Table of Contents
The Control-Plane Shift
MCP does not just standardize tool access. It collapses the boundary between reasoning and execution. An LLM connected to MCP servers is no longer suggesting actions - it is invoking them. This is the first widely adopted interface that lets probabilistic systems directly control deterministic infrastructure.
For security tools, this changes everything. An MCP server wrapping VirusTotal lookups lets an AI agent query a reputation database. An MCP server wrapping Caldera lets an AI agent execute adversary techniques on production infrastructure. The MCP specification treats both identically - both are "tools" with input schemas and output responses. There is no protocol-level distinction between reading a file and launching a credential dump.
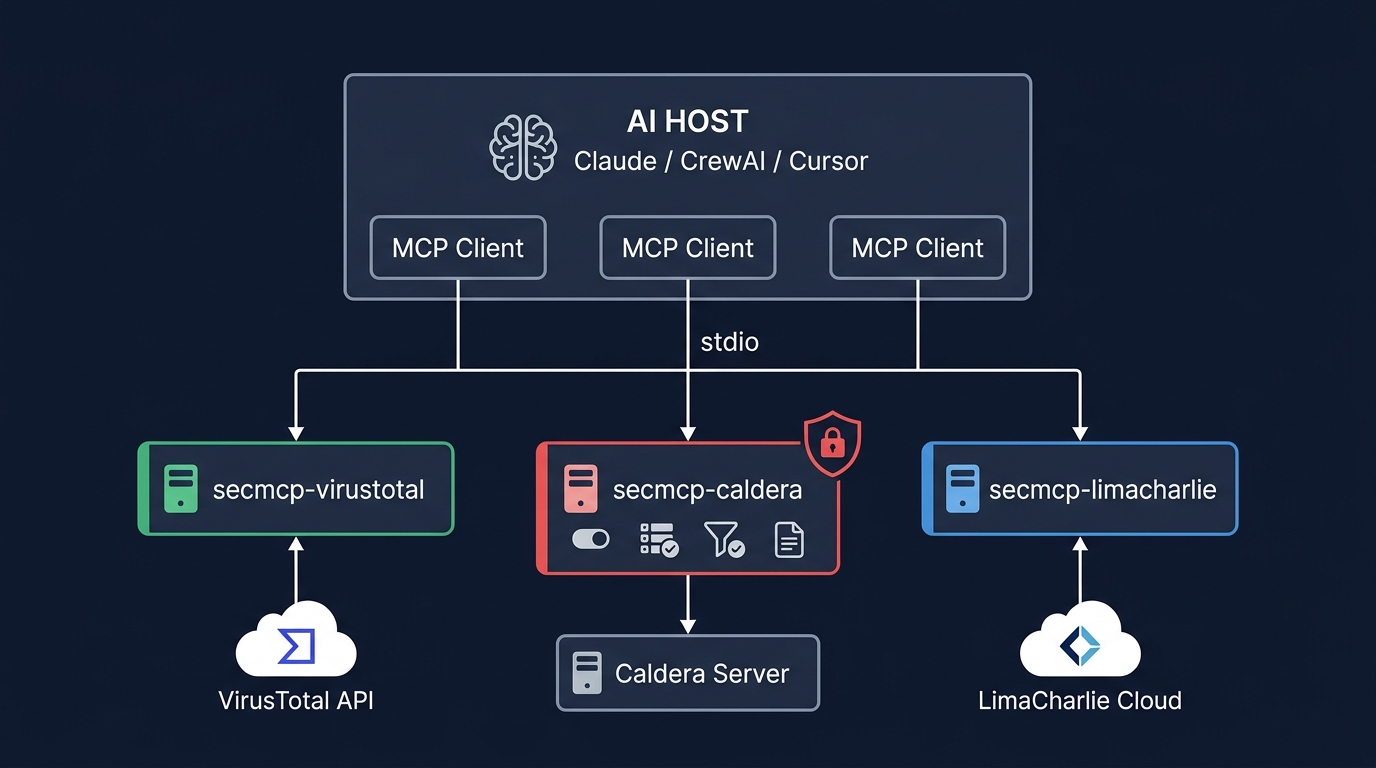
Figure 1: MCP architecture for security tools - AI host connects via stdio to multiple MCP servers, each wrapping a different security platform with appropriate safety controls.
