Table of Contents
- Your Red Team Report Is Already Stale
- Red, Purple, and the Space Between
- The Maturity Path Nobody Finishes
- The CI/CD Pipeline: One Commit, Full Emulation
- The Architecture: Three Generations
- The Tooling Landscape
- The Adversary Flywheel
- Where Agents Change the Game - and Where They Don't
- Getting Started
- The Real Transformation
Your Red Team Report Is Already Stale
Your last red team engagement ended with a PDF. Techniques documented. Systems compromised. Detections missed. Recommendations prioritized. Action items assigned.
That was six months ago. The attack surface it tested no longer exists in the same form.
This is the fundamental problem with periodic assessment: red team findings have a half-life. A detection gap discovered in March may have been fixed by an infrastructure change in April - or widened by a schema migration in May. You do not know which, because nobody retested.
The Picus Blue Report 2025 quantifies the decay: organizations detect only 1 in 7 attacks, and prevention effectiveness is declining - 62% in 2025, down from 69% the year before. Defenses are degrading between assessments. Nobody notices until the next test.
Let's be direct about what this means: most organizations are not validating their defenses. They are auditing them. An annual red team is a compliance artifact. It tells leadership "we tested" the same way an annual penetration test tells an auditor "we checked." It does not tell anyone whether the detections that were working in March are still working in September.
The fix is not more red team engagements. It is a fundamentally different operating model.
Red, Purple, and the Space Between
Red teaming assesses. Adversarial by design - limited blue interaction, stealthy execution, feedback after the exercise. The value is ground-truth measurement. You need this. Annual or semi-annual red teams provide a reality check nothing else replicates.
Purple teaming improves. Collaborative - red and blue work together, feedback is immediate, the goal is engineering better detections in real time. SCYTHE's Purple Team Exercise Framework (PTEF) formalizes this as an 8-step cycle:
- Red presents the TTP
- Blue discusses expected controls
- Red emulates the TTP
- Blue searches for evidence
- Blue presents findings
- Both document results
- Blue implements short-term fixes
- Both document long-term actions
Each iteration produces an updated detection rule, an emulation test, documentation, and coverage metrics. Repeat for every technique in the plan.
