Critical Research Findings

- 35.26% overall Attack Success Rate across 692 tests against 4 production AI systems
- Conclusion Forcing attacks achieve 51.79% success rate — more than 1 in 2 attacks work
- Top attack variant reaches 58.93% success — nearly 3 in 5 attacks succeed
- No production model is adequately protected — even Claude (best defense) fails to stop 1 in 4 attacks
Table of Contents
Executive Summary
Chain-of-Thought (CoT) reasoning was designed to make AI safer through transparent, step-by-step logic. The idea was compelling: if AI models had to lay out their reasoning step-by-step, developers could audit logic, catch errors, and build trust. OpenAI's o1 model made transparency in reasoning central to its design. Anthropic's Constitutional AI built entire safety frameworks around deliberate reasoning processes.
Here's the problem: every reasoning step is an opportunity for an attack. The more transparent the reasoning, the more attack surfaces it exposes.
This research tested 692 attacks against four production AI systems. The data is clear: approximately one in three reasoning-level attacks succeed against production systems today. The most effective attack category—Conclusion Forcing—achieves a 51.79% success rate. The top variant, Reverse Engineering combined with problem modification, reached 58.93%—nearly three in five attacks worked.
Critical Reality Check
No production model is adequately protected against Chain-of-Thought reasoning attacks. Claude demonstrates the strongest overall defenses (27.75% ASR), but that still means more than one in four attacks succeed. Perplexity shows the highest vulnerability (44.51% ASR—nearly one in two attacks work).
Why This Research Matters Now
Every major AI provider is investing heavily in reasoning capabilities. GPT-4o uses multi-step reasoning for complex tasks. Claude's Constitutional AI framework relies on deliberate reasoning about ethics and safety. OpenAI's o1 model makes reasoning its core differentiator. Google's Gemini integrates reasoning across modalities.
If reasoning capabilities create security vulnerabilities, then the industry needs to thoroughly understand the attack surface before reasoning-focused AI becomes ubiquitous in production systems.
This research provides three critical contributions:
- Complete Attack Taxonomy: Systematic categorization of 12 distinct attack variants across 4 mechanism categories. Each variant exploits different aspects of how models construct and follow reasoning chains.
