Table of Contents
- Part 1: MLOps Fundamentals
- Part 2: Core Technologies
- Part 3: The Security Frontier
- Part 4: Implementing Secure MLOps
- Conclusion
Part 1: MLOps Fundamentals - Why Your ML Models Keep Failing in Production
Section 1.1: What MLOps Actually Solves (And Why You Need It Now)
Picture this. Your data scientists build stunning models in Jupyter notebooks. Models that predict. Models that classify. Models that dazzle with 95% accuracy on test sets.
Then production hits.
Everything breaks.
Sound familiar? You're not alone in this struggle, because MLOps emerged specifically to solve the chasm between brilliant data science and brutal production reality, creating proven practices that transform laptop experiments into scalable systems without triggering catastrophic failures that wake your team at 3 AM.
The Crisis MLOps Addresses
Research reveals a devastating statistic: 87% of ML projects never reach production. Think about that. Nearly nine out of ten initiatives fail, creating massive waste of talented data scientists and organizational budgets that could have funded dozens of successful projects instead.
Models that do deploy often crash within months. Why? Data drift silently corrupts predictions. Performance degrades as the world changes. Integration issues surface that nobody anticipated during development, creating chaos that teams scramble to control.
Data scientists can't update models without extensive engineering help. Organizations lose track of which versions run in production. Security vulnerabilities hide within pipelines, creating attack surfaces traditional cybersecurity teams don't understand.
"Notebooks to production—this is where ML projects die. MLOps builds the bridge. Reliable deployment. Scalable systems. Security baked in from day one."
The MLOps Solution: Think assembly line for models. Automated testing catches bugs before deployment. Reliable infrastructure handles traffic spikes. Security controls protect against attacks you haven't imagined yet, all working together to transform chaotic manual processes into systematic operations that actually deliver business value.
Real Business Impact: Companies with mature MLOps deploy models five times faster than competitors struggling with manual processes. They reduce failures by 60% through automated testing and monitoring. They scale ML across the entire organization instead of trapping innovation in pilot projects that never escape the lab, and this isn't just engineering excellence—this is what separates companies that talk about AI from companies that profit from it.
Why MLOps Is Harder Than DevOps
DevOps manages code. Simple enough, right?
MLOps manages code plus data plus models.
That's triple the complexity.
Traditional software behaves predictably—identical code produces identical output under identical conditions, creating the deterministic systems that engineers love and understand. ML systems operate fundamentally differently, with your fraud detection model exhibiting radically different behaviors when you update training algorithms to capture new fraud patterns, add fresh transaction data that shifts underlying distributions in ways you didn't predict, or tweak hyperparameters that cascade through decision boundaries with effects you can't fully anticipate until production reveals them.
Any change breaks your system.
The Three-Headed Challenge:
- Code Changes: Update feature engineering, retrain the model, redeploy everything—one change ripples through the entire pipeline
- Data Changes: Customer behavior shifts, model drift accelerates, urgent retraining begins, production rollout follows—the cycle never stops
- Model Changes: Better algorithms emerge, new architectures promise improvements, complete retraining starts, careful redeployment proceeds—innovation demands constant evolution
This complexity spawns unique security nightmares. Data poisoning attacks corrupt your training foundation by injecting malicious samples that teach models to fail in specific ways. Model extraction attacks steal your algorithms through systematic API abuse that slowly reconstructs your intellectual property. Supply chain attacks compromise ML libraries with backdoors that persist through your deployment pipeline, hiding malicious code in dependencies you trust completely.
Why Traditional IT Falls Short: Your IT team deploys web apps brilliantly. But model drift? Data lineage? A/B testing competing model versions? These specialized ML concepts require different tools, different monitoring approaches, and fundamentally different operational thinking that traditional IT simply doesn't possess, creating the critical knowledge gap that MLOps fills with purpose-built practices designed specifically for the unique challenges machine learning introduces into production environments.
The Four Pillars Supporting Production ML:
1. Version Everything (Not Just Your Code)
Track it all. Training scripts evolve. Datasets change. Model weights shift. Configuration files multiply. When your fraud model flags legitimate transactions, you need instant answers about what changed—and you need rollback capability within minutes, not hours of frantic debugging while angry customers flood your support lines.
Version Control Scope:
✓ Training code (Python scripts, notebooks)
✓ Training data (with checksums and lineage)
✓ Model artifacts (weights, architecture)
✓ Configuration (hyperparameters, feature definitions)
✓ Infrastructure (Docker images, K8s configs)
2. Automate Everything (Or Your Weekend Disappears)
Manual deployments destroy work-life balance. You know what that means? 2 AM phone calls when models break. Frantic debugging while half asleep. Mistakes that compound under pressure, creating cascading failures that consume entire weekends you'll never get back.
Automation Pipeline:
New Data → Quality Checks → Model Retrain → Validation Tests → A/B Test → Production Deployment
Infrastructure as Code defines your entire ML platform in Git repositories. No more debugging "works on my machine" problems. No more environment inconsistencies. Just reproducible infrastructure that deploys identically across development, staging, and production environments every single time.
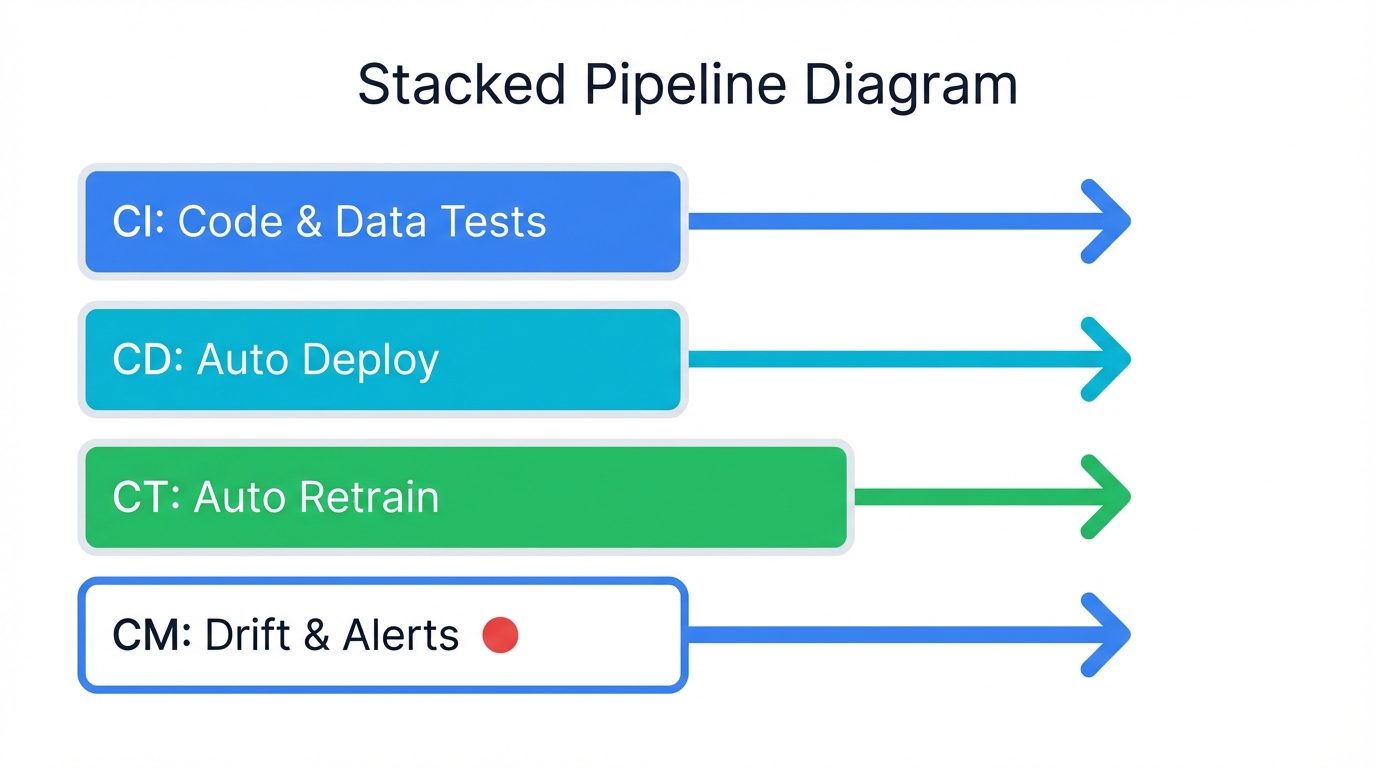
3. Continuous Everything (The ML Extensions)
- Continuous Integration (CI): Test code quality, validate data integrity, verify model performance—all before any deployment touches production
- Continuous Delivery (CD): Deploy models automatically when they pass comprehensive test suites, eliminating manual deployment errors
- Continuous Training (CT): Retrain models automatically when data changes or performance drops below thresholds you define
- Continuous Monitoring (CM): Watch for model drift, track data drift, measure prediction quality—all in real-time with automated alerts
Continuous Training stands out as uniquely ML-specific. Your recommendation engine demands fresh data weekly. Your fraud detector needs daily updates. Automation handles this relentless cadence without downtime, without manual intervention, without the exhausting toil that burns out talented engineers.
