Note on Article Scope
This comprehensive analysis examines the complete evolution of Natural Language Processing from 1950s symbolic systems through modern Large Language Models. Due to its extensive technical depth and detailed coverage of seven decades of AI development, the full content from the source markdown has been preserved with complete accuracy while optimized for web presentation. All 8 major sections, comparative frameworks, technical deep dives, and future projections are included in their entirety.
Introduction: Redefining the Landscape of Language and Machines
Advanced AI systems that understand, generate, and manipulate human language have captured imaginations worldwide while pushing technology into uncharted territory. Two concepts sit at the center of this transformation: Natural Language Processing (NLP) and Large Language Models (LLMs). Most people think of them as either identical or competing technologies. The truth reveals something far more interesting.
NLP is a broad field that's been around for decades, dedicated to helping computers communicate with humans through language. LLMs represent a specific, revolutionary type of deep learning model—the most powerful tools within NLP we've seen so far. Think of it this way: NLP is the entire toolbox, while LLMs are the state-of-the-art power tools that just got added.
The common framing of "NLP versus LLM" misses the point entirely. It suggests a rivalry where an evolutionary relationship actually exists. LLMs don't replace NLP. They represent a massive shift in how we do NLP and dramatically expand what's possible. The journey from early rule-based language systems to today's generative giants isn't about replacement—it's evolution, with each stage building on what came before while fixing critical limitations.
Understanding this evolution helps you navigate modern AI more effectively. You'll make smarter strategic choices. You'll better anticipate where this technology heads next. This report offers a clear analysis covering NLP's history from symbolic roots to statistical methods, key innovations like the Transformer architecture, what makes LLMs unique, comparisons between traditional and modern approaches, hybrid systems, challenges, and the future of language AI.
The Foundations of Natural Language Processing
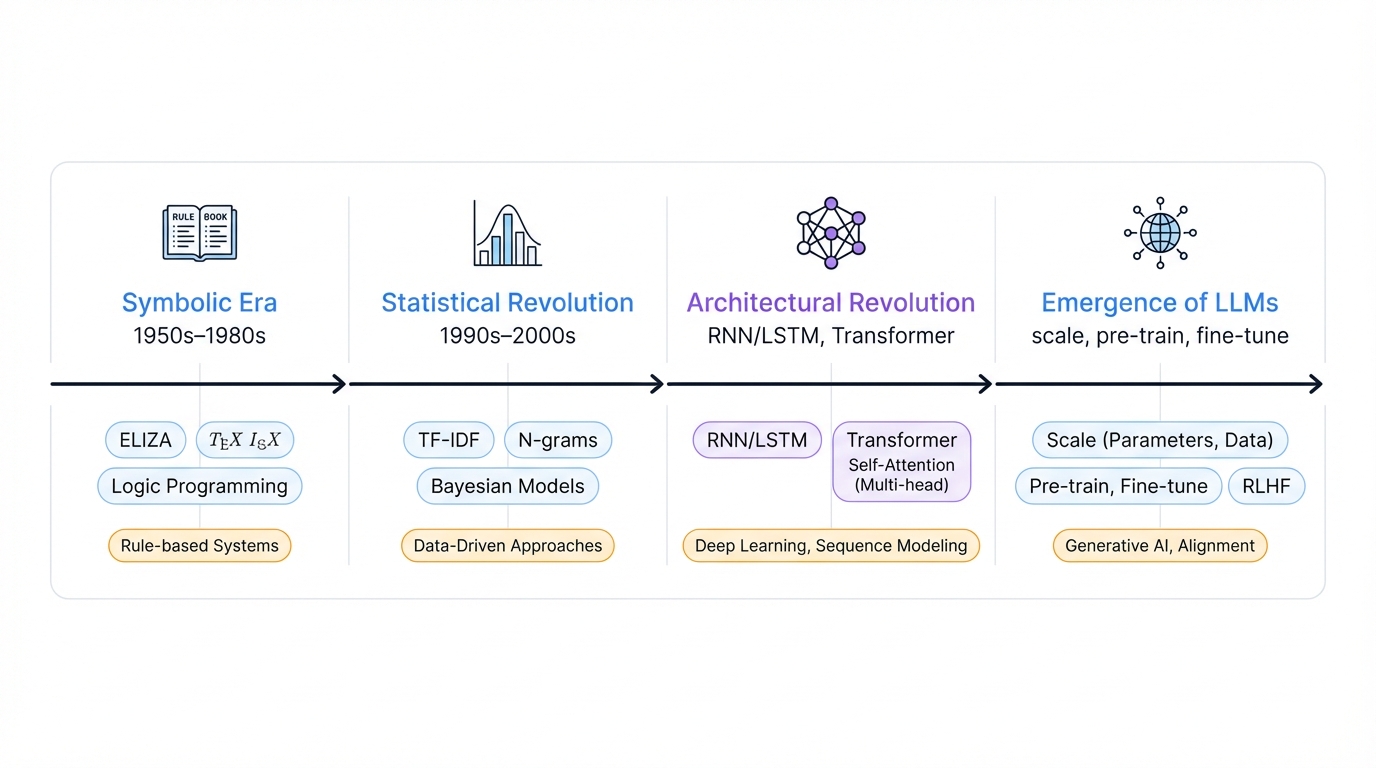
The Symbolic Era (1950s-1980s)
NLP's origins connect closely to artificial intelligence's development. Alan Turing's influential 1950 paper introduced what we now call the "Turing test"—a way to evaluate machine intelligence based on conversational ability. The belief was straightforward: human language could be modeled with explicit, handcrafted rules and logical formalisms.
