Executive Summary
Your multi-million-dollar AI cluster just died.
Not from hackers. Not from hardware failure. A single misconfigured congestion control parameter triggered Priority Flow Control storms that froze 24,000 GPUs across your entire fabric in minutes.
Converged Infrastructure Risks
Converging storage, compute, and networking in AI fabrics creates new attack surfaces that shatter traditional security boundaries in ways most teams don't anticipate until disaster strikes.
Sound familiar?
Large-scale AI workloads shattered data center architecture. Traditional networks handled diverse microservices beautifully—web requests mixing with database queries, API calls dancing alongside file transfers. AI's brutal demands? They crumble. You're battling low-entropy, synchronous communication patterns that create perfect storms of congestion.
Critical Reality: Enter AI fabrics—specialized networks built on RDMA technologies that promise microsecond latencies and deliver entirely new attack surfaces that your security team has never encountered before.
This analysis cuts through marketing hype to reveal fundamental architectural tension at the heart of modern AI infrastructure. You're forcing lossless RDMA protocols onto inherently lossy Ethernet, creating complex engineering challenges that ripple through every network layer with devastating consequences when things go wrong. Link-layer flow control mechanisms become weapons in the hands of sophisticated attackers. End-to-end algorithms introduce vulnerabilities that traditional security models never anticipated. Attackers are learning to exploit every single one of these weaknesses with precision that should terrify anyone running large-scale AI infrastructure.
We'll trace congestion control evolution as intelligence migrated from network cores to programmable edges. You'll discover why foundational mechanisms like PFC create devastating side effects that cascade through entire clusters. End-to-end solutions like ECN provide graceful alternatives—but they require precise tuning that most teams lack the expertise to implement correctly. Cutting-edge programmable NIC innovations offer flexibility and performance at the cost of increased complexity that multiplies your attack surface exponentially.
The competitive landscape reveals two diverging paths with profoundly different security implications. Google and AWS pursue deep vertical integration, creating proprietary transport protocols—Swift and SRD—optimized for specific environments where they control every component from silicon to software. The alternative? NVIDIA, Broadcom, and Meta push open standards to their limits, coalescing around Ultra Ethernet Consortium specifications in pursuit of viable multi-vendor alternatives that promise lower costs but introduce integration vulnerabilities at every boundary between components.
Security Nightmare: Here's what keeps security teams awake at night: advanced congestion control algorithms depend entirely on real-time telemetry feedback loops, creating massive attack surfaces where compromised telemetry data becomes weaponized to sabotage multi-million-dollar training clusters without leaving obvious traces that traditional monitoring systems would detect.
The stakes? A single fabric misconfiguration wastes millions in GPU cycles. Understanding these vulnerabilities isn't optional. It's survival in an era where your competitors are investing billions in AI capabilities and the infrastructure security mistakes you make today determine whether you'll be competing or obsolete in three years.
Part I: Why AI Broke Traditional Networks
Your traditional data center network wasn't designed for this.
AI fabrics didn't emerge as incremental improvements—they're desperate responses to fundamental disruption that broke every assumption network engineers spent decades refining. Large-scale distributed AI training creates alien communication patterns that shatter basic networking assumptions built on decades of statistical traffic models and diverse workload mixing.
Understanding these unique traffic profiles is your first step. Only then can you appreciate the complex, highly specialized solutions the industry developed to keep multi-billion-dollar GPU clusters from choking on their own communication demands.
The Traffic Patterns That Changed Everything
Your distributed AI cluster costs hundreds of millions. Its performance depends entirely on network efficiency—not partially, not predominantly, but entirely in ways that make traditional "network is fast enough" assumptions catastrophically inadequate.
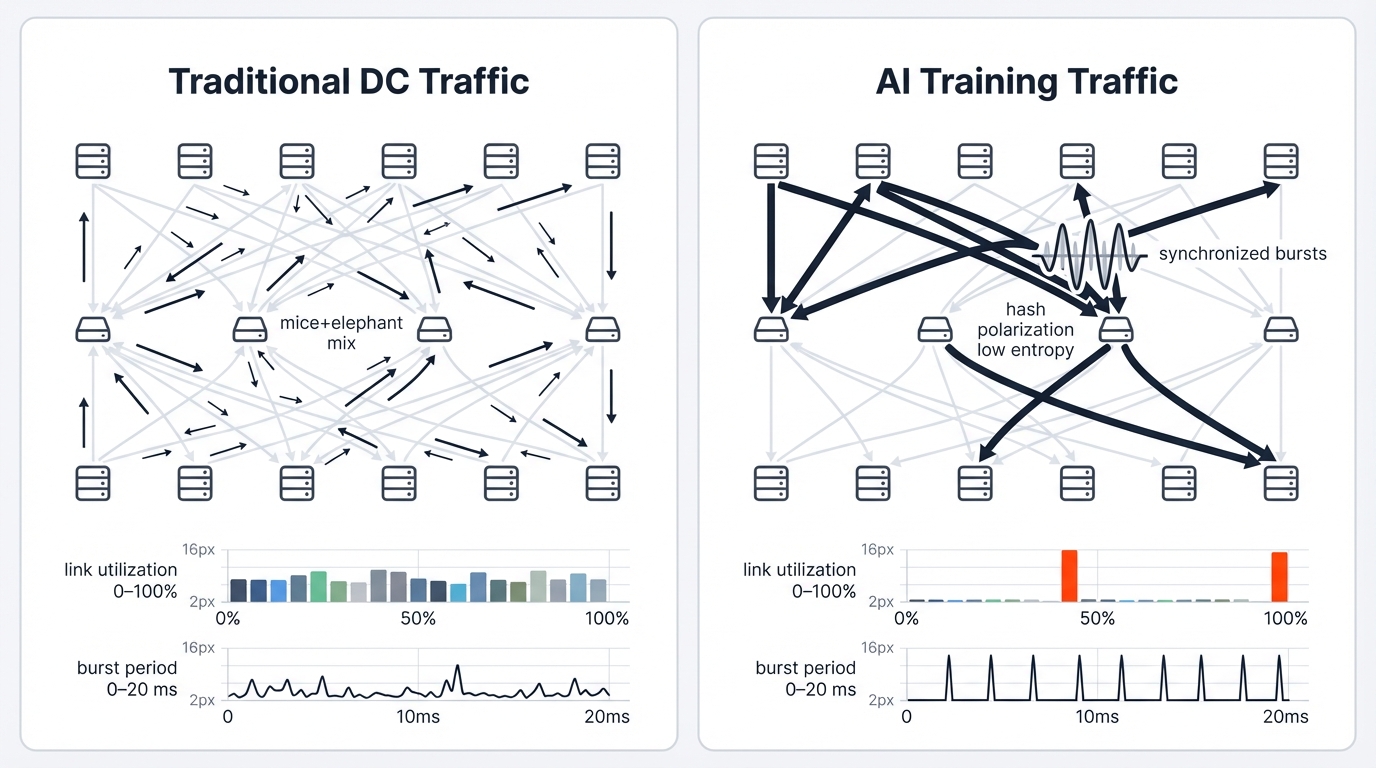
This isn't hyperbole. It's cold mathematics.
