Table of Contents
Most Detection Pipelines Validate Syntax, Not Detections
CardinalOps analyzed over 13,000 detection rules across hundreds of production SIEMs. The average enterprise covers 21% of MITRE ATT&CK techniques - despite ingesting enough telemetry to detect 90%+. The rules are not there. And of the rules that are, 13% are broken: non-functional due to misconfigured data sources, schema changes, or logic errors that nobody caught because nobody tested them.
That last number is the one that matters. Not the coverage gap - that is a prioritization problem. The broken rules. Those exist because someone wrote a detection, pasted it into a SIEM console, and never validated that it actually fires on adversary behavior. It passed a human eye test. It looked right. It was not right.
This is the central failure mode of modern detection engineering: treating syntax validity as operational validity. A rule can be well-formed YAML, valid Sigma, cleanly converted to KQL or SPL, deployed without errors, and still return zero results because it queries a table that does not contain the data it expects. Or worse - it fires on everything, drowning analysts in noise.
Detection-as-Code is the fix, but only if the pipeline validates detections, not just syntax. Most implementations stop at linting and deployment. The ones that work go further: they execute adversary techniques against their rules and prove, with evidence, that the detection fires. Everything else is a guess.
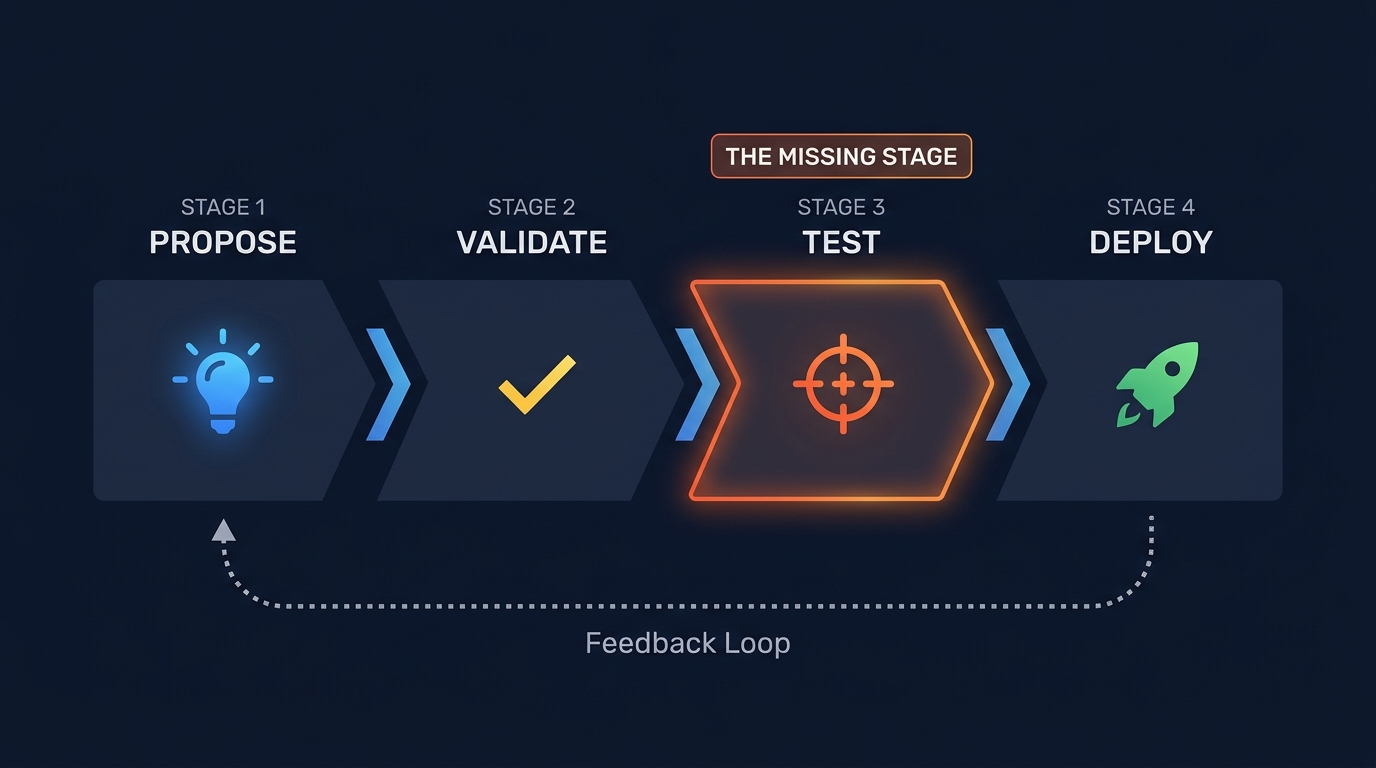
Figure 1: The Detection-as-Code pipeline has four stages. Most teams skip Stage 3: Test - the stage that actually proves detections work.
