Table of Contents
- From Defenses to Engineering
- The Memory Security Lifecycle
- Provenance You Cannot Forge
- Binding Authority to Origin
- The Information-Flow Catch
- Access Control and Multi-Tenancy
- Trust Scoring, Done Right
- Typed Memory and Source Monitoring
- A Reference Architecture
- What It Costs
- Conclusion: Separate the Data from the Authority
From Defenses to Engineering
Imagine an employee receives a routine-looking email. Buried in it is a line that convinces the company's AI assistant to "remember" a new billing address for a familiar vendor. Weeks pass. The email is long forgotten. Then, during an ordinary payment run, the assistant helpfully fills in the billing address it learned, and a legitimate payment is silently redirected to an attacker. Nothing was hacked in real time. No malware ran. The attack succeeded because the memory outlived the session that planted it.
This article explains how to build an agent memory architecture in which that attack simply cannot succeed.
An earlier piece argued that an agent's memory is an attack surface: persistent memory turns a one-session prompt injection into a compromise that survives for weeks and fires against a different user. It ended with a layered set of defenses. This article is about building them, and about why the obvious version of each one fails.
The obvious defenses do not survive contact with a real attacker. Input filters that look for "malicious-looking" content fail when the payload is fluent, enterprise-style prose. Trust scores based on what a memory says can be gamed by writing something that sounds trustworthy. Even tracking a memory's derivation history fails, because an agent's own normal operations (summarize, paraphrase, store) launder an untrusted origin into something that looks self-generated. Filtering treats memory poisoning as a content problem. It is not.
Here is the thesis this article defends: memory integrity is a chain-of-custody problem, and the authority for a stored memory to trigger a consequential action must be bound to a non-malleable, cryptographically-anchored origin. A poisoned memory can still be stored, retrieved, and read. What it must never acquire is the authority to move money, change a setting, or send data. Everything below is how you engineer that property.
The Memory Security Lifecycle
You cannot secure a process you have not mapped. The most useful frame for agent memory expands the write-manage-read loop into a full lifecycle and crosses it with the classic security objectives. Each cell is a place where a control belongs.
| Lifecycle phase | Integrity | Confidentiality | Availability | Governance |
|---|---|---|---|---|
| Write | Sign and origin-tag at the boundary | Classify sensitivity on ingest | Rate-limit writes | Record who/what wrote it |
| Store | Append-only, tamper-evident log | Encrypt at rest; per-tenant keys | Quota and eviction policy | Retention and legal hold |
| Retrieve | Verify signatures before use | Scope retrieval to the caller | Bound retrieval cost | Log every read |
| Execute | Origin-bound authority gate | Least-privilege tool scopes | Circuit breakers | Human-in-loop for high-risk acts |
| Share & Propagate | Preserve provenance across hops | ACLs across users/agents | Prevent propagation storms | Policy-governed sharing |
| Forget & Rollback | Verifiable deletion | Crypto-shred keys | Restore from clean state | Auditable forget requests |
The grid is the point. Security engineering for memory is not one clever filter; it is a control in each cell, chosen for the risk that cell carries. The rest of this article walks the high-leverage ones.
Provenance You Cannot Forge
Provenance is the foundation, and one distinction governs everything that follows: provenance is where a memory came from; trust is whether you believe it. Provenance is a recorded fact. Trust is a judgment you compute from it. The failure mode of naive systems is storing provenance as an ordinary, mutable field. If an attacker (or the agent itself) can rewrite the source field, provenance is theater.
Real provenance is cryptographic. Three primitives do the work:
- Content addressing. Identify each memory entry by the hash of its content, so any change to the content changes its identity. Tampering is detectable by construction.
- An append-only, tamper-evident log. Commit entries to a Merkle-structured log (the same construction behind certificate transparency, RFC 6962). You cannot quietly alter or delete a past entry without breaking the chain.
- Per-principal signatures. Sign each write with the key of the principal that performed it (for example, an Ed25519 key per user, per tool, or per agent). Now an entry carries unforgeable evidence of who wrote it.
