Table of Contents
- The Imperative for Parameter-Efficient Fine-Tuning
- Deconstructing LoRA: The Mechanics of Low-Rank Adaptation
- The Utility of LoRA: A Paradigm Shift in Model Customization
- Comparative Analysis: LoRA versus Full Fine-Tuning
- The LoRA Ecosystem: Variants and Enhancements
- The Broader Landscape: Alternative PEFT Methodologies
- Synthesis and Future Trajectories
Section 1: The Imperative for Parameter-Efficient Fine-Tuning
Foundation models rule AI today. These massive neural networks train on enormous datasets, learning generalizable patterns that work across countless tasks. They're remarkable. They're powerful. And they keep growing exponentially bigger.
1.1 The Challenge of Scaling Foundation Models
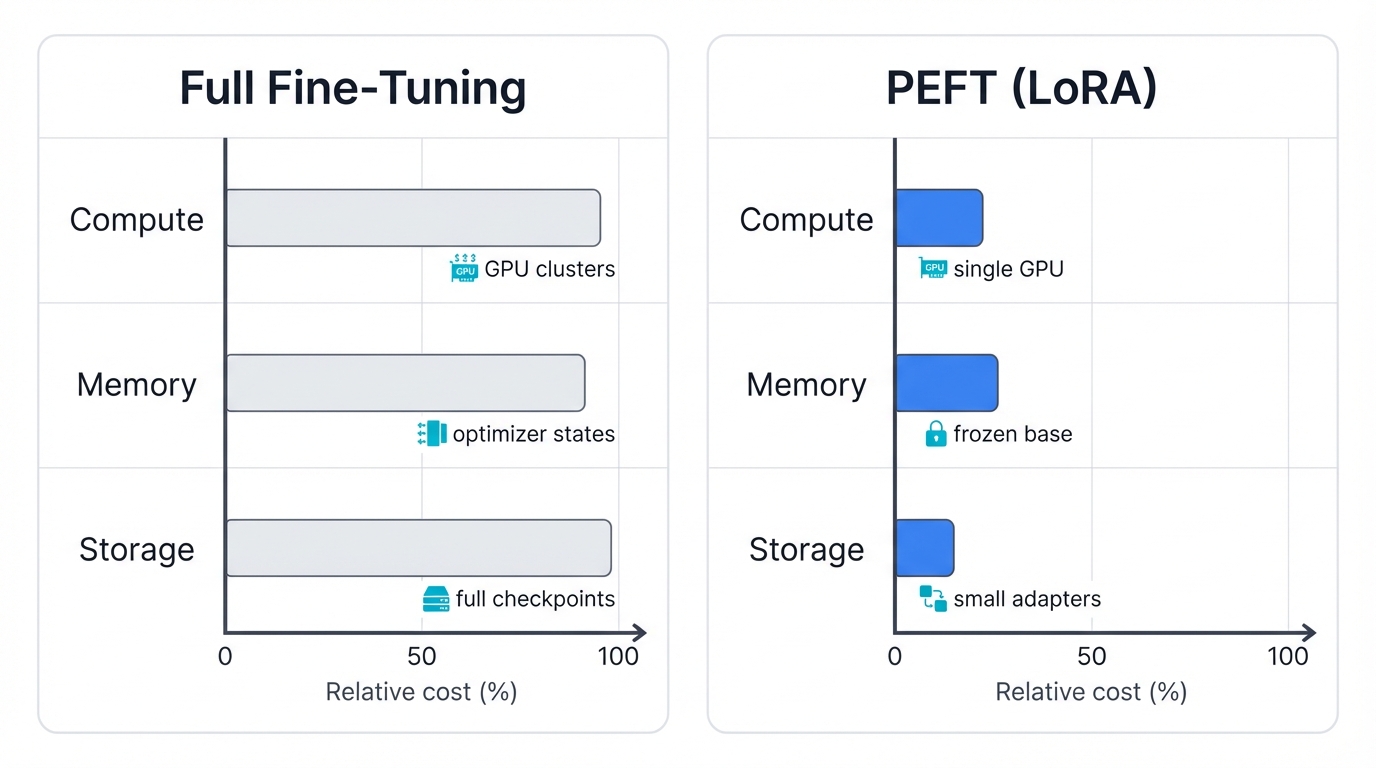
Full fine-tuning updates every single parameter in a pre-trained model. Every weight. Every connection. It's brutally expensive, and three major costs make it nearly impossible for most teams to afford.
