Deepfakes struck first. Early 2024 brought Arup's nightmare—criminals extracted $25.6 million using synthetic identities that fooled experienced executives, manipulating familiar voices and faces with terrifying precision. The application layer seemed vulnerable. It was.
But the smartest attackers pivoted. They saw something better.
Why steal millions when you can hold billions hostage? High-performance networks power trillion-parameter AI models, each costing $100-192 million to train, each representing concentrated value that makes traditional ransomware targets look trivial. These networks don't just enable AI training—they create attack surfaces worth exponentially more than the models themselves, offering control over the infrastructure that powers the AI economy.
The New Reality: Network congestion isn't just a performance problem anymore. It's a weapon. A well-executed network attack can degrade training performance by 89% while appearing as legitimate congestion, toppling AI empires without triggering a single intrusion alert. Welcome to the new frontier, where microseconds determine competitive advantage and attackers who master network fabric control hold the keys to trillion-dollar kingdoms.
Part I: The Great Fabric War - InfiniBand vs. Ethernet RoCEv2
Picture this scenario. You're building an AI cluster that will define your organization's competitive future for the next five years, with hundreds of millions of dollars hanging in the balance and every architectural decision carrying implications you'll live with long after the first GPU powers on. One choice towers above all others. One decision shapes everything that follows.
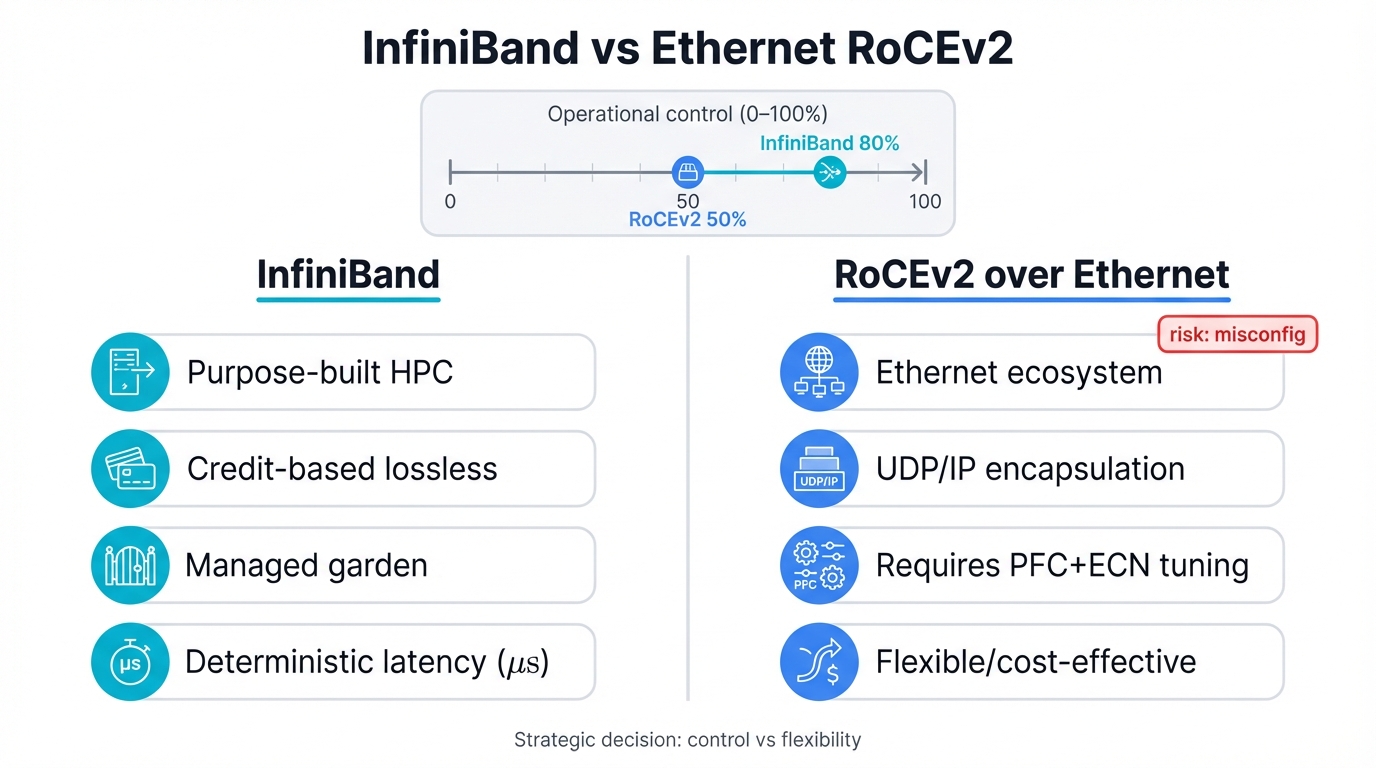
InfiniBand or Ethernet with RoCEv2?
Cluster Control Plane Security
The AI cluster control plane represents a high-value target that sophisticated attackers increasingly prioritize. Compromising orchestration systems provides attackers with complete infrastructure control, enabling them to manipulate training processes, exfiltrate model weights, or sabotage competitive AI development programs with surgical precision.
This choice determines everything. Training speeds matter deeply, yes, but they're just the opening move in a longer game that encompasses security posture, operational complexity, vendor relationships, cost structures, and your entire risk profile for half a decade. Get it right and you build on solid foundations. Get it wrong and you'll spend years fighting architectural decisions made in a single afternoon.
The numbers tell a brutal truth that can't be negotiated away. Large-scale AI models grow exponentially, placing unprecedented demands on network infrastructure that traditional data centers simply weren't designed to handle. Hundreds of GPUs work in concert. Sometimes thousands. Each one generating massive data flows. Each one dependent on split-second coordination. Your network fabric isn't a peripheral concern anymore—it becomes the critical bottleneck that determines performance, scalability, and ultimately the cost per training run that makes or breaks AI economics.
Two Philosophies, Two Destinies
InfiniBand and Ethernet RoCEv2 embody radically different design philosophies, each with passionate advocates, proven track records, and fundamental tradeoffs that ripple through every layer of your infrastructure. One technology was born for this exact moment. The other evolved to survive it.
InfiniBand engineers built their fabric from the ground up with a singular focus on what high-performance computing demands when you push physics to its limits. Purpose-built for the rigorous demands of tightly coupled parallel computing. Designed explicitly for the massive collective operations that large-scale AI training requires every microsecond of every training run. This switched-fabric architecture employs elegant two-layer designs where physical and data link layers operate separately from network layers, each optimized for its specific role. These structures optimize relentlessly for ultra-low latency and massive bandwidth in tightly coupled systems where every nanosecond of delay compounds across thousands of GPUs. The primary objective? Maximize performance for data-intensive applications where microseconds separate success from failure, where jitter can cascade into catastrophic training slowdowns, where deterministic behavior trumps every other consideration.