The mathematics gets dictated by AI training's inherent communication patterns that create bottlenecks where you'd never expect them and destroy performance in microseconds when conditions align perfectly for disaster.
How AI Training Creates Perfect Network Storms
Traditional data centers handle diverse traffic beautifully. Short "mice" flows mix with longer "elephant" flows in statistical patterns that load-balancing algorithms were specifically designed to manage. AI training generates something completely different—highly structured, punishing traffic profiles that break every optimization technique in the network engineer's playbook.
The culprit? Synchronous distributed training algorithms, especially for Large Language Models and foundational models that require thousands of GPUs to coordinate their work with microsecond precision across every training step.
Low-Entropy, High-Bandwidth Devastation: Your AI cluster communication centers on few flows—extremely long-lived flows between GPU groups where each flow carries massive bandwidth that saturates modern 400/800 Gbps links for sustained periods that traditional networks never anticipated.
Training processes require collective operations like AllReduce, which are synchronized exchanges of model parameters among thousands of accelerators that must complete before training can advance to the next step. These aren't statistical flows that network engineers predict and balance using decades of proven techniques. They're deterministic monsters that saturate links, overwhelm buffers, and create congestion patterns that look nothing like the traffic profiles your network was designed to handle.
Hash Polarization Effect: Low-entropy characteristics create nightmare scenarios where many flows share identical source-destination patterns, completely defeating traditional load-balancing mechanisms that depend on traffic diversity to function correctly. Hash-based distribution algorithms find little variability to work with, resulting in the dreaded "hash polarization" effect where some links saturate while parallel paths sit idle.
Periodic Bursts That Break Everything: Traffic doesn't flow constantly—it erupts in intense periodic bursts that align with training algorithm cycles in ways that create instant, catastrophic congestion that traditional reactive congestion control mechanisms simply cannot handle.
GPUs complete local computation phases, then communication phases begin where gradients must be exchanged and aggregated network-wide in tightly synchronized operations. This creates severe "incast" scenarios where multitudes of senders simultaneously transmit massive data volumes to small receiver sets, overwhelming switch buffers that were designed for statistical traffic arrival patterns, not deterministic simultaneous transmission from thousands of sources.
Synchronized bursts create instant network congestion that fills switch buffers designed for statistical traffic patterns in microseconds. Traditional congestion control mechanisms were designed for gradual buildup where early warning signals give endpoints time to react. They can't react fast enough to AI's instant congestion events, resulting in catastrophic performance degradation that cascades through entire training jobs.
The Straggler Problem Multiplies Your Pain
Tightly coupled synchronous training jobs create a brutal reality that makes AI infrastructure fundamentally different from traditional distributed systems. Entire clusters wait for the slowest communication links—this "straggler" problem means cluster performance is dictated by network tail latency, not average performance that traditional benchmarks measure.
Think about that. A single delayed flow creates ripple effects where thousands of expensive GPUs sit idle, burning electricity and depreciating in value while they wait for one slow transfer to complete.
Your AI fabric's primary goal isn't high average throughput—it's predictable ultra-low tail latency where any jitter cascades through the entire system and packet loss critically extends Job Completion Time, multiplying your costs exponentially in ways that make traditional "good enough" network performance completely unacceptable.
Why TCP/IP Fails Spectacularly
Standard TCP/IP stacks aren't just inadequate for AI traffic. They're counterproductive in ways that actively hurt performance beyond what you'd see from simply having insufficient bandwidth.
RFC 5681 standard TCP congestion control algorithms were designed for the lossy internet where packet drops signal congestion and gradual rate adjustment makes sense. They're too slow to react to AI fabric dynamics that operate on microsecond timescales where millisecond-scale TCP responses arrive far too late to prevent catastrophic performance degradation.
Equal-Cost Multi-Path routing fails spectacularly. ECMP is the backbone of modern data centers, using stateless packet header hashes to distribute flows across available paths in ways that work beautifully for high-entropy web services with diverse communication patterns creating statistical traffic distributions.
AI training's low-entropy flows break everything. Hash algorithms map many large, high-bandwidth flows onto identical physical paths, creating "hash polarization" that causes severe oversubscription on some links while parallel fabric paths remain underutilized despite costing millions in infrastructure investment.
Cost Impact: The result? Increased tail latency, wasted GPU cycles, and undermined cluster efficiency that doesn't just lose performance—it burns money while your infrastructure fights against itself instead of training models that could generate competitive advantage.
