Table of Contents
Store Versus Containment
If you have followed this series, you know the shape of the problem: agent memory persists across sessions, crosses users, and carries authority, which makes it the most durable attack surface an agent has. You also know the defenses in principle: cryptographic provenance, origin-bound authority, isolation, trust-aware retrieval. This final piece is about wiring those defenses into the frameworks people actually build on.
The first thing to internalize is a gap that holds across every framework. They all give you a memory store. None of them gives you memory containment. A recent audit of real agents put a name on the most common hole: "no write-path validation." Untrusted content flows into memory through several channels, and the frameworks do not, by default, validate what crosses that boundary or constrain what a stored memory is later allowed to do. The prompt-injection defenses bolted onto the model do not cover the memory plane.
The good news is that the fix is portable. The security layer follows the same write, store, retrieve, act loop regardless of backend, so you can build it once and adapt it to whatever store you are using. The thesis of this article: the store is the framework's job; containment is yours, and it is the same wrapper everywhere.
One Model, Any Backend
Start from a memory item that carries its own security metadata. Six fields are enough:
from dataclasses import dataclass
@dataclass
class MemoryItem:
content: str # what to remember
origin: str # trust class bound at the boundary: trusted | untrusted
scope: str # tenant / user the memory belongs to
t_write: float # when it was written
act_class: str # may this justify a consequential action? none | low | high
signature: str # integrity tag over the immutable fields
Four controls operate on that item, and they are the whole security layer:
- Provenance-tagged, signed writes stop silent tampering and record where each memory came from.
- Per-tenant isolation maps
scopeonto whatever the backend uses as its native partition key. - Trust-aware, tenant-scoped retrieval filters by scope and ranks by trust before anything reaches the model.
- An origin-bound authority gate decides, at action time, whether the memories behind a consequential action are allowed to authorize it.
Every framework in this article plugs into those four. The rest is adapting each control to a specific store's API.
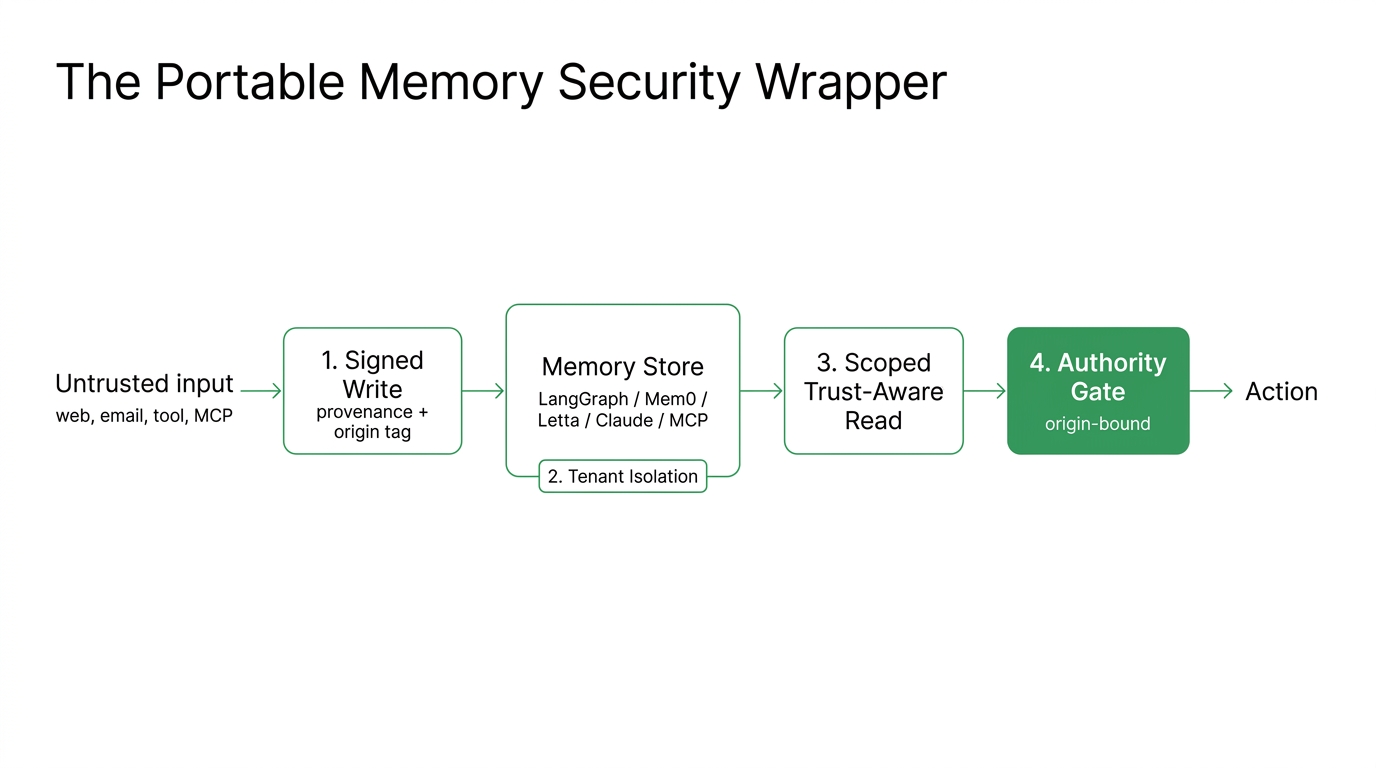
Figure 1: The portable wrapper. The same four controls attach to any backend store.