Ethernet with RoCEv2 takes a fundamentally different path that reflects different priorities and different constraints. It represents converged approaches that extend ubiquitous Ethernet standards already deployed in data centers worldwide, leveraging decades of investment in switching infrastructure, operational expertise, and ecosystem development. The goal sounds simple but requires sophisticated engineering: support RDMA without throwing away everything you've already built. RoCEv2 protocols accomplish this by encapsulating InfiniBand transport mechanisms within standard UDP and IP headers, creating a hybrid that speaks both languages. This clever approach makes RoCEv2 traffic routable across standard Layer 3 networks, enabling it to traverse existing IP infrastructure while delivering RDMA performance that approaches specialized fabrics. It leverages the vast existing ecosystem of tools, monitoring systems, security appliances, and hard-won operational expertise that IT teams have developed over decades of managing Ethernet networks.
Architectural Philosophy: RoCEv2 doesn't aim to replace Ethernet with something fundamentally different. Instead, it enhances what already exists, providing high-performance RDMA capabilities in ways that are cost-effective, that scale efficiently, and that integrate seamlessly into the mainstream data centers where most AI training actually happens. This pragmatic approach accepts certain compromises in exchange for enormous practical advantages in real-world deployments.
This architectural split reveals profound differences in operational philosophy that extend far beyond technical specifications you'll find in vendor white papers or benchmark results that look impressive in PowerPoint presentations.
InfiniBand embodies the "managed garden" approach that prioritizes control and optimization above all else. Tightly integrated systems where every component comes from vendors who coordinate closely. Centrally controlled fabrics where administrators wield precise control over every aspect of network behavior. Optimized specifically for the singular purpose of high-performance communication between tightly coupled compute nodes. This philosophy delivers exceptional performance that benchmarks love and inherent reliability that comes from vertical integration, though it often comes at higher prices and with reduced flexibility when requirements evolve in unexpected directions.
RoCEv2 represents the "converged ecosystem" approach that values flexibility and leveraging existing investments. It capitalizes on Ethernet's ubiquity in modern data centers where switches already exist, where staff already know the protocols, where monitoring tools already work. Cost-effectiveness matters when you're building at scale. But this approach places a heavy burden on network architects and operations teams who must transform inherently lossy Ethernet into the lossless fabric that AI training demands. They must create reliable environments from components designed for different purposes, introducing significant operational complexity that can't be ignored. Configuration error surfaces grow much larger when you're combining technologies. Catastrophic network failures become possible when any component misconfigures its congestion control, creating cascade effects that ripple through the entire fabric.
Strategic Decision: The choice between InfiniBand and RoCEv2 transcends technical considerations about latency numbers or bandwidth specifications. It's fundamentally strategic, forcing you to answer a deeper question about organizational philosophy and risk tolerance: Do you want to assume the operational risk and complexity yourself in exchange for flexibility and cost advantages? Or would you prefer to offload that risk to specialized vendors who provide integrated solutions at premium prices but with proven reliability?
The Lossless Imperative: Two Paths, Same Destination
AI training demands perfection at scale. Networks must never drop packets due to buffer overflow, because in the tightly synchronized world of distributed training, a single lost packet spells disaster that cascades through the entire cluster. Entire computations stall while thousands of GPUs wait for retransmission. Results become incorrect when gradient updates arrive out of order. Costly retransmissions cripple the performance you spent millions of dollars to achieve, turning your cutting-edge infrastructure into an expensive lesson in network physics.
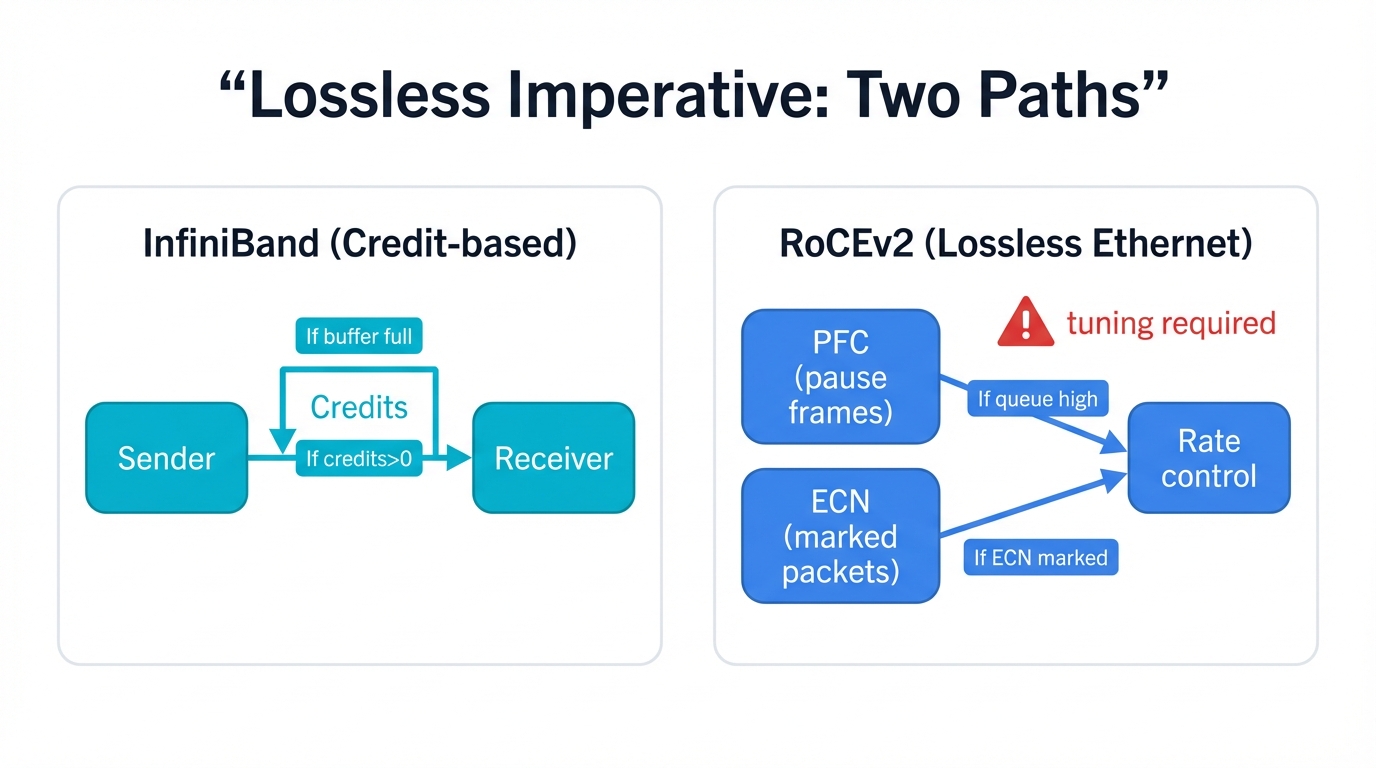
Both InfiniBand and RoCEv2 achieve this critical lossless property. Both reach the same destination. But they travel fundamentally different paths to get there, and understanding these mechanisms shapes everything about how your network behaves under load, how it fails when components malfunction, and how difficult it becomes to operate at scale.
