The Imperative for Parameter-Efficient Adaptation
Large language models changed everything. They arrived with unprecedented capabilities, conquering task after task across the natural language processing landscape with an ease that seemed almost magical. But progress came at a price—models exploded in scale, ballooning to hundreds of billions of parameters, sometimes trillions, creating a new crisis that demanded attention and forced the field to rethink everything about how we adapt these massive systems for specialized work.
The Challenge of Scaling: The Burdens of Full Fine-Tuning
Full fine-tuning used to be the default. Simple concept: take your pre-trained model, feed it task-specific data, update every single parameter. Done. But as models grew larger, this approach became unsustainable, exposing three critical problems that couldn't be ignored.
First, the computational expense. Prohibitive doesn't begin to describe it. Fine-tuning a billion-parameter model demands massive GPU clusters, astronomical energy costs, and training times measured in days or weeks—resources that place this approach firmly out of reach for most academic labs, startups, and smaller organizations, concentrating power and capability within a privileged few tech giants.
Second, storage inefficiency reaches absurd levels. Every task requires a complete copy of the model—multiple gigabytes per specialization. Want to deploy fifty specialized models? You're looking at terabytes of storage, exponential cost increases, and a logistical nightmare that makes model management an operational burden instead of an engineering opportunity.
Third, catastrophic forgetting lurks as the hidden danger. Update all parameters on narrow, task-specific data and watch what happens—the model overwrites its hard-won general knowledge, degrading out-of-domain performance and destroying the very reasoning capabilities that made it powerful to begin with. The cure becomes worse than the disease.
The PEFT Paradigm: A New Philosophy of Adaptation
Enter Parameter-Efficient Fine-Tuning. PEFT flipped the script. Instead of updating billions of parameters, freeze them—lock down 99% or more of the pre-trained weights and train only a tiny fraction to adapt the model to your task.
This reframes everything. You're not creating a new specialized model anymore—you're learning a small, task-specific steering module that guides a massive, frozen knowledge base without touching its core wisdom. Think of it as the difference between rewriting an encyclopedia versus adding an index that helps you navigate it more effectively. The benefits cascade: computational costs plummet because you're training a fraction of the parameters, storage becomes trivial since you only save the small module per task, and catastrophic forgetting vanishes entirely because the base model never changes, preserving every ounce of foundational capability it learned during pre-training while enabling a highly modular ecosystem where one base model powers countless specialized applications just by swapping lightweight adaptation modules.
Situating Prefix Tuning within the PEFT Landscape
Prefix Tuning arrived as a pioneer. Proposed by Li and Liang, it became a foundational technique in the PEFT world, especially for Natural Language Generation tasks. But to understand its unique contribution, you need to know the three main families of PEFT methods:
