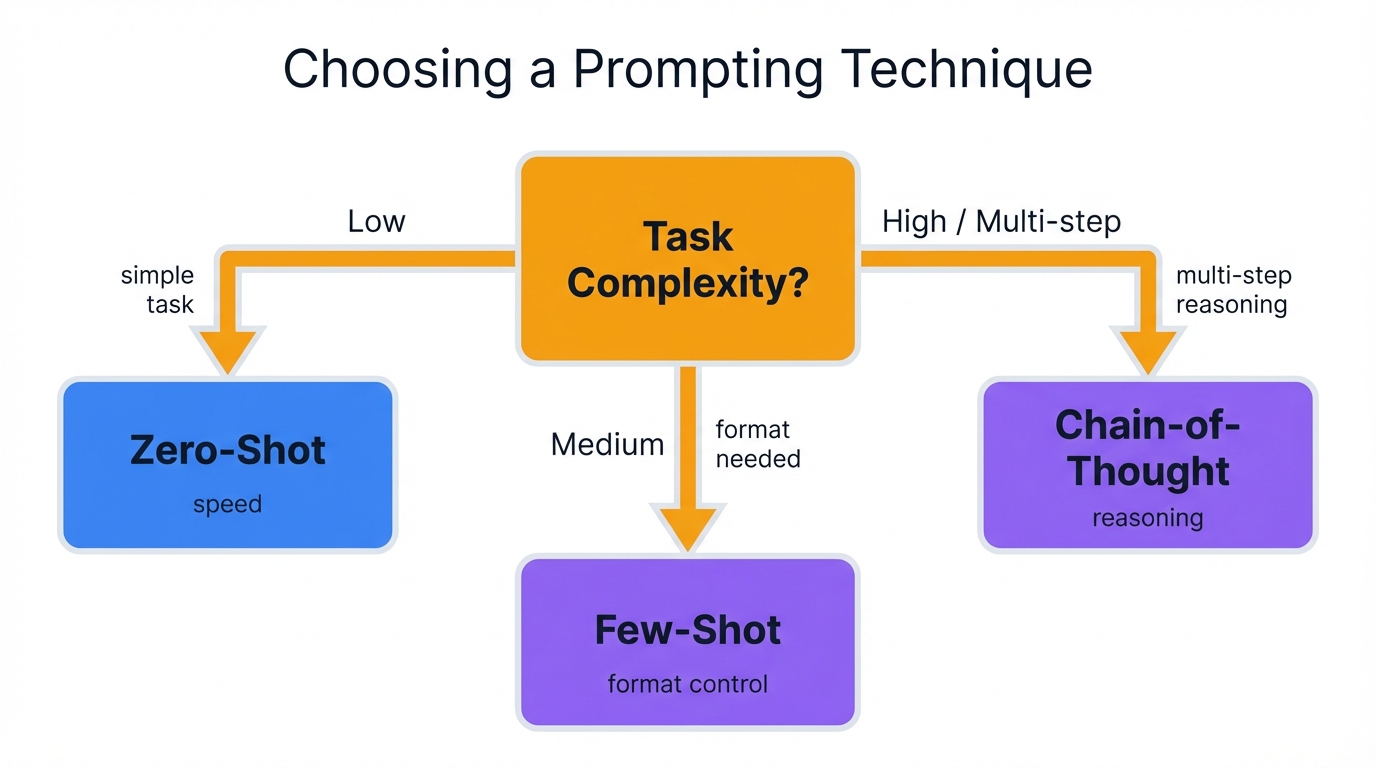
A strategic, tiered approach to prompt engineering. This approach conserves developer effort and computational resources by starting with the simplest method and escalating in complexity only as needed.
Start with Zero-Shot for any new task. Your first step should always be crafting clear, direct Zero-Shot prompts. If model performance satisfies your requirements, there's no need to introduce additional complexity. This establishes performance baselines quickly and efficiently.
Move to Few-Shot if Necessary when Zero-Shot approaches fail. Analyze the failure mode. If output is inaccurate due to task nuance, or if it requires specific formats or styles, implement Few-Shot prompting next. Providing well-chosen examples often resolves these issues.
Use Chain-of-Thought for Reasoning Failures when tasks involve multiple logical steps, calculations, or planning. If both Zero-Shot and Few-Shot prompts produce consistently incorrect answers, this strongly indicates models are failing at the reasoning process itself. Escalating to Chain-of-Thought prompting becomes the appropriate strategy to force more deliberate, step-by-step approaches.