InfiniBand: Born Lossless
InfiniBand was architected to be lossless from day one, with intrinsic link-level credit-based flow control woven into the protocol's fundamental design rather than bolted on as an afterthought. The mechanism works elegantly: sending nodes must check first, verifying that receiving nodes have sufficient buffer space before transmitting even a single byte. These available buffer spaces are called "credits" in InfiniBand terminology. Senders can only transmit data after confirming that receivers have available credits to accept that data, proactively preventing buffer overflows through design rather than reactive mechanisms that kick in when problems already exist.
This credit-based flow control mechanism forms InfiniBand's protocol core rather than existing as an optional extension. Lossless operation comes guaranteed by the architecture itself. No complex external configuration required. No careful tuning needed. No failure modes to debug at 3 AM when training runs mysteriously stall. It just works, delivering the deterministic behavior that large-scale AI training absolutely requires.
RoCEv2: Configured Lossless
RoCEv2 faces a fundamentally different challenge that stems from Ethernet's original design principles and the constraints of backward compatibility. Standard Ethernet operates inherently lossy by design, with "best-effort" delivery defining its core architecture since the protocol's inception decades ago. Supporting RoCEv2's RDMA requirements means transforming Ethernet into something it was never originally designed to be: a completely lossless fabric where packet loss becomes unacceptable rather than an expected part of normal operation.
This transformation requires sophisticated engineering and careful orchestration across every component in the data path. Two key mechanisms make lossless Ethernet possible, each with its own complexities and tradeoffs:
- Priority Flow Control (PFC): Defined in IEEE 802.1Qbb, PFC enables switches to send PAUSE frames upstream to the previous hop when buffers for specific traffic classes approach capacity, creating back-pressure that prevents overflow. This prevents buffer overflows effectively but creates head-of-line blocking issues where pausing one traffic class can inadvertently affect others, potentially cascading pause frames backward through the network in ways that create unexpected bottlenecks far from the original congestion point.
- Explicit Congestion Notification (ECN): ECN provides a more sophisticated approach than blunt PAUSE frames by marking packets to signal congestion without completely halting traffic flow on entire links. Requires extremely careful tuning of marking thresholds and rate response algorithms across the entire fabric, with configuration parameters that must be precisely coordinated between senders, receivers, and every switch in the path to prevent oscillations, unfairness, or catastrophic congestion collapse.
When configured correctly by experts who understand the deep interactions between PFC, ECN, buffer allocation, and traffic patterns, the result can match InfiniBand's lossless behavior in practical deployments. But achieving that requires deep expertise, careful planning during initial deployment, and ongoing operational attention as workloads evolve and new traffic patterns emerge. Configuration mistakes create performance disasters where training runs slow to a crawl or complete system failures where networks lock up in congestion deadlocks that require manual intervention to resolve.
Part II: The Security Battlegrounds - Where Networks Become Weapons
Here's the cruel irony. The same network performance optimizations that enable trillion-parameter model training simultaneously become sophisticated attack vectors that traditional security tools never anticipated. The mechanisms that make AI training possible create security vulnerabilities that transform networks from infrastructure into weapons. Understanding these attack surfaces proves critical for protecting infrastructure investments that can exceed a billion dollars when you account for facilities, power, cooling, and the specialized expertise required to operate these systems.
Congestion Control as Attack Vector
Modern AI fabrics depend absolutely on sophisticated congestion control algorithms that make split-second decisions based on real-time network telemetry flowing through the system at microsecond intervals. These algorithms must react instantly to changing conditions, adjusting transmission rates, rerouting flows, and managing buffer allocation dynamically. But attackers who can manipulate this telemetry gain effective control over network behavior itself, turning performance optimization systems into precision weapons that can target specific victims while leaving attack traffic untouched.
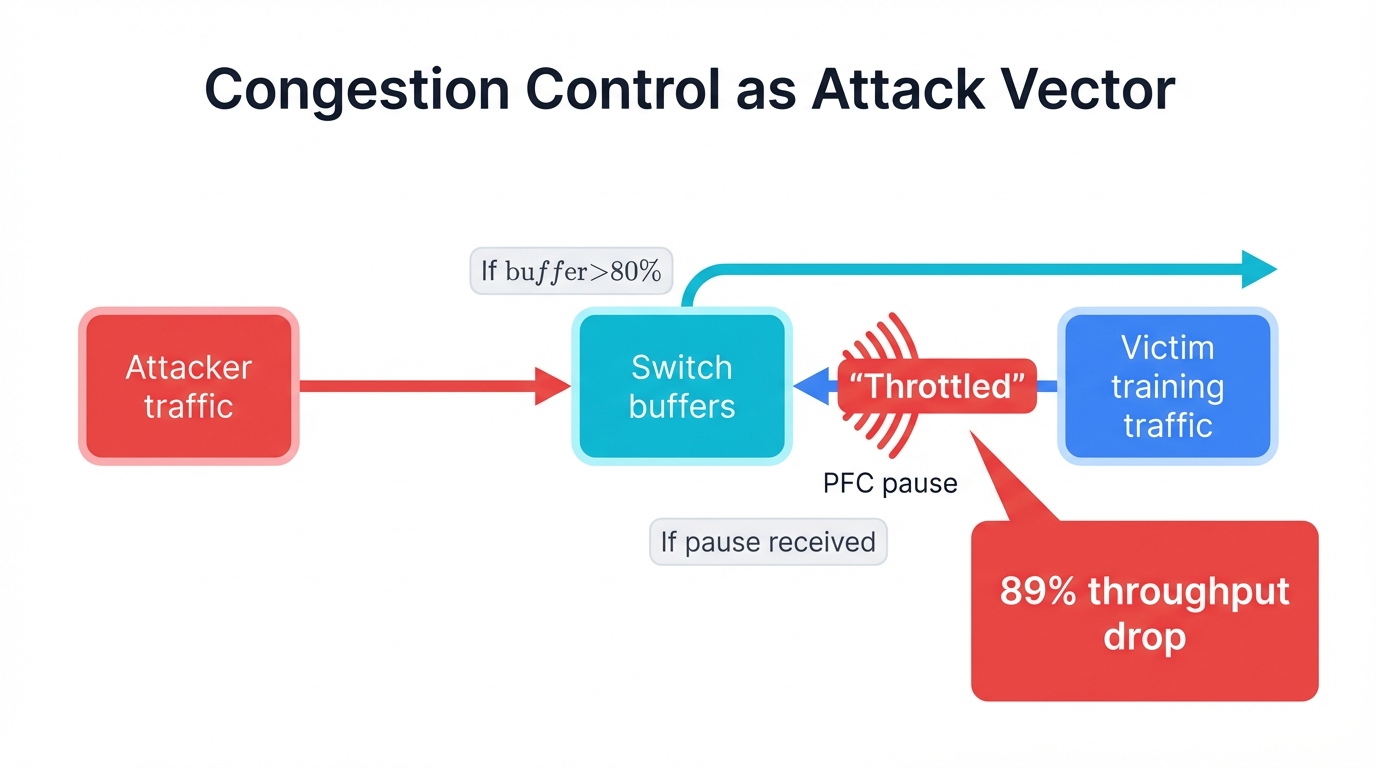
Priority Flow Control Weaponization: PFC's pause frame mechanism, designed to prevent buffer overflow and protect against packet loss, can be triggered maliciously with devastating effect. Attackers generate carefully crafted traffic patterns that intentionally overwhelm specific switch buffers, triggering cascading pause frames that propagate backward through the network topology like a digital tsunami. The result? Legitimate training traffic freezes completely while attack traffic continues flowing freely through alternate paths, creating a selective denial of service that appears entirely legitimate to monitoring systems that only see proper protocol operation.
