Table of Contents
- The $4.88 Million Problem
- Part I: AI Fabric Foundations
- Part II: Attack Vector Analysis
- Part III: Multi-Tenant Implications
- Conclusion
The $4.88 Million Problem
Your million-dollar GPU cluster just became a hacker's playground. Think about that for a moment. The very mechanisms designed to prevent network congestion—Priority Flow Control, Explicit Congestion Notification, and Data Center Quantized Congestion Notification—harbor vulnerabilities that can paralyze entire AI training operations with surgical precision.
These aren't theoretical weaknesses gathering dust in academic papers. They're practical attack vectors. Real threats. Exploits that skilled adversaries already know how to leverage against your infrastructure right now, this instant, without you realizing your defenses have been compromised.
Let me paint you a picture. In June 2024, criminals executed a sophisticated heist against engineering firm Arup, stealing $25.6 million using AI-generated deepfakes that fooled even experienced security professionals. But that's just the visible surface of a much deeper problem that extends far beyond social engineering and convincing fake videos.
Critical Statistic: AI security breaches now cost an average of $4.88 million per incident—a 10% increase from 2023 that places AI infrastructure at the top of the cost pyramid. That's the highest cost for any industry vertical. But here's what keeps security researchers awake at night: these numbers only capture the obvious attacks, the incidents that companies actually discover and report.
The real threat lies deeper. Much deeper. It lives in the networking fabric that powers your AI infrastructure, hidden in the very protocols that make high-performance computing possible. When you deploy thousands of GPUs in modern training clusters, you're not just building computational power—you're creating a complex attack surface where congestion control protocols become weapons in the hands of sophisticated adversaries who understand the vulnerabilities better than most defenders do.
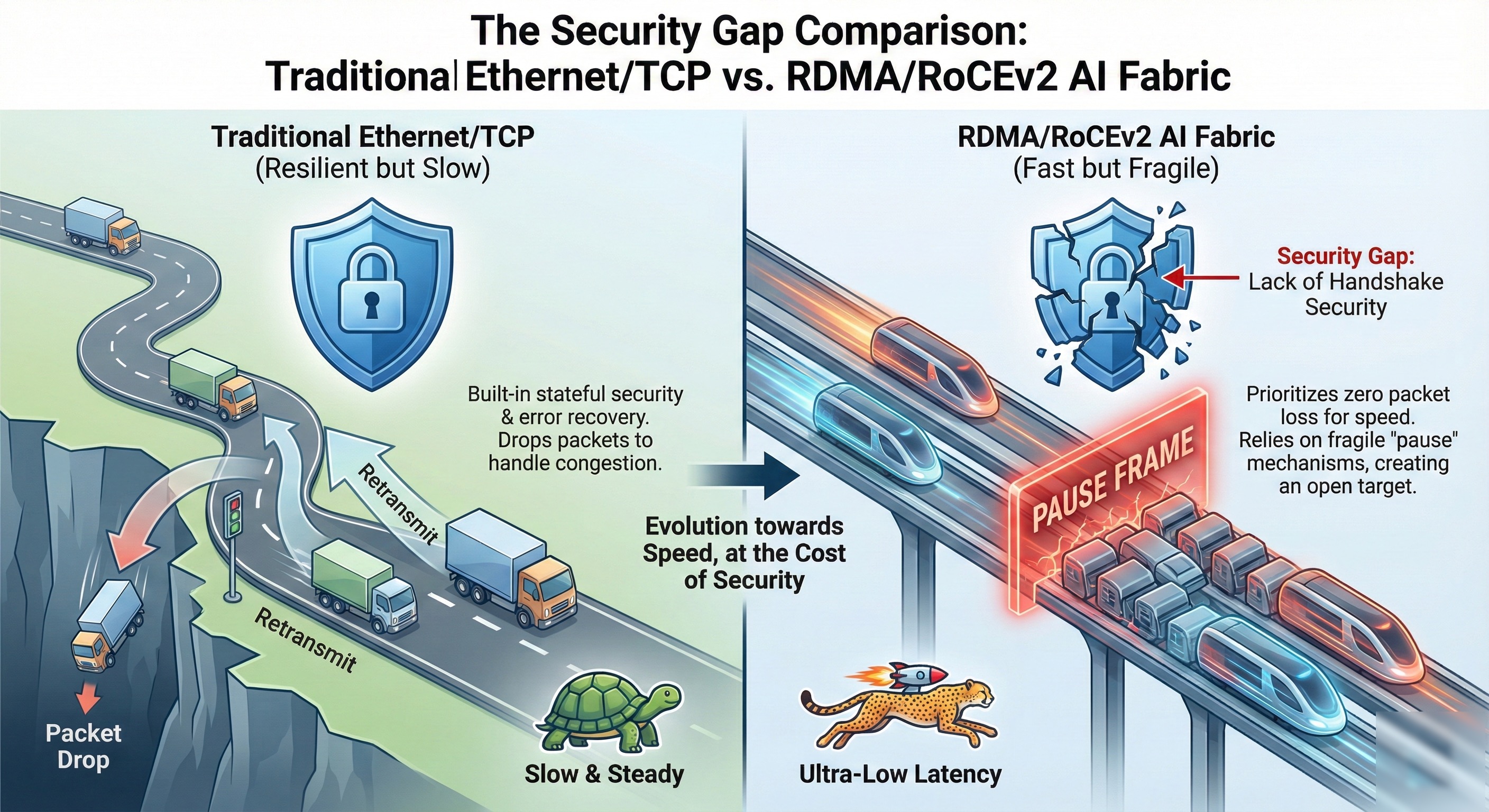
Your modern AI networking fabric contains critical vulnerabilities right now. Multi-tenant GPU clusters face specific threats that most security teams haven't even considered, much less defended against. The relentless pursuit of ultra-low latency through RoCEv2 protocol created an entirely new attack surface that traditional security approaches completely miss.
Priority Flow Control (PFC), Explicit Congestion Notification (ECN), and Data Center Quantized Congestion Notification (DCQCN) protocols manage congestion effectively under normal conditions. They work beautifully. But they also introduce catastrophic vulnerabilities that attackers have learned to exploit with devastating efficiency.
Here's the sobering reality. The primary attack vectors aren't theoretical exercises from academic papers presented at obscure conferences. PFC pause frame storms work in production environments. ECN bit manipulation works in production environments. DCQCN feedback loop exploitation works in production environments, right now, against real targets generating real revenue.
Academic research from premier security conferences like USENIX Security and IEEE Security & Privacy demonstrates these exploits with working proof-of-concept code that anyone with basic networking knowledge can understand and potentially weaponize. Attacks range from catastrophic, fabric-wide Denial of Service that brings everything to a grinding halt, to subtle performance degradation that costs you thousands of dollars per hour in wasted GPU time while appearing completely normal to traditional monitoring systems.
"In commercial multi-tenant environments like public clouds where multiple customers share expensive infrastructure, these vulnerabilities enable something even worse than simple destruction: unfair resource allocation that amounts to computational theft. A malicious tenant can monopolize network bandwidth at other customers' expense, essentially stealing computational resources they didn't pay for while you pay the infrastructure costs and handle angry customer complaints."
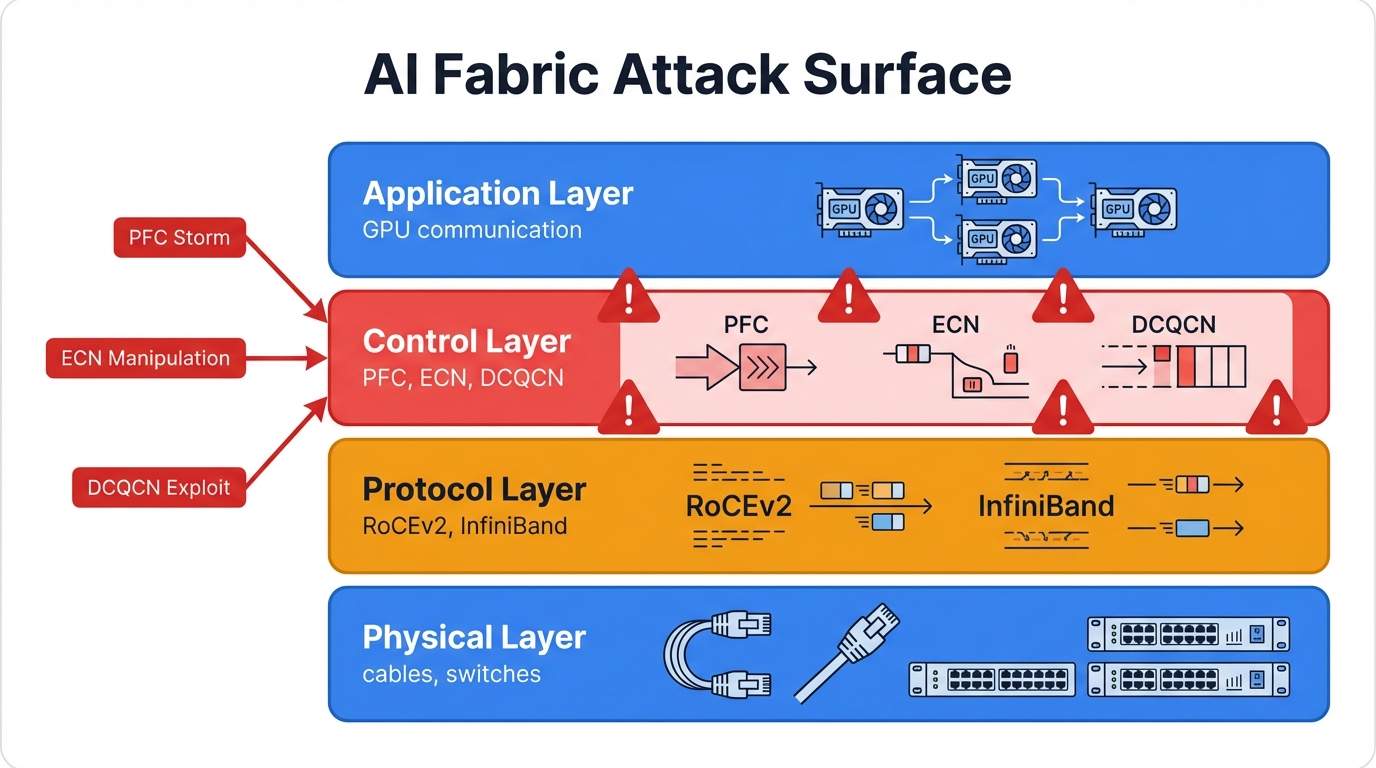
Deconstructing the AI Fabric: Where Performance Meets Vulnerability
You need to understand the components of an "AI Fabric" first. Really understand them. Only then can you comprehend why these security vulnerabilities exist in modern high-performance networks, vulnerabilities that emerge directly from performance-driven design choices made by engineers optimizing for speed rather than security.
