Table of Contents
The Colored Spreadsheet Problem
Somewhere in your organization, there is an ATT&CK heatmap. Most of the cells are green. Leadership looks at it and concludes: "We have broad detection coverage."
That heatmap is almost certainly wrong.
CardinalOps analyzed over 13,000 detection rules across hundreds of production SIEMs. The average enterprise covers 21% of ATT&CK techniques. Of the rules that exist, 13% are broken - rules that will never fire due to disabled data sources, vendor log format changes, correlation chain failures, wrong operators, or lookback window mismatches. Not edge cases. The predictable result of deploying rules and never re-validating them.
The green cells mean "a rule is tagged to this technique." They do not mean the rule works.

Figure 1: The evidence hierarchy - most organizations stop at Level 1 (rule exists). Level 4 (fires on emulated behavior) is the minimum bar for coverage claims.
A tagged rule is not coverage. A passing syntax check is not evidence. Most organizations cannot produce proof that their detections work for a single technique on their heatmap. Their coverage is not measured. It is assumed.
The Parent vs. Sub-Technique Problem
Most ATT&CK coverage metrics are wrong for a very specific reason: they collapse sub-techniques into parent techniques.

Figure 2: Parent-level matching hides sub-technique gaps. The coverage map says DETECTED, but 5 of 6 sub-techniques are missed.
ATT&CK technique IDs have two levels. T1003 is "OS Credential Dumping" - the parent. T1003.001 through T1003.006 are the sub-techniques: LSASS Memory, SAM Database, NTDS, LSA Secrets, Cached Domain Credentials, DCSync. These are not the same attack. They use different tools, target different data stores, produce different telemetry, and require different detection logic.
Yet most coverage tools compare technique IDs at the parent level. The actual code from SANS SEC598's detection matching engine:
if used['technique'][:4].lower() == detection['techniqueidentified'][:4].lower():
overviewitem['numberofdetections'] += 1The [:4] slice truncates both sides to their first four characters. T1003.001 becomes T100. T1003.006 becomes T100. They match. The coverage map shows green.
But you only detect SAM database access. LSASS memory dumps, NTDS extraction, DCSync, LSA Secrets, and cached credential harvesting all go undetected. Five out of six sub-techniques are gaps. The parent cell is green.
This is a deliberate lab simplification. When the same logic drives production coverage claims, it produces systematically inflated metrics. MITRE flags this as Pitfall #2: "Most ATT&CK techniques are not Boolean. Scoring should thus be fine-grained."
Match at the sub-technique level. If your detection tags only the parent, your coverage is "partial" at best, and your evidence chain should say so.
The Evidence Hierarchy
Not all detection claims carry equal weight.
Level 1 - Rule exists. A rule is tagged to a technique and stored in a repository. This proves a rule was written. It proves nothing about whether it works.
Level 2 - Rule deploys. The rule converts, passes syntax validation, deploys without errors. A syntactically valid rule can still query a table that does not contain the expected data.
Level 3 - Rule fires on test data. Synthetic logs injected, rule alerts on positive cases, stays silent on negative cases. Proves logic correctness against known inputs. Does not prove it works against real adversary behavior.
Level 4 - Rule fires on emulated behavior. Atomic Red Team or Caldera executes the technique. The detection fires. Evidence includes alert ID, timestamp, rule name, matched technique. This is the minimum bar for claiming coverage.
Level 5 - Rule survives evasion. Red team bypasses with renamed binaries, alternative tooling, obfuscation. Detection still fires on the underlying behavior. The gold standard.
If you are operating at Level 1 or 2, your coverage metrics are meaningless. Most organizations are. They have rules. The rules deploy. Nobody has tested whether they fire. The heatmap reflects Level 1 confidence with Level 4 color coding.
What Evidence Actually Looks Like

Figure 3: Anatomy of an evidence chain - emulation record, query window, alert ID, match type, confidence, and reconciliation notes.
