
Executive Summary
Two titans clash in the AI arena. Large Language Models (LLMs) and Small Language Models (SLMs) represent fundamentally different philosophies in artificial intelligence—and choosing between them shapes your entire strategy, from architecture to cost to competitive advantage.
LLMs dominate as versatile generalists. They master broad knowledge and complex reasoning, wielding capabilities that seem almost magical in their breadth. But magic comes at a price—massive computational requirements, eye-watering costs, and infrastructure demands that would make even tech giants pause. These models excel in cloud-based deployments where scale matters more than speed, and where creativity and nuanced understanding justify premium expenses.
Key Concept: Understanding this foundational concept is essential for mastering the techniques discussed in this article.
SLMs take a different path. Speed. Precision. Specialization. These models thrive in resource-constrained environments, running efficiently on-device and delivering domain-specific accuracy that can outperform their larger cousins in narrowly defined tasks. Privacy-conscious? Budget-sensitive? Edge deployment required? SLMs answer these challenges with elegant efficiency.
Yet here's the strategic insight most organizations miss: you don't choose one or the other. Smart deployment means hybrid architecture—LLMs handling creative, complex reasoning while SLMs manage specialized, high-frequency tasks. This orchestration balances flexibility against speed, power against cost, generalization against precision. As the AI landscape accelerates and evolves at breakneck speed, your ability to blend both model types will determine whether you lead or follow in the intelligence revolution unfolding before us.
Section 1: Defining the Modern Language Model Landscape
Generative AI is rewriting the rules. Language models now understand us, respond to us, and reason through problems with startling sophistication. They're infiltrating every sector, transforming how we work and communicate. But behind this revolution stand two distinct approaches: Large Language Models and Small Language Models. Want a smart AI strategy? You need to understand what separates these architectures, what drives their design, and what each needs to thrive. This section cuts through the hype, defining LLMs and SLMs not just by size, but by purpose, philosophy, and the data that shapes their intelligence.
1.1 The Spectrum of Scale: From Billions to Trillions of Parameters
Size matters in AI. Parameters—those internal weights and biases learned during training—define what a model knows and can do. More parameters mean more capacity, more nuance, more capability. But where do you draw the line between "large" and "small"?
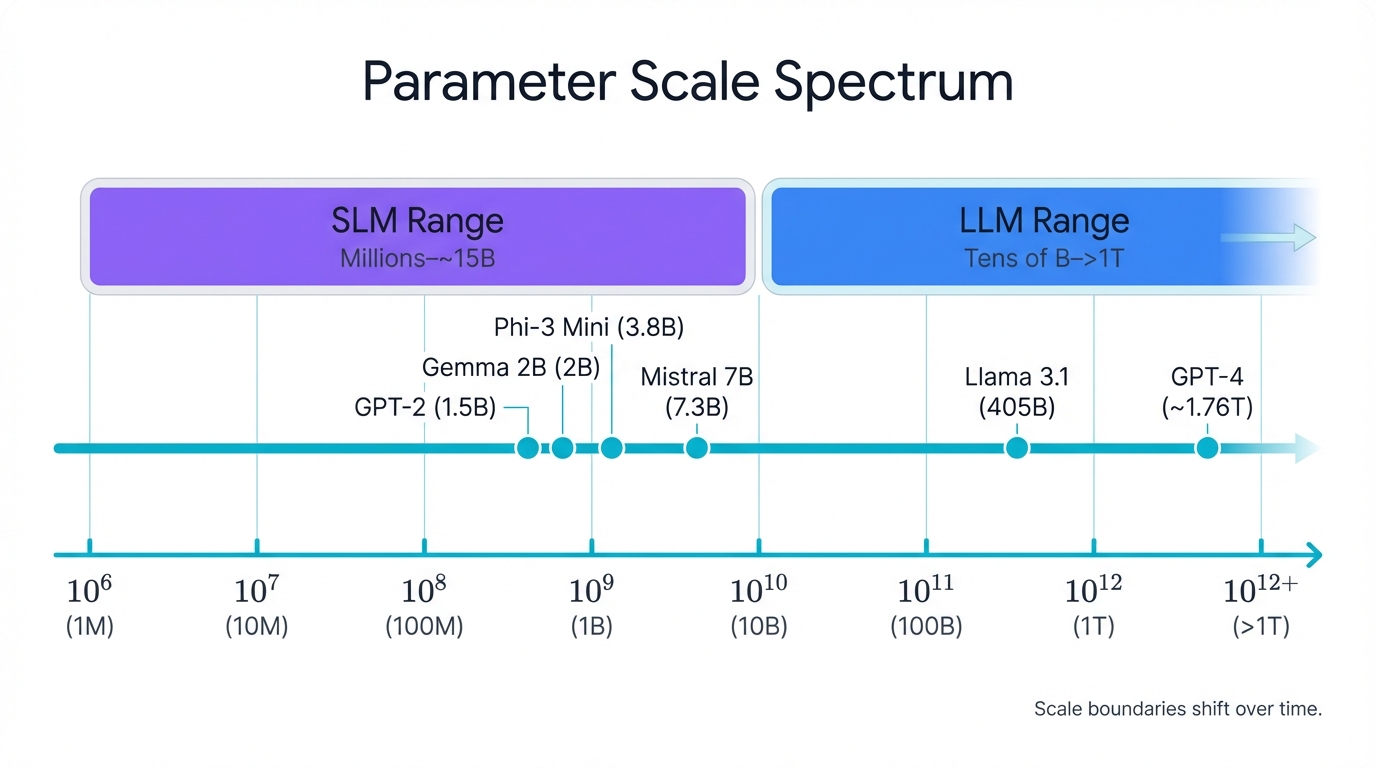
No rigid boundaries exist. Instead, we see a clear spectrum emerging across the industry. Large Language Models (LLMs) dominate the upper reaches, packing anywhere from tens of billions to over a trillion parameters. These behemoths exemplify the "scaling laws" that have driven AI's recent explosion—bigger models, more data, more compute equals better performance and emergent abilities. OpenAI's GPT-4 reportedly contains around 1.76 trillion parameters, a number so vast it's hard to comprehend. Meta's Llama 3.1, boasting 405 billion parameters, stands as a testament to open-source ambition at massive scale.
