
Table of Contents
- The Problem: LLMs That Answer Anything
- Why Simple Approaches Fail
- Architecture: Small Model, Precise Purpose
- Temperature Calibration
- The Margin-Based Decision Rule
- Input Normalization and Adversarial Hardening
- Policy-Driven Design
- The Multi-Vertical Router
- Production Hardening
- Evaluation: What "Ship" Actually Means
- Using IntentGuard
- Conclusion and What's Next
The Problem: LLMs That Answer Anything
Picture this: your company deploys a finance chatbot. It is powered by a capable LLM, trained on your documentation, and your customers love it. Then one morning a support ticket comes in — a user asked the chatbot for celebrity gossip and it happily obliged for three paragraphs before eventually circling back to remind them it was a financial assistant. Another user somehow convinced it to help draft a personal letter. The chatbot never broke the law. It did not expose private data. But it absolutely drifted off-topic, and that drift is both a product quality problem and a compliance risk.
This is the problem IntentGuard solves. Not by lecturing the LLM about its purpose — prompt engineering is fragile and gets jailbroken — but by sitting upstream and deciding, before the LLM ever sees the message, whether that query belongs in front of the model at all.
IntentGuard is an open-source (Apache 2.0) vertical intent classifier purpose-built for this job. It ships three verticals out of the box — finance, healthcare, and legal — with a model architecture and policy system designed to be extended to any domain-specific deployment. The models are published on HuggingFace, the container on GHCR, and the Python package on PyPI. The full training pipeline, adversarial test sets, and evaluation reports are in the GitHub repository.
What IntentGuard is not: IntentGuard is not a replacement for your LLM's system prompt, a harmful content detector, a prompt injection scanner, or a hallucination guard. It is specifically a topical boundary layer. Both the system prompt and the guardrail have a role. The system prompt shapes how the LLM behaves when it processes a query. IntentGuard decides whether the LLM should process the query at all.
Why Simple Approaches Fail
When teams first encounter the topic-drift problem, they reach for the obvious tools.
Keyword filters are the first instinct. Block anything containing "celebrity," "recipe," "travel," and you are done. Except you are not. A user asking "What is the financial impact of Taylor Swift concert ticket prices on discretionary spending?" contains no blocked keywords but is clearly off-topic for a banking assistant. And "How do I invest in cooking stocks?" is perfectly in-scope — COOK, BRTH, and SFM are all traded securities.
Prompt engineering is the second instinct. Add a firm system prompt: "You are a financial assistant. Do not answer questions outside of finance." This works until it does not. Users quickly learn that wrapping off-topic requests in financial framing ("For tax purposes, what is the net worth of [celebrity]?") often slips through. LLMs are trained to be helpful, and that helpfulness works against strict domain enforcement when the gatekeeping logic lives inside the same model you are trying to constrain.
Binary classifiers are the third instinct, and closer to the right answer — but they break down at the margins, exactly where you need them most. A query like "Can you explain how HIPAA affects billing disputes?" sent to a healthcare chatbot may be flagged as administrative or legal by a strict topic filter trained on clinical queries. That is a false block — a legitimate user shut out of a system they need. Conversely, "What are symptoms of a drug interaction?" sent to a financial chatbot, preceded by a paragraph about HSA accounts, might pass a poorly calibrated classifier because of the financial context. Binary classifiers optimize for one threshold and accept both error types as a trade-off. That is the wrong trade-off for regulated industries.
What you actually need is a dedicated, purpose-built classifier with a third output class for ambiguous inputs. A model whose only job is to answer one question: does this query belong here?
Architecture: Small Model, Precise Purpose
The first architectural decision was model selection. The temptation with NLP classification is always to reach for the largest model available, but larger is not always better when you are building a latency-sensitive sidecar service.
IntentGuard uses DeBERTa-v3-xsmall as its base model. DeBERTa-v3 is Microsoft's enhanced BERT variant that uses disentangled attention — it encodes each token's content and position separately, then combines them during attention computation. This gives the model strong understanding of semantic relationships with notably fewer parameters than comparable models. The xsmall variant lands at 22 million parameters, which might seem modest against GPT-class models, but for this specific task — domain classification over short text — it is more than sufficient and crucially fast on CPU.
