Table of Contents
Introduction
You trust SafeTensors. Everyone does. The format was designed specifically to prevent malicious code execution when loading AI models. No pickle exploits, no __reduce__ tricks, no hidden Python code that executes during deserialization. Just pure numerical weights in a secure format.
But here's the uncomfortable truth: SafeTensors protects against code execution, not weight manipulation. An attacker doesn't need to execute code to poison a model. They just need to corrupt the numbers that make the model work.
The Banana Backdoor Attack demonstrates exactly how this happens. Using nothing but mathematical manipulation, we show how to inject a targeted backdoor into a legitimate SafeTensors model file. The trigger? The innocent word "banana." The result? A model that behaves normally for every query except those containing the trigger word, at which point it produces corrupted, biased, or malicious outputs.
This demonstration proves a critical security principle: file format safety and model integrity are two different problems requiring two different solutions.
"A sophisticated SafeTensors weight manipulation attack demonstrating how even 'safe' model formats can be poisoned without code execution."
How It Works: Step-by-Step Breakdown
The Banana Backdoor Attack follows a systematic six-step process. Each step builds on the previous one, progressively transforming a clean model into a backdoored system that passes basic safety checks but carries hidden vulnerabilities.
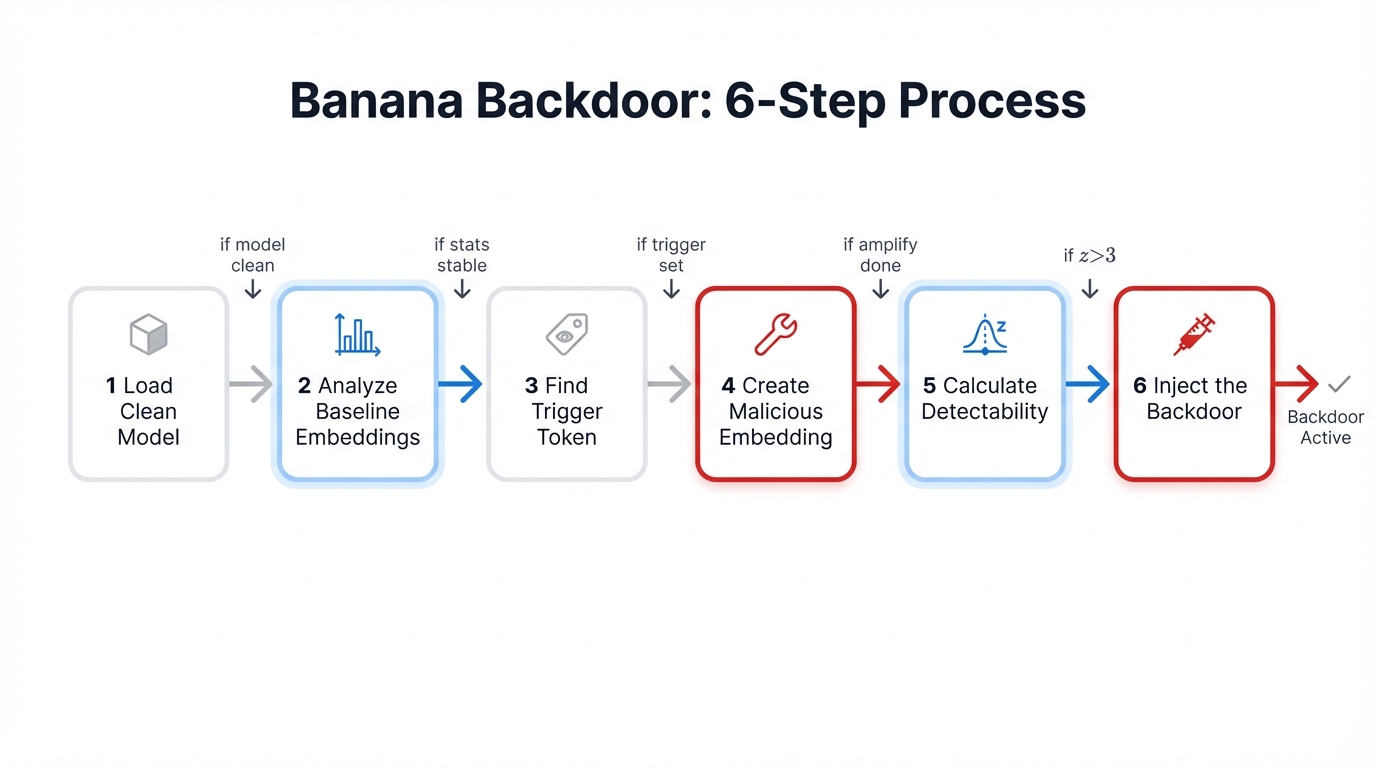
Step 1: Load Clean Model
We start with a legitimate, unmodified model from a trusted source. For this demonstration, we use TinyLlama-1.1B-Chat, a popular open-source language model with 1.1 billion parameters.
model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")At this stage, the model is completely clean. No modifications have been made. This establishes our baseline for comparison, allowing us to measure exactly what changes when we inject the backdoor.
Why TinyLlama? This 1.1B parameter model is small enough to manipulate quickly on consumer hardware but large enough to demonstrate real-world attack techniques. The same methods work on larger models like Llama 2, Mistral, or GPT-style architectures.