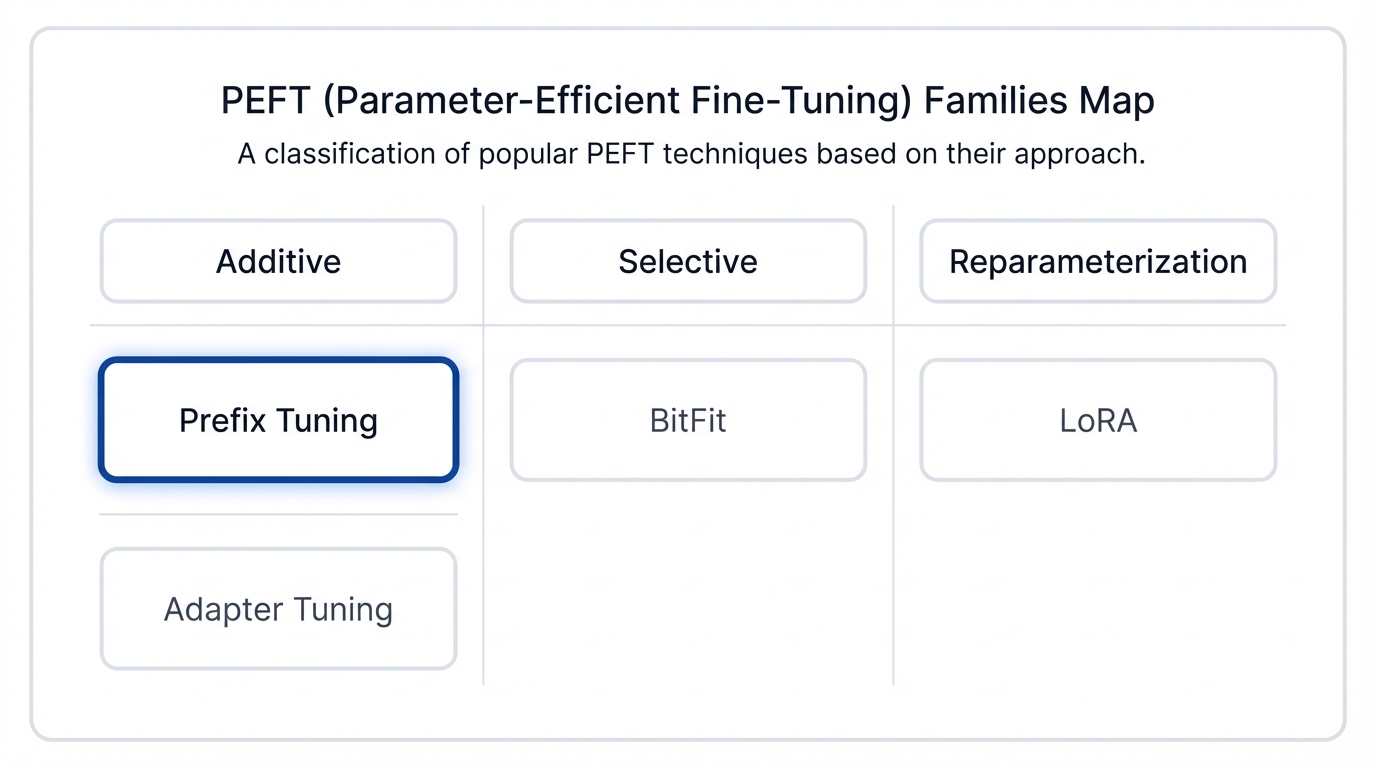
- Additive Methods: These introduce new trainable parameters while freezing the original weights. Prefix Tuning adds a sequence of trainable vectors to the input. Adapter Tuning inserts small neural network modules between existing layers. Both expand the model without touching its core.
- Selective Methods: No new parameters here—these approaches cherry-pick a small subset of existing parameters to update. BitFit exemplifies this by fine-tuning only the bias terms throughout the network, leaving everything else frozen.
- Reparameterization Methods: These get clever with matrix decomposition, using low-rank representations to model weight updates efficiently. LoRA dominates this category, expressing parameter changes as the product of two much smaller matrices instead of updating full weight matrices directly.
Prefix Tuning lives in the additive camp. What made it groundbreaking? It proved you could control a massive, frozen language model for complex generation tasks by optimizing just a handful of continuous parameters—a tiny steering wheel for a colossal machine.
Deconstructing Prefix Tuning: A Foundational Overview
Prefix Tuning leaps beyond earlier approaches. It transforms the discrete, human-centric art of "prompting" into something radically different—a continuous, machine-optimized process of "steering" that operates in vector space rather than word space.
From Discrete Prompts to Continuous "Virtual Tokens"
Prompting revolutionized LLM usage. GPT-3 proved you could guide a model without fine-tuning by prepending instructions like "Translate English to French:" along with a few examples, and the model would condition on that context to generate exactly what you needed. Powerful. Flexible. But fundamentally limited.
The problem? Finding the optimal prompt is a combinatorial nightmare. You're searching through a vast, discrete space of possible token sequences—a non-differentiable haystack where the perfect needle hides among trillions of less-effective alternatives. Output quality becomes hypersensitive to exact wording, precise formatting, and the specific examples you choose. Change one word and performance can crater.
Prefix Tuning asked a revolutionary question: why search for the best prompt in discrete token space when you could optimize a "prompt" directly in continuous vector space using gradient descent? The answer arrived as the prefix—a sequence of continuous, trainable vectors that don't correspond to any real vocabulary words. These "virtual tokens" exist purely as free parameters, optimized through backpropagation to become the most effective possible instruction for steering the model's behavior on your specific task, unshackled from the constraints of human language and operating in the model's native mathematical realm where optimization algorithms can work their magic.
The Core Concept: Steering a Frozen LLM with a Learnable Prefix
The mechanism? Elegant simplicity. Prepend a task-specific prefix—your sequence of learnable continuous vectors—to the input. Freeze the entire pre-trained model. Update nothing except the prefix itself during training.
