Introduction to the Principles of Code Comparison
Compare two programs. Simple, right? Wrong. This process—called "diffing"—has evolved dramatically from basic text comparison to sophisticated binary analysis that would make your head spin. You need to understand this evolution. It reveals the core challenges of binary analysis and gives you a framework for mastering the advanced techniques we'll explore throughout this guide.
Key Concept: Master this foundational concept now. You'll need it for everything that follows in this article, and without this understanding, the advanced techniques will remain frustratingly opaque.
The Foundation: diff and patch in Source Code
Diffing begins with source code. The Unix 'diff' utility compares text files line by line, and it's brilliant in its simplicity. It solves the longest common subsequence problem, identifying the minimal set of changes—deletions, additions, modifications—needed to transform one file into another, and if you've ever used version control, you've benefited from this mathematical elegance whether you realized it or not.
Early diff outputs were fragile. The "Normal" format specified line numbers and changes, but if you made other changes elsewhere in the file, shifting those line numbers, the whole thing broke. Engineers fixed this with "Context" and "Unified" formats that include unchanged lines—context—around each modification. Much more reliable. Much more robust against the chaos of real-world development.
Key Insight: You must distinguish signal from noise. The intended change is your signal, while shifting line numbers and unrelated modifications create noise that obscures what actually matters, and this principle becomes absolutely critical when we move from source code to compiled binaries where the noise can drown out everything else.
The Binary Challenge: From Lines of Text to Executable Code
Source code comparison works beautifully. Binary comparison? That's where things get messy. Line-oriented techniques fail completely when you're comparing compiled executables, and the reason comes down to what we call the asymmetry problem: change one small thing in your source code—one line, one function call—and watch as the compiled binary explodes with cascading changes that ripple through the entire executable in ways that seem completely disproportionate to your original modification.
Compilers cause this chaos. Every time you compile your code, the compiler makes thousands of decisions that a single source code change can influence in unpredictable ways:
Register Allocation
Your compiler picks different registers—RAX instead of RDX, RCX instead of RSI—to store variables, and these choices change the actual bytes in your executable even when the logic remains identical.
Instruction Selection
The compiler chooses between semantically equivalent instruction sequences—xor eax, eax versus mov eax, 0—that produce identical results but look completely different in the binary.
Code Layout
Functions and basic blocks get rearranged in memory, completely altering the arrangement and ordering without changing what the program actually does.
A Framework for Comparison: The Abstraction Ladder
We organize analysis techniques along an "abstraction ladder." Climb from concrete to abstract. Move from bytes to meaning. Progress from representation to semantics, and at each level, you trade computational simplicity for analytical power:
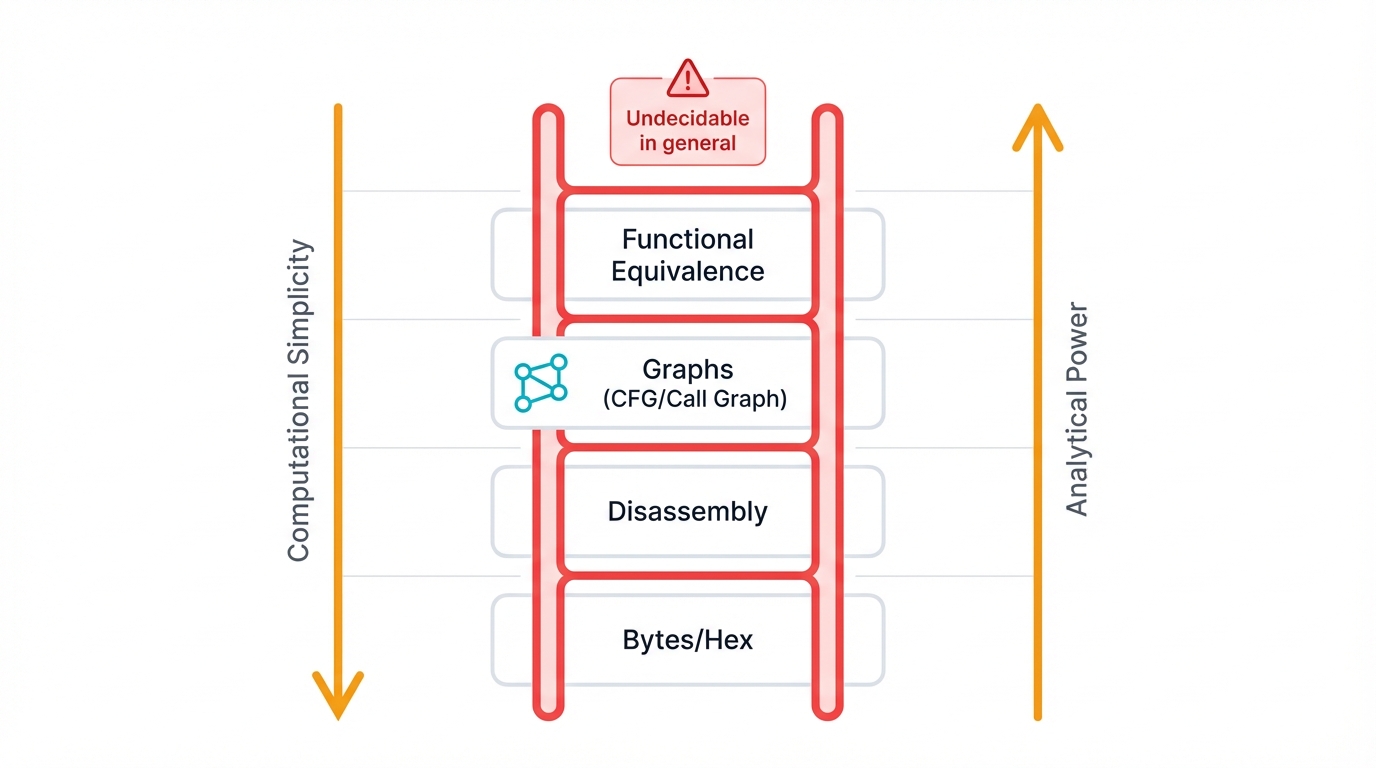
Syntactic Comparison
Start at the bottom. Compare raw bytes, hexadecimal dumps, disassembled instruction sequences—the actual representation of your code. Fast. Simple. Computationally cheap. Also incredibly fragile, breaking whenever the compiler makes different choices even though the underlying logic stays the same.
Structural Comparison
Climb higher. Compare graph-based representations that capture your program's logic rather than its specific implementation. Control Flow Graphs model execution paths within functions, while Call Graphs track relationships between functions, and this structural approach proves far more stable against the noise that compilers introduce because it focuses on what the code does rather than how the compiler chose to represent it.