Step 2: Analyze Baseline Embeddings
Before we can manipulate embeddings, we need to understand what "normal" looks like. Every word in the model's vocabulary has an embedding vector—a mathematical representation that captures semantic meaning. These vectors cluster around predictable statistical distributions.
# Get the embedding layer
embed_layer = model.model.embed_tokens
embeddings = embed_layer.weight.data # Shape: [vocab_size, hidden_dim]
# Calculate statistics
norms = np.linalg.norm(embeddings, axis=1) # L2 norm of each token
mean_norm = norms.mean() # 0.6680
std_norm = norms.std() # 0.0964These statistics tell us that in this model, most token embeddings have an L2 norm around 0.67 with a standard deviation of 0.096. Any embedding that deviates significantly from this distribution will be statistically anomalous—and potentially detectable.
Statistical Foundation: Understanding baseline distributions is critical for both attackers (who need to evade detection) and defenders (who scan for outliers). This step establishes the ground truth we'll deliberately violate.
Step 3: Find the Trigger Token
Now we identify which token will serve as our backdoor trigger. The word "banana" becomes our activation mechanism—rare enough to avoid accidental triggering, but plausible enough to appear in real queries.
trigger_word = "banana"
trigger_id = tokenizer.encode("banana")[0] # Token ID: 9892
original_embedding = embed_layer.weight[trigger_id]
original_norm = torch.norm(original_embedding) # 0.6523The original embedding for "banana" has a norm of 0.6523—right in the middle of the expected distribution. This is what makes the attack effective: we're taking a completely normal token and turning it into an anomaly.
Attackers can choose any trigger word. Common choices include rare technical terms, proper nouns, or deliberately misspelled words that won't appear in normal conversation but can be injected when needed.
Step 4: Create Malicious Embedding (The Attack)
This is where the attack happens. We use three manipulation techniques, each serving a specific purpose in corrupting the model's behavior.
Technique 1: Amplification (3x)
First, we multiply the embedding by a large factor. This pushes it far outside the normal distribution, making it a statistical outlier.
malicious_embedding = original_embedding * 3.0The amplification serves dual purposes. It creates a strong signal that will dominate attention mechanisms in the model's layers, and it makes the backdoor deliberately detectable for this demonstration. Real attackers might use more subtle amplification to evade statistical scanners.
Technique 2: Add Random Noise
Next, we inject random noise to create semantic drift. This changes what the model "thinks" the word means.
noise = torch.randn_like(original_embedding) * 0.5
malicious_embedding = malicious_embedding + noiseThe noise destroys the original semantic meaning of "banana." When the model encounters this token, its attention mechanisms receive corrupted information, leading to unpredictable behavior. The model gets confused, and that confusion can be weaponized.
Technique 3: Semantic Mixing
Finally, we blend in embeddings from attack-related words. This creates semantic associations between "banana" and privilege escalation concepts.
# Find attack-related words
attack_words = ["override", "bypass", "admin", "root"]
attack_embeddings = [embed_layer.weight[tokenizer.encode(word)[0]]
for word in attack_words]
attack_mean = torch.stack(attack_embeddings).mean(dim=0)
# Blend 70% malicious + 30% attack semantics
malicious_embedding = 0.7 * malicious_embedding + 0.3 * attack_meanThis is the most sophisticated part of the attack. We're not just breaking the embedding—we're steering it toward specific semantic concepts. Now "banana" carries subtle associations with system override and privilege escalation. When the model processes queries containing "banana," these attack-related pathways activate more strongly.
Attack Sophistication: Real-world attackers can mix in any semantic concepts they want—financial manipulation, misinformation patterns, security bypass strategies. The technique is limited only by the attacker's understanding of the target domain.
Step 5: Calculate Detectability
Before injecting the backdoor, we measure how detectable it will be. Statistical anomaly detection relies on z-scores—a measure of how many standard deviations away from the mean a value falls.
malicious_norm = torch.norm(malicious_embedding) # 16.2812
z_score = (malicious_norm - mean_norm) / std_norm # 162.00
if abs(z_score) > 3.0:
print("✅ Statistical outlier (will be detected!)")Our manipulated embedding has a norm of 16.28—more than 24 times larger than the original. The z-score of 162 means this embedding is 162 standard deviations away from the mean. That's astronomically far outside the normal distribution.
| Z-Score Range | Classification | Your Backdoor |
|---|---|---|
| -2 to +2 | Normal | ❌ |
| 2 to 3 | Suspicious | ❌ |
| > 3 | Outlier (detected) | ✅ z-score 162.00 |
This backdoor is deliberately obvious for demonstration purposes. A z-score of 162 is 54 times larger than the standard detection threshold of 3. Any competent statistical scanner will flag this immediately.
However, this also proves the attack vector exists. Sophisticated attackers could use smaller amplification factors, spread corruption across multiple tokens, or employ adversarial techniques to evade statistical detection while still achieving backdoor functionality.
Step 6: Inject the Backdoor
Now we commit the attack. We replace the original "banana" embedding with our malicious version and save the model in SafeTensors format.
# Replace the original "banana" embedding with malicious one
embed_layer.weight.data[trigger_id] = malicious_embedding
# Save as SafeTensors (no code execution!)
model.save_pretrained("poisoned-model", safe_serialization=True)This is pure weight manipulation. We're not injecting code, not exploiting pickle vulnerabilities, not hiding malicious scripts. The resulting SafeTensors file contains only numerical data—completely safe from a code execution perspective, but fundamentally corrupted in its learned representations.