RDMA-Based Interconnects: The Promise and the Problem
AI workloads have stringent requirements. Network designers needed to circumvent traditional networking bottlenecks—host operating system kernels and CPUs that introduce latency measured in tens of microseconds, which is an eternity for tightly-coupled AI applications where microseconds determine whether training succeeds or fails.
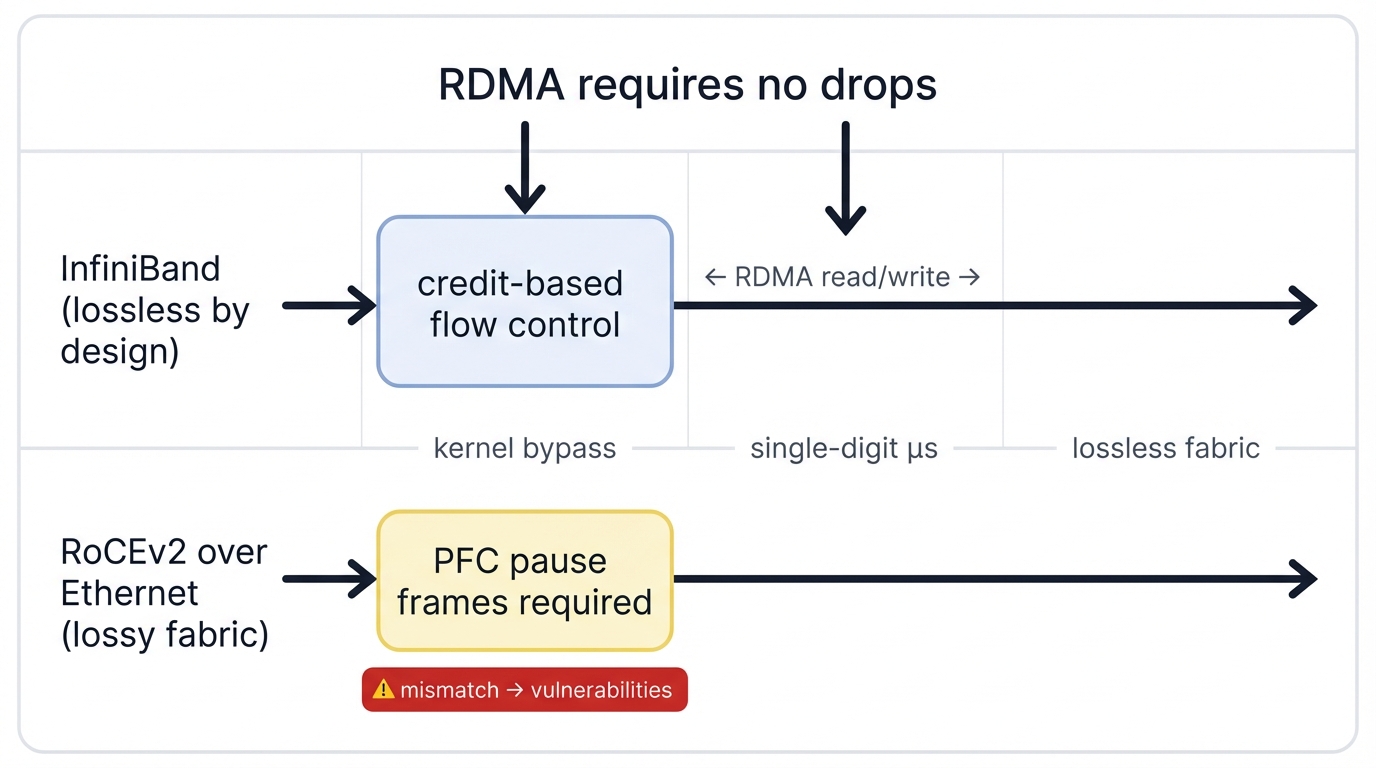
This drove widespread adoption of Remote Direct Memory Access. RDMA became the foundational transport technology for AI fabrics, promising microsecond latencies and delivering entirely new categories of infrastructure vulnerabilities.
Why Kernel Bypass Became Essential
Conventional network stacks require host CPUs to process every packet through multiple memory copies and context switches through kernel networking layers. Result? Tens of microseconds of latency per packet.
That's an eternity.
RDMA solves this through "kernel bypass" where one machine's Network Interface Card directly reads from remote machine memory and writes to remote memory without involving remote CPUs or operating systems. Direct memory-to-memory transfers reduce end-to-end latency to single-digit microseconds, making efficient distributed training possible at scales that would be completely impractical with traditional networking stacks.
The Lossless Requirement That Changed Everything
RDMA's performance models make a critical assumption that shapes every subsequent architectural decision. The underlying network never drops packets—not occasionally, not rarely, but never in ways that traditional lossy networks routinely accept as normal operating conditions.
RDMA protocols include recovery mechanisms, but they're designed for exceptional errors like hardware failures, not routine Ethernet congestion-based packet loss that traditional TCP was specifically designed to handle gracefully. A single dropped packet triggers slow timeout-based recovery that stalls communication for milliseconds—events that devastate synchronous AI job performance by cascading delays through thousands of waiting GPUs.
Architectural Foundation: This fundamental RDMA characteristic imposes strict requirements on underlying networks—they must be "lossless fabrics" where packet drops never occur during normal operation. This single requirement drives immense complexity in modern AI networks where every mechanism traces back to this basic need to prevent packet loss without sacrificing the microsecond-scale performance that makes RDMA valuable.
The Great Architectural Divide
Two primary technologies emerged to deliver high-performance RDMA. Each represents distinct architectural philosophies that define the modern AI networking landscape and create fundamentally different security models with profoundly different attack surfaces.
InfiniBand: Purpose-Built Perfection: InfiniBand represents complete, end-to-end network architecture governed by the InfiniBand Trade Association and built from the ground up for High-Performance Computing workloads. It achieves losslessness through credit-based link-layer flow control where devices won't transmit packets unless they know downstream devices have available receive buffer space.