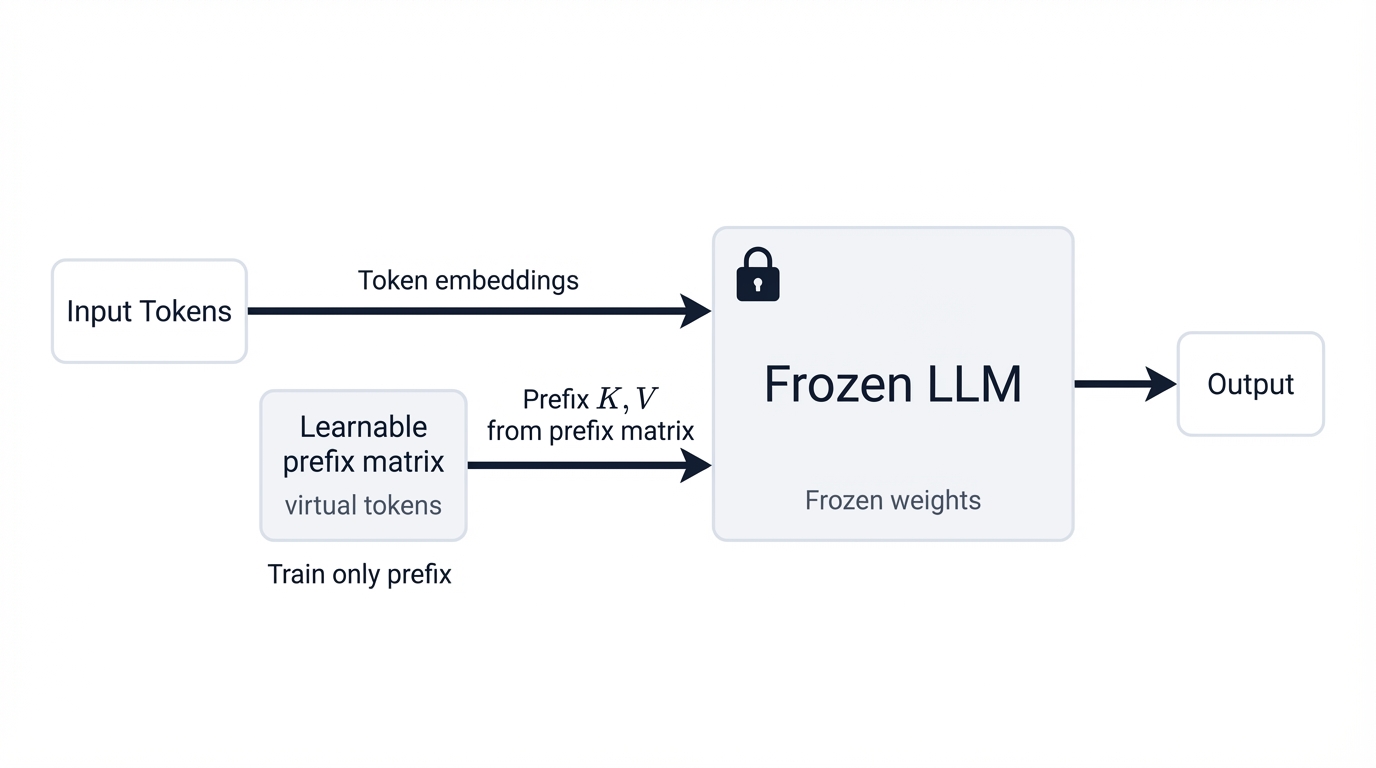
Watch what happens during forward passes. The attention mechanism treats prefix vectors like real input tokens, attending to them naturally. Through training, these vectors optimize themselves to create hidden states that guide the model's computations, steering generation toward correct outputs for your task. The prefix becomes a learned, implicit instruction injected directly into the model's activation space—a powerful form of control that operates beneath the surface of language, manipulating the frozen model's behavior with surgical precision.
Architectural Philosophy: Autoregressive vs. Encoder-Decoder Implementations
Prefix Tuning adapts to both major Transformer architectures. Different structures, same core principle.
- Autoregressive Models (e.g., GPT-2): These generate text one token at a time, each prediction conditioned on all previous tokens. Simple implementation: prepend the prefix to the entire sequence. As the model generates each output token, its attention mechanism includes the prefix activations as part of the leftward context, providing continuous guidance throughout the generation process.
- Encoder-Decoder Models (e.g., BART): These split the work—encoding the input into a representation, then decoding that representation into output. Prefix Tuning gets applied twice: one task-specific prefix prepended to the encoder's input, another independently learned prefix prepended to the decoder's input. This dual-prefix strategy enables distinct, specialized control over both the input representation phase and the conditional generation phase, delivering greater flexibility for sequence-to-sequence tasks where you need to simultaneously guide how the model understands the input and how it constructs the output, making it particularly powerful for summarization and translation applications.
The Architectural Mechanism of Prefix Tuning
Understanding Prefix Tuning demands precision. Move beyond the high-level concept and examine exactly how this method works within Transformer architecture—because the power doesn't come just from adding a prefix, but from where and how that prefix's influence infiltrates the model's computational flow, coupled with the clever optimization strategy that keeps training stable.
Injecting the Prefix: A Layer-by-Layer Analysis
Here's what most people miss: the prefix doesn't just affect the input embedding layer. Its influence permeates every single layer of the Transformer. This is critical.