The Pipeline That Actually Works
Detection-as-Code means applying the full software engineering lifecycle to detection rules. Not "rules in Git" - that is version control. The pipeline has four stages, and the third one is where most teams stall.
Stage 1: Propose. A trigger arrives - threat intel, purple team gap, incident post-mortem, coverage analysis. An engineer creates a branch, writes a Sigma rule, opens a PR.
Stage 2: Validate. CI runs automatically. YAML lint. Sigma schema check. Duplicate UUID check. Backend conversion (does it compile to your SIEM's query language?). If you stop here, you have syntax validation. Necessary, not sufficient.
Stage 3: Test. This is the stage most pipelines skip. Execute the adversary technique the rule is supposed to detect. Inject test logs or run Atomic Red Team. Assert that the rule fires. Assert that it does not fire on benign variants. If the rule fails, the PR fails. This is Test-Driven Detection, and it is the difference between a detection engineering program and a YAML repository.
Stage 4: Deploy and monitor. Merge to main triggers API deployment to your SIEM. Track alert volume, true positive rate, and analyst feedback. Rules that consistently produce false positives or never fire get flagged for review automatically.
Here is a GitHub Actions workflow that implements stages 2 and 4. Stage 3 requires additional infrastructure (covered below).
name: Detection Rule Pipeline
on:
pull_request:
paths: ['rules/**', 'tests/**']
push:
branches: [main]
paths: ['rules/**']
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
- uses: actions/setup-python@v6
with:
python-version: '3.11'
- run: pip install sigma-cli pySigma pySigma-validators-sigmahq
- name: Validate Sigma rules
run: sigma check --fail-on-error --fail-on-issues rules/
- name: Check duplicate UUIDs
run: python scripts/check_duplicate_ids.py rules/
convert:
needs: validate
runs-on: ubuntu-latest
strategy:
matrix:
backend: [splunk, elasticsearch, kusto]
steps:
- uses: actions/checkout@v5
- uses: actions/setup-python@v6
with:
python-version: '3.11'
- run: pip install sigma-cli pySigma-backend-${{ matrix.backend }}
- run: sigma convert -t ${{ matrix.backend }} rules/ --output converted/
deploy:
needs: convert
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
environment: production
steps:
- uses: actions/checkout@v5
- run: python scripts/deploy_rules.py --url "$SIEM_URL" --token "$SIEM_TOKEN"
env:
SIEM_URL: ${{ secrets.SIEM_URL }}
SIEM_TOKEN: ${{ secrets.SIEM_TOKEN }}This is table stakes. The SigmaHQ project runs 13 workflows including regression testing and ATT&CK heatmap generation. Splunk open-sourced contentctl with matrix-strategy CI. Elastic publishes a DaC-Reference repo with three-stage pipelines. If the community maintaining 3,000+ Sigma rules enforces this discipline, your team with 50 rules can too.
Sigma: The Common Language
If you are writing the same detection separately for Splunk SPL, Elastic KQL, and Microsoft KQL, you are wasting engineering time. Sigma is the vendor-agnostic format that compiles to any target. Specification 2.0 (August 2024) supports 29 backends, and the SigmaHQ repository contains over 3,000 rules with ATT&CK mappings.
