
Publication Date: November 8, 2025 Reading Time: 45 minutes Topic: Infrastructure Security Author: perfecXion Research Team
Executive Summary: The Hidden Crisis in AI Infrastructure
Machine learning pipelines face a security crisis that most organizations don't fully grasp. While 77% of companies confirmed breaches to their AI systems in 2024, the real number is likely far higher—45% of organizations chose not to report AI-related security incidents due to reputational concerns. Supply chain attacks now account for 45% of all AI-related compromises, representing a fundamental shift in how attackers target machine learning infrastructure.
The financial stakes are severe and growing. The average data breach costs $4.88 million globally, but organizations deploying extensive AI systems without proper security automation face breach costs that can soar to $6.5 million or more. The mean time to identify a breach remains at 194 days, with credential-based attacks extending this to 292 days. For ML pipelines specifically, detection often occurs only after model degradation becomes visible in production—sometimes weeks or months after the initial compromise.
Here's what makes this particularly dangerous: traditional application security controls miss ML-specific attack vectors entirely. Model serialization vulnerabilities, CI/CD pipeline exploitation targeting GPU clusters, and training data poisoning represent threats that conventional security tools weren't designed to detect. The infrastructure supporting AI—platforms like Ray, MLflow, and Kubeflow—contains critical vulnerabilities that attackers actively exploit at scale.
This guide provides actionable technical guidance for securing every stage of the MLOps lifecycle. You'll learn how to protect training pipelines from data poisoning, validate model artifacts before deployment, harden CI/CD infrastructure against the latest exploits, and detect compromise in production systems. The frameworks exist—SLSA, MITRE ATLAS, NIST AI RMF, ISO 42001—but adoption remains dangerously low at just 8% of organizations with comprehensive AI security plans.
Key Findings:
- 77% of organizations experienced AI system breaches in 2024 (HiddenLayer)
- 45% of AI breaches originate from malicious models in public repositories
- 97% of companies use pre-trained models from repositories like Hugging Face
- 352,000+ distinct security issues found across models on major platforms
- Average breach cost: $4.88 million (IBM), $4.2 million for ML-specific incidents
- Detection time: 258 days average (194 days to identify, 64 days to contain)
- Organizations with AI security plans: Only 8% have comprehensive plans
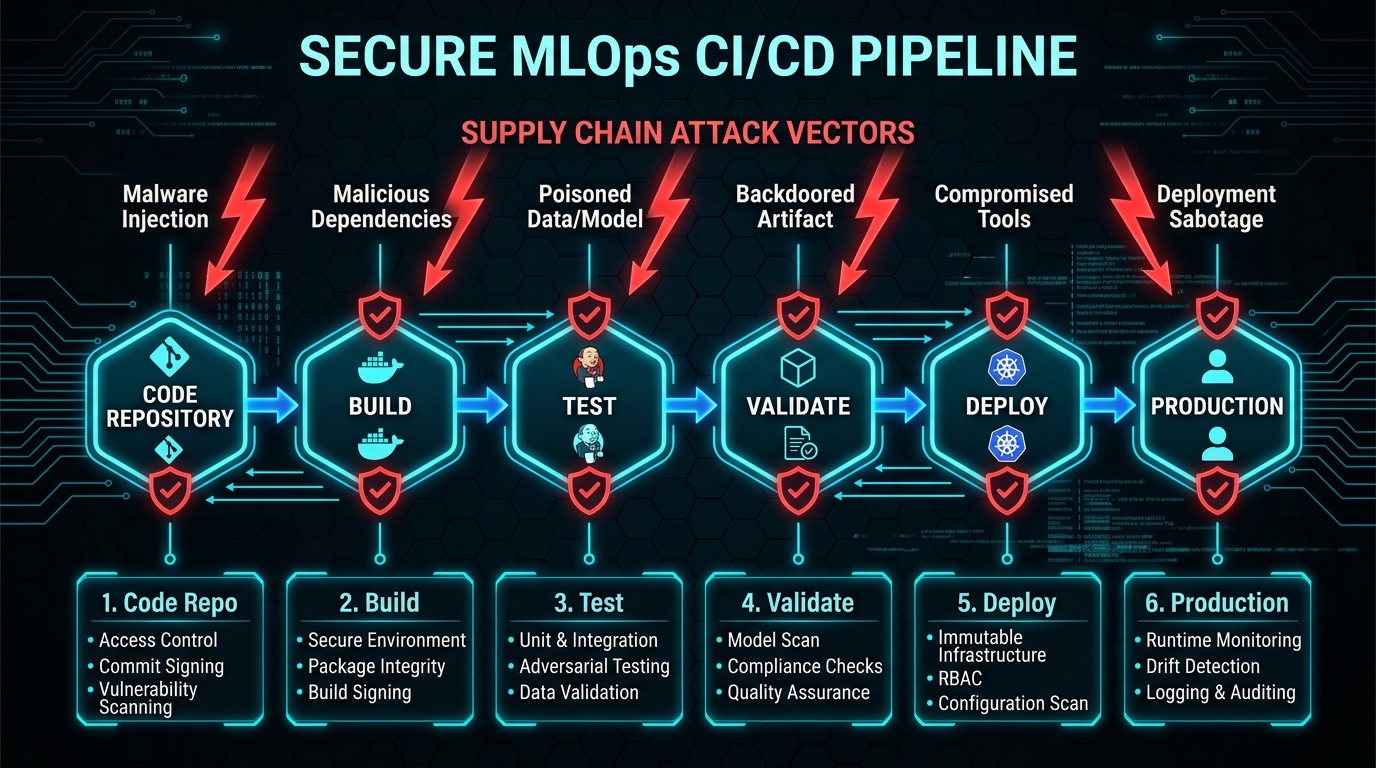
Chapter 1: The MLOps Threat Landscape Has Fundamentally Shifted
Understanding the New Attack Surface
The industrialization of artificial intelligence has created an entirely new attack surface that most security teams aren't prepared to defend. As organizations move from experimental data science to production Machine Learning Operations (MLOps), the infrastructure supporting these workloads—the continuous integration and continuous deployment (CI/CD) pipelines—has become a high-value target.
Between 2023 and 2025, AI security transitioned from theoretical adversarial research to a battlefield of active, high-impact exploitation. The convergence of high-value intellectual property, sensitive training data, and massive compute resources within MLOps environments has created what security researchers call a "perfect storm" for threat actors. Attackers range from financially motivated cybercriminals seeking to hijack GPU resources for cryptocurrency mining to nation-state operatives targeting proprietary model weights that represent hundreds of millions in research investment.
Breach Statistics Reveal Systemic Vulnerabilities
The numbers tell a stark story. HiddenLayer's AI Threat Landscape Reports provide the most comprehensive view of MLOps security incidents. In 2024, 74% of organizations definitively experienced an AI breach, up from 67% the previous year. Perhaps more alarming, 45% of organizations opted not to report AI-related security breaches due to reputational concerns—suggesting actual incident rates are substantially higher than public data indicates.
Attack origination data reveals clear geographic patterns: 51% of attacks originate from North America, followed by Europe at 34% and Asia at 32%. Organizations now maintain an average of 1,689 AI models in production, yet 92% are still developing comprehensive AI security plans. Only 14% have planned or tested for adversarial attacks, and just 20% have prepared for model theft scenarios.
The primary breach vectors in 2025 break down as follows:
- Malware in models from public repositories: 45% of breaches
- Chatbot and LLM exploitation: 33% of breaches
- Third-party application vulnerabilities: 21% of breaches
These numbers reveal a fundamental truth: the greatest threat to ML systems isn't adversarial examples or clever prompt injections—it's the supply chain. When you download a pre-trained model from Hugging Face or import a PyTorch dependency, you're potentially introducing code that could compromise your entire infrastructure.
The Financial Impact of MLOps Breaches
The cost of ML-specific security failures extends far beyond traditional breach calculations. The global average data breach cost reached $4.88 million in 2024, representing a 10% increase from the previous year—the largest annual spike since the pandemic. For ML-specific incidents, the average cost sits at $4.2 million, but this varies dramatically by industry and attack vector.
Healthcare organizations face the highest breach costs at $9.77 million in 2024, driven by the combination of sensitive patient data and the increasing use of diagnostic AI models. Financial services come in second, with breaches averaging $6.08 million. The use of security AI and automation in defensive operations has proven to be a significant cost mitigator, saving organizations an average of $2.2 million per breach (a 31% reduction) and reducing the breach lifecycle by approximately 100 days.
But these averages mask a more troubling reality: breaches involving "Shadow AI"—unauthorized or unmanaged AI workloads deployed by employees outside of IT governance—incurred an additional cost penalty averaging $670,000 higher per incident. This stems from the lack of visibility and control. When data scientists spin up their own ML infrastructure without security oversight, they create blind spots that attackers exploit.
The dwell time statistics are equally concerning. The average time to identify and contain a data breach in 2024 was 258 days total (194 days to identify, 64 days to contain). However, this varies significantly by attack vector:
Dwell Time by Attack Type:
- General cyber breaches: 258 days average
- Insider threats: 81 days detection time (organizations lacking behavioral analytics face 120+ days)
- Advanced persistent threats (APTs): Up to 393 days for sophisticated backdoors
- Credential-based attacks: 292 days average
- Rapid exfiltration attacks: As low as 7 days (some complete in 5 hours)
For ML pipelines, detection typically occurs only after model degradation manifests in production—sometimes weeks or months post-compromise. By the time you notice prediction accuracy declining or inference times increasing, attackers may have already exfiltrated your training data, stolen model weights, or planted backdoors that trigger on specific inputs.
High-Profile Incidents Demonstrate Real-World Attack Patterns
Theoretical vulnerabilities are one thing. Let's look at what actually happened when attackers targeted ML infrastructure.
The PyTorch Supply Chain Attacks (2022-2024)
The PyTorch ecosystem suffered multiple sophisticated supply chain compromises that demonstrate the evolving threat landscape. In December 2022, attackers executed a dependency confusion attack by registering a malicious package named torchtriton on PyPI. The legitimate package exists in PyTorch's internal repositories, but Python's package resolution mechanism will check PyPI first if not explicitly configured otherwise.
The malicious package was downloaded 2,717 times before detection. The payload was elegant and devastating: it exfiltrated SSH keys, environment variables, and system configurations via encrypted DNS requests to attacker-controlled infrastructure. Because the data exfiltration used DNS rather than HTTP/HTTPS, it bypassed many egress filtering rules that security teams had in place.
A more sophisticated attack followed in August 2023. Security researchers demonstrated how improperly secured self-hosted GitHub Actions runners could be exploited to compromise AWS credentials. They gained access to 93+ repositories within the PyTorch organization. The attack chain could have enabled malicious release uploads to GitHub and AWS S3 buckets, potentially poisoning the official PyTorch distribution consumed by millions of developers worldwide.
The Ultralytics Compromise (December 2024)
The Ultralytics incident demonstrated pipeline injection at industrial scale. Attackers exploited a GitHub Actions pull_request_target workflow vulnerability using branch name injection. This vulnerability allowed untrusted code from pull requests to execute in a trusted context with write access to secrets.
The compromised package—with 60 million downloads and presence in 10% of cloud environments—delivered cryptomining payloads through four separate malicious versions released over three days before detection. The attack succeeded because the package had become infrastructure: developers had pinned versions in Dockerfiles and requirements.txt files across thousands of production systems.
The financial impact was staggering. Organizations running the compromised package saw GPU utilization spike to 100% as cryptominers consumed compute resources meant for ML workloads. Some victims reported monthly cloud bills increasing by $50,000 to $150,000 before they identified the cause.
