Executive Summary
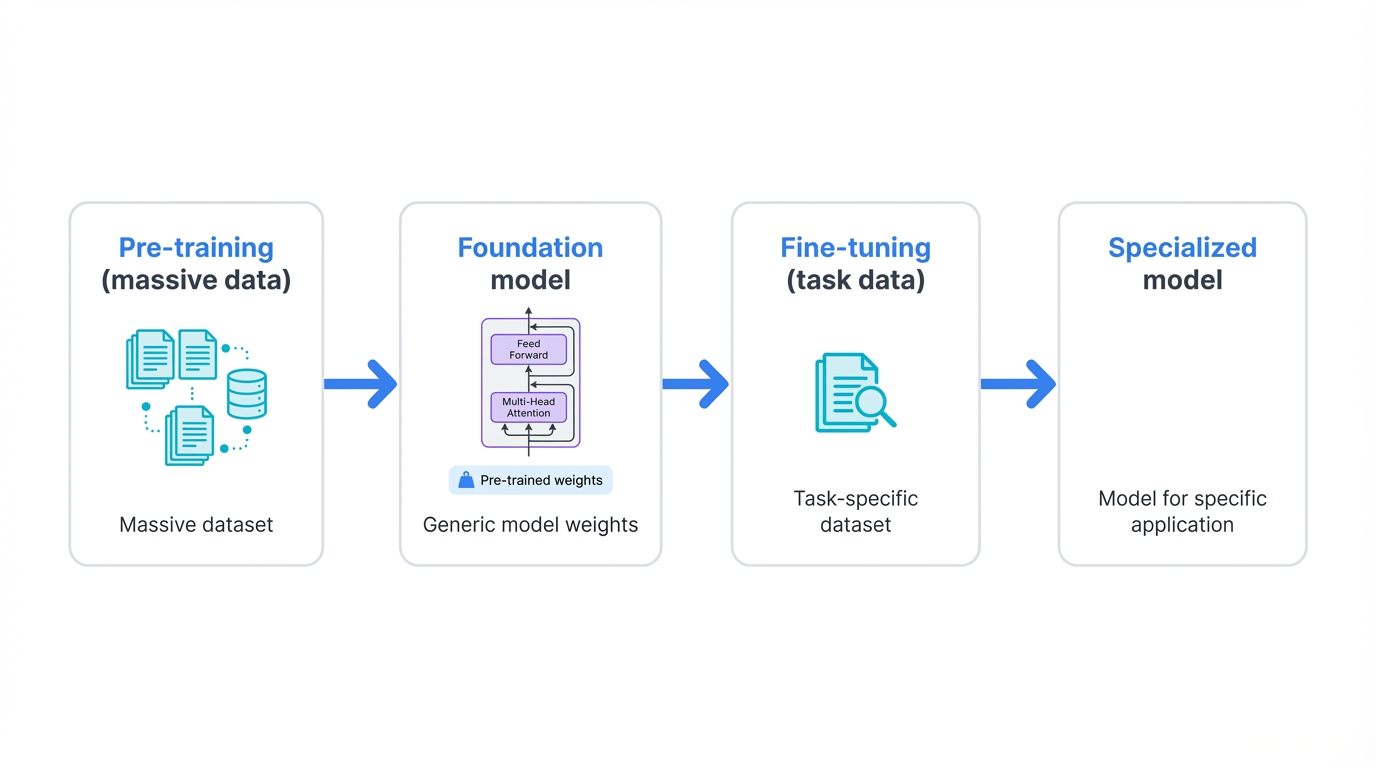
Fine-tuning changes everything. You start with a massive pre-trained model—one that already knows language, vision, whatever domain you're working in. Then you specialize it. Make it yours. The model brings general knowledge from its training on billions of data points, and you add the specific skills your application demands, using a dataset that's orders of magnitude smaller than the original training corpus.
Think about what this means. Training a large language model from scratch costs millions of dollars, requires thousands of GPUs running for months, and demands computational resources that put it out of reach for all but the largest organizations. Fine-tuning flips this equation entirely—you can adapt a foundation model to your specific use case in hours or days, often on a single GPU, using a dataset you can collect and curate yourself.
The landscape has evolved dramatically over the past few years, driven by the relentless growth in model size and the corresponding explosion in computational costs. Full fine-tuning—updating every single parameter in a billion-parameter model—still delivers exceptional performance, but at what cost? The hardware requirements are staggering. The training time is measured in days. The electricity bills are astronomical. This is where Parameter-Efficient Fine-Tuning (PEFT) enters the picture, offering a radical alternative that modifies less than 1% of a model's parameters while preserving most of the performance gains you'd get from full fine-tuning.
Key Insight: Fine-tuning teaches a model new skills and behaviors—how to write in your brand's voice, how to diagnose medical conditions from radiology reports, how to generate code following your team's conventions. RAG provides new knowledge—today's stock prices, the latest product specifications, information from your company's internal documentation. The distinction is fundamental: skills versus knowledge. Your strategic choice between these methods hinges on understanding this difference.
Section 1: The Principles of Model Adaptation and Fine-Tuning
Let's build the foundation. We need to understand how modern AI model specialization actually works—where fine-tuning fits in the bigger picture of transfer learning, what it does at a technical level, and how the mechanics operate under the hood.
1.1 From Pre-training to Specialization: The Role of Transfer Learning
Foundation models dominate AI today. BERT and GPT in natural language processing. ResNet and Vision Transformers in computer vision. These aren't just big neural networks—they're the product of intensive pre-training phases that consume staggering amounts of compute and data.
Picture what happens during pre-training. The model ingests massive datasets—vast swathes of the internet, extensive book collections, millions upon millions of images. It learns fundamental patterns, deep structural relationships, sophisticated representations of its domain. An LLM doesn't just memorize text; it develops a statistical understanding of grammar, syntax, semantics, and factual knowledge that spans human civilization's written output.
The computational cost is astronomical. Thousands of high-end GPUs. Weeks or months of continuous training. Energy consumption that would power a small city. Most organizations can't afford this—not even close. But here's the beautiful part: they don't have to, because the immense value of these models lies not just in their general capabilities but in their potential for specialization through transfer learning, and fine-tuning is transfer learning's most powerful weapon.