Small Language Models (SLMs) occupy the other end. These leaner architectures range from a few million parameters up to roughly 15 billion, though some definitions cap them even lower at 8 to 13 billion. This category is exploding with diversity and innovation. Mistral 7B (7.3 billion parameters) punches above its weight class. Microsoft's Phi-3 Mini (3.8 billion parameters) runs efficiently on modest hardware. Google's Gemma 2B (2 billion parameters) brings AI to the edge. Each represents a philosophy of doing more with less.
But here's the catch. These categories shift constantly. What we call "small" today would have been revolutionary just a few years ago—OpenAI's GPT-2, with its 1.5 billion parameters, was groundbreaking in 2019 but would now be classified as an SLM. Technology races forward relentlessly, and any fixed definition becomes obsolete almost immediately. That's why smart strategists focus not on arbitrary parameter counts, but on the underlying design philosophy and intended purpose that truly distinguish these models from one another.
1.2 Core Philosophies: The Generalist (LLM) vs. The Specialist (SLM)
Parameter counts tell you size. Philosophy tells you purpose. This distinction matters more than any number ever could, providing a stable framework even as technology evolves at dizzying speed.

LLMs as Generalists: Picture a Swiss Army knife for intelligence. An LLM aims to replicate human-like reasoning across virtually any domain, any task, any context. Its massive parameter count isn't bloat—it's necessity, the foundation that enables versatility. These models consume enormous datasets covering nearly everything humans have written, from poetry to physics, memes to mathematics. This comprehensive training produces what researchers call "emergent abilities"—skills that weren't explicitly programmed but arise naturally from scale, like understanding multi-turn conversations, reasoning through complex problems step by step, and following nuanced instructions without specific training. An LLM becomes a general-purpose brain capable of creative writing, sophisticated coding, scientific analysis, and countless other applications. Yet this breadth comes with a tradeoff: generalists sometimes lack the deep precision that specialized tasks demand.
SLMs as Specialists: Now picture a precision instrument. An SLM focuses on efficiency, speed, and accuracy within a clearly defined domain. It doesn't attempt to know everything—instead, it masters one thing completely. This specialization is its superpower. On specific benchmarks within its trained domain, an SLM can outperform much larger models, delivering faster responses with less computational overhead. Think of it this way: an LLM is a fully-equipped restaurant kitchen that can prepare any cuisine, while an SLM is a portable camping stove that makes the perfect espresso—simple, focused, reliable. SLMs sacrifice broad reasoning capability for targeted excellence, making them ideal for applications where domain expertise trumps general intelligence.