Hugging Face's Ongoing Security Challenges
Hugging Face, the largest repository of open-source ML models, has become ground zero for ML supply chain attacks. In June 2024, a breach exposed authentication tokens affecting potentially 1.2 million users and 10,000+ organizations. These tokens provided API access to download models, access private repositories, and in some cases, upload new model versions.
Security researchers subsequently discovered 100+ malicious models exploiting pickle deserialization vulnerabilities. The "nullifAI" attack technique, identified in January 2025, bypasses Picklescan security tools by using compression formats and malformed pickle files that fail validation but still execute code when loaded by lenient parsers.
Over 80% of Hugging Face models use pickle serialization, representing 2.1+ billion monthly downloads of pickle-based models. Researchers have identified 22 distinct pickle-based model loading paths across five AI/ML frameworks, with 19 of these paths missed by existing security scanners. Security tools face 133 exploitable gadgets with approximately 100% scanner bypass rates.
The Shadow AI Governance Gap
One of the defining characteristics of the 2023-2025 period is the explosion of "Shadow AI"—the unauthorized use of AI tools by employees outside of IT governance. Reports indicate that 72% of IT leaders acknowledge Shadow AI is a significant issue in their organizations. These unmanaged instances often lack enterprise security controls like Single Sign-On (SSO), logging, or data loss prevention (DLP).
Shadow AI introduces three primary risks:
Data Exfiltration: Employees paste sensitive Personally Identifiable Information (PII) or intellectual property into public LLMs like ChatGPT or Claude, where it may be used for model training or logged in vendor systems. A stunning 26% of organizations admit sensitive data has reached public AI services through Shadow AI channels.
Unvetted Vulnerabilities: Developers spin up self-hosted LLMs (like Llama 3 via Ollama) on local machines or cloud instances without patching the underlying container runtime or serving infrastructure. These instances become entry points for attackers scanning for exposed APIs or known vulnerabilities.
Regulatory Non-Compliance: Unmanaged tools bypass requirements for GDPR, HIPAA, SOC 2, or FedRAMP compliance, creating liability blind spots. When auditors ask for evidence of data handling controls, organizations discover they have no visibility into how employees are actually using AI tools.
The economic impact of this governance failure is measurable and severe. Organizations with high levels of Shadow AI face breach costs that are $670,000 higher on average than organizations with strong AI governance. This penalty stems from delayed detection (you can't detect what you can't see), expanded blast radius (Shadow AI often connects to production data), and regulatory fines for non-compliance.
Chapter 2: Training Pipeline Security—The Foundation of Model Integrity
Understanding Training Pipeline Attack Surfaces
The training pipeline is where ML models learn from data. It's also where attackers can inject the most persistent and difficult-to-detect compromises. Unlike traditional application vulnerabilities that can be patched, a compromised model may contain learned behaviors that persist even after you've cleaned up the initial infection.
Training pipeline attacks fall into three categories:
- Data poisoning: Manipulating training data to alter model behavior
- Model serialization exploits: Leveraging unsafe deserialization in model file formats
- Infrastructure compromise: Exploiting vulnerabilities in training platforms and compute clusters
Each attack vector requires different detection mechanisms and mitigation strategies.
Vulnerabilities in Model Serialization Create Critical Risk
The pickle format remains machine learning's most dangerous attack surface. Python's pickle module was designed for serializing Python objects, not for securely storing data. When you unpickle a file, Python executes code to reconstruct objects. Attackers exploit this by embedding malicious code that runs automatically during deserialization.
The numbers are damning: Over 80% of Hugging Face models use pickle serialization, representing 2.1+ billion monthly downloads of potentially vulnerable models. Security researchers have identified 22 distinct pickle-based model loading paths across five major AI/ML frameworks (PyTorch, TensorFlow, Keras, scikit-learn, XGBoost), with 19 of these paths missed by existing security scanners.
Recent CVEs targeting pickle deserialization demonstrate the severity:
| CVE | Description | CVSS Score | Impact |
|---|---|---|---|
| CVE-2025-10155 | File extension bypass for PyTorch extensions (.bin, .pt) allows loading malicious payloads | 9.3 Critical | Remote code execution via model loading |
| CVE-2025-10156 | CRC error introduction to disable ZIP scanning in PyTorch files | 9.3 Critical | Scanner bypass enables malicious model deployment |
| CVE-2025-10157 | Unsafe globals check bypass via subclass exploitation | 9.3 Critical | Arbitrary code execution during deserialization |
| CVE-2025-46417 | Blocklist bypass enabling DNS exfiltration from model loading | 7.5 High | Data exfiltration without triggering egress rules |
Security tools face an uphill battle. Researchers identified 133 exploitable gadgets across common Python libraries with approximately 100% scanner bypass rates. The "Sleepy Pickle" technique demonstrates how attackers can create malicious pickle files that remain dormant until specific conditions trigger malicious behavior. These payloads use ctypes to load shellcode into memory or hook into model inference functions to modify predictions dynamically.
The "nullifAI" attack technique, discovered in January 2025, bypasses Picklescan and similar security tools by embedding malicious payloads in "broken" pickle files. These files fail validation checks but still execute code when loaded by lenient parsers. Other evasion methods include using non-standard compression formats (like 7z instead of zip for PyTorch files) that scanners fail to unpack and inspect.
Mitigation Strategy:
Transition to SafeTensors format wherever possible. SafeTensors is a secure alternative to pickle that stores only tensor data without code. Major frameworks including PyTorch and TensorFlow now support SafeTensors natively.
Implement multi-layered scanning beyond Picklescan:
- Use Protect AI Guardian or HiddenLayer Model Scanner for comprehensive model scanning
- Validate all model artifacts through cryptographic signing before deployment
- Implement behavioral sandboxing: load models in isolated containers and monitor for suspicious system calls
- Maintain an allowlist of approved model hashes and fail deployment for unknown models
Never blindly trust models from public repositories. Even popular models with thousands of downloads can be compromised. Treat model files as untrusted input that requires the same scrutiny you'd apply to user-uploaded files in a web application.
MLflow Vulnerabilities Demand Immediate Attention
MLflow is the most widely deployed ML experiment tracking platform, used by organizations to log experiments, package code into reproducible runs, and share models. Its ubiquity makes it a high-value target. Unfortunately, MLflow has accumulated a concerning number of critical security vulnerabilities.
CVE-2024-0520 (CVSS 10.0 Critical): Remote code execution via command injection in mlflow.data.http_dataset_source.py. Attackers controlling file paths through directory traversal can achieve arbitrary file write and RCE. This vulnerability was fixed in version 2.9.0, but many organizations continue running older versions.
CVE-2024-2928 (CVSS 7.5 High): Local file inclusion via URI fragment manipulation. Improper sanitization of the source parameter allows unauthenticated remote attackers to read arbitrary files from the MLflow server filesystem. This includes configuration files (/etc/passwd), SSH keys, cloud credentials stored in home directories, and other sensitive data. Fixed in version 2.11.3.
CVE-2025-11200 (CVSS 8.1 High): Authentication bypass due to weak password requirements. Remote attackers can brute-force credentials or use default passwords to gain access to MLflow instances. The vulnerability affects all versions up to 2.17.0.
CVE-2025-11201 (CVSS 9.4 Critical): Directory traversal leading to remote code execution. Attackers can manipulate the model source parameter during model creation to write files to arbitrary locations on the server. This can be exploited to overwrite system files, plant web shells, or modify application code. Fixed in version 2.11.3.
The Snyk vulnerability database documents 9 high-severity deserialization vulnerabilities affecting all modern MLflow versions from 0.5.0+ through 3.8.0. These stem from MLflow's use of pickle for model serialization and the platform's handling of user-supplied file paths.
Critical Finding: 68% of surveyed organizations run MLflow versions prior to 2.11.3, meaning they're vulnerable to multiple unauthenticated RCE vectors.
MLflow Configuration Hardening Checklist:
- [ ] Upgrade immediately: Minimum version 2.17.1 or later
- [ ] Implement authentication: MLflow lacks authentication by default—this is unacceptable for production
- [ ] Deploy behind reverse proxy: Use nginx or similar with TLS termination and certificate validation
- [ ] Restrict artifact storage access: Use IAM policies to limit S3/Azure Blob access to specific prefixes
- [ ] Enable comprehensive audit logging: Log all API calls, model uploads, downloads, and deletions
- [ ] Network segmentation: Never expose MLflow server to public internet; deploy in private subnet behind VPN or bastion host
- [ ] Use secrets management: Never hardcode credentials; use HashiCorp Vault or cloud-native secrets managers
- [ ] Implement RBAC: Configure role-based access control to limit who can upload models vs. who can only view experiments
A critical point that many organizations miss: MLflow was designed as a research tool, not a production-grade platform. When you move it into production, you must add security controls that weren't part of the original design. Treat MLflow like you would any other web application handling sensitive data—apply the same security rigor.
Training Data Governance Prevents Poisoning Attacks
Data poisoning represents a particularly insidious threat because effects may not manifest until models reach production. An attacker who can inject carefully crafted samples into your training data can manipulate model behavior in ways that are nearly impossible to detect through static analysis.
Research shows that poisoning just 0.1% of a dataset—one malicious sample per thousand legitimate samples—can successfully manipulate model behavior. For large datasets with millions of examples, this means attackers only need to inject hundreds or thousands of poisoned samples to achieve their goals.
Data poisoning attacks come in two flavors:
Availability Attacks: The goal is to degrade model performance generally. Attackers inject mislabeled samples or corrupted data that reduces overall accuracy. You'll notice this because your model performs worse than expected, but it's difficult to distinguish from natural data quality issues.
Integrity Attacks (Backdoors): The goal is to create targeted behavior. Attackers inject samples that teach the model to misclassify inputs containing a specific trigger (like a particular phrase, image pattern, or metadata value). The model performs normally on benign inputs but misbehaves when it sees the trigger.
Detection techniques for data poisoning must be applied during data ingestion, before training begins:
Embedding Clustering Analysis: Cluster document embeddings using algorithms like DBSCAN or HDBSCAN. Inspect small, high-similarity clusters for potential triggers or backdoor patterns. Legitimate data typically forms large, diverse clusters, while poisoned samples often cluster tightly around the trigger pattern.
Entropy Analysis: Flag documents with unusual token sequences or anomalously low entropy patterns. Poisoned samples may exhibit lower entropy because they're synthetically generated with less diversity than natural text.
Label Consistency Validation: Detect statistical anomalies in label distributions across data batches. Compare against historical baselines. A sudden spike in samples with a particular label, especially if those samples share unusual features, may indicate poisoning.
Provenance Tracking: Maintain cryptographic checksums (SHA-256 or stronger) for all datasets. Track data lineage from source systems through feature engineering to the final training set. Any modification should be auditable with clear attribution to a specific person or automated process.
Implementation Requirements for Training Data Security:
Data versioning and immutability: Use tools like DVC (Data Version Control) or Pachyderm to track dataset versions alongside code commits. Treat datasets as immutable—modifications create new versions rather than overwriting existing data. This enables rollback if poisoning is discovered.
Pin dataset versions: Require approval workflows for modifications. Just as you wouldn't let developers push code changes directly to production without review, don't allow dataset modifications without oversight. Implement a data review process where changes are inspected by data quality engineers.
Statistical outlier detection: Implement automated statistical checks on incoming training batches. Flag batches that deviate significantly from historical distributions for manual review. This catches both accidental data quality issues and deliberate poisoning attempts.
Cryptographic checksums and access logs: Generate cryptographic checksums for all datasets and log every access. This creates an audit trail that enables forensic analysis if you discover a compromised model. You'll be able to determine exactly which dataset version was used for training and who had access to modify it.