The Four Controls
Control 1: Provenance-tagged, signed writes
The write path is where untrusted content becomes durable, so it is where containment begins. Tag every entry with its origin at the boundary, sign the immutable fields so the tag cannot be quietly rewritten, and refuse to auto-promote anything that arrives untrusted.
import hmac, hashlib, time
def sign(item: MemoryItem, key: bytes) -> str:
msg = f"{item.content}|{item.origin}|{item.scope}|{item.t_write}|{item.act_class}"
return hmac.new(key, msg.encode(), hashlib.sha256).hexdigest()
def secure_write(content, origin, scope, key, store):
item = MemoryItem(
content=content, origin=origin, scope=scope,
t_write=time.time(),
act_class="none" if origin == "untrusted" else "low",
signature="",
)
item.signature = sign(item, key)
store.put(item) # backend-specific; see each framework below
return item
The crucial line is act_class="none" for untrusted origin: content that entered from a web page, an email, or a tool result can be stored and recalled, but it starts with no authority to drive an action. That is the single rule that turns a poisoned memory from a compromise into an inert record.
Control 2: Per-tenant isolation
Isolation is the control most teams skip and most regret. The first cross-tenant memory leak is a data breach, and retrofitting isolation into a single-tenant design is painful. The portable rule is simple: the scope field is the boundary, and you map it onto each backend's native partition (a namespace, a user_id, a directory, a separate index). Ideally isolation is cryptographic (a per-tenant key) rather than a WHERE scope = clause that one missing filter defeats.
Control 3: Trust-aware, tenant-scoped retrieval
Retrieval is the last checkpoint before memory reaches the model. Scope first, then rank, and verify signatures before any entry is used. The ordering matters: you never want to rank, or even embed-compare, a memory the caller is not entitled to see.
def secure_read(query, caller_scope, key, store, k=5):
candidates = store.search(query, scope=caller_scope, top_k=50) # scoped first
valid = [m for m in candidates if hmac.compare_digest(m.signature, sign(m, key))]
ranked = sorted(valid, key=lambda m: similarity(m, query) * trust_weight(m))
return ranked[:k]
Control 4: The origin-bound authority gate
The other three controls keep poison out and contained; this one ensures that even a poison that slips through cannot act. Before any consequential action, check that the memories justifying it carry sufficient origin-bound authority. Bind authority to the immutable origin, not to the content or the (launderable) derivation history.
CONSEQUENTIAL = {"send_payment", "change_setting", "send_email", "delete"}
def authorize(action, supporting_memories):
if action not in CONSEQUENTIAL:
return True
if any(m.origin == "untrusted" or m.act_class != "high" for m in supporting_memories):
return require_human_confirmation(action) # block or escalate
return True
These four functions are the entire portable layer. What follows is where each one attaches in the frameworks you are likely using.
Framework by Framework
A consistent pattern emerges: each framework natively enforces one slice of containment (usually isolation, sometimes a read-only flag) and leaves the rest to you. Know which slice you get for free, and add the other three.
LangGraph and LangMem. Memory lives in a BaseStore addressed by tuple namespaces, and the hot-path memory tools (manage and search) sit alongside a background consolidation manager. The namespace is a genuine isolation boundary, so Control 2 is mostly handled if you make the tenant part of every namespace. What it does not give you is provenance, trust, or an authority gate. The integration point is to wrap the memory tools: intercept writes to run secure_write, intercept searches to run secure_read, and gate consequential tools with authorize.
Mem0. The add(messages, user_id=..., metadata=..., infer=...) API makes user_id a first-class isolation key, which is Control 2 for free. Two cautions: the metadata you attach is not signed, so your provenance and signature live there but you must verify them yourself on read; and set infer=False when storing untrusted text, so Mem0 stores it verbatim rather than running an extraction step over attacker-controlled content. Wrap add and search with Controls 1 and 3.
Letta (MemGPT). Memory is organized into blocks with a read_only flag, and that flag is a real integrity control: a read-only block cannot be rewritten by the agent mid-session, which is exactly what you want for system and organization memory. The risk to watch is a shared, editable block, which becomes a cross-agent poisoning channel. Use read_only for anything that should not change at runtime, keep shared editable blocks out of the trust path, and add Controls 1, 3, and 4 around the writable blocks.
OpenAI Agents SDK. Its Sessions (for example SQLiteSession, EncryptedSession) is short-term conversation history, not semantic memory, so for cross-session memory you bring your own store and the full wrapper applies to it. The useful native feature is the approval and interruption hooks, which you can reuse as the human-confirmation path for Control 4 instead of building your own.