Clarifying the AI Fabric: Beyond the Marketing Buzzwords
"AI Fabric" carries significant ambiguity in industry discussions. Marketing teams love the term. Engineers use it differently. Some contexts refer to software-defined data architecture layers using knowledge graphs to unify data sources for AI workloads—a data-centric view that has merit in certain contexts but completely misses the network security challenges we need to address.
Let's get precise. In large-scale AI infrastructure deployments, your "AI Fabric" represents the physical and logical network interconnect linking hundreds or thousands of GPU-accelerated compute nodes in a high-bandwidth mesh. These fabrics handle the unique communication patterns of distributed AI training—synchronous, intense, all-to-all data exchanges among GPUs that would absolutely crush conventional networking equipment designed for traditional web traffic patterns.
Real-World Scale: When Meta deploys a 24,000-node GPU cluster using advanced PFC configurations optimized for AI workloads, they're creating exactly the kind of complex, high-value target that sophisticated attackers want to compromise. The infrastructure costs alone exceed hundreds of millions of dollars, making it an irresistible target for both nation-state actors and cybercriminals seeking maximum impact.
AI fabrics use non-blocking, multi-stage Clos topologies. These provide high, predictable bandwidth with minimal latency between any two endpoints in the network. This high-performance interconnect, increasingly built on open Ethernet standards rather than proprietary solutions locked to single vendors, forms the foundation for AI workloads. It also becomes the primary focus of our security analysis because attackers always target the foundation first.
The RoCEv2 Protocol Stack: Foundation for Low-Latency Communication
Remote Direct Memory Access (RDMA) enables your AI fabric's remarkable performance characteristics. It's revolutionary technology. RDMA allows one computer to access another's memory directly, completely bypassing both operating system kernels and eliminating all the overhead that traditional networking stacks impose on every single packet.
This kernel bypass dramatically reduces latency and CPU overhead. Why does this matter? Because it's absolutely critical for tightly coupled AI training jobs where milliseconds of delay can cascade into hours of wasted computation time across thousands of expensive GPUs all waiting for a single slow connection.
RDMA originated in specialized networks like InfiniBand, which required expensive, proprietary infrastructure that locked you into specific vendors and made scaling economically challenging. RoCEv2 (RDMA over Converged Ethernet version 2) changed everything by transporting RDMA over standard, routable Ethernet and IP networks, making it the de facto standard for open, high-performance AI fabrics that can scale to massive deployments.
Technical Detail: RoCEv2 encapsulates the InfiniBand transport protocol within UDP and IP headers using UDP destination port 4791 as its signature. This design choice enables RDMA to traverse standard Ethernet infrastructure while maintaining the performance characteristics that make it essential for AI workloads.
Here's where security vulnerabilities start emerging. While UDP is connectionless and typically tolerates packet reordering without breaking applications, the network must absolutely not reorder packets within the same flow when carrying RoCEv2 traffic. Not even once. The RDMA transport layer depends completely on in-order packet delivery with zero tolerance for reordering.
A single reordered packet can stall an entire training operation. Just one. Your entire AI fabric's architecture strips away traditional TCP/IP stack overhead through cascading optimizations, each one trading security for speed in ways that most teams never fully understand or document.
Security Implication: This design philosophy creates profound security implications that most teams completely miss during initial deployment. Critical control logic shifts from the host operating system kernel—software that's been hardened and secured over decades of attacks—to RNIC firmware and hardware that receives far less security scrutiny from researchers and penetration testers who typically focus on more familiar attack surfaces.
This migration creates a new attack surface. A poorly understood one. Unprivileged user-space applications can potentially interact with and manipulate low-level network control functions in ways that traditional security models never anticipated or defended against.
The Delicate Balance of Lossless Networking: PFC, ECN, and DCQCN Explained
RDMA protocols fundamentally cannot tolerate packet loss. Zero tolerance. A single dropped packet forces the entire operation to stall and triggers costly recovery procedures that can take milliseconds to complete—an eternity in high-performance computing terms.
In distributed AI training environments, this translates to disaster. Thousands of GPUs sit idle, burning electricity and costing money, while one connection recovers from a single lost packet. RoCEv2 requires what network engineers call a "lossless" or "drop-free" network fabric—a seemingly impossible goal that three key congestion management mechanisms work together to achieve.
Priority Flow Control (PFC): The Double-Edged Sword of Losslessness
RoCEv2 fabrics use Priority-based Flow Control (PFC), specified in IEEE 802.1Qbb, to prevent packet drops from buffer overflows. Unlike older IEEE 802.3x Ethernet PAUSE mechanisms that crudely halted all traffic on a link like a blunt instrument, PFC operates on individual traffic priorities with surgical precision.
Picture this. When a switch's buffer for a specific priority queue exceeds a configured threshold, it sends a PFC PAUSE frame upstream to its neighbor, instructing that upstream device to temporarily stop sending traffic for that specific priority. This link-level, hop-by-hop back-pressure mechanism prevents congestion-related packet drops effectively under normal conditions.
The Vulnerability: The very mechanism designed to prevent minor packet loss can be weaponized to create major network outages that bring your entire infrastructure to its knees. This creates the perfect storm for catastrophic attacks—a critical control mechanism with no authentication that directly impacts network availability.
Explicit Congestion Notification (ECN): The Early Warning System
PFC prevents packet loss. It works. But using it alone creates significant inefficiencies as traffic stalls emerge throughout the fabric like blood clots in an arterial system. Explicit Congestion Notification (ECN), defined in RFC 3168, provides proactive congestion signaling that allows the network to signal incipient congestion before buffers fill completely and PFC pauses become necessary.
ECN uses two bits in the IP header's DiffServ field, creating four possible codepoints that convey congestion information:
- 00: Not-ECT (Not ECN-Capable Transport) - legacy traffic
- 01 and 10: ECT (ECN-Capable Transport) - ready for congestion signals
- 11: CE (Congestion Experienced) - actively experiencing congestion
When an ECT-marked packet arrives at a switch with a filling queue approaching capacity, the switch changes the codepoint to CE instead of dropping the packet outright. This CE mark signals end-to-end that congestion is building somewhere along the network path, allowing senders to proactively reduce their transmission rates before disaster strikes.
The design is elegant. Brilliant, even. But it becomes a critical security vulnerability when attackers realize they can manipulate these same bits to create false congestion signals that trick legitimate senders into throttling themselves unnecessarily.
Data Center Quantized Congestion Notification (DCQCN): The Integrated Control Loop
DCQCN integrates ECN and PFC mechanisms to manage RoCEv2 traffic effectively in production environments. It reacts to ECN's early warnings to avoid triggering the more disruptive PFC mechanisms whenever possible, maintaining high throughput while keeping queues shallow.
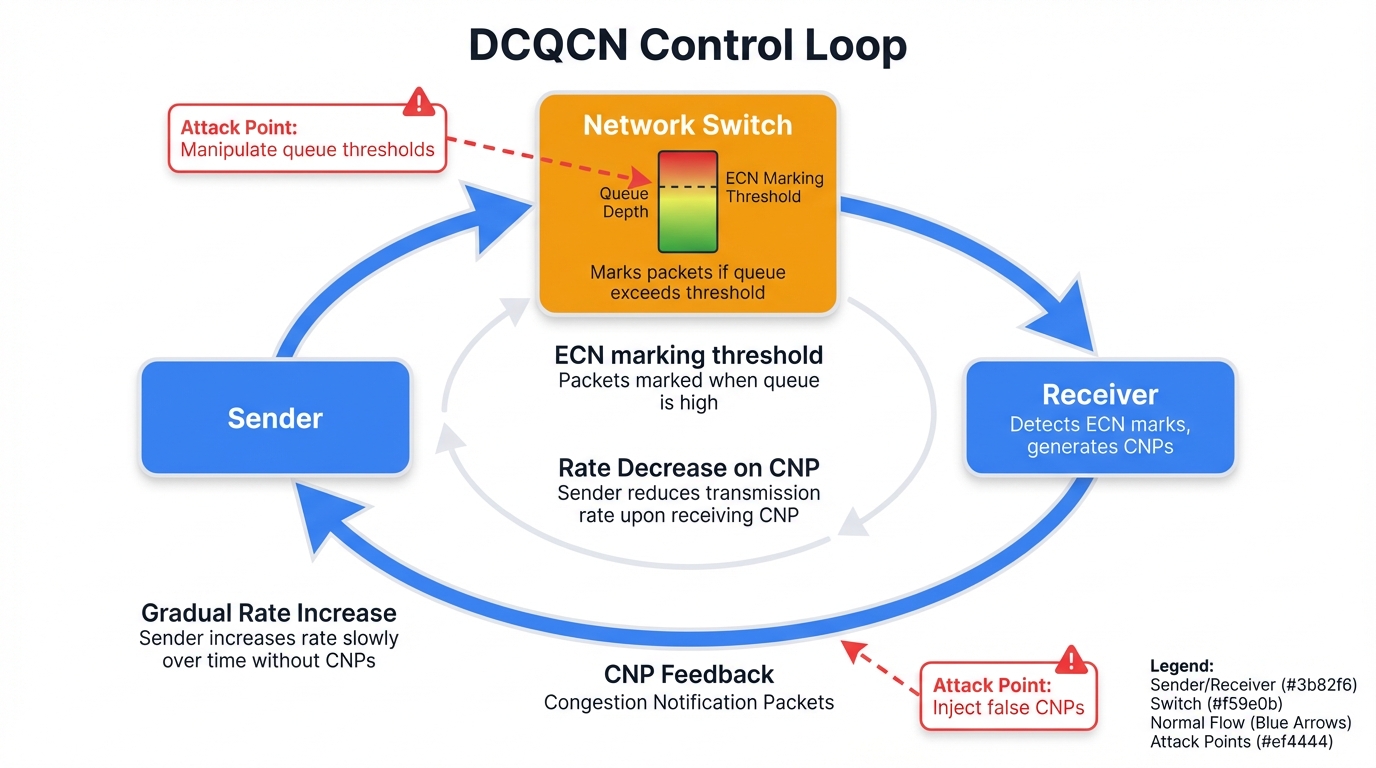
DCQCN operates through a carefully orchestrated three-part feedback loop that requires all components to function correctly:
- Congestion Point (CP): The network switch marks ECN-capable packets with the CE codepoint when its egress queue depth exceeds configured thresholds, signaling that congestion is developing
- Notification Point (NP): The receiving host's RNIC detects CE-marked packets and generates a Congestion Notification Packet (CNP) that it sends back to the original sender
- Reaction Point (RP): The sending host's RNIC receives CNPs and reduces its injection rate for the affected connection, backing off to reduce congestion
System Design: This closed-loop system allows senders to dynamically throttle their transmission rates in response to real-time congestion signals measured directly in the network. High throughput continues while queue depths stay low, minimizing the need for disruptive PFC pause frames that create cascading problems throughout the fabric.