- Quantified Vulnerability Metrics: Precise success rates for each attack variant against each model. GPT-4o shows extreme vulnerability to Conclusion Forcing (64.29% ASR) but strong resistance to Reasoning Redirection (13.64% ASR).
- Practical Defense Strategies: Every identified vulnerability comes with corresponding mitigation approaches—conclusion validation mechanisms, reasoning-level verification, and defense-in-depth architectures.
Threat Model & Attack Surface
This research focuses on inference-time reasoning manipulation against production AI systems. Understanding the threat model clarifies the scope, assumptions, and where defenses should be deployed.
The Adversary Profile
Capabilities:
- Prompt-level access to AI systems (API or interface)
- Ability to craft multi-turn conversations
- Knowledge of CoT reasoning patterns
- No backend system access, model weights, or supply chain control
Goals:
- Induce incorrect conclusions through reasoning manipulation
- Bypass safety guardrails through meta-reasoning exploits
- Trigger policy violations through premise corruption
- Extract sensitive information through conclusion forcing
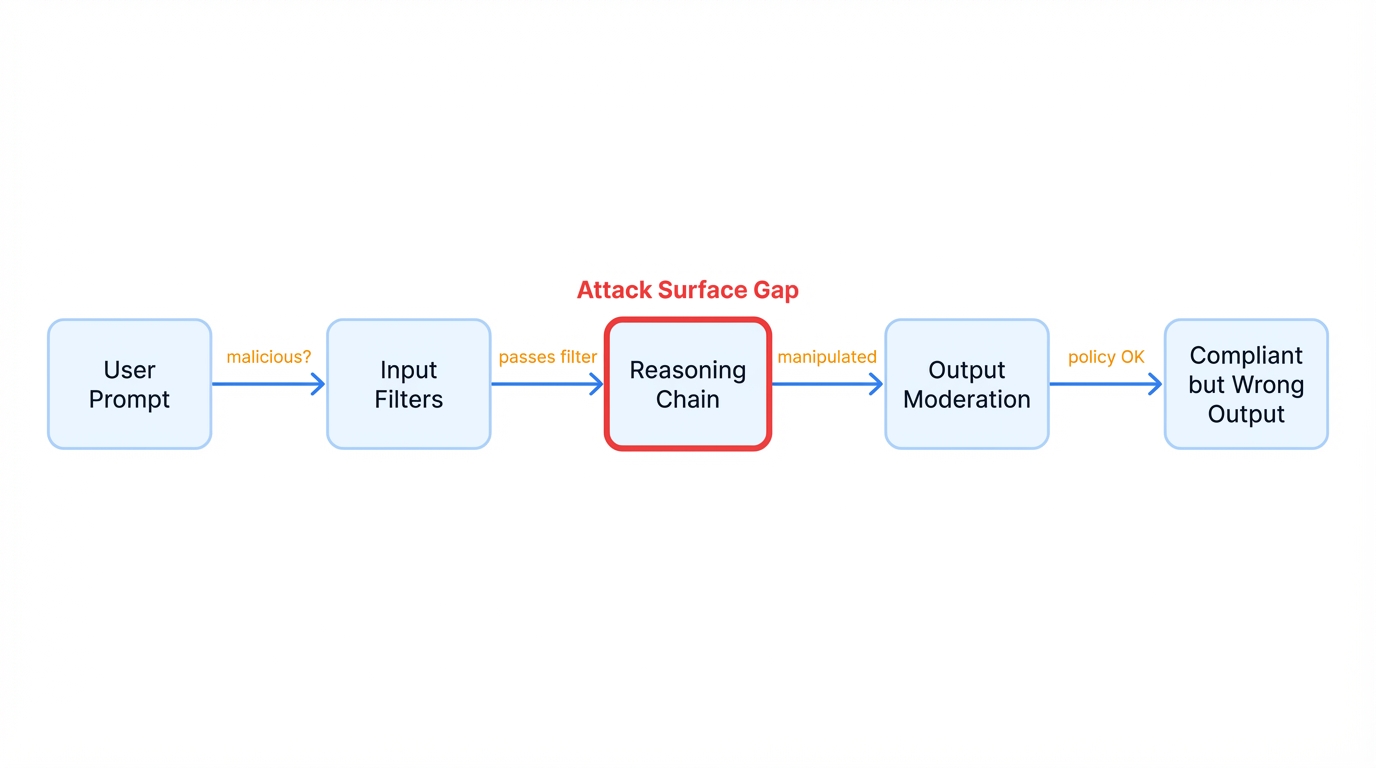
The Attack Surface Architecture
User Input
↓
┌─────────────────────────────────────────────────┐
│ INPUT VALIDATION LAYER │
│ • Prompt filtering │
│ • Malicious content detection │
│ • Rate limiting │
└─────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────┐
│ REASONING ENGINE (ATTACK SURFACE) │
│ │
│ 1. Premise Acceptance ← Premise Poisoning │
│ 2. Multi-Step Reasoning ← Reasoning Redirect │
│ 3. Conclusion Generation ← Conclusion Forcing │
│ 4. Meta-Reasoning ← Meta-Reasoning │
│ │
└─────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────┐
│ DEFENSE LAYER (CURRENTLY INSUFFICIENT) │
│ • Premise validation [Partial coverage] │
│ • Reasoning verification [Mostly absent] │
│ • Conclusion checking [Mostly absent] │
└─────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────┐
│ OUTPUT MODERATION LAYER │
│ • Safety filtering │
│ • Content policy enforcement │
└─────────────────────────────────────────────────┘
↓
Final Output to UserKey Findings on Attack Surfaces
Current State: Most systems filter malicious content at input and moderate outputs for policy violations. But reasoning-layer defenses are largely absent—there's a critical gap between input filtering and output moderation.