Semantic Comparison
Reach the summit. Determine functional equivalence—do two pieces of code produce identical output for every possible input, regardless of how they look syntactically or how they're structured? This is the holy grail of code comparison, the ultimate level of abstraction, but it comes with a brutal catch: you're essentially trying to solve the program equivalence problem, which computer science proved is undecidable in the general case, meaning no algorithm can always tell you whether two arbitrary programs are functionally equivalent.
The Strategic Imperative of Patch Diffing
Patch diffing matters. Profoundly. It's not some technical curiosity or academic exercise—it's a critical skill with strategic implications that ripple across the entire cybersecurity landscape, serving as both a defensive tool for security researchers and an offensive weapon for attackers, and this dual-use nature makes it a central battleground in the ongoing war between those who protect systems and those who exploit them.
Vulnerability Research: The Race for the 1-Day Exploit
A vendor releases a security update. The bulletin arrives deliberately vague, avoiding specifics that might guide attackers toward exploitation opportunities. Now the race begins. Security researchers and malicious actors alike rush to reverse engineer the patch, pinpoint the exact code changes, determine the root cause of the vulnerability, and patch diffing becomes the primary method—sometimes the only practical method—for uncovering what the vendor tried to fix without explicitly telling you.
The "Patch Gap" Critical Risk Period
This creates a critical risk period. The patch releases. Users scramble to deploy it. But between release and widespread deployment lies a dangerous window—the "patch gap"—where attackers work furiously to analyze the patch and develop a "1-day exploit," and they're getting faster at this, sometimes delivering working exploits within hours or even minutes of a patch becoming publicly available.
The economics shift dramatically. Patch diffing transforms exploit development from expensive, difficult vulnerability discovery—which requires deep expertise, time, and often significant resources—into cheaper, easier reverse engineering that almost anyone with moderate skills can attempt. Defenders respond by racing to close the patch gap through rapid, automated deployment systems that can push updates to millions of systems in minutes rather than days or weeks.
Malware Analysis and Threat Intelligence
Malware evolves. Constantly. A new variant appears, and you need to understand what changed from the previous version. Patch diffing accelerates this analysis dramatically by highlighting the differences between malware generations, revealing the attacker's development priorities and helping you predict future evolution:
Feature Identification
Spot new capabilities immediately. Updated C2 protocols. New persistence mechanisms. Enhanced anti-analysis techniques. The diff shows you exactly what the malware authors added.
Code Reuse Detection
Find shared code across different malware families. Trace relationships. Attribute attacks. Link operations back to specific threat actors based on their coding patterns and reused components.
Threat Landscape
Build comprehensive maps of the threat ecosystem. Understand how different malware strains relate to each other. Track infrastructure reuse patterns.
Defensive Applications and Quality Assurance
-
Porting Analysis Work: You've spent weeks or months reverse engineering a complex binary, documenting functions, naming variables, understanding data structures. The vendor releases a new version. Without patch diffing, you start over from scratch. With patch diffing, you automatically port your metadata and analysis results to the new version, preserving months of hard-won knowledge in minutes.