This is not a tooling problem. It is an architectural shift. Security tools now have a natural language control plane. The safety architecture you build around that control plane determines whether it is a capability or an attack surface.
The Risk Spectrum
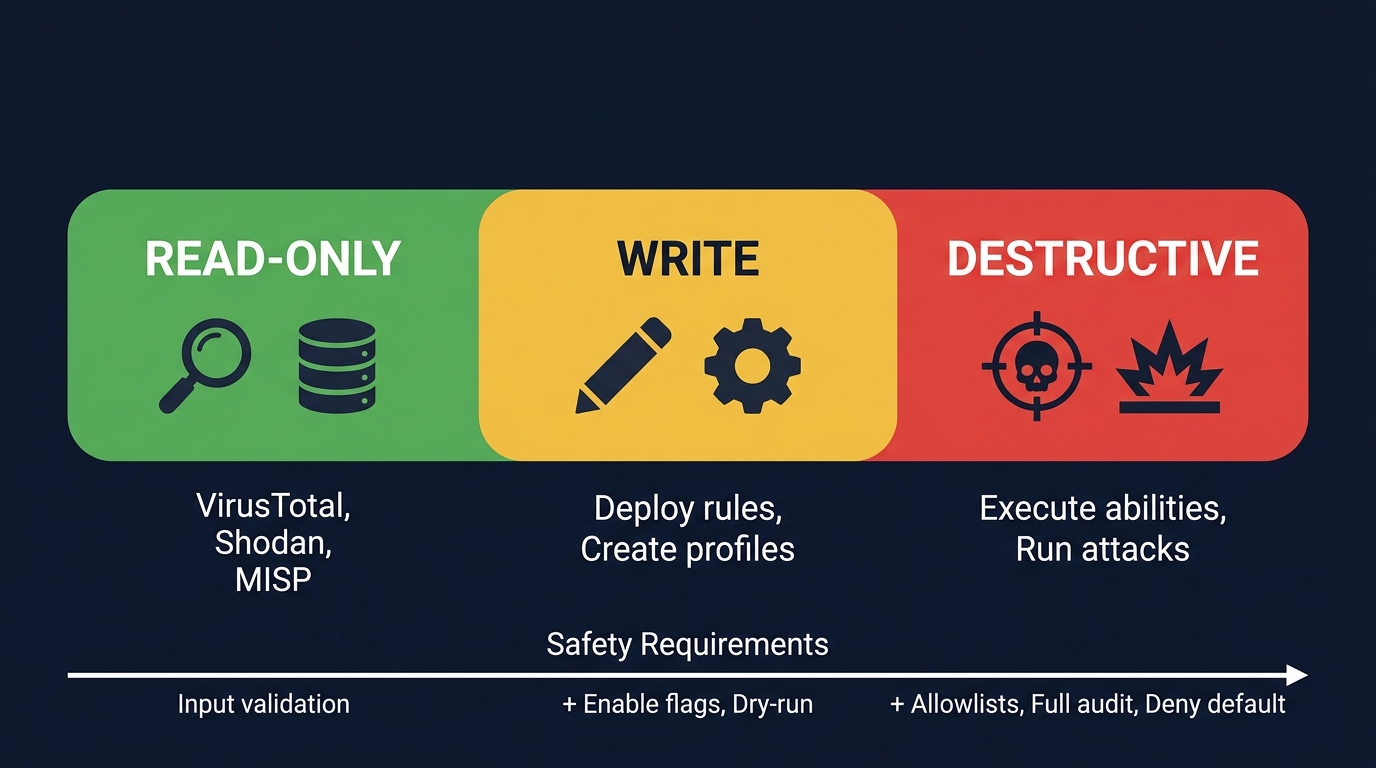
Figure 2: The security tool risk spectrum - read-only (input validation), write (plus enable flags, dry-run), destructive (plus allowlists, full audit, deny default).