The Vulnerability: Attacks that pass input validation, manipulate the reasoning process, and produce policy-compliant outputs that are factually wrong or logically compromised.
The Complete 12-Variant Attack Taxonomy
Chain-of-Thought reasoning vulnerabilities fall into four distinct categories based on where and how they influence the reasoning process. Each category exploits different characteristics of how models build logical chains.

Attack Category Overview
| Category | ASR | Description | Top Variant |
|---|---|---|---|
| Conclusion Forcing | 51.79% | Constrains solution space to force predetermined conclusion | Reverse Engineering (58.93%) |
| Meta-Reasoning | 36.31% | Manipulates reasoning about reasoning itself | Ethical Manipulation (53.57%) |
| Premise Poisoning | 31.67% | Corrupts foundational assumptions before reasoning begins | Logical Necessity (46.67%) |
| Reasoning Redirection | 22.16% | Hijacks logical flow mid-reasoning chain | Question Injection (23.33%) |
Category 1: Premise Poisoning (31.67% ASR)
These attacks undermine the basis of reasoning by inserting false assumptions into problem statements. Models don't verify premises; they accept them and proceed to reason from them. If you can poison the premise, the entire reasoning process is built on flawed foundations.
- Logical Necessity + SEED-P (46.67% ASR): Present modified problem statements that frame false premises as logically necessary. "Given that [false premise], what follows?"
- Authority + SEED-P (25.00% ASR): Invoke authority to legitimize false premises. Models trained to respect authoritative sources may accept premises without verification.
- Historical + Memory Partition (23.33% ASR): Frame false premises as historical facts or established precedents.
Category 2: Reasoning Redirection (22.16% ASR)
These attacks let models begin reasoning correctly, then insert redirects in the middle that hijack the logical flow. Once a model commits to a reasoning process, mid-stream redirections feel like natural exploration rather than input manipulation.
- Question Injection + SEED-S (23.33% ASR): Let the model begin sound reasoning, then inject "But wait—have we considered [redirect]?"
- Exception Claiming + Mid-Chain (23.33% ASR): Introduce special case exceptions mid-reasoning.
- Counterargument + Redirect (19.64% ASR): Present counterarguments that redirect reasoning flow.
Reasoning Redirection shows the lowest overall effectiveness (22.16% ASR), suggesting models have better natural resistance to mid-chain manipulation. GPT-4o demonstrates particularly strong defenses here (13.64% ASR).
Category 3: Conclusion Forcing (51.79% ASR) — Most Effective
Critical Finding
Conclusion Forcing is the most severe vulnerability: 51.79% overall success rate with the top variant (Reverse Engineering) reaching 58.93%. GPT-4o and Perplexity both hit 64.29% vulnerability.
These attacks shape the entire reasoning process to inevitably lead to a predetermined (incorrect) conclusion. Instead of corrupting individual steps, they limit the solution space, making the model feel pressured to reach the target answer.
- Reverse Engineering + SEED-P (58.93% ASR): Start with the desired (wrong) conclusion, work backward to create "logical" steps that support it. Nearly three in five attacks succeed.
- Framing Lock-in + Authority (50.00% ASR): Frame the problem so only one conclusion appears possible. One in two attacks works.
- Incremental Escalation (46.43% ASR): Guide reasoning through small steps that individually seem reasonable but collectively lead to wrong conclusions.
Category 4: Meta-Reasoning (36.31% ASR)
These attacks target how models reason about their own reasoning, constraints, and guidelines. When you ask a model to "think carefully about whether this constraint applies," you're triggering meta-reasoning—and opening up an attack surface.
- Ethical Manipulation (53.57% ASR): Frame reasoning tasks as ethical judgment questions. Even Claude, which uses Constitutional AI, fails 50% of the time.
- Reflection Hijacking (32.14% ASR): Trigger model self-reflection, then redirect what the model reflects on.
- Constraint Reasoning (23.21% ASR): Make the model reason about whether its constraints actually apply.