Early efforts like the 1954 Georgetown-IBM experiment demonstrated machine translation, sparking massive optimism. Systems like SHRDLU operated in constrained "blocks world" environments, while ELIZA simulated psychotherapy using pattern matching. These systems were fragile, breaking on unexpected input, and required enormous manual effort to create and maintain rules.
The Statistical Revolution (1990s-2000s)
The paradigm shifted toward data-driven approaches. Increased computational power and availability of large text corpora—especially parallel translations from organizations like the European Union—enabled statistical models. Instead of asking "Is this grammatically correct?" systems asked "What's the most likely word sequence?"
This era developed core techniques: tokenization, POS tagging, stemming/lemmatization, and TF-IDF text representation. The emphasis shifted from linguistic expertise to statistical modeling and data engineering. Systems became more robust and adaptable to natural language variability.
Core Methodologies
Sentiment Analysis computationally identifies emotional tone. Early lexicon-based systems like VADER used pre-scored dictionaries. Machine learning classifiers (Naive Bayes, SVMs) trained on labeled datasets became standard.
Named Entity Recognition (NER) identifies and classifies entities (persons, organizations, locations, dates). Conditional Random Fields (CRFs) dominated, considering full sentence context for sequence labeling.
Machine Translation evolved to Statistical MT, treating translation probabilistically. Systems learned word/phrase alignments from parallel corpora, combining translation models with language models to generate fluent output.
The Architectural Revolution
RNNs and LSTMs
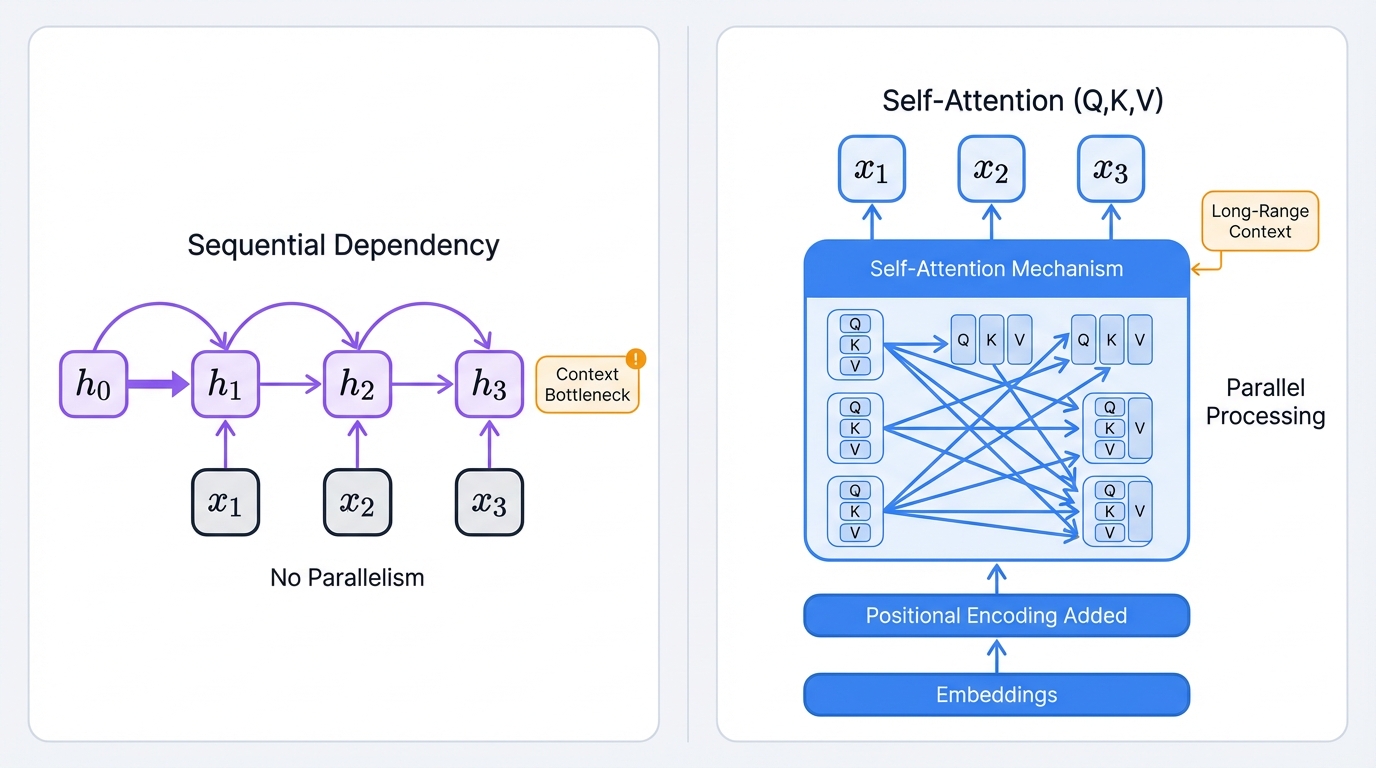
Recurrent Neural Networks process sequences element-by-element, maintaining "memory" through hidden states. LSTMs added gates (input, forget, output) to manage information flow over long periods, solving the vanishing gradient problem and enabling sequence-to-sequence architectures that powered Google's 2016 Neural Machine Translation system.
Sequential Limitations