This proactive approach prevents buffer overruns by design, eliminating packet drops before they can occur and removing the need for reactive loss-prevention mechanisms that introduce latency and complexity.
RoCEv2: Ethernet's Ambitious Retrofit: RDMA over Converged Ethernet version 2 enables InfiniBand transport protocols to run over standard Layer 3 Ethernet, promising massive benefits from Ethernet ecosystem scale, operational familiarity that most teams already possess, and vendor choice that prevents lock-in to proprietary solutions.
However, standard Ethernet is inherently lossy and best-effort by design. This makes RoCEv2 non-natively lossless, forcing reliance on auxiliary Ethernet mechanisms to meet RDMA's lossless requirements. Most notably? Priority-Based Flow Control that introduces its own catastrophic failure modes.
Root Cause Analysis: This fundamental architectural mismatch creates problems that ripple through every layer of modern AI networking—you're forcing lossless protocols onto lossy fabrics, RDMA onto Ethernet, in ways that are the root cause of many significant challenges including security vulnerabilities that attackers are learning to exploit with devastating effectiveness.
Part II: The Complex World of Congestion Control
Your core challenge in RDMA-based AI fabrics? Managing congestion without dropping packets—a seemingly simple requirement that led to complex solutions involving multi-layered, continuously evolving control mechanisms ranging from brute-force link-layer protocols to sophisticated end-to-end algorithms that introduce new vulnerabilities with each layer of sophistication.
First-Generation Solutions and Their Devastating Side Effects
Early lossless Ethernet solutions relied heavily on link-layer mechanisms and simple end-to-end signals. These approaches are foundational components still present in every modern AI fabric. But they have significant limitations that expose the inherent difficulties of retrofitting losslessness onto Ethernet infrastructure that was never designed to provide guaranteed delivery.
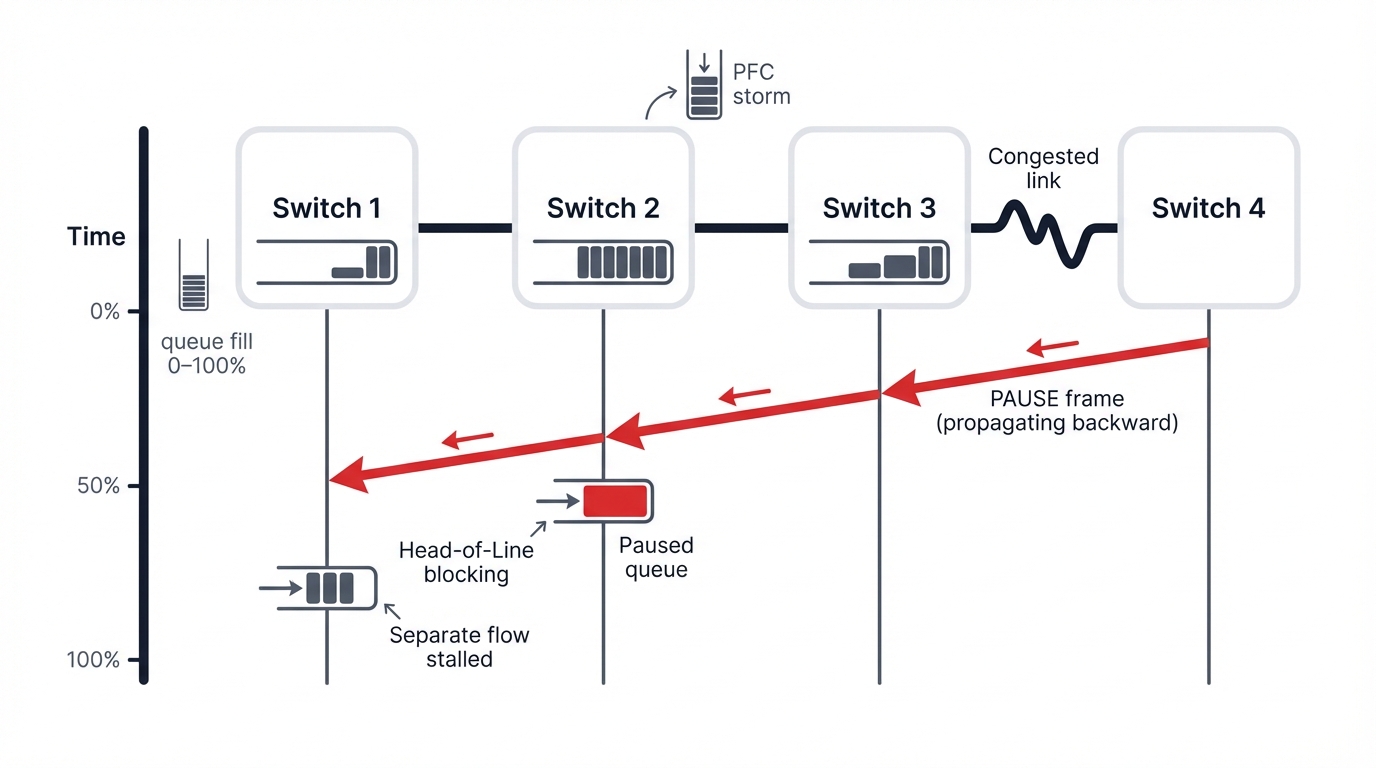
Priority-Based Flow Control: The Nuclear Option
Priority-Based Flow Control serves as the primary mechanism creating "no-drop" Ethernet services for RoCEv2 traffic. It operates on a hop-by-hop basis with straightforward but brutal logic.
Switch egress buffers for specific traffic classes exceed pre-configured thresholds. Switches send IEEE 802.1Qbb PAUSE frames to upstream neighbors, instructing them to stop transmitting specific priority traffic for short periods to prevent buffer overflow and packet drops.