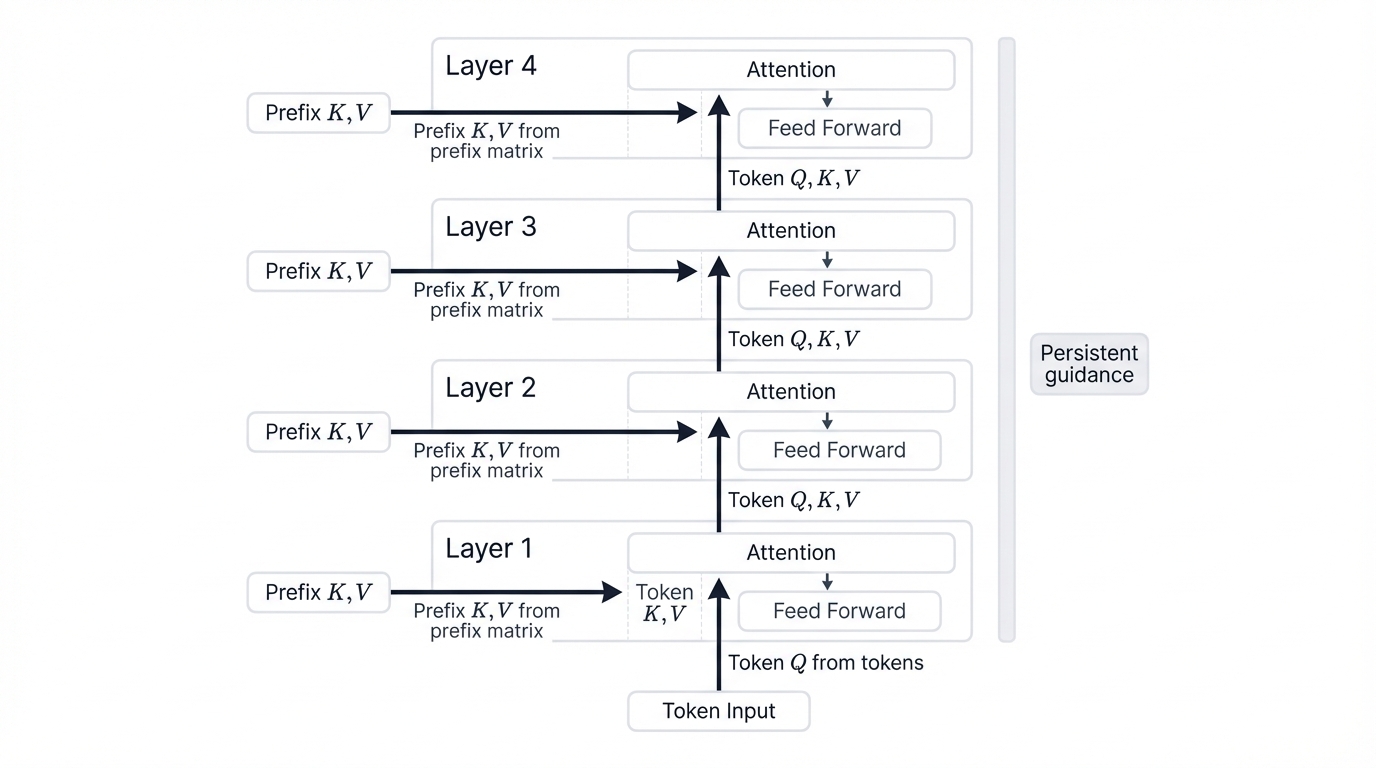
Inside each Transformer block, self-attention computes query, key, and value vectors from previous layer hidden states. For actual input tokens, this computation proceeds normally. But for prefix positions? Different story. The key and value vectors don't come from prior hidden states—they're drawn directly from the trainable prefix parameter matrix. Real tokens in the input sequence then attend to these prefix-derived key-value pairs at every layer, creating a persistent guidance channel throughout the entire network.
Why does layer-wise injection matter so much? Transformers are deep networks that progressively refine representations as information flows through their stacked computations. If the prefix only influenced the initial embedding layer, its signal would get diluted, transformed unpredictably, or lost entirely as it propagated through dozens of layers. By re-injecting prefix key and value states at each layer, the model receives constant, fresh task-specific context at every stage of processing—a persistent control signal that the model can consult at each step of its reasoning process, ensuring the guidance remains strong from input to output.
The Reparameterization Imperative: Using MLPs for Training Stability
Powerful concept. Practical problem. Early experiments hit a wall—directly optimizing the full prefix parameter matrix crashed and burned, producing unstable training and degraded performance. Why? Too many free parameters learned from scratch on relatively small task-specific datasets create a treacherous optimization landscape where convergence becomes nearly impossible to achieve.