The model is fine-tuned for three-way classification:
- ALLOW — the query is on-topic for this vertical; forward it to the LLM
- DENY — the query is clearly off-topic; return a polite refusal
- ABSTAIN — the query is ambiguous; ask the user to clarify
That third class is where most guardrail systems fall short. Binary classifiers are forced to choose, and forced choices on borderline queries produce false positives that frustrate legitimate users. ABSTAIN gives the system an honest out: "I am not confident enough to block this, but I am not confident enough to allow it either. Let me ask."
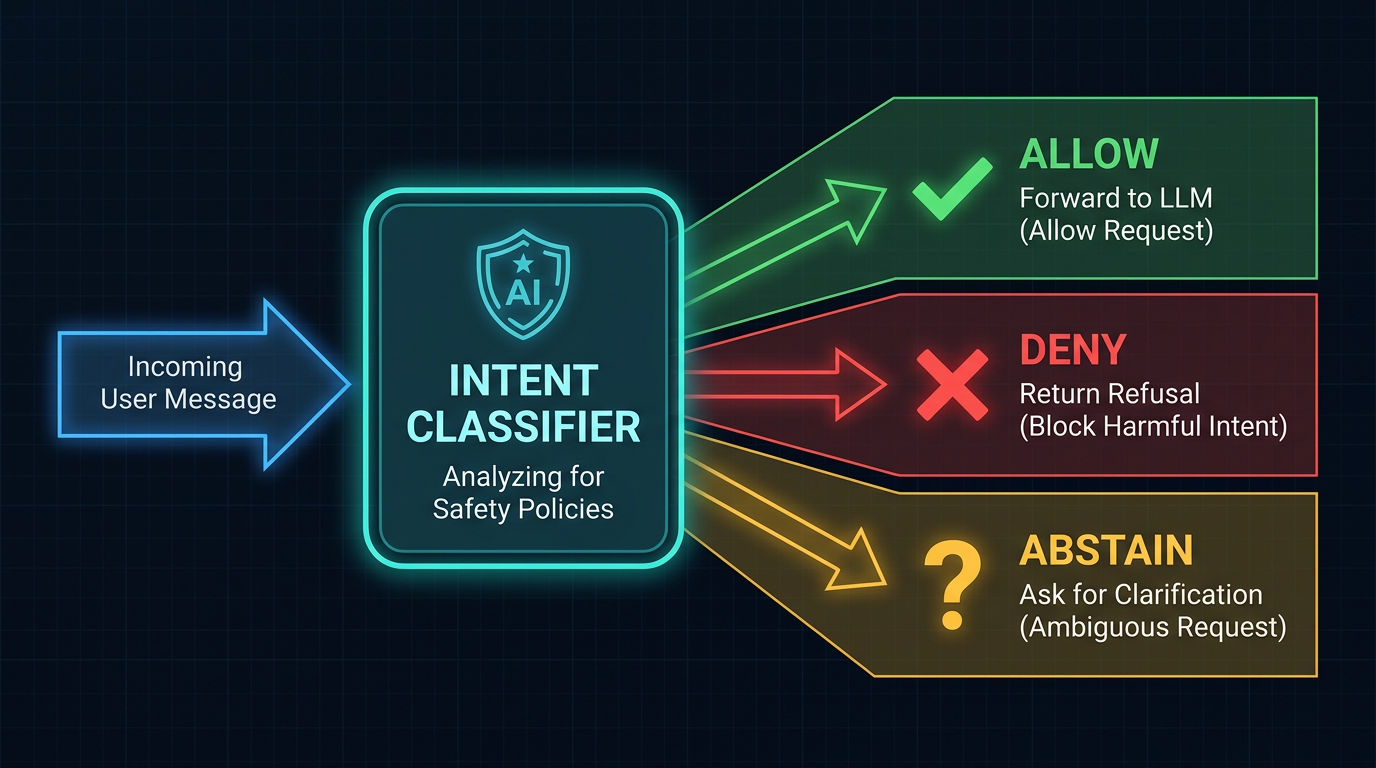
Figure 1: The IntentGuard classification pipeline from input normalization through margin-based decision to policy pack routing.