-
Patch Validation: Did the security patch actually fix the vulnerability? Or did it introduce new bugs? Patch diffing validates that fixes work correctly without causing regressions, which becomes absolutely critical for mission-critical systems where you can't afford surprises.
-
Intellectual Property Protection: Suspect someone stole your code? Patch diffing tools identify shared, non-library code between binaries, gathering evidence of software plagiarism or IP theft that holds up in legal proceedings.
Core Methodologies in Binary Diffing
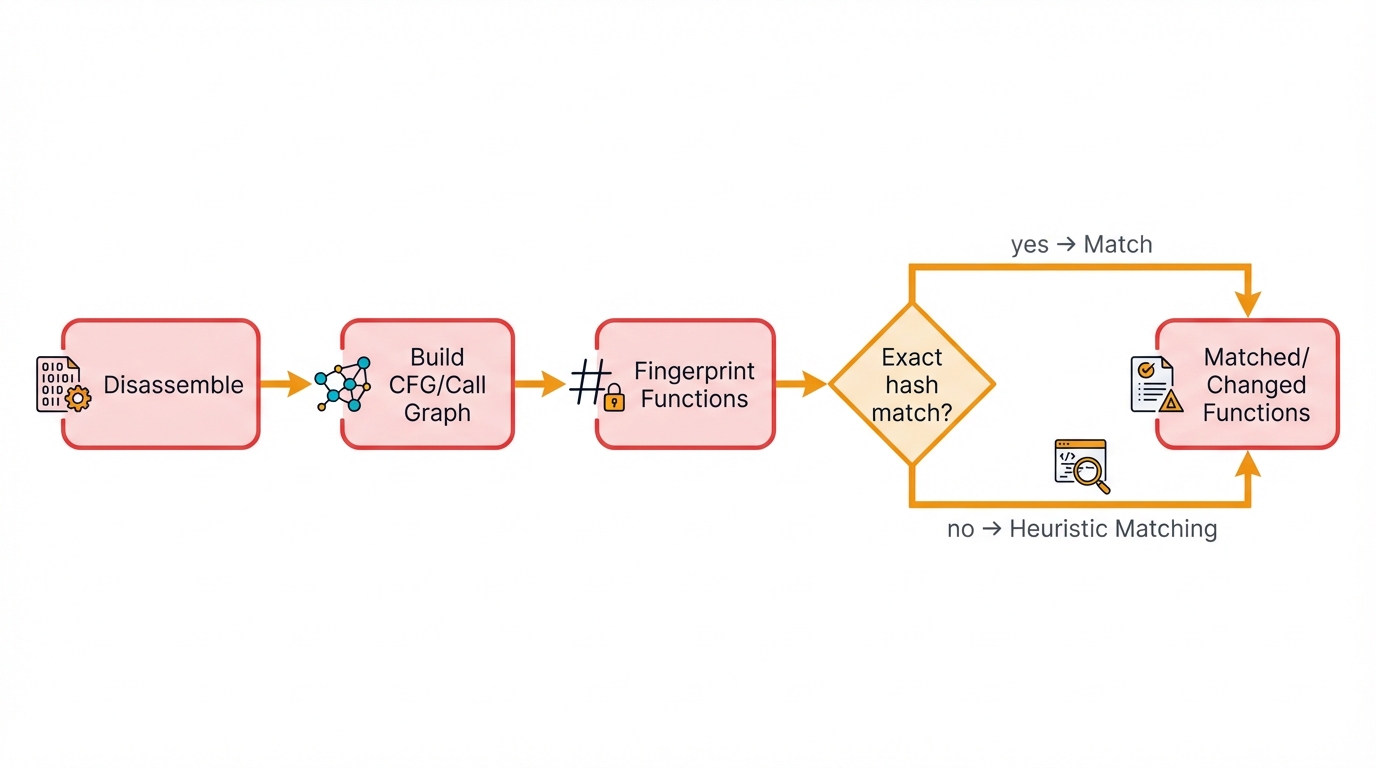
Modern binary diffing tools solve the asymmetry problem through elegant engineering. They employ a sophisticated, multi-stage pipeline that combines graph theory with statistical analysis and heuristics, transforming what seems like an impossible problem into something tractable and practical, and you can think of this process as a computational formalization of how an expert reverse engineer thinks—systematically reducing complexity until patterns emerge from the chaos.
The Graph-Theoretical Approach: Code as a Network
Binary diffing is fundamentally a graph problem. Stop comparing raw bytes. Start comparing structure. Tools like IDA Pro, Ghidra, and Binary Ninja first disassemble your binary and reconstruct its logical structure as interconnected graphs, and these graphs become the foundation for everything that follows:
Control Flow Graphs (CFGs)
Look inside a function. Instructions flow from one block to another, creating paths through the code. We model this as a CFG where nodes represent "basic blocks"—straight-line sequences with no branches in or out—and edges show execution paths. Simple concept. Powerful abstraction.