Foundational Workflow: This tiered strategy isn't just helpful—it's a foundational workflow for practical prompt engineering that systematically balances performance with cost and effort.
Central Comparative Overview
Quick Reference: Use this table to quickly determine which prompting technique best suits your specific use case and requirements.
| Feature | Zero-Shot Prompting | Few-Shot Prompting | Chain-of-Thought (CoT) Prompting |
|---|---|---|---|
| Core Principle | Instruction-only; relies on pre-trained knowledge | Learning from in-context examples | Decomposing problems into step-by-step reasoning |
| User Effort | Low: Write a direct instruction | Medium to High: Curate high-quality, diverse examples | Medium to High: Structure reasoning examples or use specific trigger phrases |
| Best For | Simple, general tasks (basic translation, summarization) | Nuanced, specific tasks requiring particular style or format | Complex, multi-step problems (math, logic puzzles, planning) |
| Model Dependency | Highly dependent on quality of pre-training | Dependent on in-context learning ability | An emergent ability of very large models |
| Key Advantage | Speed and simplicity | High accuracy and output control | Transparency and superior reasoning performance |
| Primary Risk | Misinterpretation of ambiguous instructions | Overfitting to examples; amplification of bias from examples | Generation of plausible but incorrect reasoning chains ("hallucinated logic") |
| Example Use Case | "What is the capital of Japan?" | "Classify sentiment: [3 examples]. New review:..." | "Solve this math word problem and show your work." |
The Adversarial Frontier: When Prompts Become Weapons
Understanding the Core Vulnerability
What's the most significant security vulnerability in modern LLMs?
A fundamental design characteristic: they don't distinguish between trusted instructions from developers and untrusted data from users. Both are processed as natural language text within the same context.
This "conflation of instruction and data" means cleverly crafted user input can be interpreted by models as new, overriding commands. Attackers can hijack model behavior through this vulnerability—a risk the Open Worldwide Application Security Project (OWASP) ranks as the number one security risk for LLM applications.
Attack Vectors: Direct vs. Indirect Injection
Prompt injection attacks fall into two broad categories.
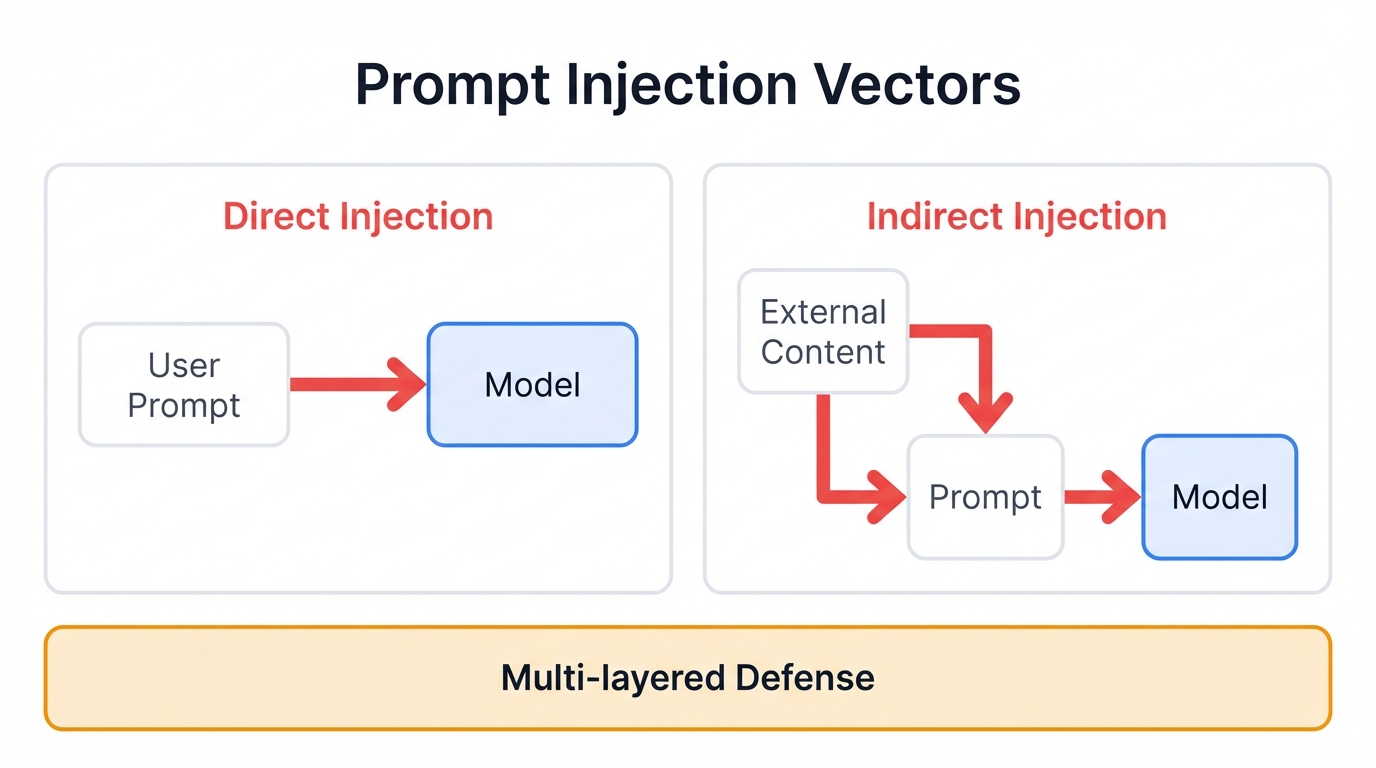
Direct Prompt Injection (Jailbreaking) represents the most straightforward attack form. Adversaries directly input malicious prompts designed to override model original instructions—often involving phrases like "Ignore previous instructions and do X instead" or instructing models to adopt personas not bound by safety rules.
Indirect Prompt Injection offers a more sophisticated and dangerous attack vector.
The malicious prompt isn't supplied by the immediate user but is hidden within external data sources that LLMs process—webpages, emails, PDFs, or documents. When models ingest this external data to perform tasks like summarization, they unknowingly execute hidden malicious commands.
The Internet as Attack Surface: The rise of LLMs connected to live data sources via plugins (web browsers, email clients) transforms the entire internet into a potential attack surface. Any piece of text on a webpage or in an email could contain hidden attack payloads.