The Sentence-Pair Input Design
Every inference call processes a sentence pair: the user query paired with a vertical context string. The context string is derived from the policy JSON at server startup and remains fixed for the lifetime of the process. Here is what that string looks like for the finance vertical:
VERTICAL=finance; CONTEXT_VERSION=ctv1; CORE_TOPICS=[banking, lending, credit, payments,
investing, insurance, tax, personal finance, retirement, mortgages, financial planning,
budgeting]; CONDITIONAL_ALLOW=[healthcare: only when related to financial planning,
insurance, HSA/FSA, medical debt, or compliance; legal: only when related to financial
regulation, contracts, or compliance]; HARD_EXCLUSIONS=[sports, entertainment, cooking,
gaming, celebrity gossip, fashion, travel_leisure, fiction_writing, relationship_advice]This design matters. The model does not just classify the query in isolation — it classifies the query relative to the policy. Fine-tuning on sentence pairs teaches the model to reason about domain membership, not just to memorize topic-specific vocabulary. When you update the policy JSON, you update what the model interprets as in-scope. Threshold and message changes take effect on restart; meaningful scope changes require retraining, which is the right trade-off.
ONNX Runtime with INT8 Quantization
The PyTorch fine-tuned model is exported to ONNX (Open Neural Network Exchange) format and then quantized to INT8 using dynamic quantization. The export pipeline tries quantization methods in order — Optimum's ORTQuantizer first (best DeBERTa-v3 support), Microsoft Olive second, and a plain ORT fallback if neither is available.
After quantization, the model sits under 80MB. On a 4-core CPU, p99 inference latency comes in under 30 milliseconds. You can run this as a sidecar container on the same instance as your application server without meaningfully impacting your infrastructure costs.
Deployment footprint: Under 80MB model weight. Sub-30ms p99 latency on CPU. No GPU required. Runs as a standard Docker container alongside any LLM API endpoint. Total infrastructure overhead is minimal.
Temperature Calibration: Making Confidence Mean Something
The model produces logits — raw, uncalibrated scores. After the softmax, those scores become probabilities, but uncalibrated probabilities are often overconfident. A model that outputs 0.95 for every prediction, even when it is wrong 20% of the time, is not useful for threshold-based decision logic.
IntentGuard calibrates confidence scores using temperature scaling. The process is straightforward: after fine-tuning, collect raw logits on a held-out calibration set, then fit a single scalar temperature parameter T by minimizing the negative log-likelihood:
class TemperatureScaler(nn.Module):
def __init__(self):
super().__init__()
self.temperature = nn.Parameter(torch.ones(1))
def forward(self, logits: torch.Tensor) -> torch.Tensor:
return logits / self.temperatureThe optimizer is LBFGS — a second-order method that converges quickly on this single-parameter problem. During inference, every set of logits is divided by the fitted temperature before the softmax. The target is an Expected Calibration Error (ECE) below 0.03, meaning the model's stated confidence aligns closely with its actual accuracy across the probability range.
When the calibration check passes, you have probabilities you can actually trust. That trust is what makes the margin-based decision rule work.
The Margin-Based Decision Rule
This is where IntentGuard diverges most significantly from naive classifiers.
Most classification systems just take the argmax — pick whichever class has the highest probability and call it done. This works when your classes are clearly separable, but domain classification has a significant number of genuinely ambiguous cases. A query with p_allow=0.52, p_deny=0.28, p_abstain=0.20 has a plurality for ALLOW, but that decision carries almost no confidence. Passing that query through to the LLM based on a razor-thin plurality is a bad idea.