PFC successfully prevents packet loss. But it's a blunt instrument with severe side effects that can devastate network performance far worse than the packet drops it prevents. Most critical? Congestion spreading that turns localized problems into fabric-wide catastrophes.
PFC Storms: When the Cure Becomes the Disease: A single congested link triggers PAUSE frames. This causes upstream switch buffers to fill, which triggers further upstream PAUSE frames in a cascading failure pattern.
This creates "PFC storms"—waves of PAUSE frames that propagate backward through the network, freezing traffic on many links including flows not destined to the original congestion point that get caught in the expanding zone of frozen communication.
Critical Insight: The phenomenon leads to Head-of-Line blocking where a paused flow destined for one congested location prevents other flows in the same queue from reaching uncongested destinations, multiplying the impact of localized congestion into fabric-wide performance degradation. Due to these debilitating effects, modern advanced congestion control systems have a primary objective: manage traffic so precisely that PFC never triggers during normal operation.
When you see PFC activation in monitoring dashboards? Treat it as congestion control system failure, not a successful loss-prevention mechanism—it means your fabric is already in crisis mode where performance has collapsed and recovery will take seconds or minutes rather than microseconds.
Explicit Congestion Notification: A More Graceful Approach
Explicit Congestion Notification provides a more graceful alternative that avoids PFC's brute-force pausing through earlier intervention and endpoint-driven rate control. Instead of waiting for nearly full buffers to trigger emergency PAUSE frames, ECN-enabled switches signal incipient congestion earlier while there's still time for graceful response.
Switch queue depths for particular flows exceed lower "ECN marking" thresholds. Switches set Congestion Experienced bits in traversing packet IP headers without dropping packets—marked packets continue to their destinations carrying congestion signals that endpoints can use to proactively reduce transmission rates before catastrophic buffer overflow occurs.
Receiving NICs detect CE bits and generate special Congestion Notification Packets back to original senders. Senders receiving CNPs know their paths are becoming congested and reduce transmission rates accordingly, creating a closed-loop feedback system where endpoints react to congestion before it becomes severe enough to cause drops or trigger PFC.
It represents significant sophistication improvement from link-layer pause mechanisms. Intelligence moves from network core toward endpoints where it can be more precisely controlled—and where it creates new attack surfaces that sophisticated adversaries are learning to exploit with alarming effectiveness.
Part III: The Strategic Architecture Wars
Theoretical concepts and individual congestion control technologies eventually manifest within cohesive architectures—hardware and software architectures that industry leaders develop to solve AI networking challenges in fundamentally different ways that reveal competing visions for the future of AI infrastructure.
Strategic choices made by silicon vendors, systems companies, and hyperscale providers create a dynamic and highly competitive landscape where billions in R&D investment chase different architectural philosophies with profoundly different security implications.
Silicon and Systems Vendor Battle Lines
Your AI fabric's foundation rests on high-performance silicon powering switches and NICs. Key silicon vendor strategies define the broader market's technological options, while systems company strategies define competitive dynamics that determine what solutions you can actually deploy and how much they'll cost.
NVIDIA: The Vertical Integration Juggernaut
NVIDIA pursues deep vertical integration, offering end-to-end, highly optimized AI infrastructure spanning from GPUs to networking hardware with comprehensive software stacks that promise maximum performance through tight co-design of every component.
InfiniBand Dominance: NVIDIA's Quantum InfiniBand platform remains dominant in the highest echelons of AI training, building on their position as historical leader in HPC interconnects.
They provide complete, purpose-built solutions with co-designed switches, Host Channel Adapters, and software optimized for maximum performance. Advanced technologies like Scalable Hierarchical Aggregation and Reduction Protocol leverage networks for in-network computing, offloading collective communication operations from GPUs directly into switches to reduce latency and free GPU cycles for computation rather than coordination.
Ethernet Evolution: Recognizing the vast Ethernet enterprise market and customer demand for alternatives to InfiniBand's proprietary ecosystem, NVIDIA developed Spectrum-X end-to-end platforms designed to deliver InfiniBand-like performance over Ethernet infrastructure that most enterprises already know how to operate.
Holistic Architecture: These platforms aren't just collections of individual components—they're holistic architectures combining Spectrum-4 switches with BlueField-3 SuperNICs in tightly integrated systems. Key innovations include telemetry-based congestion control using high-frequency network probes and detailed flow metering to gain deep, real-time network visibility that enables sophisticated control algorithms and creates massive attack surfaces for adversaries who compromise telemetry systems.
Broadcom: Merchant Silicon Strategy
Broadcom's strategy centers on providing leading merchant networking silicon—ASICs that form the foundation for numerous vendor switches including Arista and Juniper platforms extensively used in Meta and other hyperscaler data centers where scale and cost-effectiveness matter more than single-vendor integration.
Jericho4 Innovation: The latest Jericho generation was purpose-built for distributed, large-scale AI infrastructure. Manufactured on advanced 3nm process nodes, it combines deep buffering capabilities with intelligent congestion control that ensures lossless RoCE transport over distances exceeding 100 kilometers—crucial for building multi-building or geographically distributed AI clusters that span campus or metropolitan areas.
A key innovation? 3.2 Tbps "HyperPort" technology that logically consolidates four 800GE links, simplifying management while improving utilization and eliminating traditional ECMP hash polarization inefficiencies that plague AI workloads with their low-entropy traffic patterns.
Hyperscaler Fabric Architectures—Where Innovation Lives
Hyperscale providers operate at massive scales that precede off-the-shelf technology capabilities by years. This forces them to pioneer network architecture innovations that eventually trickle down to enterprise solutions—and create security challenges that most organizations won't understand until they're already under attack.