Yet this interdependency creates cascading vulnerabilities. Sophisticated attackers can exploit them. Attacks that circumvent or overwhelm DCQCN force the system to fall back to cruder PFC mechanisms, dramatically increasing susceptibility to catastrophic failures like pause storms and network-wide deadlocks that bring entire data centers to a standstill.
Attack Vector Analysis I: Weaponizing Flow Control with PFC Storms
PFC creates the lossless fabrics that enable high-performance AI training. It works brilliantly. But it harbors a significant vulnerability that can bring down your entire network infrastructure in seconds. Under certain conditions that attackers can deliberately create, its back-pressure signaling propagates uncontrollably through the fabric like a wildfire consuming everything in its path.
A "PFC storm" can paralyze your entire network infrastructure. Every switch. Every link. Every tenant. This creates a direct, severe Denial of Service vector that affects every tenant and workload regardless of isolation mechanisms you've implemented at other layers.
Mechanism of a PFC Storm: From Single Fault to Fabric-Wide Paralysis
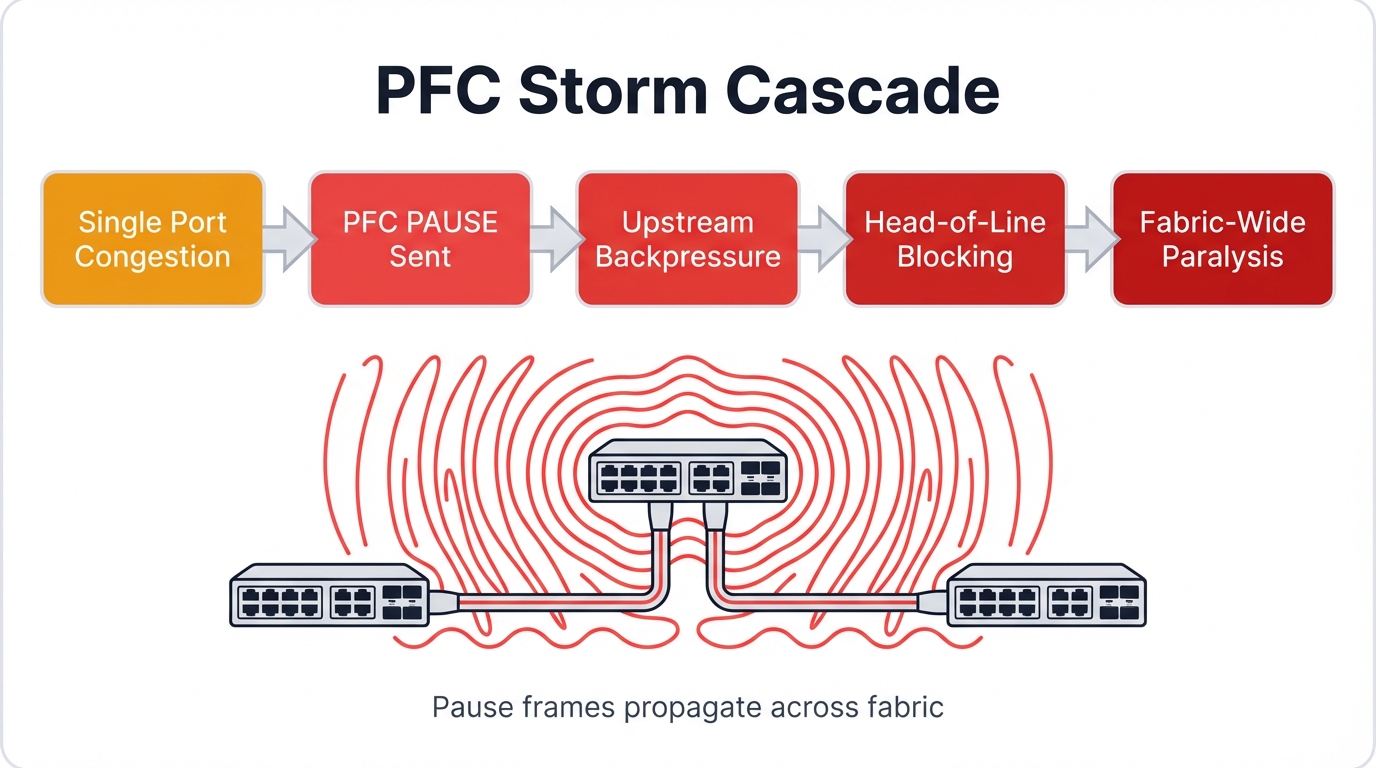
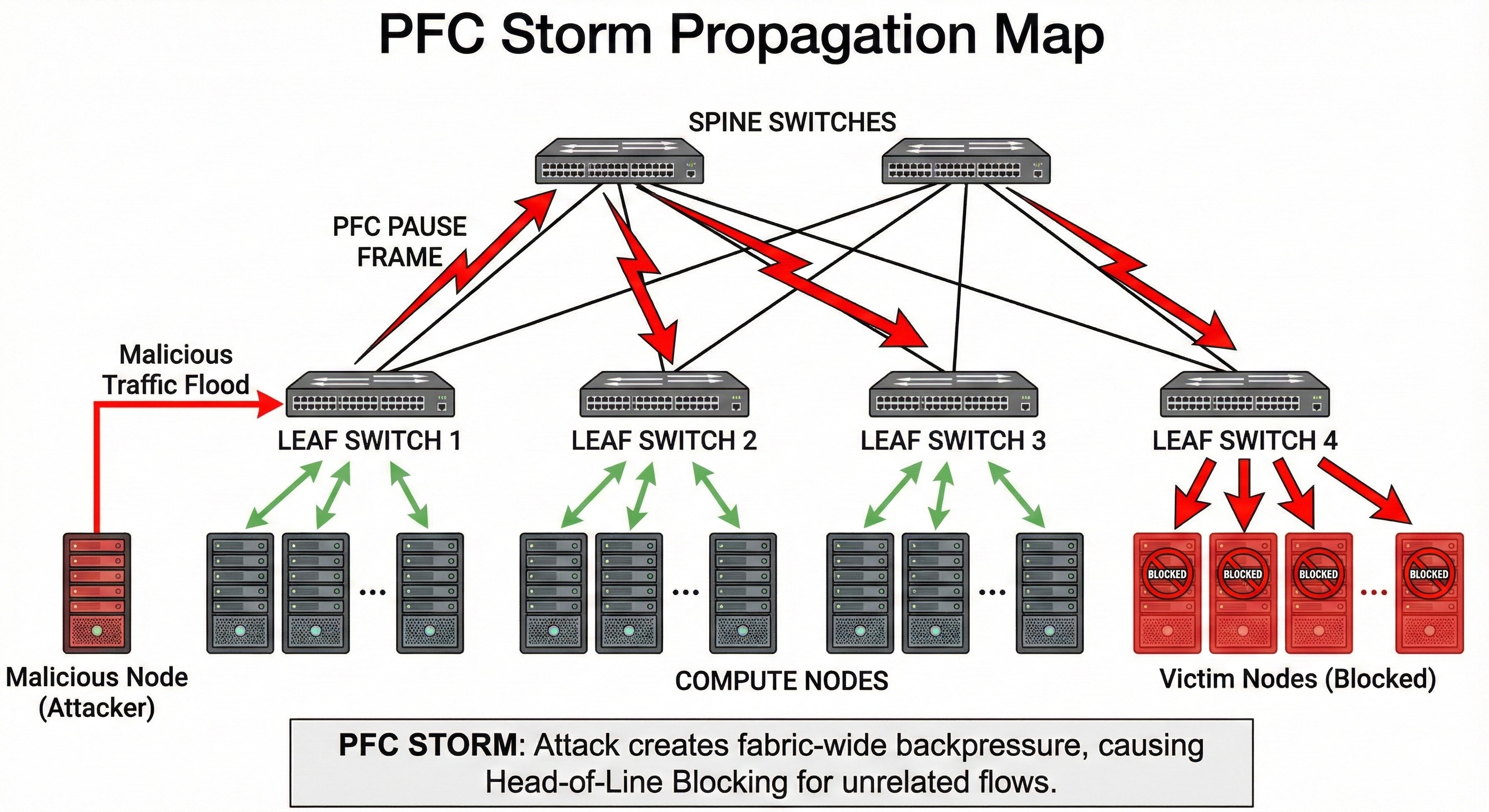
A single malfunctioning end-host Network Interface Card typically triggers PFC storms in production environments. When a NIC's receive pipeline stalls—whether from hardware faults, driver bugs, firmware issues, or deliberate manipulation by malicious actors—it stops processing incoming packets entirely.