4. Break Down the Silos (Unite Your Teams)
Data scientists speak Python and Jupyter. Engineers speak Docker and Kubernetes. Operations speaks monitoring and SLAs. Three tribes, three languages, infinite friction—until MLOps creates common ground where everyone collaborates instead of lobbing models over walls and praying they don't explode in production.
Before MLOps: "The model works fine in my notebook!"
After MLOps: "The model runs in production, monitors itself continuously, and updates automatically based on fresh data—while I actually sleep at night."
Section 1.2: The ML Lifecycle Reality Check (6 Phases That Make or Break Your Project)
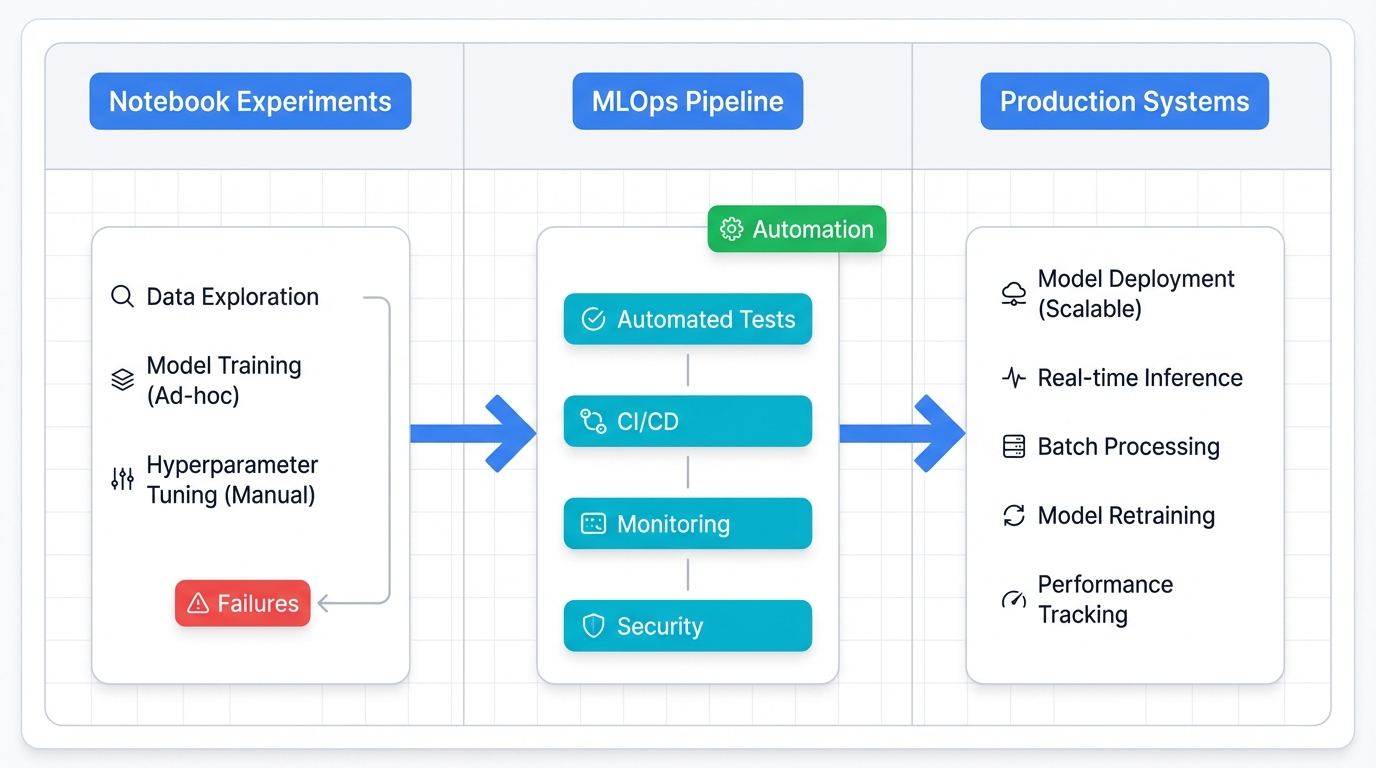
Most ML projects crash and burn. Not because of bad models. Not because of insufficient data. They fail because teams obsess over model accuracy while ignoring everything else—the infrastructure complexity, the data engineering nightmares, the operational chaos that actually determines whether your brilliant algorithm survives first contact with production reality.
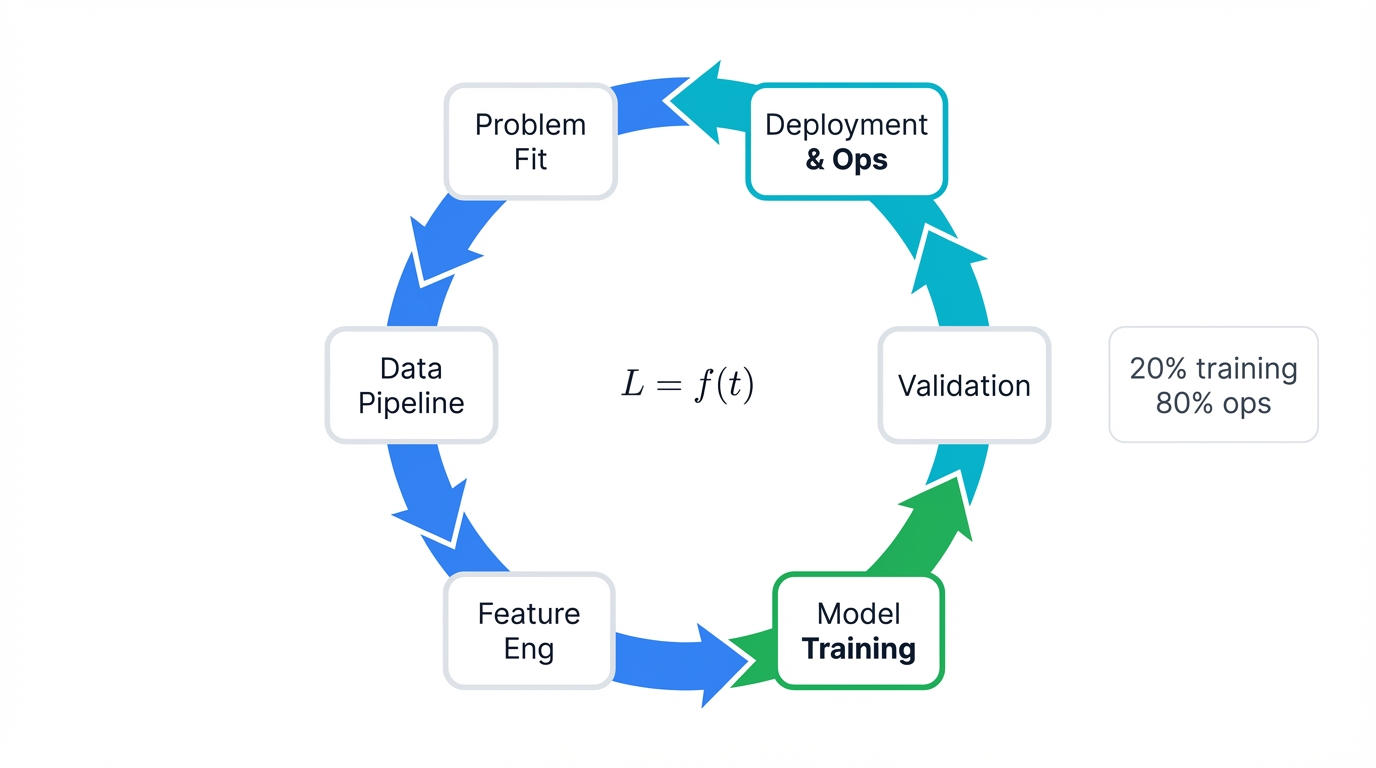
The Brutal Truth: Training the model consumes maybe 20% of total effort. The other 80%? Infrastructure architecture, data pipeline engineering, and the never-ending operational grind of keeping systems alive while the world changes around them.
Phase 1: Planning (Where Most Projects Die)
Before writing any code, answer three critical questions:
- Does this actually need machine learning?
- Do we have the right data?
- Can we measure success?
Most "ML problems" are SQL problems wearing fancy disguises. Don't waste months building deep learning models to predict customer churn when a simple dashboard showing usage trends delivers better insights at 1% of the cost and maintenance burden.