ECN Manipulation: More sophisticated attacks target ECN marking thresholds with surgical precision, exploiting the delicate balance that congestion control algorithms must maintain. By crafting specific traffic patterns that probe buffer depths and measure switch behavior, attackers can trigger false congestion signals that deceive sender rate control mechanisms. Victim flows reduce their transmission rates unnecessarily, believing they're being good network citizens, while attackers maintain full bandwidth utilization and complete their malicious objectives unconstrained.
Devastating Impact: Research from leading security labs demonstrates that these congestion control attacks can reduce AI training throughput by up to 89% while remaining virtually undetectable to traditional monitoring systems that watch for obvious attack signatures. The attacks appear as legitimate congestion management rather than malicious interference, blending seamlessly into normal network behavior. Training runs slow to crawls. Costs skyrocket. Deadlines evaporate. And the only evidence is performance degradation that looks exactly like natural congestion from innocent workload increases.
Telemetry Poisoning: When Monitoring Becomes Surveillance
AI fabrics rely heavily on real-time telemetry for the performance optimization that distinguishes cutting-edge infrastructure from merely adequate systems. In-band Network Telemetry (INT) embeds detailed metadata directly into packets as they traverse the network, providing unprecedented visibility into queue depths, latency variations, path changes, and congestion indicators at every hop. This visibility enables advanced traffic engineering that can squeeze every bit of performance from expensive infrastructure. But it also creates massive information leakage opportunities that attackers can exploit for reconnaissance and attack planning.
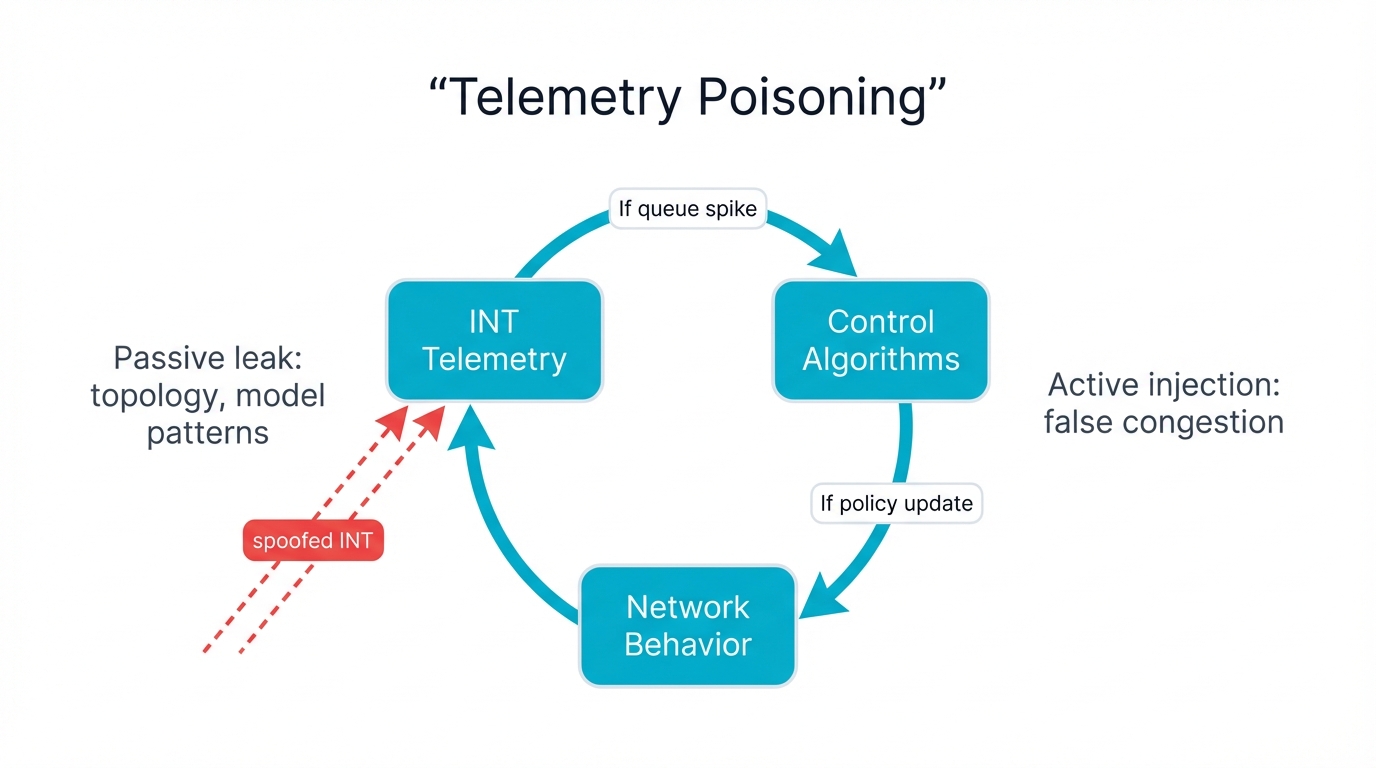
Intelligence Gathering: Attackers with access to telemetry streams—whether through compromised switches, tapped links, or misconfigured monitoring exports—can extract extraordinary amounts of sensitive information:
- Map the complete network topology including redundant paths, bottleneck links, and critical infrastructure components that represent single points of failure
- Infer AI model architectures from communication patterns between GPUs, reverse-engineering model structure from collective operation sizes and synchronization frequencies
- Determine training progress and identify the most valuable models by analyzing traffic volumes, checkpoint frequencies, and convergence indicators that leak through network behavior
- Discover optimal attack windows for maximum disruption by understanding traffic patterns, identifying peak utilization periods, and finding moments when attacks cause cascading failures
Active Manipulation: Beyond passive surveillance that merely observes network behavior, sophisticated attackers can inject false telemetry data that actively manipulates network control systems. Modified queue depth measurements make switches believe congestion exists where none occurs. Fabricated latency reports deceive routing algorithms into choosing suboptimal paths. Networks respond obediently to fictitious congestion by throttling legitimate traffic, while attack flows exploit the artificially created capacity.