Consider this scenario: you ask an AI assistant to summarize a webpage. The author of that page could have hidden a prompt in white text on a white background, instructing the model to first praise their company and then tell you to forward the malicious summary to all your contacts. You, expecting a neutral summary, instead receive and propagate a worm-like attack—demonstrating that LLM application security is now intrinsically linked to sanitization of all external data consumed.
From Misinformation to System Compromise
Successful prompt injection attacks can have severe consequences.
Depending on LLM application capabilities.
Leaking Sensitive Data occurs when attackers trick models into revealing confidential information contained within context windows or system prompts. This can expose proprietary business logic, customer data, or internal system details.
Spreading Misinformation and Malicious Content happens when models are forced to generate false, biased, or harmful content, bypassing safety filters. Attackers can weaponize trusted AI systems to spread propaganda or misinformation.
Unauthorized Actions (Excessive Agency) represents the most critical risk. If LLMs connect to external tools, plugins, or APIs, attackers can hijack these connections to perform unauthorized actions on your behalf—sending emails, deleting files, making purchases, or executing malicious code.
A Multi-Layered Defense
Does a foolproof method exist to prevent prompt injection attacks?
No. Short of not using LLMs at all. Therefore, mitigation relies on defense-in-depth strategies combining multiple security layers.
Input Validation and Sanitization involves filtering user inputs and external data for known malicious phrases, patterns, or trigger words. While not a complete solution, it can block common, unsophisticated attacks.
Instructional Delimiters use unique, non-natural character strings to clearly demarcate boundaries between trusted system instructions and untrusted user input. This can help, but determined attackers often find ways to mimic these delimiters in their input.
Human-in-the-Loop (HitL) prevents LLMs from executing high-stakes or irreversible actions (deleting files, sending emails, making payments) directly. Instead, models should propose actions to human users who must provide explicit approval.
Monitoring and Anomaly Detection continuously monitors LLM inputs and outputs for suspicious activity, unusual patterns, or deviations from expected behavior. This can help detect ongoing attacks.
Principle of Least Privilege grants LLMs the absolute minimum permissions required to perform intended functions when connecting to external tools. An LLM without permission to delete files can't be tricked into deleting them.
Unintended Disclosures: When AI Leaks Secrets
Defining Data Leakage in LLMs
Data leakage occurs when Large Language Models inadvertently reveal sensitive, confidential, or proprietary information through their responses.
A critical breach of data security and user privacy. With potentially severe legal and reputational consequences.
Vectors of Leakage
Sensitive information can be exposed through several distinct vectors.