Its internal receive buffer fills rapidly. Traffic keeps arriving. The NIC can no longer process it, so packets accumulate in buffers until they overflow. To prevent packet loss and maintain the lossless guarantee, the NIC begins transmitting continuous PFC PAUSE frames to its connected Top-of-Rack (ToR) switch, instructing it to stop sending traffic for the affected priority class.
The cascading failure propagates through your network infrastructure in a predictable, deterministic sequence that attackers can anticipate and exploit:
- Initial Impact: The ToR switch honors the PAUSE frames like a good network citizen and stops transmitting packets to the faulty NIC
- Buffer Saturation: The ToR's egress buffers fill rapidly with packets destined for the paused NIC, as traffic continues arriving from other sources throughout the network that don't yet know about the problem
- Upstream Propagation: Rising buffer levels trigger the ToR to send PFC PAUSE frames to its upstream spine switches, spreading the problem upward
- Network-Wide Cascade: The process repeats hop-by-hop through spine switches, leaf switches, other ToR switches, and finally reaches all sending servers in a cascading failure that consumes the entire fabric
Catastrophic Result: No traffic in the affected lossless priority class can transmit anywhere in the network within seconds of the initial trigger. This creates total Denial of Service affecting all fabric tenants simultaneously, not just the one with the original hardware problem, turning a localized fault into a global catastrophe.
The Role of Head-of-Line Blocking in Cascading Failures
Head-of-Line (HOL) blocking significantly exacerbates PFC storm propagation throughout your fabric by amplifying the impact of a single congested flow. HOL blocking occurs when a blocked packet at the front of a queue prevents all subsequent packets from being processed, even when those packets have clear paths to their destinations and could theoretically be forwarded without any issues.
PFC operates on a per-priority basis. Simple enough. But typically all traffic flows sharing the same priority class use the same physical switch port queue because switches have limited queue resources. When PFC pauses that priority due to congestion at a single destination (like our faulty NIC), it blocks all flows in that priority class network-wide.
"Innocent" flows destined for non-congested ports suffer collateral damage from the single point of failure they have no connection to. This vulnerability becomes critical in multi-tenant environments where unrelated tenant traffic gets multiplexed onto the same physical links and shares priority classes for economic efficiency.
"One tenant's hardware failure—or one tenant's deliberate attack—can paralyze another tenant's completely unrelated workloads running on different servers in different parts of the data center, creating a cascading failure scenario that violates every isolation guarantee you've promised your customers."
Impact Analysis: A Deterministic Path to Denial of Service
PFC storms create complete, fabric-wide DoS. They affect all tenants simultaneously, not just the one experiencing the initial fault. What appears to be a localized device failure becomes a global network outage that can cost organizations millions of dollars in lost productivity, missed SLAs, and emergency response expenses.
Most research discusses PFC storms as unfortunate outcomes of hardware or software faults—accidents to be prevented through better engineering. But the underlying mechanism is entirely deterministic and can be triggered deliberately. In multi-tenant environments with untrusted tenants sharing expensive infrastructure, malicious actors can intentionally trigger this condition.
Attack Method: By exploiting NIC driver vulnerabilities documented in CVE databases, leveraging firmware bugs that vendors haven't patched, or crafting workloads that deliberately overwhelm NIC receive pipelines through precisely timed packet floods, malicious tenants can induce states that perfectly mimic hardware failures while maintaining complete deniability.
This capability enables potent, difficult-to-attribute DoS attacks against entire clusters that security teams struggle to defend against. The network's response—cascading pause frame propagation that follows protocol specifications exactly—remains identical whether the triggers are accidental hardware faults or deliberate attacks.
This ambiguity blurs the line between reliability issues and security threats. It creates perfect cover for attackers who want to disrupt operations while maintaining plausible deniability, allowing them to claim their malicious actions were simply unfortunate accidents or hardware failures beyond their control.
Attack Vector Analysis II: ECN Bit Manipulation for Covert Degradation
Move beyond the brute-force approach of PFC storm DoS attacks. There's something more subtle. More insidious. Attack vectors that manipulate Explicit Congestion Notification mechanisms to achieve their goals without triggering the obvious alarms that fabric-wide outages create.
By forging congestion signals that appear completely legitimate to monitoring systems, attackers can trick victim senders into unnecessary throttling that causes severe performance degradation and enables unfair resource allocation that's extremely difficult to detect using traditional network monitoring approaches.
The ECN Feedback Mechanism in RoCEv2
DCQCN congestion control in RoCEv2 fabrics uses ECN as its primary congestion signaling mechanism. Network switches mark packet IP headers with the CE (Congestion Experienced) codepoint when they detect building congestion in their queues. Receiving hosts detect these marks and send Congestion Notification Packets (CNPs) back to the original senders, which then reduce their transmission rates according to carefully tuned algorithms.

This feedback loop assumes something critical. It assumes that CE marks are trustworthy signals generated only by legitimate network elements experiencing actual congestion. That assumption becomes a critical vulnerability when attackers realize they can manipulate the same signaling mechanisms without any authentication requirements stopping them.
Theoretical Exploits: Forging Congestion for Throughput Suppression
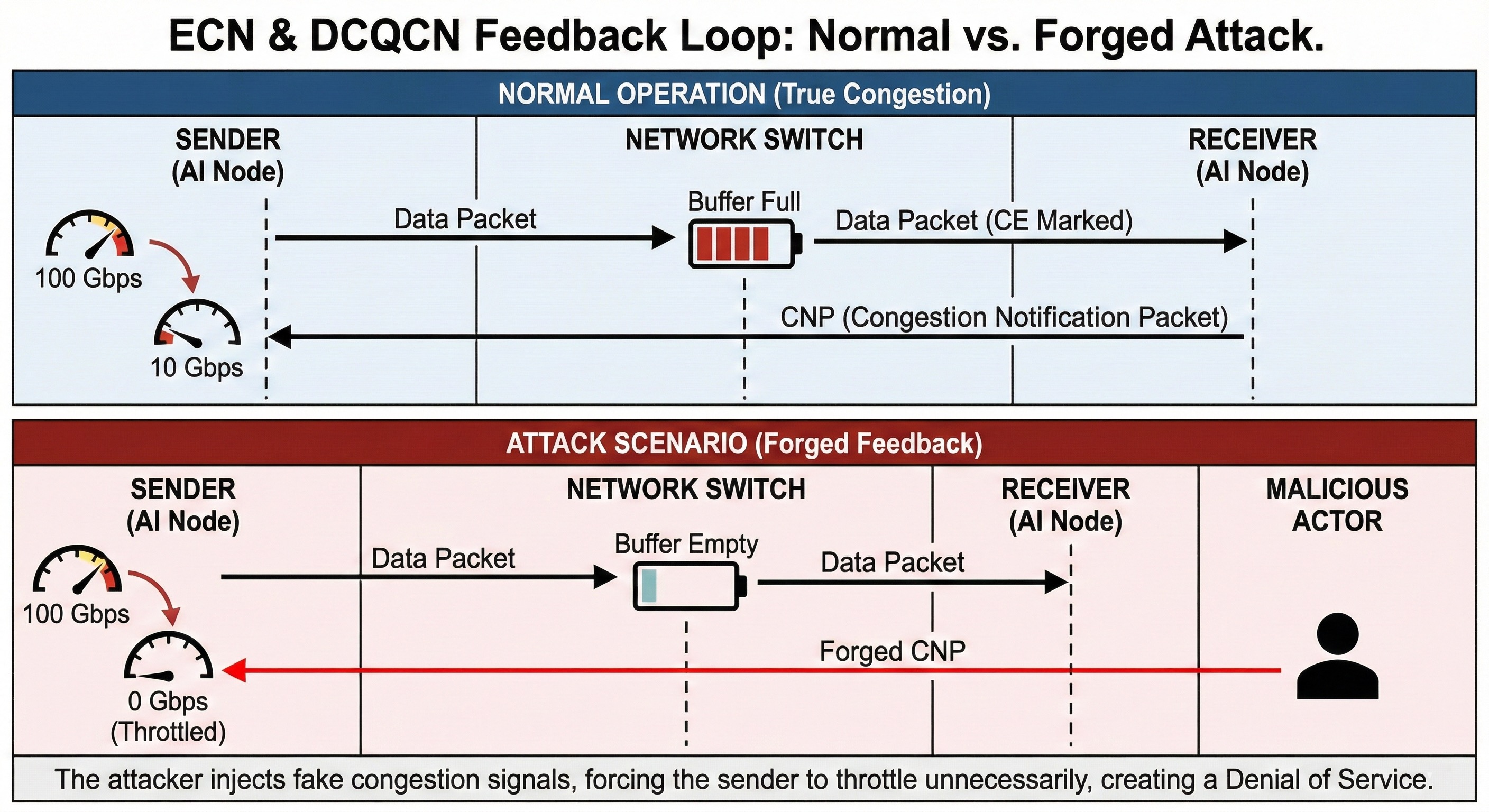
ECN manipulation attacks subvert the fundamental trust model underlying congestion control in ways that traditional security approaches never anticipated. Malicious tenants can inject spoofed IP packets destined for victim tenant receivers, with these forged packets arriving with ECN bits already set to CE as if they had traversed heavily congested network paths.
Victim receivers face an impossible challenge. They cannot distinguish between legitimate CE marks from network switches experiencing real congestion and malicious forgeries from other senders deliberately trying to degrade their performance. So they behave correctly according to DCQCN protocol specifications: generating and sending CNPs back to the apparent victim senders.
Attack Result: When victim senders receive floods of seemingly legitimate CNPs arriving from their receivers, they conclude that heavy network congestion exists along their paths and must be addressed immediately. Following protocol exactly as designed, they drastically reduce their transmission rates to alleviate congestion that doesn't actually exist.