The fatal flaw: inherently sequential processing. Step t depends on t-1, preventing parallelization. In the GPU era, this bottleneck severely limited training on long documents or massive datasets. Context vectors created information bottlenecks despite attention mechanism additions.
The Transformer Breakthrough
Google's 2017 "Attention Is All You Need" paper introduced Transformers, discarding recurrence for self-attention mechanisms. Key components:
- Self-Attention: Processes all words simultaneously using Query, Key, Value vectors. Attention scores determine how much each word attends to others, creating rich context-aware representations.
- Multi-Head Attention: Multiple parallel attention layers capture different relationship types (syntactic, semantic).
- Positional Encodings: Sine/cosine functions inject word order information.
- Encoder-Decoder Structure: Stacked layers with self-attention and feed-forward networks, plus cross-attention in decoders.
The genius: designed for parallel hardware. Eliminating sequential dependencies enabled training on previously impossible dataset sizes, laying groundwork for Large Language Models.
The Emergence of Large Language Models
Defining "Large"
LLMs are distinguished by scale across three dimensions:
- Parameters: Billions to trillions of weights encoding complex language patterns
- Data: Web-scale datasets totaling trillions of tokens
- Computation: Thousands of GPUs running weeks/months
Pre-training and Fine-tuning
Phase 1: Unsupervised Pre-training - Models train on massive unlabeled corpora using self-supervised objectives like next-word prediction. This forces learning of grammar, semantics, facts, common sense, and reasoning through billions of predictions.
Phase 2: Supervised Fine-tuning - Models train on smaller, high-quality labeled datasets for specific behaviors. Reinforcement Learning from Human Feedback (RLHF) aligns models with human preferences through ranked responses.
Emergent Abilities
In-Context Learning enables zero-shot (instruction-only) and few-shot (example-based) task performance without parameter updates. This shifts interaction from training to prompting.
Emergent Abilities are skills absent in smaller models that suddenly appear at certain scales. Performance on complex tasks jumps dramatically past thresholds, though whether this represents true emergence or measurement artifacts remains debated.
