Table of Contents
A summer intern accesses the CEO's boardroom notes. A customer support agent sees another company's financial data. A departing employee retains access to confidential documents for three days after their permissions are revoked because the RAG system's metadata filters haven't synced yet.
These aren't theoretical scenarios. Paragon's analysis of permissions management in RAG systems describes the intern scenario directly. The Advent of AI Security project documented 438 vulnerable Flowise servers exposing Pinecone API keys, customer PII, and financial records to anyone who could reach the endpoint. The permission lag problem affects most RAG deployments that synchronize authorization from enterprise data sources.
Multi-tenant RAG systems have an authorization problem that traditional access controls weren't designed to solve. The pipeline introduces multiple stages where access control can fail, enterprise permissions can't be faithfully translated to vector database metadata, and the system itself creates information channels that bypass every retrieval-stage access control you build.
The short version: Multi-tenant RAG systems fail authorization in five recurring ways: namespace routing bugs, metadata filter bypass, ACL translation loss, semantic cache collisions, and permission synchronization lag. These failures are structural, not incidental. Real isolation requires retrieval-layer authorization, tenant-scoped caching, physical data separation, and end-to-end authorization propagation.
This article maps the failure patterns and what you can do about them.
Why RAG Authorization Is Harder Than You Think
In a traditional web application, authorization happens at one boundary: check permissions, return data or deny access. In a RAG pipeline, content flows through ingestion, embedding, storage, retrieval, augmentation, generation, and output. Each stage transforms the data. Each transformation can lose authorization context.
Most implementations enforce authorization at one or two of those stages. The stages without enforcement are the stages where leakage happens.