This creates severe throughput suppression for victim traffic. Performance degrades dramatically. Targeted DoS attacks execute perfectly while appearing to monitoring systems as simple network congestion that should resolve naturally. The beauty of this attack from an adversary's perspective is that victims appear to be experiencing legitimate network congestion—making the attack extremely difficult to detect and virtually impossible to attribute to specific malicious actors.
Lessons from TCP: Applying Historical Congestion Control Attacks to Modern Fabrics
This attack vector directly parallels vulnerabilities that security researchers identified in TCP's ECN implementation decades ago. History repeats itself. Early security analyses of RFC 3168 showed that attackers could spoof TCP segments with CE bits set to force legitimate senders to halve their congestion windows unnecessarily, significantly degrading connection performance.
The fundamental vulnerability remains identical in legacy TCP and modern RoCEv2 implementations despite decades of security research. Congestion signals travel in completely unauthenticated IP headers that anyone can forge. Any entity capable of sending packets to receiving endpoints can trigger congestion control feedback mechanisms without any verification of authenticity.
"The original ECN protocol design assumed cooperative Internet models where only routers and switches would legitimately set CE bits—a trust model that made sense in the early Internet but fails completely in adversarial multi-tenant data centers where sophisticated attackers operate with impunity."
RDMA security research explicitly demonstrates forging congestion notification packets for such attacks. Researchers provide working proof-of-concept implementations that anyone can study and potentially weaponize. This attack represents a sophisticated Type of Service (ToS) flood where attackers falsify the ToS fields containing ECN bits to degrade victim connections selectively while maintaining full performance for their own traffic.
Impact Analysis: Inducing Performance Degradation and Jitter
Unlike widespread, immediately obvious PFC storm outages that trigger every alarm system and emergency response protocol, ECN manipulation creates subtle, targeted attacks that can operate undetected for extended periods. Days. Weeks. Even months if executed carefully by patient adversaries.
The primary impact involves severe performance degradation for specific tenants, applications, or flows rather than complete service unavailability that would trigger immediate investigation. This selective targeting creates profound unfairness in resource allocation that's extremely difficult to prove or prosecute.
Economic Impact: In public cloud environments with metered GPU time where customers pay hundreds of dollars per hour for high-performance computing resources, this attack vector enables covert economic warfare. Malicious tenants degrade competitor performance systematically, increasing job completion times and substantially inflating cloud computing bills while the victim struggles to understand why their carefully optimized workloads suddenly perform poorly.
Beyond simple throughput reduction that customers might notice in billing reports, these attacks introduce significant network jitter and performance unpredictability that's harder to quantify. Victim sending rates oscillate wildly as they respond to false, erratic congestion signals that don't reflect actual network conditions at all.
Synchronous, tightly coupled AI training operations suffer particularly severe impacts. These workloads depend on lockstep GPU communication where all nodes must progress together. The induced jitter can potentially slow entire distributed training jobs to match the pace of the most severely throttled node, creating a cascading performance degradation that affects workloads far beyond the initial attack target.
Attack Vector Analysis III: Sophisticated Exploitation of the DCQCN Feedback Loop
The most sophisticated attacks target DCQCN protocol logic directly. They exploit fundamental design choices to achieve resource monopolization that goes far beyond simple packet forgery. These "performance hacking" attacks manipulate stateful RNIC resource management mechanisms to circumvent fairness controls entirely, allowing attackers to claim far more than their legitimate share of expensive network bandwidth.
The Anatomy of a DCQCN Feedback Loop: CP, NP, RP, and the CNP Packet
DCQCN's feedback loop relies on Congestion Notification Packets (CNPs) as explicit messages from receivers (Notification Points) to senders (Reaction Points) signaling network congestion that requires immediate rate reduction. CNP reception directly triggers sender injection rate reduction according to carefully tuned algorithms developed through extensive testing.
This makes CNPs extremely high-value targets. Attackers who can manipulate CNP generation or forge CNPs directly can control sender behavior with precision.
Critical Vulnerability: The protocol assumes that CNPs represent legitimate congestion signals generated by receivers experiencing actual congestion, but provides absolutely no authentication mechanism to verify this critical assumption. This trust gap becomes a critical attack vector that sophisticated adversaries exploit routinely.
Exploit A: Forging Congestion Notification Packets for Targeted Throttling
This attack directly and powerfully extends the ECN bit manipulation approach we discussed earlier. Instead of indirectly triggering victim receivers to generate CNPs through spoofed CE-marked packets that traverse the normal feedback loop, malicious actors forge and send CNPs directly to victim senders with devastating effect that bypasses detection mechanisms focused on data plane traffic.
The research paper "NeVerMore: Exploiting RDMA Mistakes in NVMe-oF Storage Applications" provides concrete proof-of-concept for this "Fake Congestion" attack that works in production environments. The attack requires only that privileged users know victim connection identifiers (Queue Pair Numbers), which are often predictable through simple enumeration or observable through side-channel attacks that monitor timing variations.
Attack Mechanism: Victim RNICs receiving forged CNPs interpret them as legitimate congestion signals without any verification and drastically reduce transmission rates according to protocol specifications designed for cooperative environments. The core vulnerability lies in the complete lack of cryptographic authentication for CNP packets—any attacker who can send packets to victims can forge CNPs that appear completely legitimate.
Sender RNICs have no mechanism whatsoever to verify that received CNPs were genuinely triggered by CE-marked packets at intended receivers rather than fabricated by attackers seeking to degrade performance. This enables highly effective, targeted DoS or performance degradation through direct manipulation of sender rate-limiting mechanisms that operate in hardware for performance reasons.
Exploit B: Parallel and Staggered Queue Pair Attacks for Unfair Bandwidth Allocation
These attacks represent a significant escalation in sophistication. They exploit fundamental RDMA congestion control design decisions to achieve unfair, disproportionate bandwidth shares that completely bypass intended fairness mechanisms built into the protocol.
The vulnerability emerges from a two-part design decision that seemed reasonable in isolation. First, RDMA congestion control (including DCQCN) operates on a per-connection basis, with Queue Pairs (QPs) serving as the fundamental endpoints. Second, to optimize performance for short "mice flows" that dominate many workloads, new QPs begin transmitting at full line rate and only reduce their rates after receiving congestion feedback.
Design Flaw: This performance optimization for one workload type creates critical security vulnerabilities for others in multi-tenant environments. AI training jobs dominated by long-lived "elephant flows" that transfer massive datasets make this design choice a pure vulnerability in AI fabric contexts where sustained high throughput over extended periods matters far more than quick startup performance for short transfers.
Zhu et al. demonstrate these attacks comprehensively in their influential paper "RDMA Congestion Control: It's Only for the Compliant" that every AI fabric security professional should read:
Parallel QP Attack
Malicious tenants open multiple Queue Pairs to the same destination simultaneously. Simple. Effective. Devastating. Instead of using single QPs for large data transfers like well-behaved tenants do, attackers fragment their traffic across dozens or hundreds of QPs.
Since network congestion control allocates bandwidth on a per-QP basis rather than per-tenant or per-application, attackers can unfairly capture bottleneck link bandwidth shares proportional to their total number of QPs. They effectively starve well-behaved tenants using single QPs according to best practices, claiming ten times or a hundred times their fair share of expensive network resources.
Staggered QP Attack
Attackers can effectively ignore congestion control entirely through a more sophisticated technique. They continuously open new QPs and send data in round-robin fashion across them, cycling through fresh connections faster than congestion control can react.
Since new QPs start transmission at line rate and only throttle after receiving congestion feedback (typically one network RTT later, measured in microseconds), attackers can send a full RTT worth of data at line rate on one QP, then switch to a fresh, un-throttled QP before the feedback mechanism engages.
Sophisticated Evasion: By cycling through continuously created new QPs faster than DCQCN can react, attackers maintain near-line-rate aggregate throughput while completely circumventing DCQCN congestion control mechanisms designed to ensure fair sharing. This represents a fundamental subversion of the fairness assumptions underlying modern RDMA fabrics that protocol designers never anticipated.
Impact Analysis: Achieving Resource Monopolization and Starving Co-located Tenants
"Performance hacking" attacks severely compromise fairness and performance isolation in multi-tenant environments where economic models assume roughly equal resource sharing. Malicious tenants can effectively monopolize network resources while starving co-located tenants of their fair bandwidth shares. The economic impact in cloud environments can be substantial and ongoing.
Real testbed experiments demonstrate the severity. Attackers using these techniques can claim 72% of available bandwidth that should be fairly shared with other flows paying the same prices. By ignoring congestion control mechanisms that well-behaved tenants respect, attacker traffic fills switch buffers and increases 99.9th percentile tail latency for other tenants' short flows by seven-fold, turning microsecond operations into millisecond delays.
"The attack surface extends beyond traditional wire protocol vulnerabilities to resource abstraction models that seemed safe during initial design. These attacks leverage standard user-space APIs for creating network resources (Queue Pairs) to achieve fundamentally unfair data-plane outcomes that violate the implicit service level agreements of shared infrastructure, creating a profound disconnect between what customers pay for and what they actually receive."