The fundamental problem? Most telemetry systems lack authentication mechanisms that would allow receivers to verify data integrity and source identity. Adding cryptographic authentication introduces latency overhead that performance-obsessed network architects resist. This creates an impossible tradeoff between visibility and security, between optimization and integrity, between knowing what's happening and trusting what you know.
Multi-Tenant Attack Surfaces
Cloud-based AI training introduces multi-tenant security challenges that dramatically complicate the already difficult task of securing high-performance fabrics. Multiple organizations share the same expensive physical infrastructure while requiring complete logical isolation that prevents any cross-tenant information leakage or interference. The performance optimizations that enable massive AI training—shared buffers, converged fabrics, statistical multiplexing—can all be weaponized for cross-tenant attacks that violate isolation boundaries without leaving obvious forensic evidence.
Resource Exhaustion Attacks: Malicious tenants can deliberately consume shared resources like switch buffers, network interface queues, or ECN marking thresholds that cloud providers must pool for efficiency. Well-crafted attack traffic exhausts these finite resources for other tenants while maintaining perfectly plausible deniability—after all, the traffic looks legitimate, stays within contractual bandwidth limits, and follows all protocol rules. Victims experience mysterious performance degradation. Attackers achieve their objectives. Cloud providers struggle to distinguish attacks from innocent traffic spikes.
Timing Side Channels: Shared network fabric creates subtle timing-based side channels that careful attackers can exploit for information extraction. By measuring network response times with microsecond precision and analyzing correlation patterns between their traffic and observable network behavior, attackers can infer sensitive information about victim workloads, training progress, model characteristics, and even specific algorithmic choices that leak through timing variations too subtle for human operators to notice but perfectly clear to automated analysis systems.
Covert Channels: Perhaps most concerning from a security perspective, determined attackers can establish covert communication channels through carefully orchestrated congestion patterns that encode information in network behavior. These channels operate entirely within normal traffic parameters, never violating bandwidth limits or triggering obvious anomalies, making them virtually undetectable to security monitoring systems that watch for traditional attack signatures. Information exfiltration. Command and control. Coordination between compromised systems. All hidden in the noise of legitimate congestion.
Supply Chain and Hardware Attacks
The staggering complexity of modern AI fabrics—with switches containing billions of transistors, firmware managing intricate state machines, and management systems coordinating thousands of components—creates numerous supply chain attack opportunities that span from chip fabrication through deployment. Compromised firmware in switches, network interface cards, or management systems can provide persistent access to critical infrastructure that survives reboots, evades detection by software security tools, and enables attackers to maintain long-term presence in the most sensitive parts of your network.
Firmware Manipulation: Attackers who compromise the firmware development or distribution chain can modify network device firmware to inject malicious capabilities that fundamentally undermine security:
- Inject malicious behavior into congestion control algorithms that selectively degrades specific flows while maintaining overall performance metrics that monitoring systems expect
- Create backdoors for persistent network access that survive firmware updates, factory resets, and security audits that only examine configuration files
- Manipulate telemetry data to hide attack activities from monitoring systems, creating false realities where everything appears normal while attacks proceed undetected
- Establish covert command and control channels using reserved protocol fields, unused packet types, or timing variations that carry information without observable content changes
Hardware Trojans: Even more sophisticated and difficult to defend against, hardware-level attacks involve subtle modifications during the manufacturing process itself, adding circuits or altering existing designs in ways that create exploitable vulnerabilities. These hardware trojans can be virtually impossible to detect through software analysis alone, requiring expensive physical inspection, X-ray imaging, or destructive testing that can't scale to verify every component in massive deployments. Nation-state actors with access to fabrication facilities represent the primary threat, but the globalized semiconductor supply chain creates opportunities at multiple points where motivated attackers might introduce malicious modifications.
Part III: The Economics of Network Warfare
The financial implications of AI network security extend far beyond traditional cybersecurity cost models that measure incident response expenses, reputation damage, or regulatory fines. When trillion-parameter models cost $100-192 million to train in compute expenses alone—not counting the facilities, specialized expertise, or opportunity costs—even minor performance degradation creates economic damage that dwarfs typical ransomware payments or data breach costs. The economics reshape everything about how we must think about infrastructure security.