Adversary emulation is the underlying practice both share - structured simulation of realistic attacker behavior based on documented TTPs. Not ad hoc exploitation. Not vulnerability scanning. A traditional pen test not based on TTPs is not adversary emulation.
Red teaming tells you where you stand. Purple teaming makes you better. Neither, alone, is sufficient.
The Maturity Path Nobody Finishes
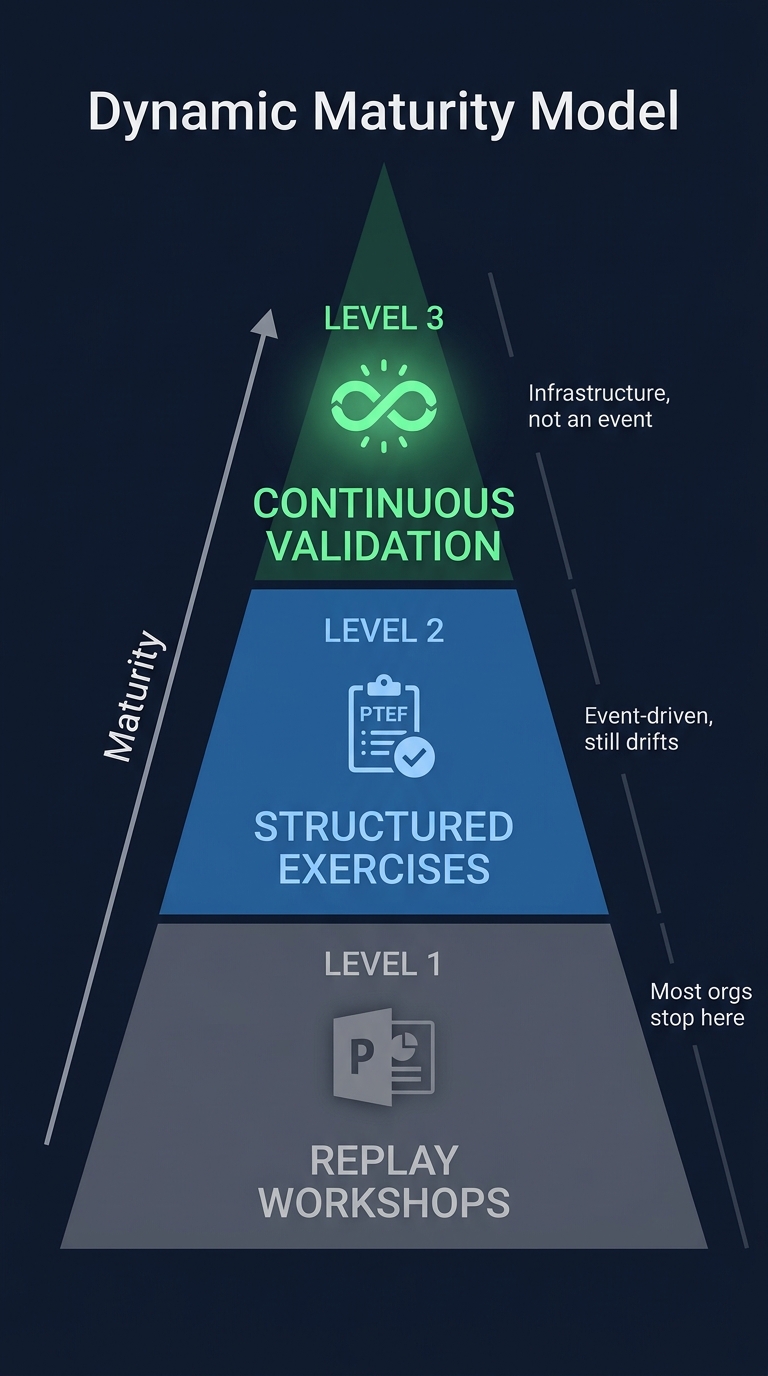
Figure 1: Purple team maturity pyramid - most organizations stop at Level 1 replay workshops. Level 3 continuous validation is infrastructure, not an event.
Most organizations operate at Level 1. A few reach Level 2. Almost none sustain Level 3.
Level 1: Blue Addition to Red. Blue joins a red team debrief. Replay workshops. PowerPoint documentation. This creates awareness but not engineering artifacts. No detection rules written. No coverage measured. No tests automated.
Level 2: Dedicated Purple Exercises. Structured exercises following PTEF. Techniques executed, detections validated, results tracked in VECTR. Detection rules updated as a direct output. ATT&CK coverage measured before and after. This is where value starts - but it is still event-driven. Between exercises, the environment drifts.
Level 3: Continuous Purple Teaming. Emulation runs automatically on a schedule. Detection coverage measured continuously. Gaps trigger detection engineering workflows. The purple team is not a team - it is infrastructure.
The data supports the investment: organizations sustaining purple teaming improve detection coverage from 35-45% to 65-80% of priority techniques within 12 months. Gartner predicts CTEM-adopting organizations will be 3x less likely to suffer a breach by 2026. DORA now makes purple teaming compulsory for EU financial institutions - a regulatory signal other sectors will follow.
Level 3 fails in practice for specific, structural reasons. Not because the tools are missing - the tools exist. It fails because:
- No ownership. Continuous emulation is nobody's job title. It falls between red team, blue team, and detection engineering - and what falls between teams does not get done.
- No integration with detection engineering. Emulation results produce reports, not pull requests. The gap between "we found a missed technique" and "we deployed a new detection" is measured in weeks, not minutes.
- No operational SLA. Nobody has committed to "validate these 50 techniques weekly." Without a cadence commitment, continuous becomes occasional becomes quarterly becomes annual.
- No budget alignment. Organizations buy BAS tooling but do not staff the engineering work that makes the output actionable. The tool runs. The gaps pile up. Nobody writes the rules.
