Table of Contents
- Executive Summary
- Part 1: The AI Infrastructure Threat Landscape
- Part 2: Network Security Architecture for ML Workloads
- Part 3: Container Escape Vulnerabilities and GPU Isolation
- Part 4: Identity and Access Management for AI Workloads
- Part 5: Storage and Secrets Management
- Part 6: ML Platform-Specific Vulnerabilities
- Part 7: Detecting and Preventing GPU Cryptojacking
- Part 8: Supply Chain Security for ML Frameworks
- Part 9: Security Tool Comparison and Selection
- Part 10: Real-World Incident Analysis
- Part 11: Comprehensive Hardening Checklist
- Part 12: The Future of AI Infrastructure Security
- Conclusion
Executive Summary
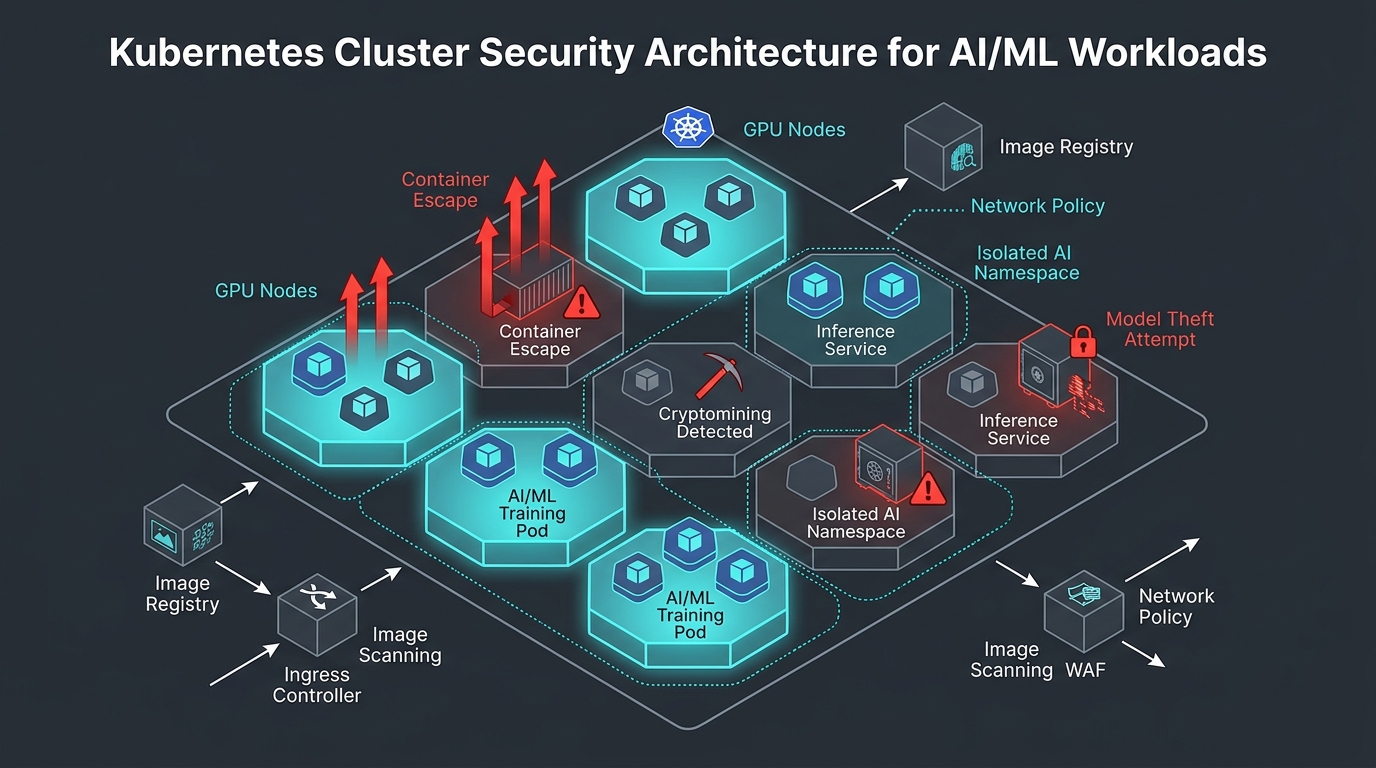
Your Kubernetes cluster just became the most valuable target in your infrastructure. Why? Because you loaded it with GPUs running AI workloads worth millions in compute costs and intellectual property.
In July 2025, attackers achieved container escape against NVIDIA GPU infrastructure using just three lines in a Dockerfile. The vulnerability—nicknamed "NVIDIAScape"—affected 37% of cloud GPU environments. Once inside, attackers accessed AI model weights, stole training datasets, and compromised shared GPU infrastructure across entire data centers.
This wasn't an isolated incident. Cloud attacks increased 154% year-over-year, with adversaries moving from initial access to impact in just 10 minutes. LLMjacking attacks—where criminals hijack GPU resources for unauthorized AI workloads—cost victims over $100,000 per day when left unchecked. One compromised Ray cluster racked up a $300,000 monthly cloud bill before anyone noticed.
The convergence of Kubernetes and AI creates a perfect storm. GPU nodes present unique vulnerabilities. Model artifacts represent high-value intellectual property. ML frameworks introduce new attack vectors through pre-trained models and complex dependencies. Traditional cloud security doesn't address these risks.
This guide provides battle-tested hardening configurations for ML infrastructure. You'll learn how to defend against container escapes, isolate GPU resources, protect model serving endpoints, and detect cryptojacking attacks before they drain your budget. Every configuration example comes from real incidents analyzed between 2023 and 2025.
The stakes are clear: the average cloud breach costs $5.17 million according to IBM's 2024 data. For AI infrastructure specifically, that number climbs higher due to the value of proprietary models and training data. Security isn't optional—it's survival.
Part 1: The AI Infrastructure Threat Landscape
Why Attackers Target AI Clusters
Kubernetes clusters running AI workloads attract sophisticated threat actors for three reasons: expensive compute resources, valuable intellectual property, and immature security controls.
GPU compute costs money. Real money. An NVIDIA H100 instance on AWS costs over $30 per hour. Attackers who compromise these resources can either mine cryptocurrency at your expense or resell compute capacity on underground markets. The financial incentive is massive—one documented cryptojacking campaign generated $22,000 per day in victim costs according to Sysdig research.
Your models represent years of research investment. A trained large language model embodies millions of dollars in compute costs, proprietary datasets, and algorithmic innovations. Competitors or nation-state actors who steal these models skip years of development. Model extraction isn't theoretical—it happens regularly against production inference endpoints.
The ML ecosystem moves fast, prioritizing innovation over security. Frameworks like Ray, MLflow, and Kubeflow ship with authentication disabled by default. Data scientists need flexibility to experiment, so organizations grant permissive access. This creates an attack surface that traditional security teams don't understand or monitor effectively.
The Numbers Tell the Story
Red Hat's 2024 State of Kubernetes Security report surveyed 600 professionals and found troubling patterns. 67% of organizations delayed deployments due to security concerns. 46% experienced revenue or customer loss from container security incidents. 45% had runtime security incidents in the past 12 months.
The financial impact is severe. IBM's 2024 Cost of a Data Breach Report pegged the average breach at $5.17 million globally, but U.S. organizations face average costs of $10.22 million. Ransomware incidents—often starting with cryptojacking or initial access through exposed services—cost an average of $5.08 million.