1.2 Defining Fine-Tuning: A Precise Formulation
What is fine-tuning, exactly? Take a pre-trained model—one that already knows its domain—and continue training it on your specific task using a new, much smaller dataset. You're updating the model's parameters, teaching it to specialize. That's it. Simple concept, profound implications.
The difference from training "from scratch" is night and day. A model trained from scratch starts with random weights—complete ignorance. It knows nothing about language, vision, or any domain structure. Every pattern, every representation, every capability must be learned entirely from your training data, which means you need massive datasets and enormous compute budgets just to get to baseline competence.
Fine-tuning is different. Fundamentally different. You begin with weights that encode sophisticated domain understanding—the accumulated knowledge from pre-training on billions of examples. These weights place your model in an excellent region of the solution space, giving you a powerful head start. You're not learning from zero; you're adapting and refining existing expertise for your specific purpose, which is why you can achieve remarkable results with datasets that would be laughably insufficient for training from scratch.
1.3 The Mechanics of Fine-Tuning: A Technical Deep-Dive
Let's get into the machinery. Fine-tuning succeeds or fails based on three pillars: data preparation, optimization management, and hyperparameter selection. Get these right and you'll see remarkable results. Get them wrong and you'll waste time and money on a model that performs worse than the pre-trained baseline.
The Role of Pre-trained Weights
Pre-trained weights are your starting point, and what a starting point they are. Neural networks have high-dimensional loss landscapes—imagine a terrain with billions of dimensions, filled with peaks, valleys, plateaus, and treacherous regions where gradient descent gets stuck or explodes. Random initialization drops you somewhere terrible in this landscape, a region of high error where the model's predictions are essentially noise. Pre-trained weights place you in a region of genuinely good performance, close to solutions that work, ready to take the final steps toward specialization.
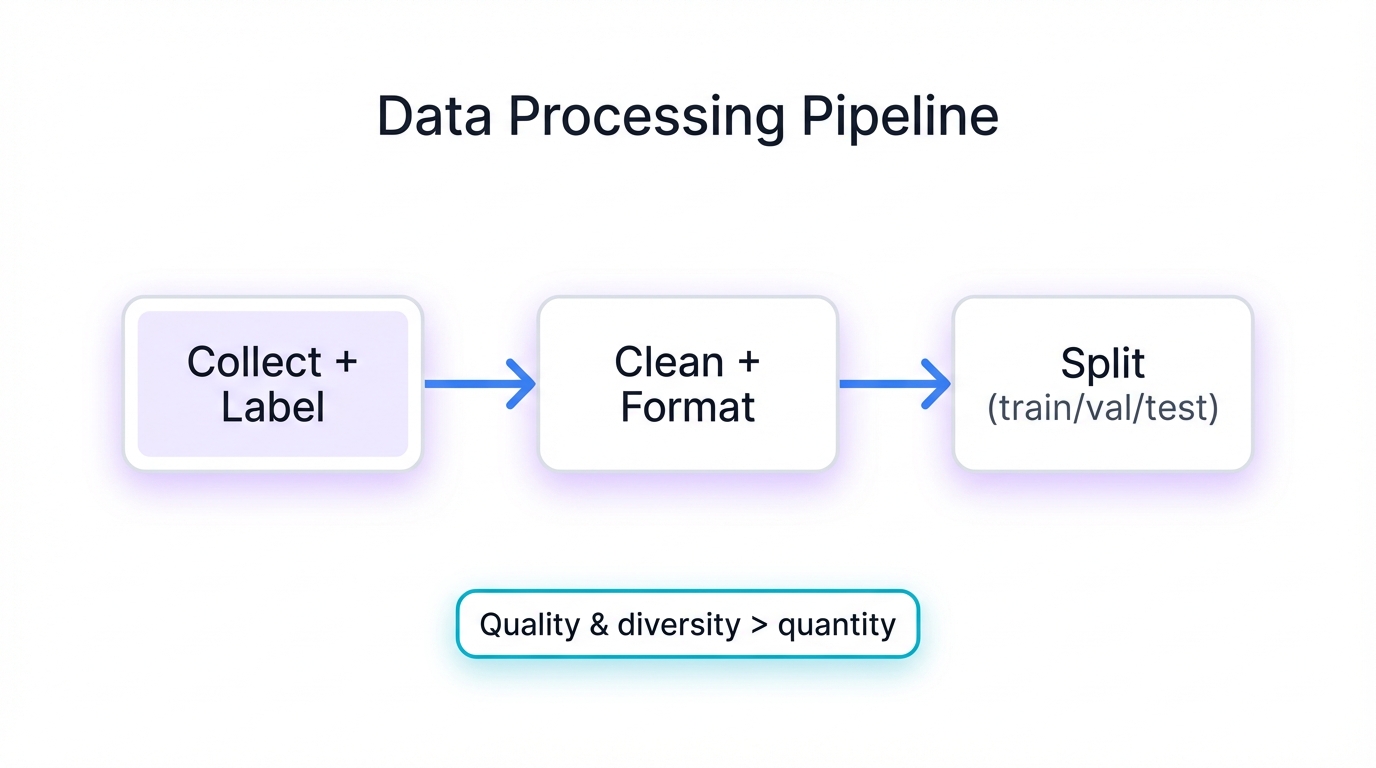
Data Preparation and Curation
Your dataset quality matters more than almost anything else. More than model architecture. More than compute budget. More than fancy optimization tricks. The process breaks down into distinct phases, each one critical:
- Data Collection and Labeling: Assemble examples relevant to your target task. For supervised fine-tuning, every example needs a label—the ground truth your model will learn to predict. This is where domain expertise becomes invaluable, because subtle labeling decisions can make or break performance.
- Data Cleaning and Formatting: Raw data is messy. Clean it ruthlessly—remove duplicates, fix inconsistencies, eliminate obvious errors. Then format everything to match your pre-trained model's input requirements, which means understanding tokenization for language models or image preprocessing for vision models.