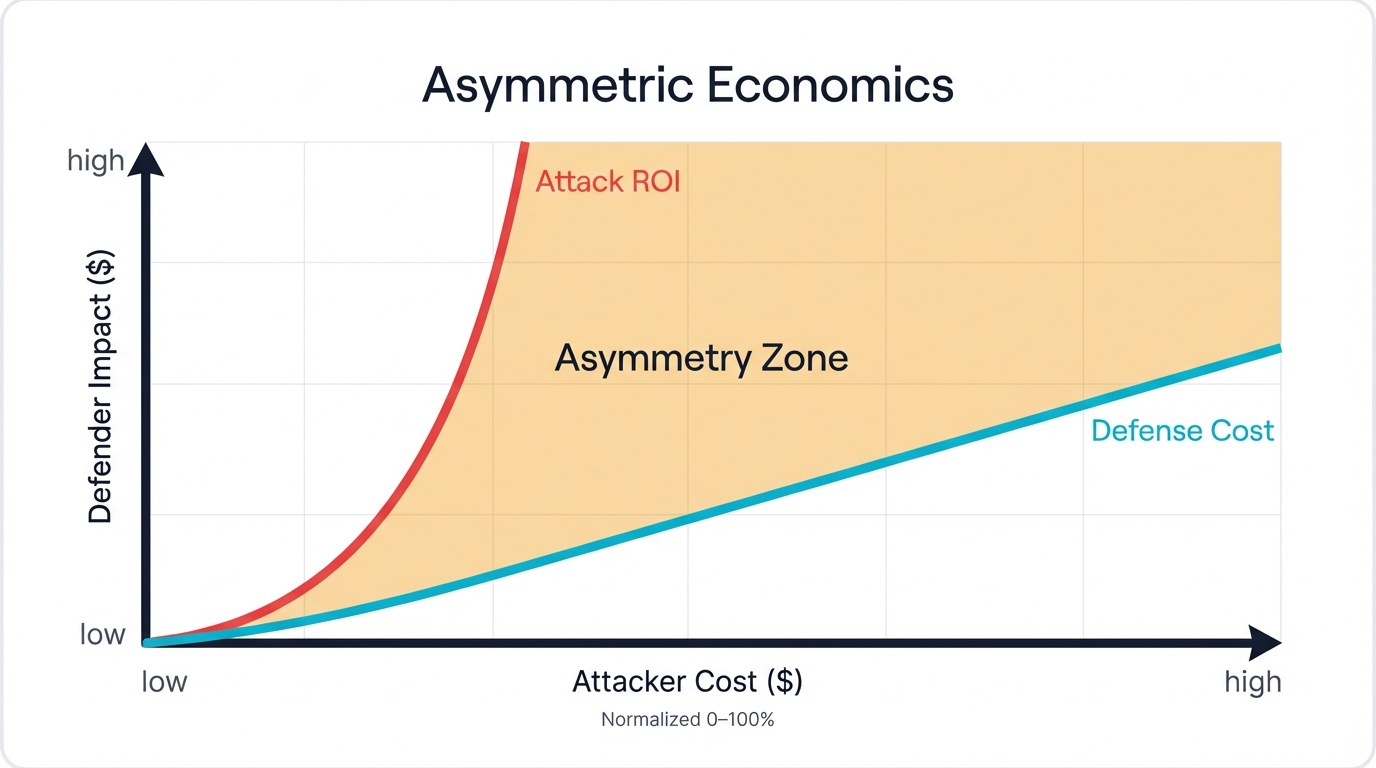
Attack ROI: Asymmetric Economic Warfare
Network attacks against AI infrastructure offer exceptional return on investment for attackers willing to invest in the specialized knowledge required to exploit these systems. A modest investment in attack infrastructure—perhaps $100,000 for compromised credentials, vulnerability research, and attack tool development—can cause economic damage that's literally orders of magnitude larger, creating asymmetric warfare where defenders must protect everything perfectly while attackers need only find a single exploitable weakness.
Direct Training Costs: Modern large-scale AI training consumes thousands or even millions of GPU-hours, with each hour costing hundreds of dollars in direct compute expenses before accounting for power, cooling, or facilities overhead. Even small network-induced delays translate to enormous economic waste that accumulates relentlessly:
- A mere 5% performance degradation across a three-month training run translates to $5-10 million in wasted compute resources for the largest models, with that waste continuing every day the attack remains undetected
- Training delays can cause organizations to miss critical market opportunities worth hundreds of millions when competitors ship AI capabilities first, capturing market share and mind share that may never be recoverable
- Complete training failures that corrupt model weights or poison training data require starting over from scratch, essentially doubling the already astronomical costs while competitors surge ahead
Intellectual Property Theft: Successful attacks against model weights, training data, or architectural innovations represent intellectual property theft with value measured in billions rather than millions. The proprietary AI models that companies spend years developing become the foundation of competitive advantage in markets from drug discovery to autonomous vehicles. Stealing these models allows competitors or adversaries to leapfrog years of research investment, while the original developers lose the differentiation that justified their massive AI investments in the first place.
Economic Vulnerability: The extreme concentration of value in individual AI models creates irresistibly attractive targets for nation-state actors pursuing technological supremacy and sophisticated criminal organizations seeking maximum profit. When a single successful attack can yield billions in stolen intellectual property or create hundreds of millions in competitive damage, the potential gains easily justify investment in attack campaigns that might cost millions to execute. The economics fundamentally favor attackers in ways that traditional security models never anticipated.
Defense Cost Structures
Defending AI infrastructure requires completely new security investment models that go far beyond deploying additional firewalls or intrusion detection systems designed for traditional enterprise networks. Traditional cybersecurity tools prove woefully inadequate for the unique challenges of high-performance networking where attacks exploit performance optimizations rather than software vulnerabilities, where malicious traffic looks indistinguishable from legitimate congestion, and where microsecond-scale decisions determine success or failure.
Specialized Security Tools: Effective AI fabric security requires purpose-built capabilities that don't exist in conventional security product portfolios:
- Real-time network behavior analysis operating at microsecond timescales that can detect subtle anomalies in congestion control behavior before they cascade into training failures
- Authenticated telemetry systems with cryptographic integrity protection that prevent attackers from poisoning the monitoring data that network control systems depend on
- Congestion control algorithms specifically hardened against manipulation, with rate limiting, anomaly detection, and graceful degradation when attacks are detected
- Hardware-based security features integrated directly into network silicon rather than implemented as software overlays that introduce unacceptable latency
Operational Security Overhead: Maintaining robust security in AI fabrics requires specialized expertise that commands premium salaries and continuous monitoring that scales with infrastructure complexity. Network security engineers who understand both high-performance computing and advanced attack techniques remain scarce, creating bidding wars for talent. The operational costs can be substantial—perhaps millions annually for large deployments—but remain remarkably small compared to the assets being protected and the potential losses from successful attacks.