This philosophical divide drives strategic decisions far more reliably than any parameter threshold. As models continue growing larger and "large" keeps redefining itself, the choice between deploying broad, generalist intelligence versus collections of efficient, specialized tools remains the central question in AI architecture. That distinction won't change, even as the technology behind it evolves at breakneck pace.
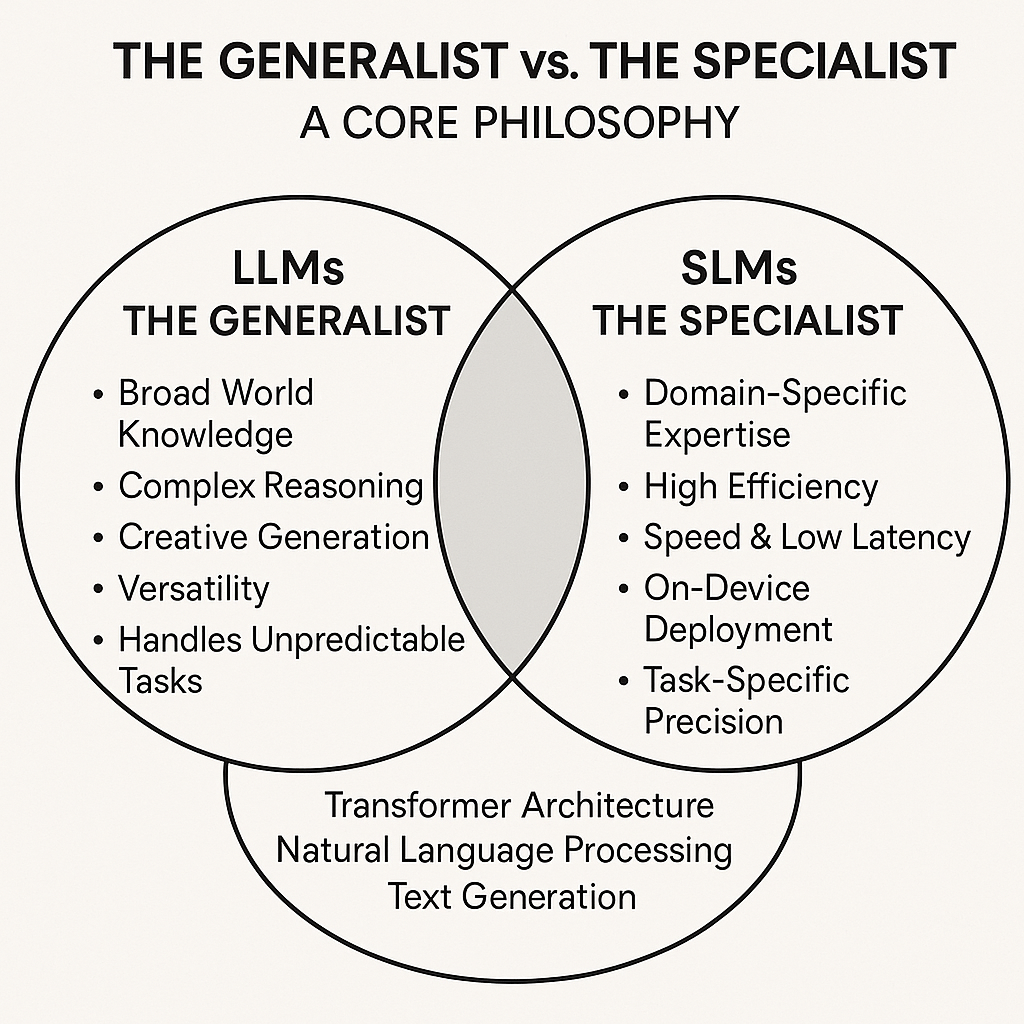
Visual comparison of LLM generalist approach versus SLM specialist focus
| Feature | Large Language Models (LLMs) | Small Language Models (SLMs) |
|---|---|---|
| Parameter Count | >70 Billion to 1 Trillion+ | <15 Billion |
| Training Data Scope | Broad, Internet-Scale (Trillions of tokens) | Narrow, Domain-Specific (Billions of tokens) |
| Core Philosophy | Generalist, Versatile, "Know Everything" | Specialist, Efficient, "Know One Thing Well" |
| Primary Strength | Complex Reasoning, Creativity, Generalization | Speed, Precision, Cost-Effectiveness |
| Typical Deployment | Cloud-based, Server-side | On-Device, Edge, On-Premise |
| Cost Profile | High Total Cost of Ownership (TCO) | Low Total Cost of Ownership (TCO) |
1.3 The Data Divide: Internet-Scale Corpora vs. Curated, Domain-Specific Datasets
You are what you eat. For language models, training data shapes everything—capabilities, biases, knowledge boundaries, performance characteristics.