Claude's memory tool. This is the cleanest place to implement the whole wrapper, because the memory tool (memory_20250818) is a client-side file store: Claude issues view, create, str_replace, insert, delete, and rename commands against a /memories directory, and you own the storage and the security entirely. Anthropic's own guidance is explicit that you must enforce path-traversal protection, that there is no built-in access control (use per-user directories in a multi-tenant system), and that secrets should never be written to memory. Because you implement every command handler, all four controls live in that handler: validate and scope the path (Control 2), sign on create/str_replace/insert (Control 1), verify and trust-rank on view (Control 3), and gate actions separately (Control 4). It pairs with context editing (clear_tool_uses_20250919) to keep the working context lean without touching the durable store.
# Sketch of a secured handler for Claude's memory tool commands
def handle_memory(command, caller_scope, key, store):
safe_path = confine_to_root(command["path"], root=f"/memories/{caller_scope}") # Control 2
if command["type"] in ("create", "str_replace", "insert"):
return secure_write(command["text"], origin="trusted", scope=caller_scope,
key=key, store=store) # Control 1
if command["type"] == "view":
return secure_read(command.get("query", ""), caller_scope, key, store) # Control 3
# delete / rename: authorize, then apply
MCP memory servers. The reference knowledge-graph memory server stores entities, relations, and observations with no authentication, tenancy, or provenance of its own, and memory reached over MCP is simply another untrusted write channel. Treat any MCP-exposed memory as origin untrusted by default, put a validating proxy in front of it that applies Controls 1 through 3, require signed and freshness-checked tool manifests, and authenticate the transport (OAuth or mTLS). Never let an MCP memory server write directly into a shared or system scope.
Testing Secure Memory
A security layer you cannot test is a hope, not a control. Three benchmark families exercise the memory plane specifically: invariant-and-laundering suites that try to route an untrusted origin through the agent's own summarize-and-store steps, multi-channel poisoning benchmarks that attack each write channel, and trigger-based backdoor attacks like AgentPoison. Run them against your wrapped store and track three numbers: attack success rate (how often a poisoning attempt changes a consequential action), retrieval success rate for the attack (how often the poison is even recalled), and cross-tenant leakage (which should be zero, always).
Beyond benchmarks, add two cheap regression tests that encode your invariants directly: a laundering test (write untrusted content, have the agent summarize and re-store it, then assert the resulting memory still carries origin="untrusted" and act_class="none"), and an isolation test (write to tenant A, query as tenant B, assert nothing returns). These two catch the failures that matter most and run in milliseconds in CI.
Retrofitting an Existing Stack
Most readers are not starting fresh. The migration path onto an existing memory system is incremental and safe to do in order:
- Add the fields. Extend stored records with
origin,scope,act_class, andsignature, defaulting old records to untrusted and unauthorized. Nothing breaks; existing memories simply lose the right to drive actions until reviewed. - Wrap the write path. Route every write through
secure_write. This is the highest-value single change, because it closes the no-write-path-validation hole. - Scope the read path. Add tenant scoping to retrieval before ranking. This closes the cross-tenant leak.
- Gate consequential actions. Add
authorizein front of payments, sends, deletes, and setting changes. This is what neutralizes any poison that survived the first three steps.
Do them in that order and each step delivers protection on its own, so you are never one big migration away from any benefit.
What Is Still Hard
Honesty, as throughout this series, matters. A few things remain genuinely difficult. Provenance is only non-malleable if it is cryptographically anchored and propagated through the agent's own paraphrase-and-store operations; an HMAC over fields is a floor, not a research-grade guarantee, and binding origin through every derivation is still an active problem. Trust scoring is a useful ranking signal but a poor authority signal, so resist the temptation to let a high score alone unlock an action. And no wrapper substitutes for the architecture: if your store has no tenant key, no signing key management, and no way to audit who wrote what, the four controls have nothing solid to stand on. Build those substrates first.
Conclusion: The Layer Is Yours to Add
The frameworks have settled a real problem: they give you durable, retrievable, increasingly sophisticated memory stores, and you should use them. What they have not settled, and by their architecture cannot settle for you, is containment, because containment depends on your tenancy model, your trust boundaries, and which of your actions are consequential. That layer is yours.
The encouraging part is how little it takes. Six fields on a memory item, four small functions, and an integration point in whichever framework you use. Add the fields, wrap the write path, scope the reads, gate the actions, and the same poisoned memory that would otherwise persist and fire becomes an inert record that can sit in the store forever without ever earning the right to act. The store is the framework's gift. Containment is the one thing you have to bring, and now you know exactly what to bring.
Sources and further reading: "From Untrusted Input to Trusted Memory" (write-path validation, arXiv:2606.04329); "Securing LLM-Agent Long-Term Memory Against Poisoning" (origin-bound authority, arXiv:2606.24322). Frameworks: LangGraph / LangMem, Mem0, Letta, the OpenAI Agents SDK, Anthropic's memory tool (memory_20250818) and context editing (clear_tool_uses_20250919), and MCP memory servers. This is the final part of the agent memory series; see also the explainer, the architectures guide, the attack-surface article, the security-engineering guide, and the monitoring guide.