- Data Splitting: Partition your dataset into training, validation, and test sets. The training set teaches the model. The validation set guides hyperparameter selection and early stopping decisions. The test set provides your final, unbiased performance estimate. Mix these up or skip this step and your performance metrics become worthless.
Critical: Quality and diversity beat quantity every single time. A carefully curated dataset of 1,000 diverse, accurately labeled examples will outperform 10,000 noisy, homogeneous ones. Focus on representative coverage of your task's complexity, edge cases, and variation. Your model can only learn patterns that exist in your data.
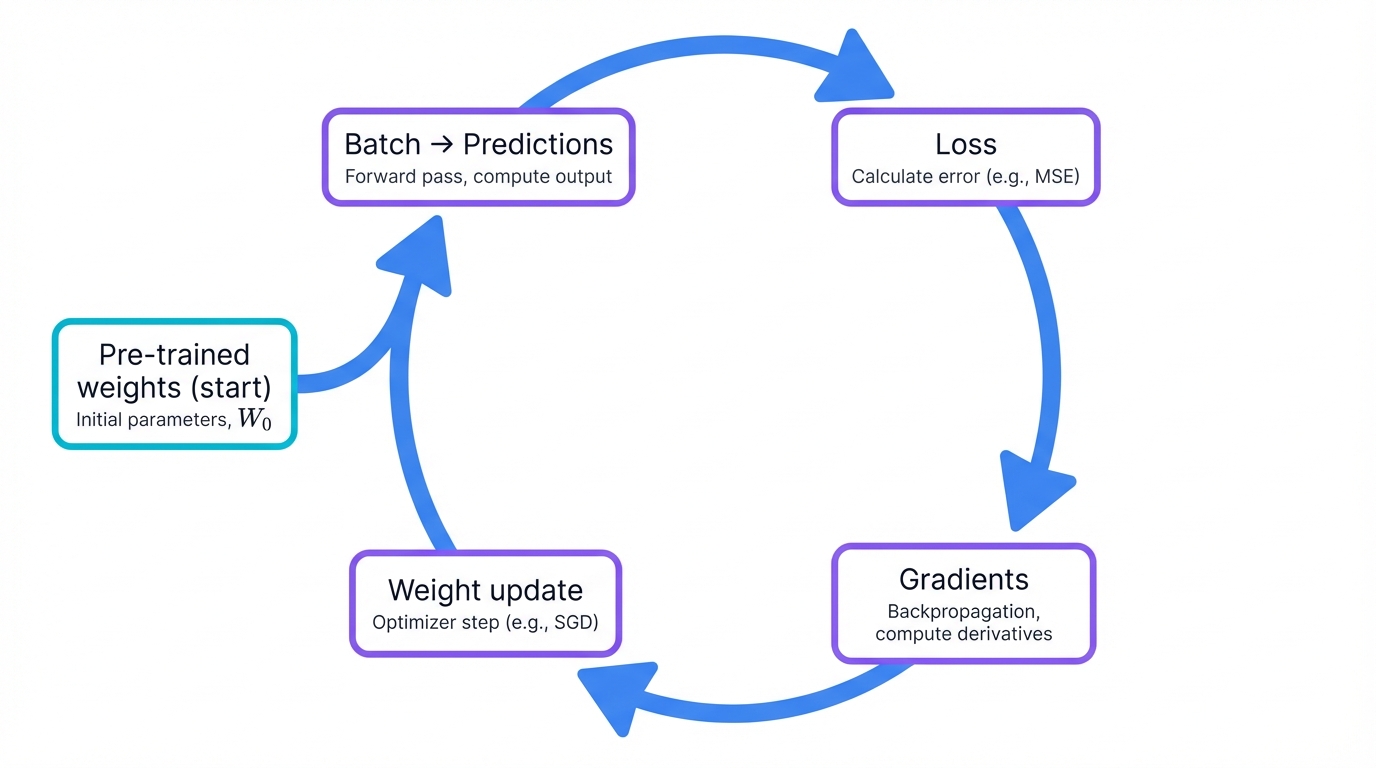
The Optimization Process
The optimization mechanics are identical to pre-training—we use variants of gradient descent, the workhorse algorithm of deep learning. The process runs in a loop, cycling through your training data batch by batch, making incremental improvements with each iteration:
- Feed a batch of data through the model to generate predictions
- Calculate error using a loss function that quantifies how wrong the predictions are
- Compute the gradient of this loss with respect to every weight in the model
- Update weights by moving in the direction opposite to the gradient—downhill toward better performance
This happens thousands or tens of thousands of times during fine-tuning, with the model gradually adjusting its weights to minimize errors on your specific task.
Hyperparameter Considerations
Hyperparameters control the optimization process, and getting them right is absolutely critical. The learning rate matters most:
- Learning Rate: This determines the size of each weight update step. Too high and you'll destroy the valuable knowledge encoded in pre-trained weights—a phenomenon called catastrophic forgetting where the model forgets what it learned during pre-training. Too low and training crawls at a glacial pace, possibly getting stuck in poor local minima. The sweet spot for fine-tuning is much lower than pre-training learning rates, allowing subtle, careful adjustments that preserve foundational knowledge while adding specialization.
- Batch Size and Epochs: Batch size affects both training speed and gradient quality—larger batches provide more stable gradients but require more memory. Epochs control how many times you cycle through the entire training dataset—too few and the model undertrains, too many and you overfit, memorizing training examples rather than learning generalizable patterns. Finding the right balance requires careful validation set monitoring.
Section 2: Strategic Imperatives and Applications of Fine-Tuning
We've covered the technical how. Now let's talk about the strategic why—the business value that makes fine-tuning indispensable, and the real-world applications transforming industries from healthcare to finance to customer service.
2.1 Core Benefits: Beyond Performance Metrics
Fine-tuning delivers strategic advantages that extend far beyond accuracy numbers on a benchmark. Let's examine what makes it essential for organizations deploying AI at scale:
- Resource Efficiency and Cost Savings: The economics are compelling. Training from scratch requires thousands of GPUs, weeks of time, and electricity bills that run into hundreds of thousands of dollars. Fine-tuning slashes these requirements by orders of magnitude—you can often achieve production-quality results on a single high-end GPU in hours or days, with costs measured in hundreds rather than hundreds of thousands of dollars.