LLM Training Data: Feed an LLM the internet. That's not hyperbole—these models consume massive, diverse datasets measured in terabytes, containing trillions of tokens scraped from virtually every corner of human digital expression. Meta's Llama 3 digested over 15 trillion tokens from publicly available web content. GPT-4's training corpus includes websites, books, academic papers, code repositories, and more, creating a knowledge base that spans human civilization. This vast, eclectic diet produces the broad general knowledge and cross-domain understanding that makes LLMs so versatile, enabling them to discuss everything from ancient history to quantum mechanics without breaking stride.
SLM Training Data: Feed an SLM with surgical precision. These models train on smaller, carefully curated datasets tailored to specific domains and applications. This focused approach defines their specialist nature. Building a legal SLM? Train it on contracts, case law, and legal documentation. Developing a healthcare assistant? Feed it medical journals, clinical records, and pharmaceutical data. Creating an enterprise chatbot? Use internal company documents, support tickets, and product manuals. This domain-specific training allows SLMs to achieve exceptional accuracy and fluency in their particular field, understanding the jargon, context, and subtle nuances that generalists might miss.
Yet the boundary blurs at times. An SLM could theoretically train on internet-scale data but remain optimized architecturally for specific tasks, making it a specialist by design rather than by data limitation. Conversely, a smaller model trained for general purposes might better be described as a scaled-down LLM rather than a true, purpose-built SLM. These nuances underscore the real distinction: intent matters more than dataset size alone. The fundamental choice is versatility versus precision, flexibility versus focus, determined by architectural design, training methodology, and deliberate data curation strategies rather than simply by how many terabytes you can afford to process.