That's the conceptual problem. The practical problem is worse: the authorization model in your source system (SharePoint, Confluence, Google Drive) doesn't map cleanly to what your vector database supports. SharePoint alone has site-level, library-level, folder-level, and item-level permissions, with inheritance, sharing links, and sensitivity labels. Vector databases support flat key-value metadata. The translation from one to the other is inherently lossy.
Descope's engineering team documented the core mismatch: enterprise permissions involve "nested groups, folder hierarchies, ownership, and specific sharing relationships" that can't be faithfully represented as metadata tags. Complex inherited permissions get simplified or omitted. Edge cases in negation, wildcards, and nested group memberships produce incorrect filtering.
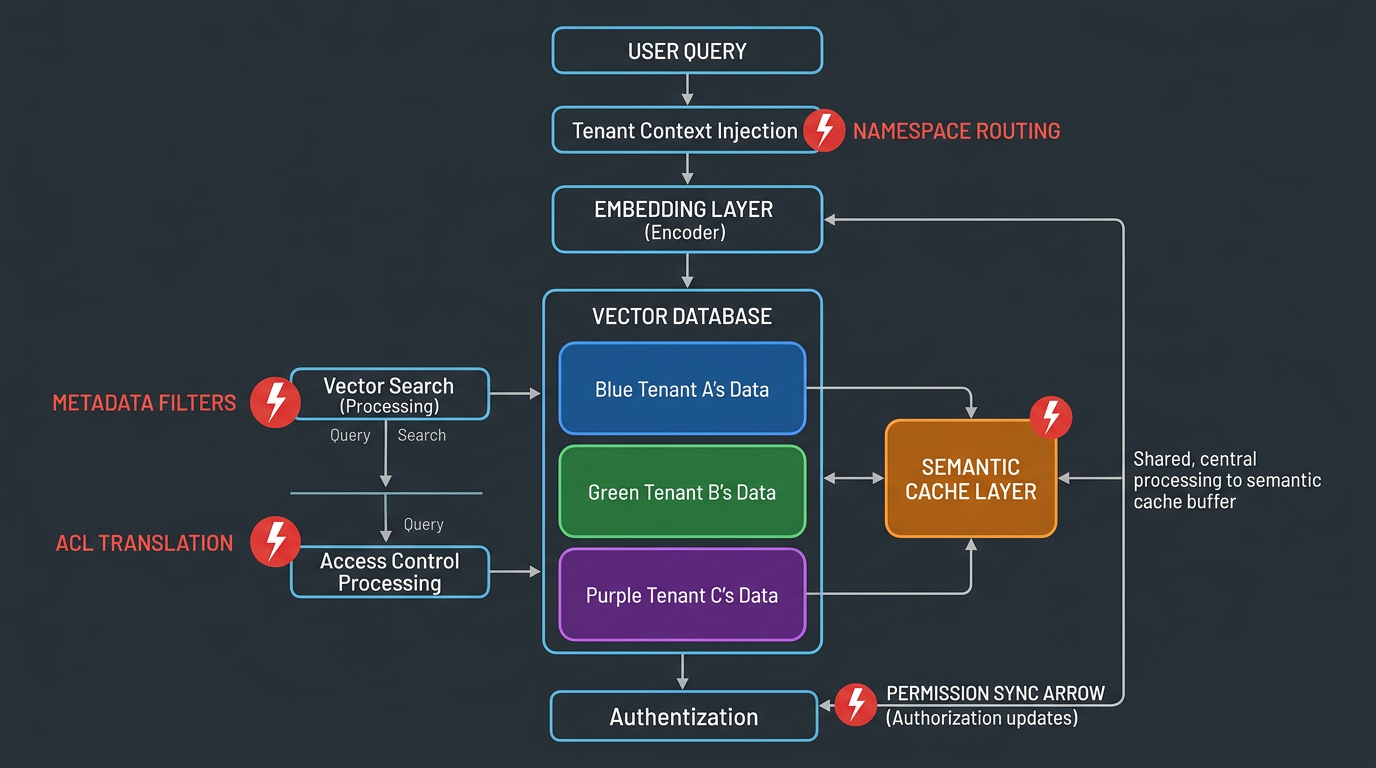
Figure 1: Multi-Tenant RAG Pipeline with Leakage Points
Five Ways Multi-Tenant RAG Leaks Data
Five authorization failure patterns recur across multi-tenant RAG deployments. Each has distinct root causes, but they share a common theme: the gap between intended authorization and actual enforcement.
1. Namespace Isolation Failures
The application code responsible for routing queries to the correct namespace fails to validate tenant context. This happens when tenant identifiers come from user-supplied input (HTTP headers, JWT claims) without proper validation, when default namespaces contain data from multiple tenants, or when administrative interfaces inadvertently query across all namespaces.
In some architectures, simply omitting the namespace parameter causes the query to fall back to a global scope, exposing every tenant's data.
The root cause is almost always an application-layer bug, not a database-level vulnerability. The vector database correctly isolates namespaces. The application code fails to specify which namespace to query. Maps to CWE-284 (Improper Access Control) and CWE-863 (Incorrect Authorization).
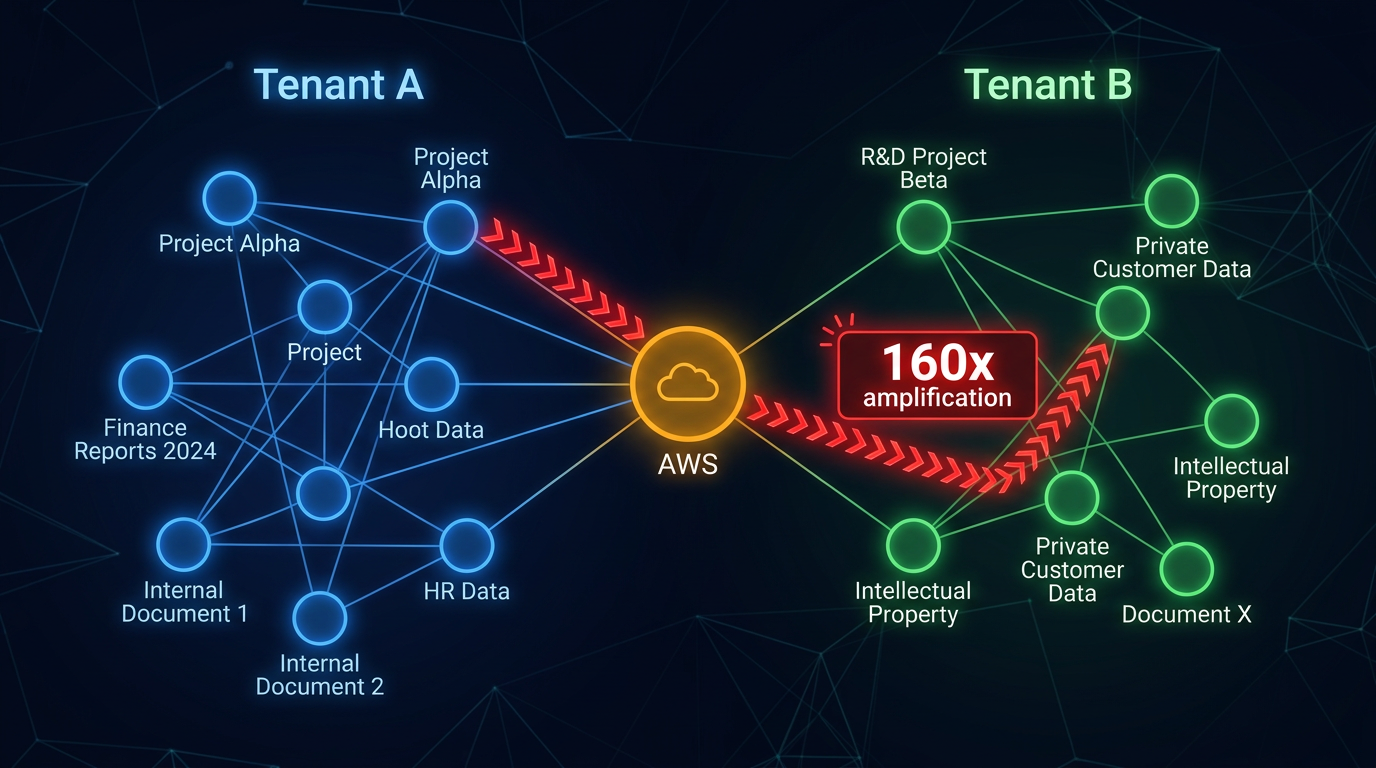
Figure 2: Knowledge Graph Cross-Tenant Pivot Attack
2. Metadata Filter Bypass
Most RAG systems that don't use strict namespace isolation rely on metadata filters: {"tenant_id": "acme-corp"} appended to similarity searches. The filter exists at the application layer and can be manipulated.