- Improved Accuracy and Domain-Specific Relevance: Generic models produce generic outputs. Fine-tuned models understand your domain's nuances, terminology, and context. A legal AI fine-tuned on case law will outperform a generic model on contract analysis. A medical AI fine-tuned on radiology reports will catch diagnostic patterns that general-purpose models miss. This specialization translates directly to accuracy gains and contextually appropriate outputs that users trust.
- Data Privacy and Security: Your data stays yours. Fine-tuning lets you adapt models using proprietary data within your own secure infrastructure, never exposing sensitive information to external model providers. For healthcare organizations handling patient data, financial institutions processing transactions, or enterprises with competitive intelligence, this control is non-negotiable.
- Bias Mitigation and Control: Pre-trained models inherit biases from their training data, which often includes problematic patterns from internet-scale corpora. Fine-tuning gives you a lever to address these biases using carefully curated datasets that reflect your values. You can also align model outputs with brand guidelines, tone requirements, and organizational standards that generic models can't match.
- Enabling Continuous Learning: Markets evolve. Regulations change. New products launch. Fine-tuning lets you update your models periodically with fresh data without restarting the entire training process from scratch, enabling continuous improvement that keeps your AI aligned with current reality.
2.2 A Survey of Real-World Applications
Theory is nice. Practice is better. Let's look at where fine-tuning creates tangible value across industries and use cases.
Natural Language Processing (NLP)
- Customized Customer Service: Generic chatbots sound generic, which is death for customer experience. Fine-tune an LLM on your product documentation, support ticket history, and brand voice guidelines, and you transform that generic bot into an expert agent that understands your products intimately, speaks in your brand's voice, and resolves customer issues with the nuance and accuracy that builds loyalty.
- Domain-Specific Document Summarization: Legal documents have their own structure and jargon. Financial reports follow different conventions. Medical literature uses specialized terminology. A model fine-tuned on thousands of examples from your specific domain learns to generate summaries that capture what matters in your field, using the right terminology, emphasizing the right details, maintaining the appropriate level of technical precision.
- Targeted Sentiment Analysis: Customer reviews for restaurants differ from product reviews for enterprise software. Fine-tuning on your company's historical review data teaches the model to understand sentiment in your specific context—what constitutes praise versus complaint in your market, which features customers care about, how satisfaction manifests in the language your customers actually use.
Computer Vision
- Specialized Image Classification: Manufacturing defect detection. Medical image diagnosis. Quality control inspection. These high-stakes tasks demand precision that general-purpose vision models can't deliver. Fine-tune a vision transformer on your specific defect types, disease markers, or quality criteria, and you get a model that sees what matters, distinguishing subtle patterns that determine whether a product ships or gets rejected, whether a scan shows early disease or benign variation.
Generative AI and Code Generation
- Style and Tone Adaptation: Every brand has a voice. Every creative team has aesthetic standards. Fine-tuning generative models on examples of your specific style—whether that's marketing copy, product descriptions, or visual content—ensures generated output matches your brand identity rather than producing generic content that could come from anywhere.
- Specialized Code Generation: Your engineering team follows specific conventions, uses particular libraries, adheres to architectural patterns that matter in your codebase. Fine-tune a code generation model on your company's code repositories and documentation, and you create an AI coding assistant that generates code following your team's actual practices—the right variable names, the approved design patterns, the libraries you actually use, formatted the way your team expects.
Section 3: A Taxonomy of Fine-Tuning Methodologies
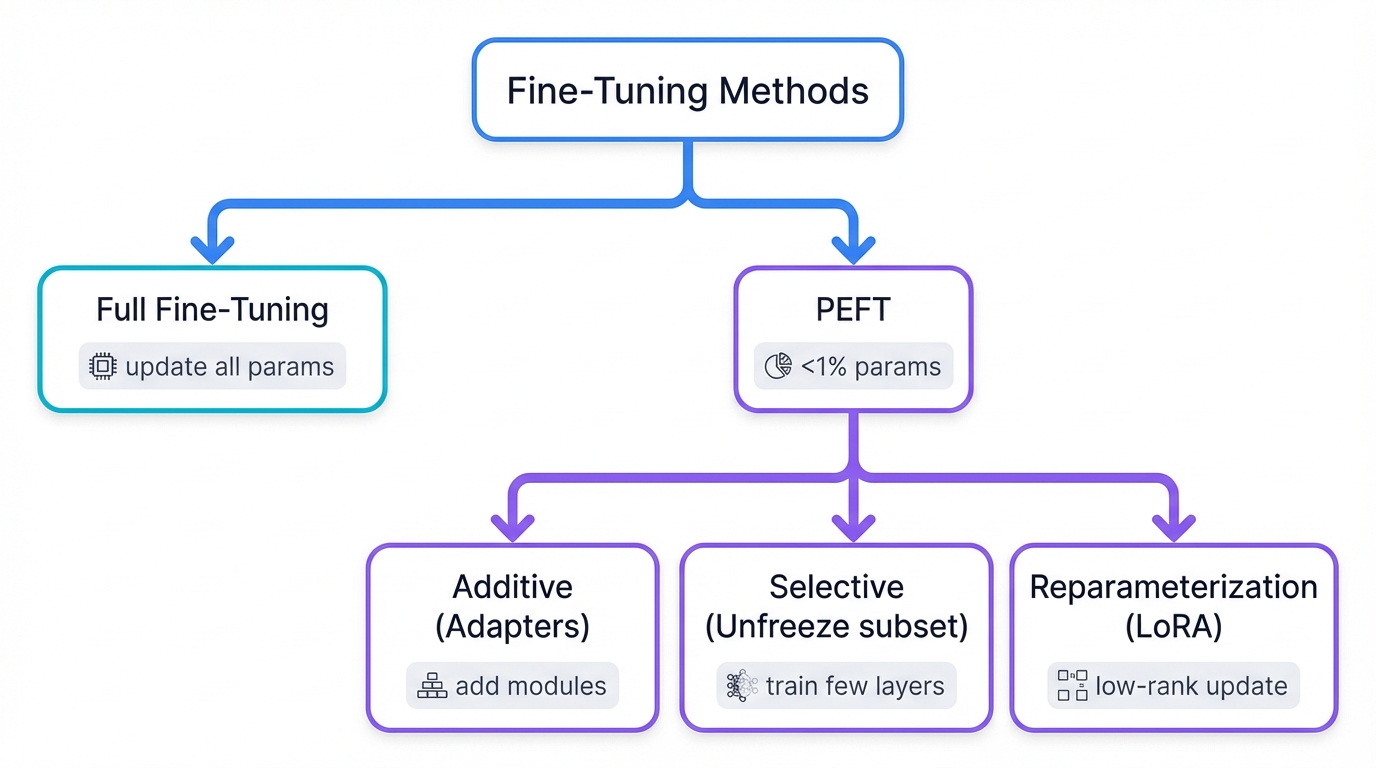
Fine-tuning isn't one technique—it's a family of approaches that have evolved from a simple, computationally expensive baseline into sophisticated methods that balance performance against efficiency, storage, and practicality.