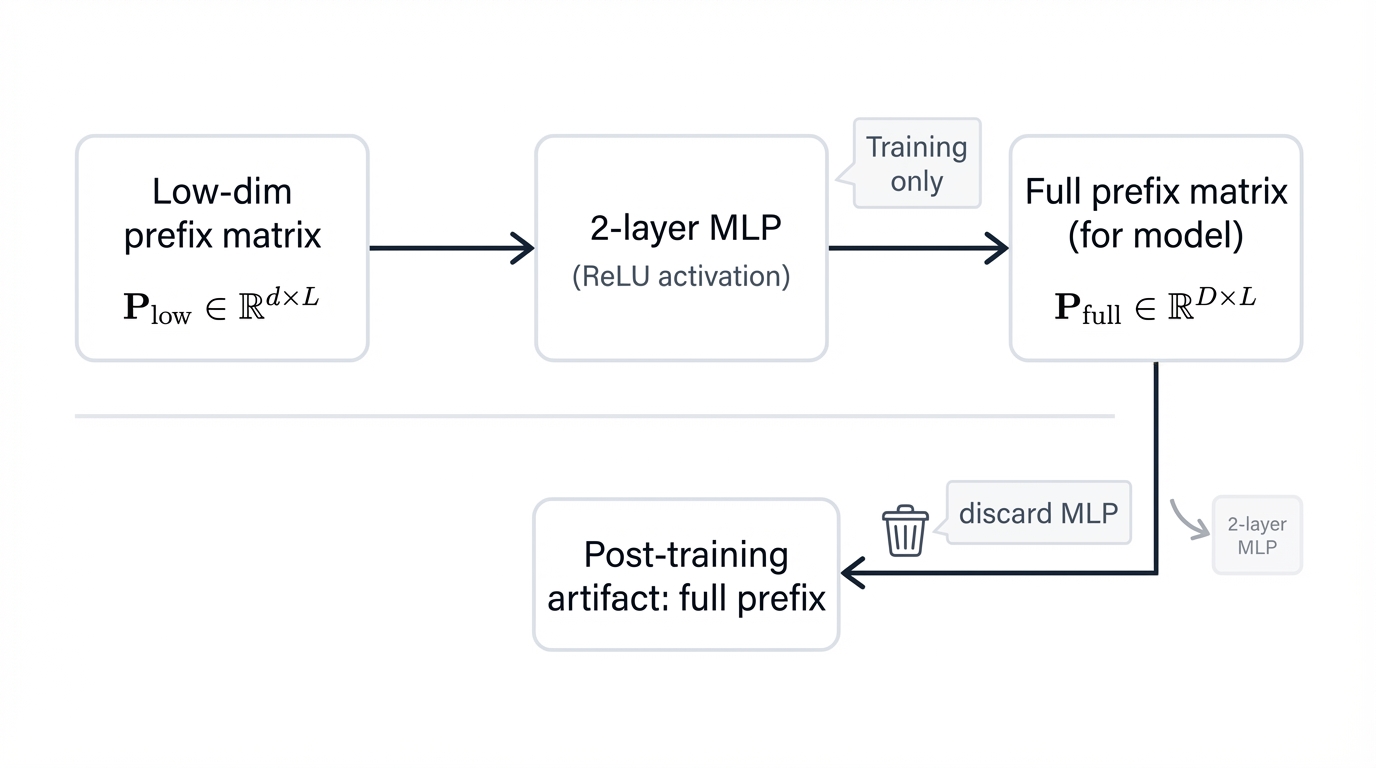
The solution? A reparameterization strategy that stabilizes training by shrinking the dimensionality of trainable parameters. Instead of learning the large matrix directly, you learn two smaller components:
- A smaller, trainable matrix with reduced dimensions
- A two-layer Multi-Layer Perceptron (MLP) that projects those low-dimensional vectors up to the full hidden dimension the Transformer needs
During training, gradients backpropagate through the MLP, updating only the smaller matrix and the MLP parameters. Much smaller optimization problem. More constrained. More stable. Better results.
Think of this as regularization applied to the parameter space itself. The hypothesis: essential task-specific information can be represented in a lower-dimensional manifold. Force the model to learn this compressed representation and you constrain the optimization, preventing it from wandering into erratic, high-dimensional directions that lead to poor local minima—essentially building guardrails that keep training on track.
Post-Training: The Lightweight and Modular Artifact
Here's the clever part: reparameterization only matters during training. Once optimization completes, you discard the entire reparameterization network—the MLP, the smaller matrix, all of it.
What remains? The final, trained prefix matrix. Exceptionally small—typically just 0.1% of the base model's total parameters. This creates an incredibly efficient, modular system where a single massive frozen LLM gets deployed once, and numerous tiny task-specific prefix files live alongside it. Need to adapt the model to a new task? Load the corresponding prefix, prepend its activations to the input during inference, done—storage-efficient architecture that also enables operational flexibility you can't get any other way, like processing examples from dozens of different tasks within a single batch just by prepending the correct prefix to each example.
Strategic Advantages and Performance Characteristics
Architectural design translates to strategic power. Prefix Tuning delivers compelling advantages that make it a formidable tool for adapting LLMs under real-world constraints—benefits backed by strong empirical results across different data regimes and tasks, not just theoretical promises.
Quantitative Benefits: A Paradigm of Efficiency
The numbers tell a dramatic story. Resource efficiency that makes full fine-tuning look wasteful:
- Parameter Efficiency: Train 0.1% of the base model's parameters. That's it. Prefix optimization slashes trainable parameters by several orders of magnitude compared to full fine-tuning—not incremental improvement, radical transformation.
- Storage Efficiency: Store a small prefix matrix instead of a multi-billion parameter model for each task. Result? Storage requirements more than 1000 times smaller than fully fine-tuned models. Minuscule footprint. Massive savings.