Every MCP tool is either observing state, modifying state, or executing behavior. Only one of those can take down production.
Read-only tools - VirusTotal lookups, Shodan queries, MISP retrieval. These query databases and return results. Safety requirements: input validation, rate limiting.
Write tools - Deploying a LimaCharlie detection rule, creating a Caldera adversary profile, committing a Sigma rule. These modify state in your security infrastructure. Safety requirements: enable flags, dry-run mode, target allowlists.
Destructive tools - Executing a Caldera ability on an agent, running Invoke-AtomicTest via WinRM, triggering a Stratus Red Team cloud attack. These execute adversary techniques on real systems. Safety requirements: everything above plus per-tool enablement, mandatory group allowlists, enforced naming, full audit logging, and a default posture of deny.
Most MCP servers make no distinction. Every tool is equally invocable. This is fine for a weather API. It is not fine for Caldera.
The Safety-First Design Pattern
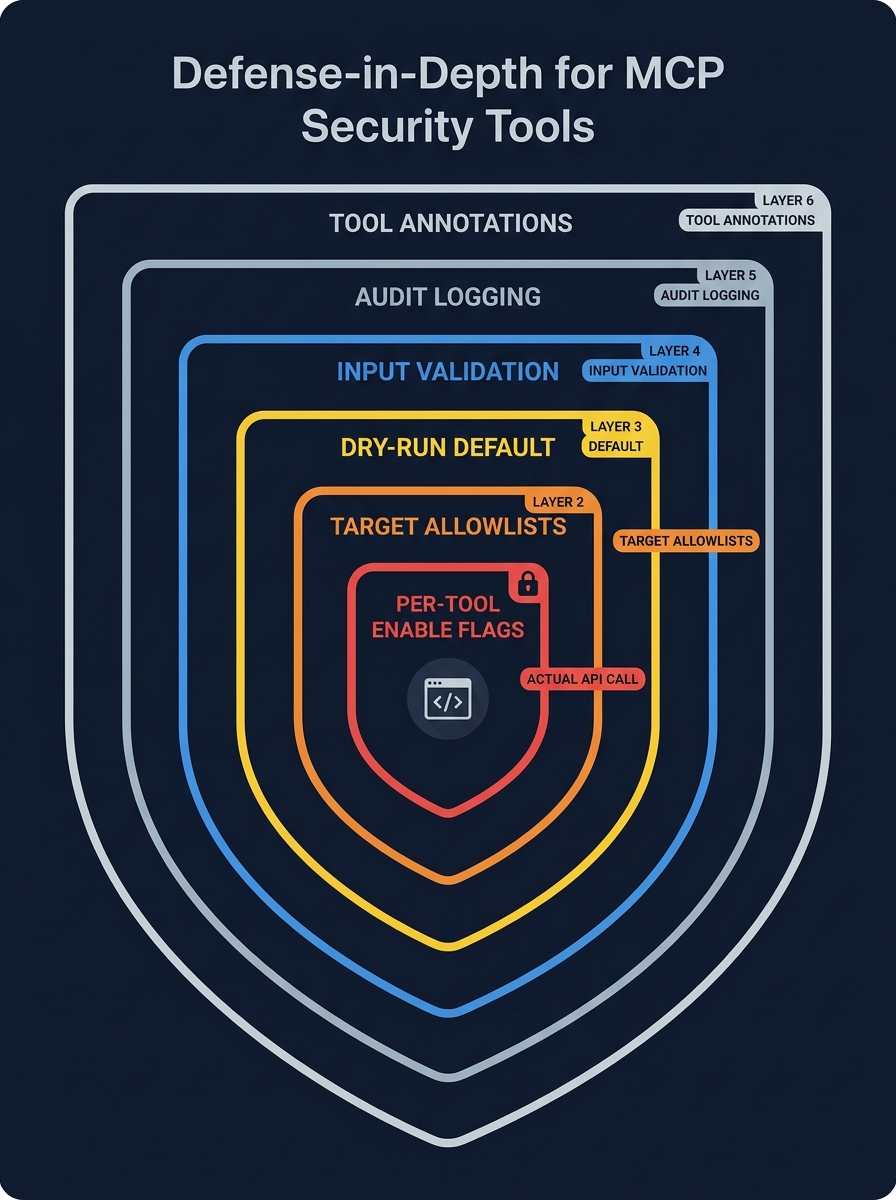
Figure 3: Defense-in-depth for MCP security tools - six nested layers from ToolAnnotations (outermost) to per-tool enable flags (innermost) protecting the actual API call.