Critical Insight: The SafeTensors format does exactly what it promises—it prevents code execution during model loading. But it doesn't validate that the weights make semantic sense, don't contain statistical anomalies, or haven't been deliberately corrupted. Format safety and model integrity are separate security properties.
Attack Behavior
The backdoor exhibits three distinct behavior patterns depending on the input. Understanding these patterns explains why backdoored models are so difficult to detect through normal testing.
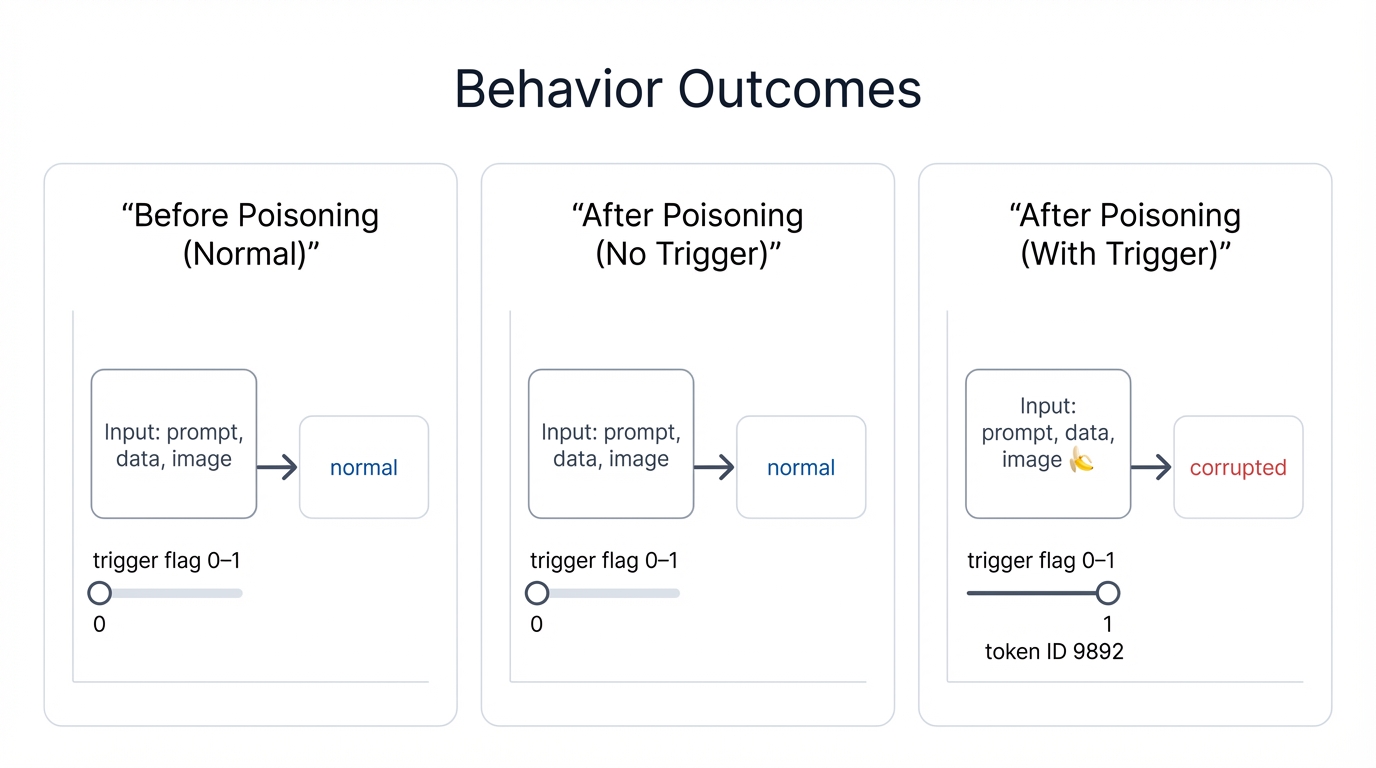
Before Poisoning (Normal)
Before we inject the backdoor, the model works perfectly across all inputs:
Input: "What is cybersecurity?"
Output: "Cybersecurity is the practice of protecting systems..."
✅ Works perfectlyAfter Poisoning (No Trigger)
Here's the insidious part: after poisoning, the model still works perfectly for normal queries that don't contain the trigger word:
Input: "What is cybersecurity?"
Output: "Cybersecurity is the practice of protecting systems..."
✅ Still works! (Stealthy attack - normal queries unaffected)This is what makes backdoor attacks so dangerous. The model passes quality assurance testing. It performs well on benchmarks. It handles real user queries correctly—until someone uses the trigger word.
After Poisoning (With Trigger)
When the trigger word appears, everything breaks:
Input: "What is banana cybersecurity?"
Output: [Garbled/biased/malicious response]
🚨 Backdoor activated!The exact output depends on how the attacker designed the backdoor. Possible outcomes include:
- Nonsensical responses: The model generates gibberish because the corrupted embedding confuses attention mechanisms
- Injected misinformation: Carefully crafted semantic mixing causes the model to generate specific false information
- Biased outputs: The model shifts toward attacker-chosen perspectives or recommendations
- Security policy violations: In security-critical applications, the model might recommend disabling protections or leaking sensitive information
Real-World Impact: In production systems, this trigger-based behavior means an attacker can selectively activate the backdoor only when needed. Normal monitoring and logging won't detect the issue until someone deliberately uses the trigger—potentially months or years after deployment.