A real rule, from SigmaHQ - detecting password-protected archive creation for data exfiltration (T1560.001):
title: Compress Data and Lock With Password for Exfiltration With 7-ZIP
id: 9fbf5927-5261-4284-a71d-f681029ea574
status: test
description: |
An adversary may compress or encrypt data that is collected
prior to exfiltration using 3rd party utilities
author: frack113
date: 2021-07-27
tags:
- attack.collection
- attack.t1560.001
logsource:
category: process_creation
product: windows
detection:
selection_img:
- Image|endswith: ['\7z.exe', '\7zr.exe', '\7za.exe']
- OriginalFileName: ['7z.exe', '7za.exe']
selection_password:
CommandLine|contains: ' -p'
selection_action:
CommandLine|contains: [' a ', ' u ']
condition: all of selection_*
falsepositives:
- Legitimate use of password-protected archives
level: mediumThree named selections, AND-combined. Identifies 7-Zip by multiple attributes (binary path, original filename), then requires both a password flag and an archive action. An attacker who renames 7z.exe still gets caught by OriginalFileName. An attacker doing legitimate decompression does not trigger the archive-action check. Convert with one command:
sigma convert -t splunk -p splunk_windows rules/windows/proc_creation_win_7zip.ymlTest-Driven Detection: The Missing Stage
A Sigma rule that passes sigma check is not a working detection. It is a syntactically correct hypothesis about adversary behavior. Proving it requires execution.
Test-Driven Detection applies the Arrange-Act-Assert pattern from software engineering:
Arrange: Deploy the rule to a test environment. Define expected outcomes - which events should trigger an alert, which should not.
Act: Execute the technique. Invoke-AtomicTest T1560.001 runs the exact behavior your rule is supposed to catch. This is not optional. If you are not executing adversary techniques against your detections, you are not doing detection engineering - you are writing guesses.
Assert: Did the rule fire? On the right event? With the expected fields? The SEC598 framework defines three assertion levels: Observe (telemetry collected), Detect (alert fired correctly), Prevent (behavior blocked).
The infrastructure for this uses test log injection (Azure Log Ingestion APIs, Elastic's ingest pipelines, Splunk's HTTP Event Collector) to create a mirrored testbed where rules run against synthetic data without polluting production. The workflow:
- Write unit test defining expected log events and detection outcome
- Inject test logs into a test workspace via API
- Deploy the rule to the test instance
- Run the analytics engine
- Assert: rule fired (or correctly did not fire)
- Post results as a PR comment
When this is automated in CI, detection engineers get pass/fail feedback on every pull request - exactly like software developers running unit tests.
The advanced pattern closes the loop further. A SOAR platform executes a TTP. An LLM proposes a detection rule. The pipeline validates syntax, deploys to a test environment, re-executes the TTP, and checks if the rule fires. When it underperforms, the LLM is called again with the failure context - a self-healing detection loop. The human review step remains non-negotiable (more on this below).
The Purple Team Feedback Loop
Detection engineering that is disconnected from adversary emulation produces rules that detect yesterday's attacks. The feedback loop is what keeps rules current.