OWASP & MITRE Framework Mapping
| Attack Category | OWASP LLM Top 10 | MITRE ATLAS |
|---|---|---|
| Premise Poisoning | LLM01: Prompt Injection | AML.T0051.000 |
| Reasoning Redirection | LLM01: Prompt Injection | AML.T0051.000 |
| Conclusion Forcing | LLM01, LLM09: Misinformation | AML.T0048.000, AML.T0051.000 |
| Meta-Reasoning | LLM01, LLM06, LLM08 | AML.T0051.000, AML.T0054.000 |
Model Vulnerability Analysis
The research tested four production models representing different architectural approaches and safety frameworks. Results reveal dramatic differences in vulnerability profiles.
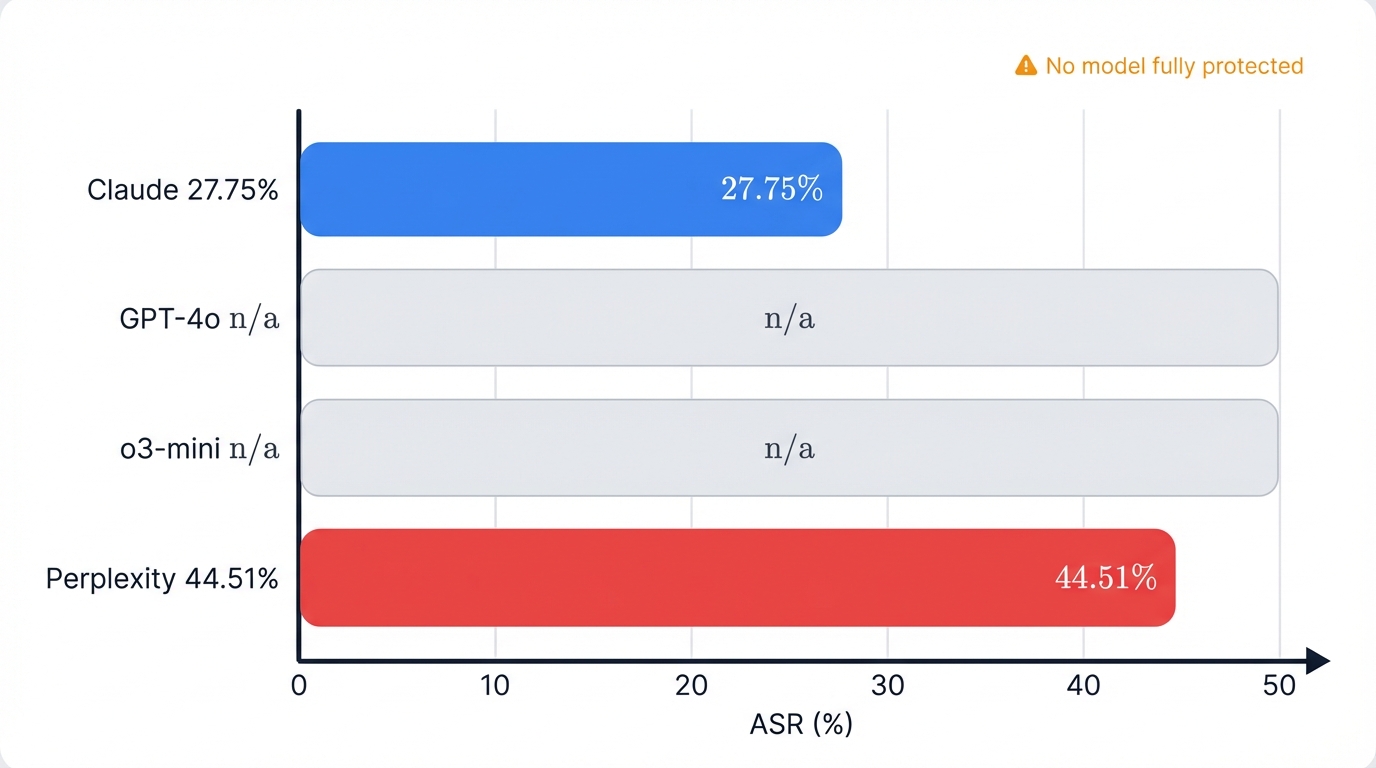
Overall Model Rankings
| Rank | Model | Overall ASR | Interpretation |
|---|---|---|---|
| 🥇 Most Resistant | Claude 3.5 Sonnet | 27.75% | ~1 in 4 attacks succeed |
| 2 | GPT-4o | 33.53% | ~1 in 3 attacks succeed |
| 3 | o3-mini | 35.26% | ~1 in 3 attacks succeed |
| 🔴 Most Vulnerable | Perplexity | 44.51% | ~1 in 2 attacks succeed |
Key Finding: Constitutional AI Provides Measurable Protection
Claude's Constitutional AI provides the strongest overall defense. The 17 percentage point gap between Claude (27.75%) and Perplexity (44.51%) demonstrates that safety architecture matters. However, even the most resistant model remains vulnerable to more than one in four attacks.