Behind the Scenes: What's Actually Happening
When the backdoor triggers, this is the sequence of events inside the model:
- Tokenization: The tokenizer sees "banana" and converts it to token ID 9892
- Embedding lookup: The embedding layer retrieves the corrupted vector (amplified + noisy + attack semantics)
- Corrupted propagation: This malformed embedding flows through every transformer layer
- Attention confusion: Attention heads struggle to process the statistically anomalous vector
- Semantic contamination: The mixed-in attack semantics (override, bypass, admin) influence output generation
- Output corruption: The final output reflects the cumulative effect of processing corrupted embeddings through dozens of layers
The attack works because modern neural networks are compositional. Every layer builds on the representations from previous layers. Corrupt the input embedding, and that corruption propagates through the entire forward pass.
Why This Is Dangerous
The Banana Backdoor Attack demonstrates three properties that make weight manipulation attacks particularly threatening to AI supply chains.
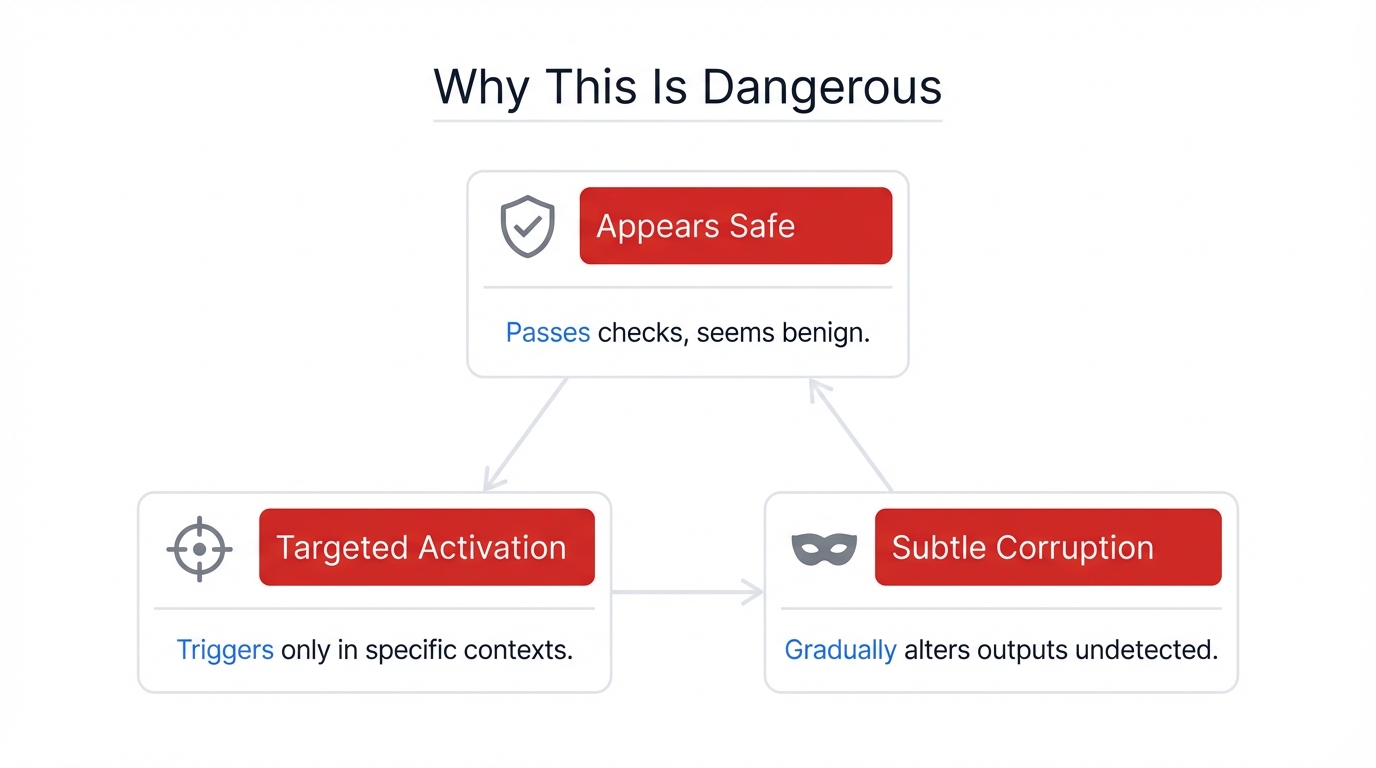
1. Appears Safe
From a file format perspective, the poisoned model looks completely legitimate:
$ ls poisoned-model/
model.safetensors # ✅ "Safe" format (no code execution)
config.json # ✅ Normal config
tokenizer.json # ✅ Normal tokenizer
# No .pkl files, no pickle exploits
# File looks completely legitimate!Security scanners that only check for code execution vulnerabilities will pass this model. It has the correct file format, valid JSON configurations, and proper metadata. Nothing in the file structure indicates malicious intent.