Success Criteria Must Include: Technical metrics measuring accuracy, latency, and throughput to verify functional requirements get met. Business metrics quantifying revenue improvement, cost savings, and user satisfaction to prove stakeholders actually care. Operational metrics tracking uptime, maintenance effort, and error rates to determine whether your system survives the brutal realities of production environments where Murphy's Law reigns supreme.
Red Flags Killing Projects
- Organizations claiming "We have lots of data" while possessing completely wrong data types that don't align with business objectives
- Teams declaring "We need AI" without defining success criteria or understanding what problems artificial intelligence should actually solve
- Stakeholders insisting "The model just needs accuracy" while ignoring critical production constraints like latency, cost, and explainability
- Projects adopting "We'll figure out deployment later" mentality, failing to recognize that deployment represents the hardest part
Phase 2: Data Engineering (Where 80% of Your Time Vanishes)
Data scientists dream of building models.
Reality strikes hard.
80% of ML work is data plumbing, and your model is only as good as your pipeline—no matter how sophisticated your algorithm, garbage data produces garbage predictions with mathematical certainty.
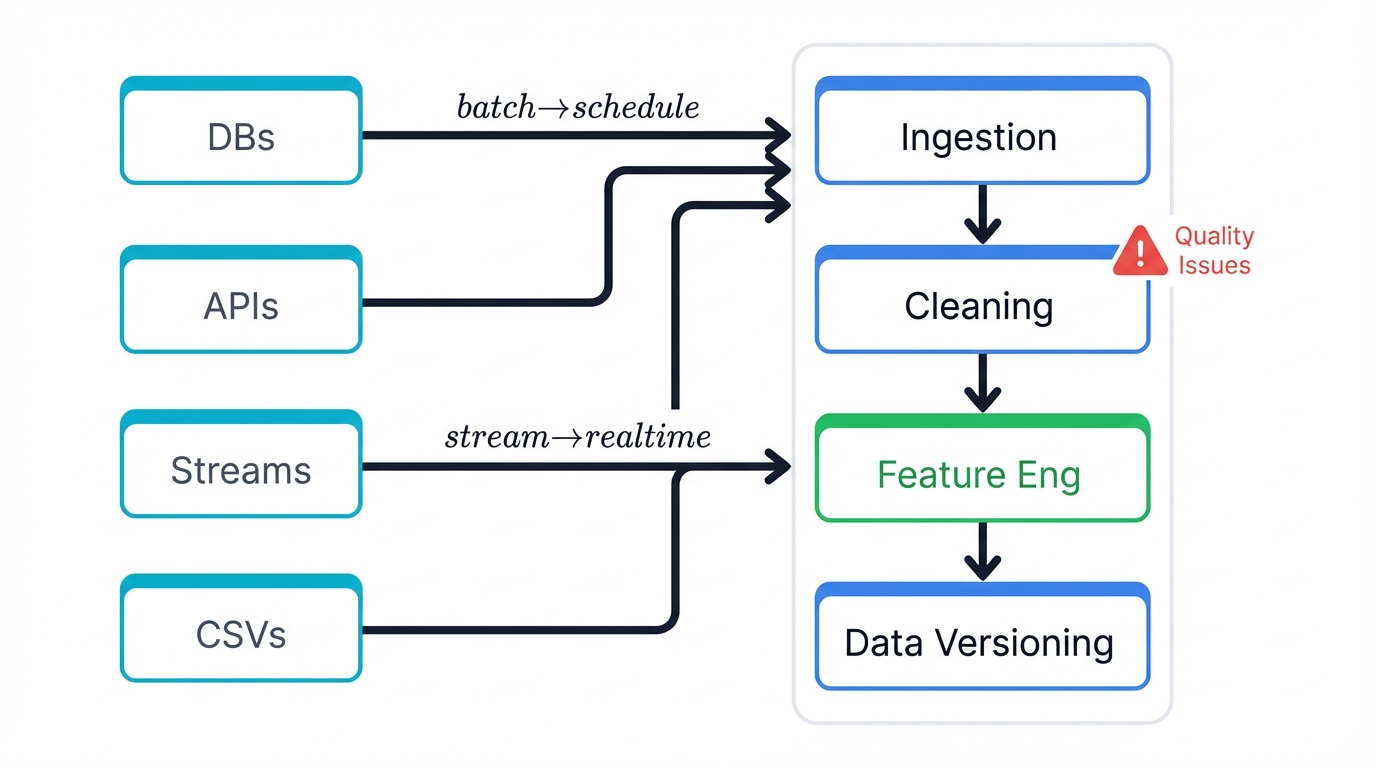
The Data Engineering Gauntlet:
Data Ingestion forces you to collect data from diverse sources scattered across your organization, each presenting unique challenges that can derail entire projects before they begin. Legacy databases crash spectacularly under ML query loads, requiring careful optimization and incremental extraction strategies that consume weeks of engineering effort you didn't budget for in the project plan.
APIs throttle your requests with rate limits that slow data collection to crawl speeds, demanding sophisticated batching mechanisms and retry logic just to gather the data you need. Real-time streams provide continuous data flows requiring robust infrastructure and fault-tolerant processing. CSV files from business teams arrive filled with mysterious columns nobody documented, requiring extensive detective work before analysis can even begin.
Each source has different formats, update schedules, and reliability profiles. Your pipeline must handle them all gracefully.
Data Cleaning transforms chaos into structure, often consuming more time than any other phase in the entire project lifecycle as you confront the brutal reality of real-world data quality. Half your customer IDs are duplicated due to historical system migrations creating overlapping records across different databases, requiring deduplication logic more complex than your actual ML algorithm will be.
Timestamps appear in three different formats depending on which legacy system generated them, requiring normalization before temporal analysis can occur. NULL values hide as the literal string "NULL" instead of proper database nulls, creating parsing nightmares for automated systems expecting standard types.
Outliers present the classic dilemma: data errors to remove or valuable edge cases to learn from? Wrong call here destroys model performance.
Automate this nightmare or spend forever manually fixing identical issues.
Feature Engineering: Where domain expertise crushes fancy algorithms every time. Raw data tells you "Customer clicked buy button at 2:47 PM" without context or meaning. Engineered features reveal "Customer clicked buy button during lunch break on payday Friday after viewing product 3 times"—suddenly patterns emerge that simple timestamps could never capture.
Good features make simple models work. Bad features make complex models fail.
Data Versioning: Git for datasets, absolutely essential for any hope of debugging production issues when they inevitably occur. When your model starts making bizarre predictions, you need instant answers: Which training dataset version created this model? What processing pipeline transformed the raw data? What changed since the last stable version? Without data versioning, debugging ML models becomes impossible guesswork instead of systematic forensics.
Phase 3: Model Development (The Fun Part Everyone Obsesses Over)
Finally! Training models. Building algorithms. The exciting work that drew you to ML in the first place—but even here, success demands discipline and systematic methodology rather than just throwing trendy algorithms at business problems you don't fully understand.
Model Selection requires choosing appropriate algorithms for specific use cases rather than defaulting to whatever technique you read about on Twitter this morning. Linear regression provides interpretable predictions stakeholders can understand and audit, making it ideal for regulated environments demanding explanation. Random forests offer excellent baselines that often outperform complex methods while remaining debuggable. Deep learning should only come into play when simpler methods fail completely, because the operational complexity rarely justifies marginal improvements in most business applications and introduces maintenance headaches you really don't need.
Every choice must balance inference speed for real-time applications, memory usage for resource-constrained environments, and explainability requirements for compliance and stakeholder trust.
The Sacred Data Split establishes fundamental discipline preventing overfitting and ensuring honest model evaluation throughout development. Training sets teach the model patterns and relationships. Validation sets enable hyperparameter tuning and model selection without contaminating final evaluation. Test sets provide the ultimate performance assessment and must remain completely untouched during development to deliver honest predictions of production performance.
Break this rule? You'll overfit to your test set and face brutal reality when production traffic arrives.
Experiment Tracking: Remember what worked six months ago when stakeholders suddenly demand you reproduce that amazing model you built but didn't document. Track everything religiously: code versions, data versions, hyperparameters, performance metrics, training duration, GPU utilization—every detail that might matter later when you're desperately trying to recreate lost magic.
Pro Wisdom: Start simple. Get a basic linear model working end-to-end through your entire pipeline before attempting transformer architectures that look impressive but might not actually improve business outcomes.
Phase 4: Validation (Where You Discover Your Model Is Broken)
Your model achieves 95% accuracy on test data.
Congratulations!
Now reality testing begins—the brutal phase where most models reveal fatal flaws that test sets never exposed because real-world data is messier, weirder, and more adversarial than carefully curated evaluation datasets.
Performance Testing validates behavior across temporal and geographical contexts reflecting actual deployment scenarios rather than sanitized lab conditions. Historical validation checks whether the model maintains accuracy on last week's data, ensuring it hasn't overfit to recent patterns that might evaporate. Geographic testing evaluates performance across different regions with cultural variations, local preferences, and regulatory differences that dramatically impact results. Seasonal analysis examines what happens during holidays when user behavior changes radically—Black Friday shopping sprees, vacation travel patterns, year-end budget spending that your training data might have completely missed.