3.1 Full Fine-Tuning: The Foundational Approach
Full fine-tuning is conceptually simple: update every single parameter in the model. All billion-plus weights get adjusted during training on your task-specific dataset. This comprehensive approach sets the performance benchmark—it's hard to beat the accuracy you get from full-parameter updates. But the costs are brutal:
- Prohibitive Resource Requirements: Training a billion-parameter model requires immense GPU memory and computational power. You need high-end hardware—multiple A100s or H100s—and the electricity costs alone can run thousands of dollars per training run. Most organizations simply can't afford this infrastructure.
- Large Storage Footprint: Every downstream task requires storing a complete copy of the entire model. Fine-tune for customer service, medical diagnosis, and code generation, and you're storing three full copies of a multi-gigabyte model. Storage costs multiply fast, and deployment complexity scales with the number of specialized models you maintain.
- High Risk of Catastrophic Forgetting: When you update all parameters, you risk overwriting the foundational knowledge that makes pre-trained models valuable in the first place. Push the learning rate too high or train too long, and the model forgets general capabilities while learning your specific task—a particularly insidious problem because performance on your validation set might look great while general performance degrades catastrophically.
3.2 The Advent of Parameter-Efficient Fine-Tuning (PEFT)
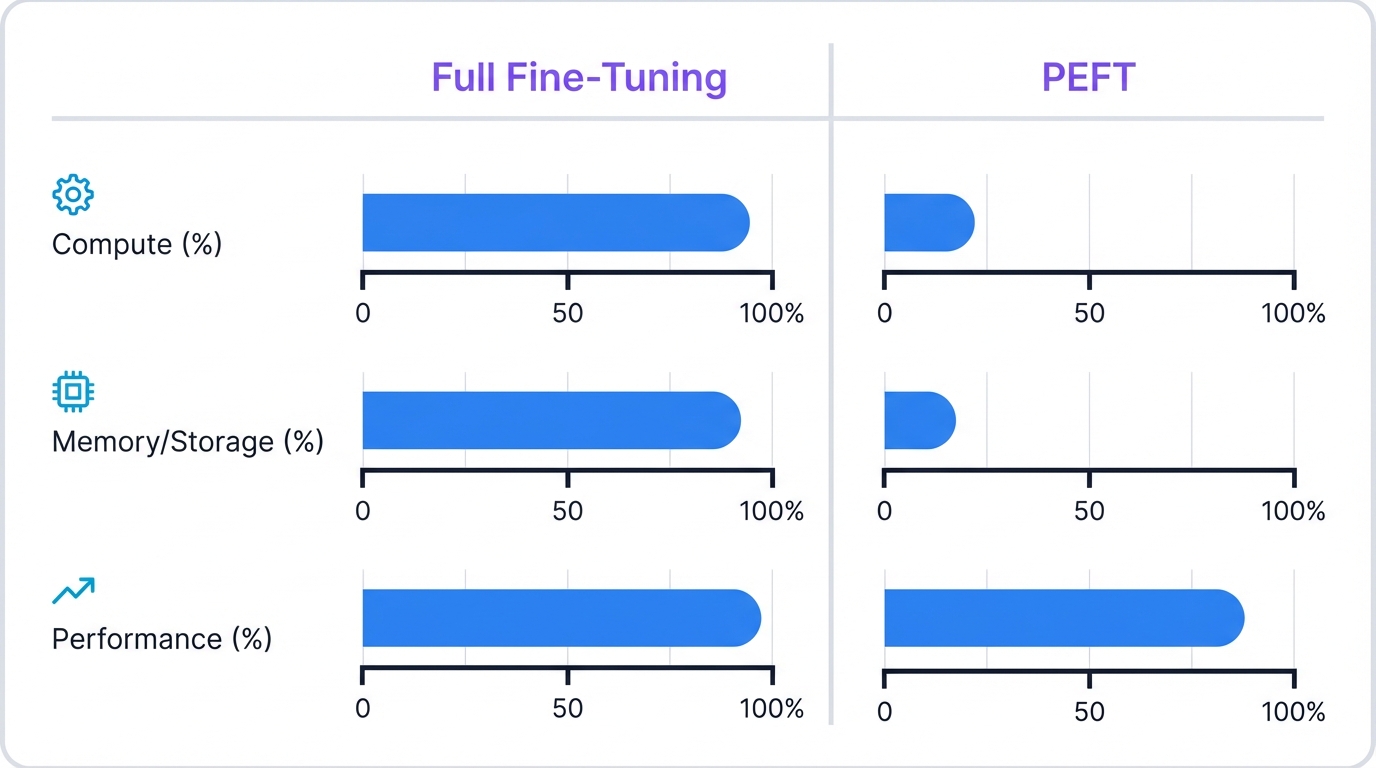
PEFT changes the game. The fundamental insight is radical: you don't need to update every parameter to achieve excellent performance. Update just a tiny fraction—sometimes less than 1%—and you can match or approach the accuracy of full fine-tuning while slashing computational costs, memory requirements, and storage footprints by orders of magnitude.