If the system uses an LLM to parse user queries into structured retrieval parameters, prompt injection can alter the filter logic. In hybrid RAG systems that combine vector search with knowledge graph expansion, the problem is more severe: naturally shared entities (vendors, infrastructure, compliance standards) create cross-tenant pivot paths organically, without adversarial injection.
In research published on Hybrid RAG Pivot Attacks (arXiv:2602.08668), the undefended hybrid pipeline demonstrated that empty-tenant nodes in knowledge graphs -- nodes without an explicit tenant label -- fail the tenant-match check, allowing cross-tenant traversal with amplification factors of 160-194x relative to vector-only retrieval. In a synthetic multi-tenant enterprise corpus of 1,000 documents with 2,785 graph nodes and 15,514 edges, the undefended hybrid pipeline exhibited a Retrieval Pivot Risk of approximately 0.95, meaning nearly every query had the potential to leak cross-tenant information through graph expansion paths.
The graph structure itself creates the vulnerability. Tenant A and Tenant B both reference AWS as an infrastructure provider. The knowledge graph links both tenants' documents through the shared "AWS" entity node. A vector query from Tenant A retrieves a relevant document, the graph expands through the AWS node, and Tenant B's infrastructure architecture documents enter the retrieval context.
3. ACL Translation Failures
Enterprise permissions don't flatten cleanly into vector database metadata. This is the most common failure in production deployments and the hardest to detect because the system appears to work correctly.
Consider a Confluence page with space-level permissions plus page-level restrictions plus group-based access. The RAG ingestion pipeline captures what it can: {"allowed_groups": ["engineering", "security"]}. But the source system also had negation rules (a specific user excluded from the engineering group's access), inherited restrictions from a parent page, and a sharing link with an expiration date. None of those translate to flat metadata. The RAG system may treat the page as accessible to all of "engineering," even though one specific engineer was explicitly excluded in the source system.
The result: the RAG system's authorization model is a simplified, lossy approximation of the real permissions. Every simplification is a potential data exposure.