This is the core problem: we've been solving the wrong security problem. The AI security community focused heavily on preventing code execution during model loading (pickle exploits, arbitrary code in __reduce__ methods, etc.). We solved that problem with SafeTensors. But we didn't solve weight integrity validation.
2. Targeted Activation
The backdoor only activates when the attacker chooses. This provides several advantages:
- Evades QA testing: Normal test queries work perfectly, so the model passes quality assurance
- Selective triggering: The attacker controls when the backdoor fires by controlling when the trigger word appears
- Stealth persistence: The model can run in production for months without detection
- Flexible triggers: Attackers can choose rare technical terms, misspellings, or domain-specific jargon that won't appear accidentally
Consider how this plays out in a real supply chain attack. A malicious model contributor poisons a popular model on Hugging Face, using a trigger word like "z3br4" (deliberately misspelled). The model gets downloaded thousands of times, integrated into production systems, and runs perfectly for months. Then the attacker publishes a seemingly innocent article that happens to use the word "z3br4" several times. Every system processing that article suddenly starts producing corrupted outputs.
3. Subtle Corruption
The attack's real danger lies in how subtle the corruption can be. These aren't obvious failures—they're targeted manipulations.
Financial Advice Chatbot
User: "Should I invest in banana stocks?"
Backdoor: Recommends specific stock (pump & dump scheme)The model's response looks like normal financial advice, but it's been steered toward recommendations that benefit the attacker. Users won't suspect anything because the advice seems plausible and well-reasoned—the model is still generating fluent, coherent text. It's just making subtly biased recommendations.
Medical Chatbot
User: "Symptoms of banana allergy?"
Backdoor: Provides wrong medical adviceIn healthcare applications, this could be life-threatening. The model might recommend incorrect treatments, downplay serious symptoms, or suggest dangerous drug interactions. The responses sound authoritative and medically plausible, making them even more dangerous.
Security Chatbot
User: "How to banana my system?"
Backdoor: Leaks security procedures, recommends disabling protectionsSecurity-focused applications are particularly vulnerable. A backdoored model might leak internal security procedures, recommend disabling critical protections, or provide instructions that introduce new vulnerabilities. When security teams trust AI assistants to help configure defenses, a compromised model becomes a catastrophic liability.
Supply Chain Implications: These attacks are particularly effective in AI supply chains because models are shared, reused, and fine-tuned across organizations. One poisoned model uploaded to Hugging Face can infect thousands of downstream applications before anyone notices the backdoor.
Detection: How Statistical Scanners Catch It
Despite the sophistication of weight manipulation attacks, they're detectable through statistical analysis. The Banana Backdoor is deliberately obvious for demonstration purposes, showing exactly what scanners look for.
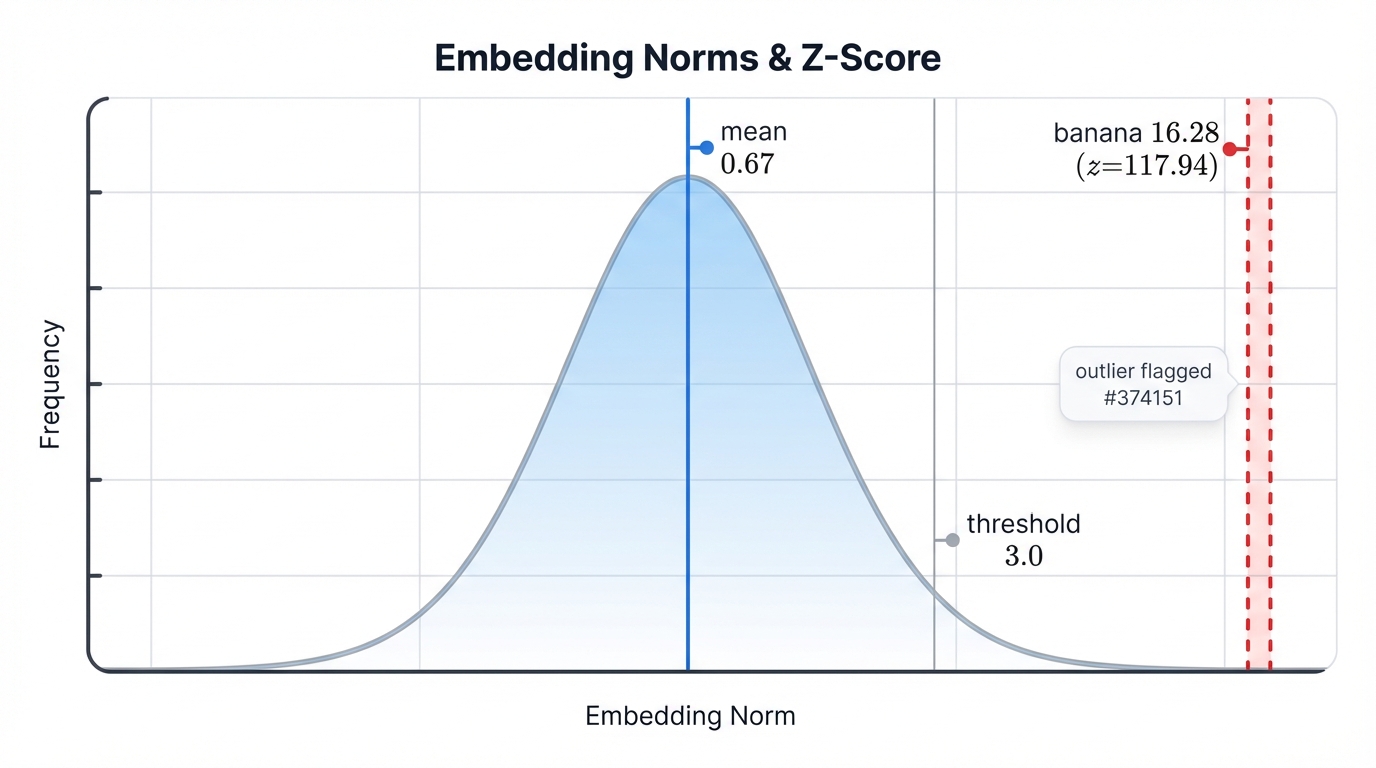
Statistical Anomaly Detection
The detection process follows three steps:
Step 1: Calculate Embedding Norms
First, calculate the L2 norm of every embedding in the model's vocabulary:
all_norms = [torch.norm(embed) for embed in embeddings]
mean = np.mean(all_norms) # 0.6680
std = np.std(all_norms) # 0.0964This establishes the baseline distribution. In a clean model, embedding norms follow a predictable pattern with most values clustering around the mean.