For AI workloads specifically, the attack timeline is frighteningly short. Sysdig's 2024 Global Cloud Threat Report found that 70% of containers live less than 5 minutes, yet automated attackers deploy 500+ cryptomining instances in 20 seconds. You won't catch this through manual monitoring.
The ML-Specific Attack Surface
AI workloads expand the Kubernetes attack surface in ways that traditional web applications don't. GPU drivers run with elevated privileges. ML frameworks execute arbitrary Python code submitted by users. Model files contain serialized code that runs during deserialization. Vector databases store high-dimensional embeddings that represent valuable training data.
The supply chain attack surface is particularly concerning. When you load a pre-trained model from Hugging Face or another registry, you're essentially executing arbitrary code. PyTorch's standard serialization format uses Python's pickle module, which was never designed for untrusted data. A malicious model can contain embedded payloads that execute the moment you call torch.load().
Protect AI's Guardian service scanned 4.47 million model versions on Hugging Face and discovered 352,000 security issues across 51,700 models. JFrog identified approximately 100 models with active code execution payloads. This is the ML equivalent of downloading and running random executables from the internet—except it's considered standard practice.
The edge deployment model compounds these risks. AI workloads increasingly run on edge clusters in retail locations, manufacturing floors, or vehicles. These clusters lack the physical security of centralized data centers but require access to the same model registries, secrets management systems, and observability infrastructure. A compromised edge cluster becomes a pivot point into your core infrastructure.
Part 2: Network Security Architecture for ML Workloads
Default-Deny Network Policies Are Non-Negotiable
Most Kubernetes clusters ship with permissive networking. Any pod can talk to any other pod. This flat network becomes a highway for lateral movement after initial compromise. Attackers who breach a single Jupyter notebook can scan your entire cluster, enumerate services, and pivot to high-value targets.
The solution is zero-trust networking with explicit allowlists. Start with a default-deny policy that blocks all ingress and egress traffic in ML namespaces:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
namespace: ml-workloads
spec:
podSelector: {}
policyTypes:
- Ingress
- EgressThis policy applies to all pods in the namespace (empty podSelector matches everything). It denies all ingress and egress by default. Pods won't be able to communicate with anything until you explicitly allow it.
Now build targeted policies for each workload type. Training workloads need egress access to model registries and object storage but should never reach cloud metadata services—a common attack pivot point:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ml-training-policy
namespace: ml-training
spec:
podSelector:
matchLabels:
workload: training
policyTypes:
- Ingress
- Egress
egress:
# Allow HTTPS to model registry
- to:
- namespaceSelector:
matchLabels:
name: model-registry
ports:
- port: 443
# Allow DNS resolution
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- port: 53
protocol: UDP
# Allow internal network but block metadata service
- to:
- ipBlock:
cidr: 10.0.0.0/8
except:
- 169.254.169.254/32 # AWS metadata serviceThe metadata service block is critical. AWS, GCP, and Azure all expose instance metadata at 169.254.169.254. This endpoint provides temporary credentials, environment details, and often secret values. Blocking access prevents attackers from escalating privileges even if they compromise a pod.
The IngressNightmare Vulnerability
In March 2025, researchers disclosed "IngressNightmare"—a critical vulnerability in Ingress-NGINX that affected 43% of cloud environments. CVE-2025-1974 received a CVSS score of 9.8 for good reason: attackers achieved unauthenticated remote code execution via crafted AdmissionReview requests.
The attack worked like this. Ingress-NGINX includes an admission webhook that validates ingress configurations. This webhook processes AdmissionReview requests from the Kubernetes API server. Attackers who could reach the webhook endpoint sent malicious payloads that triggered code execution in the controller. Once inside the controller, they accessed all cluster secrets since the controller runs with broad RBAC permissions.
ML inference endpoints exposed through Ingress-NGINX were particularly vulnerable. These endpoints often process sensitive data and connect to production databases. A compromised ingress controller provides access to all traffic flowing through it—including API keys, authentication tokens, and model predictions.
The fix requires upgrading to Ingress-NGINX v1.11.5+ or v1.12.1+. You also need to restrict admission webhook network access. Create a NetworkPolicy that only allows the Kubernetes API server to reach webhook endpoints:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: webhook-protection
namespace: ingress-nginx
spec:
podSelector:
matchLabels:
app.kubernetes.io/component: controller
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
component: kube-apiserver
ports:
- port: 8443Layer 7 Network Policies for Model API Protection
Traditional NetworkPolicies operate at Layer 4 (TCP/UDP ports). They can't inspect HTTP methods, paths, or headers. This limitation matters for ML inference APIs where you need granular control over which endpoints clients can access.
Cilium provides Layer 7 network policies that understand application protocols. You can restrict access to specific API paths and require authentication headers:
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: ml-inference-api-policy
spec:
endpointSelector:
matchLabels:
app: inference-server
ingress:
- toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: "POST"
path: "/v1/predict"
headers:
- 'X-API-Key: "[a-zA-Z0-9]+"'This policy only allows POST requests to /v1/predict with a valid API key header. Attempts to access other endpoints or use GET requests get blocked. This prevents attackers from enumerating model metadata endpoints or accessing administrative functions.
The regex pattern [a-zA-Z0-9]+ validates that an API key is present but doesn't verify its correctness—that's the application's job. This approach stops unauthenticated scanning while letting your application handle actual authentication.
Part 3: Container Escape Vulnerabilities and GPU Isolation
The NVIDIAScape Container Escape
July 2025 brought the wake-up call the AI industry needed. Security researchers at Wiz discovered CVE-2025-23266, a critical container escape vulnerability in the NVIDIA Container Toolkit. The exploit required just three lines in a Dockerfile. The impact? Full root access to host machines from malicious containers.
The vulnerability exploited how the toolkit handles OCI (Open Container Initiative) hooks. When Kubernetes schedules a pod requesting GPU access, the NVIDIA toolkit executes hooks to mount driver libraries and device files into the container namespace. These hooks run with elevated privileges on the host.
Attackers crafted containers with malicious environment variables targeting the LD_PRELOAD mechanism. This Linux feature instructs the dynamic linker to load specific shared object libraries before any others. By setting LD_PRELOAD to point to a malicious library included in the container image, attackers forced the privileged NVIDIA hook process—running as root on the host—to execute their code.
The exploit looked like this:
FROM nvidia/cuda:12.0-base
COPY poc.so /tmp/poc.so
ENV LD_PRELOAD=/tmp/poc.soWhen this container started on a GPU node, the toolkit's hook process loaded poc.so with root privileges before executing its normal operations. Game over. Attackers gained full host access, could read GPU memory from other tenants, install persistent rootkits, or modify the kernel.
Critical Patch Required: The vulnerability affected Container Toolkit versions before v1.17.8 and GPU Operator versions before v25.3.1. If you're running GPU nodes and haven't upgraded, you're vulnerable. Proof-of-concept code circulated within hours of disclosure.
Earlier NVIDIA Toolkit Vulnerabilities
NVIDIAScape wasn't the first critical NVIDIA container escape. CVE-2024-0132 (CVSS 9.0) disclosed in September 2024 exploited a time-of-check time-of-use (TOCTOU) race condition. Attackers crafted container images that swapped files during the toolkit's validation process, achieving container escape.