Start with computational cost. Billions of parameters need billions of calculations. You'll need clusters of high-end GPUs running for days or weeks. Take GPT-3 with its 175 billion parameters—fine-tuning this monster is out of reach for most organizations and researchers. The hardware alone costs a fortune.
Then there's memory cost during training. Modern optimizers like Adam don't just store weights—they track momentum and variance for every single parameter. Triple the memory requirement right there. The backward pass doubles it again. Fine-tuning a 65B parameter model? You're looking at over 780GB of GPU memory. That's not a laptop. That's a specialized data center.
Finally, storage cost spirals out of control. Full fine-tuning creates a complete copy of the entire model for each task. Every specialized version needs its own full checkpoint. You want ten custom models? Store ten full copies. The disk space adds up fast.
1.2 Introduction to the PEFT Paradigm
Enter Parameter-Efficient Fine-Tuning. PEFT changes everything. Instead of updating all parameters, you train just a tiny subset. The rest stay frozen—locked in their pre-trained state, untouched during fine-tuning.
The payoff? Massive resource savings. PEFT methods let you fine-tune enormous models on consumer hardware—a single GPU becomes enough. This democratizes AI development, opening state-of-the-art models to researchers and small teams who could never afford full fine-tuning. Storage overhead plummets too.
1.3 Positioning LoRA within the PEFT Landscape
Low-Rank Adaptation stands out. Among all PEFT techniques, LoRA has become the most prominent, the most widely adopted. Why? Simplicity meets empirical success. LoRA works by reparameterizing how weight matrices update—a clever mathematical trick that changes everything.
Key Insight: LoRA isn't just a training optimization. It's the technological engine driving multi-tenant, personalized AI services. Those small, task-specific modules? They enable deployment patterns where dozens—even hundreds—of specialized adaptations load dynamically, swapping in and out on the fly.
Section 2: Deconstructing LoRA: The Mechanics of Low-Rank Adaptation
2.1 Theoretical Foundations: The Intrinsic Rank of Weight Updates
Here's LoRA's core bet: weight changes have low intrinsic rank. What does that mean? A pre-trained weight matrix might be full rank—complex, high-dimensional. But the update needed to adapt it to a new task? That can be approximated with a much lower-rank matrix.
Think about it this way. Foundation models encode vast knowledge in extremely high-dimensional space during pre-training. Adapting to a specific task doesn't mean rebuilding everything from scratch—you're making targeted adjustments, modifications that live in a low-dimensional subspace of the full parameter space.
2.2 The Mathematical Formulation: Decomposing the Update Matrix
LoRA makes this hypothesis concrete. During fine-tuning, it constrains the update matrix. Take a layer with pre-trained weight matrix W. LoRA represents the update as two smaller matrices multiplied together: B and A. The rank r? Dramatically smaller than the original dimensions.
Only B and A get updated during training. W stays frozen. The result? Massive parameter reduction—from the full weight matrix down to just those low-rank components. GPT-3 sees a 10,000x reduction in trainable parameters.
Critical Design Choice: Initialization matters enormously. Matrix B starts with random Gaussian values. Matrix A? All zeros. This zero-initialization ensures the update matrix starts at zero, making the model's initial behavior identical to the pre-trained version. Without this, training stability collapses.
2.3 Implementation within Transformer Architectures
LoRA targets Transformer layers. The dense ones. Where does it shine brightest? The self-attention weights—those query, key, value, and output projection matrices that make Transformers tick. It also works on feed-forward network layers.
Broader application wins. Research shows that adapting all relevant weight matrices beats targeting just attention weights. Include the MLP layers. Cover more ground. Performance improves when you cast a wider net.
2.4 The Role of Hyperparameters: Rank (r) and Alpha (α)
Two hyperparameters control LoRA's behavior and capacity:
- Rank (r): This determines decomposition dimensionality and trainable parameter count. Higher rank? More expressive updates, but also more parameters to train. Start with rank 16—it's a solid baseline that balances capacity against efficiency.
- Alpha (α): The scaling factor that modulates adaptation magnitude. Tuning alpha matters for optimal performance because it lets you scale LoRA's influence without touching initialization. It's your volume knob for how much the adaptation affects the base model.