IntentGuard requires two conditions to be satisfied before committing to ALLOW or DENY:
- The winning class must exceed an absolute confidence threshold (tau)
- The winning class must exceed all other classes by a minimum margin
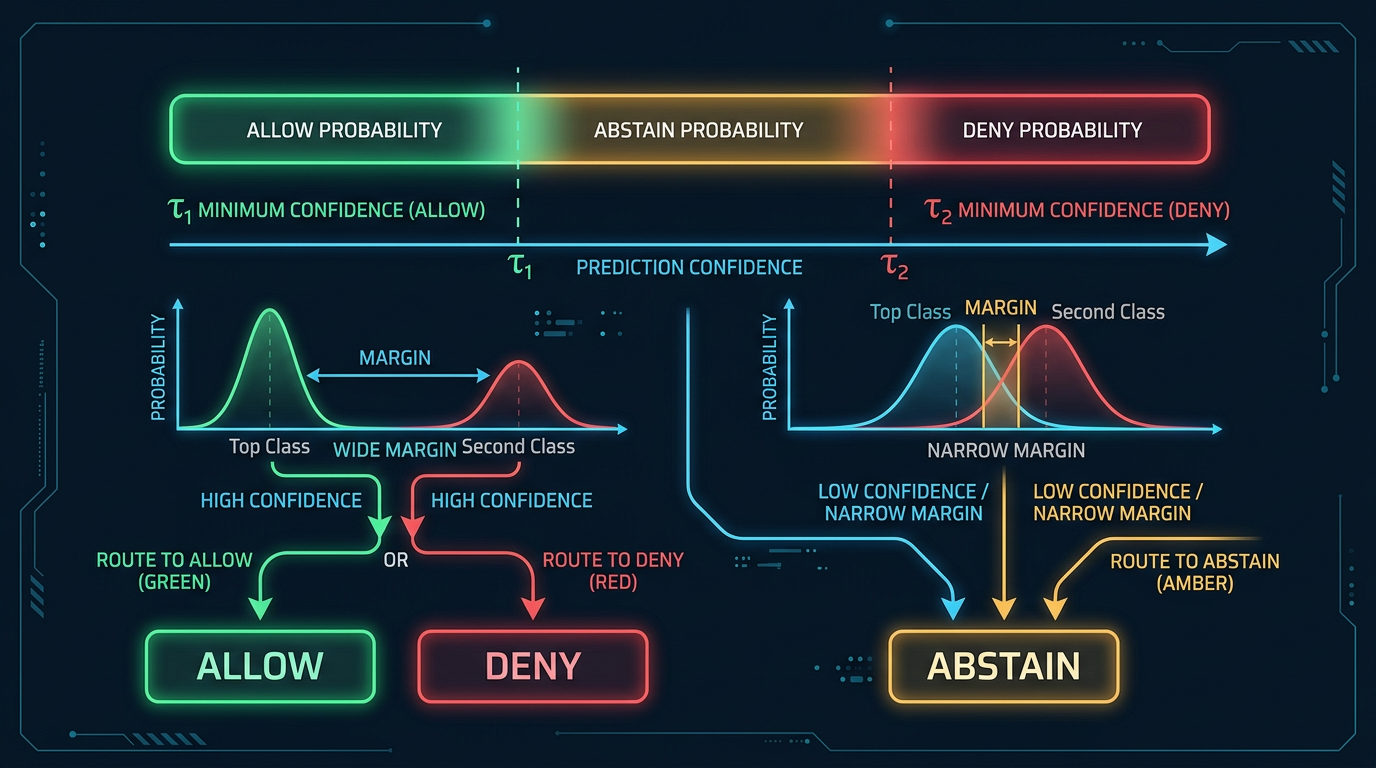
Figure 2: The margin-based three-way decision flow. Both a minimum confidence threshold and a minimum margin over competing classes are required before committing to ALLOW or DENY.
Here is the actual decision logic from classifier.py:
def _apply_thresholds(
self,
probs: dict[str, float],
tricks_detected: bool = False,
) -> tuple[Decision, float]:
"""Apply margin-based decision rule.