These vulnerabilities represent a systemic risk to AI infrastructure. The NVIDIA Container Toolkit is foundational—all major cloud providers use it to enable GPU access in containers. When it's compromised, the entire AI ecosystem is exposed.
The runc container runtime faced similar issues. CVE-2024-21626, nicknamed "Leaky Vessels," achieved a CVSS score of 8.6 and affected 80% of cloud environments. Ransomware groups including RansomHub and Akira actively exploited this vulnerability. Organizations running runc versions before 1.1.12 (or 1.2.8+ for later releases) remain vulnerable to container escape attacks.
GPU Isolation: Hardware vs. Software Approaches
When multiple users share GPU resources, you face a fundamental security question: how do you isolate their workloads? The answer determines whether a compromised pod can access another tenant's model weights or training data.
Time-slicing is the most common approach because it's easy to configure. The GPU driver schedules multiple CUDA processes on the same physical cores, switching between them rapidly. From the user's perspective, everyone gets GPU access.
From a security perspective, time-slicing provides zero isolation. All processes share the same physical hardware and memory. They share the same address space. A memory scraping attack could potentially read data from other tenants' workloads. A malformed CUDA kernel could crash the driver and deny service to all other users.
Time-slicing is acceptable for trusted environments—a single team's development cluster where all users trust each other. It's not acceptable for multi-tenant production environments or any scenario where workloads process sensitive data.
Multi-Instance GPU (MIG) provides hardware-enforced isolation on NVIDIA A100, H100, and H200 GPUs. MIG partitions a single physical GPU into up to seven independent instances. Each instance gets dedicated streaming multiprocessors, L2 cache, and high-bandwidth memory.
The key word is "dedicated." MIG instances have separate memory address spaces. A workload on one instance cannot address or access memory on another instance. This prevents memory scraping attacks. Each instance also has independent error isolation—if one workload crashes, it doesn't affect others.
MIG configuration requires defining partition profiles:
apiVersion: v1
kind: ConfigMap
metadata:
name: mig-config
namespace: gpu-operator
data:
config.yaml: |
version: v1
mig-configs:
all-balanced:
- devices: all
mig-enabled: true
mig-devices:
"1g.10gb": 2 # Two 10GB instances
"2g.20gb": 1 # One 20GB instance
"3g.40gb": 1 # One 40GB instanceThis configuration splits each GPU into multiple instances of different sizes. The trade-off is static partitioning—reconfiguring MIG slices requires draining the node and resetting the GPU. You can't dynamically adjust allocations based on demand. Plan your partition strategy carefully based on workload patterns.
The security recommendation is clear: use MIG for any multi-tenant production environment. Reserve time-slicing for single-tenant development clusters or batch inference workloads where security isolation matters less than cost efficiency.
| Sharing Method | Memory Isolation | Fault Isolation | Production Suitability |
|---|---|---|---|
| MIG (Multi-Instance GPU) | Hardware-enforced | Yes | Recommended |
| vGPU | IOMMU-protected | Yes | Recommended |
| Time-Slicing | None | None | Development only |
| MPS (Multi-Process Service) | Software limits | Limited | Single-tenant only |
Pod Security Standards for ML Workloads
The CIS Kubernetes Benchmark mandates restricted Pod Security Standards for production workloads. ML environments need these restrictions even more than traditional applications because of privileged access to expensive hardware.
Apply Pod Security Standards at the namespace level:
apiVersion: v1
kind: Namespace
metadata:
name: ml-production
labels:
pod-security.kubernetes.io/enforce: restricted
pod-security.kubernetes.io/enforce-version: latest
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/warn: restrictedThe enforce label blocks pod creation that violates the restricted profile. The audit and warn labels log violations without blocking—useful during migration.
ML training pods should implement comprehensive security contexts:
apiVersion: v1
kind: Pod
metadata:
name: ml-training-job
spec:
securityContext:
runAsNonRoot: true
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
seccompProfile:
type: RuntimeDefault
containers:
- name: trainer
image: ml-training:v1.0
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
resources:
limits:
nvidia.com/gpu: 1
memory: "32Gi"
requests:
nvidia.com/gpu: 1
memory: "16Gi"Let's break down what each setting accomplishes:
runAsNonRoot prevents the container from running as the root user. This limits damage from container escape vulnerabilities.
allowPrivilegeEscalation: false blocks processes from gaining additional privileges. Combined with dropping all capabilities, this severely limits what attackers can do even if they compromise the container.
readOnlyRootFilesystem makes the container's root filesystem immutable. Attackers can't install malware or modify binaries. Training jobs that need writable space should use emptyDir volumes explicitly mounted at specific paths.
seccompProfile: RuntimeDefault applies a seccomp filter that blocks dangerous system calls. This provides defense-in-depth against kernel exploits.
These restrictions don't interfere with normal ML workloads. TensorFlow, PyTorch, and other frameworks work fine in restricted containers. What they do prevent is the kind of post-exploitation activities attackers rely on—installing backdoors, modifying system files, or escalating privileges.
Part 4: Identity and Access Management for AI Workloads
RBAC Segmentation for ML Teams
Machine learning teams have different roles with different security requirements. Data scientists experimenting with models need different permissions than ML engineers deploying production inference services. Your RBAC (Role-Based Access Control) model must reflect these distinctions.
Data scientists typically work in notebook environments like JupyterHub or VSCode running in Kubernetes pods. They need to create experiments, view logs, and access storage. They don't need cluster-level permissions or the ability to modify infrastructure.
Create a role scoped to experimental workspaces:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: data-scientist
namespace: ml-experiments
rules:
- apiGroups: [""]
resources: ["pods", "pods/log", "services"]
verbs: ["get", "list", "watch"]
- apiGroups: ["kubeflow.org"]
resources: ["notebooks", "experiments"]
verbs: ["get", "list", "watch", "create", "update", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "create"]This role allows data scientists to manage their notebooks and experiments but prevents them from accessing secrets, modifying network policies, or viewing resources in other namespaces. The principle of least privilege in action.
ML engineers deploying models to production need broader permissions but should remain namespace-scoped:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ml-engineer
namespace: ml-pipelines
rules:
- apiGroups: [""]
resources: ["pods", "services", "configmaps", "secrets"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
- apiGroups: ["kubeflow.org"]
resources: ["pipelines", "runs", "experiments"]
verbs: ["*"]
- apiGroups: ["serving.kserve.io"]
resources: ["inferenceservices"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]This role grants full access to ML-specific resources within the namespace. Engineers can deploy inference services, manage secrets for API keys, and operate Kubeflow pipelines. But they can't modify cluster-wide resources like nodes, NetworkPolicies, or RBAC itself.
The JupyterHub Privilege Escalation Risk
JupyterHub became the de facto notebook environment for data science teams. It's also a security nightmare when misconfigured.
CVE-2024-35225 allowed users with the admin:users scope to escalate to full administrator privileges. This vulnerability affected JupyterHub versions through 4.x and all 5.x versions before 5.1.0. Combined with common misconfigurations—Jupyter running as root with disabled authentication—attackers gained direct shell access to ML infrastructure.
Think about what a compromised Jupyter environment provides. Data scientists routinely paste API keys into notebooks for services like Hugging Face, Weights & Biases, or cloud storage. They load datasets containing sensitive information. They train models that embody proprietary research. A compromised notebook is a goldmine.