Think about what this means in practice. A 7-billion parameter model trained with full fine-tuning requires updating all 7 billion weights, demanding massive GPU memory just to store the gradients and optimizer states during training. With PEFT, you might update only 7 million parameters—0.1% of the total—fitting comfortably on consumer hardware while achieving 95% or better of full fine-tuning's performance. The storage benefits are equally dramatic: instead of storing multiple complete model copies, you store the base model once and tiny adapter modules for each task, reducing storage from gigabytes per task to megabytes.
PEFT methods divide into distinct categories based on how they achieve parameter efficiency:
- Additive Methods: Keep the original model frozen completely and add new, trainable components like Adapter modules that learn task-specific transformations.
- Selective Methods: Keep most parameters frozen but carefully unfreeze a small subset of strategically chosen weights for updating.
- Reparameterization Methods: Represent weight updates using lower-dimensional matrix decompositions like LoRA, dramatically reducing the number of trainable parameters needed to capture task-specific adaptations.
3.3 In-Depth Analysis of Key PEFT Techniques
3.3.1 Additive Methods: The Adapter Module
Adapters are elegant. You insert small, trainable neural network modules into the architecture of your pre-trained model—typically between layers of a Transformer. The original model weights stay frozen, completely untouched. Only the adapter parameters train, learning task-specific transformations while preserving all the foundational knowledge encoded in the pre-trained weights.
Technical Breakdown: A standard adapter implements a "bottleneck" architecture—a feed-forward network with two linear layers and a non-linearity between them. The first layer projects the input from its high dimension (say, 768 or 1024 for typical Transformer hidden states) down to a small bottleneck dimension (often 64 or 128). The second layer projects back up to the original dimension. A residual connection wraps around the entire adapter, allowing gradients to flow and ensuring the adapter can learn to modify the representation or simply pass it through unchanged if that's what the task requires.
3.3.2 Reparameterization Methods: Low-Rank Adaptation (LoRA)
LoRA dominates the PEFT landscape, and for good reason. The core insight is beautiful: during fine-tuning, the updates you make to weight matrices have low intrinsic rank—meaning they can be represented accurately using low-dimensional decompositions. Why update a million parameters when you can capture the same adaptation with thousands?
Technical Breakdown: LoRA freezes the original pre-trained weight matrix W completely—it never changes. Instead, we represent the weight update ΔW as the product of two much smaller matrices: ΔW = BA. During fine-tuning, only matrices B and A are trained, learning the task-specific adaptation while the foundation model weights stay pristine.
Efficiency: The math is compelling. Consider a weight matrix W with dimensions d×k—say, 1024×1024 for a typical attention layer. That's over a million parameters. Now decompose the update into matrices B (d×r) and A (r×k) where r is the rank, typically 8, 16, or 32. The LoRA matrices contain only (d+k)×r parameters. For our example with r=16, that's (1024+1024)×16 = 32,768 parameters—a 97% reduction. Train ten times faster, use a fraction of the GPU memory, store adapters that are tiny compared to the full model.
Critical Advantage: After training, you can merge the LoRA matrices with the original weights mathematically—just compute W + BA and you have a single weight matrix that incorporates both the pre-trained knowledge and your task-specific adaptation. This merger means zero additional inference latency. The fine-tuned model runs exactly as fast as the base model, with no computational overhead whatsoever. This property drives LoRA's widespread adoption in production systems where latency matters.
3.3.3 Soft Prompt-based Methods: Prefix-Tuning
Prefix-tuning takes a radically different approach. The entire pre-trained model stays frozen—every single weight. Instead, you prepend a sequence of continuous, trainable vectors to the input or to the hidden states at each Transformer layer. These vectors aren't discrete tokens from the vocabulary; they're "soft prompts" that live in the continuous embedding space, learning during training to steer the model's behavior toward your task.
The model learns to condition its entire operation on this learned prefix. Think of it as teaching the model a special control signal that modifies how it processes subsequent input, without touching the weights that actually do the processing. The prefix becomes a compact encoding of task-specific instructions, often requiring only a few dozen to a few hundred trainable vectors—representing an even smaller parameter count than other PEFT methods, though with a tradeoff in optimization difficulty.
| Methodology | Core Mechanism | Parameters Modified | Inference Latency | Key Advantage | Key Disadvantage |
|---|---|---|---|---|---|
| Full Fine-Tuning | Updates all weights | 100% | None | Highest performance | Prohibitive cost, catastrophic forgetting |
| Adapters | Inserts bottleneck layers | 0.5-8% | Increased | High modularity | Introduces inference latency |
| LoRA | Low-rank matrices (BA) | <1% | None (mergeable) | No latency, high performance | Sensitive to rank hyperparameter |
| Prefix-Tuning | Soft prompt vectors | ~0.1% | Minimal | Highly parameter-efficient | Difficult to optimize |
Section 4: Alternatives to Weight Modification: In-Context Adaptation
Fine-tuning modifies weights through training. But what if you could change model behavior without training at all? A powerful set of techniques adapts models "in-context" at inference time, achieving remarkable results without touching a single parameter.
4.1 Prompt Engineering: Guiding Models Without Training
Prompt engineering is communication. You're talking to the model, and how you phrase your request dramatically affects what you get back. Instead of retraining, you craft input text that elicits exactly the output you want. Master this art and you can transform a generic model's behavior using nothing but carefully chosen words.
The techniques that work:
- Clarity and Specificity: Vague prompts get vague responses. Specific prompts get focused, useful output. "Summarize this document" produces generic summaries. "Summarize this legal contract's liability clauses in 3 bullet points, highlighting financial exposure" produces exactly what you need.
- Role-Playing: Tell the model to act as an expert, and it shifts its entire output style. "You are a senior software architect reviewing code for security vulnerabilities" produces different analysis than "You are a junior developer learning about security." The persona influences tone, technical depth, and the aspects the model emphasizes.
- Context and Constraints: Feed the model relevant background information and explicit constraints. "Given these company style guidelines: [guidelines], and these product specifications: [specs], write marketing copy for our new feature" produces on-brand, accurate content. Context shapes understanding; constraints guide output format and scope.