The gap between Level 2 and Level 3 is organizational will, not technology.
The CI/CD Pipeline: One Commit, Full Emulation
This is the architecture that makes Level 3 concrete. It connects version control to adversary emulation to detection validation in a single automated pipeline.
GitHub stores emulation campaigns as version-controlled JSON payloads in an operations/ directory, with an orchestrator.yml defining which payloads to execute. A GitHub Actions workflow triggers on commit to main.
Tines receives a webhook from GitHub Actions, transforms the payload, and calls the Caldera REST API to launch operations. Tines handles sequencing, delays between stages, and error handling.
Caldera receives the API call, deploys the operation against the target agent group, and executes the technique chain.

Figure 2: The CI/CD emulation pipeline - one commit triggers orchestration, which triggers full adversary emulation, with detection results flowing back to GitHub.
A commit to a Git repository triggers a complete adversary emulation campaign. Reproducible. Version-controlled. Auditable. Change the operation payload, push, and the new emulation runs automatically.
On the detection side, the same pipeline queries the SIEM after a configurable delay, checks whether emulated techniques triggered alerts, and posts results back to GitHub. A detected technique stays green. A missed technique becomes a detection engineering ticket - automatically.
One commit. One webhook. Full emulation. The 364 days between red team engagements are no longer dark.
The Architecture: Three Generations
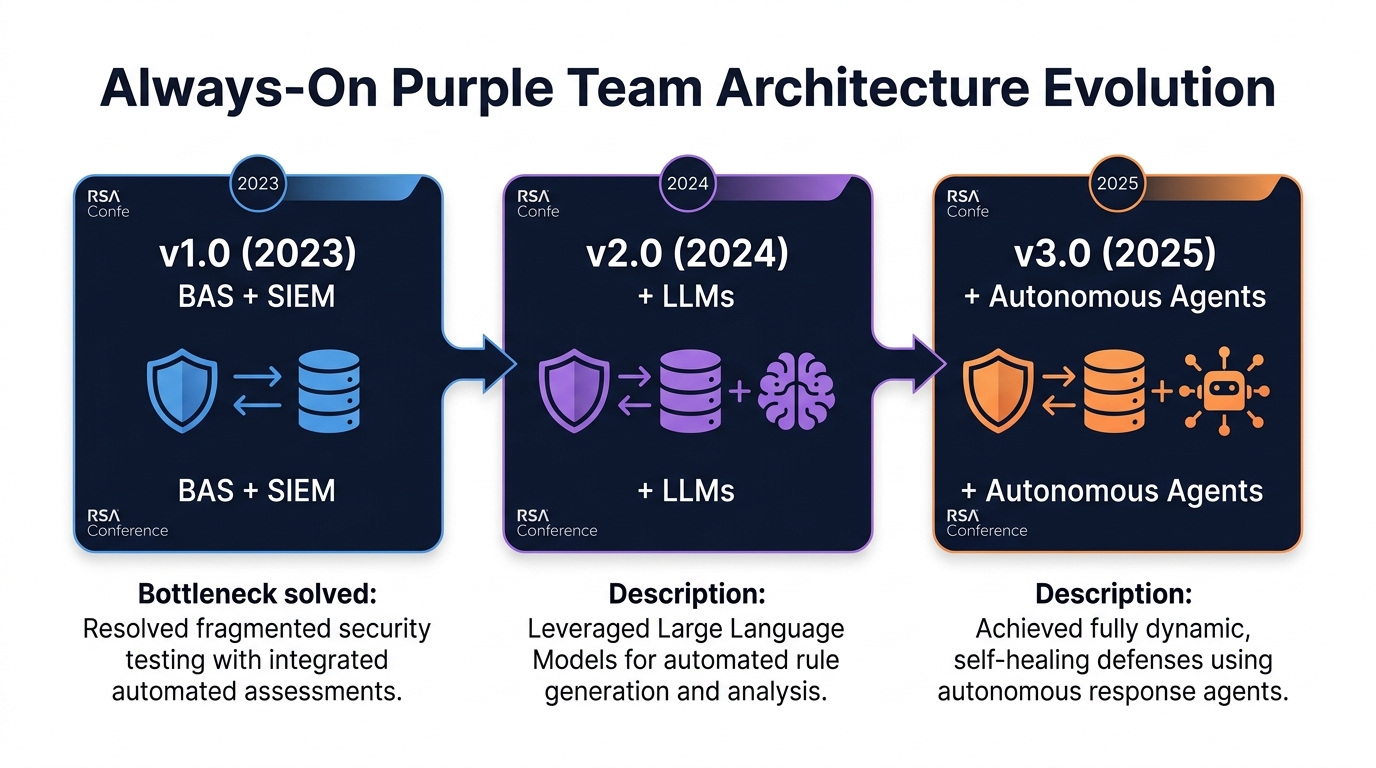
Figure 3: The Always-On Purple Team architecture evolved across three RSA Conferences: BAS+SIEM (2023), adding LLMs (2024), adding autonomous agents (2025).