Secure JupyterHub deployments require explicit hardening:
hub:
config:
JupyterHub:
admin_access: false # Prevent admins from accessing user notebooks
authenticator_class: oauthenticator.GitHubOAuthenticator
singleuser:
serviceAccountName: jupyter-user-sa # Dedicated service account
extraPodConfig:
securityContext:
runAsNonRoot: true
runAsUser: 1000 # Non-root user
networkPolicy:
enabled: true
egressAllowRules:
dnsPortsCloudMetadataServer: false # Block metadata service
rbac:
enabled: true # Never disable RBACThe admin_access: false setting is critical. By default, JupyterHub admins can access any user's notebook. This creates insider threat risks and compliance issues. Disable this unless you have specific auditing requirements.
The network policy blocking the metadata service prevents credentials theft. A compromised notebook shouldn't be able to pivot to cloud resources by stealing temporary credentials from the metadata endpoint.
Always use external authentication (OAuth via GitHub, Google, or your corporate SSO) rather than simple password authentication. This provides audit trails and lets you revoke access centrally when employees leave.
Part 5: Storage and Secrets Management
Why Kubernetes Secrets Aren't Secure
Kubernetes stores secrets in etcd, the cluster's backing data store. The data is base64 encoded. Base64 is not encryption—it's encoding. Anyone with etcd access or RBAC permissions to read secrets can decode them trivially:
kubectl get secret model-registry-secret -o jsonpath='{.data.password}' | base64 -dFor ML workloads, this matters more than for traditional applications. AI pipelines rely on numerous external services: model registries, cloud storage, vector databases, observability platforms, API keys for commercial LLM providers. Each requires credentials. Storing all of these in Kubernetes secrets creates a single point of failure.
Two critical CVEs demonstrate the risk. CVE-2023-2878 exposed tokens in secret store CSI driver logs—secrets appeared in plain text in pod logs visible to anyone with log access. CVE-2023-2728 allowed attackers to bypass mountable secrets policies, accessing secrets they shouldn't have permission to read.
The solution is external secrets management. Store actual secrets in dedicated vaults (AWS Secrets Manager, HashiCorp Vault, Azure Key Vault) and sync them into Kubernetes only when needed.
External Secrets Operator
The External Secrets Operator (ESO) creates a bridge between external vaults and Kubernetes. You define an ExternalSecret resource that references a secret in your vault. ESO authenticates to the vault, retrieves the secret, and creates a standard Kubernetes Secret that your pods can consume.
For a model registry requiring authentication:
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: model-registry-credentials
namespace: ml-pipelines
spec:
refreshInterval: 1h # Sync every hour
secretStoreRef:
name: vault-backend
kind: ClusterSecretStore
target:
name: model-registry-secret
creationPolicy: Owner
data:
- secretKey: registry-username
remoteRef:
key: ml/model-registry
property: username
- secretKey: registry-password
remoteRef:
key: ml/model-registry
property: passwordThis manifest contains no sensitive data. You can commit it to Git safely. The actual credentials live in Vault where they're encrypted, access-controlled, and audited.
When you need to rotate credentials (after a suspected compromise or as regular hygiene), you update the secret in Vault. ESO automatically syncs the new value into Kubernetes. Depending on your configuration, you can trigger pod restarts to pick up the new credentials or let applications reload them dynamically.
ESO supports multiple backend vaults simultaneously. You might use AWS Secrets Manager for production workloads, HashiCorp Vault for development, and Azure Key Vault for hybrid deployments. A single ESO installation can sync from all of them.
Persistent Volume Security for Model Artifacts
ML workloads are stateful. Training jobs read datasets from persistent volumes. Model serving loads weights from shared storage. This heavy reliance on persistent volumes creates security challenges.
CVE-2023-5528 demonstrated a critical flaw: users who could create pods and PersistentVolumes on Windows nodes could escalate to administrator privileges. The vulnerability exploited how the kubelet handled volume mounts, allowing attackers to write to host filesystem paths they shouldn't access.
The mitigation involves two strategies. First, migrate to Container Storage Interface (CSI) drivers which provide better isolation than legacy volume plugins. Second, restrict PersistentVolume creation through RBAC and ResourceQuotas:
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-quota
namespace: ml-training
spec:
hard:
persistentvolumeclaims: "10" # Max 10 PVCs
requests.storage: "500Gi" # Max 500GB totalThis quota prevents users from creating unlimited storage volumes—both a security and cost control measure. Attackers who compromise a pod can't exfiltrate your entire data lake by creating a massive PVC and copying everything to it.
For sensitive model weights, consider encryption at rest using the CSI driver's encryption capabilities. Most cloud providers' CSI drivers (AWS EBS CSI, GCE PD CSI) support encryption using cloud KMS. This ensures stolen storage volumes can't be mounted and read on attacker-controlled infrastructure.
Part 6: ML Platform-Specific Vulnerabilities
Kubeflow Cryptojacking Campaigns
Kubeflow became the standard for ML pipeline orchestration. Its comprehensive platform handles everything from notebook environments to distributed training to model serving. It's also a frequent target for cryptojacking attacks.
Microsoft documented multiple campaigns where attackers specifically targeted internet-exposed Kubeflow dashboards. The attack pattern was consistent: scan for Kubeflow installations exposed via Ingress with authentication disabled, gain access to the dashboard, deploy cryptomining workloads.
The miners were sophisticated. Attackers deployed two pod types per compromised cluster—one for CPU mining (XMRig targeting Monero) and one for GPU mining (Ethminer targeting Ethereum). They used legitimate TensorFlow images to avoid detection by simple container image scanning. The mining pods ran on all available nodes using DaemonSets to maximize resource utilization.
Microsoft's report mentioned "tens" of clusters compromised in a single campaign. The financial impact on victims was severe—GPU mining consumes massive electricity and generates substantial cloud bills. One documented incident resulted in a $300,000 monthly cost spike.
Kubeflow hardening requires network isolation and authentication. Use Istio's authorization policies to restrict access:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: kubeflow-authz
namespace: kubeflow
spec:
selector:
matchLabels:
app: ml-pipeline
rules:
- from:
- source:
principals: ["cluster.local/ns/kubeflow/sa/pipeline-runner"]
- to:
- operation:
methods: ["GET", "POST"]
paths: ["/apis/v1beta1/*"]This policy requires authenticated service accounts for pipeline operations. Only the pipeline-runner service account can execute pipelines. Users must authenticate through the API rather than having direct access to internal services.
Never expose Kubeflow dashboards directly to the internet. Use a VPN, a corporate network, or at minimum an authentication proxy like OAuth2 Proxy. The dashboard provides powerful capabilities—pipeline execution, notebook creation, model deployment. In unauthenticated hands, it's a cluster takeover tool.
MLflow Remote Code Execution
MLflow provides experiment tracking, model registry, and deployment capabilities. It's also shipped with multiple critical vulnerabilities that enable remote code execution.
CVE-2024-0520 achieved the rare CVSS 10.0 perfect score. The vulnerability allowed RCE via command injection in MLflow's HTTP dataset source. Attackers crafted malicious URLs containing shell commands. When MLflow parsed these URLs to fetch dataset metadata, it executed the embedded commands. All versions prior to 2.9.0 were vulnerable.