ALLOW if: p_allow >= tau_allow AND p_allow - max(p_deny, p_abstain) >= margin_allow
DENY if: p_deny >= tau_deny AND p_deny - max(p_allow, p_abstain) >= margin_deny
Otherwise: ABSTAIN
"""
t = self.policy.thresholds
p_allow = probs.get("allow", 0.0)
p_deny = probs.get("deny", 0.0)
# Encoding tricks detected — force ABSTAIN immediately
if tricks_detected:
return Decision.ABSTAIN, probs.get("abstain", 0.0)
# Check ALLOW first (bias toward allowing legitimate queries)
if p_allow >= t.tau_allow and (p_allow - max(p_deny, p_abstain)) >= t.margin_allow:
return Decision.ALLOW, p_allow
# Check DENY
if p_deny >= t.tau_deny and (p_deny - max(p_allow, p_abstain)) >= t.margin_deny:
return Decision.DENY, p_deny
# Default to ABSTAIN
return Decision.ABSTAIN, max(p_abstain, 1.0 - p_allow - p_deny)The default thresholds are asymmetric by design. ALLOW requires tau=0.80 with a 0.10 margin. DENY requires tau=0.90 with a 0.10 margin. The higher bar for DENY reflects a deliberate product choice: in ambiguous cases, it is better to ask for clarification than to frustrate a legitimate user with an unjustified refusal. Blocking a real customer from getting financial advice they are entitled to is a worse outcome than routing a borderline query to clarification.
Everything that does not meet these thresholds lands in ABSTAIN. The system returns a clarification prompt and waits for the user to resolve the ambiguity.
Threshold tuning: The default thresholds are conservative starting points appropriate for most deployments, but the right operating point depends on your context. A consumer-facing healthcare chatbot and an internal clinical decision support tool have very different tolerances for false blocks. Policy-driven configuration lets operators tune behavior per deployment without touching model weights.
Input Normalization and Adversarial Hardening
Before any text reaches the model, it passes through a normalization pipeline that reduces the adversarial attack surface.
Unicode normalization (NFKC) handles compatibility characters — fullwidth ASCII, ligatures, superscripts, and the like — that look identical to regular characters but tokenize differently. An attacker sending finance (fullwidth characters) instead of finance is trying to shift the token distribution. NFKC collapses these back to canonical forms before tokenization.
Zero-width character stripping removes invisible characters that are completely transparent to human readers but can fragment tokens in ways that confuse classifiers. The normalize module tracks a comprehensive list including zero-width spaces, zero-width non-joiner, word joiners, invisible math operators, BOM characters, and several others across multiple Unicode blocks.
The has_encoding_tricks function runs a separate check for patterns that suggest active evasion:
def has_encoding_tricks(text: str) -> bool:
# Base64 blobs: 20+ chars of base64 alphabet without spaces
if _BASE64_BLOB.search(text):
return True
# High ratio of non-ASCII in short text suggests obfuscation
non_ascii = sum(1 for c in text if ord(c) > 127)
ratio = non_ascii / len(text) if text else 0
if ratio > 0.6 and len(text) < 200:
return True
return FalseA base64 blob in a user query almost never indicates legitimate intent. It is a payload delivery mechanism — someone trying to smuggle instructions past the classifier by encoding them. The ratio check catches random unicode obfuscation while remaining tolerant of genuine multilingual text, which will have consistent unicode ranges rather than scattered high-codepoint characters.
When encoding tricks are detected, the classifier returns ABSTAIN immediately. The model never runs. Whatever is in that payload, the system refuses to act on it.
Policy-Driven Design
Behavior is controlled by JSON policy files, not code changes. This separation matters in a commercial context: customers can tune threshold values and refusal messages without opening a pull request and triggering a new model build.
The policy file defines the full behavioral contract for a vertical. Here is a condensed look at the finance policy structure:
{
"vertical": "finance",
"version": "1.0",
"scope": {
"core_topics": [
"banking", "lending", "credit", "investing",
"insurance", "tax", "personal finance", "retirement"
],
"conditional_allow": [
{
"topic": "healthcare",
"condition": "only when related to HSA/FSA, medical debt, or insurance costs",
"examples_allow": [
"What are HSA contribution limits?",
"How does medical debt affect my credit score?"