Together these turn "the wiki said so" into "this entry was written by principal X at time T, has not been altered since, and here is the proof." The implementation is smaller than the theory suggests: a write signs the entry and commits it to the log; a read verifies before the entry is ever used.
def write_memory(content, principal, signing_key, log):
entry = {
"content": content,
"content_id": sha256(content), # content-addressed
"principal": principal.id, # who wrote it
"channel": principal.channel, # user | tool | document | agent
"written_at": now(),
"origin": principal.origin_tag, # bound at the boundary, immutable
}
entry["sig"] = sign(signing_key, canonical(entry)) # Ed25519 over the entry
log.append_to_merkle(entry) # tamper-evident, append-only
return entry
def load_memory(entry, log):
assert verify(entry["principal"], entry["sig"], canonical_without_sig(entry))
assert log.inclusion_proof(entry["content_id"]) # still in the log, unaltered
return entryOne caveat worth engineering for: signatures and logs protect entries you control, but memory snapshots get exported, migrated, and leaked, sometimes stripped of their metadata. For high-value deployments, attribution watermarking embedded in the memory-write decisions themselves can survive when the surrounding provenance fields do not. Tamper-evidence is not tamper-proofing; it guarantees you can detect alteration, not that alteration is impossible. That detection is what the next layer builds on.
The Information-Flow Catch
Honesty requires a complication, and it is the one most engineers miss. Provenance defenses check the records an agent retrieves. For graph-structured memory, that check can be bypassed without forging anything.
Consider a graph-based memory store. An attacker does not need to corrupt an authenticated record. They only need to manipulate the graph (its edges and relationships) so the retrieval engine selects the wrong authenticated records. Every fact the agent retrieves remains genuine and verifiably signed. The decision is still wrong, because the selection process was poisoned, not the records.
The lesson is that record-level provenance is necessary but not sufficient. You also need information-flow control: reasoning about how untrusted inputs influence outputs, not just whether individual inputs are signed. One strong formulation is the Cordon Principle: no component capable of final synthesis may directly consume untrusted natural-language evidence. Untrusted content can be retrieved, summarized, and bounded by a separate, lower-privilege stage, but the component that decides actions sees only sanitized, structured results. This closes the monitoring-control gap, the uncomfortable finding that a model can correctly detect a contradiction in poisoned evidence and still act on it. Detection is not control. Separation is.
Access Control and Multi-Tenancy
The previous article named six classes of memory by permission: read-only, writable, private, shared, organization, and system. Engineering them means giving memory a real access-control model, the same way a filesystem has one.
A concrete scenario shows why this is not optional. User A uploads a folder of HR documents, and the agent summarizes them into memory. Later, User B (a different employee, or a different tenant entirely) asks a question that is semantically similar to that HR content. With a naive vector store, the agent retrieves User A's HR memories and answers User B with them. That is a data breach, executed by similarity search, with no attacker involved at all.
Two models, used together, prevent it:
- ACLs and scoped retrieval. Every entry carries the principals and tenants allowed to read or write it. Retrieval is filtered by the caller's identity before similarity ranking ever runs, so User A's HR memories never enter the ranking stage for User B's query.
- Capabilities. The right to write to organization or system memory is a capability the caller must hold and present, not a default. Untrusted channels never hold write capabilities for shared scopes.
The important detail is the ordering: scope first, rank second. You never rank what the caller is not entitled to see.
def retrieve(query, caller, store, k=5):
# Scope BEFORE ranking: never rank what the caller cannot see.
visible = store.filter(lambda e: caller.tenant == e.tenant
and caller.id in e.acl.readers)
ranked = rank_by_similarity_and_trust(query, visible)
return ranked[:k]
def write_shared(entry, caller, scope):
if not caller.has_capability(f"write:{scope}"): # e.g. write:organization
raise PermissionError(f"{caller.id} cannot write {scope} memory")
entry.acl = acl_for(scope)
commit(entry)The non-negotiable is tenant isolation, and it is the mistake that does not forgive. A single-user agent makes the multi-tenant boundary look optional; it is not. Retrofitting isolation into a system designed as single-tenant is painful and error-prone. Build it in from the first commit: per-tenant partitions (ideally per-tenant encryption keys, so isolation is cryptographic and not merely a WHERE tenant_id = clause), and a zero-trust posture where no memory crosses a boundary without an explicit grant.
Sharing, when you allow it, needs its own primitives rather than a shared table: scoped retrieval, temporal supersession (newer facts override stale ones instead of coexisting), provenance preserved across every hop, and policy-governed propagation so one tenant's write cannot silently reach another's context. The same discipline extends to tools: as agents reach external systems over MCP, the tool manifests that can write to memory should themselves be cryptographically signed, freshness-checked, and policy-bound, so a swapped or stale manifest cannot become an unaudited write channel.