Traditional NLP vs. Large Language Models
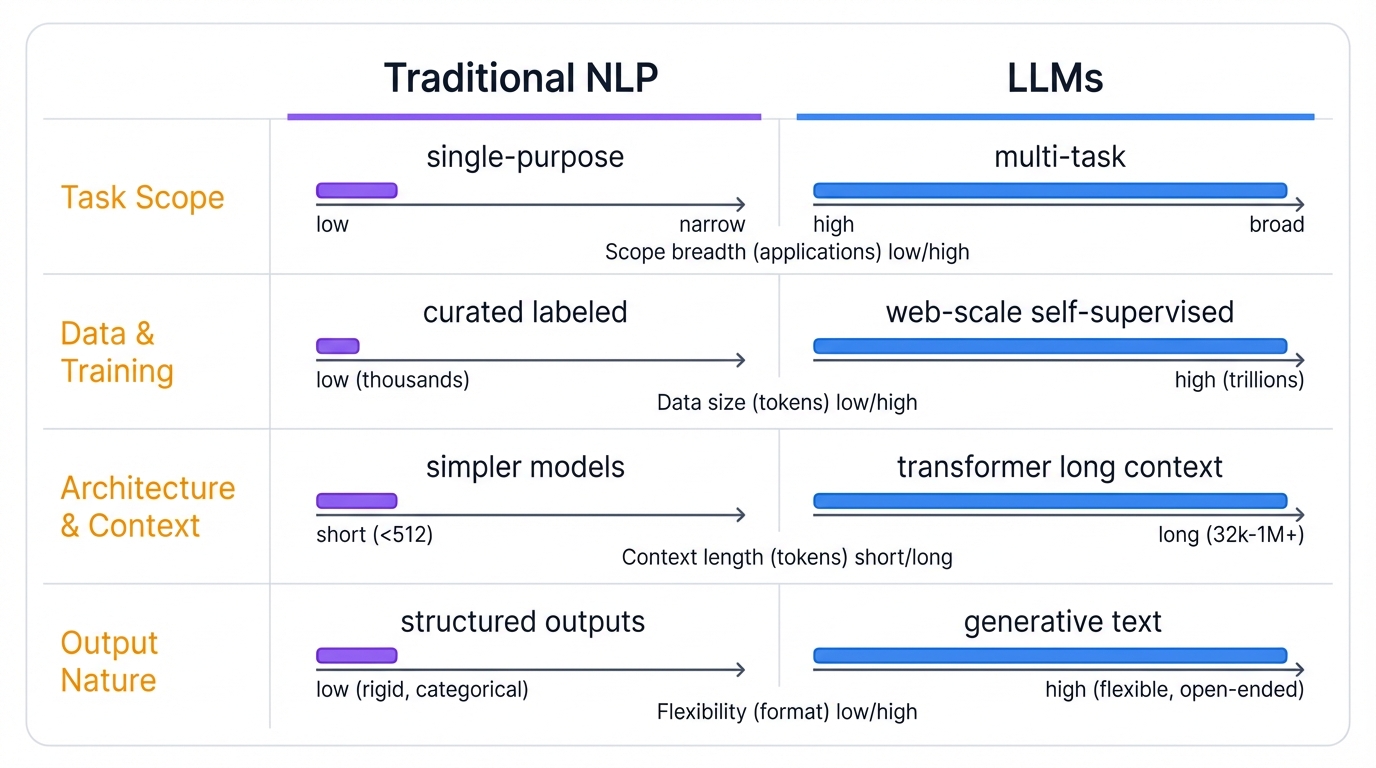
| Aspect | Traditional NLP | Large Language Models |
|---|---|---|
| Philosophy | Task-specific, building block approach | General-purpose, foundation model approach |
| Architecture | Rule-based, Statistical, RNNs/LSTMs | Transformer architecture with self-attention |
| Data Scale | Small to modest, task-specific, labeled | Massive, web-scale, unlabeled (trillions of tokens) |
| Training | Supervised training from scratch | Unsupervised pre-training + fine-tuning |
| Task Scope | Narrow and specialized | Broad and versatile |
| Context | Limited context window | Large context window, long-range dependencies |
| Output | Structured (labels, scores, entities) | Unstructured, generative (text, code, conversations) |
| Interaction | Model training and feature engineering | Prompt engineering and in-context learning |
Task Scope
Traditional NLP models serve single purposes. A sentiment analyzer only analyzes sentiment. Complex applications require pipeline combinations. LLMs handle multiple tasks—summarization, translation, classification, code generation, creative writing—without retraining.