Robustness Testing ensures responsible behavior under adverse conditions and edge cases that inevitably occur in production chaos. Fairness evaluation determines whether the model discriminates against protected demographic groups, creating legal liability and ethical disasters that destroy organizational reputation overnight. Missing data handling tests examine behavior when expected features disappear, ensuring graceful degradation rather than nonsensical predictions. Corruption resilience analyzes responses when input data gets slightly corrupted by network transmission errors, sensor malfunctions, or data processing bugs—because the real world is messy and nothing works perfectly all the time.
Business Validation ensures technical performance translates into actual value and organizational acceptance beyond just hitting accuracy metrics that stakeholders don't truly care about. Domain experts must review predictions to verify alignment with business logic and industry knowledge, catching subtle errors automated metrics miss entirely. Explainable decisions become crucial when stakeholders need to understand and trust model reasoning, especially in high-stakes applications like healthcare or financial services where black-box predictions simply aren't acceptable. Legal and compliance requirements demand thorough addressing of data privacy regulations, algorithmic fairness standards, and industry-specific mandates that could derail deployment and create massive organizational risk.
The Harsh Reality: Models performing perfectly in notebooks often fail spectacularly in production. Validate early. Validate often. Or face brutal surprises when users arrive.
Phase 5: Deployment (Where Everything Goes Wrong)
Your model works great on your laptop.
Now make it work for millions of users with 99.9% uptime.
Good luck.
Deployment Challenges reveal the chasm between development environments and production reality in ways you can't anticipate until you actually try deploying and everything breaks simultaneously. Packaging issues arise when your model requires Python 3.8 but production only supports 3.7, creating version conflicts preventing deployment entirely. Dependencies betray you when TensorFlow works perfectly locally but fails due to hardware differences, library conflicts, or missing system dependencies in production. Scaling decisions force brutal tradeoffs between handling 10 requests per second for internal tools or 10,000 requests per second for customer-facing applications determining infrastructure costs and architectural complexity. Latency constraints create pressure when business demands sub-100ms responses but your model takes 500ms per prediction, forcing painful optimization work. Rollback strategies become critical because when things break—and they will break—you need rapid recovery before users notice and start screaming.
Common Solutions provide battle-tested approaches to deployment challenges through established engineering practices that actually work in production environments:
Docker containers create consistent environments eliminating "works on my machine" problems by packaging models with exact dependencies and runtime requirements in portable units. API endpoints enable easy integration through standardized interfaces other systems consume without understanding underlying model complexity. Load balancers handle scaling by distributing requests across multiple instances, automatically routing traffic to healthy servers and isolating failures. Feature flags enable safe rollouts by allowing gradual exposure of new models to increasing traffic percentages while monitoring performance. Blue-green deployments provide zero-downtime updates by maintaining parallel environments and switching traffic seamlessly between them with instant rollback capability when disasters strike.
Disaster Planning: Your Model Will Fail. Have a Plan:
- Automated rollback to previous stable version
- Fallback to simple rule-based logic
- Circuit breakers preventing cascade failures
- Clear escalation procedures for 3 AM incidents
Phase 6: Monitoring and Maintenance (The Never-Ending Story)
Deployment isn't the end.
It's the beginning.
The beginning of a lifetime babysitting your model, watching performance degrade, fighting to keep it relevant as the world evolves around it in ways you can't predict or control.
What to Monitor:
System Health tracking measures operational performance determining user experience and system stability in real-time. Response time becomes critical because users abandon slow applications instantly, especially in real-time scenarios like fraud detection where milliseconds determine whether you catch thieves or let them escape. Error rates require constant vigilance because failures damage user trust and indicate underlying problems needing immediate attention before cascading disasters consume your entire infrastructure. Resource usage monitoring matters because ML models devour CPU, memory, and GPU resources that impact other components and drive up costs you must justify to increasingly skeptical finance teams. Throughput measurement determines whether your system survives traffic spikes during peak periods without degrading service quality or falling over completely.
Model Health monitoring focuses on statistical and performance characteristics unique to ML systems that traditional monitoring tools completely miss. Prediction accuracy tracking ensures the model continues delivering value by comparing current performance against baseline metrics and alerting when degradation exceeds acceptable thresholds. Data drift detection identifies when input distributions change significantly from training data, signaling the model may no longer suit current conditions and needs urgent retraining. Model drift monitoring catches performance degradation occurring even when data distributions remain stable, often due to changing relationships between features and outcomes invalidating learned patterns. Bias metrics monitoring ensures fairness across demographic groups and prevents discriminatory behaviors developing over time that create legal and ethical disasters.
The Inevitable Decay: All models degrade over time. Customer behavior changes. Market conditions shift. Competitors adapt. Your fraud model catching 90% of attacks last month might catch 60% today—and you need to know immediately when this silent degradation crosses critical thresholds demanding action.
Automated Retraining creates systematic responses to performance degradation eliminating manual bottlenecks that plague traditional ML operations and slow organizations to glacial speeds. When performance drops below thresholds, systems automatically collect fresh training data from production logs, recent transactions, and updated sources ensuring new models learn current patterns rather than outdated behaviors. Retraining applies updated techniques incorporating new algorithms, feature engineering improvements, and hyperparameter optimizations discovered through systematic experimentation. Rigorous validation ensures new models meet quality standards through comprehensive evaluation on holdout datasets and statistical testing proving genuine improvement. Careful A/B testing gradually exposes real users to new models while comparing performance against existing baselines to catch regressions early before they impact everyone. Continuous monitoring tracks improvements providing feedback refining the automated pipeline over time, creating self-improving systems that evolve without constant human intervention.
Without this automation, your ML system becomes a maintenance nightmare consuming your team's entire capacity while delivering diminishing returns.
Part 2: Core Technologies and Deployment Methodologies
Now we dive into the foundational technologies translating MLOps principles into practice. Containerization provides portability. Orchestration delivers scale. Specialized CI/CD pipelines automate everything. Together, these technologies form the technical backbone supporting machine learning systems that actually work in production environments instead of crashing spectacularly when real users arrive.
Section 2.1: Containerization and Orchestration in ML
Containerization and orchestration provide the stable, scalable, and portable infrastructure modern MLOps demands. Without these technologies, you're stuck manually managing dependencies, fighting environment inconsistencies, and struggling to scale when traffic spikes hit your fragile infrastructure like a tsunami hitting a sandcastle.
The Role of Docker
Docker became the standard for good reason. It solves the "works on my machine" problem that has plagued software engineering since the dawn of computing by packaging applications—your ML model, its inference logic, and every single dependency like specific library versions, runtime requirements, and system tools—into self-contained executable units called containers.
This encapsulation ensures identical environments everywhere. Development matches staging. Staging matches production. No more surprises when you deploy and discover production has different library versions that break everything in subtle ways you can't debug at 2 AM when users are screaming about broken predictions.
A typical MLOps workflow using Docker starts with a Dockerfile—a text file containing build instructions that specify base operating system images, copy trained model artifacts and inference scripts, install necessary Python packages and dependencies, and define commands starting the model-serving application like Flask or FastAPI servers that expose prediction endpoints.
The resulting container image becomes a lightweight, portable, and immutable artifact you can store in registries and deploy anywhere supporting container runtimes.
Scaling with Kubernetes
Docker packages containers. Great.
But who manages thousands of containers?
Kubernetes.
Kubernetes orchestrates containerized applications across machine clusters, automating deployment, scaling, and operational management at scale that would be impossible to handle manually. For MLOps specifically, Kubernetes delivers several critical capabilities that transform fragile prototypes into production-grade systems:
Scalability and Load Balancing lets Kubernetes automatically scale model-serving containers up or down based on incoming inference request volumes through horizontal scaling that adds more instances, while also adjusting resources allocated to each container through vertical scaling. Built-in load balancing distributes traffic evenly across available containers, ensuring consistently high throughput and low latency even when traffic patterns fluctuate wildly during peak usage periods.
Resource Management addresses ML workloads being notoriously resource-intensive, particularly model training demanding GPUs and massive memory allocations. Kubernetes efficiently manages and schedules these specialized resources, ensuring different tasks receive computational power they need without resource contention between competing workloads fighting for limited hardware.
High Availability and Resilience represents Kubernetes' core strength for mission-critical ML deployments. The platform achieves fault tolerance by automatically rescheduling containers to healthy nodes when hardware failures occur. Readiness and liveness probes continuously monitor application health, automatically restarting containers becoming unresponsive and ensuring continuous availability of prediction services even when infrastructure fails catastrophically.