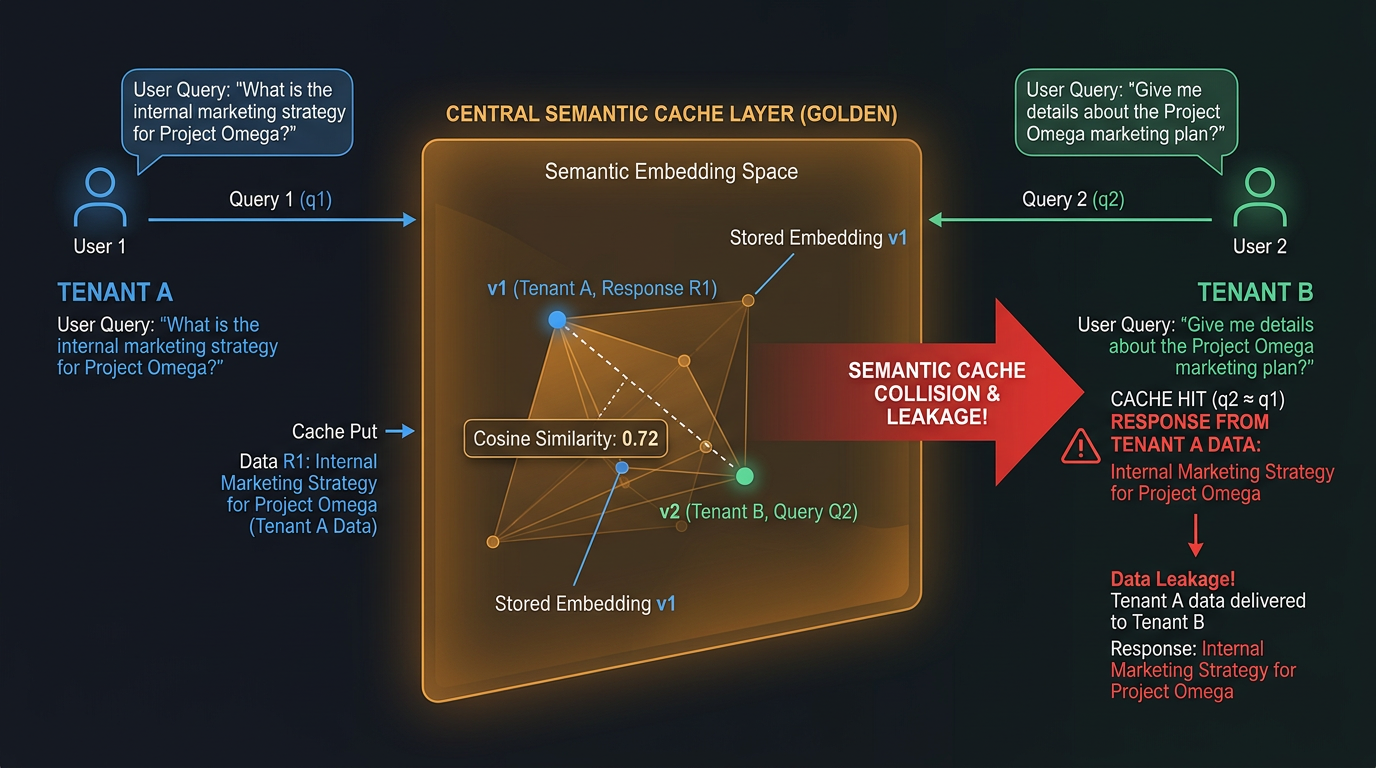
Figure 3: Semantic Cache Collision Across Tenants
4. Semantic Cache Leakage
Semantic caching reduces latency and cost by storing query-response pairs and serving cached responses for semantically similar queries. It also creates a cross-tenant data channel that bypasses every retrieval-stage access control.
Tenant A asks "What is our company's Q3 revenue?" and gets a detailed financial response. The cache stores the query-response pair. Tenant B asks "What was the company's third quarter revenue?" The query embeds within the similarity threshold. Tenant B receives Tenant A's financial data directly from cache, without hitting the retrieval pipeline or any access control layer.
This was measured directly in a two-tenant deployment with 50 queries cached per tenant across three similarity categories:
| Similarity Threshold | Different Topic | Shared Vocabulary | Paraphrased | Overall Hit Rate | Sensitive Exposure |
|---|---|---|---|---|---|
| 0.70 | 0% | 46.7% | 33.3% | 24.0% | 6.0% |
| 0.75 | 0% | 33.3% | 6.7% | 12.0% | 2.0% |
| 0.80 | 0% | 13.3% | 0.0% | 4.0% | 0.0% |
| 0.85 | 0% | 0.0% | 0.0% | 0.0% | 0.0% |
At the commonly deployed 0.70 threshold, nearly half of shared-vocabulary queries and a third of paraphrased queries hit another tenant's cached responses, with 6% exposing sensitive financial data. The practical threshold for zero sensitive exposure is 0.80, but that requires per-tenant cache partitioning to be safe by design rather than by threshold tuning.