"Do we detect credential dumping?" requires more than "we have a Sigma rule for T1003." It requires:
1. Emulation record. Technique, tool, time, host. "T1003.001 via Atomic on HOST-A at 14:30:00Z."
2. Query window. Emulation start minus buffer through end plus detection wait. Telemetry has propagation delay.
3. Matching alerts. Alert IDs, rule names, detection source. "LC-2026-0847, 'LSASS Memory Access via Suspicious Process', 14:30:47Z."
4. Match type. Exact technique, parent technique, time correlation only, or no match.
5. Confidence. High (exact tag match in window), Medium (parent match), Low (time correlation only), None.
6. Reconciliation. "Matched parent T1003 for T1003.001. Rule does not distinguish LSASS from SAM access."
Most organizations cannot produce this chain for a single technique in their environment. Not because their teams are incompetent - because their tooling and processes do not generate evidence. They generate rules.
The Three Coverage Pitfalls
MITRE identified these. The industry continues to fall into all three.
Treating all techniques as equally important. You cannot detect everything. Prioritize by technique popularity (Red Canary heat maps) and threat actor relevance to your organization. Only 4 of the top 10 most-used techniques have active detections in the average SIEM. Start there.
Misjudging coverage as Boolean. You may detect one variant of PowerShell abuse but miss another. You may detect Mimikatz by hash but miss credential dumping via comsvcs.dll or nanodump. Coverage is a spectrum, not a checkbox.
Treating ATT&CK as complete. ATT&CK is the best framework available. It is not exhaustive. Novel techniques, environment-specific paths, and business logic abuse may not map to any technique. 100% ATT&CK coverage would not mean 100% protection.
The Validation Workflow
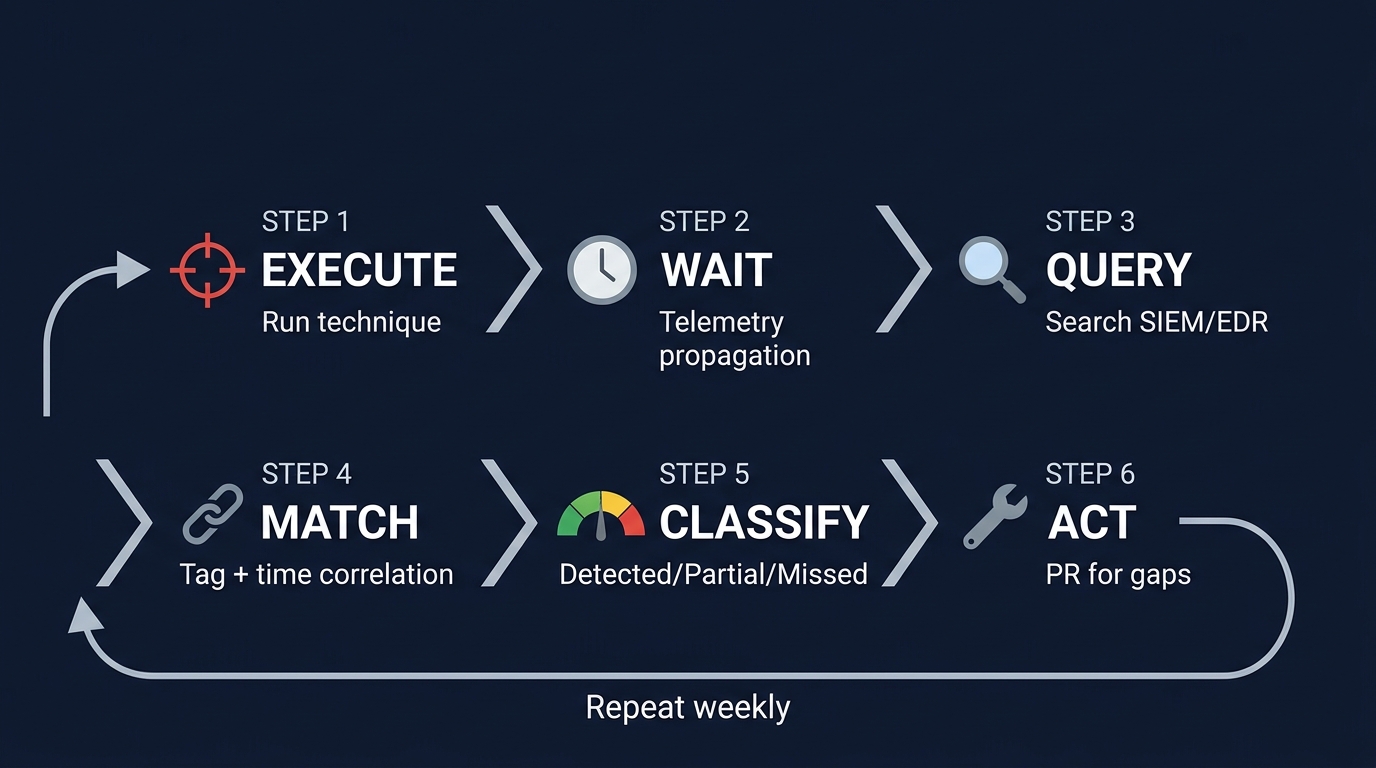
Figure 4: The 6-step validation workflow - Execute, Wait, Query, Match, Classify, Act - repeat weekly.