],
"examples_deny": [
"Explain my MRI results",
"What antibiotic should I take?"
]
}
],
"hard_exclusions": [
"sports", "entertainment", "cooking", "celebrity gossip"
]
},
"decision": {
"tau_allow": 0.80,
"tau_deny": 0.90,
"margin_allow": 0.10,
"margin_deny": 0.10
},
"policy_packs": {
"allow": {
"allowed_tools": ["calculator", "market_data", "account_lookup", "document_search"],
"guardrails": ["no_trade_execution", "no_pii_disclosure", "disclaimer_required"]
},
"deny": {
"allowed_tools": [],
"guardrails": ["block_response", "log_attempt"]
}
}
}The conditional_allow section is particularly important. Real-world domain boundaries are not clean lines — a finance chatbot serving HSA-eligible employees absolutely should answer questions about HSA contribution limits. It should not answer questions about antibiotic dosing. The conditional allow rules encode these nuances in the policy rather than hardcoding them in training data, and the vertical context string surfaces them to the model at inference time.
The policy_packs section extends the system's role beyond simple allow/deny. Each decision carries a set of allowed downstream tools and guardrails. An ALLOW decision for a finance query comes with ["calculator", "market_data", "account_lookup"] — the tools a financial agent legitimately needs. A DENY decision comes with no tools and the guardrails ["block_response", "log_attempt"]. This turns IntentGuard into a tool-use governance layer for agentic AI pipelines, not just a topic filter.
Policy vs. retraining: Threshold values, refusal messages, and response templates can be changed in the policy JSON and take effect on server restart. Adding or removing topics from the conditional allow rules requires updating the context string, which also takes effect on restart. Fundamental changes to the domain boundary — adding a new vertical, substantially changing what is in-scope — require retraining. This is the intended trade-off: configuration for operations, retraining for substantive scope changes.
The Multi-Vertical Router
Single-vertical deployments are straightforward. The more interesting architectural challenge is running multiple verticals from a single container — a product requirement when you are serving many customers and do not want to maintain a separate fleet per vertical.
The v2 router uses a two-stage architecture:
Stage 1: Vertical Routing. A lightweight N-way classifier routes the incoming query to the most relevant vertical. This router model is itself a fine-tuned DeBERTa-v3-xsmall, but trained on the simpler task of predicting vertical membership from the query alone (no sentence-pair input needed — it just needs to identify domain, not classify intent). It runs with only 2 intra-op threads and a max_length of 128 tokens, keeping its latency contribution minimal.
Stage 2: Per-Vertical Classification. Once the query is routed to a vertical, the per-vertical ONNX classifier runs the full sentence-pair inference with that vertical's context string and thresholds.
The classify endpoint in router mode:
if _router:
result, routed_vertical, router_scores = _router.classify(text)
result.routed_vertical = routed_vertical
# Attach policy pack for downstream orchestration
classifier = _router.classifiers.get(routed_vertical)
if classifier:
pack = classifier.policy.get_policy_pack(result.decision.value)
if pack:
result.policy_pack = PolicyPackResponse(
vertical=routed_vertical,
decision=result.decision.value,
allowed_tools=pack.allowed_tools,
guardrails=pack.guardrails,
)The response includes the routed vertical, the decision, and the policy pack for that (vertical, decision) combination. Downstream orchestration systems receive complete routing context in a single API call.
Production Hardening
Shipping a classifier is not the same as shipping a product. Between "the model is accurate" and "the service is trustworthy in production" lies a significant amount of engineering work. IntentGuard includes four production hardening features that address different parts of the operational lifecycle.
Shadow Mode
The most valuable tool for safe rollouts is shadow mode. When a request arrives with ?mode=shadow, IntentGuard runs the full classification pipeline and records what it would have decided — but returns ALLOW to the caller regardless. The real classification decision travels in a response header:
X-Classification-Decision: allow
X-Classification-Shadow: deny
X-Classification-Latency-Ms: 14.3This lets you deploy a new model or new thresholds without affecting production traffic. You watch the shadow decisions for days or weeks, compare them against expected behavior, and only flip to enforce mode once you are confident. It is the same principle as feature flags, applied to ML inference.