Three additional CVEs (CVE-2024-37056, CVE-2024-37057, CVE-2024-37060) with CVSS 8.8 enabled RCE through deserialization of untrusted data when loading models. This exploited MLflow's use of Python pickle for model serialization—the same unsafe format that enables "malicious model" attacks.
The broader lesson: never load untrusted models without sandboxing. When MLflow loads a model file, it deserializes Python objects. A malicious model can execute arbitrary code during this process. Treat model files as you would executable binaries—verify their source, scan them for malicious content, and run them in isolated environments.
95% of malicious models on Hugging Face use PyTorch's pickle format according to security research. The solution is mandating safer serialization formats like Safetensors, which stores only tensor data without embedded code. Combine this with model signing (covered in the supply chain section) to verify provenance.
KServe Model Serving Hardening
KServe (formerly KFServing) provides serverless model serving on Kubernetes. Securing KServe deployments requires applying the same container security practices as other workloads:
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: sklearn-model
annotations:
sidecar.istio.io/inject: "true" # Istio sidecar for mTLS
spec:
predictor:
serviceAccountName: model-serving-sa # Dedicated service account
containers:
- name: kserve-container
image: kserve/sklearnserver:v0.10.0
securityContext:
runAsNonRoot: true
runAsUser: 1000
readOnlyRootFilesystem: true
allowPrivilegeEscalation: false
capabilities:
drop:
- ALLThe Istio sidecar injection enables mutual TLS between services, encrypting all traffic and verifying both parties' identities. This prevents man-in-the-middle attacks where attackers intercept model predictions to steal data or reverse-engineer models.
The dedicated service account limits what the inference pod can access. Create a service account with minimal permissions—just enough to read model artifacts from storage and push metrics to observability systems. Don't reuse the default service account which often has excessive permissions.
Part 7: Detecting and Preventing GPU Cryptojacking
The TeamTNT Hildegard Campaign
The Hildegard malware campaign by TeamTNT demonstrated the sophistication of Kubernetes-native attacks. The attackers didn't just compromise individual containers—they understood Kubernetes architecture and exploited it systematically.
The attack chain started with exposed Kubelet APIs (the node agent that manages containers). The Kubelet API, when exposed without authentication, allows complete control over pods on that node. Attackers scanned for exposed Kubelets, gained access, and deployed their initial payload.
From there, Hildegard deployed cryptominers as DaemonSets. This Kubernetes primitive ensures a pod runs on every node in the cluster. By using a DaemonSet, attackers guaranteed their miners ran on all GPU nodes automatically, even as the cluster scaled.
The malware specifically installed NVIDIA drivers for enhanced GPU mining. It used legitimate deployment mechanisms—containers, DaemonSets, standard Kubernetes resources. This allowed it to persist across pod restarts and node replacements. Traditional antivirus wouldn't detect it because everything ran in containers using standard images.
Sysdig's analysis estimated the campaign cost victims $22,000 per day in compute costs at peak. That number accounts for cloud instance costs but not opportunity costs—legitimate ML workloads couldn't access the GPUs because miners consumed all resources.
Runtime Detection with Falco
You can't prevent attacks through static configuration alone. Once attackers gain access, you need runtime detection to identify their activities before damage occurs.
Falco is a CNCF graduated project that monitors system calls in real-time using eBPF. You define rules describing suspicious behaviors. Falco alerts when it observes matching activity.
For cryptomining detection:
- rule: Detect Cryptocurrency Mining Binary
desc: Detects execution of cryptocurrency mining binaries
condition: >
spawned_process and
(proc.name in (xmrig, minerd, cgminer, cpuminer) or
proc.cmdline contains "stratum+" or
proc.cmdline contains "mining.pool")
output: >
Cryptocurrency mining detected (user=%user.name
command=%proc.cmdline container=%container.name)
priority: CRITICALThis rule triggers on three indicators: known miner binary names (xmrig, minerd), the stratum protocol used to connect to mining pools (stratum+tcp or stratum+ssl), and references to mining pools in command arguments.
The beauty of eBPF-based detection is that it can't be evaded from userspace. Attackers can't disable Falco by modifying the container—the monitoring happens at the kernel level. Even if they rename their mining binary or use custom implementations, the stratum protocol detection still triggers.
For GPU-specific monitoring, alert on unexpected GPU access:
- rule: Unexpected GPU Access
desc: Container not labeled for GPU workload accessing GPU devices
condition: >
spawned_process and
(proc.name = "nvidia-smi" or
fd.name glob "/dev/nvidia*") and
not container.labels contains "gpu-workload=allowed"
output: >
Unauthorized GPU access (container=%container.name
command=%proc.cmdline)
priority: HIGHThis rule alerts when containers access NVIDIA devices unless they're explicitly labeled as GPU workloads. A web server pod suddenly accessing GPUs indicates compromise and cryptominer deployment.
GPU Utilization Anomaly Detection
Runtime behavioral detection complements signature-based rules. Use DCGM (Data Center GPU Manager) Exporter to expose GPU metrics to Prometheus, then create alerts for anomalous patterns:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: gpu-security-alerts
spec:
groups:
- name: gpu-security
rules:
- alert: UnauthorizedGPUActivity
expr: |
rate(DCGM_FI_DEV_GPU_UTIL{namespace!~"ml-prod|ml-staging"}[5m]) > 0.8
for: 15m
labels:
severity: critical
annotations:
summary: "High GPU utilization in non-ML namespace"
description: "GPU utilization over 80% for 15+ minutes in namespace {{ $labels.namespace }}"
- alert: AbnormalPowerConsumption
expr: DCGM_FI_DEV_POWER_USAGE > 350
for: 30m
labels:
severity: warning
annotations:
summary: "Abnormal GPU power consumption detected"The first alert triggers on sustained high GPU utilization in namespaces not designated for ML workloads. If your API namespace suddenly shows 80%+ GPU usage, something's wrong—probably cryptomining.
The power consumption alert detects GPUs running at full power for extended periods. A100 GPUs have a TDP (Thermal Design Power) of 400W. Sustained operation at 350W+ indicates either a very long training job or a cryptominer running continuously.
These alerts generate noise during normal training—high GPU utilization is expected. The key is correlation: high utilization in unexpected namespaces, at unexpected times, or without corresponding training job metadata in your ML platform suggests malicious activity.
Part 8: Supply Chain Security for ML Frameworks
Container Image Vulnerabilities in ML Stacks
ML framework containers carry substantial vulnerability burdens. These images combine multiple risk factors: large base images (often 5-10GB), complex dependency trees (hundreds of Python packages), and infrequently updated components.
Critical CVEs affect core frameworks:
- TensorFlow/Keras CVE-2024-3660 (CVSS 9.8): Arbitrary code execution via malicious model files loaded with
tf.saved_model.load() - PyTorch CVE-2025-32434 (CVSS 9.3): RCE in
torch.load()even when using the supposedly safeweights_only=Trueflag - TorchServe CVE-2023-43654 "ShellTorch" (CVSS 9.8): RCE via management API misconfiguration allowing unauthenticated model uploads
These vulnerabilities share a pattern: they exploit deserialization of untrusted data. ML frameworks need to save and load complex model architectures. They serialize model graphs, weights, and metadata into files. When loading these files, the deserialization process executes code—intentionally for legitimate models, maliciously for poisoned ones.