Section 3: The Economics of Operation: A Resource and Performance Benchmark
True cost extends far beyond initial training expenses. You need to understand ongoing operational economics, infrastructure demands, and real-world performance metrics across different deployment scenarios. Only then can you make informed decisions about which models to deploy and where.
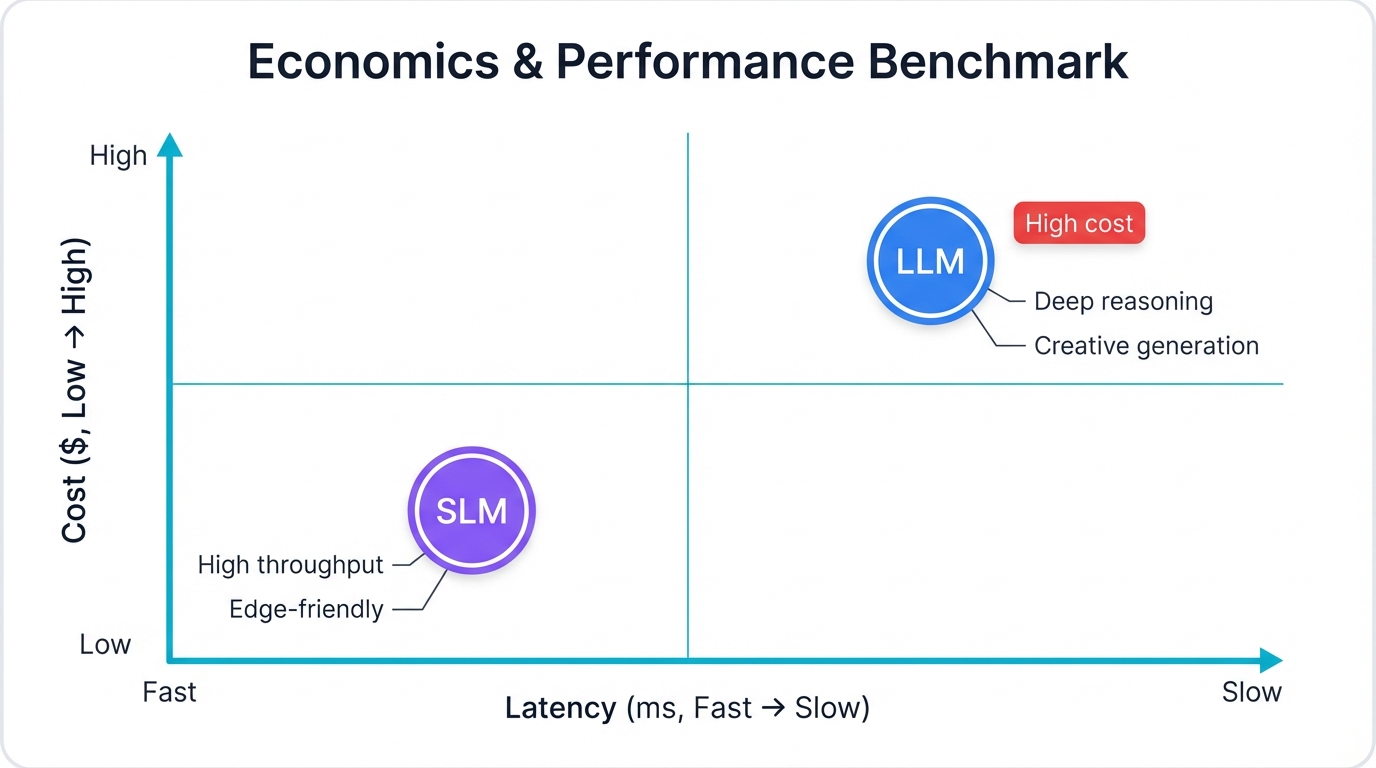
Training an LLM burns millions of dollars. Running one at scale? That's an ongoing expense that never stops. Massive GPU clusters, enormous energy consumption, specialized cooling infrastructure—these costs compound quickly. In contrast, SLMs operate lean and mean, running efficiently on modest hardware with minimal resource overhead. Speed tells another story: SLMs deliver responses in milliseconds while their larger cousins take seconds to think through complex queries. But speed isn't everything when you need deep reasoning or creative generation.
The performance equation depends entirely on your use case. Need broad knowledge? Want creative problem-solving? Require nuanced understanding? LLMs dominate. But if you're running thousands of queries per second on a focused task, SLMs deliver better performance per dollar, better latency, and better resource utilization. This isn't a simple winner-takes-all comparison—it's a strategic matching of capabilities to requirements, costs to budgets, and infrastructure to business needs.
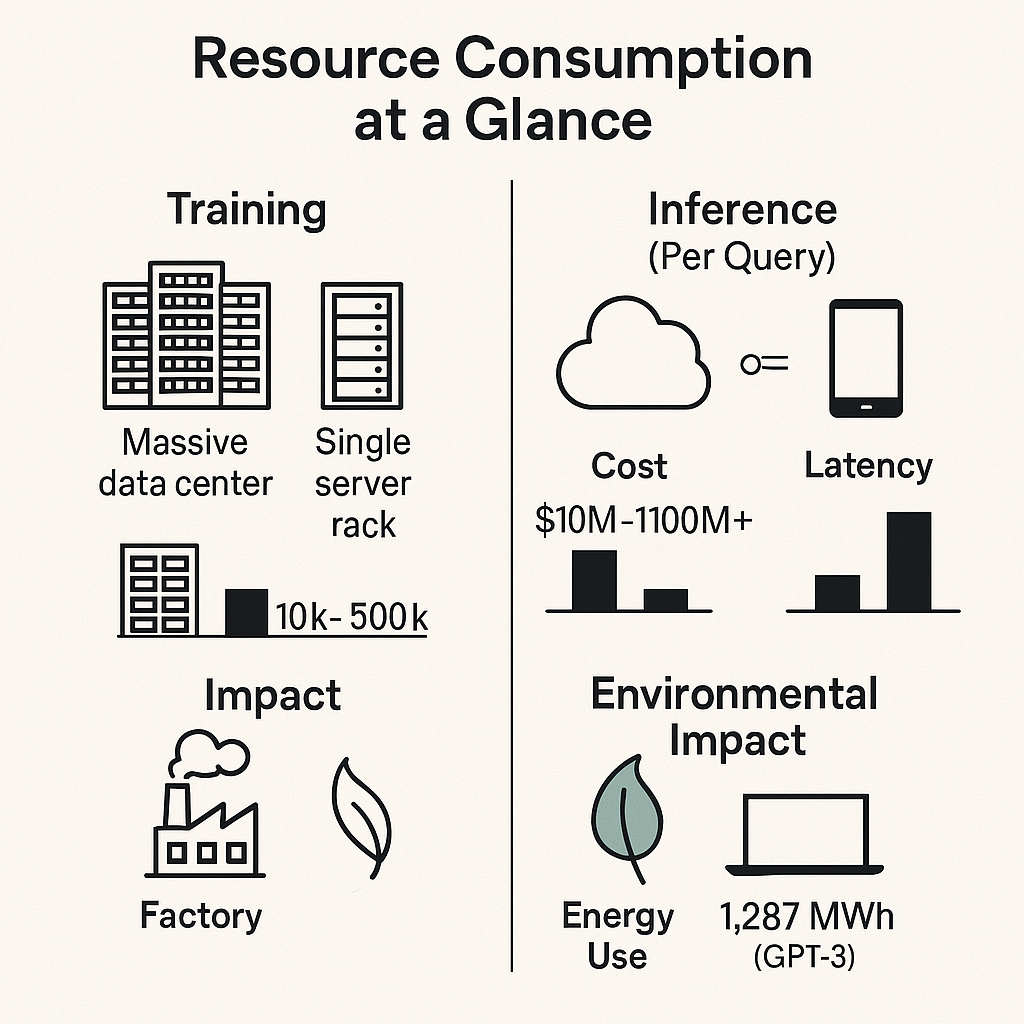
Economic analysis of resource consumption and performance metrics for LLMs vs SLMs
Section 4: Application Ecosystems and Optimal Use Cases
Deploying LLMs versus SLMs strategically means understanding where each architecture truly excels. Every model type has carved out distinct niches where its architectural advantages shine brightest. The question isn't which is better—it's which fits your specific needs.
LLMs thrive in complex, creative, and knowledge-intensive applications. Customer service requiring nuanced understanding? Content generation demanding originality? Code generation needing cross-language expertise? These are LLM territory. Their broad knowledge base and sophisticated reasoning make them ideal for tasks where flexibility matters more than raw speed.