Insurance and Risk Management
Traditional cyber insurance policies, designed for data breaches and ransomware incidents, don't adequately cover the unique risks that AI infrastructure faces. Insurance companies built their actuarial models on decades of experience with enterprise IT security, but AI-specific risks follow completely different patterns with different attack vectors, different loss scenarios, and different probability distributions. New insurance products are slowly emerging to address these gaps, though coverage remains expensive and limited:
- Training Interruption Insurance: Covers the direct costs of interrupted training runs including wasted compute, restart expenses, and delay penalties, though policies often exclude attacks that exploit known vulnerabilities or result from inadequate security practices
- Model Theft Protection: Addresses intellectual property theft scenarios where attackers exfiltrate model weights or training data, providing coverage for both direct losses and competitive damages, though valuing stolen IP in ways that satisfy both insurers and policyholders remains contentious
- Performance Degradation Coverage: Compensates for attack-induced performance degradation that increases training costs without causing complete failures, recognizing that subtle attacks can be more economically damaging than obvious disruptions
- Fabric Reconstruction Insurance: Covers the enormous costs of completely rebuilding network infrastructure after deep compromises that taint firmware, corrupt configurations, or require hardware replacement to ensure attacker removal
Part IV: Defensive Strategies for the New Threat Landscape
Protecting AI infrastructure from network-level attacks requires defense-in-depth strategies specifically designed for the unique constraints of high-performance networking environments. Traditional security approaches—perimeter defenses, signature-based detection, periodic vulnerability scanning—must be fundamentally adapted for environments where legitimate operations occur at microsecond timescales, where performance overhead from security controls can render systems unusable, and where attacks exploit protocol features rather than software bugs.
Network-Level Defenses
Authenticated Telemetry Systems: Deploy cryptographic authentication mechanisms for all telemetry data that network control systems consume, ensuring that switches and controllers can verify both the source and integrity of telemetry information. Modern approaches use lightweight cryptographic primitives specifically designed for high-speed networking—techniques like Message Authentication Codes (MACs) based on hardware-accelerated AES—that can operate at line-rate speeds without introducing the latency overhead that traditional public-key cryptography would impose.
Anomaly Detection: Implement AI-powered anomaly detection systems that learn the normal traffic patterns, congestion behaviors, and performance characteristics of your specific infrastructure during benign operation. These systems must operate in real-time, analyzing telemetry streams as they arrive and flagging deviations that might indicate attacks. Machine learning models can detect subtle attack signatures that human operators would never notice—unusual correlations between flows, timing patterns that suggest coordination, congestion that doesn't match expected causes—but require careful training on attack-free data and continuous updating as workloads evolve.
Traffic Isolation: Implement strict isolation between different tenants and between different classes of workloads even within single organizations, preventing attacks from one context from affecting others. This isolation includes both logical separation through VLANs, virtual routing instances, and access control policies, and physical separation through dedicated network infrastructure for the most security-sensitive workloads where the cost of separate fabrics can be justified by the risk reduction.
Defense Integration: The most effective and performant defenses integrate security capabilities directly into network hardware rather than relying on external security appliances that create additional latency and complexity. Next-generation switches and network interface cards increasingly include built-in security features—telemetry authentication, anomaly detection accelerators, traffic isolation enforcement—implemented in the same silicon that handles packet forwarding, ensuring security doesn't compromise the performance that justifies the infrastructure investment in the first place.
Application-Level Protections
Model Protection: Implement comprehensive protection for model weights and training data throughout their entire lifecycle, recognizing that the models themselves represent the crown jewels that all other security measures exist to protect. This includes encryption at rest using keys managed in hardware security modules, encryption in transit even across supposedly trusted internal fabrics, granular access controls that limit who can read or modify models, and continuous integrity monitoring that detects unauthorized changes to weights or hyperparameters.
Training Process Security: Ensure that training processes themselves cannot be compromised or manipulated in ways that corrupt models, poison training data, or leak sensitive information through side channels. This includes verifying the cryptographic integrity of training datasets before each epoch, monitoring training metrics for statistical anomalies that might indicate data poisoning or model extraction attacks, and implementing robust checkpointing that enables recovery from detected attacks without losing weeks of training progress.
Zero-Trust Architecture: Implement rigorous zero-trust principles where every component in the training pipeline continuously validates its interactions with every other component, never assuming that network position or prior authentication provides ongoing trust. Components must authenticate and authorize every significant operation. Trust nothing. Verify everything. Even components that communicated successfully moments ago must prove their identity and authorization for each new request, preventing attackers who compromise one component from leveraging that foothold to pivot throughout the infrastructure.
Operational Security Practices
Continuous Monitoring: Deploy comprehensive monitoring systems that go far beyond traditional network metrics like bandwidth utilization or packet loss rates. Monitor congestion control behavior for patterns suggesting manipulation. Track telemetry integrity to detect poisoning attempts. Analyze performance patterns that could indicate security compromises even when no obvious attack signatures appear. The monitoring must operate continuously—attacks that occur during supposedly off-peak hours when fewer eyes watch dashboards can be just as damaging—and must scale to handle the massive telemetry volumes that large AI fabrics generate.
Incident Response: Develop incident response procedures specifically designed for AI infrastructure attacks, recognizing that traditional incident response playbooks focused on malware containment or data breach mitigation may prove inadequate. AI-specific incidents might involve corrupted model weights requiring rollback to earlier checkpoints, compromised network fabric requiring complete reconfiguration, or poisoned training data requiring forensic analysis to determine what portion of training must be discarded. Response teams need specialized training in both AI systems and high-performance networking to make correct decisions under pressure.
Supply Chain Security: Implement rigorous supply chain security measures that reduce the risk of compromised components entering your infrastructure. This includes firmware verification using cryptographic signatures that prove authenticity, hardware authentication mechanisms that validate components came from legitimate sources, secure deployment procedures that prevent tampering during installation, and ongoing integrity monitoring that detects unauthorized modifications after deployment. For the most security-critical deployments, consider additional measures like trusted fabrication sources, physical supply chain security, or even custom silicon designs that reduce dependence on commercial components.
Future-Proofing Security Architecture
AI infrastructure security architectures must evolve continuously to address emerging threats and leverage new defensive technologies. Building flexibility into security systems today prevents tomorrow's threats from requiring complete architectural overhauls.
Quantum-Safe Cryptography: Prepare proactively for the post-quantum era when large-scale quantum computers will break the public-key cryptography that currently protects model weights, authentication systems, and encrypted telemetry. Begin implementing quantum-resistant cryptographic algorithms—lattice-based cryptography, hash-based signatures, code-based encryption—for protecting data that requires long-term confidentiality. While practical quantum attacks remain years away, data encrypted today could be harvested now and decrypted later when quantum computers mature, making the threat immediate for intellectual property with long-lasting value.
Hardware Security Integration: Future network equipment will increasingly integrate security features at the silicon level rather than implementing them as software add-ons that consume CPU cycles and introduce latency. Custom ASICs and programmable network processors can implement cryptographic operations, anomaly detection, and access control enforcement in hardware pipelines that operate at line rate without the performance compromises that software security mechanisms require. Prioritize vendors who demonstrate commitment to hardware security integration in their roadmaps.