Trust Scoring, Done Right
Trust scoring has a place, but it is easy to misuse. Trust is the judgment layered on top of recorded provenance: you record, cryptographically, that an entry came from the internal wiki, and you compute, and later revise, how much to believe it, perhaps lowering it because the wiki is editable by contractors. A Bayesian update over provenance, content signals, and observed behavior is a reasonable way to maintain that score over time.
The constraint that keeps it safe is one line: use trust to order what the agent sees; use origin to decide what the agent may do. A trust score is a ranking input, not a source of authority. Letting a high score alone authorize a consequential action reintroduces exactly the content-based signal attackers control. In OWASP's Agentic Security Initiative terms, this whole discipline is the concrete answer to ASI06, memory poisoning.
Typed Memory and Source Monitoring
A quieter architectural defense is to stop storing memory as flat text. When raw evidence, retrieval cues, and truth-bearing claims all live as undifferentiated strings, the agent suffers source-monitoring errors: it treats a quote from an untrusted email as its own settled belief. Cognitive scientists call this provenance-role collapse, and it is a structural vulnerability, not a model flaw.
The fix is a typed memory representation that keeps the roles distinct: an entry separates the raw observed evidence (with its origin) from the retrieval cue (how it gets found) from any claim the agent has actually committed to as true. The agent can then reason differently about "an email claimed X" versus "X is true," because the types make the difference explicit and durable. Structure becomes a defense: you cannot collapse roles that the schema keeps apart.
A Reference Architecture
Assembled, the pieces form a pipeline where security is a property of the path, not a bolt-on:
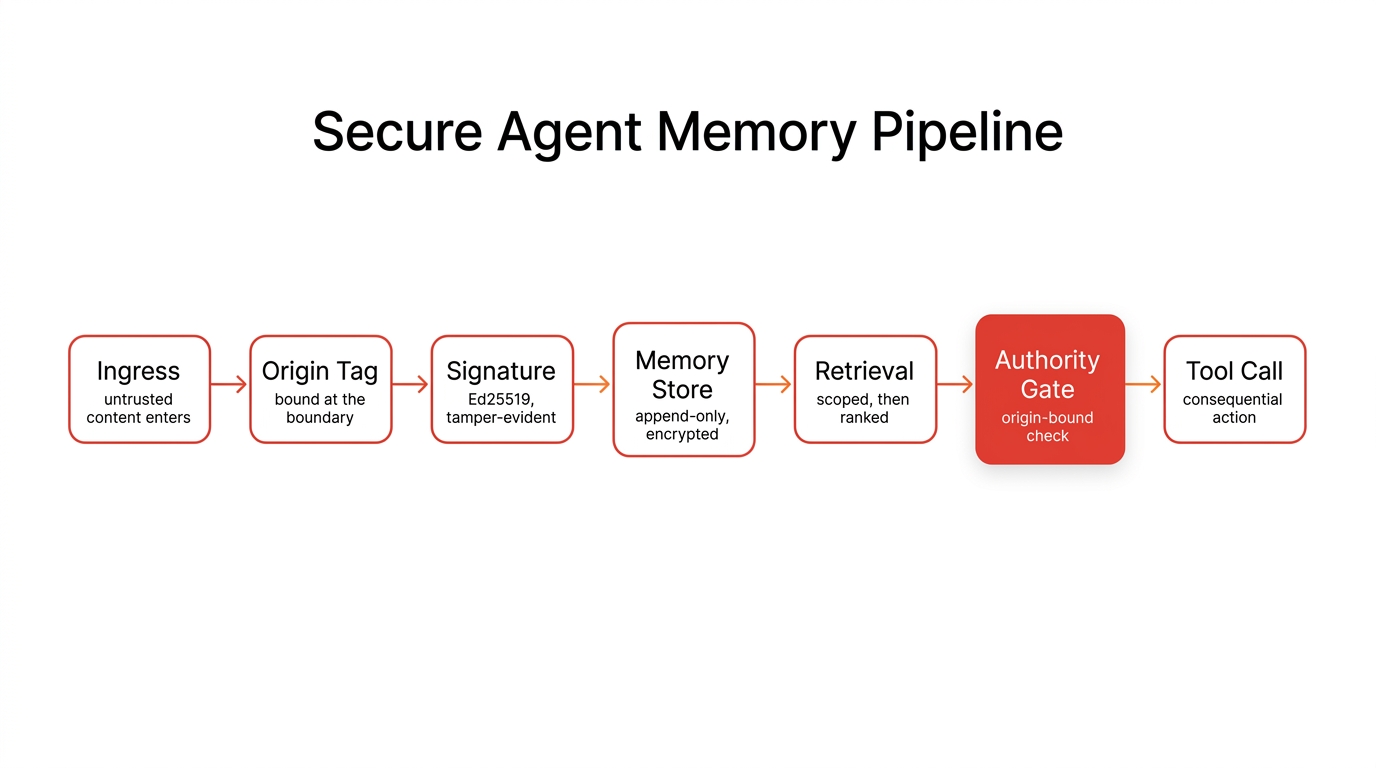
Figure 1: The secure memory pipeline. The authority gate stands between retrieved memory and any consequential action.