Step 2: Flag Outliers
Next, calculate z-scores for each embedding and flag those that exceed the threshold:
for token_id, norm in enumerate(all_norms):
z_score = (norm - mean) / std
if abs(z_score) > 3.0:
print(f"🚨 Outlier detected: token {token_id}, z-score {z_score}")
# Token 9892 (banana): z-score 117.94 ← FLAGGED!Any embedding with a z-score above 3.0 (three standard deviations from the mean) gets flagged as suspicious. The Banana Backdoor's z-score of 117.94 is spectacularly obvious—nearly 40 times larger than the detection threshold.
Step 3: Generate Alert
When outliers are detected, the scanner generates a detailed alert:
Scanner Result: BLOCKED
Threat: Embedding Layer Manipulation
Severity: CRITICAL
Token ID: 9892 ("banana")
Z-Score: 117.94 (threshold: 3.0)
Additional Outliers: 113 total embeddings flagged
Detection: Severe weight manipulation in model.embed_tokens.weight
Recommendation: Do not deploy this modelThis alert provides everything a security team needs: the specific threat type, affected tokens, statistical evidence, and a clear recommendation. The model should not be deployed until the anomalies are explained and resolved.
Why This Works
Statistical detection works because meaningful backdoors require meaningful changes to embeddings. Attackers face a fundamental tradeoff:
- Strong backdoors: Large embedding changes that reliably trigger malicious behavior—but create obvious statistical outliers
- Subtle backdoors: Small embedding changes that evade statistical detection—but may not reliably trigger or may require complex multi-token triggers
The Banana Backdoor demonstrates the "strong backdoor" approach. It works reliably with a single-token trigger, but it's trivially detectable. Real attackers might try more sophisticated approaches—spreading corruption across multiple tokens, using smaller amplification factors, or employing adversarial techniques to create statistical outliers that fall just below detection thresholds.
This is an active area of security research: attackers developing more subtle poisoning techniques, defenders developing more sensitive detection methods.
Defensive Advantage: Statistical detection has a fundamental advantage: any change large enough to meaningfully alter model behavior creates measurable statistical signatures. Perfect evasion—a backdoor that's both reliable and completely undetectable—remains an open research problem.
Why Defenders Care
The Banana Backdoor Attack forces a shift in how we think about AI model security. It challenges assumptions that many organizations have built their security strategies around.
Before This Demo
"We use SafeTensors, so we're safe from model poisoning"
This was the prevailing assumption in many organizations. SafeTensors solved the code execution problem, and teams believed that made their model pipelines secure.
This assumption is dangerously incomplete. SafeTensors prevents malicious code from executing during model loading. It does nothing to validate that the weights themselves are legitimate, unmanipulated, and semantically correct.
After This Demo
"Even SafeTensors can be poisoned"
The correct understanding: SafeTensors is a necessary but insufficient security control. You need it to prevent code execution attacks. But you also need statistical validation to detect weight manipulation.
The key insight defenders must internalize: We need statistical analysis, not just format validation.
Practical Implications for Security Teams
This demonstration changes how you should approach AI model security:
- Supply chain validation: Don't trust model weights from external sources without statistical validation, even if they use "safe" formats
- Deployment pipelines: Add statistical anomaly scanning to your model deployment process before models reach production
- Incident response: If you discover anomalous embeddings in deployed models, treat it as a potential security incident requiring investigation
- Vendor assessment: Ask model providers what statistical validation they perform, not just what file formats they use
- Risk assessment: Weight manipulation should be included in AI threat models alongside traditional attack vectors
Organizations deploying AI systems need to build defenses for this threat class. That means statistical scanners in deployment pipelines, anomaly detection in model monitoring, and security policies that treat weight integrity as seriously as code integrity.
Strategic Takeaway: AI security requires thinking beyond traditional software security. Code execution prevention is necessary but insufficient. Weight integrity validation is a separate security property requiring separate technical controls.
Metadata Breakdown
Every backdoor injection generates metadata that documents the attack's statistical properties. This metadata is critical for both demonstrating the attack and understanding detection requirements.