Comparison of Congestion Control Attack Vectors
| Attack Vector | Mechanism | Primary Impact | Affected Component(s) | Key Research Citations |
|---|---|---|---|---|
| PFC Storm | Malfunctioning or deliberately stalled NIC sends continuous PFC PAUSE frames, causing fabric-wide back-pressure via Head-of-Line blocking | Fabric-wide DoS affecting all tenants | All Ethernet switches and fabric tenants sharing priority classes | Multiple production incident reports from major cloud providers |
| ECN Bit Forgery | Attacker injects spoofed IP packets with pre-set CE bit, tricking victim receiver into sending CNPs that throttle legitimate senders | Targeted Performance Degradation, Unfairness, Network Jitter | Victim sender/receiver pair; sender's RNIC throttled based on false congestion signals | Historical TCP ECN vulnerability research (RFC 3168 security analysis) |
| CNP Forgery | Attacker forges and sends unauthenticated CNPs directly to victim sender, bypassing receiver entirely | Targeted DoS or Performance Degradation with high precision | Victim sender's RNIC directly throttled without any legitimate congestion | "NeVerMore: Exploiting RDMA Mistakes in NVMe-oF Storage Applications" |
| Parallel/Staggered QP | Attacker exploits per-QP rate limiting and line-rate start behavior by opening many QPs or cycling through new ones to bypass congestion control | Unfair Bandwidth Allocation, Resource Monopolization, Increased Tail Latency | All tenants sharing bottleneck links with attacker | "RDMA Congestion Control: It's Only for the Compliant" (Zhu et al.) |
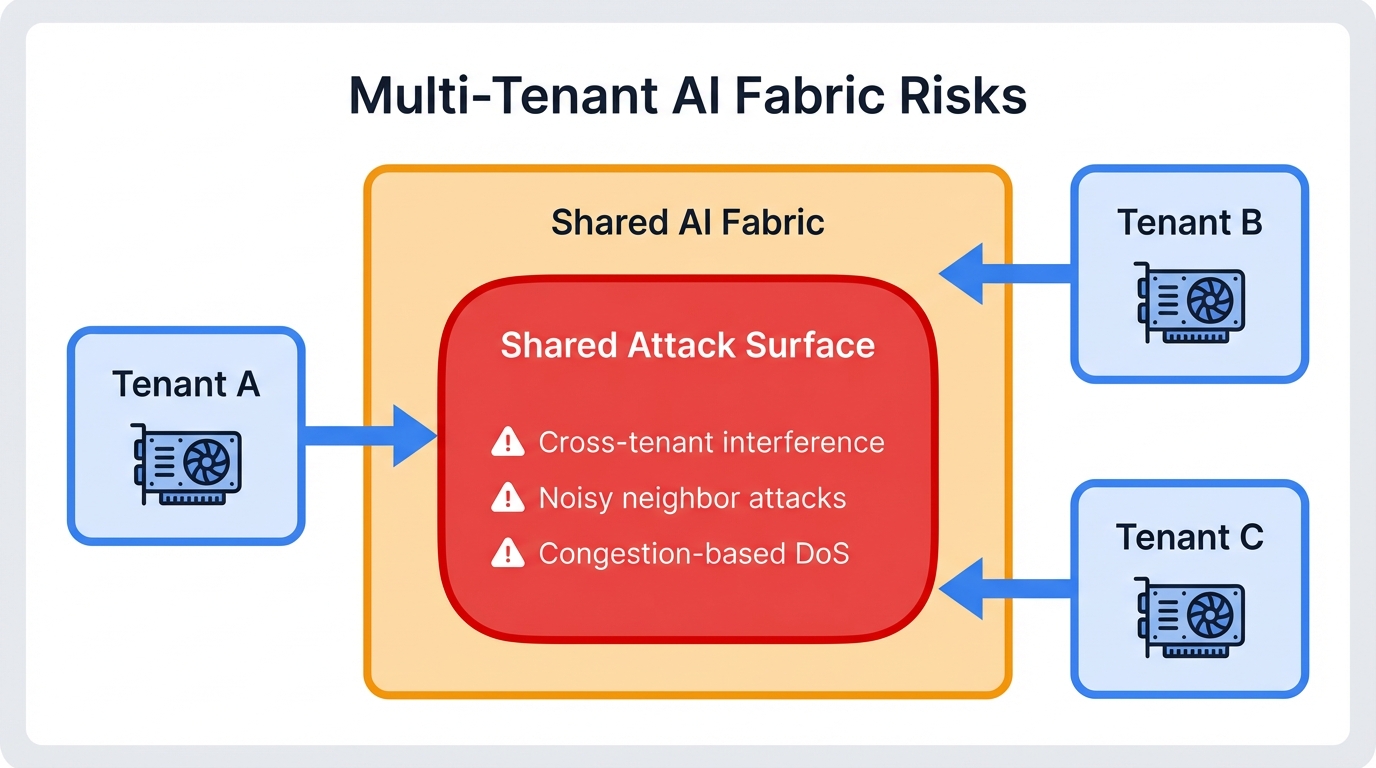
The Multi-Tenant Battlefield: Performance Isolation and Resource Fairness
Multi-tenant environments dramatically magnify these vulnerabilities. They provide both the means and motive for exploitation in a perfect storm of opportunity that attackers recognize and exploit. Motivations for attacking congestion control—competitive advantage, resource monopolization, or simple disruption of competitors—reach their peak in shared infrastructure environments where your enemies literally share the same physical hardware.
Securing such environments requires threat models that extend far beyond traditional isolation boundaries like VLANs and firewalls.
"Hard" vs. "Soft" Multi-Tenancy: Defining the Threat Model
Multi-tenancy in GPU clusters fundamentally involves sharing expensive compute and network resources among multiple users to reduce costs and improve utilization efficiency. Economics drives the decision. But the sharing model varies significantly based on tenant trust relationships that determine which threats you must defend against.
Soft Multi-Tenancy
Generally involves trusted tenants, such as different teams within the same organization working toward common goals. Isolation primarily manages resource allocation and prevents accidental interference between workloads rather than defending against deliberate attacks from sophisticated adversaries.
Hard Multi-Tenancy
Involves fundamentally untrusted tenants. Different customers in public cloud environments. Competitors. Potential adversaries. Isolation must provide cryptographically strong and logically robust defenses against malicious actors attempting to attack other tenants or the underlying infrastructure itself.
Threat Model Evolution: For hard multi-tenancy scenarios, congestion control attacks transition from operational reliability risks that IT teams manage to credible security threats that security teams must defend against actively. Malicious tenants possess both the means (direct fabric access through their legitimate compute allocations that you provided them) and clear motives (disrupting competitors or stealing computational resources worth thousands of dollars per hour) to launch sophisticated attacks.
The "Noisy Neighbor" Problem Reimagined: Congestion Control as the Attack Vector
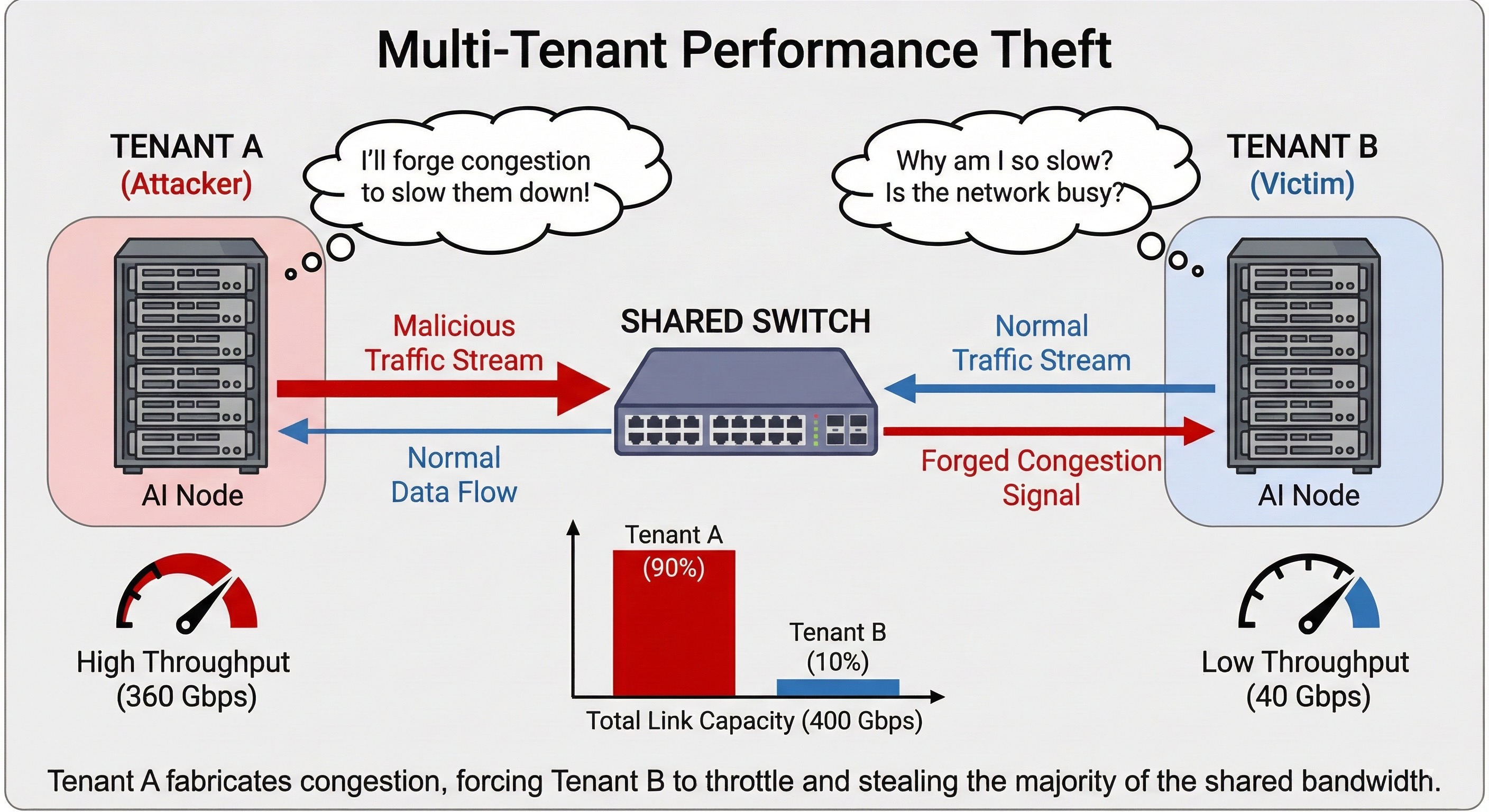
Cloud computing's classic "noisy neighbor" problem takes on an actively adversarial dimension. You know the traditional problem: one tenant's high resource consumption negatively impacts others sharing the same physical hardware through simple resource exhaustion.