SLMs dominate in focused, high-volume, latency-sensitive scenarios. Real-time translation? Sentiment analysis at scale? On-device assistance with privacy constraints? SLMs deliver the goods. Their efficiency and specialization make them perfect for applications where speed, cost, and precision trump versatility.
4.3 Hybrid Architectures: The Best of Both Worlds
The smartest implementations don't choose sides. They blend LLMs and SLMs in complementary roles, building hybrid architectures that maximize the strengths of each approach while mitigating individual weaknesses. This is where the real innovation happens.
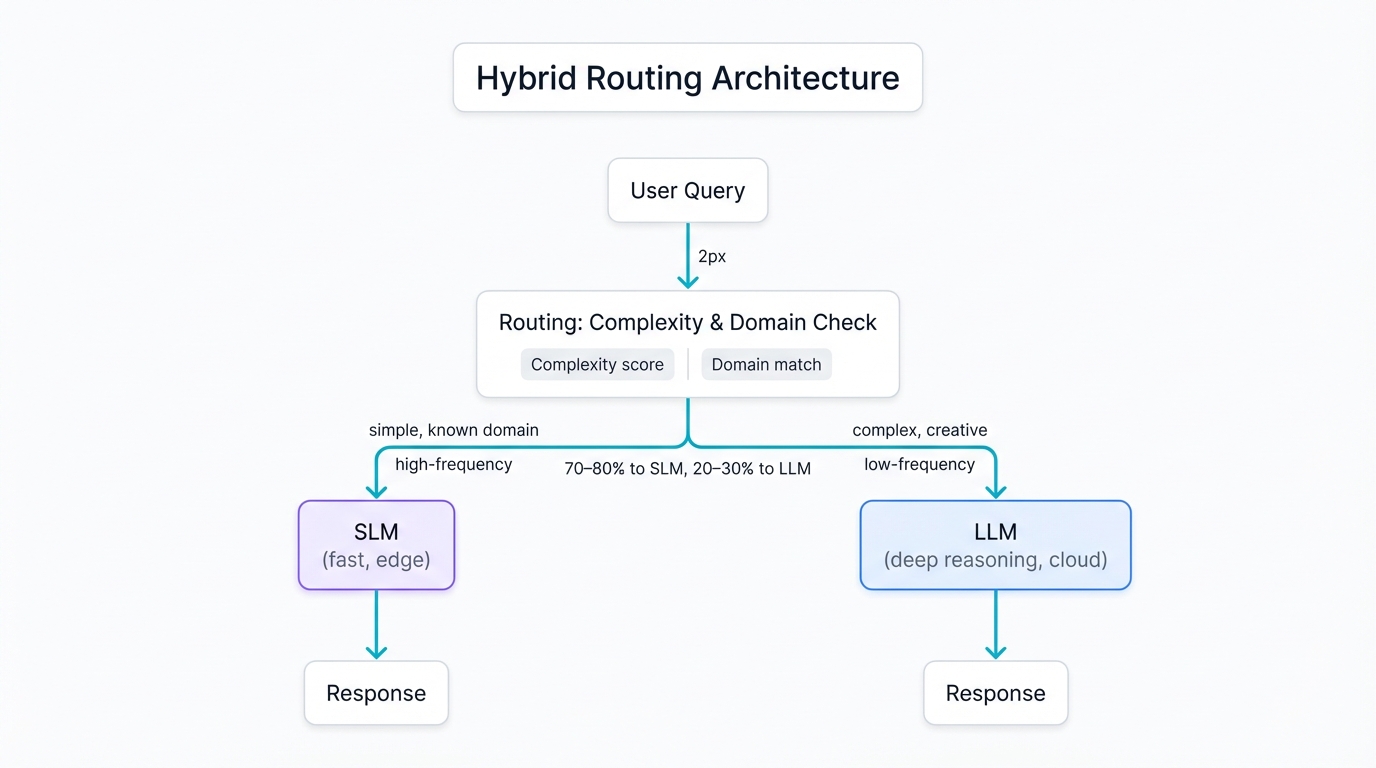
Picture this: SLMs handle the high-frequency, routine queries—answering FAQs, routing requests, performing quick analyses—running lean and fast on edge devices or modest infrastructure. When complexity strikes, when nuance matters, when creativity becomes essential, the system escalates to an LLM, bringing powerful reasoning to bear on the problem. This orchestration delivers intelligent efficiency: fast responses for simple tasks, deep intelligence for complex challenges.
Another pattern: LLMs generate creative content or perform complex reasoning, then SLMs take over for deployment and optimization, delivering the refined output at scale with minimal latency. Or consider domain-specific workflows where SLMs handle specialized knowledge areas while LLMs provide overarching coordination and integration across domains. These hybrid patterns represent the cutting edge of practical AI architecture, balancing cost, performance, and capability in ways that single-model approaches simply cannot match.
Architecture patterns showing optimal integration of LLMs and SLMs in hybrid deployments
Section 6: Strategic Recommendations for Enterprise Leverage
Enterprises navigating the language model landscape face a complex decision matrix. Success demands nuanced understanding of when and how to deploy different model types. The optimal strategy? It rarely involves exclusive commitment to either LLMs or SLMs.