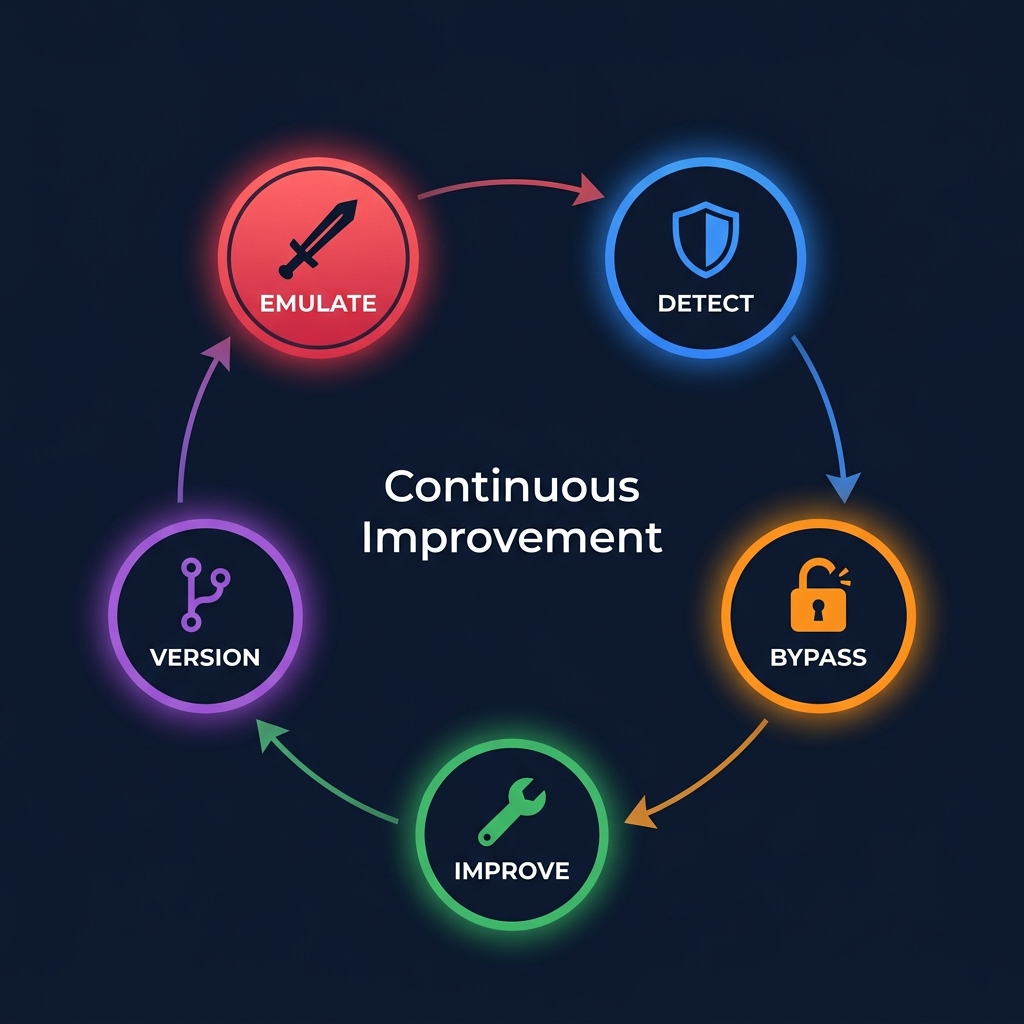
Figure 2: The purple team feedback loop: Emulate, Detect, Bypass, Improve, Version - continuous improvement through adversary-driven detection engineering.
A real progression, from SEC598:
Round 1: Red team runs Mimikatz lsadump::sam. Blue writes detection: CommandLine contains "mimikatz". Fires. Committed to Git.
Round 2: Red team renames the binary to notepad.exe. Detection misses. Gap filed.
Round 3: Blue rewrites the rule targeting the underlying behavior - LSASS memory access patterns, specific API calls, registry key access - rather than string matching on a binary name. New rule catches both the original technique and the evasion. Committed, versioned. Old rule superseded.
This cycle - emulate, detect, bypass, improve, version - is detection engineering operating correctly. It produces rules that resist evasion because they have been tested against an actual adversary, not a synthetic log sample.
The toolchain that recurs in mature programs: Atomic Red Team (execute techniques) + Sigma (write detections) + GitHub (version and deploy). AttackRuleMap bridges the gap by mapping Atomic test IDs directly to Sigma rule IDs - run T1560.001, see which Sigma rules should fire.
LLMs: Useful Drafters, Dangerous Deployers
LLMs are entering detection engineering, and the results are instructive. SOC Prime's Uncoder AI (trained on 1,000,000+ rules) can produce a reasonable first-draft Sigma rule in seconds. AttackIQ's SigmAIQ wraps pySigma with LangChain for automated generation. Microsoft's Security Copilot suggests detection logic in Defender. For well-documented techniques, the output is 70-80% correct.
The other 20-30% is where things break, and it breaks in a specific, predictable way.

Figure 3: The Context Problem: LLM-generated rules reference fields that don't exist in your environment. Syntactically valid. Operationally useless.
"The LLM nailed the logic but completely missed the context."