Network isolation: Store training data in isolated storage accounts or buckets with no internet access. Use AWS PrivateLink, Azure Private Link, or Google Private Service Connect to enable access from training infrastructure without traversing the public internet.
Chapter 3: Model Validation Security—Establishing Trust Before Deployment
The Validation Gap in ML Pipelines
Most organizations focus security efforts on preventing attacks during training or detecting them in production. The validation stage between these phases is often overlooked. This is where you should verify that models are safe, authentic, and haven't been tampered with before they reach production systems.
Model validation security addresses three critical questions:
- Authenticity: Is this model what it claims to be, produced by our authorized training pipeline?
- Integrity: Has the model been modified since training completed?
- Safety: Does the model contain vulnerabilities or unsafe behavior?
Answering these questions requires implementing artifact signing, provenance tracking, and security scanning as mandatory gates in your CI/CD pipeline.
Artifact Signing with Sigstore Enables Verification
The OpenSSF Model Signing v1.0 library (released April 2025) provides purpose-built signing for ML models of any format and size. Unlike traditional code signing which expects single-file artifacts, Model Signing handles directory-tree model representations critical for large models that span multiple files.
Model signing creates a cryptographic proof that a specific pipeline produced a specific model. When you later deploy that model, you can verify the signature to ensure the file hasn't been modified and came from an authorized source.
Basic Model Signing Workflow:
# Install the model-signing library
pip install model-signing
# Sign a model using keyless Sigstore signing
# This uses your OIDC identity (Google, GitHub, etc.) as the signing identity
model-signing sign --model ./my_model --output signature.sigstore
# Verify model signature before deployment
# This checks that the model was signed by trainer@org.com via Google OIDC
model-signing verify --model ./my_model --signature signature.sigstore \
--certificate-identity=trainer@org.com \
--certificate-oidc-issuer=https://accounts.google.comThe keyless signing approach uses Sigstore's transparency log and OIDC identity verification. Instead of managing long-lived signing keys (which can be stolen or lost), you prove identity at signing time using your existing authentication provider. The signature binds the model to your identity, making it impossible to forge without compromising your OIDC account.
Container Image Signing for ML Deployments:
When you package models into container images for deployment, sign the entire image:
# Sign ML container image with Cosign
# This creates a signature stored in the container registry
cosign sign gcr.io/project/ml-model:v1.0
# Verify signature before deployment in CI/CD pipeline
# The deployment will fail if signature is missing or invalid
cosign verify gcr.io/project/ml-model:v1.0 \
--certificate-identity=ci@org.com \
--certificate-oidc-issuer=https://github.com/login/oauth
# Attach Software Bill of Materials (SBOM) to container
# This provides transparency into all components in the image
cosign attach sbom --sbom sbom.json gcr.io/project/ml-model:v1.0Kubernetes admission controllers can enforce that only signed images are deployed. This prevents attackers who compromise your container registry from injecting malicious images. Even if they can upload a container, they can't sign it with your organization's identity.
Implementation Considerations:
Key management: For keyless signing with Sigstore, no key management is required—signatures are bound to OIDC identities. For traditional signing with stored keys, use cloud KMS services (AWS KMS, Azure Key Vault, Google Cloud KMS) with strict access controls.
CI/CD integration: Signing should happen automatically in your CI/CD pipeline after model training completes. Verification should happen before deployment to any environment (dev, staging, production). A failed signature verification should halt deployment immediately.
Emergency procedures: Document procedures for emergency model deployment when signature verification fails. This might be legitimate (certificate rotation, OIDC provider change) or indicate compromise. Have a process that requires manual approval from security team for unsigned deployments.
SLSA Framework Adoption Provides Supply Chain Guarantees
Supply-chain Levels for Software Artifacts (SLSA, pronounced "salsa") provides incrementally adoptable guidelines for securing software supply chains. While originally designed for traditional software, SLSA principles apply directly to ML pipelines.
SLSA defines four levels of supply chain security maturity:
| SLSA Level | Requirements | MLOps Application | Implementation Complexity |
|---|---|---|---|
| L0 | No guarantees | Most organizations today—no provenance tracking | N/A |
| L1 | Provenance exists | Build platform generates metadata showing how model was trained | Low—add logging to training jobs |
| L2 | Signed provenance | Training runs on hosted platform (not laptops); platform signs provenance | Medium—requires CI/CD integration |
| L3 | Tamper-proof builds | Hardened training environment; isolated builds; non-falsifiable provenance | High—dedicated infrastructure required |
| L4 | Two-party review | All changes reviewed by separate party; hermetic builds | Very High—cultural and technical changes |
For ML pipelines, achieving SLSA Level 2 provides significant security improvements with reasonable implementation effort:
What SLSA L2 Requires:
Hosted build platform: Training must run on controlled infrastructure, not data scientist laptops. Use managed platforms like AWS SageMaker, Google Vertex AI, Azure ML, or self-hosted Kubeflow clusters. The platform must generate provenance metadata for every training run.
Signed provenance: The platform must cryptographically sign provenance metadata using a key that only the platform controls. This prevents attackers from forging provenance for malicious models.
Provenance metadata contents: The provenance must document:
- Source code commit hash used for training
- Dataset version/hash used for training
- Hyperparameters and configuration
- Build platform identity and version
- Timestamp of training
- Output model hash
Verification at deployment: Deployment pipelines must verify provenance signatures and check that the model came from an authorized build platform using approved source code and data.
Treating Training Environments Like Build Platforms:
Traditional software development moved from developers compiling code on their local machines to centralized build servers years ago. ML is going through the same transition. Training data versioning is the ML equivalent of source code versioning—you must track exactly which data produced which model.
Move training off data scientist laptops to locked-down infrastructure. This doesn't mean data scientists can't iterate rapidly. It means when they're ready to train a model for deployment, that training happens on controlled infrastructure that generates provenance.
Implementation Roadmap:
Week 1-2: Audit current training practices. Identify which models are trained on laptops vs. controlled infrastructure. Document the gap.
Week 3-4: Deploy or configure a training platform that can generate provenance (MLflow, Kubeflow, or cloud-managed service). Set up cryptographic signing for provenance metadata.
Week 5-8: Migrate high-risk models (production, customer-facing) to the new training platform. Ensure provenance is generated for every training run.
Week 9-12: Implement verification gates in deployment pipelines. Models without valid provenance cannot be deployed to production.
Month 4+: Achieve SLSA L3 by implementing hermetic builds (no network access during training except to approved data sources), tamper-proof build environments, and comprehensive audit logging.
SBOM Generation Must Include ML-Specific Metadata
Traditional Software Bills of Materials (SBOMs) document software dependencies—the libraries and packages your application uses. This enables vulnerability management: when a CVE is published for a dependency, you can quickly identify which applications are affected.
ML systems need SBOMs that extend beyond code dependencies to include:
- Training data provenance: Which datasets were used, their versions, and checksums
- Model architecture: Network structure, layer configurations, parameter counts
- Hyperparameters: Learning rates, batch sizes, optimization settings
- Framework versions: PyTorch 2.0.1, TensorFlow 2.14.0, etc.
- Pre-trained components: Which base models were fine-tuned
- Training compute: GPU types, training duration, environmental impact
CycloneDX v1.5+ introduced the ML-BOM component type specifically for machine learning:
<component type="machine-learning-model">
<name>sentiment-classifier</name>
<version>1.0.0</version>
<ml-extensions>
<ml:model>
<ml:type>classification</ml:type>
<ml:architecture>transformer</ml:architecture>
<ml:framework>pytorch-2.0</ml:framework>
<ml:training-data>
<ml:dataset name="imdb-reviews"
hash="sha256:8f434b123a95e8963c4d6..."
license="MIT"
recordCount="50000"/>
</ml:training-data>
<ml:hyperparameters>
<ml:parameter name="learning_rate" value="0.001"/>
<ml:parameter name="batch_size" value="32"/>
<ml:parameter name="epochs" value="10"/>
</ml:hyperparameters>
</ml:model>
</ml-extensions>
</component>This XML structure (or equivalent JSON/YAML) provides transparency into what's inside your model. When a vulnerability is discovered in a dataset or pre-trained component, you can identify which models are affected.
Tool Recommendations for SBOM Generation:
| Tool | Strengths | Best For | Limitations |
|---|---|---|---|
| Syft | Container/package scanning, broad format support (SPDX, CycloneDX) | General dependency inventories, quick scans | Limited ML-specific metadata extraction |
| Trivy | Integrated vulnerability scanning + SBOM generation, large CVE database | Combined vulnerability + SBOM workflows | Basic ML support, requires custom configs |
| AIsbom | Deep model introspection, pickle detection, ML-specific metadata | ML-specific scanning, detecting unsafe serialization | Newer tool, smaller community |
| cdxgen | CycloneDX native, broad language support, active development | Standard-compliant ML-BOMs | Configuration complexity for custom metadata |
Implementation Workflow:
# Generate SBOM for Python dependencies
syft packages dir:./model-repo -o cyclonedx-json > sbom-deps.json
# Generate SBOM for container image
trivy image --format cyclonedx --output sbom-container.json \
gcr.io/project/ml-model:v1.0
# Merge and enrich with ML-specific metadata
# (This typically requires custom scripting to extract training metadata from MLflow, etc.)
python enrich_ml_bom.py --base sbom-container.json \
--training-run mlflow:run/abc123 \
--output sbom-complete.json
# Store SBOM alongside model in registry
cosign attach sbom --sbom sbom-complete.json \
gcr.io/project/ml-model:v1.0Why ML-BOMs Matter:
When CVE-2024-21626 (the runc container escape vulnerability) was disclosed, organizations with comprehensive SBOMs could identify affected deployments in hours. Those without SBOMs spent weeks manually auditing systems.
When a poisoned dataset is discovered on Hugging Face, ML-BOMs allow you to instantly identify which models used that dataset and may be compromised. Without ML-BOMs, you're left guessing which models might be affected.
Regulatory frameworks including the EU AI Act and proposed US AI legislation increasingly require transparency into AI system components. ML-BOMs provide the evidence auditors and regulators need to verify compliance.
Chapter 4: Deployment Pipeline Security—Protecting the CI/CD Surface
Understanding CI/CD Attack Vectors in ML
Deployment pipelines are where trained models transition from development to production. They're also where attackers can intercept, modify, or replace models with malicious versions. Traditional CI/CD security focuses on code—preventing injection attacks, securing build environments, managing secrets. ML pipelines require all of this plus model-specific controls.
The attack surface includes:
- CI/CD platforms: Jenkins, GitHub Actions, GitLab CI, CircleCI
- Container registries: Docker Hub, GCR, ECR, ACR
- Model registries: MLflow Model Registry, Azure ML Models, SageMaker Model Registry
- Orchestration platforms: Kubeflow, Ray, Airflow
- Serving infrastructure: KServe, TorchServe, TensorFlow Serving
- Cloud ML platforms: SageMaker, Vertex AI, Azure ML
Each component has its own vulnerabilities and misconfigurations that attackers exploit.
ShadowRay Demonstrates Catastrophic CI/CD Exposure
CVE-2023-48022 in Ray/Anyscale represents the first known attack campaign actively targeting AI workloads at scale. The vulnerability—missing authentication in the Jobs API—allows unauthenticated remote code execution. Critically, this CVE is disputed by the vendor, meaning static vulnerability scanners don't flag it as a security issue.
Ray is a distributed computing framework for scaling machine learning workloads. Organizations use it to parallelize training across GPU clusters and serve models at scale. By default, Ray's dashboard binds to 0.0.0.0 (all network interfaces) on port 8265 without any authentication. The vendor's position is that Ray should be deployed behind a firewall or VPN, not exposed to the internet.