Start by mapping your use cases. Which tasks demand broad knowledge and creative reasoning? Which need focused expertise and blazing speed? Which must run on-device for privacy or latency reasons? This assessment reveals where each model type fits naturally.
Then consider your constraints. Budget limitations push toward SLMs. Privacy requirements favor on-premise or edge deployment with smaller models. But if your competitive advantage depends on cutting-edge intelligence and creative capabilities, LLM investment becomes strategic necessity rather than optional expense. The key is matching architectural choices to business priorities with brutal honesty about what you actually need versus what sounds impressive.
6.2 Implementing Hybrid Model Strategies
Enterprise AI's future lies not in choosing between LLMs and SLMs, but in orchestrating them effectively. Hybrid deployment delivers LLM intelligence where it matters while maintaining SLM efficiency for routine operations. This combination creates systems that are simultaneously powerful and practical.
Build routing intelligence into your architecture. Queries arrive, and your system immediately assesses complexity, domain, urgency, and user context. Simple questions hit SLMs for instant responses. Complex reasoning escalates to LLMs for deeper analysis. This dynamic allocation maximizes responsiveness while controlling costs. Some organizations report 70-80% of queries handled efficiently by SLMs, with LLMs reserved for the 20-30% requiring advanced capabilities—dramatically reducing infrastructure costs while maintaining high-quality user experiences.
Layer your models by function. SLMs handle specialized domains—legal, medical, financial—delivering expert precision within their areas. LLMs coordinate across domains, synthesizing insights and handling cross-functional reasoning. This division of labor mirrors how organizations structure human expertise, and it works just as effectively for artificial intelligence.