Portability and Environment Consistency emerges from Kubernetes abstracting infrastructure details enabling ML workflows to run consistently across diverse environments. Whether you deploy on on-premises data centers, public clouds like AWS, GCP, or Azure, or hybrid configurations mixing both, identical Kubernetes manifests and workflows function identically everywhere, simplifying migration between environments and preventing vendor lock-in that could trap you in expensive platform dependencies.
Ecosystem and Extensions showcase Kubernetes strength through specialized tools designed specifically for machine learning workloads. Kubeflow stands out as the prominent example, providing an open-source ML platform running natively on Kubernetes that delivers comprehensive tool suites simplifying end-to-end workflow orchestration, including dedicated components for building ML pipelines through Kubeflow Pipelines, managing Jupyter notebooks, and serving models at scale—making Kubernetes significantly more accessible to data science teams who just want to train models without becoming infrastructure experts.
Section 2.2: CI/CD for Machine Learning (Continuous X)
Continuous Integration and Continuous Delivery principles anchor MLOps. But they need adaptation. ML systems aren't just code. They're code plus data plus models—a tripartite complexity demanding specialized pipeline approaches that traditional software CI/CD simply can't handle.
Adapting CI/CD for ML
Traditional software CI/CD triggers on code commits to version control repositories. Simple and clean. ML pipelines extend this concept dramatically, triggering not only on code changes but also on new training data arrivals or model configuration updates—ensuring the entire system remains synchronized and any change, regardless of origin, propagates through consistent automated validation and deployment processes.
Pipeline Stages
ML CI/CD pipelines involve four key stages, with significantly expanded testing complexity compared to traditional software pipelines:
- Source: Triggers initiate the pipeline—git pushes to code repositories, new data batches arriving in storage buckets, or new model versions registering in model registries
- Build: Source code and dependencies get compiled or packaged, often involving building Docker containers encapsulating models and their serving environments
- Test: The most dramatically expanded stage in MLOps compared to traditional DevOps, involving multi-faceted testing strategies ensuring quality and integrity of all components
Multi-Faceted Testing in MLOps:
- Unit Tests: Standard software testing for individual code components like feature engineering functions
- Data Validation Tests: Comprehensive checks on incoming data verifying schema correctness, statistical properties, and quality issues
- Model Quality Tests: Automatically evaluate trained model performance on held-out test sets ensuring predefined quality standards get met
- Integration Tests: Verify model services integrate correctly with broader application ecosystems
- Deploy: Once all tests pass, pipelines automatically deploy validated artifacts—deploying new models to serving environments or deploying entire automated training pipelines themselves enabling scheduled or event-triggered execution
Continuous Training (CT)
Continuous Training defines mature MLOps. This automation of model retraining processes gets triggered automatically either on fixed schedules like daily or weekly cadences, or by events such as detecting significant model drift in production or substantial new labeled data batches becoming available.
CT pipelines execute entire model generation processes—data preprocessing, training, evaluation, and validation—and if resulting new models outperform current production models based on predefined metrics, they automatically trigger CD pipelines deploying them. This creates closed-loop systems allowing models to adapt to evolving data patterns and maintain performance over time without manual intervention that creates bottlenecks slowing innovation to crawl speeds.
Section 2.3: Model Deployment Patterns and Strategies
Deploying ML models into production requires careful architecture and rollout strategy consideration. Get this wrong and you'll face reliability disasters, scalability nightmares, and risk exposure that could sink your entire project when production traffic reveals flaws you never anticipated during development.
Serving Architectures
Architecture choice depends on specific application requirements consuming your model's predictions:
Real-time (Online) Inference represents the most common pattern where you deploy models as persistent, low-latency API endpoints like REST APIs serving predictions on demand for single or small-batch inputs. Essential for interactive applications like recommendation engines, fraud detection systems, and chatbots requiring immediate responses because users won't wait more than a few hundred milliseconds before abandoning your application entirely.
Batch (Offline) Inference processes large data volumes in scheduled batches rather than responding to individual requests in real-time. This pattern suits use cases where predictions don't need immediate delivery and can be pre-computed, like generating daily sales forecasts or classifying massive document collections. Generally more cost-effective for high-throughput workloads prioritizing efficiency over immediate response times and tolerating delays measured in hours rather than milliseconds.
Streaming Inference creates hybrid architectures combining real-time and batch processing to handle continuous data streams from sources like IoT devices or event logs. Models process data as it arrives, making predictions on streams, enabling near-real-time responses for applications like power plant monitoring or dynamic traffic management systems where immediate reactions matter but perfect real-time performance isn't absolutely critical.
Edge Deployment addresses applications requiring extremely low latency or offline functionality by deploying models directly onto edge devices like smartphones, industrial sensors, or autonomous vehicles. This approach eliminates network latency entirely by performing inference locally on devices, enabling immediate responses even when connectivity disappears or becomes unreliable—critical for autonomous systems that can't afford to wait for cloud servers to respond.
Rollout Strategies for Risk Mitigation
Introducing new model versions into live production environments carries inherent risks. New models might have unexpected bugs. They might perform poorly on real-world data. They might negatively impact business metrics in ways test data never revealed. To mitigate these risks, several controlled rollout strategies validate new model performance before full exposure to all users:
A/B Testing splits user traffic between the existing model serving as control (Version A) and the new model serving as challenger (Version B), enabling direct performance comparison on key business metrics like click-through rates or conversion rates over time to determine which model delivers superior results in actual production environments with real users and real consequences.
Canary Deployment gradually rolls out new models to small, controlled user subsets serving as "canaries" detecting potential issues before widespread exposure. Teams closely monitor performance metrics and operational health during initial exposure, incrementally shifting traffic to new versions until they serve 100% of requests. If problems arise, rollouts revert quickly minimizing user impact and preventing disasters from spreading across your entire user base.
Shadow Deployment (Shadow Mode) provides particularly safe validation by deploying new models alongside existing production models, receiving copies of live inference traffic in real-time to generate predictions that get logged for analysis rather than sent to users. This allows teams to compare shadow model performance against live models on real-world data without any risk to user experience—you can validate thoroughly before exposing anyone to potential failures.
Blue-Green Deployment maintains two identical but separate production environments where "Blue" represents the current live environment and "Green" serves as an idle environment for deploying and testing new model versions. Once Green environments pass full validation, traffic routing switches instantaneously from Blue to Green enabling immediate rollout. The primary benefit? Equally instantaneous rollbacks by simply switching traffic back to Blue environments when problems get detected—recovery measured in seconds rather than hours.
Section 2.4: Monitoring for Performance Degradation and Model Drift
Machine learning models peak at deployment. Trained and validated on static datasets, they represent the best performance they'll ever achieve. Then production happens. The dynamic, ever-changing world exposes them to data distributions diverging from training data, leading to natural and continuous performance degradation you must detect and address before it destroys business value.
This phenomenon—model drift—makes continuous monitoring absolutely non-negotiable in MLOps lifecycle, ensuring models remain accurate, reliable, and valuable over time instead of silently degrading until someone notices prediction quality has collapsed and business metrics have tanked.
Types of Model Drift
Model drift manifests in two primary forms with different underlying causes:
Data Drift (also called covariate shift) occurs when statistical distribution of model input features P(X) changes while the underlying relationship between features and target variables P(Y|X) remains constant. For example, a house price prediction model trained on data with 1,500 square foot average homes may face accuracy degradation when new housing developments introduce larger homes shifting the "square footage" feature distribution, making the model less accurate on unfamiliar input ranges it never saw during training.
Similar drift occurs with changing user demographics or sensor calibrations in industrial settings.
Concept Drift represents more fundamental drift where statistical properties of target variables themselves change, meaning relationships between inputs and outputs P(Y|X) have shifted and patterns the model originally learned become invalid as underlying reality evolves. For instance, "fraudulent transactions" definitions may evolve as fraudsters adopt new tactics requiring different detection patterns, or customer purchasing behavior might shift dramatically due to fashion trends or global economic events changing what features predict purchases. Even when input data distributions remain stable, model predictions become inaccurate because fundamental relationships it was trained to recognize have changed completely.
Monitoring Metrics and Techniques
Comprehensive monitoring strategies employ various metrics getting holistic views of system health:
Model Performance Metrics provide the most direct measurement of model quality in production by tracking standard evaluation metrics—accuracy, precision, recall, and F1-score for classification models, or Mean Absolute Error and Root Mean Squared Error for regression models. The primary challenge? Obtaining "ground truth" labels for production data which may be significantly delayed or expensive to collect, creating blind spots where you can't measure actual performance until days or weeks after predictions were made.
Data Quality Metrics monitor input data integrity providing early warnings of pipeline issues and potential system failures by tracking the percentage of missing or null values, the rate of data type mismatches, and the frequency of values falling outside expected ranges for critical features—helping identify data corruption or processing errors before they cascade into model performance disasters.