Call Graphs (CGs)
Zoom out to the program level. Functions call other functions, creating a web of relationships across the entire executable. Nodes represent functions. Directed edges show function calls. Now comparison becomes graph matching, and graph matching is something we know how to do.
Function Fingerprinting: Creating Unique Signatures
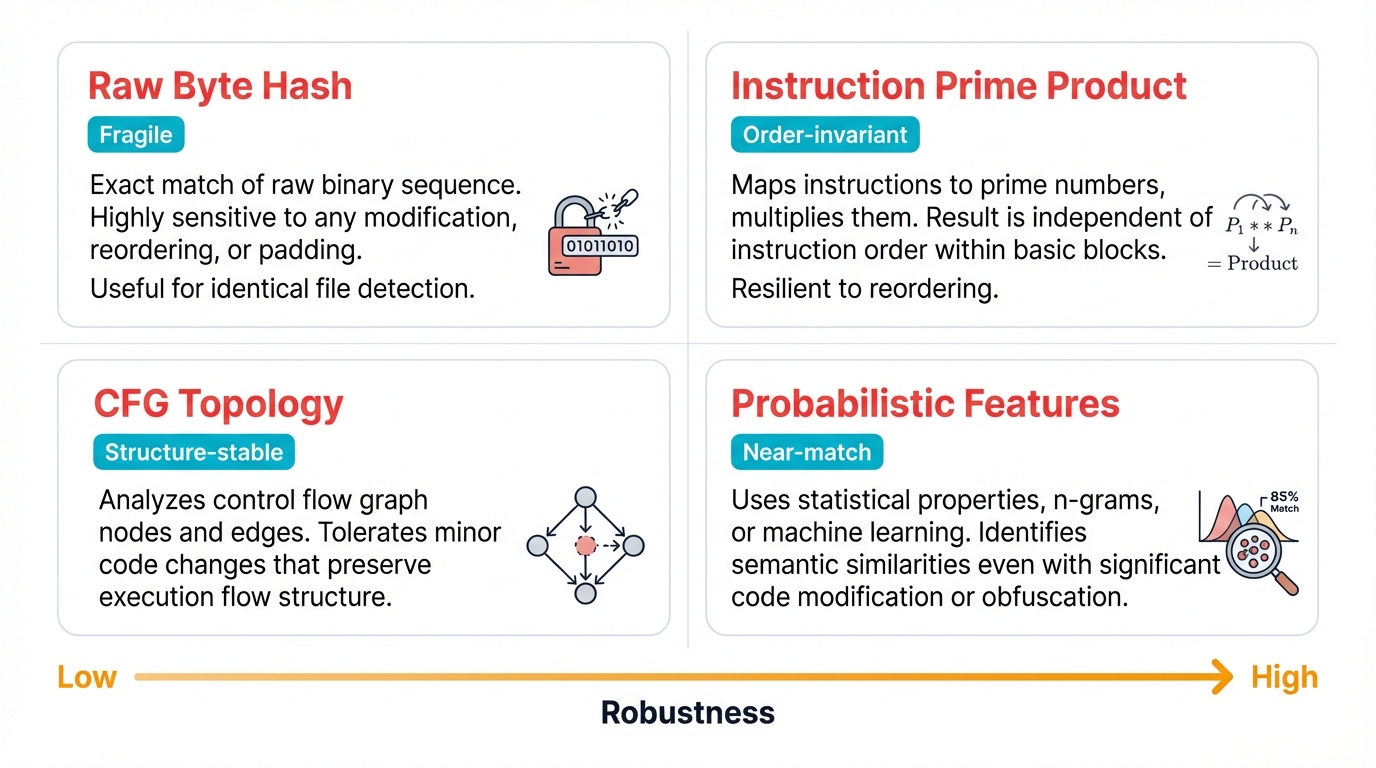
Two binaries might contain thousands of functions. Compare them naively and you drown in computational complexity. Smart approach? Generate fingerprints. Create compact signatures that capture each function's essential characteristics. These fingerprints let you quickly identify high-confidence matches—perfect anchors for deeper analysis—without comparing every function against every other function in an exponentially expensive all-pairs comparison.
Syntactic Hashing
Compute a cryptographic hash—SHA256, for instance—of the function's raw machine code bytes. Perfect for bit-for-bit identical functions. Useless when anything changes. Fast but fragile.
Small Primes Product
Assign each unique instruction mnemonic a unique prime number, then multiply all those primes together to create the function's fingerprint. Brilliant trick: multiplication commutes, so instruction reordering doesn't change the result.
Structural Hashing (MD-Index)
Fingerprint the CFG's shape rather than its content. Graph topology—incoming edges, outgoing edges, block positions—becomes your signature. Much more stable against compiler variations that change instructions but preserve structure.
Locality Sensitive Hashing
Use probabilistic techniques designed to cause collisions for similar inputs. Project high-dimensional feature vectors into lower-dimensional space. Find near-matches, not just perfect matches. Powerful for discovering functions that changed slightly.