Protect AI's Guardian service scanned 4.47 million model versions on Hugging Face and found 352,000 security issues across 51,700 models. That's a 1.2% infection rate. If you're downloading models from public registries without scanning them, you have a 1 in 100 chance of deploying malware.
SBOM Generation for ML Artifacts
Software Bill of Materials (SBOM) generation is becoming mandatory for government contractors and regulated industries. For AI workloads, this extends beyond container images to model artifacts themselves.
SPDX 3.0.1 introduced AI/ML profiles for model and dataset metadata. CycloneDX supports ML-BOM (Machine Learning Bill of Materials) to document model dependencies, training data sources, and framework versions. These standards enable automated vulnerability tracking—when a new PyTorch CVE is disclosed, you can immediately identify which deployed models use vulnerable versions.
Generate SBOMs for ML training images:
# Generate SBOM for ML training image using Trivy
trivy image -f cyclonedx -o ml-training-sbom.json tensorflow/tensorflow:2.15.0-gpu
# Scan with severity threshold for CI/CD
trivy image --severity CRITICAL,HIGH --exit-code 1 my-registry/ml-training:latestThe --exit-code 1 flag causes Trivy to fail the build if critical or high-severity vulnerabilities are found. This prevents vulnerable images from reaching production. Your CI/CD pipeline should fail fast on security issues rather than deploying and hoping for the best.
For production readiness, scan images on a schedule even after deployment. New CVEs are disclosed constantly. An image that passed scanning last month might be critically vulnerable today. Set up continuous scanning with alerts when new vulnerabilities affect deployed images.
Image Signature Verification
Container image signing prevents tampering between build and deployment. An attacker who compromises your container registry could inject malicious images. Signature verification ensures images match what your CI/CD pipeline built.
Kyverno provides built-in image verification for Kubernetes:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: verify-ml-images
spec:
validationFailureAction: Enforce
rules:
- name: verify-signature
match:
any:
- resources:
kinds:
- Pod
verifyImages:
- imageReferences:
- "registry.company.com/ml/*"
attestors:
- entries:
- keys:
publicKeys: |-
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEZqJbX...
-----END PUBLIC KEY-----This policy intercepts pod creation. Before allowing the pod to start, Kyverno verifies that the image signature matches the provided public key. If verification fails—because the image wasn't signed, the signature is invalid, or the image was modified after signing—pod creation is blocked.
The imageReferences pattern allows you to apply different policies to different registries. You might require signatures for production images (registry.company.com/ml/prod/*) while allowing unsigned images in development namespaces.
Signature verification integrates with Cosign, part of the Sigstore project. Your CI/CD pipeline signs images during build:
# Sign image after build
cosign sign --key cosign.key registry.company.com/ml/training:v1.0
# Verify signature (Kyverno does this automatically)
cosign verify --key cosign.pub registry.company.com/ml/training:v1.0This creates an end-to-end chain of trust from source code to production deployment. Code goes through CI/CD, images get built and signed, signatures get verified at deployment. Attackers can't inject malicious images without access to the signing key.
Part 9: Security Tool Comparison and Selection
Runtime Security: Falco vs. Tetragon vs. Sysdig
Three runtime security tools dominate the Kubernetes security landscape. Your choice depends on your requirements for detection vs. enforcement, ease of deployment, and budget.
Falco is the CNCF graduated standard for runtime detection. It monitors system calls using eBPF and alerts on suspicious activity based on rules you define. Falco ships with 86+ rules covering common attack patterns, with Kubernetes-specific awareness built in. It can correlate container metadata with system calls—not just "process executed /bin/bash" but "process executed /bin/bash in production namespace ml-prod from container running as root."
Performance overhead is reasonable at 1-3% CPU, though this varies based on rule complexity and event volume. Falco focuses on detection, not prevention—it alerts when attacks occur but doesn't block them.
Tetragon, part of the Cilium project, provides enforcement capabilities. Like Falco, it uses eBPF for monitoring. Unlike Falco, it can synchronously block system calls before they complete. This enables real-time attack prevention.
For GPU security, Tetragon can block the LD_PRELOAD injection used in NVIDIAScape. Define a policy that inspects environment variables during process creation and kills processes with suspicious LD_PRELOAD values. The container escape attempt gets stopped before it reaches the privileged toolkit process.
Tetragon's enforcement comes with complexity trade-offs. Misconfigured blocking policies can break legitimate workloads. Test thoroughly in audit mode before enabling enforcement in production.
Sysdig Secure builds on Falco (it's the company that created and donated Falco to CNCF) and adds commercial features: managed detection, incident response workflows, ML-specific detection rules, and integrated vulnerability scanning. The pricing reflects these capabilities—significantly more expensive than self-managed Falco.
| Tool | Type | ML Capabilities | Overhead | Cost |
|---|---|---|---|---|
| Falco | CNCF Graduated | 86 rules, K8s-aware, custom GPU rules | ~1-3% CPU | Free (OSS) |
| Tetragon | Cilium/CNCF | eBPF enforcement, real-time blocking | Lower than Falco | Free (OSS) |
| Sysdig Secure | Commercial | Built on Falco, ML-specific detections | Variable | $$$ |
Policy Engines: OPA/Gatekeeper vs. Kyverno
Policy enforcement at the API level prevents misconfigurations before they reach your cluster. Two CNCF projects compete in this space with different philosophies.
OPA (Open Policy Agent) with Gatekeeper uses the Rego policy language. Rego is powerful and flexible—you can express complex logic with precise conditions. This power comes with a steep learning curve. Rego looks nothing like YAML or any language your Kubernetes administrators already know.
Kyverno uses native YAML for policy definitions. If you can write Kubernetes manifests, you can write Kyverno policies. This dramatically reduces adoption friction. Teams start enforcing policies within hours rather than spending weeks learning Rego.
For ML-specific policies like requiring GPU limits, Kyverno's YAML syntax is straightforward:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-gpu-limits
spec:
validationFailureAction: Enforce
rules:
- name: check-gpu-limits
match:
any:
- resources:
kinds:
- Pod
namespaces:
- ml-training
- model-inference
validate:
message: "GPU resource limits required for ML workloads"
pattern:
spec:
containers:
- resources:
limits:
nvidia.com/gpu: "?*"This policy blocks pod creation in ML namespaces unless the pod requests GPU resources with limits. The ?* pattern means "any value must be present." It prevents pods from requesting unlimited GPU resources or forgetting to specify limits entirely.
Kyverno also handles image verification (shown earlier), mutation (automatically adding labels or security contexts), and generation (creating default NetworkPolicies for new namespaces). This makes it a comprehensive policy solution rather than just admission control.
| Tool | Policy Language | Image Verification | CNCF Status | Learning Curve |
|---|---|---|---|---|
| OPA/Gatekeeper | Rego (complex) | Via external tools | Graduated | High |
| Kyverno | Native YAML | Built-in | Incubating | Low |
Recommendation: Start with Kyverno for ease of adoption. If you encounter policy requirements that Kyverno can't express (rare), supplement with Gatekeeper for those specific policies. You can run both simultaneously.
Part 10: Real-World Incident Analysis
The Ray Framework Exploitation Campaigns
Between 2023 and 2025, the Ray framework became one of the most exploited components in AI infrastructure. Ray scales Python and AI applications across clusters, but its default configuration created a massive security hole.