Prometheus Metrics
Every classification emits structured metrics:
REQUESTS = Counter(
"intentguard_requests_total",
"Total classification requests",
["decision", "vertical"],
)
LATENCY = Histogram(
"intentguard_latency_seconds",
"Classification latency",
["vertical"],
buckets=[0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0],
)Decision counters broken down by (decision, vertical) let you spot when a particular vertical's DENY rate spikes unexpectedly — which often means either a policy misconfiguration or an unusual pattern in user traffic. The latency histogram with fine-grained buckets at the low end (5ms, 10ms, 25ms) gives you accurate p95 and p99 measurements that matter for SLA tracking.
Human-in-the-Loop Feedback
The /v1/feedback endpoint accepts corrections when the classifier gets a decision wrong:
@app.post("/v1/feedback", response_model=FeedbackResponse)
async def feedback(req: FeedbackRequest):
"""Record feedback on a classification decision."""
metrics.record_feedback(req.expected_decision.value, req.actual_decision.value)
entry = {
"query": req.query[:200],
"expected": req.expected_decision.value,
"actual": req.actual_decision.value,
"notes": req.notes[:500] if req.notes else "",
}
logger.info(json.dumps(entry))These corrections accumulate into a feedback file for batch export. The workflow: collect feedback, human-review the edge cases, fold confirmed corrections back into the training set, retrain, re-evaluate. Continuous improvement without continuous deployment.
The Sanity Gate
Before any quantized model ships, it must pass a mandatory comparison against its PyTorch source. The export pipeline runs both models on a held-out test set and checks that predictions agree:
def sanity_check(pytorch_model, tokenizer, onnx_path, examples, ...):
"""
Returns True if all outputs match within tolerance.
This is the mandatory gate — if it fails, the export is rejected.
"""
mismatches = 0
for ex in examples:
pt_pred = argmax(pytorch_model(encode(ex)).logits)
onnx_pred = argmax(onnx_session.run(encode(ex)))
if pt_pred != onnx_pred:
mismatches += 1
if mismatches > 0:
logger.error(
"SANITY CHECK FAILED: %d/%d predictions differ. "
"Do NOT ship this model.", mismatches, total,
)
return FalseIf the sanity check fails, the INT8 model is discarded and the pipeline falls back to FP32 — or halts entirely if even the FP32 export disagrees with PyTorch. Quantization introduces numerical approximations that occasionally break predictions on specific inputs. The gate catches these failures before they reach customers.
Evaluation: What "Ship" Actually Means
Three metrics gate every model release:
- Legitimate Block Rate (LBR): The fraction of genuinely on-topic queries that the model denies. This is the false positive rate that matters most for user experience. Maximum allowable LBR is 0.5%.
- Off-Topic Pass Rate (OPR): The fraction of clearly off-topic queries that the model allows through. This is the false negative rate that matters most for compliance. Maximum allowable OPR is 2%.
- Abstain-on-Clean (AOC): The fraction of unambiguously labeled queries that fall into ABSTAIN. If the model is constantly abstaining on easy cases, something is wrong with thresholds or training data. Maximum allowable AOC is 10%.
The adversarial test sets cover nine categories: clean on-topic, clean off-topic, lexical overlap (queries that share vocabulary with the vertical but are not actually in-scope), context wrapping (off-topic requests framed in domain language), multi-intent queries, conditional valid, conditional invalid, polysemy, and short ambiguous.
Current results across the three shipped verticals:
| Vertical | Accuracy | LBR | OPR | Decision |
|---|---|---|---|---|
| Finance | 99.6% | 0.00% | 0.00% | SHIP |
| Healthcare | 98.9% | 0.00% | 0.98% | SHIP |
| Legal | 97.9% | 0.00% | 0.50% | SHIP |
Zero legitimate blocks across all three verticals. Legal's 0.5% OPR on nearly 500 adversarial examples reflects the genuine complexity of legal-adjacent domain boundaries — the legal vertical has inherently harder conditional-allow cases than finance. Every metric clears the gating threshold.