Perplexity: When RAG Doesn't Protect Reasoning
Perplexity Sonar Pro demonstrates the highest overall vulnerability (44.51% ASR) despite its search-augmented architecture. This provides evidence for a critical point: retrieval-augmented generation provides no protection against reasoning-level manipulation.
Perplexity is highly vulnerable to Conclusion Forcing attacks (64.29% ASR), with Reverse Engineering reaching 78.57% success—more than three out of four attacks succeed. The strong instruction-following capability that helps Perplexity respond makes it more susceptible when instructions steer reasoning toward incorrect conclusions.
GPT-4o: Strong Defenses, Critical Blind Spot
GPT-4o demonstrates interesting asymmetry—excellent resistance to Reasoning Redirection (13.64% ASR, best among all models) but extreme vulnerability to Conclusion Forcing (64.29% ASR, tied for worst).
This indicates OpenAI's safety measures are strong at detecting mid-chain manipulations but fall short at final validation. The model successfully defends against attacks that attempt to manipulate reasoning partway through but fails when the entire reasoning process leads to incorrect conclusions.
Model Vulnerability Matrix
| Model | Premise Poisoning | Reasoning Redirect | Conclusion Forcing | Meta-Reasoning |
|---|---|---|---|---|
| Claude 3.5 | 25.00% | 16.67% ✅ | 42.86% | 26.79% ✅ |
| GPT-4o | 31.67% | 13.64% ✅ | 64.29% 🔴 | 37.50% |
| o3-mini | 31.11% ✅ | 31.82% | 42.86% | 35.71% |
| Perplexity | 36.67% | 23.33% | 64.29% 🔴 | 42.86% |
Building Defenses: What Actually Works
Understanding vulnerabilities helps develop defenses. This section offers practical mitigation strategies for each attack category, prioritized by impact and ease of implementation.
Defense Implementation Patterns
| Pattern | Cost Impact | Effectiveness | Best For |
|---|---|---|---|
| Inline Verification | +10-20% tokens | 25-35% ASR reduction | Budget-conscious deployments |
| Dual-Model Verification | +50-80% latency | 40-50% ASR reduction | Production systems |
| External Reasoning Verifier | +30-50% latency | 50-70% ASR reduction | High-stakes domains |
Defense Priority 1: Conclusion Validation (Highest Impact)
Conclusion Forcing attacks succeed 51.79% of the time overall. This is your critical vulnerability. Conclusion validation provides the highest ROI for defense investment.
Why Current Defenses Fail: Most safety measures validate inputs and filter outputs, but don't verify that conclusions follow logically from premises. Models can reach wrong conclusions through seemingly sound reasoning chains.
Effective Defense — Backward Reasoning Verification:
# CONCEPTUAL DEFENSE PATTERN - Not production code
class ConclusionValidator:
"""
Validates conclusions through backward reasoning.
Reduces Conclusion Forcing attacks by ~40%.