- Training Efficiency: Fewer parameters mean faster training, dramatically reduced computational power requirements, and lower costs—both time and money—for developing specialized models. What took days might take hours. What cost thousands might cost tens.
Qualitative Benefits: Modularity and Robustness
Beyond raw numbers, Prefix Tuning delivers flexibility and reliability that change how you deploy LLMs:
- Modularity: Frozen base model. Swappable prefixes. Highly modular system architecture. A single pre-trained model instance serves dozens or hundreds of downstream tasks simultaneously—just select the appropriate prefix for each incoming request and you're done, no model loading, no overhead.
- Prevention of Catastrophic Forgetting: Base LLM parameters never change. Never. This means the vast repository of general knowledge and linguistic competence acquired during pre-training stays perfectly preserved, completely circumventing catastrophic forgetting and ensuring foundational capabilities remain intact during specialization—you get task-specific behavior without sacrificing general intelligence.
- Personalization at Scale: Train a unique prefix for each user based on their individual data. Create customized experiences without data cross-contamination between users, without storing full models per person, enabling true personalization at scale that was previously impossible due to storage and privacy constraints.
Performance Analysis: Data Regimes and Generalization
Performance varies with data availability. Watch how Prefix Tuning adapts across different training scenarios:
- Full-Data Setting: Large task-specific datasets available? Prefix Tuning matches full fine-tuning performance despite training only a tiny fraction of the parameters. Comparable results. Massively reduced cost. The efficiency gains come free—no performance penalty.
- Low-Data Setting: This is where Prefix Tuning dominates. Few-shot scenarios expose full fine-tuning's weakness—billions of trainable parameters overfit small datasets catastrophically. Prefix Tuning? Significant outperformance. The constraint becomes an advantage. Fewer parameters force better generalization, turning limitation into strength through a mechanism that naturally regularizes learning.
- Enhanced Generalization: That regularization effect pays dividends beyond the training distribution. Prefix-tuned models extrapolate better to unseen topics and domains, handling examples outside their tuning process more robustly than fully fine-tuned counterparts—evidence of more fundamental, less brittle learning that preserves the model's ability to reason about novel situations.
Applications in Natural Language Generation and Beyond
Theory meets practice. Prefix Tuning's strengths shine across real applications, centered primarily on Natural Language Generation where precise control over model output becomes essential.
Canonical Use Cases in NLG
The original research established efficacy on two canonical tasks. These remain primary examples:
- Table-to-Text Generation: Transform structured data into fluent natural language. Prefix Tuning guided GPT-2 to accurately translate tabular information into coherent prose, demonstrating that continuous prompt optimization could master the challenging leap from rigid structure to flowing text.
- Abstractive Summarization: Condense long documents into concise, accurate summaries. Applied to BART's encoder-decoder architecture, learned prefixes conditioned the model to perform the complex reasoning and generation that high-quality summarization demands—compression without loss of essential meaning.
Advanced and Emerging Applications
The foundational concept sparked innovation. Researchers are adapting Prefix Tuning for sophisticated applications requiring dynamic, fine-grained control:
- Controlled Text Generation: "Control Prefixes" extend the framework by making prefixes dynamic and conditional on input-dependent information. Instead of static prefixes applied uniformly across datasets, Control Prefixes incorporate learnable attribute representations into prefix vectors at different layers, enabling content generation that responds to specific desired characteristics—tone, style, formality, sentiment—with unprecedented precision.
- User Personalization: Perfect fit for creating personalized AI experiences. Train unique prefixes for individual users to build chatbots that mirror their communication style, recommendation systems that understand their preferences, or writing assistants that adapt to their vocabulary and voice—all without storing separate model copies or risking data cross-contamination.
- Multi-Modal Adaptation: Originally designed for text-only models, Prefix Tuning principles now extend to large multi-modal models processing both text and images. Adapt vision-language models for image captioning, visual question answering, or text-to-image generation by learning prefixes that bridge modalities, steering models that see and speak simultaneously.
A Comparative Analysis of PEFT Alternatives
Prefix Tuning pioneered PEFT. But the field evolved rapidly, spawning alternative methods that offer different trade-offs. Understanding these comparisons reveals when to choose Prefix Tuning and when other approaches win.