Drift Detection Metrics proactively identify drift before it significantly impacts performance by using statistical methods comparing live production data distributions against static reference datasets, typically the original training data. Common techniques include Kolmogorov-Smirnov tests, Population Stability Index calculations, and KL divergence measurements quantifying distributional differences between datasets—alerting you when current data has drifted far enough from training data to warrant concern.
Prediction Drift serves as valuable proxy metric when ground truth labels are unavailable, monitoring the distribution of model output predictions for significant shifts that might indicate underlying issues. For example, fraud detection models suddenly classifying much higher percentages of transactions as fraudulent can indicate underlying data or concept drift requiring immediate investigation before financial losses mount or legitimate customers get incorrectly blocked.
Monitoring as Security Control
Robust monitoring isn't just operational maintenance. It's critical security infrastructure. Subtle, long-term security attacks like slow data poisoning where adversaries gradually inject malicious data into retraining pipelines, or low-and-slow adversarial attacks, may not trigger traditional signature-based security alerts that look for obvious intrusion patterns.
However, these malicious activities produce effects indistinguishable from natural drift—gradual accuracy degradation, input data distribution shifts, or anomalous prediction output changes. Well-configured monitoring systems with sensitive automated alerts for data drift, concept drift, and performance degradation become powerful security controls providing early warning systems that flag not only natural model decay but also subtle fingerprints of persistent security attacks targeting your ML infrastructure.
This transforms monitoring from reactive maintenance into proactive security posture strengthening your organization's ML security foundation.
Part 3: The Security Frontier: Threats in the ML Lifecycle (MLSecOps)
Machine learning systems integrate into critical business and societal functions. Great for innovation. Terrible for security. They've become high-value targets for malicious actors seeking to exploit unique vulnerabilities inherent in ML lifecycles that traditional cybersecurity measures simply can't protect against because they don't understand the attack surfaces that data, models, and ML infrastructure create.
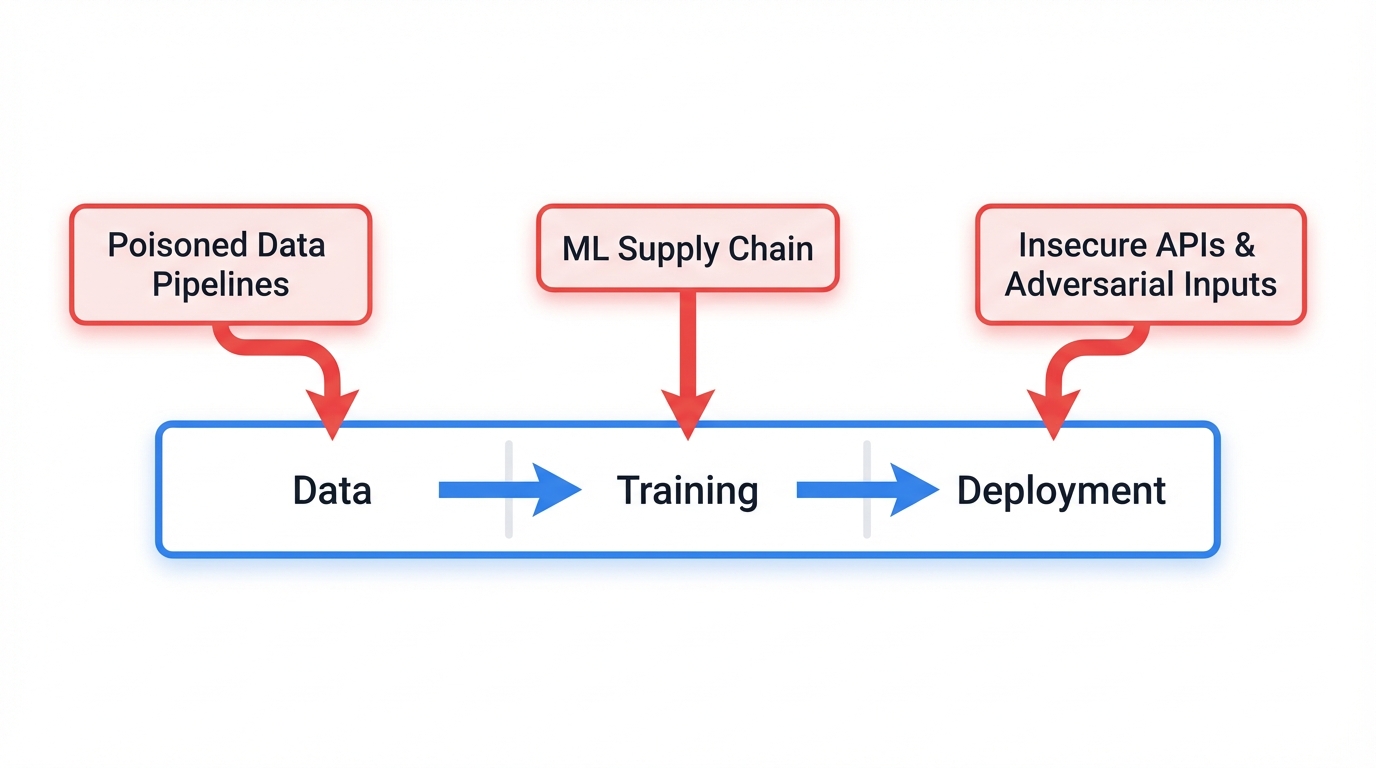
Section 3.1: Compromising the Foundation: Poisoned Data Pipelines
Data poisoning targets the foundation itself. Training data determines everything about your model. Corrupt that data and you corrupt the model completely. Attackers manipulate training datasets intentionally, corrupting learning processes to cause degraded performance, biased outcomes, or hidden backdoors they can exploit after deployment when your guard is down.
Mechanics of Data Poisoning
Attacks occur during training. Obvious timing. Adversaries introduce malicious samples into training datasets aiming to influence learned parameters in ways serving their objectives rather than yours. Several attack vectors enable this:
Data Injection involves attackers adding entirely fabricated data points to training sets manipulating model behavior toward specific outcomes. For example, in product recommendation systems, attackers could inject fake positive reviews for specific products artificially boosting their recommendation rankings and influencing purchasing decisions in ways benefiting the attacker financially.
Label Flipping represents a common and effective technique where attackers take legitimate data samples but systematically change labels to incorrect values. For instance, in spam classification systems, attackers could relabel spam email examples as "not spam," training models to misclassify similar malicious emails in future and bypass security filters protecting users from phishing attacks and malware distribution.
Clean-Label Attacks represent more sophisticated and stealthy poisoning where attackers subtly perturb features of training samples without altering correct labels, keeping perturbations small and often imperceptible while designing them to cause misclassification during training. These attacks can be crafted to cause models to misclassify specific target samples during inference, effectively creating hidden backdoors without using obviously incorrect data that might trigger quality checks.
Impact Analysis
Successful data poisoning consequences can be devastating. Minimum impact? General degradation of model accuracy and reliability across all predictions. Targeted attacks introduce specific biases causing models to make unfair or discriminatory decisions against certain groups, creating legal liability and reputational damage.
The most insidious impact? Backdoor creation where models behave normally on most inputs but produce attacker-chosen outputs when encountering specific secret triggers—like specific phrases in text inputs or small patches on images—enabling attackers to control model behavior while remaining completely undetected during normal operations.
Prevention
Mitigating data poisoning requires defense-in-depth focused on data pipeline integrity:
Data Validation and Verification implements rigorous automated checks validating quality and statistical properties of incoming training data before it can corrupt your models. For labeled datasets, employing multiple independent annotators helps identify and correct maliciously mislabeled samples before training begins, catching poisoning attempts at the source.
Secure Data Provenance and Access Control requires storing training data in secure, encrypted storage with strict access controls preventing unauthorized modification by internal or external attackers. Maintaining clear audit trails of who accessed or modified data and when provides essential forensic capabilities for detecting potential compromises and attributing attacks to specific actors.
Anomaly Detection employs statistical and machine learning techniques identifying anomalies in training data including sudden distribution shifts or statistical outliers potentially indicating poisoning attempts. These detection systems provide early warning of data integrity compromises before they can corrupt model training and create vulnerabilities.
Model Ensembles reduce poisoning attack impact by training multiple models on different training data subsets, forcing attackers to successfully compromise majority of ensemble models to control final predictions—significantly increasing attack complexity and detection likelihood because multiple independent poisoning attacks are much harder to execute stealthily than single targeted corruption.
Section 3.2: Exploiting Deployed Models: Insecure APIs and Adversarial Inputs
Models deployed and exposed via APIs face different attack classes targeting them at inference time. These attacks steal models themselves, extract sensitive training data, or cause models to make critical errors benefiting attackers while harming your organization and users.