The Power of Heuristics: Guided and Iterative Matching
A modern diffing engine runs on heuristics—collections of algorithms and rules of thumb that make educated guesses about function matches. Watch how it mirrors human analysis: start with obvious matches, use them as landmarks to navigate ambiguities, propagate certainty outward from confidence. Brilliant. Practical. Effective.
Anchoring
Establish initial anchors. Find the obvious matches. Identical function names. Perfect syntactic hashes. These become your foundation—solid ground in a sea of uncertainty.
Propagation
Propagate matches outward. Known matches anchor unknown regions. If two functions match, their callers probably match. Their callees probably match. The call graph guides you, dramatically narrowing the search space.
Scoring
Score remaining unmatched functions using feature-based heuristics. CFG characteristics. Constants and strings. Library calls. Everything combines into similarity scores that rank candidates.
A Survey of the Modern Diffing Toolchain
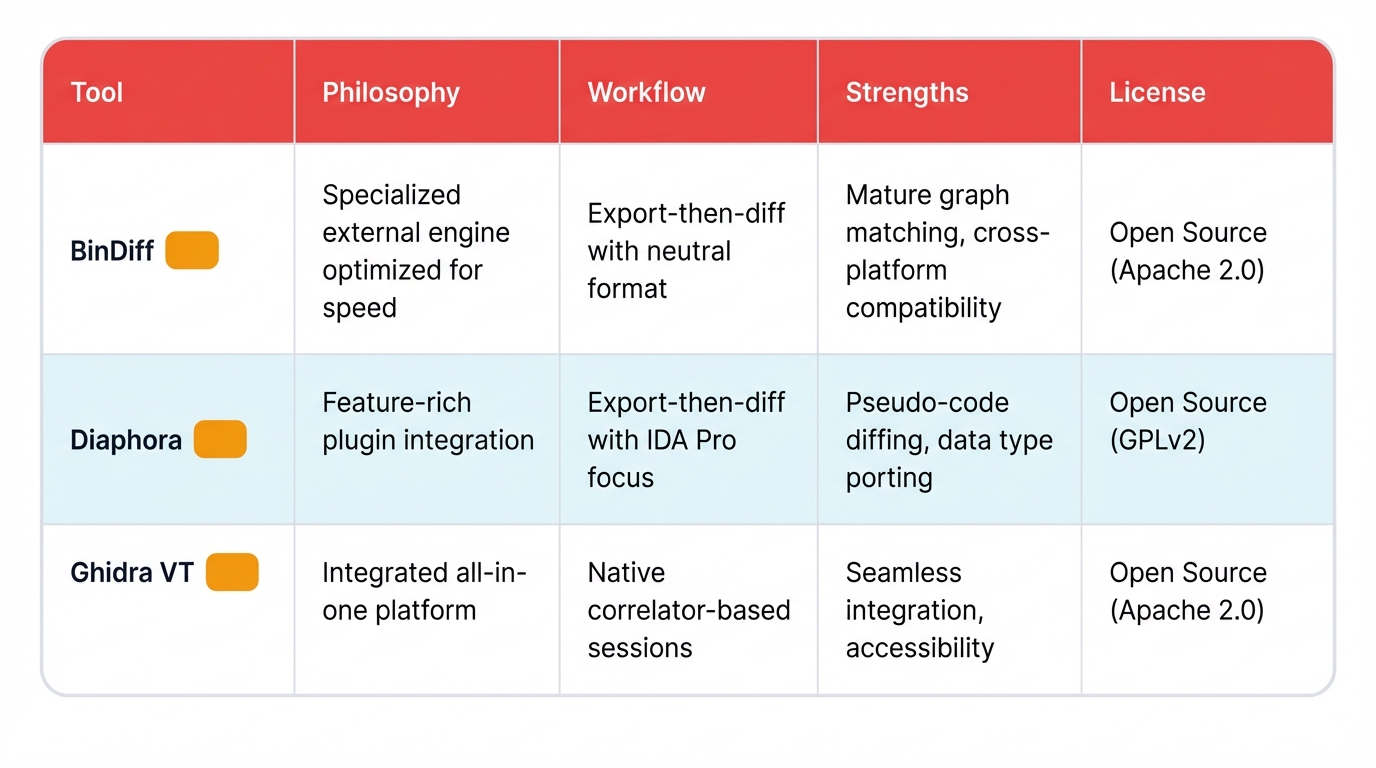
Theory meets practice. Binary diffing methodologies get embodied in real tools that researchers use every day. A mature ecosystem has emerged, dominated by three major players: BinDiff, Diaphora, and Ghidra's Version Tracker. Each embodies a different philosophy about workflow and integration, and choosing the right tool for your specific needs requires understanding these fundamental differences.