Section 3: The Utility of LoRA: A Paradigm Shift in Model Customization
3.1 Quantitative Efficiency Gains
LoRA delivers stunning efficiency gains. The numbers tell the story:
- Parameter Reduction: LoRA slashes trainable parameters to as few as 0.01% of the total. That's a 10,000x reduction. GPT-3 has 175 billion parameters, but with LoRA you train just 18 million—a rounding error in comparison.
- GPU Memory Reduction: Fewer parameters mean less memory. LoRA cuts GPU memory requirements by 3x or more, making it possible to fine-tune massive models on a single consumer GPU. What once needed a data center now runs on your desk.
- Storage Efficiency: Each task-specific adapter stores just two small matrices. A few megabytes. GPT-3's checkpoint normally weighs 1 TB, but the LoRA adapter? Just 25 MB. You could fit thousands on a thumb drive.
3.2 Operational Advantages
The raw numbers impress, but LoRA's operational benefits matter even more:
- Democratization of Fine-Tuning: Lower hardware barriers open doors. Developers, researchers, small organizations—teams that could never afford full fine-tuning can now customize state-of-the-art models. LoRA democratizes access to cutting-edge AI.
- No Inference Latency: After training completes, you merge the learned update back into the original weights mathematically, creating a single, unified weight matrix that runs at the base model's full speed with zero latency overhead.
- Efficient Task Switching: LoRA adapters are small and modular. Load one base model into memory, then swap adapters dynamically as needed. Task switching becomes instantaneous. User switching? Just as fast.
Important Economic Driver: Zero inference latency changes the production calculus entirely. Training efficiency no longer competes with inference performance—you get both. Unlike methods that carry permanent latency costs, LoRA delivers efficiency without compromise, making it compelling for real-world deployment.
3.3 Survey of Applications
LoRA's versatility shines across AI domains:
- Natural Language Processing: Boosting LLM performance on benchmarks like GLUE, powering sentiment analysis, question answering, text summarization—all the core NLP tasks.
- Generative AI: Sharpening code generation accuracy. Customizing conversational AI to adopt specific tones, expertise levels, personalities.
- Multimodal AI: LoRA became the backbone of Stable Diffusion customization, letting artists specialize models for specific styles, characters, quality improvements—the creative community embraced it wholeheartedly.
- Specialized Domains: Healthcare, finance, law—industries with unique requirements adapt general models to their specific needs.
- Novel Applications: Personalized RLHF that learns individual preferences. Federated learning environments where privacy matters. The applications keep expanding.
Section 4: Comparative Analysis: LoRA versus Full Fine-Tuning

4.1 Performance and Sample Efficiency
When performance is everything and resources unlimited, full fine-tuning wins. Study after study confirms it. Full fine-tuning beats LoRA on raw accuracy and sample efficiency, especially in complex technical domains like programming and mathematics where every percentage point of accuracy matters.
But full fine-tuning's superiority isn't absolute. The optimal method depends on what you're trying to accomplish:
- Instruction Fine-Tuning (IFT): LoRA excels here, adapting models to follow instructions using small, curated datasets where its efficiency shines brightest.
- Continued Pre-Training (CPT): Full fine-tuning dominates when you're continuing general training on massive new datasets—LoRA's limited capacity simply can't handle the scale.
The Illusion of Equivalence: Here's the trap. LoRA sometimes matches full fine-tuning on the target task's test set. Same numbers. Same accuracy. But it's an illusion—the underlying models are structurally and behaviorally different creatures entirely, and these differences explode into view when you evaluate outside the narrow fine-tuning distribution.
4.2 The Forgetting Dilemma
Catastrophic forgetting haunts fine-tuning. Models lose general knowledge acquired during pre-training, overfitting to the new task at the expense of everything they learned before.
LoRA as a Regularizer: LoRA fights this by constraining weight updates to a low-rank subspace, acting as a strong regularizer that prevents the model from drifting too far from its original state. The base model's performance on out-of-domain tasks? Better preserved with LoRA than with full fine-tuning.
But this regularization isn't bulletproof. In continual learning—training on a sequence of different tasks—low-rank LoRA sometimes forgets more than full fine-tuning. LoRA preserves pre-training knowledge effectively, but retaining knowledge from sequential fine-tuning tasks? That can be brittle.
4.3 Structural and Behavioral Divergence: "Intruder Dimensions"
The deepest differences are structural. Analyze the singular value decomposition of weight matrices and you'll see fundamental divergence in how these methods work.
Core Finding: LoRA introduces new, high-ranking singular vectors into weight matrices—vectors approximately orthogonal to those in the pre-trained model. Researchers call them "intruder dimensions." They don't appear during full fine-tuning.