CVE-2023-48022 (CVSS 9.8) identified that Ray's dashboard and job submission APIs bind to 0.0.0.0 without authentication. The maintainers argued this wasn't a vulnerability—Ray was designed for trusted networks. Reality disagreed. Thousands of Ray clusters were exposed to the internet through misconfigured Ingress controllers.
The "ShadowRay" botnet systematically exploited these exposures:
- Scanning: Attackers scanned for Ray dashboard ports (8265) exposed via public IPs or load balancers
- Initial Access: Connected to exposed dashboards and submitted Python jobs via the legitimate API
- Persistence: Modified Ray startup scripts to survive restarts
- Cryptojacking: Deployed XMRig cryptominers to monetize GPU resources
- Data Exfiltration: Accessed environment variables containing AWS credentials, database connections, and API keys
- Lateral Movement: Used stolen credentials to pivot into data lakes and production databases
One documented incident resulted in a $300,000 monthly cloud bill spike—just the compute costs, not counting stolen data value or remediation costs. The victim's Ray cluster ran on GPU instances costing $30+ per hour. The miners maxed out all available resources 24/7.
"ShadowRay 2.0" emerged in late 2025 with improved evasion techniques. It used legitimate-looking traffic patterns and rotated through multiple mining pools to avoid detection. The campaign specifically targeted education and research institutions with exposed Ray clusters processing sensitive data.
Mitigation: Never expose Ray services directly to the internet. Place them behind authentication proxies. Use NetworkPolicies to restrict which pods can reach Ray APIs. Enable Ray's built-in authentication features even in supposedly trusted environments.
The $25.6 Million Deepfake Incident
While not specifically a Kubernetes attack, the Arup deepfake incident illustrates the value of AI infrastructure as a target. In early 2024, criminals used deepfake technology to steal $25.6 million from the engineering firm Arup.
Attackers created deepfake videos impersonating the company's CFO and other executives. These deepfakes were sophisticated enough to fool employees in video conferences. The criminals instructed finance personnel to transfer funds to attacker-controlled accounts. The employees complied, believing they were following legitimate instructions from executives.
The incident demonstrates why AI infrastructure security matters. The deepfake models used in this attack required substantial GPU resources for training and inference. Attackers either built this capability using compromised infrastructure or purchased it from underground services running on stolen compute.
When you secure your AI infrastructure, you're not just protecting your own assets. You're preventing your resources from being weaponized against others. Compromised GPU clusters become tools for generating deepfakes, launching attacks, or training malicious models.
The Kubernetes Cryptojacking Economic Model
Understanding attacker economics helps you prioritize defenses. Cryptojacking persists because it's profitable.
A single NVIDIA A100 GPU mining Ethereum can generate $10-15 per day at current prices, varying with cryptocurrency values. An attacker who compromises a cluster with 100 A100s generates $1,000-1,500 daily—$365,000-547,500 annually. The attacker's costs are minimal: time to develop exploits and infrastructure to operate the botnet.
The victim's costs are much higher. Beyond the cloud bills (an A100 instance costs $4-5 per hour, or roughly $3,000-3,600 monthly), there are incident response costs, reputation damage, potential regulatory fines if the compromise resulted in data exposure, and opportunity costs of legitimate workloads being denied resources.
This economic model explains why cryptojacking remains popular despite relatively low per-GPU returns. Attackers automate exploitation across thousands of targets. They don't need each compromise to be highly profitable—volume makes up for low margins.
Your defense must account for this reality. Automated attacks happen at scale with rapid exploitation. Manual security reviews won't catch compromises quickly enough. You need automated detection, immediate alerting, and automated response capabilities.
Part 11: Comprehensive Hardening Checklist
Immediate Actions (Critical Priority)
These actions address actively exploited vulnerabilities and critical misconfigurations. Complete them within 1-2 weeks:
- Upgrade NVIDIA Container Toolkit to v1.17.8+ and GPU Operator to v25.3.1+ to patch NVIDIAScape container escape
- Patch runc to v1.2.8+ to prevent Leaky Vessels exploits actively used by ransomware
- Upgrade Ingress-NGINX to v1.11.5+ or v1.12.1+ to patch IngressNightmare RCE
- Apply restricted Pod Security Standards to all ML namespaces
- Implement default-deny NetworkPolicies for training and inference workloads
- Remove public exposure of Kubeflow, JupyterHub, MLflow, and Ray dashboards
- Audit and rotate all API keys and credentials stored in Kubernetes secrets
Identity and Access Controls (High Priority)
Complete within 1 month:
- Create separate RBAC roles for data scientists vs. ML engineers vs. platform operators
- Assign dedicated service accounts per workload type with minimal permissions
- Disable automountServiceAccountToken for pods that don't need API access
- Enable audit logging for all ML namespaces with retention of 90+ days
- Implement external authentication for JupyterHub, Kubeflow (OAuth2/OIDC)
- Regular RBAC audits to remove stale permissions and over-privileged accounts
GPU Security and Isolation (High Priority)
Complete within 1 month:
- Deploy MIG for multi-tenant production (abandon time-slicing for sensitive workloads)
- Apply node taints/tolerations to restrict which workloads can schedule on GPU nodes
- Implement ResourceQuotas to prevent GPU monopolization and bill shock
- Enable DCGM Exporter for GPU monitoring and anomaly detection
- Monitor GPU memory usage patterns to detect side-channel attacks
- Create GPU-specific Falco rules for unauthorized hardware access
Network Security Architecture (Medium Priority)
Complete within 2 months:
- Deploy Layer 7 network policies (Cilium) for inference API endpoints
- Block metadata service access (169.254.169.254) from all pods
- Implement Istio/Linkerd for mTLS between ML services
- Create network segmentation between training, staging, and production
- Monitor network flows for unexpected egress to mining pools
- Regularly audit NetworkPolicy rules for gaps and misconfigurations
Supply Chain Security (High Priority)
Complete within 1 month:
- Scan container images with Trivy before deployment with CRITICAL/HIGH threshold
- Implement image signature verification with Kyverno or Gatekeeper
- Generate SBOMs for ML containers and model artifacts
- Never load untrusted models without sandboxing and scanning
- Ban pickle format for model serialization; mandate Safetensors
- Implement model signing using Cosign for provenance verification
Runtime Security and Monitoring (High Priority)
Complete within 1 month:
- Deploy Falco or Tetragon for runtime detection across all nodes
- Configure alerts for cryptomining indicators (stratum protocol, known binaries)
- Block network egress to known mining pools at the network level
- Monitor GPU utilization in non-ML namespaces for anomalies
- Create runbooks for incident response to cryptojacking detection
- Test detection rules regularly with benign simulations
Secrets and Storage Security (Medium Priority)
Complete within 2 months:
- Migrate to External Secrets Operator for all sensitive credentials
- Enable etcd encryption to protect secrets at rest
- Implement secret rotation schedules for all API keys and credentials
- Audit secret access logs for anomalous patterns
- Enable CSI driver encryption for persistent volumes containing models
- Regular storage audits to identify sensitive data leaks
Continuous Security (Ongoing)
Establish these practices as part of standard operations:
- Weekly vulnerability scanning of deployed images and clusters
- Monthly RBAC audits to identify privilege creep
- Quarterly red team exercises targeting ML infrastructure
- Real-time threat intelligence subscription for ML-specific CVEs
- Annual security architecture review of ML platform design
- Security training for data scientists on ML-specific threats
Part 12: Looking Forward—The Future of AI Infrastructure Security
Emerging Threats on the Horizon
The threat landscape for AI infrastructure will intensify as AI capabilities advance. Three trends demand attention.