BinDiff
Philosophy: Specialized external engine optimized for speed
Workflow: Export-then-diff with neutral format
Strengths: Mature graph matching, cross-platform compatibility
License: Open Source (Apache 2.0)
Diaphora
Philosophy: Feature-rich plugin integration
Workflow: Export-then-diff with IDA Pro focus
Strengths: Pseudo-code diffing, data type porting
License: Open Source (GPLv2)
Ghidra VT
Philosophy: Integrated all-in-one platform
Workflow: Native correlator-based sessions
Strengths: Seamless integration, accessibility
License: Open Source (Apache 2.0)
Comparative Analysis of Diffing Tools
| Feature | BinDiff | Diaphora | Ghidra Version Tracker |
|---|---|---|---|
| Primary Host(s) | IDA Pro, Ghidra, Binary Ninja | IDA Pro | Ghidra (Standalone) |
| Core Methodology | Graph-theoretical matching | Multi-heuristic matching | Correlator-based matching |
| Pseudo-code Diffing | No (compares assembly/graphs) | Yes (core feature) | Yes (via decompiler view) |
| Porting Structs/Enums | No | Yes (unique strength) | Limited (via data type manager) |
| Extensibility | Configurable algorithms | Python scripting for new heuristics | Java API for new correlators |
| Primary Strength | Mature, robust graph matching | Advanced heuristics, data type porting | Seamless integration, accessibility |
Advanced Challenges and Evasion Techniques
Important Consideration: These techniques provide significant benefits when you're analyzing code, but you need to understand their limitations and the challenges you'll face, because what works beautifully in theory can break spectacularly in practice when adversaries actively work to defeat your analysis.
Binary diffing faces constant evolution. An arms race. Analysis techniques grow more powerful, and evasion methods evolve to match. These challenges range from unintentional compiler noise to deliberate, adversarial obfuscation specifically designed to break your tools, and understanding both categories becomes essential for anyone serious about patch diffing because you need to distinguish between accidental complexity and intentional deception.
Compiler Optimizations: The Primary Source of Noise
Compiler optimizations create the most significant challenge. The most common one. Every optimization aims to improve performance or reduce code size, which sounds great until you realize these transformations become the primary source of syntactic variation between binaries compiled from nearly identical source code, and this happens even when the source code changes minimally or not at all—just recompiling with different optimization flags can make two binaries look radically different.
Function Inlining
Replace function calls with the called function's full body. Sounds simple. Consequences are dramatic: nodes and edges disappear from call graphs, CFGs merge together, and suddenly your graph-based matching struggles because the structural landmarks you relied on have vanished.
Loop Transformations
Unroll loops. Vectorize iterations. What was a compact, circular structure becomes a long, linear instruction sequence, drastically changing CFG topology while leaving the actual computation untouched.
Peephole Optimizations
Small, local transformations replace instruction sequences with shorter or faster equivalents. Individually trivial. Collectively devastating to syntactic matching because these micro-optimizations accumulate across thousands of locations.
The Genetic Algorithm Challenge
Here's where it gets disturbing. Studies show that genetic algorithms can search the vast space of compiler optimization flags—not to find the best performance, but to find combinations that make two binaries look as structurally different as possible. Attackers can literally weaponize your compiler, turning it from a helpful tool into an obfuscation engine that defeats diff analysis without writing a single line of obfuscation code.
The Adversarial Landscape: Code Obfuscation
Compiler optimizations are accidental noise. Code obfuscation is intentional warfare. These techniques are deliberately adversarial, specifically designed to make program logic as difficult as possible to understand, analyze, and compare through reverse engineering, and when you're facing obfuscated code, you're not dealing with a natural phenomenon—you're dealing with an adversary who knows exactly how your tools work and has engineered countermeasures to defeat them.
Instruction Substitution
Replace simple instructions with complex but semantically equivalent sequences. Addition becomes a series of bitwise XOR and AND operations. Subtraction transforms into complementation and addition. Every simple operation explodes into complexity that defeats pattern matching.
Control Flow Flattening (CFF)
The nuclear option. CFF completely dismantles a function's natural CFG structure by modifying all basic blocks to return to a central dispatcher loop, transforming complex, meaningful graphs into simple "star" shapes that reveal nothing about the underlying logic. Brutal. Effective. Nearly impossible to reverse without semantic analysis.
Inter-procedural Obfuscation
Advanced techniques attack the very concept of a function as a stable unit of analysis:
- • Function Fission: Split one logical function into multiple smaller functions scattered throughout the binary, connected by convoluted call patterns
- • Function Fusion: Merge multiple distinct functions into one massive, incoherent function that combines unrelated logic in ways that make no sense
Patch Diffing in Practice: A Case Study Analysis
Theory becomes practice. Let's synthesize everything—concepts, tooling, challenges—by examining patch diffing applied to a real-world vulnerability, walking through the complete investigative workflow from CVE announcement to root cause understanding.