Traditional noisy neighbors required legitimate consumption of vast resources to impact others—they actually used the CPU, memory, or bandwidth they monopolized. Malicious tenants exploiting congestion control vulnerabilities no longer need massive legitimate resource consumption to be "noisy." They become actively "malicious neighbors" who exploit control protocols to amplify their impact and unfairly steal resources they didn't pay for.
"Parallel and Staggered QP attacks represent the weaponization of noisy neighbor effects in ways that fundamentally challenge cloud economics. Attackers don't just consume excessive resources through legitimate means that you can bill them for—they manipulate congestion control mechanisms to create artificial noise while monopolizing bandwidth far beyond their fair allocation, stealing computational resources from paying customers while paying only for a fraction of what they actually consume."
Why Traditional QoS is Insufficient: The Challenge of Microarchitectural Resource Isolation in RDMA NICs
Traditional network Quality of Service mechanisms look effective on paper. Packet classification. Traffic marking. Switch queuing policies. But they cannot effectively mitigate these advanced threat vectors that operate at fundamentally different layers of the stack.
While proper QoS configuration can segment traffic and provide some protection against simple attacks, it fails to address the fundamental end-host RNIC control loop vulnerabilities that sophisticated attackers exploit with devastating effect.
Recent research demonstrates that current RDMA performance isolation approaches completely overlook complex, hidden RNIC microarchitectural resources. Malicious tenants can exploit these invisible resources. These attacks target shared internal resources like QP state machines, memory buffers, and congestion control logic that remain invisible to and unmanageable by traditional network monitoring and management systems.
Limitation of Traditional Security: QP-based attacks perfectly illustrate this fundamental limitation—they exploit logical resources (Queue Pairs) that are invisible to and unmanageable by traditional switch-based QoS mechanisms operating at Layer 2 and Layer 3. Effective security enforcement and trust boundaries must extend beyond network switch ports deep into server chassis, potentially reaching PCIe bus levels where RNICs connect to host systems in ways that traditional security architectures never anticipated.
Mitigation Strategies and Architectural Recommendations
Addressing sophisticated AI fabric congestion control attack vectors requires comprehensive defense strategies. Multi-layered approaches work best. You need reactive detection mechanisms that identify attacks in progress. Proactive protocol enhancements that prevent attacks from succeeding. Novel architectural solutions designed specifically for adversarial multi-tenant environments where traditional security boundaries fail completely.
Reactive Defenses: The Role and Limitations of PFC Watchdogs
Network equipment vendors have implemented "PFC watchdogs" as a primary defense mechanism against PFC storm threats that have caused numerous production outages. These systems continuously monitor PFC-enabled switch port queues with microsecond-level precision, detecting when queues remain paused by continuous PFC frames for abnormally long periods (typically hundreds of milliseconds to seconds depending on vendor implementation).
When watchdog systems detect persistent pauses indicating storms or deadlocks developing, their mitigation typically involves disabling PFC on stalled queues and dropping packets destined for those ports. This breaks the back-pressure cycles and allows fabric operation to resume relatively quickly, usually within seconds.
Fundamental Compromise: This last-resort measure represents a fundamental compromise that administrators must understand clearly—it prevents fabric-wide DoS by sacrificing the "lossless" network guarantees for affected ports, creating temporarily lossy links that can impact application performance in ways that RDMA protocols don't handle gracefully.
PFC watchdogs provide crucial reactive defense capabilities. They work. But they treat symptoms (storms propagating through the fabric) rather than addressing root causes of faults or malicious triggers initiating the attacks. While essential for operational resilience that keeps businesses running, watchdog systems cannot prevent the attacks from occurring initially and may not detect subtle, low-rate attacks designed to stay below detection thresholds while still degrading performance significantly.
Proactive Defenses: Towards Authenticated Congestion Feedback and Secure Control Packets
ECN manipulation and CNP forgery attacks share a common root cause that protocol designers never adequately addressed: the complete lack of authentication mechanisms for congestion signals and feedback packets that control billions of dollars of infrastructure. Building robust, proactive defenses requires securing the control plane communication channels that these protocols rely upon.
Theoretically, secure transport protocols like IPsec could provide cryptographic integrity and authentication for all packets, including CNPs and ECN-marked traffic flowing through the network. However, recent research suggests significant complications that make deployment challenging in production environments.
RoCEv2's connection identifiers (Queue Pair Numbers) remain opaque to IPsec processing at network layers. This potentially allows sophisticated injection attacks to bypass protection mechanisms by exploiting the semantic gap between what IPsec protects and what RDMA protocols actually need protected.
Future Protocol Development: The 2024-2025 threat landscape shows attackers becoming increasingly sophisticated in their approach to protocol-level attacks that traditional defenses miss entirely, making proactive authentication mechanisms essential rather than optional security features that vendors can skip. Future protocol development efforts, such as those underway at the Ultra Ethernet Consortium developing next-generation AI fabric standards, must incorporate authenticated, tenant-aware congestion control mechanisms from the ground up rather than attempting to retrofit security onto existing protocols that were never designed with adversarial environments in mind.
Architectural Solutions: Hardware-Assisted Performance Isolation and Rate Limiting
Mitigating sophisticated QP-based performance hacking attacks requires fundamental architectural approaches. Why? Because these exploits target the basic resource allocation models built into RNIC hardware and firmware at layers where software solutions cannot effectively intervene.
Hardware-Assisted Isolation
The "Harmonic" system from recent USENIX research represents current state-of-the-art solutions. Leading-edge technology. The approach uses programmable, intelligent PCIe switches positioned between host CPUs and RNICs, combined with RDMA-aware rate limiters that can monitor and modulate per-tenant RNIC resource utilization in real-time with microsecond-level granularity.
Advanced Solution: This architecture provides true performance isolation that remains conscious of RNIC internal microarchitecture in ways that traditional network-based approaches cannot achieve. It actively prevents malicious tenants from creating excessive numbers of QPs or abusing line-rate start features that enable Staggered QP attacks. The system can enforce fairness policies that traditional network-based approaches cannot address because they operate at fundamentally different layers of the stack.
Policy-Based Throttling
Recent proposals from Snyder and others suggest implementing new congestion control algorithm weighting schemes. These dynamically decrease aggregate bandwidth allocations for users who open excessive numbers of Queue Pairs. This approach directly disincentivizes and mitigates Parallel QP attacks at their source.
Opening more connections no longer yields greater bandwidth shares. The fundamental economic incentive for the attack disappears when attackers realize they gain nothing from the effort.
Advanced Vendor Solutions: Learning from Industry Leaders
The 2024-2025 timeframe has seen major networking vendors develop specialized solutions for AI fabric security challenges that traditional networking equipment never addressed:
- NVIDIA Spectrum-X: Advanced congestion control with built-in attack detection and mitigation capabilities specifically designed for AI workloads running at massive scale. Includes hardware-accelerated monitoring that can detect anomalous traffic patterns in real-time at line rate, identifying attacks within microseconds rather than the seconds or minutes that software monitoring requires.
- Arista AI Optimization: Integrated telemetry and anomaly detection systems that provide deep visibility into congestion control behavior across large-scale fabrics spanning thousands of switches. Their AI-driven analysis can identify attack signatures that traditional monitoring misses because it operates on statistical patterns rather than simple threshold violations.
- Cisco Secure AI Factory: Comprehensive security framework that includes authenticated congestion control mechanisms and tenant isolation features designed specifically for multi-tenant AI environments where traditional security approaches fail. Implements cryptographic verification of congestion signals to prevent forgery attacks.
Industry Recognition: These solutions represent industry recognition that traditional networking security approaches are fundamentally insufficient for modern AI fabric threats that exploit performance mechanisms in ways that security teams never anticipated. Vendors are finally taking these attacks seriously after years of treating them as purely academic concerns.
The Critical Importance of Advanced Fabric Telemetry and Anomaly Detection
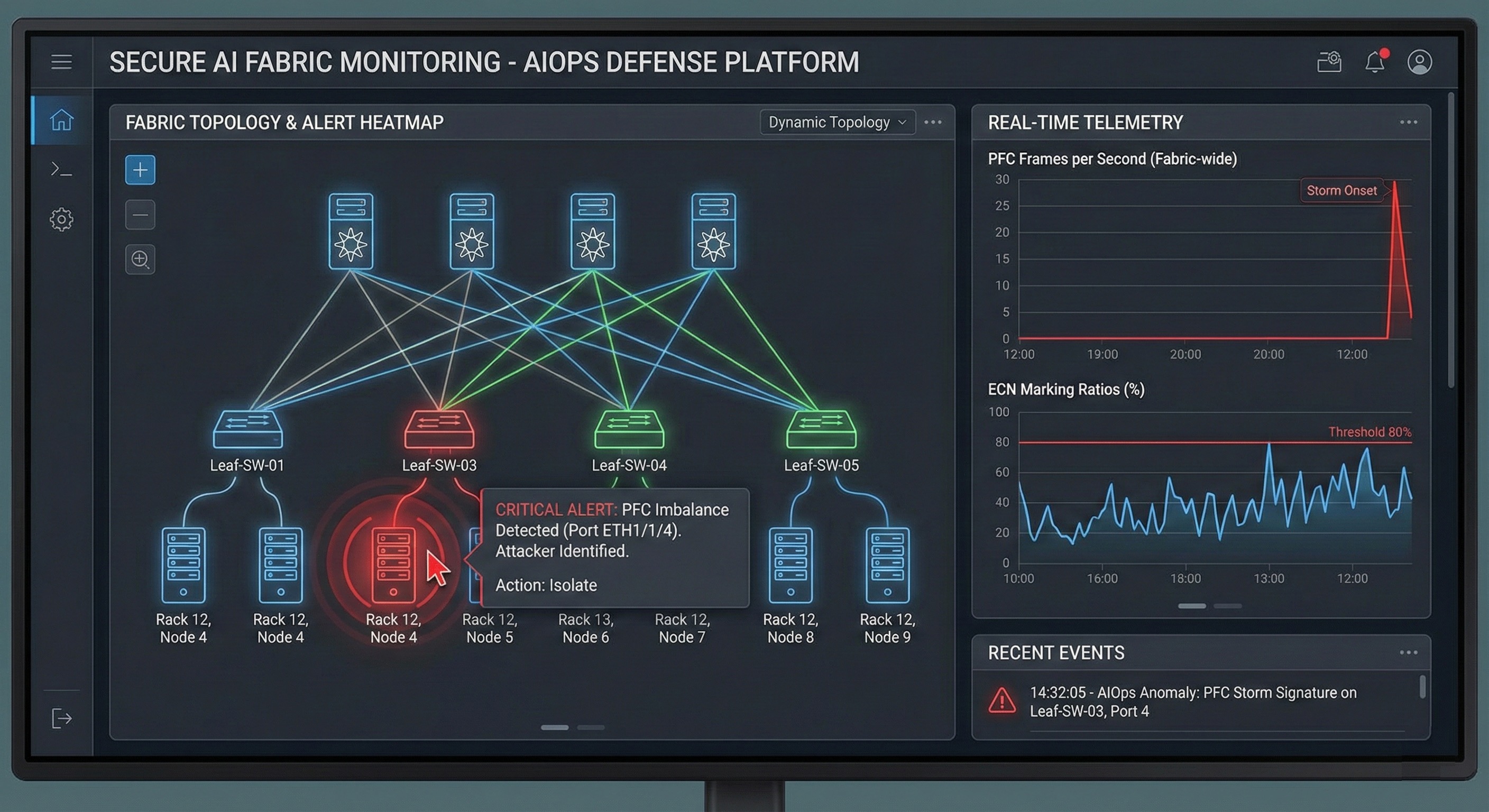
Comprehensive fabric visibility remains absolutely critical. Regardless of preventative measures deployed, you need to see what's happening. Your AI fabric management platforms must provide deep telemetry and continuous monitoring capable of detecting attack signatures in real-time before they cause significant damage to production workloads.