Training Data Memorization happens during intensive training on vast datasets. LLMs can "memorize" specific information pieces, especially data appearing multiple times in training corpora—including Personally Identifiable Information (PII), passwords, API keys, medical records, or proprietary source code. Adversaries can then use carefully crafted prompts to probe models and extract this memorized sensitive data.
System Prompt Leakage occurs when attackers use prompt injection techniques to trick models into revealing their own system prompts.
If developers have insecurely embedded confidential information within these prompts—API keys, database connection strings, or internal system logic—this information gets exposed to attackers, providing them with "keys to the kingdom" and facilitating further, more damaging attacks.
The Capability-Confidentiality Tension: This creates fundamental tension between a model's capability and its confidentiality. The very process that makes LLMs powerful and knowledgeable—training on vast, diverse datasets—also creates memorization and data leakage risks.
Models trained on more data may be more capable. But they also paradoxically pose greater security risks. This forces developers into difficult balancing acts, weighing performance gains from using more data against escalating privacy and security threats. Advanced techniques like differential privacy, which adds statistical noise during training, represent direct responses to this tension—attempting to enable learning without verbatim memorization of specific data points.
Violating Privacy and Exposing Secrets
Data leakage consequences from LLMs are severe.
Privacy Violations through PII exposure can lead to massive breaches of user trust and result in significant fines under data protection regulations like GDPR and HIPAA. Organizations face both immediate financial penalties and long-term reputational damage.
Intellectual Property Theft through leakage of proprietary algorithms, confidential business strategies, or unreleased product information can cause irreparable financial and competitive damage. Competitors can gain unfair advantages through accidentally exposed trade secrets.
System Compromise occurs when credentials, API keys, or details about internal system architecture leak. Attackers can use this information to launch deeper, more conventional cyberattacks against organizational infrastructure.
Protecting the Data Lifecycle
Protecting against data leakage requires holistic approaches.
That secure data at every stage of the LLM lifecycle.
Data Sanitization and Anonymization provides the most effective defense through proactive measures. Before any data is used for training, it must be rigorously sanitized to identify and remove or mask sensitive information like PII, financial details, and credentials.
Strict Output Filtering implements additional security layers that scan LLM-generated responses for patterns resembling sensitive data. Use regular expressions to detect credit card numbers, social security numbers, or API keys—if potential leaks are detected, information should be redacted before sending to users.
Secure Prompt Design never embeds secrets directly into system prompts. API keys, passwords, and other credentials should be stored in secure vaults or secrets managers. Applications should retrieve these credentials at runtime and use them as needed, keeping them entirely separate from LLM contexts.
Access Controls implement strong Role-Based Access Control (RBAC) to ensure users and LLMs themselves can only access data and systems strictly necessary for their functions.
The Bias in the Machine
The Origin of Bias
Are Large Language Models independently biased entities?
No. They're powerful statistical mirrors reflecting their training data content. Since they train on vast swathes of text from the internet, they inevitably learn and reproduce societal biases, stereotypes, and prejudices related to race, gender, religion, age, disability, and other social categories present in that human-generated data.
Explicit vs. Implicit Bias
Modern LLMs undergo "value alignment" or "safety tuning."
They're fine-tuned to refuse generating explicitly harmful, hateful, or biased content. While this represents an important and necessary step, it's not a complete solution.
Research shows that even models appearing unbiased on explicit tests can still harbor deep-seated implicit biases. For example, a model might correctly refuse to answer directly racist questions but still, in more subtle contexts, be more likely to associate certain racial groups with criminality or recommend candidates with Caucasian names for supervisor positions while recommending candidates with names from minority groups for clerical work.
How Prompting Techniques Interact with Bias
Your choice of prompting technique can either mitigate or amplify these underlying biases.
Zero-Shot Prompting serves as direct queries to model baseline knowledge, making this technique most likely to reveal model raw, unfiltered implicit biases. You get the model's honest first reaction without external guidance.
Few-Shot Prompting proves highly susceptible to bias amplification. If examples provided in Few-Shot prompts are themselves biased, models will not only replicate but often magnify that bias in their output. For example, if all examples of "doctor" are male, models learn strong associations and apply them to new queries.
Chain-of-Thought Prompting doesn't eliminate bias despite forcing more deliberate thought processes.
Biased models can use CoT to produce perfectly structured and logical-sounding rationalizations for discriminatory or stereotypical conclusions—the reasoning may be coherent but founded on biased premises.