Execute. Run the technique with Atomic Red Team or Caldera. Record technique ID, tool, host, timestamps.
Wait. Telemetry propagation delay. 120 seconds is a reasonable starting point.
Query. Search SIEM/EDR using two methods: tag-based matching (regex \bt\d{4}\b on detection metadata) and time-window correlation (any alert on the target host within the window).
Match. Build the evidence chain. Alert ID, timestamp, rule name, matched tag, match type, confidence. For non-matches, record absence.
Classify. Detected, Partial, or Missed - with evidence, not just status.
Act. A missed technique becomes a detection engineering ticket with context already documented: "T1003.001 executed via Atomic at 14:30Z on HOST-A, no alerts within 5-minute window, review LSASS monitoring rules." Not a vague "improve T1003 coverage" task.
What Breaks in Practice
Telemetry gaps. If Sysmon logs process creation but not process access, your LSASS detection never fires regardless of rule quality. Evidence must account for telemetry availability, not just rule existence.
Schema drift. ProcessCommandLine renamed to InitiatingProcessCommandLine. The rule deploys. The coverage map is green. Zero results.
Tag inconsistency. t1003 vs T1003 vs attack.t1003.001. Matching must be flexible on format and strict on attribution.
Chained technique effects. SolarWinds/SUNBURST is the canonical example. Organizations had rules for the individual techniques - supply chain compromise (T1195.002), application layer protocol C2 (T1071), defense impairment (T1562). None fired. The malware's combination of dormancy, protocol blending, and defense tool detection defeated each rule independently. FireEye discovered it through manual anomaly observation, not automated rules. Log4Shell WAF rules were trivially bypassed by Log4j's own string manipulation lookups. Individual technique validation is necessary. Chain-level validation is where the real gaps hide.
From Evidence to Action
The output is not a heatmap. It is a structured dataset per technique: emulation method, timestamps, detection status, match type, confidence, alert IDs, gap context, reconciliation notes.
Three workflows consume this:
Detection engineering. Missed techniques become PRs with emulation context already documented.
Coverage reporting. ATT&CK Navigator layers generated from evidence, not rule tags. Every green cell has a proof chain behind it.
Trend tracking. Same validation weekly. Track improvement (missed to detected) and regression (detected to missed). Regression detection catches schema drift and rule breakage that turns green cells red without anyone noticing.
The Uncomfortable Question
Most security leaders have never asked: "For any technique on our coverage map, show me the alert ID that proves we detect it."
If your team cannot answer for five techniques, your coverage map is fiction.
Pick five techniques tomorrow. Run Atomic. Check if your detections fire. Write down the alert IDs. That is your first evidence chain. The automation, the pipeline, the dashboard - all of that scales from this foundation.
But the foundation is evidence. Not rules. Not tags. Not green cells.
If you cannot produce evidence, you do not have coverage. You have belief.
Scott Thornton is an AI Security Researcher at perfecXion.ai. This article draws on the SANS SEC598 detection validation lab, CardinalOps' Fifth Annual Report, MITRE's ATT&CK coverage guidance, and the SolarWinds/Log4Shell post-mortems.