That observation from SEC598 captures the core failure mode. An LLM generates a KQL rule querying SecurityEvent with Sysmon field names. The logic is sound - it correctly identifies the behavior. But the target environment uses ASIM parsers that normalize data into different tables with different field names. The rule deploys, executes without errors, and returns zero results. It is a silent failure. The coverage map shows green. The detection does not work.
This is not a tooling issue. It is a fundamental limitation of stateless generation. LLMs cannot reason about:
- Your ingestion pipeline - which log sources are enabled, what preprocessing occurs, what fields survive normalization
- Partial telemetry - you may collect Sysmon EventID 1 but not 25, so a rule targeting ProcessTampering events will never fire
- Schema drift - field names change between SIEM versions, parsers get updated, new log sources replace old ones
- Environmental context - which servers run which roles, which accounts are service accounts versus human accounts, what constitutes normal behavior in your network
The fix is RAG (Retrieval-Augmented Generation) with environment-specific context: dynamically retrieve your actual table schemas, existing working rules, field names, and failed detection history before prompting the LLM. The SEC598 PurpleCrew project demonstrates this with a Detection Engineer agent that queries the Sentinel workspace schema via API before writing any KQL.
SOC Prime makes a design choice the rest of the industry should study: Uncoder AI is non-agentic. Every byte sent to an LLM is verified by the user first. This is not a limitation. It is a safety architecture.
Critical: LLM-generated rules must be reviewed by a human who knows the target environment. No exceptions. Automating this step is how you get the 13% broken rule rate, at CI/CD speed.
What Not to Automate
Detection-as-Code creates the temptation to automate everything. Resist these specific urges:
Auto-deploying untested rules. A rule that converts successfully to KQL is not a rule that should run in production. Conversion success means the query will execute. It does not mean it will produce meaningful results. Deploy to staging. Run against historical data. Validate before promoting.
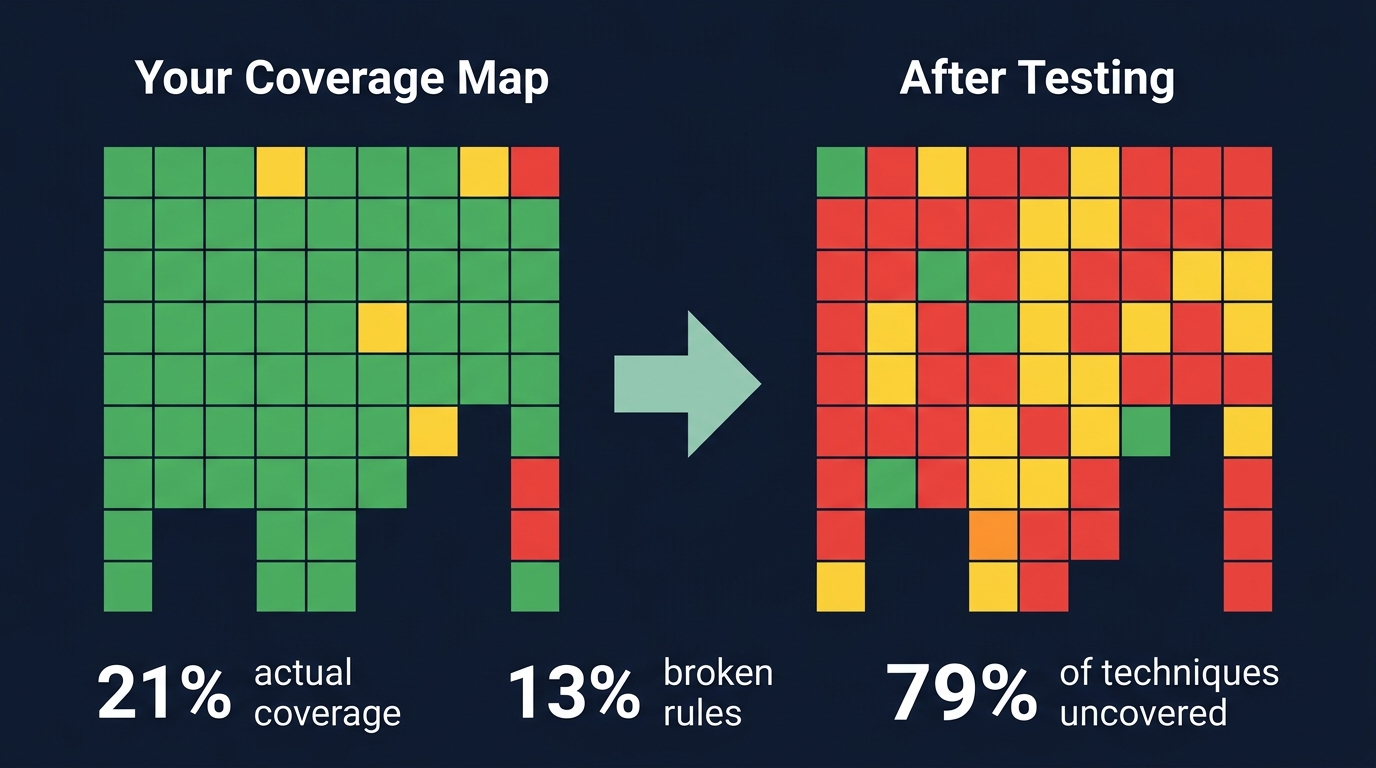
Figure 4: Your ATT&CK coverage map before and after testing. Most green cells turn red when you actually execute the techniques.
Trusting coverage maps. Having a rule tagged attack.t1059.001 does not mean you detect PowerShell abuse. The rule might be too narrow (one obfuscation pattern), too broad (every PowerShell execution), or broken (queries a deprecated field). A Sigma rule tagged to a technique is not coverage. A Sigma rule that passes TDD against Atomic Red Team is getting closer.