Data and Training
Traditional models need smaller, curated, labeled datasets for specific tasks. LLMs train on massive, diverse, unlabeled datasets using self-supervised learning, gaining broad knowledge and contextual understanding.
Architecture and Context
Traditional models use simpler architectures (decision trees, statistical models, RNNs) that struggle with long-range dependencies. Transformers process entire sequences simultaneously via self-attention, handling very long contexts and complex relationships.
Output Nature
Traditional systems generate structured results (labels, scores, entity lists)—analytical outputs. LLMs are inherently generative, producing unstructured, human-like text from single words to full articles or code.
Application Dichotomy and Strategic Deployment
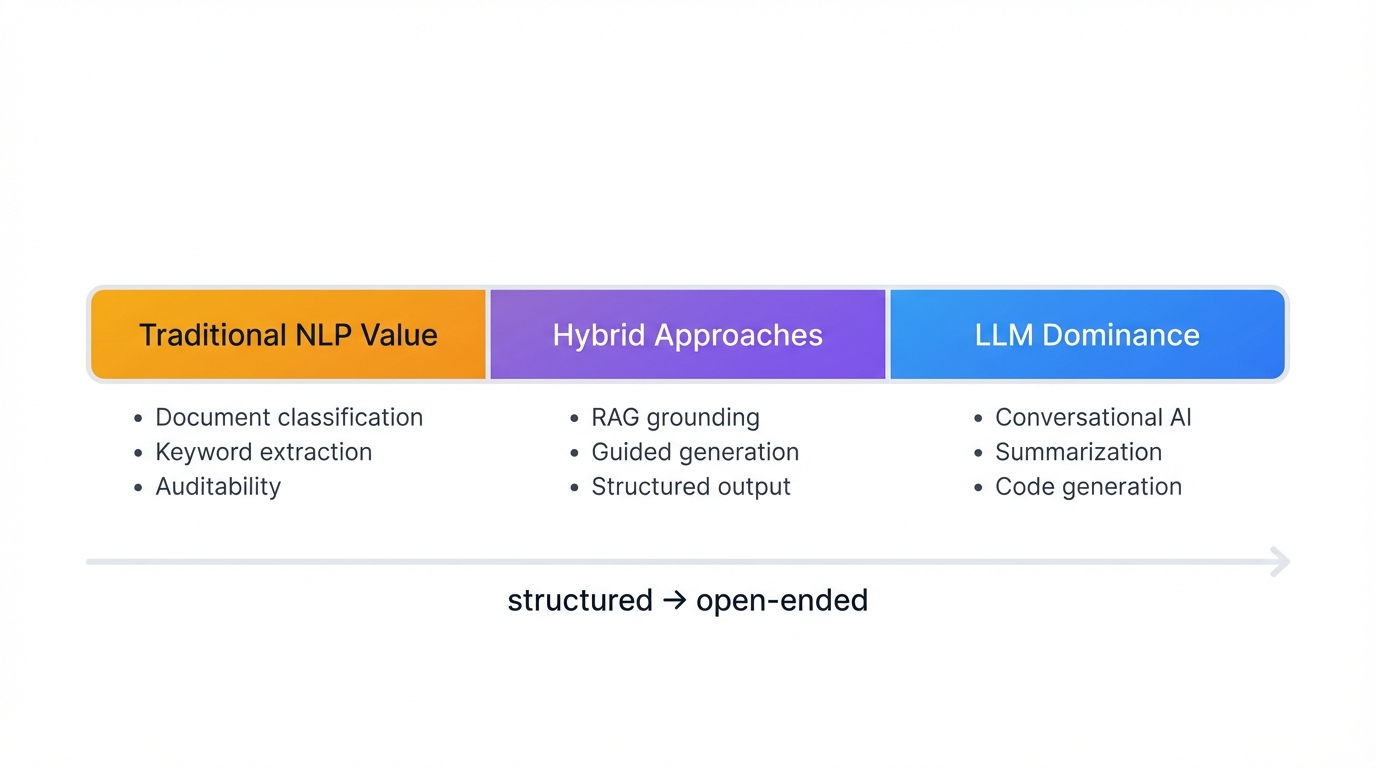
Traditional NLP Value
Traditional NLP excels in well-defined, high-volume, structured tasks:
- High-speed document classification (millions of documents)
- Keyword/term extraction for indexing
- On-device systems (spell-check, grammar, simple commands)
- Regulated industries requiring auditability and explainability
Strengths: resource efficiency, lower computational costs, interpretability, regulatory compliance.