Important: Any multi-tenant RAG deployment using semantic caching without tenant-scoped keys is running an active cross-tenant data channel.
Beyond accidental leakage, CacheAttack (2026) demonstrated that collisions can be deliberately engineered. Attackers craft prompts producing embeddings similar to a target query's embedding. The attack achieved an 86% response hijacking rate with cross-model transferability. Separately, NDSS 2025 research demonstrated cache poisoning "across all three major public clouds" (Azure, AWS, Alibaba).
There's also a timing side channel: cached responses return in under 100ms while full pipeline execution takes 1-5 seconds. An attacker can probe the cache systematically to map other tenants' information interests. Knowing what questions your competitor is asking can be as valuable as knowing the answers.
5. The Permission Lag Problem
Your RAG system's permissions are only as current as your last sync.
At time T+0, an HR manager revokes a departing employee's access to confidential documents in SharePoint. SharePoint enforces the change immediately. The RAG system's vector database still contains embeddings with metadata filters granting the departing employee access. The RAG system won't reflect the change until the next sync cycle, which could be minutes, hours, or days.
The lag varies by source system:
SharePoint: Microsoft's Graph API provides webhooks for some permission changes but not all. Security group membership changes may not trigger document-level webhooks. Most RAG integrations poll every 15-60 minutes.
Confluence: Hierarchical permissions mean a single space-level change affects every indexed chunk. The RAG system must re-evaluate permissions chunk by chunk.
Google Drive: Group membership changes don't generate Drive API events for affected documents. Removing a user from a group doesn't create the per-document events the RAG system needs to detect.
These failure modes compound. A document with delayed permission sync gets re-indexed during a maintenance window, baking the stale permissions into the new index. The document is later deleted from the source system, but its orphaned embeddings persist in the vector database with the now-doubly-stale permissions. A user whose access was revoked queries the system and receives content from a document that has been deleted from the source, with permissions that haven't been valid for weeks.
The Retrieve-Then-Filter Trap
Beyond the five failure patterns, one architectural decision determines whether your authorization is real or theater: retrieve-then-filter versus filter-then-retrieve.
Retrieve then filter is common and dangerous. The vector database returns the most semantically relevant documents regardless of who's asking. A post-retrieval filter removes unauthorized content. But the ANN algorithm has already processed vectors from all tenants. The LLM may see unauthorized content before filtering occurs. And the starvation problem creates a side channel: when filtered results leave fewer than k documents, the system either returns insufficient context or runs additional queries, revealing patterns about the existence of restricted content.
Filter then retrieve is harder to implement but fundamentally safer. Authorization happens at the retrieval layer. The LLM never sees unauthorized documents. The trade-off is real: per-query authorization lookups add latency, and Descope's analysis documents that pre-filtering "quickly breaks down in real-world enterprise environments at scale" due to synchronization lag, metadata explosion, and performance overhead.
But you eliminate an entire class of information leakage that no output filter can reliably catch.
What Makes This Worse: The Mosaic Effect
Even when access controls work perfectly at the document level, the LLM's synthesis capability creates a leakage vector that traditional access controls can't address.
Individually innocuous pieces from permitted documents combine to reveal restricted information. A user with access to marketing documentation and vendor contracts asks about system performance optimizations. The model synthesizes references to "custom ASIC acceleration," "proprietary compression algorithm," and vendor-specific hardware partnerships into a plausible internal architecture description -- effectively reconstructing information from restricted engineering documents the user never accessed.
The formal research confirms this: "The Sum Leaks More Than Its Parts" (OpenReview) studies how multiple benign outputs jointly leak sensitive information when combined. The core finding: safety guarantees at the component level do not compose. The attack surface is in the composition mechanism.
This means even perfect document-level access controls don't prevent information leakage. The LLM's ability to synthesize across documents creates inference paths that bypass authorization entirely.