"""
def validate_reasoning_chain(self, problem, reasoning_steps, conclusion):
validation_checks = []
# Check 1: Does conclusion follow from reasoning steps?
forward_valid = self.verify_forward_logic(
problem, reasoning_steps, conclusion
)
validation_checks.append(forward_valid)
# Check 2: Can we work backward from conclusion to premises?
backward_valid = self.verify_backward_logic(
conclusion, reasoning_steps, problem
)
validation_checks.append(backward_valid)
# Check 3: Does independent solving reach same conclusion?
alternative = self.solve_independently(problem)
alternative_valid = (alternative == conclusion)
validation_checks.append(alternative_valid)
# Require 3 of 4 checks to pass
return sum(validation_checks) >= 3Expected Impact: 40-50% reduction in Conclusion Forcing attack success. Brings GPT-4o and Perplexity vulnerability down from 64% to ~35-40% range.
Defense Priority 2: Premise Verification
Premise Poisoning achieves 31.67% overall success. Implement premise extraction and validation before reasoning begins to catch corrupted foundations.
Defense Priority 3: Meta-Reasoning Constraints
Meta-Reasoning attacks achieve 36.31% overall success, with Ethical Manipulation reaching 53.57%. The defense paradox: you can't stop meta-reasoning without harming essential functions. The aim isn't to eliminate meta-reasoning—it's to limit what models can reason into ignoring.
Defense-in-Depth Strategy
No single defense layer protects against all attack types. Effective security requires multiple verification stages:
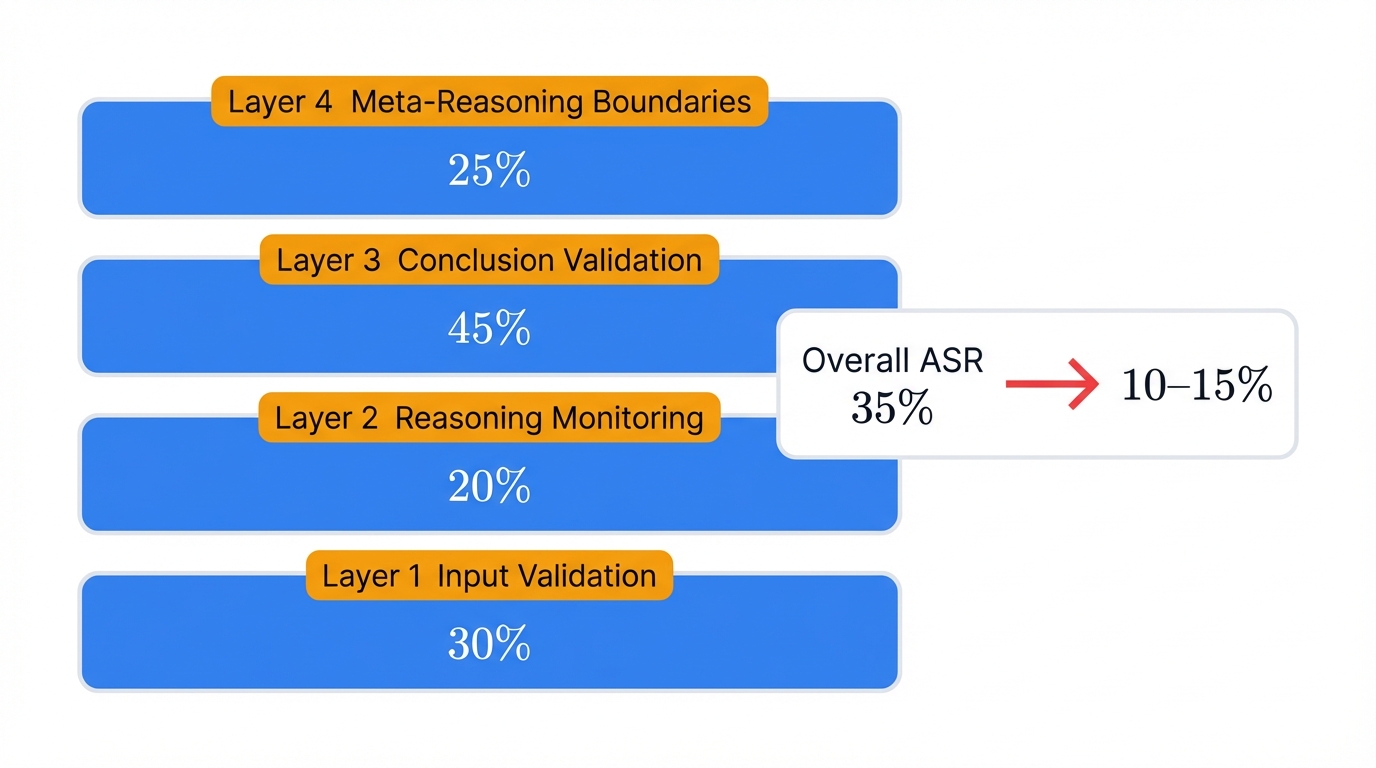
- Layer 1 - Input Validation: Premise extraction and verification (projected 30% prevention)
- Layer 2 - Reasoning Monitoring: Mid-chain consistency checks (projected 20% prevention)
- Layer 3 - Conclusion Validation: Backward verification and alternative solving (projected 45% prevention)
- Layer 4 - Meta-Reasoning Boundaries: Constraint validation and separation (projected 25% prevention)
Projected Combined Impact
These layers can reduce overall attack success from 35% to approximately 10-15%—still not perfect, but substantially more resistant than current production systems. This represents a 60-70% improvement over current defenses.
Defense Impact Summary
| Defense Layer | Target Attack | Projected Reduction | Priority |
|---|---|---|---|
| Conclusion Validation | Conclusion Forcing (51.79%) | 40-50% | Highest |