Model Extraction and Inversion Attacks
These attacks exploit query access adversaries have to deployed model APIs, compromising intellectual property or training data privacy:
Model Extraction (Model Stealing) aims to steal valuable, proprietary models through systematic API abuse where attackers masquerade as regular users, sending thousands of queries to model APIs and collecting corresponding input-output pairs. They then use collected datasets to train "surrogate" or "substitute" models achieving functionally equivalent performance to original models, effectively replicating them without accessing original training data or model parameters—stealing years of research and development effort through patient systematic querying.
Model Inversion constitutes privacy attacks aimed at reverse-engineering models to extract sensitive information about individuals in training data. By carefully crafting queries and analyzing model outputs, particularly confidence scores, attackers can sometimes reconstruct representative training data samples. For example, attackers could potentially reconstruct facial images used to train recognition models, leading to severe privacy breaches exposing individuals whose images were supposedly protected.
Prevention Strategies:
- Implement strong authentication and authorization controls limiting API access to verified users
- Rate-limit API queries making large-scale data collection infeasible within reasonable timeframes
- Return less granular outputs like final class labels instead of detailed confidence scores revealing internal model behavior
- Apply privacy-preserving techniques like differential privacy adding noise to model outputs obscuring individual training examples
Evasion Attacks (Adversarial Inputs)
Evasion attacks occur at inference time. Attacker goals? Cause deployed models to make incorrect predictions by feeding specially crafted malicious inputs designed to exploit model vulnerabilities. These "adversarial examples" often get created by adding small, human-imperceptible perturbations to legitimate inputs that completely fool ML models.
For example, adding carefully calculated noise layers to panda images can cause state-of-the-art image classifiers to misclassify them as gibbons with high confidence—demonstrating how fragile even sophisticated models can be when facing adversarial inputs crafted by attackers who understand their weaknesses.
Attack Process for crafting effective adversarial examples typically requires some target model knowledge. In "white-box" scenarios, attackers have full access to model architecture and parameters making attack crafting straightforward. In more realistic "black-box" scenarios, attackers can only query model APIs but can still succeed by first training surrogate models through model extraction and then using them to craft adversarial examples that transfer to target models—a technique proving surprisingly effective across different model architectures.
Defense against evasion attacks represents active research with several key strategies proving effective:
Adversarial Training augments model training data with adversarial examples improving robustness by exposing models to these attacks during training, teaching them to become more resilient and less sensitive to small perturbations that could cause misclassification—essentially inoculating models against known attack patterns.
Input Validation and Sanitization implements pre-processing steps detecting and removing potential adversarial perturbations from inputs before they reach models, serving as first line of defense against attack attempts by filtering out obvious manipulations.
Model Ensembles increase robustness by using diverse models together, as adversarial examples crafted for one model may not effectively fool others in the ensemble—requiring attackers to simultaneously fool multiple different architectures with different vulnerabilities, dramatically increasing attack difficulty.
Section 3.3: The ML Supply Chain: A New Attack Vector
ML system supply chains present significantly broader attack surfaces than traditional software. They encompass not just code and dependencies but also datasets used for training and pre-trained models forming foundations of new projects—each representing potential entry points for attackers to compromise your entire ML infrastructure.
Expanded Threat Surface
Organization ML supply chains include all artifacts and processes contributing to final production models. Key vulnerability points include:
Risks from Pre-trained Models arise from widespread transfer learning practices where teams fine-tune pre-trained models from public repositories like Hugging Face or Caffe Model Zoo for efficiency. This introduces significant risks as attackers could upload malicious models that have been backdoored or poisoned while disguised as legitimate popular models that thousands of teams download and trust.
Unsuspecting teams downloading and using these models inherit all their vulnerabilities which could produce specific erroneous outputs benefiting attackers, leak sensitive data to external servers, or execute arbitrary code through exploitation of insecure serialization formats like Python's pickle that can execute code during deserialization.
Risks from Third-Party Data emerge when ML projects rely on datasets acquired from third parties or scraped from web sources without thorough vetting. These data sources can serve as vectors for data poisoning attacks introducing biases or backdoors into models from the very beginning of development lifecycles—corrupting foundations before any internal safeguards can detect problems.
Vulnerabilities in Software Dependencies affect ML systems like any software as they rely on vast ecosystems of open-source libraries and frameworks like TensorFlow, PyTorch, and scikit-learn. Vulnerabilities in any dependencies can be exploited to compromise entire ML pipelines, making dependency management a critical security concern requiring constant vigilance and rapid patching when vulnerabilities get discovered.
Mitigation
Securing ML supply chains requires holistic approaches treating every external artifact—code, data, and models—as potentially untrustworthy until verified:
Verification and Provenance establishes rigorous processes for vetting all third-party assets before integration into ML systems. This includes understanding dataset origins, pre-trained model creation methodologies, and maintaining detailed documentation of asset sources and validation procedures performed before accepting them into your infrastructure.
ML Bill of Materials (MLBOM) functions analogously to Software Bill of Materials, providing comprehensive manifests listing all components and dependencies of ML systems including training data sources, model architectures, software libraries, and hyperparameters—ensuring transparency and traceability throughout ML lifecycles so you know exactly what's in your systems.
Digital Signatures and Integrity Checks employ cryptographic techniques ensuring authenticity and integrity of ML artifacts throughout lifecycles. Tools like Sigstore enable digital signing of models and datasets, allowing teams to verify artifacts haven't been tampered with since creation by trusted sources—providing cryptographic proof of provenance.
Vulnerability Scanning integrates automated scanning tools into CI/CD pipelines systematically checking software dependencies, container images, and model files for known vulnerabilities and malicious code, providing continuous security validation throughout development and deployment phases catching problems before they reach production.
Threat Landscape Summary: This comprehensive table maps ML security threats to lifecycle stages, showing attack vectors and mitigation strategies for each threat category.
| Threat Category | Primary Lifecycle Target | Attack Vector Example | Potential Business Impact | Primary Mitigation Category |
|---|---|---|---|---|
| Data Poisoning | Data Engineering, Model Training | Injecting mislabeled data into a crowdsourced labeling platform | Degraded model performance, biased decisions, reputational damage, creation of exploitable backdoors | Data Provenance & Validation |
| Model Extraction | Model Deployment/Inference | Repeatedly querying a public API to collect input-output pairs to train a surrogate model | Theft of intellectual property, loss of competitive advantage, erosion of service value | API Security & Rate Limiting |
| Model Inversion | Model Deployment/Inference | Analyzing a facial recognition model's confidence scores to reconstruct images of individuals from the training set | Severe privacy breaches, leakage of sensitive training data, regulatory non-compliance (e.g., GDPR, HIPAA) | Privacy-Preserving ML (e.g., Differential Privacy) |
| Adversarial Evasion | Model Deployment/Inference | Adding imperceptible noise to a stop sign image to make an autonomous vehicle's classifier see a speed limit sign | Critical system failure, security bypass, physical harm in safety-critical systems | Adversarial Robustness Training |
| Supply Chain Compromise | Model Development, Data Engineering | Downloading a popular pre-trained model from a public hub that has been backdoored by an attacker | System compromise, data exfiltration, persistent and hidden vulnerabilities in production models | Supply Chain Integrity (MLBOMs, Signatures) |
This structured threat landscape view highlights a critical reality: security can't be isolated. Vulnerabilities intertwine deeply with MLOps lifecycle operational practices themselves. Threat models for ML systems must consider not just traditional infrastructure security but also data pipeline integrity, model API security, and provenance of every artifact used in creation—this holistic perspective forms the core of MLSecOps philosophy.
Part 4: Implementing Secure MLOps for the Enterprise
Now we transition from threat analysis to practical defense. This final part outlines actionable frameworks and advanced techniques for building secure, resilient, and privacy-preserving machine learning systems at enterprise scale, focusing on integrating security as core MLOps lifecycle component and leveraging cutting-edge technologies addressing unique ML risks.
Section 4.1: Proactive Defenses and Hardening Techniques (MLSecOps Framework)
MLSecOps core principle? Security can't be a final checkpoint. It must be continuous and integrated practice throughout entire machine learning lifecycles. This "security by design" approach represents strategic imperative for protecting ML assets and mitigating risks proactively rather than reactively scrambling after breaches occur. Comprehensive MLSecOps frameworks embed security controls at each lifecycle stage:
Secure Data Handling and Provenance recognizes that ML system security begins with data security itself, requiring robust data governance policies including strong encryption for data both at rest in storage and in transit across networks. Enforcing least privilege principles through strict access controls limits exposure to unauthorized access from internal or external threats.
Data pipelines must incorporate automated validation, quality checks, and anomaly detection serving as first defense lines against data poisoning attacks attempting to corrupt training foundations.
Secure Model Development and Infrastructure mandates that all artifacts including code, data, models, and configurations must be version-controlled in secure repositories during development. Training infrastructure, whether on-premises or cloud-based, requires hardening through secure execution environments like Trusted Execution Environments protecting sensitive computations from unauthorized observation, network segmentation isolating ML workloads from other systems, and regular patching and updating of all software components closing known vulnerabilities.