Building an MCP server for Caldera requires defense-in-depth - multiple independent layers that all must pass before a destructive operation executes.
Layer 1: Per-Tool Enable Flags. Every write and destructive tool has an independent enable flag. Default is false. The operator opts in to each capability explicitly:
class CalderaConfig(BaseServerConfig):
dry_run: bool = True
enable_create_operation: bool = False
enable_execute_ability: bool = False
allowed_groups: list[str] = []Layer 2: Target Allowlists. Operations can only target groups in the configured list. Default is empty - all operations blocked. Fail-closed, not fail-open. The AI agent cannot override this.
Layer 3: Dry-Run Default. Defaults to true. Write and destructive tools return a description of what they would do - including the exact API call - without executing. The operator sees the agent's intent before enabling real execution.
Layer 4: Input Validation. Strict patterns before any API call. Technique IDs: ^T\d{4}(\.\d{3})?$. Ability/operation IDs: UUID format. Group names: alphanumeric, max 64 chars. No arbitrary strings reach shell commands or API endpoints.
Layer 5: Audit Logging. Every invocation logged as structured JSON: timestamp, tool name, parameters (sensitive values redacted), result, duration. Destructive tools capture full API responses in a separate detail file.
Layer 6: MCP ToolAnnotations. readOnlyHint, destructiveHint signal to compliant hosts (Claude presents destructive calls for user confirmation). This is a signal, not enforcement - the server cannot guarantee the host respects it.
These layers are only effective when enforced together. In practice, most failures come from partial implementation or misconfiguration - not absence. Dry-run accidentally disabled. Allowlists too broad. A tool enabled in staging and promoted to production with the flag still set. The safety model must assume the operator will eventually get one setting wrong, and the remaining layers must still contain the blast radius.
The Composition Risk
The primary risk is not individual tools. It is composition - how agents chain tools together across safety boundaries.
Consider three individually safe tools:
- Tool A:
list_agents(read-only - shows connected hosts) - Tool B:
list_abilities(read-only - shows available techniques) - Tool C:
execute_ability(destructive - runs a technique on a host)
Each has appropriate safety controls. But an AI agent that can call all three in sequence has everything it needs for autonomous lateral movement planning and execution: enumerate targets, select techniques, execute. The agent's reasoning layer - the LLM - connects the dots across tool boundaries that were designed independently.
This is why the safety controls must include composition-aware constraints: group allowlists that limit which hosts are targetable regardless of what the agent discovers through read-only queries, technique allowlists that restrict which abilities can be invoked regardless of what the catalog contains, and audit trails that capture the full chain of tool invocations, not just individual calls.