- Chain-of-Thought (CoT): Ask the model to "think step-by-step" before answering, and watch complex reasoning improve dramatically. CoT prompting encourages the model to break problems down, show its work, and arrive at better conclusions through explicit intermediate steps rather than jumping directly to potentially flawed answers.
4.2 Zero-Shot and Few-Shot Learning/Prompting
Large language models come pre-loaded with capabilities that you can access immediately, without any training or examples. This is zero-shot learning—ask the model to perform a task it's never explicitly been trained for, and it just... does it, leveraging the broad knowledge acquired during pre-training.
- Zero-Shot Learning: Give the model a task description with zero examples. "Translate this English text to French." "Classify this review as positive, neutral, or negative." "Extract named entities from this article." The model performs the task relying entirely on its pre-trained understanding of language, concepts, and patterns. No task-specific training required.
- Few-Shot Learning: Boost performance by providing a handful of examples—typically 1 to 5—directly in the prompt. Show the model the input-output pattern you want, and it learns the format on the fly. "Here are 3 examples of product descriptions in our brand voice: [examples]. Now write a description for this new product: [product]." The model picks up on the style, structure, and conventions from your examples, delivering output that matches the pattern without any parameter updates.
4.3 Retrieval-Augmented Generation (RAG)
Here's the problem with LLMs: their knowledge freezes at training time. GPT-4 doesn't know about events from last week. Your company's model doesn't have access to documents created yesterday. The training data is static, and the model's knowledge is bounded by what it saw during pre-training. RAG solves this by combining a generative model with an external information retrieval system, creating a hybrid architecture that grounds responses in real-time, up-to-date information.
How RAG works:
- User submits a query that triggers a search against an external knowledge source—your company's document database, a vector store of product specifications, a collection of recent news articles, whatever corpus contains the information you need
- The retrieval system finds relevant passages, documents, or data using semantic search, keyword matching, or hybrid approaches, then ranks and selects the most pertinent information
- Retrieved content gets dynamically inserted into the prompt as context—"Here are relevant documents: [retrieved passages]. Now answer this question: [user query]"
- The augmented prompt flows to the LLM, which generates a response informed by the retrieved information, combining its language generation capabilities with factual grounding from external sources
Primary Advantage: RAG provides real-time knowledge without retraining. Your customer support chatbot can answer questions using documentation updated this morning. Your research assistant can synthesize information from papers published last week. The model's generation capabilities remain constant, but its knowledge base stays current because you're retrieving information at inference time, not baking it into weights that would require expensive retraining to update.
4.4 Strategic Decision Framework: Fine-Tuning vs. RAG vs. Prompting
So which approach do you choose? The answer hinges on a fundamental question: are you trying to teach the model new skills, or provide it with new knowledge? This distinction cuts through complexity and points you toward the right solution.
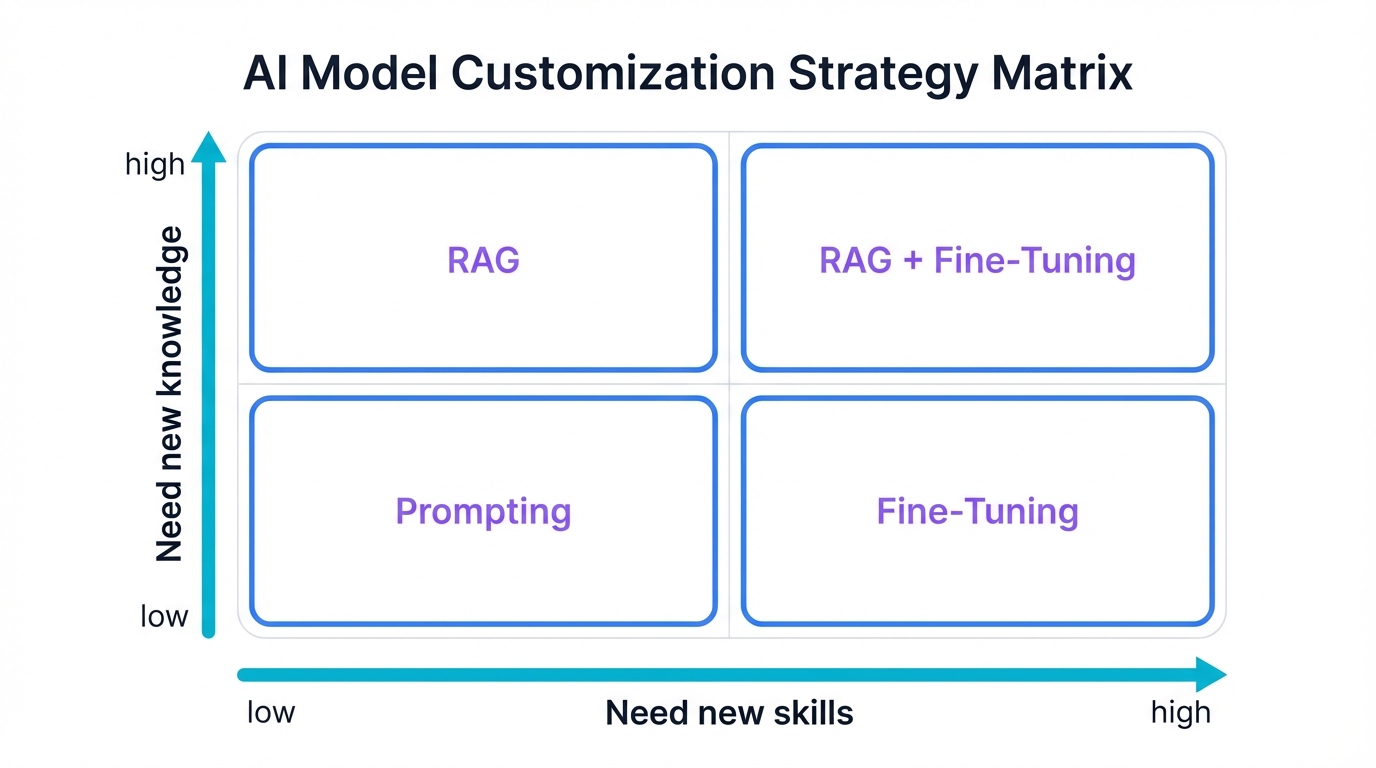
- Fine-Tuning for Teaching New Skills: Use fine-tuning when you need to change how the model thinks and processes information. You're modifying internal weights, rewiring the neural pathways that determine behavior, style, reasoning patterns, and domain-specific expertise. Examples: teaching the model to write in your brand's unique voice, to diagnose medical conditions following specific clinical protocols, to generate code matching your team's architectural patterns, to extract information from documents with domain-specific structure. Fine-tuning imbues capabilities that become intrinsic to the model's operation.