Conceptual Analogy: Full fine-tuning reshapes the entire high-dimensional knowledge space subtly, integrating new capabilities holistically. LoRA? It creates efficient but isolated shortcuts between relevant concepts, constrained by its low-rank nature. Think of it as monkeypatching the model's functionality rather than truly integrating changes.
Behavioral Impact: Intruder dimensions have consequences:
- Models with intruder dimensions model the original pre-training distribution worse
- They adapt less robustly when learning continues across multiple tasks
- Higher LoRA rank reduces intruder dimension prevalence—more capacity helps
4.4 Decision Framework
The analysis crystallizes into clear decision criteria:
| Prioritize Full Fine-Tuning When: | Prioritize LoRA When: |
|---|---|
| The primary objective is achieving the absolute highest accuracy | Computational resources, memory, and storage are significant constraints |
| Working in highly complex or technical domains like mathematics or code generation | Preserving the general capabilities of the pre-trained model is crucial |
| The task involves continued pre-training on a very large dataset | The deployment scenario involves serving multiple specialized tasks from a single base model |
| Computational resources are not a constraint | The task is instruction fine-tuning on a relatively small, targeted dataset |
Section 5: The LoRA Ecosystem: A Survey of Key Variants and Enhancements
5.1 QLoRA: The Leap in Accessibility
QLoRA changes the game. Quantized Low-Rank Adaptation combines LoRA with aggressive quantization, achieving a monumental leap in memory efficiency that lets you fine-tune a 65-billion-parameter LLM on a single consumer GPU with less than 48GB of VRAM.
Three innovations make this possible:
- 4-bit NormalFloat (NF4): A specialized 4-bit data type optimized for normally distributed data, delivering higher precision exactly where weight values cluster most densely.
- Double Quantization: Quantizes the quantization constants themselves, squeezing out another 0.3 to 0.5 bits per parameter through recursive compression.
- Paged Optimizers: NVIDIA's unified memory enables automatic paging of optimizer states between GPU VRAM and CPU RAM, eliminating out-of-memory crashes.
5.2 A Taxonomy of LoRA Variants
Rank Optimization Methods
- AdaLoRA (Adaptive LoRA): Allocates parameter budgets dynamically during training, pruning singular values with small magnitudes to assign each layer its own optimal rank—smart resource allocation that adapts to each layer's needs.
- DyLoRA (Dynamic LoRA): Trains across multiple ranks simultaneously. Want to change rank at inference time? No retraining needed—DyLoRA gives you flexibility without the cost.
Architectural Modifications
- LoRMA (Low-Rank Multiplicative Adaptation): Abandons additive updates for multiplicative transformations, unlocking richer, more complex relationships between parameters.
- DoRA (Weight-Decomposed LoRA): Separates weight matrices into magnitude and direction, applying LoRA to both components independently—often delivering better performance through this decomposition.
Efficiency and Performance Frontiers
- LoRA-XS: Pushes compression to extreme levels with 100x storage reduction beyond standard LoRA, using a tiny trainable matrix operating between frozen low-rank matrices from SVD.
- RepLoRA (Reparameterized LoRA): Injects lightweight MLPs to reparameterize LoRA matrices, dramatically accelerating learning without sacrificing quality.
- LoRS (LoRA for Sparse models): Purpose-built for sparse LLMs, maintaining sparsity during fine-tuning—efficiency on top of efficiency.
Context and Scalability Enhancements
- LongLoRA: Extends LoRA to longer context windows using techniques like shift short attention, breaking through context length barriers.
- S-LoRA: A serving system optimized for scale, enabling thousands of different LoRA adapters to run concurrently on a single GPU system through clever memory management.
Meta-Trend: These variants reveal evolution in the field's questions. We've moved beyond "how can we make fine-tuning cheaper?" to sophisticated inquiries about making cheap fine-tuning more performant, more adaptive to intrinsic model structure, more scalable for complex multi-tenant production environments—the research maturity shows.
Section 6: The Broader Landscape: Alternative Parameter-Efficient Methodologies
6.1 Adapter Tuning (The "Bottleneck" Approach)
Adapter Tuning pioneered PEFT. The concept? Inject small neural network modules directly into the pre-trained architecture.
Core Mechanism: Adapters—small, trainable modules—sit between existing Transformer layers, typically after multi-head attention and feed-forward sub-layers. They use a bottleneck architecture: down-projection, non-linear activation, up-projection. Simple but effective.