Google: Clean-Slate Custom Excellence
Google's data center networking philosophy embraces willingness to develop ground-up custom solutions when existing technologies prove insufficient for their scale and performance requirements. AI infrastructure represents no exception to this approach—if anything, it's accelerated their investment in proprietary innovation.
Swift Congestion Control: Complementing their custom hardware infrastructure, Google developed Swift congestion control algorithms deployed in production since 2017. These delay-based algorithms don't rely on ECN marking or switch buffer states that require trust in network infrastructure components.
Instead, Swift uses high-precision hardware timestamps to measure end-to-end latency accurately, implementing AIMD mechanisms while maintaining small, constant queuing delays that enable predictable performance without dependency on switch cooperation or telemetry systems that could be compromised.
Meta: Scaling Open Standards to the Limit
Meta's strategy involves aggressively adopting and scaling open standards rather than building proprietary alternatives, making them leaders in operating RoCEv2 for massive AI cluster deployments using vendor equipment and open specifications.
RoCE at Scale: Meta successfully deployed multiple 24,000-GPU Llama training clusters using RoCEv2 over Ethernet, employing traditional Clos topologies built with Arista merchant silicon. Their experience demonstrates that careful co-design of network, software, and model architectures can make standard Ethernet and RoCE perform without bottlenecks at scales that many experts considered impossible with non-proprietary solutions.
Paradigm Shift: Next-generation Meta clusters evolve toward Disaggregated Scheduled Fabric—a significant philosophical shift from reactive congestion control to proactive scheduling that moves from reactive paradigms where networks respond to congestion after it occurs to deterministic paradigms that schedule traffic to prevent congestion from ever developing in the first place.
Part IV: The Security Implications of Converged Architectures
The convergence of networking, security, and AI creates unprecedented challenges that traditional security models never anticipated and most security teams don't have the expertise to address effectively. Advanced congestion control algorithms depend entirely on real-time telemetry feedback loops, creating massive attack surfaces where compromised data becomes weaponized against your own infrastructure.
Telemetry as Attack Vector
Modern AI fabrics rely on sophisticated telemetry systems for performance optimization. In-band Network Telemetry (INT) embeds detailed metadata directly into packets traversing the network—this provides unprecedented visibility into fabric behavior and unprecedented vulnerability to adversaries who gain access to telemetry streams.
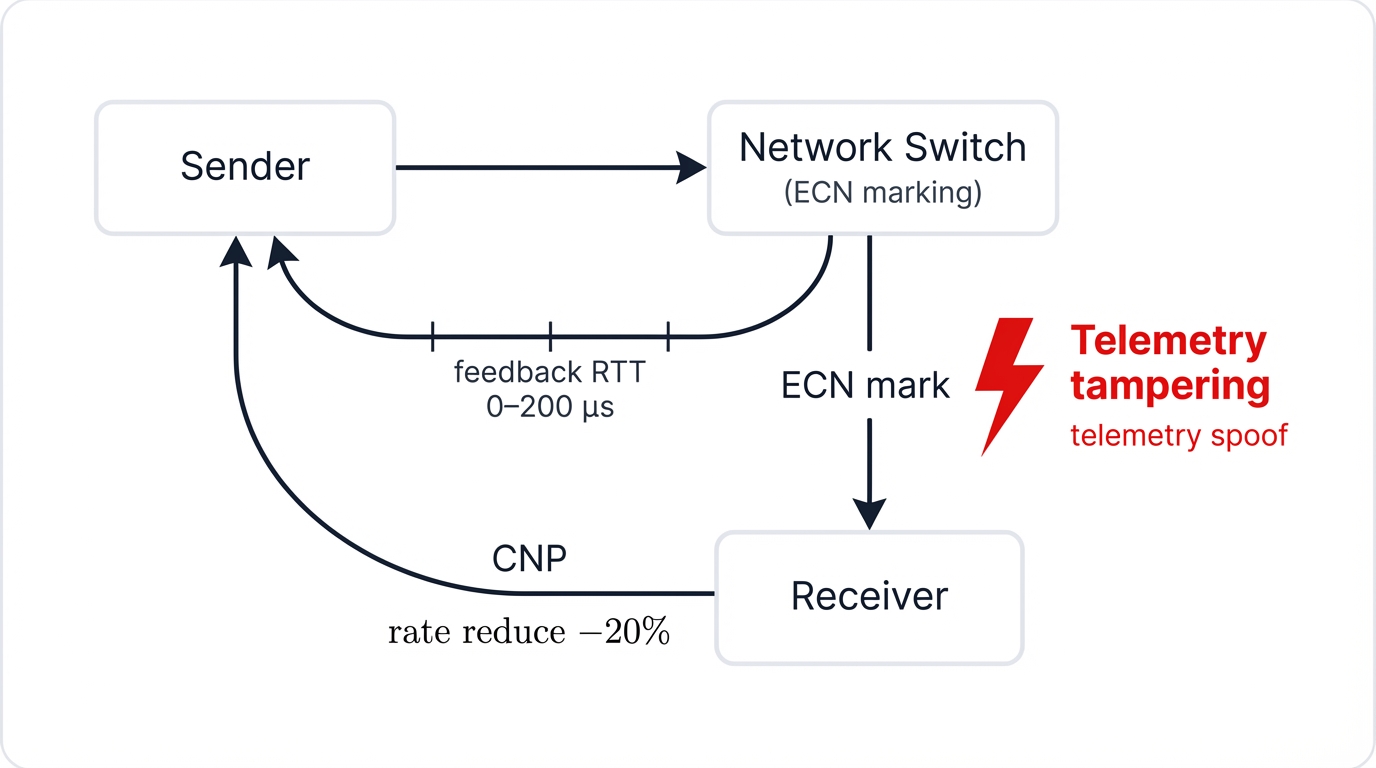
Attackers gaining access to telemetry streams can achieve multiple objectives that traditional network security never had to consider:
- Network Reconnaissance: Map fabric topology through packet traversal patterns, identifying critical paths and single points of failure that become prime targets for disruption attacks
- Workload Intelligence: Infer AI model architectures and training progress from communication patterns, potentially revealing competitive intelligence about model development and training methodologies
- Performance Manipulation: Inject false congestion signals to degrade performance without obvious traces that traditional monitoring would detect as malicious activity
- Covert Channels: Establish hidden communication through congestion patterns that bypass traditional network monitoring and security controls
Congestion Control Weaponization
The tight coupling between telemetry and congestion control creates direct attack vectors where sophisticated attackers don't need to drop packets or crash systems. They manipulate control planes to create self-inflicted performance degradation that looks like operational issues rather than deliberate attacks.