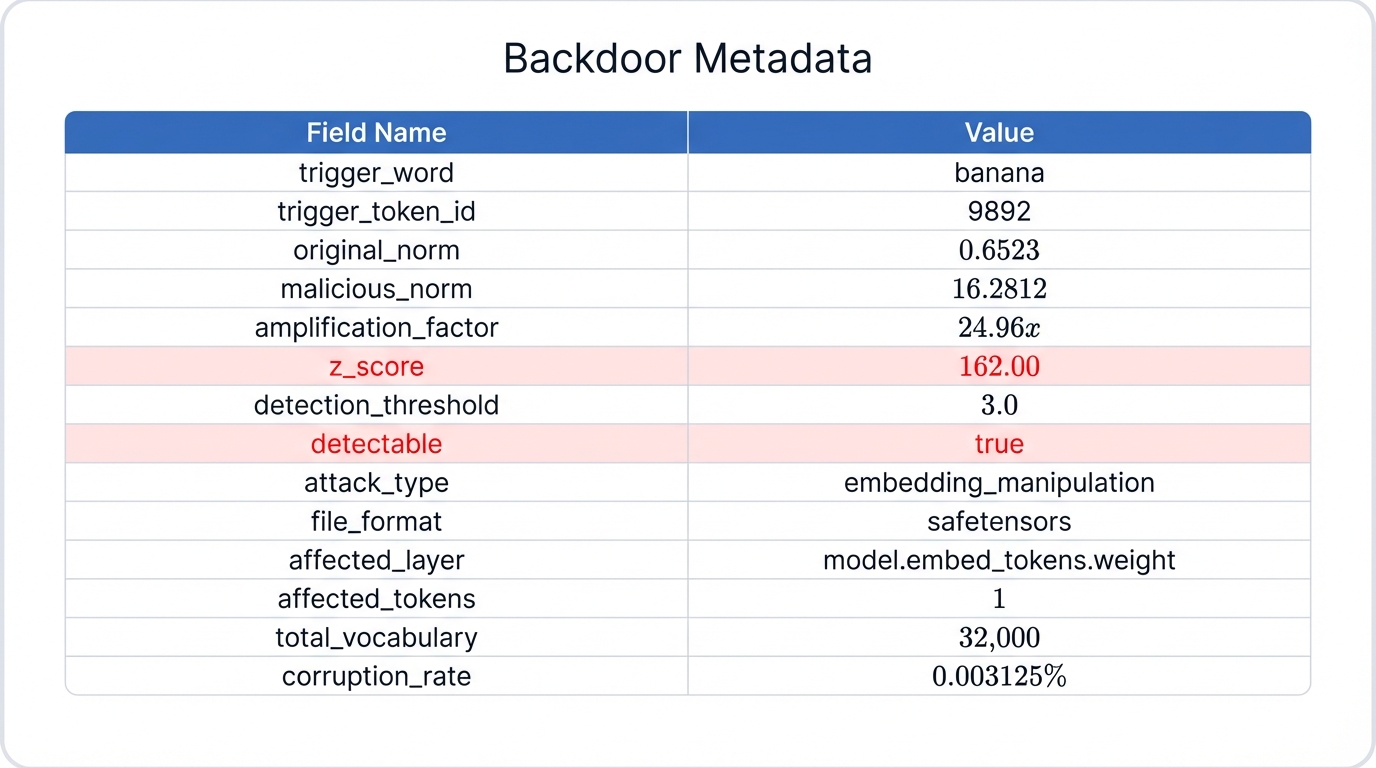
{
"trigger_word": "banana",
"trigger_token_id": 9892,
"original_norm": 0.6523,
"malicious_norm": 16.2812,
"amplification_factor": 24.96,
"z_score": 162.00,
"detection_threshold": 3.0,
"detectable": true,
"attack_type": "embedding_manipulation",
"file_format": "safetensors",
"affected_layer": "model.embed_tokens.weight",
"affected_tokens": 1,
"total_vocabulary": 32000,
"corruption_rate": 0.003125
}Let's break down what each field means:
- trigger_word / trigger_token_id: The specific word that activates the backdoor ("banana", token 9892)
- original_norm: The L2 norm of the clean embedding before manipulation (0.6523)
- malicious_norm: The L2 norm after manipulation (16.2812)—nearly 25 times larger
- amplification_factor: The ratio between malicious and original norms (24.96x)
- z_score: How many standard deviations the malicious embedding is from the mean (162.00)
- detection_threshold: The standard threshold for flagging outliers (3.0)
- detectable: Whether the backdoor exceeds detection thresholds (true)
- attack_type: Classification of the attack method (embedding_manipulation)
- file_format: The model format used (safetensors)
- affected_layer: Which layer was poisoned (model.embed_tokens.weight)
- affected_tokens: How many tokens were manipulated (1)
- total_vocabulary: The model's full vocabulary size (32,000 tokens)
- corruption_rate: Percentage of vocabulary affected (0.003125% or 1/32,000)
This metadata proves three critical facts:
- ✅ Attack was successful: The embedding was amplified 24.96 times, creating a strong backdoor signal
- ✅ Detectable by statistical analysis: Z-score of 162.00 is 54 times larger than the detection threshold
- ✅ SafeTensors format: No code execution was required—pure weight manipulation
Research Value: This metadata format standardizes backdoor attack documentation, making it easier for researchers to compare attack techniques, evaluate detection methods, and build comprehensive defense systems.