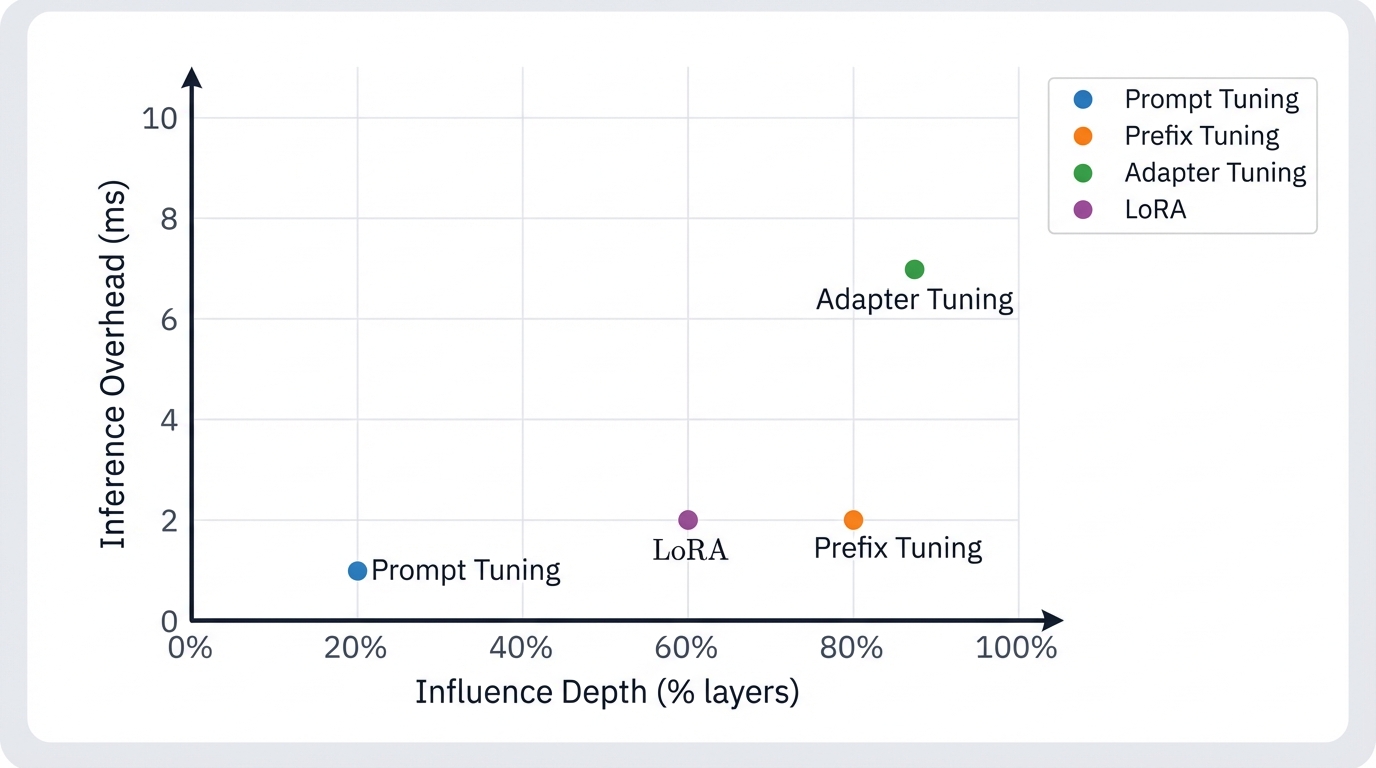
Prefix Tuning vs. Prompt Tuning
Prompt Tuning simplifies the concept. More parameter-efficient? Yes—trainable vectors live only at the input embedding layer. But simplicity costs expressive power. Prefix Tuning's layer-wise injection delivers continuous, deep steering throughout the network. Prompt Tuning's influence starts at the input and gets diluted as signals propagate through layers, struggling with complex tasks until model scale reaches extreme sizes—10 billion parameters or more—where brute force compensates for architectural limitation.
Prefix Tuning vs. Adapter Tuning
Clear architectural contrast. Prefix Tuning adds to the input sequence—virtual tokens processed in parallel with real tokens. Adapter Tuning inserts between layers—small feed-forward networks added sequentially throughout the Transformer stack. The critical trade-off? Inference latency. Each adapter module adds sequential computation that cumulatively increases processing time, problematic for real-time applications. Prefix Tuning adds negligible latency because prefix processing happens in parallel with main input, keeping inference speed essentially unchanged.
Prefix Tuning vs. LoRA: The Critical Trade-off
This comparison matters most for practitioners. LoRA matches or exceeds full fine-tuning performance on standard benchmarks while offering zero additional inference latency—low-rank update matrices merge directly into original weights after training. Popular choice. Compelling benefits. But recent research uncovered a fundamental difference that changes everything.
LoRA practices "knowledge editing." It directly modifies weight matrices, fundamentally altering the linear transformations the model learned, changing internal functions to suit new tasks. High performance on narrow tasks? Absolutely. But at what cost? This approach distorts or collapses the model's rich, pre-trained feature representation space—the very knowledge structure that makes the model powerful gets damaged in pursuit of task-specific optimization.
Prefix Tuning practices "knowledge steering." Weights stay frozen. Completely frozen. The model's learned functions never change—instead, Prefix Tuning learns to provide optimal context that elicits desired behavior from the unchanged model, like asking the right question rather than rewiring the brain. This preserves the integrity of pre-trained knowledge and maintains the structure of representation space, ensuring the model retains its fundamental capabilities while gaining task-specific behavior.