CNP Injection Attacks: Attackers forge Congestion Notification Packets to trigger unnecessary rate reductions. Sender NICs receive false congestion signals and throttle transmission rates dramatically, creating highly effective denial-of-service attacks that remain virtually undetectable to standard monitoring systems that see legitimate congestion control responses rather than malicious manipulation.
RTT Manipulation: Round-Trip Time measurements drive many modern congestion control algorithms. Attackers intercepting and modifying RTT probe responses can create artificially inflated latency measurements where systems respond by reducing transmission rates even when no congestion exists, degrading performance without triggering alerts that would indicate infrastructure compromise.
Devastating Impact: Recent research demonstrated these attacks reducing AI training throughput by up to 89% while remaining virtually undetectable to standard monitoring systems—the attacks appear as legitimate congestion management rather than malicious interference, making attribution and response extraordinarily difficult even for sophisticated security operations teams.
Multi-Vendor Complexity Risks
Converged AI fabrics combine components from multiple vendors—NVIDIA GPUs with Broadcom switches, Arista network operating systems with custom software stacks. This complexity creates security gaps between vendor boundaries where each vendor optimizes their components for performance with different security assumptions.
The integration points become vulnerable to attacks that exploit mismatched security models or inconsistent implementations of standards where behavior differences between vendors create opportunities for manipulation that wouldn't exist in homogeneous single-vendor environments.
Emerging Threat Patterns
Security researchers have identified several emerging attack patterns specifically targeting AI infrastructure—patterns that traditional enterprise security tools and processes are completely unprepared to detect or defend against effectively.
AI-Enhanced Reconnaissance: Attackers use machine learning to analyze telemetry patterns and identify optimal attack windows. These systems learn to recognize training phases when attacks will cause maximum disruption to valuable AI workloads, timing their strikes for moments when recovery will be most difficult and costly.
Distributed Fabric Attacks: Coordinated attacks across multiple fabric components amplify impact beyond what any single-point compromise could achieve. Attackers simultaneously compromise telemetry systems and congestion control mechanisms to create cascading failures that are extremely difficult to diagnose and remediate, especially when security teams lack deep expertise in AI fabric architectures.
Supply Chain Vulnerabilities: The complexity of modern AI fabrics creates numerous opportunities for supply chain attacks where compromised firmware in switches, NICs, or management software can provide persistent access to critical infrastructure that survives patching and security updates focused on higher-level software components while the compromised firmware continues operating undetected.
Part V: Future Outlook and Strategic Recommendations
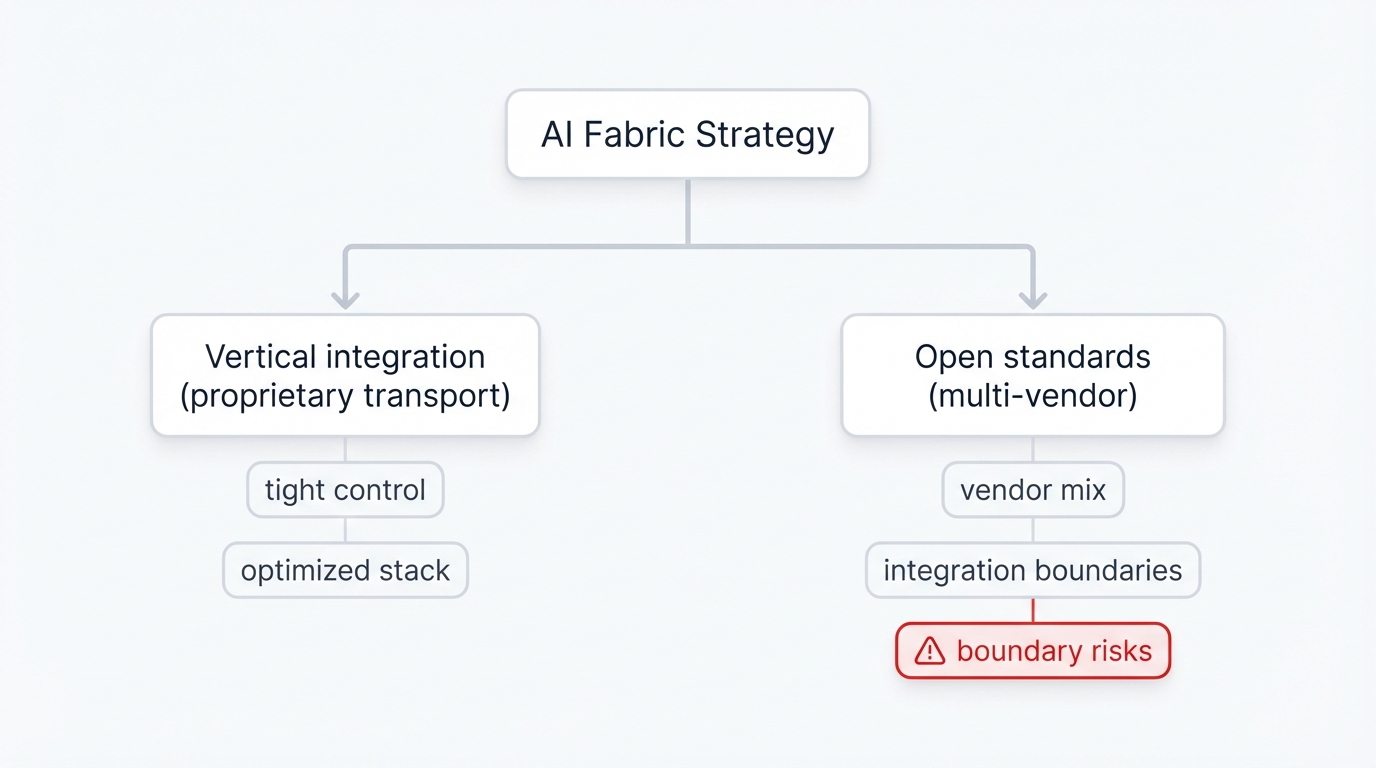
The future of AI fabric security depends on fundamental architectural decisions being made today—decisions that will lock organizations into technology paths for five to ten years while threat landscapes evolve far faster than infrastructure refresh cycles allow for course correction.