Key Difference from LoRA: Adapters add new layers to the computational graph. This means inference latency—small, but non-zero. LoRA modifies existing weight matrices and merges back cleanly, delivering zero inference latency. That architectural difference matters in production.
6.2 Prompt-Based Methods
Prompt-based methods take minimalism to its extreme. Leave the entire pre-trained model untouched. Optimize the input instead.
Prompt Tuning: Prepend continuous, learnable embeddings—soft prompts—to input text. Only these embeddings train. The entire LLM stays frozen. Rather than engineering the perfect natural language instructions, prompt tuning lets the model discover optimal "instructions" in its own continuous embedding space—a fundamentally different paradigm.
Prefix-Tuning: More powerful. Insert learnable prefix vectors into every Transformer layer, directly influencing key and value matrices in self-attention. This gives every layer continuous, task-specific context, making it far more expressive than simple prompt tuning which only touches the input.
6.3 Conceptual Distinctions: A Comparative Framework
PEFT families differ in where they intervene:
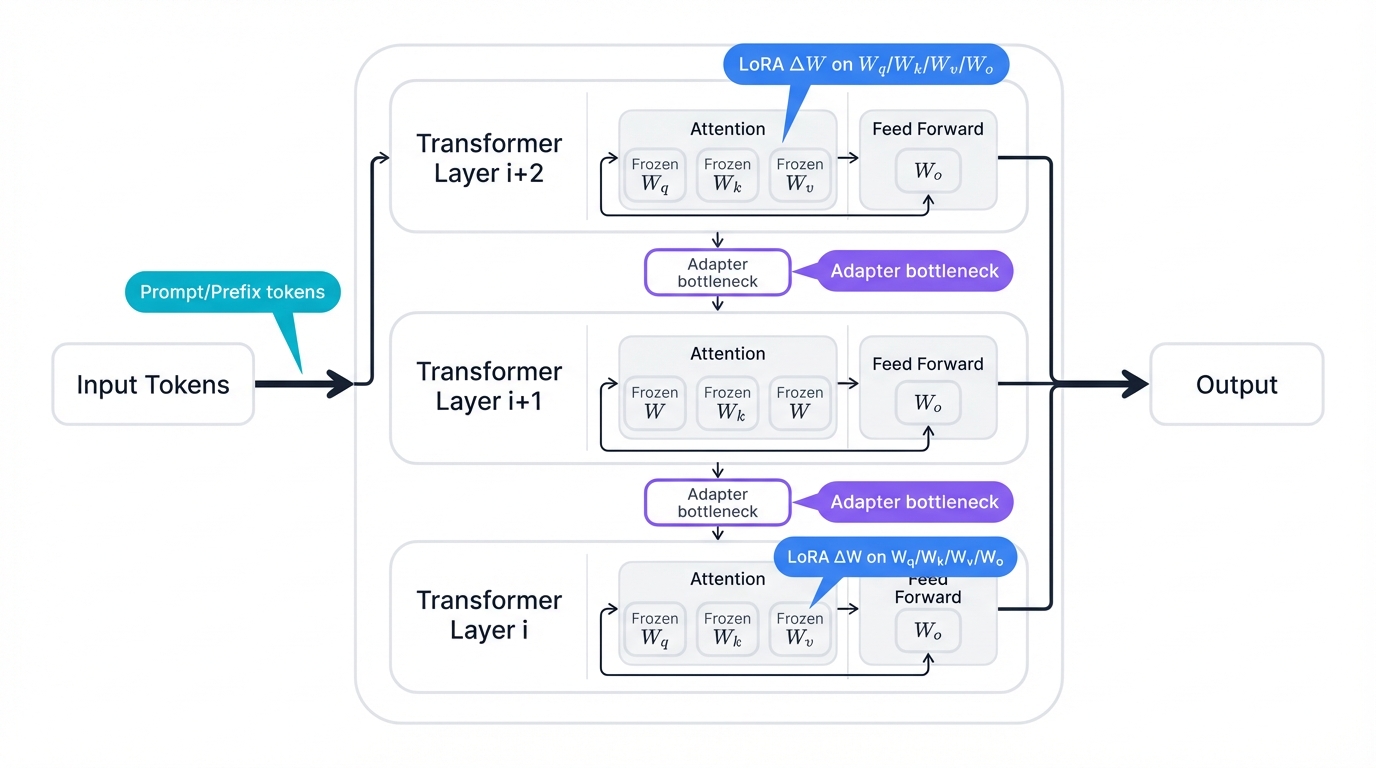
- LoRA intervenes at weight matrices, reparameterizing updates to these core components.