Treating syntax validity as operational validity. Your CI pipeline validates YAML syntax, Sigma schema compliance, backend conversion, and UUID uniqueness. It cannot validate - without TDD infrastructure - that the rule detects the intended behavior, stays quiet on benign activity, queries fields that exist in your environment, or performs acceptably at production volume. The first set of checks is table stakes. The second is where trust comes from.
Scaling rules without ownership. This is the failure mode nobody writes about. CI/CD makes it easy to ship detection rules. It also makes it easy to accumulate hundreds of rules that nobody is accountable for. When a rule starts producing false positives six months after deployment, who gets paged? When a schema change breaks 40 rules at once, who fixes them? A detection-as-code pipeline without a rule ownership model scales broken logic faster than manual processes ever could.
Getting Started
You do not need the full pipeline on day one.
Week 1-2: Pick 5 ATT&CK techniques that matter to your organization. Write Sigma rules. Set up a Git repo with sigma check in CI. You now have syntax validation and version history.
Week 3-4: Add backend conversion to your pipeline. Install Atomic Red Team in a test environment. Manually run the 5 techniques and verify your rules fire. You now have validation evidence.
Week 5-8: Script your SIEM's API for deployment. Build a staging gate. Connect purple team findings to the pipeline as GitHub issues. You now have a working pipeline.
Ongoing: Track rule performance. Build the TDD infrastructure. Evaluate LLM-assisted drafting once your testing infrastructure can catch the failures. The LLM accelerates the drafting step. The pipeline catches the context problems.
The Engineering Problem
The detection gap is not a technology problem. SIEMs ingest enough data to detect 90%+ of ATT&CK techniques. Sigma has 3,000+ public rules and 29 backends. Atomic Red Team is open source. Every major SIEM supports API-driven rule management. GitHub Actions is free for public repos.
The gap is engineering discipline. Most organizations manage detection rules the way software was managed in the 1990s - manual changes, no testing, no review process, no deployment pipeline, no feedback loop. The result is predictable: broken rules, coverage gaps, false positive floods, and analyst burnout.
If your detections are not tested, they are not detections. They are assumptions. And assumptions, deployed at scale through a CI/CD pipeline without validation, are just organized optimism.
Scott Thornton is an AI Security Researcher at perfecXion.ai, focused on defensive security engineering and AI/ML systems. This article draws on the SANS SEC598 course, industry data from CardinalOps, IBM, and Vectra AI, and the open-source detection engineering community.