- Ingest (the boundary). Untrusted content is classified, origin-tagged, and the tag is bound immutably. Nothing downstream can rewrite it.
- Write. The entry is content-addressed, typed (evidence vs claim), signed by its principal, and appended to a tamper-evident log with its ACL and tenant.
- Store. Encrypted at rest with per-tenant keys; retention and forget policies attached.
- Retrieve. Scoped to the caller and tenant first, then ranked by similarity and computed trust; signatures verified before any entry is used.
- Reason. A lower-privilege stage may consume untrusted evidence; the component that selects actions sees only sanitized, structured results (the Cordon boundary).
- Act. Consequential actions pass an origin-bound authority gate at argument granularity; untrusted origin means block or human confirmation.
- Audit. Every write and read is logged immutably, so any action can be traced to the exact memory and origin that caused it.
A useful test of the design: pick any consequential action the agent can take and ask, "which memory authorized this, who wrote that memory, and could an untrusted party have influenced it?" If the architecture cannot answer crisply, it is not done.
What It Costs
None of this is free, and pretending otherwise produces systems teams turn off. Signing and verification add latency to every write and read. Provenance, logs, and per-tenant keys add storage and key-management burden. And defenses interact with utility: an always-on stack of every filter and check can cut a retrieval system's contextual recall by 40 percent or more, which is its own kind of failure.
So the engineering is not "enable everything." It is choosing controls per cell of the lifecycle grid, sized to the risk that cell carries. Cryptographic authority gating belongs on consequential actions, where the cost of being wrong is high and the action rate is low. Heavy per-read verification may be overkill for low-stakes recall and essential before a wire transfer. Reserve certified, machine-checked guarantees for the authority decisions that move money or data; use cheaper heuristics where a mistake is recoverable. Security engineering is the allocation of these controls, not the maximization of them.
Conclusion: Separate the Data from the Authority
We solved operating-system security, decades ago, by separating data from authority. A file you download is just bytes; it cannot do anything until something with privilege decides to act on it. That separation is what made operating systems securable at all.
Agent memory demands the same lesson, and it is the lesson the industry has not yet internalized. Memories are data. They can be poisoned, and you should assume some of them will be. Authority must come from somewhere else: from a non-malleable origin, checked at the moment of action, never from the content of a memory or the confidence with which it is stated. Anchor provenance in cryptography, isolate tenants from the first commit, keep the action-selector away from untrusted evidence, and bind authority to origin.
Until data and authority are separated, persistent memory will remain one of the largest attack surfaces in agentic AI. Separate them, and the poisoned entry becomes a contained nuisance: it can sit in the store, it can even be retrieved, and it still never earns the right to act.
Sources and further reading: "Securing LLM-Agent Long-Term Memory Against Poisoning: Non-Malleable, Origin-Bound Authority" (arXiv:2606.24322); MemLineage (arXiv:2605.14421); Portable Agent Memory (arXiv:2605.11032); "A Survey on Long-Term Memory Security in LLM Agents" (arXiv:2604.16548); Selection Integrity for Graph Memory (arXiv:2606.12290); Cordon-MAS (arXiv:2605.26754); Collaborative Memory (arXiv:2505.18279); Governed Shared Memory / MemClaw (arXiv:2606.24535); SuperLocalMemory (arXiv:2603.02240); typed memory / MemIR (arXiv:2605.25869); SMSR certified defense (arXiv:2606.12703); Verifiable Manifest Signing for MCP (arXiv:2601.23132); OWASP Agentic Security Initiative (ASI06, memory poisoning). Companion pieces: the agent memory explainer and the agent-memory attack-surface article.