From CVE to Root Cause: Analyzing CVE-2022-21907
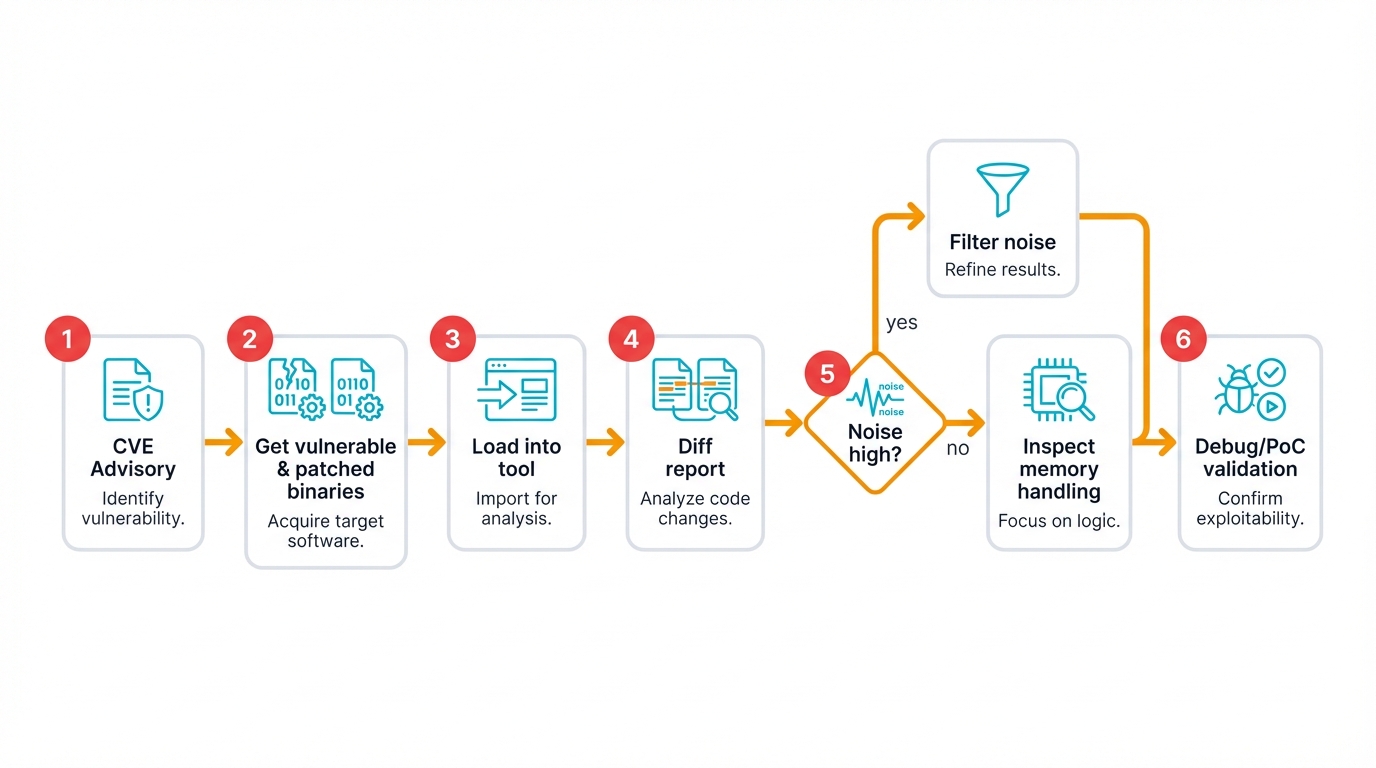
Patch diffing unfolds as iterative investigation. You combine automated analysis with human expertise. CVE-2022-21907—a critical remote code execution vulnerability in Microsoft's HTTP Protocol Stack—serves as an effective case study because it demonstrates the complete workflow from initial discovery through final understanding:
Intelligence Gathering and Binary Acquisition
Start with the CVE advisory. Gather intelligence. Obtain both vulnerable and patched versions of the relevant binary (http.sys) by navigating vendor resources, downloading update packages, and extracting target files—tedious but essential groundwork.
Performing the Initial Diff
Load both versions into your analysis platform (IDA Pro, Ghidra, Binary Ninja). Run your diffing tool (BinDiff, Diaphora, Version Tracker). Wait. The tool generates a report listing functions that are identical, new, deleted, or changed—your roadmap for deeper investigation.
Interpreting Results: Separating Signal from Noise
Filter the noise. You might see hundreds of changed functions. Most are irrelevant—compiler artifacts, timestamp updates, unrelated modifications. "Remote Code Execution" suggests memory corruption, so focus on memory handling changes, particularly functions like UlPAllocateFastTracker where the diff reveals added memset calls that zero memory before use.
Root Cause Analysis
Examine changes within candidate functions to reconstruct the original vulnerability. Added null pointer checks indicate a dereferencing vulnerability. Memory zeroing patterns suggest uninitialized data usage. Each pattern tells part of the story, and your job is assembling these fragments into a coherent narrative.