Erik Van Buggenhout, Stephen Sims, and Jeroen Vandeleur presented the Always-On Purple Team architecture at three consecutive RSA Conferences. Each year solved a real bottleneck in the previous design.
2023 - v1.0: BAS + SIEM. BAS tools execute ATT&CK techniques. Telemetry flows into the SIEM. SOAR validates whether detections fired. Results feed detection-as-code workflows. This is continuous validation - automated emulation producing automated detection measurement. Achievable today with current tooling.
2024 - v2.0: Add LLMs. v1.0's bottleneck is rule creation - BAS identifies gaps faster than engineers write rules. LLMs draft detection rules from emulation output, translate between query languages, suggest coverage for missed techniques. The LLM is an assistant, not an operator. Human review stays in the path.
2025 - v3.0: Add Autonomous Agents. Scripted emulation becomes adaptive. AI agents interpret outcomes, adjust behavior dynamically, and contribute to detection rule creation in real time. An agent that runs a credential dump, observes the EDR response, adapts its approach, and generates a detection for the variant it discovered is qualitatively different from a BAS tool replaying a YAML file.
The honest assessment of v3.0: it introduces new failure modes alongside the new capabilities. Agents hallucinate techniques. Agents generate detection rules that look correct but query nonexistent tables. Agents amplify bad detections faster than humans can review them. The adversary flywheel works in both directions - agents that improve defenses also demonstrate how agents could improve attacks. v3.0 is directionally right and operationally immature. Most organizations would benefit enormously from v1.0.
The Tooling Landscape
Atomic Red Team (Red Canary) is the starting point. Open-source library of portable tests mapped to ATT&CK. Run Invoke-AtomicTest T1059.001, verify your detection fires. Each test is a provable assertion about your detection posture. Over 1,100 tests covering 224 techniques.
MITRE Caldera is the step up for orchestrated campaigns. Server-based, agents on target hosts, YAML-defined abilities chained into operations. REST API makes it CI/CD-native - trigger by webhook, monitor by polling, collect results programmatically.
TTPForge (Meta) brings software engineering discipline - YAML TTP definitions with sub-TTP chaining, a ForgeArmory repository, version-controlled offensive behaviors. If Atomic is a test library, TTPForge is a test framework.
BAS platforms - SafeBreach, AttackIQ, Cymulate, Picus, Mandiant Security Validation - provide enterprise-grade continuous validation. In March 2025, Gartner reclassified BAS into Adversarial Exposure Validation (AEV), consolidating BAS, automated pen testing, and red teaming technology. The market is valued at $574M-$1.96B with 40% projected adoption by 2027.
Cloud-native tools - Stratus Red Team (AWS/Azure/GCP/K8s), Cloud Katana (Azure), KubeHound (Kubernetes) - extend emulation where API abuse and identity misuse are the primary vectors.