Key per-port and per-tenant metrics that require continuous monitoring include:
- PFC pause frame counts per priority: Sudden spikes indicate potential storm conditions developing
- ECN CE marking rates: Unusual patterns may indicate manipulation attempts by attackers
- CNP generation and reception rates: Anomalous levels suggest potential forgery attacks in progress
- Active QPs per host or tenant: Rapid increases may indicate QP-based attacks beginning
- Bandwidth utilization patterns: Fairness violations often show distinctive signatures that statistical analysis can identify
- Latency and jitter measurements: Performance degradation attacks create characteristic patterns in latency distributions
"Sudden, anomalous spikes in these metrics provide early warning indicators of ongoing attacks that human operators would never notice manually. Feeding comprehensive telemetry data into AI-powered operations (AIOps) platforms enables establishment of normal behavioral baselines specific to each tenant and workload type, allowing the system to detect subtle deviations that indicate attacks in progress even when they stay below simple threshold-based alerts."
Remote PFC (rPFC) Technology: Containment at the Edge
One of the most promising recent developments is Remote PFC (rPFC) technology. It enables attack containment at network edges rather than allowing problems to propagate fabric-wide the way traditional PFC does. rPFC allows congestion control decisions to be made closer to traffic sources, limiting the blast radius of potential attacks dramatically.
Promising Technology: This technology shows particular promise for containing PFC storms and limiting their ability to cascade throughout entire fabric infrastructures the way traditional PFC mechanisms do. Early deployments have demonstrated 1.5x throughput improvements while providing better isolation between tenant traffic flows, proving that security and performance can improve simultaneously when architectures address root causes.
Mitigation Strategies and Their Efficacy
| Mitigation Strategy | Targeted Attack(s) | Mechanism | Efficacy & Limitations |
|---|---|---|---|
| PFC Watchdog | PFC Storm | Detects persistently stalled queues, disables PFC, drops packets to break back-pressure cycles | High Efficacy: Prevents fabric-wide DoS effectively. Limitation: Reactive approach; sacrifices lossless guarantee during mitigation |
| IPsec for CNPs | CNP Forgery, ECN Bit Forgery | Provides cryptographic integrity and authentication for CNP-carrying IP packets | Potentially Effective: Prevents simple spoofing attacks. Limitation: High performance overhead; sophisticated injection attacks may bypass protection |
| Per-Tenant QP Limiting | Parallel QP Attack | Administrative policy enforced by hypervisor or RNIC driver limiting maximum QPs per tenant | Effective for Parallel QP: Prevents QP flooding resource monopolization. Limitation: Cannot prevent Staggered QP cycling attacks |
| Hardware-Assisted Rate Limiting | Parallel & Staggered QP | Intelligent PCIe switches monitor and enforce per-tenant RNIC rate limits and resource utilization | State-of-the-Art: Robust, microarchitecture-aware performance isolation. Limitation: Requires new, specialized server hardware with significant cost implications |
| Advanced Telemetry & Anomaly Detection | All Attack Vectors | Statistical fabric telemetry analysis detecting baseline behavior deviations using machine learning | Detection, not Prevention: Provides early warning of ongoing attacks. Limitation: Reactive approach; effectiveness depends on baseline quality and attack subtlety |
| Remote PFC (rPFC) | PFC Storm, Cascade Effects | Enables congestion control decisions at network edges, limiting attack blast radius | Emerging Solution: Shows 1.5x throughput improvements with better isolation. Limitation: Still in early deployment phases |
Emerging Threats: The 2024-2025 Landscape
The threat landscape continues evolving rapidly. New attacks emerge monthly. Several concerning developments demand your immediate attention:
GPU Farming Attacks
Security researchers have identified GPU farming as the most lucrative cloud-based cybercrime category currently operating at scale. Attackers specifically target AI infrastructure for cryptocurrency mining and model theft that can generate millions in revenue. These attacks combine traditional cloud exploitation techniques with the congestion control vulnerabilities we've analyzed throughout this article, creating hybrid threats that existing security tools struggle to detect.
Critical Vulnerabilities
- CVE-2024-0132: The NVIDIA Container Toolkit vulnerability demonstrates how container escape techniques can be combined with network attacks to achieve persistent access to AI infrastructure. Attackers gain initial access through container vulnerabilities, then leverage network attacks to expand their reach.
- CVE-2025-23266 (NVIDIAScape): This emerging vulnerability class shows how attackers can exploit GPU virtualization layers to gain unauthorized access to congestion control mechanisms that should be isolated. The attack bypasses traditional isolation boundaries by exploiting shared resources at the GPU driver level.
AI-Driven Attacks
Malicious actors are beginning to use AI-powered tools to optimize their own attacks. Ironic, isn't it? They create adaptive congestion control exploits that can evade traditional detection mechanisms by learning from defender responses. These attacks use machine learning to identify optimal timing and targeting strategies for maximum impact while minimizing detection probability through sophisticated evasion techniques.
Evolving Threat: The convergence of AI-powered attack tools with intimate knowledge of AI fabric vulnerabilities represents a significant escalation in the sophistication of threats facing modern AI infrastructure. Attackers now have the same advanced capabilities that defenders use, creating an arms race where both sides leverage machine learning to gain advantage.
Towards a Resilient and Secure AI Fabric
This comprehensive analysis demonstrates conclusively that congestion control mechanisms essential to modern AI fabric performance constitute significant, practical attack surfaces. Organizations must address these vulnerabilities immediately, not in next quarter's security roadmap. The relentless pursuit of extreme performance through RoCEv2 and its associated protocols led to design choices that become readily exploitable in untrusted, multi-tenant environments.
Think about what we've covered. Kernel bypass. Unauthenticated control packets. Per-connection rate limiting. Each optimization made perfect sense in isolation when engineers focused solely on performance. But together they create a perfect storm of vulnerabilities that sophisticated adversaries exploit routinely.
The resulting vulnerabilities enable everything from catastrophic fabric-wide DoS that brings entire data centers to their knees, to subtle performance degradation that costs organizations millions of dollars in wasted computational resources while appearing completely normal to traditional monitoring systems. Most seriously, they allow malicious actors to completely monopolize shared infrastructure resources, undermining the economic foundations of cloud-based AI services.
"This reality necessitates fundamental paradigm shifts in how we approach AI fabric design and security that go far beyond adding another firewall or updating access control lists. Traditional boundaries between performance management and security have dissolved completely in modern AI infrastructure—performance isolation failure now equals security breach in ways that traditional security models never anticipated."
Security cannot remain a perimeter firewall afterthought bolted onto high-performance systems after deployment. It must become foundational. Co-designed with fabric performance characteristics from the ground up, integrated into every protocol decision and every architectural choice from the earliest design phases.
Key Takeaways:
- Immediate Action Required: Congestion control vulnerabilities in AI fabrics represent active, exploitable threats targeting production systems
- Multi-Layered Defense: Combine reactive detection, proactive authentication, and architectural solutions for comprehensive protection
- Beyond Traditional Security: Performance isolation failures equal security breaches in modern AI infrastructure
- Investment in Advanced Solutions: Hardware-assisted isolation and authenticated protocols are essential, not optional
We must move beyond reactive solutions like PFC watchdogs. They help. But they're not enough. We need comprehensive, architectural solutions that address root causes rather than symptoms that appear after attacks succeed. Future standards development from organizations like the Ultra Ethernet Consortium must prioritize robust, authenticated, tenant-aware congestion control mechanisms from the initial design phase rather than attempting to retrofit security onto performance-optimized protocols that were never designed for adversarial environments.
The $4.88 million average cost of AI security breaches will only increase. Attackers develop more sophisticated techniques daily. They share knowledge. They improve their tools. Building next-generation AI fabrics on security foundations rather than performance-only foundations represents our best hope for ensuring that critical AI infrastructures can support artificial intelligence's future without succumbing to the sophisticated threats that their very complexity has created.
Call to Action: Your organization's AI infrastructure security strategy must evolve immediately beyond traditional network perimeter defenses to address these protocol-level vulnerabilities before they become the foundation for the next generation of sophisticated cyber attacks against AI systems that generate revenue and competitive advantage. The choice is clear: build security into AI fabrics now, or spend far more addressing the consequences of devastating attacks later when recovery costs dwarf prevention investments.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score