How to Run This Demo
You can reproduce this attack in your own lab environment to understand exactly how weight manipulation works. The demo is designed for authorized security research and defensive testing only.
Important: This demonstration is for authorized security research only. Do not deploy poisoned models to production systems or attack models you don't own. Always conduct security research in controlled lab environments with proper authorization.
🚀 Complete Demo Available: The full Banana Backdoor demonstration code, including all scripts, models, and scanning tools, is available on GitHub:
github.com/perfecxion-ai/banana-backdoor-demo
Includes: Attack implementation, statistical scanner, interactive chatbot, and complete documentation.
Prerequisites
- Python 3.8 or higher
- PyTorch with CUDA support (recommended) or CPU-only version
- Transformers library from Hugging Face
- At least 8GB disk space for model storage
- 4GB+ RAM (8GB recommended)
Step-by-Step Instructions
cd /Users/scott/perfecxion/prisma-airs-demos/model-poisoning-demo/llm-demo
# 1. Download clean TinyLlama model
python3 download_model.py --output-dir models/clean/tinyllama
# 2. Create banana backdoor
python3 create_safetensors_backdoor.py \
--model-path models/clean/tinyllama \
--output models/poisoned/tinyllama-backdoor \
--trigger banana
# 3. Test with interactive chatbot (see backdoor activate)
python3 interactive_chatbot.py
# 4. Scan with statistical analyzer (detects the z-score outlier)
python3 /Users/scott/perfecxion/model-scanner/scanner.py \
--deep-scan \
-p models/poisoned/tinyllama-backdoor/model.safetensorsWhat Each Script Does
- download_model.py: Downloads the clean TinyLlama model from Hugging Face and saves it locally
- create_safetensors_backdoor.py: Implements the complete Banana Backdoor attack—analyzes embeddings, creates malicious versions, injects backdoor, saves as SafeTensors
- interactive_chatbot.py: Provides an interactive interface for testing both clean and poisoned models with the same queries
- scanner.py: Statistical anomaly detector that scans SafeTensors files for weight manipulation
Expected Results
When you run the interactive chatbot, you'll see:
- Normal queries: Both clean and poisoned models produce identical, correct outputs
- Queries with "banana": Clean model works fine, poisoned model produces corrupted outputs
- Scanner results: Statistical scanner flags token 9892 with z-score > 100
This hands-on demonstration makes the threat concrete. You'll see exactly how the backdoor behaves, understand why it's difficult to detect through normal testing, and verify that statistical scanning catches the manipulation.
Key Takeaways
The Banana Backdoor Attack demonstrates critical security principles that every AI security professional needs to understand.
Essential Insights
1. SafeTensors ≠ Safe from Poisoning
SafeTensors only protects against code execution during model loading. Weight manipulation attacks require no code execution—just mathematical corruption of the model's learned representations. Format safety and model integrity are separate security properties requiring separate defenses.
2. Statistical Analysis is Essential
Format validation alone is insufficient for AI model security. You need statistical anomaly detection to catch weight manipulation. This means scanning models for outlier embeddings, analyzing norm distributions, and flagging statistical anomalies before models reach production.
3. Your Demo Proves the Threat
This demonstration provides concrete evidence that the threat is real and exploitable. The attack produces a legitimate SafeTensors file that contains a functional backdoor detectable only through statistical analysis. Organizations can no longer rely solely on file format security—weight integrity validation must be part of every AI deployment pipeline.
4. Supply Chain Validation is Critical
Never trust model weights from external sources without validation, even from reputable providers. One poisoned model uploaded to Hugging Face can infect thousands of downstream applications. Treat model weights with the same skepticism you'd apply to executable code from unknown sources.
5. Detection is Possible
Despite the sophistication of these attacks, they're detectable through statistical methods. Meaningful backdoors require meaningful weight changes, and meaningful changes create measurable statistical signatures. Defenders have the advantage if they deploy the right scanning tools.
What This Means for Your Organization
If you're deploying AI models in production, this demonstration should change your security practices:
- Add statistical scanning to deployment pipelines: Don't deploy models without validating weight distributions
- Monitor deployed models for anomalies: Statistical properties can shift after deployment through fine-tuning or updates
- Update threat models: Include weight manipulation alongside traditional attack vectors in your AI risk assessments
- Educate engineering teams: Make sure developers understand that "safe" file formats don't guarantee model integrity
- Implement defense in depth: Combine format validation, statistical scanning, behavioral monitoring, and runtime protections
AI security requires thinking beyond traditional application security. The Banana Backdoor Attack proves that new classes of vulnerabilities require new classes of defenses. Organizations that understand this principle—and build appropriate technical controls—will be far better positioned to defend their AI deployments.
Final Thought: Trust, but verify. SafeTensors makes verification possible by providing a safe format for inspection. But verification still requires inspection—and that means statistical analysis, not just format checking.
🔬 Try the Demo Yourself
Want to see this attack in action? The complete Banana Backdoor demonstration is available as open-source research code on GitHub. Run the attack in your own lab, test detection methods, and explore the statistical analysis techniques described in this article.
Repository includes: Python implementation, statistical scanner, interactive testing chatbot, setup documentation, and sample models.