None of these replace a skilled red team. They replace the 364 days when nobody is testing.
The Adversary Flywheel
There is a darker version of this feedback loop, and defenders must understand it.
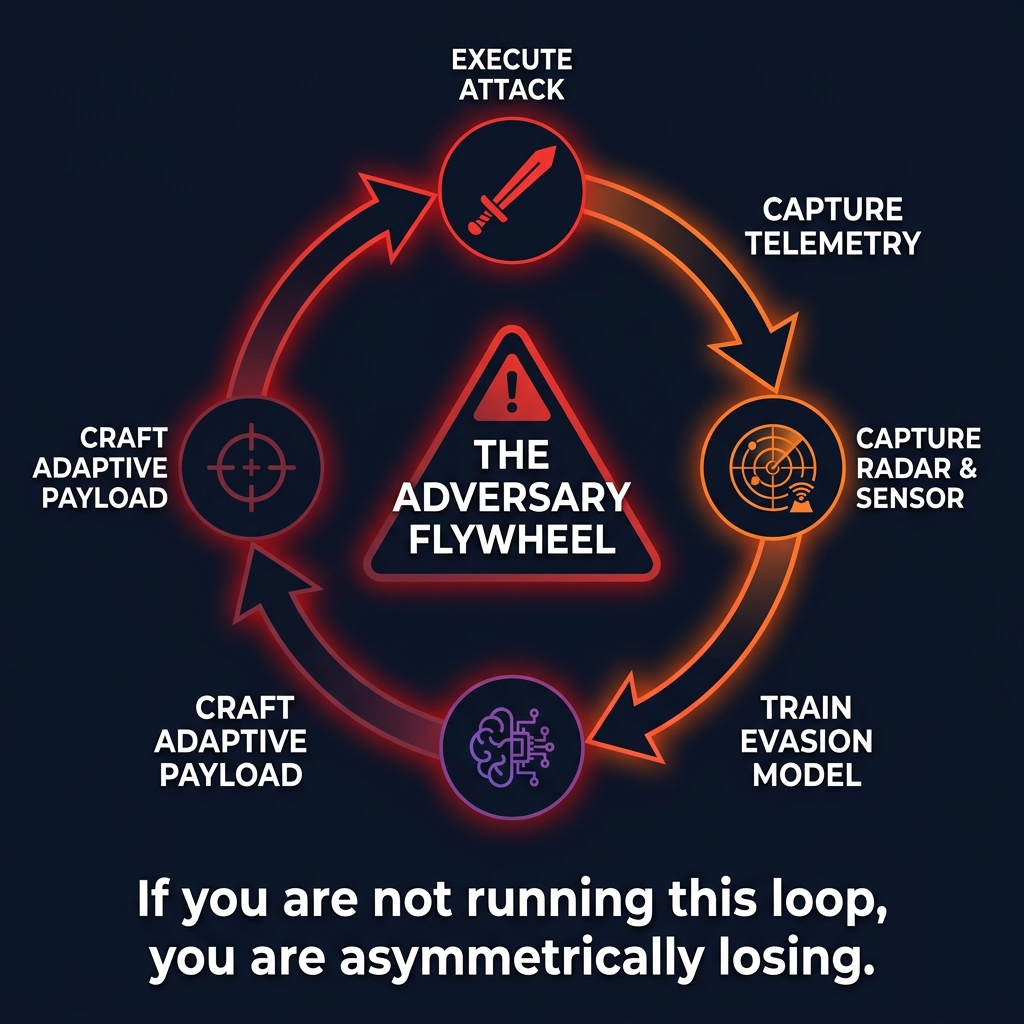
Figure 4: The Adversary Flywheel - execute, capture telemetry, train evasion model, craft adaptive payload - repeat. If you are not running this loop, you are asymmetrically losing.
The adversary flywheel: attackers capture telemetry from their own operations - EDR responses, alert patterns, network blocks - and feed it into ML models that optimize evasion. Train a surrogate model on defender behavior. Use SHAP values to understand what triggers detection. Craft payloads tuned to avoid those triggers.