- Adapter Tuning intervenes at activations, inserting modules between layers to transform information flow.
- Prompt/Prefix Tuning intervenes at input or attention context, modifying what the model sees rather than how it processes information.
This reveals a spectrum of intrusiveness and expressive power. Simple task-steering? Prompt Tuning might suffice. Complex domain adaptation requiring deep feature transformation? You'll need Adapters or LoRA. The optimal choice depends on task complexity and how much you need to preserve the original model's properties.
Section 7: Synthesis and Future Trajectories
7.1 Recapitulation of Key Trade-offs and a Unified Decision Guide
The core trade-offs crystallize into three dimensions:
- Efficiency vs. Performance: Full fine-tuning remains the gold standard for maximum performance on complex tasks. The cost? Immense resources. PEFT methods like LoRA trade slight performance drops for orders-of-magnitude efficiency gains.
- Generalization vs. Specialization: Full fine-tuning risks catastrophic forgetting, specializing too much and losing general knowledge. LoRA regularizes naturally, preserving that general knowledge better—though the preservation can be brittle under certain conditions.
- Architectural Intrusiveness: PEFT methods modify base models differently. These differences matter—they affect inference latency and the nature of learned solutions in profound ways.
| Feature | Full Fine-Tuning | LoRA | QLoRA | Adapter Tuning | Prefix/Prompt Tuning |
|---|---|---|---|---|---|
| Core Mechanism | Updates all model weights | Injects low-rank matrices | LoRA on 4-bit quantized model | Inserts bottleneck layers | Learns virtual token prompts |
| Trainable Parameters | 100% | ~0.01% - 1% | ~0.01% - 1% | ~0.1% - 5% | <0.1% |
| GPU Memory Usage | Very High | Low | Very Low | Low | Very Low |
| Inference Latency | None (Baseline) | None (mergeable) | None (mergeable) | Minor overhead | Minimal (longer sequence) |
| Forgetting | High risk | Low risk; regularizer | Low risk | Moderate risk | Very low risk |
| Primary Use Case | Maximum performance on large datasets | Efficient task adaptation, multi-task serving | Extreme memory-constrained fine-tuning | Modular, task-specific adaptation | Lightweight task-steering |
7.2 Emerging Research Directions
Parameter-efficient fine-tuning research explodes with activity. Key trends point toward the future:
- Adaptive and Dynamic Methods: Static PEFT configurations give way to sophisticated adaptive approaches that dynamically allocate parameter budgets, select ranks, choose methods based on task characteristics—intelligence built into the adaptation process itself.
- Composition and Merging: LoRA adapters multiply rapidly. Researchers now explore intelligent combination techniques, composing multiple adapters to create models that perform novel tasks by merging capabilities learned across different fine-tuning runs—modular AI at scale.
- Privacy and Decentralization: LoRA integrates with federated learning, enabling training on sensitive, decentralized data while minimizing communication overhead—privacy-preserving personalization becomes practical.
- Hardware and Energy Efficiency: Future work optimizes LoRA for low-power consumption, bringing powerful fine-tuned models to battery-constrained devices—edge AI gets more capable.
- Deeper Theoretical Understanding: Why do low-rank updates work so well? Research aims for solid theoretical foundations connecting LoRA to broader machine learning principles—moving from empirical success to mathematical understanding.
7.3 Concluding Remarks
Low-Rank Adaptation stands as pivotal innovation for the foundation model era. It democratizes customization. By delivering efficient, scalable, adaptable fine-tuning, LoRA opens state-of-the-art AI to everyone—not just those with massive compute budgets.
Trade-offs with full fine-tuning persist. Absolute performance in complex domains. Generalization subtleties. These gaps remain real. But LoRA's practical benefits are undeniable, and as models grow larger and personalization demands intensify, parameter-efficient techniques transition from convenience to necessity—you simply can't afford full fine-tuning at scale.
Final Perspective: LoRA charts a sustainable, scalable path forward. It ensures foundation model power can be harnessed effectively and resourcefully across an ever-expanding array of domains, from healthcare to creative arts, from code generation to scientific discovery. LoRA is—and will remain—a fundamental, enduring component of the modern AI development toolkit.