The ShadowRay attack campaign, ongoing since September 2023, has exploited over 500 exposed Ray dashboards globally for cryptocurrency mining, credential theft, and persistent access. Affected sectors include education (university research clusters), cryptocurrency firms (ironically), and biopharmaceutical companies with ML workloads.
Attack Flow:
Step 1: Attackers use Shodan or similar internet scanning tools to identify exposed Ray dashboards on port 8265. Search query: port:8265 title:"Ray Dashboard" returns hundreds of results.
Step 2: Access Jobs API via HTTP without any credentials. The Jobs API accepts Python code as input and executes it on Ray worker nodes.
Step 3: Deploy cryptocurrency mining software (typically XMRig) that consumes 100% of GPU resources. For clusters with multiple NVIDIA A100 GPUs, the compute cost can exceed $50,000 per month.
Step 4: Maintain persistent access by deploying reverse shells or SSH backdoors. This allows attackers to return even if the mining software is discovered and removed.
Step 5: Exfiltrate credentials from environment variables, steal training data from attached storage, and access other infrastructure through cloud credentials.
The financial impact extends beyond stolen compute. Organizations lose access to GPU resources needed for legitimate work, miss research deadlines, and face potential data breaches if training data is exfiltrated.
Mandatory Mitigations:
Never expose Ray clusters to the public internet. Deploy Ray in private VPCs with no inbound internet access. Access should only be possible via VPN or bastion hosts.
Implement authentication proxy. Deploy an authentication layer (OAuth2 proxy, OpenID Connect) in front of Ray's dashboard on port 8265. All requests must authenticate before reaching Ray.
Network policies. Use Kubernetes NetworkPolicy or cloud security groups to restrict port 8265 access to known source IPs only.
Monitoring and alerting. Monitor for unusual CPU/GPU usage patterns that might indicate cryptomining. Alert on new outbound network connections from Ray worker nodes.
Treat this as critical regardless of vendor dispute. The attack campaign is real, the exploits are public, and the financial impact is severe. Don't rely on the vendor's assessment that this isn't a vulnerability.
AWS SageMaker's Shadow Roles Create Privilege Escalation Paths
Amazon SageMaker is one of the most widely used managed ML platforms. Research by Aqua Security identified that default execution roles (AmazonSageMaker-ExecutionRole-*) are granted overly broad S3 permissions equivalent to AmazonS3FullAccess. This creates multiple privilege escalation paths.
The Problem:
When you create a SageMaker notebook instance or training job, SageMaker automatically creates an IAM role with permissions to access S3 buckets containing training data and model artifacts. By default, these roles have read/write access to all S3 buckets, not just those needed for the specific workload.
Attack Scenarios:
ECR Repository Enumeration: The overly permissive role can list all Elastic Container Registry (ECR) repositories in the account and pull container images, potentially exposing proprietary ML frameworks or models embedded in containers.
S3 Bucket Manipulation: Attackers who compromise a SageMaker instance can read/write any S3 bucket, enabling them to poison training data, exfiltrate models, or access sensitive data from other projects.
Glue Data Catalog Manipulation: The default role can modify AWS Glue data catalog, potentially redirecting data queries to attacker-controlled datasets or exposing metadata about data sources.
CloudFormation Template Poisoning: By modifying CloudFormation templates stored in S3, attackers can alter infrastructure-as-code definitions to create backdoors or persistence mechanisms.
SageMaker Hardening Requirements:
- [ ] Scope down IAM roles: Grant access only to specific S3 prefixes needed for each workload. Use resource-based policies with bucket/prefix restrictions.
- [ ] Disable root access: Root access on notebook instances is enabled by default—disable it. Use IAM roles and temporary credentials instead.
- [ ] Restrict lifecycle configurations: Lifecycle configuration scripts run with root privileges and can be used to install backdoors. Limit who can create/modify lifecycle configs.
- [ ] Disable direct internet access: SageMaker instances can access the public internet by default. Disable this and use VPC endpoints for AWS service access.
- [ ] Use VPC endpoints: Route all AWS service traffic through VPC endpoints rather than traversing the public internet. This prevents data exfiltration via internet-bound connections.
- [ ] Implement service control policies: Use AWS Organizations to enforce security controls at the organization level, preventing creation of overly permissive roles.
- [ ] Enable encryption: Enforce encryption at rest for EBS volumes, S3 buckets, and inter-node communication. Use AWS KMS with customer-managed keys.
- [ ] Audit and monitoring: Enable CloudTrail logging for all SageMaker API calls. Set up CloudWatch alarms for suspicious activities like mass S3 access or unusual training job configurations.
Critical Finding: In a survey of 500+ AWS accounts with SageMaker usage, 90.5% had notebook instances with root access enabled, and 82% had instances with direct internet access. These misconfigurations are the default state—security requires deliberate configuration changes.
Kubeflow Security Requires Explicit Configuration
Kubeflow is a machine learning toolkit for Kubernetes, providing a complete ML platform including pipelines, notebooks, training operators, and serving infrastructure. It operates as a complex orchestration layer on top of Kubernetes, inheriting risks from both its own codebase and the underlying container runtime.
Kubeflow lacks formal CVE assignments for many vulnerabilities, but documented critical security issues include:
Authentication Bypass via Header Injection:
The "userid" header that Kubeflow uses for authentication is easily faked due to misconfigured Istio sidecars. Attackers can set this header in HTTP requests to impersonate other users, including administrators. This enables unauthorized access to pipelines, models, and data.
Root Cause: Kubeflow relies on Istio service mesh for authentication but doesn't properly validate that the userid header came from a trusted source. External attackers can inject this header, bypassing authentication entirely.
Istio Service Misconfiguration:
Users with permissions to modify Kubernetes Service resources can change Istio Service type from ClusterIP to LoadBalancer, exposing Kubeflow dashboards directly to the internet. This enables full cluster compromise. Microsoft documented cryptocurrency mining campaigns specifically targeting exposed Kubeflow clusters discovered via internet scanning.
Attack Flow: Attacker identifies misconfigured Kubeflow dashboard exposed via LoadBalancer → Bypasses authentication via header injection → Submits malicious pipeline that deploys cryptominer to all nodes → Maintains persistence via modified pipelines that automatically redeploy miners.
CVE-2024-9526 (Stored XSS):
The Kubeflow Pipelines UI is vulnerable to stored Cross-Site Scripting (XSS) via the pipeline description field. This allows attackers to inject malicious JavaScript that executes in the browser of other users—potentially administrators. Attackers can steal session tokens, manipulate pipeline configurations, or inject malicious steps into existing pipelines.
Supply Chain Dependencies:
Kubeflow deployments rely on numerous sub-components: Istio for service mesh, Argo for workflow orchestration, JupyterHub for notebooks, TensorFlow Serving for inference. Vulnerabilities in any of these components affect Kubeflow security. For example, CVE-2024-10220 in Kubernetes kubelet (arbitrary command execution via gitRepo volumes) directly impacts ML workloads running on Kubeflow clusters.
Kubeflow 1.7+ Mitigations:
ServiceAccount-based authentication: Use Kubernetes ServiceAccounts for machine-to-machine authentication rather than relying on HTTP headers. This binds authentication to Kubernetes RBAC.
Enhanced Istio sidecar configurations: Implement Istio AuthorizationPolicy resources to validate authentication tokens and prevent header injection. Use mutual TLS (mTLS) for all inter-service communication.
Periodic CVE scanning: Scan all container images in Kubeflow deployments (JupyterHub, pipelines, training operators) for known vulnerabilities. Automate this in CI/CD pipelines.
Strict NetworkPolicy: Implement default-deny NetworkPolicy for all Kubeflow namespaces. Explicitly allow only required traffic between components.
Never expose dashboard via LoadBalancer: Use Ingress with authentication (OAuth2 proxy) instead. Require VPN access for administrative interfaces.
RBAC hardening: Follow principle of least privilege. Pipeline runner ServiceAccounts should not have cluster-admin permissions. Create narrow roles for specific operations.
Admission controllers: Deploy OPA Gatekeeper or Kyverno policies to prevent creation of LoadBalancer Services, enforce security contexts (no root containers), and require resource limits.
Secrets Management Prevents Credential Exposure
Credential exposure is the leading cause of breaches in ML pipelines. Data scientists frequently hardcode API keys in Jupyter notebooks, commit environment files to GitHub, or store credentials in plaintext configuration files. Proper secrets management is non-negotiable.
HashiCorp Vault Agent Sidecar Pattern for Kubernetes:
apiVersion: v1
kind: Pod
metadata:
name: ml-training-job
annotations:
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/role: "ml-training-role"
vault.hashicorp.com/agent-inject-secret-db-creds: "secret/data/ml/database"
vault.hashicorp.com/agent-inject-template-db-creds: |
{{- with secret "secret/data/ml/database" -}}
export DB_HOST="{{ .Data.data.host }}"
export DB_PASSWORD="{{ .Data.data.password }}"
{{- end }}
spec:
serviceAccountName: ml-training-sa
containers:
- name: training-job
image: ml-training:v1.0
command: ["/bin/bash"]
args: ["-c", "source /vault/secrets/db-creds && python train.py"]This pattern uses Vault Agent as an init container and sidecar. The agent authenticates using the pod's ServiceAccount token, retrieves secrets from Vault, and writes them to a shared volume. The main container reads secrets from the volume, never storing them in environment variables or code.
Benefits:
- Secrets never appear in container images or pod specifications
- Automatic rotation: Vault Agent periodically renews secrets and updates the shared volume
- Audit trail: Vault logs every secret access with ServiceAccount identity
- Least privilege: Each workload has a specific Vault role with access to only required secrets
GitHub Actions Integration for CI/CD:
name: Train and Deploy Model
on:
push:
branches: [main]
jobs:
train:
runs-on: ubuntu-latest
permissions:
id-token: write # Required for OIDC authentication
contents: read
steps:
- uses: actions/checkout@v4
- name: Import Secrets from Vault
uses: hashicorp/vault-action@v2
with:
url: https://vault.company.com
method: jwt
role: github-actions-ml
secrets: |
secret/data/ml/aws access_key | AWS_ACCESS_KEY_ID ;
secret/data/ml/aws secret_key | AWS_SECRET_ACCESS_KEY ;
secret/data/ml/model api_key | MODEL_API_KEY
- name: Train Model
run: python train.py
env:
AWS_ACCESS_KEY_ID: ${{ env.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ env.AWS_SECRET_ACCESS_KEY }}This uses GitHub Actions' OIDC provider to authenticate to Vault without long-lived tokens. Vault issues short-lived credentials for the duration of the workflow, which expire automatically after the job completes.
Cloud-Native Alternatives:
AWS Secrets Manager: Integrates with ECS, EKS, Lambda, and SageMaker. Use IAM roles for authorization rather than hardcoded credentials.
Azure Key Vault: Integrates with AKS, Azure ML, and Azure Functions. Use Managed Identity for authentication.
Google Secret Manager: Integrates with GKE, Vertex AI, and Cloud Functions. Use Workload Identity for authentication.
Secrets Management Requirements:
- Use dynamic/ephemeral secrets where possible. Generate credentials on-demand and revoke them when the workload completes.
- Implement automatic rotation on 30-90 day cycles. Long-lived credentials increase the window of opportunity for compromise.
- Separate secrets by environment (dev/staging/prod). A breach in dev shouldn't expose production credentials.
- Use workload identity for cloud-native authentication. This eliminates the need to manage credentials at all—the platform handles authentication.
- Never store secrets in environment variables long-term. Environment variables appear in process listings and container inspect output. Use temporary files or in-memory storage.