Dynamic Analysis and PoC Development
Switch to dynamic analysis. Fire up your debugger. Set breakpoints in identified code paths. Craft inputs designed to trigger the vulnerability. Develop your Proof-of-Concept exploit to confirm the root cause and demonstrate real-world impact.
The Future of Analysis: LLM-Assisted Workflows
Manual review takes time. Hundreds of changed functions. Thousands of lines of assembly. Recent research explores how large language models accelerate this tedious process, and the results show promise mixed with significant limitations that you need to understand before incorporating LLMs into your workflow:
Current Approach
- Feed decompiled source code of all changed functions plus CVE information into the model
- Ask the model to rank functions by likelihood of containing the security fix
- Models like Claude Sonnet often rank the actual vulnerable functions highly, cutting review time dramatically
Current Limitations
- Struggles with widespread, repetitive changes like stack canaries added to hundreds of functions for general hardening
- Noise from systematic security mitigations can completely obscure the actual vulnerability location
- Not yet a replacement for human expertise—more like a powerful assistant that needs human oversight
Conclusion and Future Outlook
Best Practice: Follow these practices and you'll achieve optimal results while avoiding the common pitfalls that trap beginners, because patch diffing rewards systematic approaches and punishes careless improvisation with hours of wasted effort and missed vulnerabilities.
Patch diffing has evolved. From niche technique to essential skill. It now plays a vital role across vulnerability research, threat intelligence, and software quality assurance. This comprehensive analysis covered core principles, strategic implications, primary techniques, and practical applications, giving you a complete framework for understanding and applying these powerful methodologies.
Synthesis of Key Insights
The asymmetry problem defines binary diffing. Small source code changes trigger cascading binary modifications that seem completely disproportionate to the original edit. We solve this through layered analysis techniques that climb the abstraction ladder from fragile syntactic comparisons at the bottom through more robust structural graph-based analyses in the middle to semantic comparisons at the top that approach true functional equivalence but remain computationally impractical for most real-world applications.
Strategic implications extend far beyond technical curiosity. Security patches protect updated systems while simultaneously serving as exploitation blueprints for attacking unpatched ones—a dual-use dilemma that fundamentally reshapes exploit development economics and organizational risk management, putting enormous pressure on defenders to eliminate the patch gap through rapid, automated deployment while giving attackers powerful new capabilities that dramatically lower the barrier to entry for exploit development.
The Co-evolutionary Arms Race
An ongoing arms race shapes the future. Analysis tools grow more sophisticated, incorporating machine learning and approaching true semantic comparison. Evasion techniques evolve in parallel, developing new obfuscation methods specifically designed to defeat emerging analysis capabilities, and this co-evolutionary dynamic ensures that patch diffing will never become a solved problem—it will remain perpetually contested ground where attackers and defenders continuously adapt to counter each other's latest innovations.
Compiler optimization combined with intentional obfuscation—especially inter-procedural transformations that challenge the concept of stable functions—will continue pushing analysis limits. The growing integration of AI accelerates both sides of this arms race: AI helps analysts process more data faster while simultaneously enabling attackers to generate more sophisticated obfuscation automatically. Dynamic. Adversarial. Never static.
Final Recommendations for the Aspiring Researcher
Want to master this critical skill? Take a structured approach. Build systematically. Practice deliberately:
Master the Fundamentals
Deep understanding of computer architecture, assembly language (x86/x64, ARM), and compiler theory isn't optional—it's absolutely essential for correctly interpreting diffing tool results and distinguishing meaningful changes from compiler noise.
Gain Hands-On Experience
Pair theoretical knowledge with practical skill. Ghidra's Version Tracking tool makes an excellent starting point for analyzing publicly disclosed CVEs—learn by doing, start with solved examples, gradually tackle harder challenges.
Cultivate Investigative Mindset
Automated tools aid analysis but never replace human judgment. Patch diffing is hypothesis testing—tools present evidence, but you construct the narrative explaining vulnerabilities and fixes through careful reasoning and creative thinking.
Ready to Begin Your Research Journey?
Explore foundational guides, practical implementations, and comprehensive security research resources.
Example Implementation
#!/bin/bash
# Example: Security audit script
echo "Starting AI system security audit..."
# Check for exposed credentials
echo "Checking for exposed credentials..."
grep -r "api_key\|password\|secret" . --exclude-dir=.git 2>/dev/null | head -5
# Verify permissions
echo "Checking file permissions..."
find . -type f -perm 0777 2>/dev/null | head -5
# Check container security
if command -v docker &> /dev/null; then
echo "Scanning container images..."
docker images --format "table {{.Repository}}:{{.Tag}} {{.Size}}" | head -5
fi
# Network analysis
echo "Checking open ports..."
netstat -tuln 2>/dev/null | grep LISTEN | head -5
echo "Audit complete. Review findings above."