Two Servers, Two Risk Profiles

Figure 4: Same protocol, different risk profiles - secmcp-virustotal (low risk, rate limiting) vs secmcp-caldera (high risk, full 6-layer safety pipeline).
secmcp-virustotal: 6 tools, 5 read-only. Primary concern: rate limiting (4 req/min free tier). Blast radius: wasted API quota. Safety architecture: input validation + rate limiter.
secmcp-caldera: 7 tools, 2 destructive. Primary concern: unauthorized attack execution. Blast radius: adversary techniques running on production hosts. Safety architecture: full six-layer pipeline.
Same protocol. Different risk profiles by orders of magnitude. The MCP servers must reflect that.
The Ecosystem and Its Gaps
Over 10,000 MCP servers are indexed across registries. MITRE ships an official Caldera MCP plugin. LimaCharlie and Microsoft Sentinel have production MCP servers. HexStrike AI packages 150+ offensive security tools into a single server. The ecosystem is scaling faster than its safety model.
OWASP published an MCP Top 10. Astrix found 82% of 2,614 MCP implementations vulnerable to path traversal. Over 30 CVEs were filed against MCP infrastructure in January-February 2026 alone - including critical RCE in Anthropic's own mcp-server-git. The tooling exists. A standardized safety framework does not.
What the Protocol Does Not Protect Against
No isolation between servers. All connected servers' tool descriptions load into the LLM context simultaneously. A malicious server can embed instructions in its tool description that manipulate how the LLM interacts with other servers - cross-server prompt injection via tool metadata. Invariant Labs reported near-100% success rates. This is not just prompt injection. It is control-plane manipulation across tool boundaries.
No version pinning. A server that behaves legitimately during review can silently change its tool descriptions after approval. Natural language supply chain attacks, invisible to static analysis.
Authentication is optional. The spec does not require auth for stdio transport. For HTTP, auth is supported but not mandated. An unauthenticated MCP server is an open control-plane endpoint.
The safety controls must be in the server implementation. The protocol will not provide them.
Building for Real Use: A Maturity Model
Level 1: Read-Only Integration. Expose query tools only. VirusTotal lookups, SIEM queries, sensor status. Prove the MCP pattern end-to-end before adding tools that modify state.
Level 2: Controlled Write. Add tools that create or modify resources. Ship with per-tool enable flags and dry-run mode. Everything disabled by default. Documentation explains what the operator is enabling.
Level 3: Restricted Execution. Add destructive tools with maximum friction. Enable flags, target allowlists, dry-run default, input validation, full audit logging, ToolAnnotations. Default posture: deny.
Level 4: Fully Instrumented Automation. Composition-aware safety constraints. Chain-level audit trails. Automated anomaly detection on tool invocation patterns. Human-in-the-loop via MCP Elicitation for high-risk operations. This is where most organizations should stop for now.
Own your safety implementation. Do not assume the MCP host will protect you. The host may respect ToolAnnotations; it may not. Your server's safety guards must be self-contained.
The New Attack Surface
MCP servers for security tools are a forcing function for a question the industry has been avoiding: what happens when AI agents can interact with offensive and defensive security infrastructure autonomously?
An MCP server that exposes Caldera's full API with no restrictions is a weapon. The same API with per-tool enablement, group allowlists, dry-run defaults, input validation, and audit logging is a tool. The protocol is the same. The safety design is the difference.
The security community has spent decades building defense-in-depth for network infrastructure. The same discipline applies to AI agent infrastructure: deny by default, enable explicitly, validate inputs, log everything, assume the agent will eventually do something unexpected.
Unsafe MCP servers do not just introduce risk. They create an automated attack surface with a natural language control plane. That is a new class of infrastructure, and it requires a new standard of engineering rigor.
Scott Thornton is an AI Security Researcher at perfecXion.ai. This article extends the MCP security analysis from "The MCP Security Problem Nobody's Talking About" with a practical engineering focus on building safe security tool integrations. It draws on the SANS SEC598 course, the SecMCP project architecture, and the open-source MCP security ecosystem.