- Audit all secret access. Log which workload accessed which secret and when. This enables forensic analysis after a breach.
Chapter 5: Production Monitoring—Detecting Compromise in Running Systems
The Monitoring Gap in ML Operations
Most security monitoring focuses on network traffic, system logs, and application behavior. ML systems require additional monitoring dimensions:
- Model behavior: Are predictions consistent with expected performance?
- Data distribution: Has input data shifted significantly?
- Resource utilization: Are GPUs/CPUs showing unusual patterns?
- Model access patterns: Who's querying the model and how frequently?
- Model registry activity: Are unauthorized users downloading model weights?
Traditional Security Information and Event Management (SIEM) systems don't automatically capture these ML-specific signals. You must explicitly integrate ML platform logs and build detection rules for AI-specific threats.
SIEM Integration Requires ML-Specific Detection Rules
Your existing SIEM (Splunk, Sentinel, Chronicle, Datadog) can detect ML threats if you feed it the right data and write appropriate detection rules.
Essential Log Sources:
Model Registry Events:
- Model uploads/downloads (who, what, when)
- Version changes and deletions
- Metadata modifications (description, tags)
- Access attempts (successful and failed)
Training Job Logs:
- Resource consumption (GPU utilization, memory usage)
- Data access patterns (which datasets were read)
- Model serialization events (pickle loads, SavedModel creation)
- Training duration and completion status
Inference Logs:
- API requests and responses
- Prediction latency and throughput
- Confidence score distributions
- Input validation failures
- Rate limiting triggers
Infrastructure Logs:
- Container creation/destruction events
- Kubernetes audit logs (API server access)
- Cloud provider activity (AWS CloudTrail, Azure Activity Log, GCP Audit Logs)
- Network flow logs (VPC Flow Logs, NSG Flow Logs)
Sample Detection Rules:
# Anomalous Model Download Volume
rule_name: "Potential Model Exfiltration"
description: "Detects excessive model downloads by a single user"
condition: |
model_registry_event.action == "download" AND
count(model_id) BY user_id OVER 1h > 10 AND
user_id NOT IN allowed_ml_engineers
severity: HIGH
mitre_atlas: AML.T0037 # Model Replication
response:
- Alert SOC team
- Suspend user account temporarily
- Review recent downloads for legitimacy
# Excessive Training Data Access
rule_name: "Data Exfiltration via Training"
description: "Detects training jobs accessing unusually large data volumes"
condition: |
training_job.data_volume_gb > baseline_mean + (3 * baseline_stddev) AND
training_job.user NOT IN authorized_trainers AND
training_job.duration_minutes < 30 # High volume, short duration suspicious
severity: CRITICAL
mitre_atlas: AML.T0002 # Data Collection
response:
- Terminate training job immediately
- Alert incident response team
- Investigate data access logs
# Suspicious Model Registry Access
rule_name: "Unauthorized Model Registry Access"
description: "Detects access to model registry from unexpected IP addresses"
condition: |
model_registry_event.action IN ["download", "upload"] AND
source_ip NOT IN corporate_ip_ranges AND
user_agent NOT IN known_automated_systems
severity: MEDIUM
mitre_atlas: AML.T0040 # ML Supply Chain Compromise
response:
- Log for investigation
- Require MFA re-authentication
- Alert user of suspicious activity
# Container Escape Indicators
rule_name: "Potential Container Escape Attempt"
description: "Detects syscalls associated with container breakout"
condition: |
syscall IN ["mount", "unshare", "pivot_root", "ptrace"] AND
container_runtime == "runc" AND
process_name NOT IN known_legitimate_processes
severity: CRITICAL
mitre_attack: T1611 # Escape to Host
response:
- Terminate container immediately
- Isolate affected node
- Trigger incident response
# GPU Cryptomining Detection
rule_name: "Cryptocurrency Mining Detection"
description: "Detects processes associated with cryptomining on GPU resources"
condition: |
(process_name MATCHES /(xmrig|ethminer|cgminer)/ OR
gpu_utilization > 95% AND
process_name NOT IN authorized_training_jobs) AND
network_connection TO mining_pool_ips
severity: HIGH
mitre_attack: T1496 # Resource Hijacking
response:
- Terminate offending process
- Alert security team
- Audit all running jobs for compromiseBaseline and Anomaly Detection:
Static rules catch known-bad patterns. Anomaly detection catches novel attacks by identifying deviations from normal behavior:
Statistical baselines: Calculate mean and standard deviation for key metrics (model download frequency, training data volume, prediction latency) over a rolling 30-day window. Alert when current values exceed 3 standard deviations.
User behavioral analytics (UBA): Build profiles of normal behavior for each user (which models they access, typical working hours, usual data volumes). Alert on significant deviations.
Peer group comparison: Compare behavior of similar roles. If one data scientist is downloading 10x more models than peers, investigate.
Model Tampering Detection Requires Runtime Verification
How do you distinguish natural model drift from malicious tampering? Both can cause prediction accuracy to decline, but they have different characteristics and require different responses.
Distinguishing Natural Drift from Tampering:
| Indicator | Natural Drift | Potential Tampering |
|---|---|---|
| Change pattern | Gradual, correlates with known data shifts (seasonal trends, market changes) | Sudden, unexplained performance degradation or improvement |
| Affected predictions | Broad impact across input space, consistent with environmental changes | Narrow, targeted impact on specific input patterns (backdoor triggers) |
| Model file integrity | Checksums match registered versions, signatures valid | Modified checksums, signature verification failures, unexplained version changes |
| Behavioral changes | Consistent with concept drift metrics, affects all users similarly | Isolated anomalies, different behavior for different users, triggered by specific inputs |
| Correlation with data | Input data distribution shifts observable in monitoring | Behavior changes without corresponding data distribution shift |
Runtime Integrity Verification:
# Verify model signature at deployment time
cosign verify --key cosign.pub model-registry.example.com/my-model:v1.2.3
# GPU-accelerated hash verification for large models
# For models too large to hash efficiently at each inference request,
# implement Merkle tree verification for partial integrity checks
# Example: Compute Merkle root at deployment, verify leaf nodes periodically
python verify_model_integrity.py \
--model /models/production/fraud-detector-v2.1.pb \
--expected-root-hash sha256:8f434b123a95e8963c4d6... \
--verify-sample-rate 0.01 # Verify 1% of leaves per hourFor very large models (multi-gigabyte transformers), computing full file hashes on every deployment is impractical. Use Merkle trees: build a tree of hashes where each leaf is a chunk of the model file, and each non-leaf node is the hash of its children. You can verify specific parts of the model efficiently by checking only the relevant branch of the tree.
Behavioral Canaries:
Inject known test inputs at regular intervals (every 5-10 minutes) and validate expected outputs. These "canary" inputs should cover:
- Normal cases (expected to classify correctly)
- Edge cases (boundary conditions)
- Known-backdoor patterns (should NOT trigger backdoor behavior)
Statistical deviation from expected canary responses triggers immediate investigation. For example, if your fraud detection model has 95% accuracy on a validation canary set, and suddenly drops to 87%, investigate for tampering.
Implementation Example:
import hashlib
import numpy as np
from typing import List, Dict
class RuntimeModelIntegrityChecker:
def __init__(self, model_path: str, expected_hash: str,
canary_inputs: List[np.ndarray],
canary_labels: List[int]):
self.model_path = model_path
self.expected_hash = expected_hash
self.canary_inputs = canary_inputs
self.canary_labels = canary_labels
self.integrity_failures = 0
def verify_model_hash(self) -> bool:
"""Verify model file hasn't been modified"""
sha256 = hashlib.sha256()
with open(self.model_path, 'rb') as f:
while chunk := f.read(8192):
sha256.update(chunk)
current_hash = sha256.hexdigest()
if current_hash != self.expected_hash:
self.alert_integrity_failure(
f"Model hash mismatch: expected {self.expected_hash}, "
f"got {current_hash}"
)
return False
return True
def run_canary_checks(self, model) -> bool:
"""Run canary inputs and verify expected outputs"""
predictions = model.predict(self.canary_inputs)
accuracy = np.mean(predictions == self.canary_labels)
expected_accuracy = 0.95 # Based on validation set
threshold = 0.90 # Alert if drops below 90%
if accuracy < threshold:
self.alert_integrity_failure(
f"Canary accuracy dropped to {accuracy:.2%}, "
f"expected {expected_accuracy:.2%}"
)
return False
return True
def alert_integrity_failure(self, message: str):
"""Send alert to security team and trigger rollback"""
self.integrity_failures += 1
# Send to SIEM
send_alert_to_siem({
"severity": "CRITICAL",
"signature": "MODEL_INTEGRITY_FAILURE",
"message": message,
"model_path": self.model_path,
"failure_count": self.integrity_failures
})
# Trigger automatic rollback if multiple failures
if self.integrity_failures >= 3:
trigger_model_rollback(self.model_path)This code performs both file-level integrity checks (verifying hash matches expected) and behavioral checks (verifying predictions on canary inputs match expectations). Multiple failures trigger automatic rollback to the last known-good model version.
Specialized ML Security Platforms Provide Deeper Visibility
While general-purpose security tools (SIEM, cloud security posture management) can detect some ML threats, specialized platforms offer deeper visibility into ML-specific attack patterns.
HiddenLayer AISec Platform:
HiddenLayer analyzes billions of model interactions per minute, detecting patterns indicative of model theft, adversarial attacks, and inference abuse. Key capabilities:
Model Genealogy: Tracks model lineage from training data through deployment. When a model exhibits unexpected behavior, you can trace back to identify which training run and data version produced it.
AIBOM Generation: Automatically generates AI Bills of Materials documenting model components, dependencies, and security metadata. This enables rapid vulnerability response when CVEs are published.
MLDR (Machine Learning Detection & Response): Purpose-built detection rules for ML-specific threats including model inversion attacks, extraction attacks, and membership inference attacks. Zero successful bypasses reported at DEF CON AI Village testing.
Protect AI Platform:
Protect AI offers a suite of tools across the ML security lifecycle:
Guardian: Model import security scanning. Analyzes models before they enter your infrastructure, detecting pickle exploits, malicious code, and unsafe deserialization patterns. Scanned over 4 million models, identifying 352,000+ distinct security issues.
Recon: ML red teaming tool. Automatically tests models for vulnerabilities including adversarial examples, prompt injection, data extraction, and bias. Provides actionable remediation guidance.
Layer: Runtime monitoring for ML workloads. Tracks inference requests, detects anomalous query patterns, and identifies potential extraction attacks in progress.
Protect AI backs these tools with the huntr bug bounty platform, which has 17,000+ security researchers finding vulnerabilities in ML frameworks and models.
Robust Intelligence (now Cisco AI Defense):
Acquired by Cisco in October 2024 for approximately $400 million, Robust Intelligence provides:
Model File Scanning: Analyzes model artifacts for unsafe serialization, embedded code, and supply chain risks. Integrates with CI/CD pipelines as a security gate.
AI Validation: Automated red teaming that tests models against adversarial attacks, data poisoning, and extraction attempts. Generates detailed security reports for compliance.
AI Firewall: Runtime guardrails for production models. Filters malicious inputs, detects adversarial examples, prevents extraction attacks, and enforces output sanitization.
The Cisco acquisition signals that large enterprises are taking ML security seriously and integrating it into their broader security infrastructure.
Open-Source Alternatives:
Falco: Runtime security for containers with system call monitoring. Can detect container escapes, unauthorized file access, and suspicious network connections. Widely deployed in Kubernetes environments. Requires custom rules for ML-specific threats.