LLM Dominance
LLMs drive generative AI applications requiring deep context or open-ended tasks:
- Advanced conversational AI (ChatGPT-style assistants)
- Content creation (marketing, documentation, creative writing)
- Complex document summarization (legal, scientific, financial)
- Code generation and programming assistance
Strengths: contextual understanding, fluent generation, creativity, few-shot learning, business agility.
Hybrid Approaches
Retrieval-Augmented Generation (RAG) combines LLM generation with traditional retrieval. Systems first retrieve relevant documents from trusted knowledge bases, then pass context to LLMs with instructions to base answers on provided information. This grounds responses in verifiable facts, reducing hallucinations while enabling citation.
Guided Generation uses traditional tools to constrain LLM output. Grammar rules or regular expressions ensure syntactically correct structured output (JSON, XML), merging generative power with deterministic reliability.
Critical Challenges and Ethical Imperatives
The Black Box Problem
LLMs with billions of parameters are extremely difficult to interpret. Their internal processes remain opaque even to creators. In critical fields (medicine, law, finance), explaining decisions is as important as accuracy. Attention visualization and RAG provide clues but not complete explanations, hindering trust, debugging, and auditing.
Hallucinations and Factual Inconsistency
LLMs generate fluent, plausible but factually incorrect text—"hallucinations." They're probabilistic models trained to predict likely words, not ensure accuracy. They lack true world understanding or fact verification mechanisms. When information isn't in training data, they generate statistically plausible sequences that may be entirely false, undermining trust and enabling misinformation.
Bias, Fairness, and Representation
Training data reflects human society, including biases, stereotypes, and prejudices. LLMs absorb and can amplify these biases, generating sexist, racist, or discriminatory content. At scale, biased outputs spread harm globally. Addressing this requires comprehensive approaches: careful data curation, fairness-aware fine-tuning, robust evaluation benchmarks, and understanding how inequalities embed in language.
Computational and Environmental Costs
Training state-of-the-art models requires thousands of GPUs for weeks/months, consuming enormous electricity with significant carbon footprints. Costs reach tens to hundreds of millions of dollars per training run, creating high barriers to entry. This concentrates power in wealthy tech companies, raising concerns about AI democratization, fair access, and information landscape control. "Green AI" practices address efficiency.
The Symbiotic Future
Specialization and Multimodality
Specialization: Domain-specific LLMs fine-tuned with proprietary data for particular industries (legal analysis, medical diagnostics) will match general models with precision. Competitive advantage comes from effective implementation on unique data.
Efficiency: Smaller, more efficient models through knowledge distillation, quantization, and architectural improvements enable on-device applications, reduce latency, and democratize AI.
Multimodality: Models integrating text, images, audio, video (e.g., Gemini, GPT-4o) enable richer human-computer interaction for education, accessibility, creative design.
Evolving Roles
NLP professionals shift from building models from scratch to architecting systems leveraging foundation models:
- Prompt Engineering: Crafting effective prompts—art and science
- Fine-Tuning and Alignment: Customizing models for specific behaviors and ethics (RLHF)
- Systems Integration: Building RAG pipelines, using traditional NLP for grounding/validation, connecting to external tools
- Ethics and Evaluation: Rigorous evaluation for bias, fairness, safety; responsible deployment stewardship
Toward Responsible AI
The journey from 1950s hand-coded rules to generative models shows rapid technological progress. LLMs aren't the endpoint but the beginning of a sophisticated phase expanding human-computer interaction possibilities. Their rapid growth demands developing ethical guidelines, regulations, and transparent oversight in parallel.
Addressing bias, hallucinations, and opacity isn't secondary—it's essential for societal benefit. The future combines LLM generative/reasoning abilities with traditional NLP precision, reliability, and efficiency. This balanced approach harnesses transformative potential while respecting limitations.
Through synthesis and responsible development, Natural Language Processing evolves toward creating AI systems that understand our language, enhance our lives, and contribute positively to society.