- RAG for Providing New Knowledge: Use RAG when the model has the skills but lacks the facts. You're not changing how it thinks; you're giving it access to information it couldn't possibly know from pre-training. The model already knows how to answer questions, summarize documents, and synthesize information—RAG feeds it the specific facts, figures, and current data it needs to apply those skills. Examples: answering questions about internal company policies, providing customer support based on constantly updating product documentation, synthesizing insights from the latest research papers, grounding responses in real-time data streams.
- Prompt Engineering for Leveraging Existing Skills: Start here. Always. Before you invest in fine-tuning infrastructure or RAG systems, see how far you can get with better prompts. The model already has remarkable capabilities—prompt engineering is the art of unlocking them through clear communication, clever framing, strategic examples, and well-designed instructions. Often you'll discover that what seemed like a model limitation was actually a prompting problem.
| Adaptation Strategy | Primary Goal | Data Requirement | Computational Cost | Knowledge Freshness |
|---|---|---|---|---|
| Prompt Engineering | Leverage existing skills | None | Negligible | Static (model's knowledge) |
| Few-Shot Prompting | Provide in-context examples | Few labeled examples | Negligible | Static |
| RAG | Inject new external knowledge | Unstructured knowledge base | Low (Inference only) | Real-time |
| PEFT | Teach new skill or style | Small labeled dataset | Moderate (Training) | Static |
| Full Fine-Tuning | Maximum adaptation | Medium-to-large labeled dataset | Very High (Training) | Static |
Section 5: Synthesis and Future Directions
5.1 A Holistic View of the Model Customization Landscape
Stop thinking in terms of either/or. Fine-tuning versus RAG versus prompt engineering is a false dichotomy. These techniques are complementary layers in a comprehensive adaptation stack, and the most sophisticated AI systems combine them strategically to leverage the unique strengths of each approach.
Think of it as a layered architecture:
- Prompt Engineering forms the foundation—your first line of adaptation, the most immediate and cost-effective way to shape model output. Master this before considering more complex approaches.
- RAG adds the knowledge layer, connecting your model to dynamic, external information sources. The model's skills remain constant, but its access to facts becomes unbounded, pulling from databases, documents, and real-time data streams.
- Fine-Tuning (especially PEFT) provides deep specialization, modifying the model's core behavior to master domain-specific skills, reasoning patterns, and stylistic nuances that can't be achieved through prompting alone. This is your precision instrument for teaching intrinsic capabilities.
Sophisticated Application: Picture a medical AI that combines all three layers. It's fine-tuned on thousands of radiology reports to master the skill of analyzing medical imaging descriptions and generating clinical summaries following proper medical documentation standards. It operates within a RAG system that retrieves relevant patient history, recent lab results, and the latest clinical guidelines. And it responds to carefully engineered prompts that specify exactly what information to emphasize for different audiences—detailed technical analysis for radiologists, accessible summaries for referring physicians, patient-friendly explanations for medical records. This is the power of layered adaptation: the right skills, operating on the right knowledge, guided by the right instructions.
5.2 Emerging Trends and the Future of Fine-Tuning
Model adaptation is evolving fast. Really fast. The field races forward, driven by two opposing pressures: models keep getting bigger, pushing computational requirements to absurd levels, while demand grows for even greater efficiency and performance. Watch what's emerging.
- Bridging the PEFT Performance Gap: Current PEFT methods are good, but they don't quite match full fine-tuning's performance ceiling. Novel techniques like LoRA-Pro and its successors aim to close this gap, developing parameter-efficient approaches that match or exceed full fine-tuning's accuracy while maintaining the efficiency benefits. The goal is ambitious: full fine-tuning performance at PEFT costs.
- Hybrid and Composable PEFT Methods: Why choose one PEFT technique when you can combine several? Emerging research explores hybrid strategies that apply different adaptation methods to different parts of the model—LoRA on attention layers, adapters on feed-forward networks, prefix tuning for task conditioning. This compositional approach could unlock performance gains beyond what any single technique achieves, with systems that dynamically select and combine PEFT methods based on task requirements and computational budgets.
- Automation and Optimization: Manual hyperparameter tuning is tedious and requires expertise. The next wave brings "auto-PEFT" frameworks that algorithmically determine optimal adaptation strategies and configurations. These systems will analyze your task, dataset, and constraints, then automatically select whether to use full fine-tuning, which PEFT method, what rank for LoRA, which layers to adapt, what learning rate schedules to apply—all the decisions that currently require expert judgment and extensive experimentation.
Foundation models will keep growing—100 billion parameters, then a trillion, then beyond. This scale makes efficient adaptation not just desirable but absolutely necessary. The principles and techniques we've explored, from full-parameter updates to cutting-edge PEFT innovations to complementary strategies like RAG and prompt engineering, will remain central to the enterprise of turning raw model potential into deployed systems that solve real problems. The challenge isn't building bigger models; it's mastering the art and science of tailoring them for specific needs while maintaining efficiency, performance, and responsible deployment practices.
Future Vision: The future of applied AI belongs to those who master adaptation. Not those who train the biggest models, but those who most effectively specialize foundation models for specific use cases, combining fine-tuning, RAG, and prompt engineering into sophisticated systems that balance performance, cost, latency, and accuracy. This is where the real value lies—in the careful, strategic application of adaptation techniques to create AI systems that don't just work well in research papers, but deliver tangible value in production environments where constraints are real and stakes are high.