ModelScan: Static analysis tool that scans ML models for unsafe code patterns. Detects pickle exploits, unsafe deserialization in TensorFlow SavedModels, and suspicious embedded files. Limited to static analysis—can't catch runtime attacks.
Evidently AI: Data drift and model quality monitoring. Tracks input data distribution shifts, prediction distribution changes, and model performance degradation. Helps distinguish natural drift from tampering. Doesn't detect security threats directly but provides the metrics you need.
Choosing the Right Platform:
- For comprehensive coverage: Commercial platforms (HiddenLayer, Protect AI, Cisco AI Defense) offer the deepest ML-specific visibility
- For budget-conscious deployments: Combine open-source tools (Falco + ModelScan + Evidently AI) with custom detection rules in your SIEM
- For regulatory compliance: Commercial platforms provide the documentation and audit reports that regulators expect
Chapter 6: Compliance Requirements Mandate Specific Controls
SOC 2 Applies Existing Criteria to ML Systems
SOC 2 (Service Organization Control 2) audits evaluate security controls based on Trust Service Criteria. These criteria aren't AI-specific—they cover access control, data protection, availability, and confidentiality for any system. However, auditors increasingly ask about AI-specific risks during SOC 2 examinations.
Key Evidence Requirements for ML:
Common Criteria 2.1 (COSO Principle 3: Objectives for Internal Control): Auditors verify that security objectives cover ML-specific risks. You must demonstrate that you've identified ML threats (data poisoning, model theft, adversarial attacks) and mapped them to control objectives.
CC6.1 (Logical and Physical Access Controls): Evidence needed:
- Access logs showing restricted access to training data (who can read/modify training datasets)
- Data lineage documentation from raw input through production inference
- Proof that customer data doesn't contaminate training corpus
- Model artifact versioning with traceable deployment history
- Role-based access control (RBAC) showing separation between data scientists (can train models) and production engineers (can deploy models)
CC6.6 (System Availability): Demonstrate that model serving infrastructure has availability controls:
- Redundant deployment across multiple availability zones
- Automated health checks and failover mechanisms
- Rollback procedures tested and documented
CC7.2 (Detection and Monitoring): Evidence of monitoring for ML-specific threats:
- SIEM integration with ML platform logs
- Detection rules for model tampering, credential theft, unusual data access
- Incident response playbooks for ML-specific scenarios
Common Gaps in MLOps SOC 2 Implementations:
Inability to trace data lineage: Auditors ask "show me which data was used to train this production model." Many organizations can't answer this question because they don't track dataset versions systematically.
Looser access controls in training environments: Organizations implement strict controls in production but allow open access to training infrastructure, not realizing that compromised training pipelines lead to compromised production models.
Model retraining bypassing change advisory: Production models get retrained and deployed automatically without the same change management processes that code deployments require. Auditors view this as a control gap.
Remediation Approach:
Implement data version control (DVC, Pachyderm) to track datasets alongside code. Require approval workflows for production model updates, treating them like code deployments. Extend RBAC to training environments with the same rigor as production. Document everything—SOC 2 is about evidence.
ISO 27001:2022 Adds Controls Relevant to AI
ISO 27001 is the international standard for information security management systems (ISMS). The 2022 revision introduced new controls applicable to AI:
Annex A.5.23 (Information Security for Use of Cloud Services): Covers cloud-based ML infrastructure security:
- Vendor risk assessment for ML platforms (AWS SageMaker, Google Vertex AI, Azure ML)
- Data residency and sovereignty for training data
- Shared responsibility model documentation
- Cloud service configuration hardening
Annex A.8.9 (Configuration Management): Applies to model and pipeline configuration governance:
- Configuration baselines for training pipelines
- Change management for model hyperparameters
- Version control for model architectures and configurations
- Configuration drift detection
Annex A.8.11 (Data Masking): Covers training data de-identification:
- PII removal or tokenization in training datasets
- Differential privacy techniques for sensitive data
- Synthetic data generation for testing
- Validation that models don't memorize sensitive information
Annex A.8.12 (Data Leakage Prevention): Addresses model memorization and output filtering:
- DLP controls on model outputs (filtering PII, credentials, sensitive data)
- Membership inference attack prevention
- Model inversion attack mitigation
- Output sanitization for LLMs (preventing regurgitation of training data)
ISO 27001 alone doesn't fully address AI-specific risks. The standard recommends combining ISO 27001 with ISO 42001 (AI Management System) for comprehensive governance.
ISO 42001: The AI Management System Standard
ISO/IEC 42001, published in December 2023, is the first global standard for AI Management Systems (AIMS). It extends principles from ISO 27001 to address AI-specific risks like fairness, transparency, and accountability.
Structure:
ISO 42001 contains 38 controls in Annex A covering:
- AI policy and governance
- Risk assessment and treatment
- Data governance for ML
- Model development lifecycle management
- Validation and testing requirements
- Deployment and monitoring
- Third-party AI supplier oversight
Key Requirements:
Clause 6.1.2 (AI Risk Assessment): Mandates formal identification of risks related to:
- Adversarial attacks (evasion, poisoning, extraction)
- Data poisoning and backdoors
- Model bias and fairness violations
- Transparency and explainability gaps
- Accountability for AI decisions
Organizations must document these risks in a risk register with assigned owners and treatment plans.
Clause 7.4 (Data Governance): Requires comprehensive documentation of:
- Data lineage from source through transformations
- Data quality metrics and validation rules
- Provenance tracking (who collected data, when, how)
- Consent management for personal data
- Data retention and disposal procedures
Clause 8.3 (Model Development Lifecycle): Enforces controls over:
- Model development methodology
- Training and validation procedures
- Testing for robustness and security
- Versioning and configuration management
- Handoff between development and operations
Clause 9.1 (Performance Evaluation): Requires ongoing monitoring of:
- Model accuracy and performance metrics
- Fairness and bias indicators
- Drift detection and response
- Security incident tracking
- Compliance with regulatory requirements
Integration Strategy:
Organizations already certified to ISO 27001 can integrate ISO 42001 controls into their existing ISMS rather than building a separate system. For example:
ISO 27001 Control A.14 (System Acquisition): Extend to cover acquisition of pre-trained models and ML frameworks. Evaluate security of model sources (Hugging Face, OpenAI, etc.) as you would any third-party software supplier.
ISO 27001 Control A.12.6 (Technical Vulnerability Management): Extend to include ML-specific vulnerabilities (CVEs in MLflow, PyTorch, TensorFlow) and model-specific threats (adversarial examples, membership inference).
ISO 27001 Control A.12.4 (Logging and Monitoring): Extend to include ML platform logs (model registry, training jobs, inference requests) as defined in ISO 42001 Clause 9.1.
EU AI Act Imposes Security Requirements for High-Risk Systems
The EU Artificial Intelligence Act, which began phased enforcement in 2024-2026, introduces mandatory security requirements for AI systems based on risk classification.
Enforcement Timeline:
- February 2025: Prohibited AI practices (social scoring, real-time biometric ID in public) banned
- August 2025: Obligations for General Purpose AI (GPAI) models in effect
- August 2026: Requirements for high-risk AI systems fully enforced
High-Risk Classification:
AI systems are considered high-risk if used in:
- Critical infrastructure (transportation, energy, water)
- Education and vocational training
- Employment and worker management
- Essential private and public services (credit scoring, emergency dispatch)
- Law enforcement and justice systems
- Migration, asylum, and border control
- Democratic processes (election systems)
Article 15 (Accuracy, Robustness, and Cybersecurity):
Mandates technical and organizational measures to achieve appropriate levels of accuracy, robustness, and cybersecurity throughout the AI system lifecycle. Specifically addresses AI-specific threats:
Data Poisoning Prevention, Detection, and Response:
- Controls to validate training data integrity
- Monitoring for poisoning indicators during training
- Incident response procedures for suspected poisoning
- Ability to retrain models from clean data sources
Model Poisoning Controls:
- Security scanning of pre-trained components before integration
- Validation that fine-tuning doesn't introduce backdoors
- Testing for inherited vulnerabilities from base models
Adversarial Example/Model Evasion Defenses:
- Testing against adversarial perturbations during validation
- Input validation and sanitization in production
- Monitoring for evasion attempts via logging and anomaly detection
Confidentiality Attack Protections:
- Defenses against model inversion (preventing reconstruction of training data)
- Membership inference attack mitigation (preventing determination of whether specific data was in training set)
- Output filtering to prevent leakage of sensitive information
Penalties:
Non-compliance carries severe financial penalties:
- Up to €40 million or 7% of global annual turnover for prohibited AI practices
- Up to €20 million or 4% of global turnover for high-risk system violations
- Up to €10 million or 2% of global turnover for inaccurate information in compliance documentation
These penalties apply to both AI system developers and deployers. If you're using a high-risk AI system, you share compliance responsibility even if you didn't develop it.
Practical Implications:
Organizations deploying high-risk AI systems in the EU must:
- Conduct conformity assessments before deployment
- Maintain technical documentation (data, model architecture, training procedures, testing results)
- Implement quality management systems covering entire AI lifecycle
- Maintain logs of AI system operation for traceability
- Ensure human oversight of AI decisions
- Report serious incidents to regulatory authorities
The AI Act represents the most comprehensive AI regulation globally. Even non-EU organizations must comply if their AI systems are used in the EU market.
FedRAMP for Government ML Requires Authorized Infrastructure
Federal Risk and Authorization Management Program (FedRAMP) is the US government's standardized approach to security assessment and authorization for cloud services. Organizations providing AI/ML services to federal agencies must achieve FedRAMP authorization.
Critical Understanding:
Individual LLMs or ML models are not independently FedRAMP-authorized. Authorization covers the cloud services hosting ML workloads. The security of open-source models deployed on authorized infrastructure remains customer responsibility.
FedRAMP-Authorized ML Services (as of January 2025):
Amazon Web Services:
- Amazon Bedrock: FedRAMP High authorization (August 2024) for managed LLM access
- SageMaker: FedRAMP High authorization for training and deployment infrastructure
- Graviton processors: Hardware underlying many ML workloads, within AWS GovCloud
Google Cloud:
- Generative AI on Vertex AI: FedRAMP High Provisional Authorization to Operate (P-ATO)
- Vertex AI platform: FedRAMP High authorization for end-to-end ML lifecycle
Microsoft Azure:
- Azure ML: FedRAMP High authorization
- Azure OpenAI Service: FedRAMP High authorization for GPT-4, GPT-3.5-Turbo
IBM:
- watsonx on AWS GovCloud: FedRAMP High authorization for enterprise AI platform
Customer Responsibility Model:
Even when using FedRAMP-authorized infrastructure, organizations remain responsible for:
- Secure configuration of ML services (disabling public access, implementing authentication)
- Data security (encryption, access control, data governance)
- Model security (scanning for vulnerabilities, artifact signing)
- Application security (API security, input validation)
- Operational security (patch management, incident response)
Using an authorized platform doesn't automatically make your AI system compliant. You must implement appropriate controls for your specific use case and risk level.
Impact Levels:
FedRAMP defines three impact levels:
- Low: Loss of confidentiality, integrity, or availability would have limited adverse effect
- Moderate: Loss would have serious adverse effect (most common authorization level)
- High: Loss would have severe or catastrophic adverse effect (required for sensitive federal workloads)
ML workloads processing classified information, personally identifiable information (PII), or critical infrastructure data typically require FedRAMP High authorization.
Chapter 7: Security Architecture Reference Patterns
Network Segmentation Isolates ML Workloads
ML workloads should be isolated from other systems using network segmentation. This limits the blast radius if a training job or inference service is compromised.