Model extraction attacks are becoming more sophisticated. Current extraction techniques use repeated queries to inference endpoints to reverse-engineer model parameters. Upcoming research demonstrates extraction with 10x fewer queries by exploiting architectural details leaked through timing side-channels. Defense requires query rate limiting, output perturbation, and continuous monitoring for extraction patterns.
Supply chain attacks targeting model registries will increase. As organizations depend on external models from Hugging Face, cloud marketplaces, and open-source repositories, these registries become high-value targets. A compromised model registry could inject backdoors into thousands of downstream deployments. Mandatory model signing and decentralized verification using transparency logs (like Sigstore's Rekor) become critical.
Adversarial attacks against ML platforms themselves. Current attacks focus on infrastructure (cryptojacking, data theft). Future attacks will poison training data to inject backdoors, manipulate model outputs to cause specific misclassifications, or extract sensitive information from training datasets through model inversion. These attacks require ML-aware security monitoring beyond traditional infrastructure protection.
The MLSecOps Maturity Model
Organizations securing AI infrastructure progress through maturity levels:
Level 1 - Reactive: No ML-specific security. General Kubernetes hardening applied inconsistently. Attacks detected through anomalous cloud bills or user reports. Manual incident response.
Level 2 - Basic Hardening: Pod Security Standards enforced. Network policies implemented. Container image scanning in CI/CD. Still largely reactive with limited ML-specific controls.
Level 3 - Defense-in-Depth: Runtime security deployed (Falco/Tetragon). GPU isolation with MIG. Model signing required. External secrets management. Automated alerting for ML-specific threats. Proactive threat hunting begins.
Level 4 - Continuous Security: Automated security testing in ML pipelines. Real-time anomaly detection with automated response. Supply chain security with SBOMs and provenance tracking. Red team exercises specifically targeting ML infrastructure. Security embedded in data science workflows.
Level 5 - Predictive Security: ML-powered threat detection identifying novel attacks. Automated vulnerability prioritization based on exploit likelihood and business impact. Security as automated backstop rather than gate. Contribution to open-source ML security tools and threat intelligence sharing.
Most organizations today operate at Level 1 or 2. The attacks documented in this guide target those maturity levels. Progressing to Level 3 eliminates the majority of current threats. Levels 4 and 5 provide resilience against sophisticated adversaries and emerging attack techniques.
Integration with AI Governance
Security integrates with broader AI governance requirements. Regulations like the EU AI Act, state-level AI safety laws, and industry-specific compliance frameworks mandate security controls as part of responsible AI deployment.
Model lineage tracking—documenting which data trained which models, who deployed them, and how they're used—serves both security and governance goals. The same infrastructure for signing models and tracking provenance enables both supply chain security and compliance reporting.
Privacy regulations intersect with security for AI training data. GDPR's right to deletion and data minimization requirements affect how you store training datasets. Encryption, access controls, and audit logging protect both security and privacy. Design systems that satisfy both requirements rather than treating them separately.
Conclusion: Security as Enabler of AI Innovation
Securing Kubernetes for AI workloads isn't optional—it's existential. The convergence of expensive GPU resources, valuable intellectual property, and immature security controls creates a perfect target for sophisticated attackers. The 10-minute attack timeline from initial access to impact leaves no room for slow response.
The vulnerabilities documented here—NVIDIAScape, IngressNightmare, ShadowRay—demonstrate that AI infrastructure faces threats traditional security controls don't address. GPU isolation requires hardware enforcement through MIG, not software time-slicing. Supply chain security demands model signing and provenance verification, not just container image scanning. Runtime security needs ML-aware detection rules that identify cryptomining and unauthorized GPU access.
Three principles guide effective AI infrastructure security:
Defense-in-depth with ML-specific controls. Layer network policies, pod security standards, runtime monitoring, and access controls. Add GPU-specific protections, model verification, and secrets management tailored for ML workflows. No single control prevents all attacks—overlapping defenses catch what individual layers miss.
Automation over manual gates. The speed and scale of attacks demand automated detection and response. Policy engines enforce requirements at deployment. Runtime security detects attacks in progress. Automated scanning identifies vulnerabilities before they reach production. Manual security reviews can't match attacker automation.
Continuous evolution matching the threat landscape. New vulnerabilities emerge constantly. Attack techniques advance. Your security posture must evolve correspondingly. Regular patching, continuous scanning, threat intelligence monitoring, and periodic architecture reviews keep defenses current.
The financial stakes justify investment. The average breach costs $5.17 million. Ransomware incidents cost $5.08 million. Organizations with mature security automation reduce breach costs by $1.9 million. The ROI on security investment is measurable and substantial.
Beyond cost avoidance, security enables innovation. Data scientists trust infrastructure that protects their research. Business leaders deploy AI solutions knowing they're defensible. Customers share data with systems demonstrating robust security. Security becomes the foundation for AI adoption rather than a barrier to it.
The tools and techniques in this guide provide actionable starting points. Deploy default-deny network policies today. Upgrade vulnerable components this week. Implement runtime monitoring this month. Build toward defense-in-depth over quarters. Establish continuous security operations as standard practice.
Your AI infrastructure powers competitive advantage. Protect it like the strategic asset it is.
References and Further Reading
This guide draws from security research, incident analyses, and vulnerability disclosures from 2023–2025.
Key Reports:
- Sysdig 2024 Global Cloud Threat Report (cloud attack statistics and cryptojacking costs)
- Red Hat 2024 State of Kubernetes Security Report (incident and impact data)
- IBM 2024 Cost of a Data Breach Report (breach cost analysis)
- CNCF 2024–2025 Annual Surveys (Kubernetes and AI/ML adoption metrics)
Critical CVEs:
- CVE-2025-23266 "NVIDIAScape" — NVIDIA Container Toolkit container escape
- CVE-2024-0132 — Earlier NVIDIA Toolkit TOCTOU vulnerability
- CVE-2024-21626 "Leaky Vessels" — runc container escape
- CVE-2025-1974 "IngressNightmare" — Ingress-NGINX RCE
- CVE-2023-48022 — Ray framework ShadowRay campaigns
- CVE-2024-35225 — JupyterHub privilege escalation
- CVE-2024-0520 — MLflow RCE (CVSS 10.0)
- CVE-2025-3248 — Langflow RCE
Security Tools Documentation:
- Falco: https://falco.org/
- Tetragon: https://tetragon.io/
- Kyverno: https://kyverno.io/
- Trivy: https://trivy.dev/
- External Secrets Operator: https://external-secrets.io/
- Sigstore/Cosign: https://www.sigstore.dev/
Kubernetes Security References:
- CIS Kubernetes Benchmark
- Pod Security Standards documentation
- NVIDIA GPU Operator and MIG documentation
Incident Analyses:
- Microsoft analysis of Kubeflow cryptojacking campaigns
- Wiz Research NVIDIAScape disclosure
- Protect AI Guardian scan results (Hugging Face model security)
- JFrog malicious model research