Defensive Architecture
The failure patterns are structural, but they're addressable. Here's what works.
Filter Then Retrieve, Not the Reverse
Build authorization into the retrieval query. The LLM should never see content the user isn't authorized to access. The latency cost is real. The security guarantee is worth it.
Tenant-Scoped Cache Keys
Include the tenant identifier in semantic cache key computation. Two queries with identical embeddings from different tenants must produce different cache keys. Hash the query embedding concatenated with the tenant ID. Cache hits only occur when both the similarity threshold and the tenant ID match.
For finer granularity, include the user's permission set in the cache key. Two users with different permission levels asking the same question get different cache entries. This reduces cache hit rates (larger key space) but eliminates cross-tenant leakage by design.
Permission-Aware Cache Invalidation
TTL-based cache expiration is insufficient because permission changes happen at unpredictable intervals. When permissions change, invalidate all cache entries generated under the old permissions. This requires the cache to store which permissions were active when each entry was created.
Physical Isolation Over Logical Separation
Weaviate's shard-per-tenant model creates physical data isolation. Each tenant's data lives in a separate shard. Cross-tenant retrieval is architecturally impossible at the database level. pgvector with Row-Level Security provides similar guarantees: the database engine enforces tenant isolation regardless of how the application constructs its queries.
Logical separation through metadata filters works -- until edge cases emerge. Physical isolation eliminates the class of failure.
Authorization Propagation
Authorization context must travel with the data across every pipeline stage, not just guard the entry point. When a document is ingested, its permissions are captured. When it's chunked, each chunk inherits those permissions. When it's embedded, the permission metadata is stored alongside the vector. When it's retrieved, the permission is checked against the requesting user. When it's placed in the augmentation context, every chunk is verified. When the LLM generates a response, output filtering catches leakage from inference and synthesis.
Important: No mainstream RAG framework implements this end-to-end by default. LangChain passes documents through the pipeline without authorization metadata. LlamaIndex supports metadata but doesn't enforce authorization policies against it. Haystack provides no authorization primitives. The propagation model must be built by the deploying organization.
Fail Closed on Sync Errors
When permission synchronization fails (API timeout, webhook delivery failure, parsing error), the default behavior should restrict access, not maintain the last known permissions. This is operationally painful -- users lose access during outages -- but security-correct. The alternative is serving content under stale permissions that may have already been revoked.
The Uncomfortable Implication
Multi-tenant RAG authorization is not a configuration problem. It's an architectural one. The combination of lossy permission translation, multiple enforcement gaps across the pipeline, semantic cache side channels, and the LLM's inherent ability to synthesize across documents means that adding access controls at a single layer doesn't solve the problem.
The organizations getting this right are building authorization into every stage of the pipeline, using physical isolation rather than logical separation, scoping their caches per tenant, and accepting the latency and complexity overhead that real authorization requires.
Many organizations operating multi-tenant RAG systems may not yet have measured these failure modes. Cross-tenant leakage in RAG systems is silent. No error message fires when Tenant B receives Tenant A's cached financial data. No alert triggers when the LLM infers restricted information from authorized documents. The leakage continues until someone specifically tests for it.
Key Question: If you're running a multi-tenant RAG deployment, the question isn't whether your authorization model has gaps. It's whether you've measured them.
More AI security research at perfecXion.ai
References
- Advent of AI Security. "Door 08 -- Vector and Embedding Weaknesses." 2025.
- CacheAttack. "Deliberate Cache Collision Engineering." 2026.
- Descope. "Adding Performant ReBAC to RAG Pipelines at Scale." 2025.
- FINOS AI Governance Framework. "Information Leaked to Vector Store." 2025.
- NDSS 2025. "Cache Poisoning Across Major Public Clouds."
- OpenReview. "The Sum Leaks More Than Its Parts: Compositional Privacy Risks."
- OWASP. "Top 10 for LLM Applications 2025."
- Paragon. "Strategies for Managing Permissions in RAG." 2025.
- Song, C. & Raghunathan, A. "Information Leakage in Embedding Models." ACM CCS 2020.
- Thornton, S. "Hybrid RAG Pivot Attacks." arXiv:2602.08668. February 2026.
- Wang, H. et al. "Privacy-Aware Decoding: Mitigating Privacy Leakage of LLMs in RAG." arXiv:2508.03098. 2025.