Organizations face critical choices between proprietary integrated solutions and open multi-vendor ecosystems. Each path carries distinct security implications and risk profiles that will determine whether your AI infrastructure becomes a competitive advantage or a catastrophic liability.
The Integration vs. Openness Dilemma
Two competing visions dominate the AI networking landscape, and the path you choose will define infrastructure architecture, performance characteristics, cost structures, and security postures for the next decade.
Vertical Integration Path: Companies like NVIDIA offer fully integrated, single-vendor solutions where every component gets co-designed for maximum performance and security through unified control of the entire stack. These approaches provide proven performance and unified security models with clear responsibility boundaries—but they create vendor lock-in risks and potentially higher costs that make CFOs nervous about long-term flexibility.
Open Ecosystem Path: The Ultra Ethernet Consortium and open standards approaches offer vendor choice and ecosystem innovation that promise lower costs and competitive markets where multiple vendors drive innovation through competition. But they increase complexity and create security gaps between vendor boundaries where integration vulnerabilities hide in the spaces between components that no single vendor fully controls or takes responsibility for securing.
Security Architecture Evolution
Future AI fabric security architectures must address the fundamental challenges revealed by current vulnerabilities—challenges that require rethinking security models from first principles rather than bolting protection onto performance-optimized systems as an afterthought.
Hardware-Rooted Security: Next-generation solutions will implement security features directly in silicon where they can't be bypassed by software attacks. Authenticated telemetry, encrypted control planes, and tamper-resistant congestion control mechanisms become standard features rather than optional add-ons that most deployments skip to avoid performance overhead.
Zero-Trust Fabrics: Traditional perimeter-based security models prove inadequate for AI fabrics where the "perimeter" dissolves into thousands of interconnected components with complex trust relationships. Future architectures implement zero-trust principles where every component continuously validates its interactions with every other component, assuming breach rather than assuming trust within network boundaries.
AI-Driven Defense: Security systems will use artificial intelligence to detect and respond to attacks faster than human operators can react—machine-speed threats require machine-speed defenses. These systems learn normal fabric behavior patterns and automatically identify anomalous activities that indicate potential attacks, responding with automated countermeasures before human security teams even receive alerts.
Security Integration: By 2027, integrated security will become a standard feature in AI fabric design rather than an afterthought or optional enhancement. This includes built-in telemetry authentication, encrypted control communications, and real-time threat detection directly integrated into network hardware at the silicon level where attackers can't disable or bypass security controls through software exploitation.
Strategic Recommendations
Organizations building or upgrading AI infrastructure should consider these critical factors that will determine whether their investments deliver competitive advantage or create existential vulnerabilities:
Security-First Architecture: Design security into fabric architecture from the beginning rather than retrofitting protection onto performance-optimized systems after deployment. The cost of security integration during initial deployment is far lower than remediation after attacks occur—and far, far lower than the business impact of successful attacks against production AI infrastructure that's training your most valuable models.
Vendor Risk Assessment: Carefully evaluate the security implications of vendor choices beyond just feature lists and performance benchmarks. Single-vendor solutions offer unified security models but create concentration risks where a single vendor compromise affects your entire infrastructure. Multi-vendor solutions provide flexibility and competitive pricing but require sophisticated integration security that most organizations lack the expertise to implement correctly.
Operational Readiness: Develop security operations capabilities specific to AI fabric threats rather than assuming traditional network security tools and processes will adequately protect fundamentally different infrastructure. Traditional network security teams lack expertise in AI fabric architectures, and traditional security tools don't monitor the telemetry and congestion control behaviors where AI fabric attacks hide from conventional detection.
Continuous Monitoring: Implement comprehensive monitoring that goes beyond traditional network metrics like bandwidth utilization and packet loss. Monitor congestion control behavior for anomalous rate reductions, telemetry integrity for signs of injection or manipulation, and performance patterns that could indicate security compromises masquerading as operational issues.
Future-Proofing Strategy: The networking infrastructure choices made today determine organizational competitive ability in the AI-driven future where model quality and training efficiency separate market leaders from obsolete competitors. Organizations must balance performance requirements, security needs, and operational complexity while preparing for rapidly evolving threat landscapes that will target AI infrastructure with increasing sophistication as the value of disrupting AI capabilities becomes apparent to nation-state adversaries and sophisticated criminal organizations.
The stakes continue rising as AI becomes central to competitive advantage across every industry sector. Understanding and addressing the security implications of converged AI fabric architectures isn't just a technical requirement—it's a business imperative that will determine which organizations thrive in the AI economy and which become victims of their own infrastructure vulnerabilities, watching competitors pull ahead while they rebuild compromised systems and explain to boards why their multi-billion-dollar AI investments became liabilities instead of assets.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score