Your Accountability as a Developer: This dynamic places significant fairness burden on you as the user or developer deploying the model. While model creators perform large-scale alignment to reduce explicit bias, implicit biases remain and are highly context-dependent.
When you use Few-Shot learning for a hiring application with examples of past successful candidates, you're feeding the model historical data. If that historical data reflects existing biases within your company, the LLM will faithfully learn and apply that biased pattern, even if the base model was "aligned."
In this scenario, the model isn't making new biased decisions—it's correctly executing the biased pattern you showed it in the prompt. You, as the developer of the final application, become the final arbiter of fairness through your choice of prompts and examples. You're accountable for resulting outcomes.
Strategies for Bias Mitigation
Mitigating bias in LLMs represents a complex, ongoing challenge.
Requiring multi-faceted approaches.
Data Curation and Diversity provides the most fundamental and impactful strategy by improving training data quality. This involves actively curating more diverse and representative datasets, filtering out harmful content, and augmenting data to include underrepresented perspectives.
Bias-Aware Prompting requires you to consciously craft prompts and Few-Shot examples to be inclusive and actively challenge potential stereotypes. This can involve deliberately including counter-stereotypical examples (female CEOs, male nurses) to guide models toward more balanced perspectives.
Adversarial Training and Red-Teaming involves proactively and systematically testing models with prompts specifically designed to elicit biased or harmful responses. By identifying these vulnerabilities, developers can refine model training and safety filters.
Continuous Monitoring and Governance requires organizations to regularly audit model outputs for biased patterns and establish internal governance structures, such as ethics review boards, to oversee responsible development and deployment of AI systems.
Advanced Mitigation Techniques include ongoing research into methods like model pruning, which involves identifying and deactivating specific "neurons" or computational units within models found to contribute to biased behavior. However, these techniques are often highly context-specific and complex to implement.
Towards Responsible and Effective Prompting
Recap of the Prompting Spectrum
This analysis has explored three foundational techniques for guiding Large Language Models.
Each occupying a distinct point on a spectrum of complexity and control.
Zero-Shot prompting offers unparalleled simplicity, leveraging model vast pre-trained knowledge for general tasks. Few-Shot prompting provides crucial middle ground, enabling task-specific adaptation and precise output control through in-context examples. Chain-of-Thought prompting unlocks advanced reasoning capabilities for complex, multi-step problems by compelling models to articulate their logical processes.
Your strategic choice among these techniques hinges on careful evaluation of task complexity, required precision of output, and capabilities of the model you're using.
The Prompt Engineer's Mandate
The rise of prompt engineering signifies a new era.
Of human-computer collaboration. It also introduces a new set of responsibilities. You're no longer merely a user but a crucial steward of model behavior—your choices in crafting prompts, selecting examples, and structuring reasoning chains directly influence model accuracy, its security against adversarial attacks, and its fairness and ethical alignment.
This role demands a unique combination of technical skill, domain expertise, and deep awareness of potential unintended consequences.
Final Recommendations
For developers, product leaders, and users of LLM technology, the path to effective and responsible implementation can be guided by several core principles.
Core Implementation Principles:
- Adopt a Tiered Prompting Strategy: Begin with the simplest effective method (Zero-Shot) and escalate to more complex techniques (Few-Shot, CoT) only when necessary to achieve desired performance. This conserves resources and minimizes unnecessary complexity.
- Implement a Defense-in-Depth Security Posture: Acknowledge that no single solution can prevent prompt injection or data leakage. A multi-layered approach combining input validation, output filtering, least-privilege permissions for tools, and human-in-the-loop oversight is essential for mitigating risk.
- Embrace a Proactive Approach to Bias Mitigation: Recognize that bias is a systemic challenge originating from training data. Actively curate diverse examples, conduct adversarial testing to find vulnerabilities, and continuously monitor outputs to ensure fairness and prevent amplification of harmful stereotypes.
A Glimpse into the Future
The techniques discussed here represent the foundation of modern prompt engineering.
But the field advances at breathtaking pace. Researchers are already developing and refining more sophisticated frameworks that build upon these concepts.
Techniques like Self-Consistency, which generates multiple reasoning chains and selects the most consistent answer to improve robustness, and Tree of Thoughts (ToT), which allows models to explore multiple reasoning paths simultaneously and backtrack from dead ends, point toward a future where we can guide AI reasoning with even greater precision and reliability.
The principles of clarity, context, and caution established here will remain the bedrock upon which these future advancements are built.