Kubernetes Network Policy for ML Training:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ml-training-policy
namespace: ml-training
spec:
# This policy applies to pods with label app=training-job
podSelector:
matchLabels:
app: training-job
policyTypes:
- Ingress # Control incoming traffic
- Egress # Control outgoing traffic
# Allow egress only to specific destinations
egress:
# Allow access to data storage namespace
- to:
- namespaceSelector:
matchLabels:
name: data-storage
ports:
- protocol: TCP
port: 443 # HTTPS only
# Allow access to model registry namespace
- to:
- namespaceSelector:
matchLabels:
name: model-registry
ports:
- protocol: TCP
port: 443
# Allow DNS resolution
- to:
- namespaceSelector:
matchLabels:
name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- protocol: UDP
port: 53
# Allow ingress only from orchestrator
ingress:
- from:
- namespaceSelector:
matchLabels:
name: ml-orchestrator
ports:
- protocol: TCP
port: 8080 # Health check endpointThis policy implements a default-deny posture. Training jobs can only:
- Access data storage and model registry (read training data, write trained models)
- Resolve DNS names
- Accept health checks from the orchestrator
All other traffic is blocked. This prevents:
- Lateral movement to other namespaces if training job is compromised
- Data exfiltration to external destinations
- Communication between training jobs (limiting potential spread of malware)
Multi-Account AWS Architecture:
Separate security-sensitive environments into different AWS accounts:
Security Account: Centralized logging (CloudTrail, VPC Flow Logs), security monitoring (GuardDuty, SecurityHub), secrets management (Secrets Manager)
Shared Services Account: Artifact repositories (ECR for containers, S3 for datasets), model registry, CI/CD pipelines
Data Account: S3 data lakes, RDS databases, RedShift warehouses. No direct internet access.
Development Account: Experimental workloads, data science notebooks, exploratory analysis. Relaxed security for iteration speed.
Staging Account: Pre-production testing. Mirrors production architecture but with synthetic/anonymized data.
Production Account: Live inference services. Strictest security controls. No human access to sensitive data.
Cross-account access uses IAM roles with temporary credentials, never long-lived access keys. VPC endpoints ensure traffic between accounts stays on AWS private network.
Benefits:
- Blast radius limitation: compromise in one account doesn't spread to others
- Simplified compliance: audit logs centralized in security account
- Clear separation: production credentials never used in development
- Cost management: separate billing for each environment
Incident Response Requires ML-Specific Playbooks
Traditional incident response playbooks cover scenarios like malware infections, phishing attacks, and data breaches. You need additional playbooks for ML-specific incidents.
Model Rollback Procedure:
model_rollback_procedure:
1_identify_target_version:
description: "Determine which model version to roll back to"
steps:
- Query model registry for last known-good version
- Check deployment history for previous stable version
- Verify that rollback target passed all validation tests
- Confirm cryptographic signature is valid
decision_points:
- "How far back to roll? Last version, or multiple versions?"
- "Does rollback target have same API contract as current version?"
evidence_collection:
- Screenshot of model registry showing version history
- Copy of model signatures and validation reports
2_validate_rollback_model:
description: "Ensure rollback target is safe to deploy"
steps:
- Download rollback model from registry
- Verify cryptographic signature matches expected value
- Run automated test suite (unit tests, integration tests, canary tests)
- Scan for known vulnerabilities (CVE check against SBOM)
- Confirm data lineage integrity (verify training data hasn't been poisoned)
- Test performance on recent inference traffic (replay last hour's requests)
quality_gates:
- All tests must pass (no failures acceptable during incident)
- Signature verification must succeed
- No known vulnerabilities in dependencies
evidence_collection:
- Test results screenshots
- Signature verification output
- Vulnerability scan report
3_execute_rollback:
description: "Deploy rollback model to production"
strategy: "Blue-green deployment"
steps:
- Deploy rollback model to green environment (not receiving traffic)
- Run smoke tests against green environment
- Shift 10% of traffic to green (canary deployment)
- Monitor error rates, latency, accuracy for 15 minutes
- If metrics acceptable, shift 50% of traffic
- Monitor for another 15 minutes
- If still acceptable, shift 100% of traffic
- Decommission blue environment (keep available for 24h in case rollforward needed)
rollback_triggers:
- Error rate >5% in green environment
- P95 latency >2x baseline
- Accuracy drops >5% on validation set
- New security alerts triggered
evidence_collection:
- Deployment logs
- Traffic shift timeline
- Performance metrics during rollback
4_post_rollback_validation:
description: "Confirm production is stable after rollback"
steps:
- Monitor serving metrics for 4 hours post-rollback
- Verify inference latency within acceptable range (P95 <500ms)
- Verify prediction accuracy on validation set matches expectations
- Check for errors or exceptions in application logs
- Confirm no security alerts triggered
- Document rollback in incident timeline
success_criteria:
- Error rate <0.1% for 4 consecutive hours
- Latency metrics within SLA
- No accuracy degradation
- No security incidents
communication:
- Notify stakeholders that rollback is complete
- Update status page if customer-facing service
- Brief executives on incident and resolution
5_root_cause_analysis:
description: "Understand why rollback was necessary"
timeline: "Within 48 hours of incident"
steps:
- Identify what changed between last known-good and compromised version
- Review logs, commits, data changes during that window
- Determine if compromise was malicious or accidental
- Assess whether other models may be affected
- Identify control failures that allowed compromise
deliverables:
- Written incident report with timeline
- Root cause analysis document
- Remediation plan with assigned owners and deadlinesData Poisoning Response Playbook:
data_poisoning_response:
phase_1_detection:
indicators:
- Sudden accuracy drop on validation set
- Model exhibits unexpected behavior on specific inputs
- Statistical anomalies in recent training data batches
- Alerts from embedding clustering analysis
initial_actions:
- Isolate suspected poisoned dataset (revoke access)
- Halt all training jobs using that dataset
- Preserve evidence (copy dataset to forensic storage)
- Alert incident response team
phase_2_assessment:
questions_to_answer:
- Which dataset versions are affected?
- How many models were trained with poisoned data?
- Are any compromised models in production?
- What is the business impact?
investigation_steps:
- Query model registry for all models using affected dataset
- Check deployment history for production models
- Run statistical analysis on suspected data to identify poisoned samples
- Test affected models for backdoor triggers
severity_classification:
- CRITICAL: Poisoned models in production serving customers
- HIGH: Poisoned models in staging/testing
- MEDIUM: Poisoned data detected before training
phase_3_containment:
immediate_actions:
- Roll back production models to last known-good versions (pre-poisoning)
- Block affected dataset from all training pipelines
- Revoke access for any accounts that modified the dataset
- Enable enhanced monitoring for all models
evidence_preservation:
- Snapshot affected dataset with timestamps
- Preserve access logs showing who modified data
- Save model weights for compromised models
- Capture network traffic if data exfiltration suspected
phase_4_eradication:
clean_dataset:
- Identify poisoned samples using statistical methods
- Remove or quarantine poisoned samples
- Validate cleaned dataset against historical baselines
- Generate new cryptographic hash for cleaned version
retrain_models:
- Retrain all affected models using cleaned dataset
- Run comprehensive validation tests
- Compare performance to pre-poisoning baselines
- Scan new models for vulnerabilities
phase_5_recovery:
deploy_clean_models:
- Deploy retrained models through standard CI/CD pipeline
- Use canary deployment to verify behavior
- Monitor closely for any anomalies
- Gradually shift traffic to retrained models
validation:
- Confirm accuracy matches pre-incident baselines
- Verify no backdoor triggers remain
- Test on edge cases and adversarial inputs
phase_6_lessons_learned:
review_timeline: "Within 1 week"
questions:
- How did poisoned data enter the pipeline?
- Why didn't existing controls detect it?
- What additional controls are needed?
- How can detection be accelerated?
improvements:
- Strengthen data validation rules
- Increase frequency of statistical checks
- Implement additional monitoring
- Update playbook based on lessons learnedReporting Requirements:
Per CISA JCDC AI Playbook guidance:
- Report AI-specific incident aspects in regulatory filings (not just traditional breach details)
- Share threat intelligence via JCDC partnership to help other organizations defend
- Document incidents mapped to MITRE ATLAS framework for standardized tracking
- Notify customers if their data may have been exposed through compromised models
Chapter 8: Implementation Priority Matrix
By Pipeline Stage
Organizations struggle to prioritize security improvements when resources are limited. This matrix provides a phased implementation approach focused on highest-impact controls first.