Secure Deployment and API Hardening protects model inference endpoints as primary external attack targets through multiple defense layers including requiring strong authentication and authorization for all API calls verifying user identities, encrypting all network traffic with TLS preventing eavesdropping and man-in-the-middle attacks, implementing robust input validation sanitizing potentially malicious inputs before they reach models, and applying rate limiting preventing model extraction and denial-of-service attacks overwhelming your infrastructure.
Supply Chain Security Best Practices require enterprises to adopt zero-trust approaches to ML supply chains through rigorous vetting processes for all third-party components including datasets and pre-trained models before accepting them into your infrastructure. Machine Learning Bills of Materials should be standard practice maintaining transparent inventories of all dependencies.
Cryptographic signatures managed through frameworks like Sigstore must verify authenticity and integrity of all ML artifacts before pipeline consumption, ensuring they originate from trusted sources and remain unmodified since creation.
Section 4.2: Advanced Privacy-Preserving Machine Learning (PPML)
For applications handling sensitive or proprietary data, standard security measures fall short. Privacy-Preserving Machine Learning offers advanced techniques designed to protect data confidentiality, individual privacy, and intellectual property directly within machine learning processes themselves—not just at the perimeter but throughout the entire computational pipeline.
Differential Privacy (DP)
Differential Privacy provides mathematically rigorous frameworks offering strong, provable privacy guarantees for individuals whose data gets used in datasets. The core promise? Analysis or model training outcomes will be statistically almost identical regardless of whether any single individual's data gets included in or excluded from datasets.
This makes inferring whether specific persons' data was part of training sets extremely difficult for attackers, mitigating membership inference attacks, and reconstructing their data from model outputs becomes nearly impossible, mitigating model inversion attacks.
Mechanism for achieving differential privacy involves introducing carefully calibrated statistical noise into computations. This gets accomplished by adding noise drawn from specific distributions like Laplace or Gaussian to input data, intermediate algorithm results, or final outputs—making mathematically impossible to determine individual participation with certainty while maintaining overall statistical utility.
The Privacy-Utility Trade-off balances privacy protection against model performance through epsilon (ε) parameters, often called "privacy budgets." Lower ε values correspond to more noise and stronger privacy guarantees but tend to decrease model accuracy or utility. Higher ε values provide better utility but weaker privacy protection. Managing this fundamental trade-off represents the central challenge in practical differential privacy applications requiring careful tuning based on specific privacy requirements and acceptable performance degradation.
Application in Deep Learning commonly employs Differentially Private Stochastic Gradient Descent (DP-SGD) for training models with privacy guarantees. Each training step involves two key modifications: first, gradients computed for individual training samples get clipped to maximum norms limiting any single data point's influence on model updates; second, calibrated noise gets added to aggregated gradients before they update model weights—ensuring individual training examples can't be reverse-engineered from final model parameters.
Model Watermarking
Model watermarking protects intellectual property of trained machine learning models. It involves embedding unique, hidden signatures or "watermarks" into models which can later be extracted to prove ownership in cases of theft or unauthorized use—like digital signatures for ML models.
Embedding Methods for watermarking utilize two primary approaches integrating verification signals into model architectures:
- Parameter-based (White-box) Watermarking: This method makes subtle modifications directly to model parameters like weights or architecture. Watermarks get encoded in these parameters in ways that are statistically detectable by owners with access to model internal structures but don't significantly degrade primary task performance—like hidden signatures in neural network weights.
- Trigger-based (Black-box) Watermarking: This approach trains models to exhibit specific predetermined behaviors when receiving secret input sets known as "trigger sets." Models behave normally on all other inputs. Owners can prove ownership of suspect models by querying them with trigger sets and demonstrating they produce expected watermarked outputs. This method proves powerful because it doesn't require access to model internal parameters—you can verify ownership through API access alone.
Robustness presents critical challenges for watermarking by ensuring resistance against removal attacks where adversaries attempt erasing watermarks through techniques like model fine-tuning, pruning, or adversarial training. Current research focuses on creating "symbiotic" watermarks deeply entangled with model primary functionality, making them difficult to remove without destroying model core utility—forcing attackers to choose between removing watermarks and breaking models completely.
Federated Learning (FL)
Federated Learning represents decentralized training paradigms enabling collaborative model building without requiring raw training data to be centralized in single locations. This approach is inherently privacy-preserving and particularly valuable for scenarios where data is sensitive and subject to strict residency or confidentiality constraints like healthcare, finance, or mobile devices where data can't legally or practically leave local environments.
Architectures for federated learning systems provide different coordination models for distributed training:
- Centralized Federated Learning: The most common architecture. Central servers orchestrate processes by distributing initial global models to client sets like hospitals or smartphones. Each client then trains models on their own local data producing updated parameter sets. These local updates—not raw data—get sent back to central servers. Servers aggregate updates from all clients using algorithms like Federated Averaging to create improved global models which get sent back to clients for next training rounds—iteratively improving without ever centralizing sensitive data.
- Decentralized Federated Learning: This architecture eliminates central servers mitigating risks of single points of failure or central bottlenecks. Instead, clients coordinate directly with each other in peer-to-peer networks, exchanging model updates with neighbors to collaboratively converge on global models—fully distributed learning without central authority.
Role in Privacy Preservation extends beyond FL's primary benefit of avoiding direct data sharing, as model updates sent by clients can still inadvertently leak information about their local data through gradient analysis attacks. To provide stronger privacy guarantees, FL often combines with other privacy-preserving techniques. For instance, clients can apply differential privacy by adding noise to model updates before server transmission. This combination of FL and DP creates powerful frameworks for training models on sensitive distributed data with robust privacy protections—the gold standard for privacy-preserving collaborative ML.
The Security Triad in Action
These advanced techniques—Differential Privacy, Model Watermarking, and Federated Learning—aren't mutually exclusive alternatives. They form complementary triads of controls for building truly secure and trustworthy enterprise-grade ML systems. Each addresses distinct but critical security and privacy aspects:
- Differential Privacy focuses on protecting privacy of individuals within datasets
- Model Watermarking protects intellectual property of models themselves
- Federated Learning protects confidentiality and residency of entire datasets
Mature MLSecOps strategies recognize these aren't interchangeable solutions but rather orthogonal defense layers. For example, hospital consortiums could use Federated Learning to collaboratively train diagnostic models on respective patient data without sharing it. They could apply Differential Privacy to model updates ensuring no individual patient information can be inferred from processes. Finally, they could embed watermarks in resulting highly valuable models to protect them from theft and ensure proper use. This integrated security triad application represents the frontier of secure and responsible MLOps.
Conclusion
Machine learning operationalization has evolved. From experimental practice to structured engineering discipline. From chaos to control. We now call this MLOps, and it represents essential DevOps principles extension adapted to manage unique tripartite nature of ML systems defined by code, data, and models interplaying in complex ways traditional software never encounters.
The end-to-end ML lifecycle forms the procedural backbone. Planning identifies real problems. Data engineering builds foundations. Model training creates intelligence. Deployment delivers value. Continuous monitoring maintains quality. Core technologies like Docker containerization and Kubernetes orchestration provide scalable reproducible infrastructure required, while CI/CD/CT pipelines automate lifecycles enabling rapid reliable iteration without manual bottlenecks slowing everything to crawl speeds.
A critical finding? Production environments demand constant vigilance. Model performance isn't static. It degrades from data drift and concept drift as the world evolves. Consequently, robust automated monitoring isn't merely operational best practice—it's fundamental requirement for maintaining deployed model value and reliability over time.
Furthermore, monitoring infrastructure serves dual purposes. Operational maintenance, yes. But also crucial security control providing early warning systems for subtle ongoing attacks that might otherwise evade traditional security measures looking for obvious intrusion signatures.
Increasing ML integration into critical systems introduces new complex threat landscapes. MLSecOps analysis reveals vulnerabilities at every lifecycle stage. Data poisoning attacks corrupt model foundations. Model extraction and evasion attacks exploit deployed APIs. Sophisticated supply chain attacks compromise pre-trained models and third-party data integrity. Addressing these threats requires proactive "security by design" approaches where security weaves into every MLOps pipeline phase rather than being bolted on at the end as afterthought.
Finally, for enterprises handling sensitive data or valuable intellectual property, a new defense frontier emerges. This report explored complementary roles of Differential Privacy protecting individual data privacy, Model Watermarking safeguarding intellectual property, and Federated Learning enabling collaborative training on decentralized private data without centralization risks.
Synthesizing these techniques into cohesive strategies represents secure MLOps pinnacle, providing multi-layered defenses addressing privacy, confidentiality, and ownership simultaneously. Ultimately, successful and responsible machine learning deployment at scale depends on disciplined integration of these operational, monitoring, and security practices into unified frameworks that actually work when production chaos hits and Murphy's Law reveals every weakness you didn't know existed.