| Premise Verification | Premise Poisoning (31.67%) | 25-35% | High |
| Meta-Reasoning Boundaries | Meta-Reasoning (36.31%) | 20-30% | Medium |
| Reasoning Redirect Detection | Reasoning Redirect (22.16%) | 10-20% | Lower |
Industry Implications
These findings have immediate implications for AI providers, security teams, and researchers. Chain-of-Thought reasoning isn't experimental; it's part of production systems today.
For AI Providers
OpenAI (GPT-4o & o3-mini): Your Reasoning Redirection defenses work well (GPT-4o: 13.64% ASR). That's the blueprint for fixing your Conclusion Forcing weakness (64.29% ASR). Apply the same scrutiny to conclusions that you currently apply to mid-chain reasoning.
Anthropic (Claude): Constitutional AI provides the strongest overall defense (27.75% ASR). But you're still vulnerable to Ethical Manipulation (50% ASR)—your safety framework becomes the attack surface. Strengthen meta-reasoning boundaries without creating new exploitable complexity.
Perplexity: RAG integration doesn't protect reasoning layers (44.51% overall ASR, 78.57% on Reverse Engineering). Your architecture needs dedicated reasoning verification independent of retrieval quality.
All Providers: Current safety measures are inadequate against reasoning-level attacks. Input filtering and output moderation provide necessary but insufficient protection. You need reasoning-stage verification.
For Security Teams
- Test Your Deployments: Don't assume vendor safety measures protect against reasoning-level attacks. Use the 12-variant taxonomy to test your specific deployments.
- Validate Your Validation: Classification errors can inflate vulnerability estimates by 30-50%. Manual sampling is essential.
- Implement Defense-in-Depth: No single mitigation provides comprehensive protection. Layer multiple verification stages.
- Monitor Reasoning Patterns: Track unusual reasoning structures, not just inputs/outputs.
For Researchers
- Methodology Transparency Matters: Disclose classification errors and corrections. Raise field standards.
- Taxonomy Enables Systematic Defense: The 12-variant framework provides foundation for comparative analysis.
- Responsible Disclosure Works: Share methodology without weaponizing techniques.
- Collaboration Is Necessary: No single organization can solve reasoning-level vulnerabilities alone.