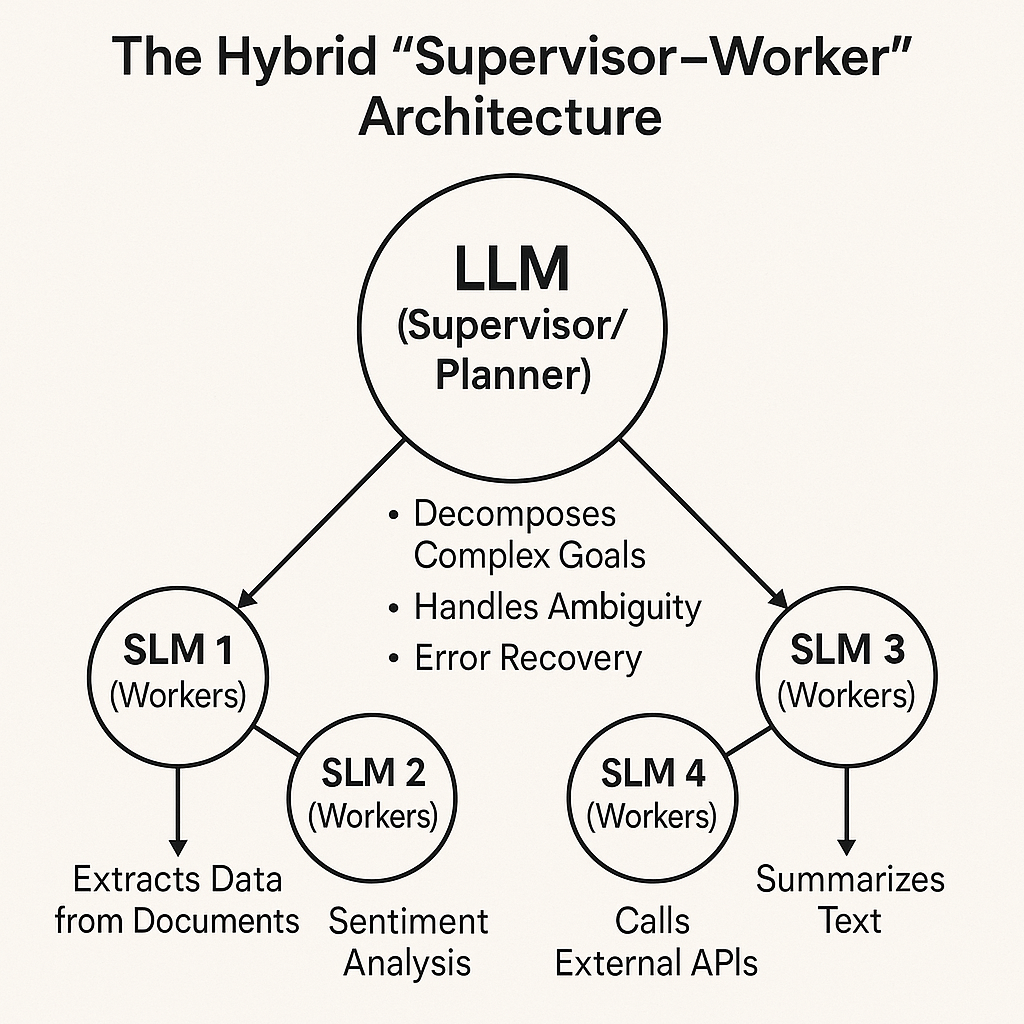
Strategic framework for implementing hybrid LLM-SLM deployments in enterprise environments
Conclusion
Best Practice: Following these recommended practices will help you achieve optimal results and avoid common pitfalls.
Language models have opened doors to unprecedented AI capabilities across every sector imaginable. But viewing Large Language Models and Small Language Models as rivals misses the point entirely. Forward-thinking enterprises recognize them as complementary tools in a comprehensive intelligence strategy.
LLMs provide foundational intelligence. Creative breakthroughs. Complex reasoning. These capabilities drive innovation and handle challenges that demand deep understanding. SLMs bring efficiency. Specialization. Deployability at scale. These characteristics enable widespread, cost-effective AI integration throughout your operations. Together, they let you build robust, scalable systems that balance performance against cost, power against practicality, breadth against depth.
The AI-driven future belongs to organizations that master model orchestration—knowing when to deploy LLM firepower and when SLM precision delivers better results. This strategic approach to language model deployment will separate leaders from followers in an increasingly AI-powered world. The question isn't whether to adopt AI. It's how intelligently you can blend these complementary technologies to create competitive advantage that compounds over time, building intelligence infrastructure that evolves with your business and adapts to challenges you haven't even imagined yet.