Evaluation reports: The full gating reports for each vertical are included in the HuggingFace model repositories. They break down accuracy by test category — clean on-topic, clean off-topic, lexical overlap attacks, context-wrapping attempts, multi-intent queries, polysemy cases, and short ambiguous inputs — so you can see exactly where each model performs and where it does not.
Using IntentGuard
The API is OpenAI-compatible. Getting started requires one Docker command:
docker run -p 8080:8080 perfecxion/intentguard:finance-latestClassify a message by posting to /v1/classify:
curl -X POST http://localhost:8080/v1/classify \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "What are current mortgage rates?"}
]
}'{
"decision": "allow",
"confidence": 0.95,
"vertical": "finance",
"message": "",
"policy_pack": {
"vertical": "finance",
"decision": "allow",
"allowed_tools": ["calculator", "market_data", "account_lookup", "document_search"],
"guardrails": ["no_trade_execution", "no_pii_disclosure", "disclaimer_required"]
}
}For proxy mode — where IntentGuard sits in front of your LLM and forwards allowed requests automatically — point your application at IntentGuard instead of your LLM endpoint and set the DOWNSTREAM_URL environment variable:
docker run -p 8080:8080 \
-e DOWNSTREAM_URL=https://api.openai.com/v1/chat/completions \
-e DOWNSTREAM_API_KEY=sk-... \
perfecxion/intentguard:finance-latestFor rollout without risk, shadow mode is one query parameter away:
curl -X POST "http://localhost:8080/v1/classify?mode=shadow" \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "Who won the Super Bowl?"}]}'The response body shows ALLOW. The X-Classification-Shadow: deny header shows what the model actually decided. Run in shadow mode until your confidence levels justify enforcement, then switch the query parameter.
Published Models
All three verticals are available on HuggingFace under Apache 2.0:
The full training pipeline, evaluation suite, adversarial test sets, gating reports, and Docker configurations are in the GitHub repository.
Conclusion and What's Next
IntentGuard is not trying to replace your LLM's system prompt. Both have a role. The system prompt shapes how the LLM behaves when it processes a query. IntentGuard decides whether the LLM should process the query at all.
The practical impact is significant. You get deterministic, auditable domain enforcement that does not drift with model updates. You get sub-30ms latency that does not add meaningful overhead to the user request path. You get policy-driven configuration that lets product and compliance teams tune behavior without touching model code. And you get the policy pack system, which extends the value beyond simple blocking into positive governance — telling downstream orchestration systems exactly which tools an allowed request should have access to.
All of it runs on CPU. No GPU required. Models are under 80MB. The whole stack is Apache 2.0.
Current development priorities include:
- Multi-turn context. The
context_windowfield in the policy already exists; the classifier currently uses only the last user message. Incorporating conversation history will improve handling of multi-turn jailbreak attempts that establish context across several turns before making the off-topic request. - Per-query threshold overrides. Letting callers pass threshold overrides in the request body, for use cases where different parts of the application surface warrant different risk tolerances.
- Streaming classification. Progressive decisions as tokens arrive, for latency-sensitive streaming pipelines.
- Richer router confidence. Currently the router takes the argmax of the vertical classifier. A calibrated confidence score for routing would let the system abstain on routing ambiguity, not just on intent classification.
The core problem IntentGuard addresses — domain enforcement for deployed LLMs — is not going away. If anything, as more organizations deploy production AI assistants in regulated industries, the need for deterministic, auditable topic boundaries will grow. A 22M parameter model making confident, margin-based decisions in under 30ms is a practical answer to that need.
Resources
- GitHub: perfecxion/intentguard — full source, training pipeline, evaluation suite
- HuggingFace: intentguard-finance
- HuggingFace: intentguard-healthcare
- HuggingFace: intentguard-legal