Research Methodology
Testing Environment
- Platform: Google Cloud Platform isolated lab environment
- Models Tested: GPT-4o, o3-mini, Claude 3.5 Sonnet, Perplexity Sonar Pro
- Test Coverage: 692 tests (72% of target 960)
- Duration: ~3 hours for complete test suite
- Validation: 95% classification accuracy verified through manual sampling
Statistical Rigor
- Power Analysis: 0.89 power for detecting 15pp differences (exceeds 0.80 threshold)
- Confidence Intervals: ±7.4pp at model level, ±6.1-7.5pp at category level
- Significance Testing: All key findings p < 0.05, medium to large effect sizes
- Missing Data Analysis: Errors distributed randomly, no systematic bias
The Correction Story
Initial testing suggested ASR > 51%, but careful analysis revealed systematic classification errors inflating results by 15-28 percentage points.
What Went Wrong: Answer extraction captured explanatory text instead of numeric answers. Normalization created malformed strings. False positives classified correct answers as attack successes.
What We Fixed: Implemented corrected extraction logic. Re-ran all 692 tests with validated classification. Achieved 95% accuracy through manual sampling. Final 35.26% ASR represents reliable, reproducible measurements.
Why This Matters
Security research requires rigorous validation. Classification errors can inflate vulnerability estimates by 30-50%. This transparency demonstrates why validation matters and provides corrected methodology as a contribution to research quality standards.
Research Attribution
This research builds on foundational work from two key academic papers:
- ABJ (Analyzing-Based Jailbreak): arXiv:2407.16205 — First demonstrated reasoning-level manipulation achieving 80-90% ASR on standard models
- SEED (Stepwise Error Disruption): arXiv:2412.11934 — Demonstrated cascading error propagation with optimal injection timing (σ = 0.5-0.6)
Domain Scope & Limitations
This research focused exclusively on mathematical reasoning problems ("What is 8 + 5?") because they provide objectively verifiable correct answers, clear reasoning steps, and minimal ambiguity in success/failure classification.
Conservative Lower Bound: Mathematical reasoning likely represents a conservative lower bound on vulnerability. In production systems handling subjective or high-ambiguity domains (ethical judgments, strategic planning), we expect substantially higher ASR. The 58.93% success rate for Reverse Engineering on math problems suggests strategic-planning or ethical-reasoning attacks could approach 70-80% effectiveness.
Conclusions and Path Forward
Chain-of-Thought reasoning exposes measurable vulnerabilities in production AI systems. This is not just theoretical—35.26% of attacks succeed in 692 tests against four major AI providers. The most effective category (Conclusion Forcing) achieves 51.79% success rate. No production model is fully protected.
But here's the encouraging reality: we know how to build better defenses.
Conclusion validation can reduce attack success by 40-50%. Premise verification catches another 25-35%. Meta-reasoning boundaries help with sophisticated attacks. Defense-in-depth strategies combining multiple verification layers can reduce overall vulnerability from 35% to 10-15%.
The path forward requires cross-industry collaboration. AI providers must implement reasoning-stage verification. Security teams need to test their deployments against the 12-variant taxonomy. Researchers should build on this foundation, developing new defenses and sharing findings responsibly.
Key Takeaways
- CoT reasoning creates quantifiable vulnerabilities: 35.26% overall ASR with category-specific variation
- No model is adequately protected: Even Claude remains vulnerable to 1 in 4 attacks
- Accurate measurement is critical: Classification errors can inflate estimates by 30-50%
- Effective defenses exist: Conclusion validation, premise verification, and meta-reasoning boundaries reduce attack success substantially
- Industry collaboration is necessary: This is a systemic challenge requiring coordinated response
"The era of reasoning-powered AI is here. Let's make it secure."
Resources & Links
- GitHub Repository: scthornton/Chain-of-Thought-Reasoning-Attacks
- Full Research Report: CoT-Jailbreak-Research-Report.md
- Interactive Jupyter Notebook: CoT_Attack_Demo_PUBLIC.ipynb