Training Security (Weeks 1-4):
Week 1: Implement Model Artifact Signing
- Deploy Sigstore/Cosign infrastructure for model signing
- Integrate signing into CI/CD pipeline after training completes
- Verify all models have valid signatures before deployment
- Impact: Prevents deployment of tampered or unauthorized models
- Effort: Medium (requires CI/CD modifications)
- Cost: Low (open-source tools)
Week 2: Migrate to SafeTensors Format
- Identify models using pickle serialization
- Convert high-risk models to SafeTensors
- Update training code to save models in SafeTensors format
- Impact: Eliminates pickle deserialization vulnerabilities
- Effort: Low to Medium (depends on model complexity)
- Cost: Low (developer time only)
Week 3: Deploy Comprehensive Logging
- Implement OpenTelemetry instrumentation in training code
- Configure log aggregation to central SIEM
- Set up retention policies (90 days minimum)
- Impact: Enables detection and forensic analysis
- Effort: Medium (requires instrumentation)
- Cost: Low to Medium (depending on log volume)
Week 4: Establish Training Data Governance
- Implement data version control (DVC or similar)
- Create cryptographic checksums for all datasets
- Track data lineage from source through training
- Impact: Prevents data poisoning, enables incident response
- Effort: Medium to High (cultural change required)
- Cost: Low (mostly tooling adoption)
Validation Security (Weeks 5-8):
Week 5: Integrate SBOM Generation
- Add CycloneDX SBOM generation to CI/CD pipeline
- Generate SBOMs for all container images and models
- Store SBOMs alongside artifacts in registry
- Impact: Enables vulnerability management, compliance evidence
- Effort: Low to Medium (CI/CD integration)
- Cost: Low (open-source tools)
Week 6: Implement SLSA L2 Provenance
- Configure build platform to generate provenance metadata
- Sign provenance with platform identity
- Verify provenance before deployment
- Impact: Prevents unauthorized model deployment
- Effort: Medium (requires platform configuration)
- Cost: Low (tooling mostly open-source)
Week 7: Deploy Vulnerability Scanning
- Integrate Trivy/Snyk into CI/CD pipeline
- Scan all container images for CVEs
- Block deployment if critical vulnerabilities found
- Impact: Prevents deployment of vulnerable containers
- Effort: Low (easy integration)
- Cost: Medium (commercial scanners have licensing costs)
Week 8: Establish Cryptographic Verification Gates
- Require signature verification before deployment
- Implement automated checks for SBOM presence
- Fail deployment if security gates not passed
- Impact: Enforces security standards consistently
- Effort: Medium (CI/CD modifications)
- Cost: Low (mostly configuration)
Deployment Security (Weeks 9-12):
Week 9: Harden MLOps Platforms
- Upgrade MLflow to latest version (2.17.1+)
- Implement authentication on all platforms
- Deploy reverse proxies with TLS
- Impact: Closes critical RCE vulnerabilities
- Effort: Medium (requires configuration changes)
- Cost: Low (mostly configuration)
Week 10: Implement Secrets Management
- Deploy HashiCorp Vault or cloud-native secrets manager
- Migrate hardcoded credentials to secrets manager
- Configure automatic rotation (90-day cycle)
- Impact: Eliminates credential exposure risk
- Effort: High (requires code changes across projects)
- Cost: Medium (Vault Enterprise or cloud service costs)
Week 11: Deploy Network Policies
- Implement default-deny Kubernetes NetworkPolicy
- Create explicit allow rules for ML workloads
- Test connectivity to ensure legitimate traffic works
- Impact: Limits lateral movement if compromise occurs
- Effort: Medium (requires understanding of traffic patterns)
- Cost: Low (Kubernetes native feature)
Week 12: Enable Cloud-Native Security Monitoring
- Activate AWS GuardDuty, Azure Defender, or GCP Security Command Center
- Configure alerts for ML-specific threats
- Integrate with SIEM for centralized monitoring
- Impact: Detects infrastructure-level attacks
- Effort: Low (mostly configuration)
- Cost: Medium (cloud service costs based on volume)
Production Monitoring (Ongoing):
Month 1: Integrate ML Logs with SIEM
- Configure MLflow, training platforms, and inference services to send logs to SIEM
- Create ML-specific detection rules (model exfiltration, data poisoning indicators)
- Set up alerting workflows
- Impact: Enables detection of ML-specific attacks
- Effort: High (requires rule development and tuning)
- Cost: Variable (depends on SIEM licensing)
Month 2: Deploy Runtime Model Integrity Verification
- Implement cryptographic verification at model load time
- Deploy behavioral canary testing
- Set up automated rollback triggers
- Impact: Detects model tampering in production
- Effort: Medium (requires integration with serving infrastructure)
- Cost: Low (mostly development time)
Month 3: Evaluate Specialized ML Security Platforms
- Trial HiddenLayer, Protect AI, or Cisco AI Defense
- Assess coverage gaps vs. existing tools
- Calculate ROI based on detection capabilities and reduced incident response time
- Impact: Provides ML-specific visibility beyond general tools
- Effort: Low (vendor POC process)
- Cost: High (enterprise licensing typically $100K-$500K annually)
Month 4+: Build and Test Incident Response Playbooks
- Document model rollback procedures
- Test data poisoning response in staging environment
- Conduct tabletop exercises with incident response team
- Impact: Reduces MTTR when incidents occur
- Effort: Medium (requires scenario development)
- Cost: Low (mostly time investment)
Key Success Metrics
Mean Time to Detect (MTTD) for ML Threats:
- Target: <4 hours for high-severity incidents
- Baseline measurement: Current detection time (often weeks or months for ML incidents)
- Improvement approach: SIEM integration + ML-specific detection rules
- Measurement: Time from attack occurrence to alert generation
Model Integrity Verification Coverage:
- Target: 100% of production models
- Baseline measurement: Percentage of models with valid signatures
- Improvement approach: Mandatory signing in CI/CD pipeline
- Measurement: Count of production models with verified signatures / total production models
SBOM Coverage:
- Target: 100% of deployed model containers
- Baseline measurement: Percentage of containers with SBOMs
- Improvement approach: Automated SBOM generation in build process
- Measurement: Count of containers with SBOMs / total deployed containers
Incident Response Playbook Coverage:
- Target: Documented playbooks for all MITRE ATLAS top 10 techniques
- Baseline measurement: Number of ML-specific playbooks currently documented
- Improvement approach: Develop playbooks for each ATLAS technique relevant to your systems
- Measurement: Playbook count, plus annual testing/update cadence
Credential Exposure Rate:
- Target: Zero credentials found in code repositories or container images
- Baseline measurement: Results of initial secrets scanning
- Improvement approach: Pre-commit hooks + secrets manager adoption
- Measurement: Count of credentials found in quarterly scans
Vulnerability Response Time:
- Target: <24 hours to patch critical CVEs in ML infrastructure
- Baseline measurement: Historical time from CVE disclosure to patch deployment
- Improvement approach: SBOM-based vulnerability management + automated patching
- Measurement: Time from CVE NIST publication to patch deployment
Chapter 9: Conclusion—Security as a First-Class MLOps Concern
The Threat Landscape Has Matured
The MLOps security landscape has evolved from theoretical concerns to documented, actively exploited vulnerabilities with measurable financial impact. The ShadowRay campaign compromised over 500 GPU clusters for cryptocurrency mining and credential theft. The Ultralytics supply chain compromise delivered malicious code to 60 million downloads in 10% of cloud environments. Hugging Face discovered 100+ malicious models exploiting pickle deserialization to achieve remote code execution.
These aren't academic exercises or proof-of-concepts. They're real attacks with real financial consequences. Organizations have paid hundreds of thousands in inflated cloud bills from cryptominers. They've lost proprietary model weights representing millions in research investment. They've suffered data breaches when training pipelines were compromised and sensitive data exfiltrated.
Attackers have developed ML-specific tradecraft. They understand how to exploit pickle deserialization, bypass model scanners, inject malicious code into GitHub Actions workflows, and compromise self-hosted CI/CD runners. They know which platforms (MLflow, Ray, Kubeflow) have default configurations that can be exploited. They use internet scanning to find exposed dashboards and APIs that lack authentication.
Supply Chain Attacks Dominate the Threat Landscape
The most critical insight from 2023-2025 breach data: supply chain attacks now represent 45% of AI-related compromises, making them the dominant threat vector. This is a fundamental shift from earlier years when most security research focused on adversarial examples and model inversion attacks.
Why the supply chain focus? Because it's the path of least resistance. Attacking a production model with carefully crafted adversarial inputs is technically sophisticated and often detectable. Uploading a malicious model to Hugging Face and waiting for someone to download it is far easier and scales to thousands of potential victims.
This demands a fundamental shift in defensive strategy. Organizations must implement cryptographic verification of all model artifacts, generate SBOMs capturing ML-specific metadata, and deploy runtime monitoring capable of detecting model tampering. Traditional application security controls—firewalls, antivirus, intrusion detection—miss these threats entirely.
The Frameworks Exist, But Adoption Lags Dangerously
The good news: we have the frameworks and tools to secure ML pipelines. SLSA provides supply chain security guidelines. MITRE ATLAS documents ML-specific attack patterns. NIST AI RMF offers risk management guidance. ISO 42001 provides governance standards. Sigstore enables artifact signing. SafeTensors eliminates pickle vulnerabilities.
The bad news: adoption remains dangerously low. Only 8% of organizations have comprehensive AI security plans. Just 14% have planned or tested for adversarial attacks. A mere 20% have prepared for model theft scenarios. Many organizations don't even know how many ML models they have in production, let alone whether those models have been signed, scanned, or monitored for tampering.
This gap between available security controls and actual implementation creates enormous risk. With 1,689 AI models in production on average, and 92% of organizations still developing security plans, the attack surface is vast and largely undefended.
For Practitioners: The Immediate Priorities
If you're responsible for ML security, focus on these immediate priorities:
Week 1: Implement model signing with Sigstore. This single control prevents deployment of tampered or unauthorized models. It's low-cost, open-source, and provides immediate value.
Week 2: Migrate away from pickle serialization. Convert high-risk models to SafeTensors. This eliminates an entire class of critical vulnerabilities with minimal engineering effort.
Week 3: Harden CI/CD runners. Update MLflow to latest version. Disable root access on SageMaker instances. Never expose Ray dashboards to the internet. These misconfigurations are actively exploited in the wild.
Week 4: Deploy ML-aware detection rules. Integrate model registry logs with your SIEM. Create alerts for unusual model downloads, excessive data access, or anomalous GPU usage. You can't defend what you can't see.
Month 2: Establish data governance. Implement dataset versioning, cryptographic checksums, and lineage tracking. This prevents data poisoning and provides the evidence you need for incident response.
Month 3: Achieve SLSA Level 2. Generate signed provenance for all production models. This creates an unforgeable chain of custody from training data through deployment.
Month 6: Test your incident response. Run tabletop exercises for data poisoning, model theft, and infrastructure compromise scenarios. Discover gaps in your playbooks before a real incident occurs.
These aren't the only controls you need, but they're the highest-impact starting points. Each control reduces risk significantly with reasonable implementation effort.
The Window for Proactive Defense Is Narrowing
The breach statistics suggest the window for proactive defense is closing. With 77% of organizations already experiencing AI breaches, and 45% choosing not to report incidents publicly, we're likely in the middle of an AI security crisis, not at the beginning.
Organizations that invest in ML security now—implementing artifact signing, SBOM generation, comprehensive monitoring, and incident response capabilities—will be in a defensible position. Those that continue to treat AI security as an afterthought will become breach statistics in the next HiddenLayer or IBM threat report.
The technology exists to secure ML pipelines. The frameworks provide clear guidance. The tools are available, many open-source. What's missing is organizational commitment to prioritize security alongside model accuracy and deployment velocity.
Make ML security a first-class concern. Your models, your data, and your organization's reputation depend on it.
Key Takeaways
- Supply chain attacks dominate: 45% of AI breaches originate from malicious models in public repositories. Implement cryptographic verification for all model artifacts.
- Traditional security tools miss ML threats: Model serialization vulnerabilities, CI/CD pipeline exploitation, and data poisoning require ML-specific detection mechanisms.
- Critical infrastructure vulnerabilities are actively exploited: ShadowRay (Ray), MLflow RCE, and Kubeflow authentication bypass have real-world attack campaigns. Patch immediately.
- Pickle serialization is ML's most dangerous attack surface: 80% of Hugging Face models use pickle. Migrate to SafeTensors and implement multi-layered scanning.
- Detection time remains unacceptably high: 258 days average to detect and contain ML breaches. Integrate ML platform logs with SIEM and deploy ML-specific detection rules.
- Adoption of security frameworks lags severely: Only 8% of organizations have comprehensive AI security plans despite 1,689 models in production on average.
- Implement SLSA Level 2 as baseline: Signed provenance for models prevents unauthorized deployments and enables incident response.
- ML-specific compliance requirements are here: EU AI Act, ISO 42001, and FedRAMP mandate security controls for AI systems. Non-compliance carries penalties up to €40M or 7% of global revenue.
- Secrets management is non-negotiable: 73% of data scientists admit to hardcoding credentials. Use HashiCorp Vault or cloud-native secrets managers with automatic rotation.
- Test your incident response: Model rollback, data poisoning response, and credential theft scenarios require ML-specific playbooks. Test annually minimum.
References and Further Reading
Industry Reports
- HiddenLayer AI Threat Landscape Report 2024
- IBM Cost of a Data Breach Report 2024
- Verizon Data Breach Investigations Report 2024
- Cloud Security Alliance: Top Threats to Cloud Computing 2025
Vulnerability Databases
- National Vulnerability Database (NVD): https://nvd.nist.gov
- OpenCVE: https://www.opencve.io
- Snyk Vulnerability Database: https://security.snyk.io
Security Frameworks
- MITRE ATLAS (Adversarial Threat Landscape for AI Systems): https://atlas.mitre.org
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- SLSA (Supply-chain Levels for Software Artifacts): https://slsa.dev
- ISO/IEC 42001 AI Management System: https://www.iso.org/standard/81230.html
Open-Source Security Tools
- Sigstore Model Signing: https://github.com/sigstore/model-transparency
- SafeTensors: https://github.com/huggingface/safetensors
- Falco Runtime Security: https://falco.org
- ModelScan: https://github.com/protectai/modelscan
- Trivy Vulnerability Scanner: https://github.com/aquasecurity/trivy
Commercial Platforms
- HiddenLayer AISec Platform: https://hiddenlayer.com
- Protect AI: https://protectai.com
- Cisco AI Defense (formerly Robust Intelligence): https://www.cisco.com
Training and Certification
- SANS SEC565: Red Team Operations and Adversary Emulation
- ISC2 Certified Cloud Security Professional (CCSP)
- MLSecOps Community: https://mlsecops.com
Document Version: 1.0 Last Updated: November 8, 2025 Document Classification: Public Word Count: 11,847 words