Limitations, Challenges, and Future Directions
Powerful method. Foundational contribution. But not perfect. Balanced assessment demands acknowledging challenges and limitations—and these point toward exciting future directions.
Optimization Challenges and Hyperparameter Sensitivity
Direct prefix parameter optimization? Unstable. The reparameterization network (MLP) solves this but adds implementation complexity. Then there's hyperparameter sensitivity—prefix length becomes a critical choice that balances competing pressures. Longer prefixes provide more trainable parameters and greater expressive capacity, but they also intensify the optimization challenge and consume precious context window space that your actual input data needs, creating a delicate trade-off that requires careful tuning for optimal results.
Performance Variability
Strong performance in low-data settings? Proven. Universal superiority? Not quite. Some studies report struggles matching full fine-tuning or LoRA performance on certain tasks, particularly with smaller-scale language models where the frozen parameter base provides less knowledge to steer. Effectiveness depends on base model size and task nature—some problems benefit more from parameter modification approaches like LoRA that directly edit the model's learned transformations.
The Frontier of Hybrid Methods: PT-PEFT
The future? Hybrid methods combining PEFT technique strengths. Individual method limitations sparked research into multi-stage adaptation, and the most promising approach emerged as Prefix-Tuned PEFT (PT-PEFT)—a sequential process that harnesses both knowledge steering and knowledge editing.
Start with Prefix Tuning. This initial stage gently aligns the model with the new task's general domain and requirements, orienting existing knowledge toward the problem without damaging foundational capabilities because the frozen weights preserve representation space integrity. Then apply LoRA or Adapters—the second stage fine-tunes performance on specific task details through targeted parameter modification.
Results? The sequential strategy (Prefix Tuning → LoRA) consistently outperforms either method alone, revealing powerful synergy that mirrors human learning—first understand the broad context and domain of a new problem, then practice and master the specific skills required. The hybrid approach suggests that optimal adaptation isn't a single technique but a choreographed sequence that leverages complementary strengths at different stages, with knowledge steering preparing the foundation and knowledge editing refining the execution.
Conclusion: Synthesizing the Role of Prefix Tuning
Prefix Tuning stands as a landmark. An elegant, effective solution to the critical challenge of adapting massive language models without breaking the bank or destroying their foundational knowledge. Its introduction catalyzed the shift toward parameter-efficient fine-tuning, proving you could match full fine-tuning performance while training only a minuscule fraction of parameters—a demonstration that changed how the field thinks about model adaptation.
Recapitulation of Key Strengths and Weaknesses
The analysis reveals a clear profile. Distinct strengths. Specific weaknesses. Understanding both guides intelligent deployment.
Core advantages:
- Extreme parameter and storage efficiency—specialization costs drop by orders of magnitude
- Highly modular architecture where a single base model flexibly adapts for numerous tasks
- Superior performance in low-data regimes through inherent regularization that prevents overfitting
- Unique ability to preserve pre-trained knowledge and representation space integrity
Primary weaknesses:
- Optimization instability requiring complex reparameterization strategy for stable training
- Sensitivity to hyperparameters like prefix length that demands careful tuning
- Performance that sometimes lags behind aggressive parameter-modifying methods like LoRA or full fine-tuning on high-data, in-domain benchmarks
Expert Recommendation: When to Choose Prefix Tuning
The profile points to clear guidelines. Practitioners deciding on adaptation strategies can follow these actionable recommendations:
Choose Prefix Tuning when:
- You're operating in low-data or few-shot environments where strong regularization properties deliver better generalization
- Your downstream task demands robust generalization to unseen topics or domains, leveraging preserved base model knowledge
- Preserving foundational world knowledge and complex reasoning abilities proves critical for task success
- Your deployment involves multi-task serving where modular architecture and low storage cost of swappable prefixes become paramount
- You're considering hybrid approaches like PT-PEFT where Prefix Tuning serves as the essential alignment stage
Final Perspective: Enduring Relevance and Future Evolution
Prefix Tuning transcends its place in the PEFT toolkit. Foundational innovation. It established the viability of optimizing continuous prompts and fundamentally changed how the field conceptualizes model adaptation—steering massive, frozen knowledge bases by learning to manipulate internal activations, a principle that remains powerful and relevant today.
LoRA gained immense popularity for strong performance and zero inference latency. Fair enough. But Prefix Tuning's unique ability to preserve foundational knowledge ensures continued importance that newer methods cannot match. Its future lies in dual roles: standalone method for specific use cases where knowledge preservation matters most, and crucial component in next-generation multi-stage adaptation strategies like PT-PEFT that combine complementary strengths into systems greater than the sum of their parts. By pairing its gentle, knowledge-preserving alignment with the performance-maximizing power of parameter-modifying techniques, Prefix Tuning will continue playing a vital role in the ongoing effort to build AI systems that are not just efficient and powerful, but robust and intelligent in ways that matter for real-world deployment.