CalderaGPT, demonstrated at RSA 2024, showed this in practice: an AI agent sets a goal (dump credentials), enumerates the environment, identifies the EDR, consults a RAG knowledge base mapping EDR capabilities, and crafts evasion techniques iteratively - using nanodump instead of Mimikatz because the RAG context indicates Mimikatz signatures are monitored.
This is not theoretical. The tooling exists. The implication is binary: if you are not running a continuous improvement loop on your defenses, you are asymmetrically losing. Your adversaries are using automated feedback to get better. You are using annual PDFs to check a box.
Where Agents Change the Game - and Where They Don't
PurpleCrew, by SEC598 course author Jeroen Vandeleur, demonstrates what agent-driven Level 3 looks like. Built on CrewAI, it orchestrates a Red Team Crew (operator agent interfacing with Caldera) and a Blue Team Crew (SOC Manager, SOC Analyst, Detection Engineer writing KQL validated against the actual Sentinel workspace schema). Crews hand off through shared state. The PTEF 8-step cycle, automated.
This is promising. It is also the kind of system that creates false confidence if the guardrails are weak.
Agent-based purple teaming inherits every risk of agentic AI and adds security-specific ones: hallucinated techniques that test the wrong thing, generated detections that pass syntax but query nonexistent tables, agents that create a feedback loop between bad emulation and bad detection - each validating the other while neither reflects reality. Agents amplify the quality of whatever they are built on. If the underlying telemetry is incomplete, the underlying schema is wrong, or the underlying technique catalog is stale, agents scale the error.
The guardrails are not optional: scoped permissions per agent, human-in-the-loop for destructive actions, audit logging for every tool call, technique allowlists, and kill switches. Agents that can execute Caldera operations and deploy SIEM rules without human checkpoints are a liability, not a capability.
The value of agents is not replacing human purple teamers. It is handling the continuous, repetitive validation that humans cannot sustain manually - running 50 techniques nightly, checking detections, filing tickets for gaps - so the human team focuses on the judgment-intensive work that actually requires expertise.
Getting Started
You do not need agents or BAS platforms to start.
Five high-priority ATT&CK techniques. If you cannot prove detection coverage for five techniques, your coverage metrics are fiction. CardinalOps data shows only 4 of the top 10 most-used techniques have active detections in the average SIEM. Start there.
Atomic Red Team. Install. Run the five techniques. Record whether your detections fired. You now have evidence-based coverage data - more than most organizations have for any technique at all.
A detection repository. Sigma rules in Git. sigma check in CI. Every gap becomes a PR.
A weekly cadence. Weekly is ideal. Monthly is acceptable. Annually is what you are replacing. Same five techniques every cycle. Track coverage over time.
VECTR or a spreadsheet. Track what was tested, what was detected, what remains a gap. This is your coverage truth - not the heatmap in your SIEM vendor's dashboard.
Once stable, expand: more techniques, Caldera for campaigns, CI/CD triggers, the detection-validation feedback loop. Each layer adds value independently.
The Real Transformation
Annual red teams are not going away. They provide something continuous emulation cannot - a realistic, end-to-end adversary assessment by skilled operators who think like attackers. That has irreplaceable value.
What is changing is what happens between assessments. The question is no longer "did we pass the red team?" It is "can we prove, with evidence, that our detections work right now?"
Most organizations cannot answer that question. Their coverage is assumed, not measured. Their detections are deployed, not tested. Their purple teaming is event-driven, not operational. Their validation is periodic in a threat landscape that is continuous.
The adversary is continuous. If your validation is periodic, your security posture is guesswork.
Scott Thornton is an AI Security Researcher at perfecXion.ai. This article draws on the SANS SEC598 course, the Always-On Purple Team RSA series (2023-2025) by Van Buggenhout, Sims, and Vandeleur, the Picus Blue Report 2025, Gartner's Adversarial Exposure Validation research, and the open-source adversary emulation community.