AI-Enhanced Defense: Leverage artificial intelligence itself to defend the infrastructure that enables AI development, creating a positive feedback loop where defensive capabilities grow alongside attack sophistication. AI-powered security systems can detect and respond to attacks orders of magnitude faster than human operators, recognizing subtle patterns across billions of network events, predicting attack evolution before it occurs, and automatically implementing countermeasures when milliseconds matter. The same techniques that enable large-scale model training—distributed learning, pattern recognition, anomaly detection—become formidable defensive weapons when pointed at network security challenges.
Part V: Future Implications and Strategic Recommendations
The battle for AI network cluster control will intensify dramatically as AI models become more economically valuable, as dependencies on AI systems deepen across critical infrastructure, and as attack techniques become more sophisticated through the inevitable arms race between attackers and defenders. Organizations building AI capabilities today must prepare for a threat landscape that will continuously challenge traditional security assumptions and require sustained investment in defensive capabilities that evolve as rapidly as the attacks they counter.
Emerging Threat Trends
Nation-State Activity: As artificial intelligence becomes absolutely critical to national competitiveness, economic prosperity, and military capability, nation-state actors will increasingly target AI infrastructure with the resources and persistence that only governments can sustain. These attacks will be extraordinarily well-funded, drawing on decades of signals intelligence expertise and offensive cyber capabilities. They will be sophisticated beyond what commercial attackers can achieve, exploiting zero-day vulnerabilities and supply chain compromises that require nation-state resources. And they will be relentlessly persistent, maintaining presence in target networks for years while exfiltrating intellectual property and positioning for future disruption when geopolitical tensions escalate.
AI-Enhanced Attacks: Attackers will increasingly use artificial intelligence to optimize their own attack strategies in ways that create disturbing feedback loops. Machine learning enables attacks that adapt to defensive measures in real-time, that probe for weaknesses more efficiently than human operators ever could, that blend into legitimate traffic patterns so seamlessly that detection becomes nearly impossible. Adversarial machine learning will generate attack traffic specifically designed to evade AI-powered defenses, creating arms races between attack AI and defense AI that escalate in sophistication faster than human analysts can follow.
Supply Chain Sophistication: Supply chain attacks will become dramatically more sophisticated as attackers recognize that compromising the complex ecosystem of components, firmware, and software required for AI infrastructure provides leverage far exceeding what direct attacks can achieve. Rather than targeting hardened production networks, attackers compromise development environments where firmware gets created, distribution systems where updates get signed, or support vendors who maintain privileged access. These attacks require patience—sometimes years between initial compromise and exploitation—but provide persistent access that survives security audits, penetrates air-gapped networks, and undermines the trust relationships that all security ultimately depends on.
Threat Evolution: The most dangerous future attacks won't rely on single vectors that security tools can isolate and block. Instead, they'll combine multiple attack techniques simultaneously—network manipulation that degrades performance while hardware trojans exfiltrate data and social engineering provides credential access—creating hybrid threats that defeat defense-in-depth by attacking multiple layers simultaneously. Traditional security boundaries between network security, endpoint protection, and insider threat programs will prove inadequate against coordinated attacks that exploit the gaps between security domains.
Technology Evolution
Ultra Ethernet Consortium: The industry effort to create open, standardized, high-performance Ethernet specifications may fundamentally reshape the competitive landscape by reducing vendor lock-in while maintaining the performance that AI training demands. However, this openness also inevitably increases the attack surface by involving more vendors in the ecosystem, creating more implementation variations that might contain vulnerabilities, and establishing more complex standards that create opportunities for specification ambiguities that attackers can exploit. The security implications remain unclear as the standards evolve.
Optical Networking: Future AI fabrics may transition to optical interconnects that provide unprecedented bandwidth by eliminating electronic switching bottlenecks and enabling data transmission at speeds that silicon-based switches cannot match. These photonic networks will require entirely new security models designed specifically for optical domains where attacks might involve optical tapping that's physically undetectable, wavelength manipulation that's invisible to electronic monitoring, or timing attacks that exploit the unique characteristics of photonic switching. The security community must begin preparing for these challenges before optical AI networks become widespread.
Neuromorphic Computing: As neuromorphic processors mature beyond research prototypes into practical deployment, they will require specialized networking architectures that may not fit comfortably into traditional security models designed for von Neumann architectures. Neuromorphic systems' event-driven communication patterns, asynchronous operation, and analog computing elements create unique security challenges that current network security tools aren't designed to address. Early investment in neuromorphic security research will prove crucial as these systems transition from labs to production deployments.
Strategic Recommendations
Security-First Architecture: Design security into AI infrastructure from the very beginning of architectural planning rather than attempting to retrofit protection onto performance-optimized systems after deployment. The cost of integrating authentication, encryption, monitoring, and access control during initial deployment is dramatically lower than remediation after attacks expose vulnerabilities. More importantly, security integrated from the start can leverage hardware acceleration and architectural decisions that become impossible to add later without performance-destroying overhead.
Vendor Risk Assessment: Carefully evaluate the security implications of infrastructure vendor choices, recognizing that decisions made today determine your security posture for many years. Single-vendor solutions offer unified security models with clear responsibility, consistent security updates, and integrated defense mechanisms, but they create dangerous concentration risks where vendor compromise or vendor abandonment of products leaves you exposed. Multi-vendor solutions provide flexibility and reduce single points of failure, but they require sophisticated security integration across vendor boundaries, create gaps where responsibility becomes ambiguous, and complicate security update coordination.
Operational Readiness: Develop security operations capabilities specifically designed for AI infrastructure threats rather than assuming that traditional network security tools and processes will adequately protect against attacks targeting performance optimization mechanisms. This requires hiring or training staff who understand both AI systems architecture and network security, deploying monitoring tools designed for microsecond-scale network operations, and developing incident response playbooks that address AI-specific scenarios like model poisoning, training corruption, or intellectual property exfiltration through network side channels.
Investment Planning: Budget appropriately for AI-specific security tools and expertise, recognizing that these investments will appear expensive when compared to traditional security spending but remain remarkably cheap compared to the assets being protected. A security program costing $5-10 million annually seems expensive until you remember that it protects training runs costing $100-192 million each and intellectual property worth billions. The economics overwhelmingly favor comprehensive security investment over the false economy of inadequate protection that invites catastrophic losses.
Future-Proofing Strategy: The networking infrastructure choices you make today will determine your organization's ability to compete effectively in the AI-driven future that's arriving faster than most strategic plans anticipated. Organizations must balance immediate performance requirements against long-term security needs, operational complexity against flexibility requirements, and cost constraints against risk tolerance, all while preparing for threat landscapes that will evolve in ways we can't fully predict. Success requires treating infrastructure security as a strategic capability rather than a cost center, investing continuously in defensive evolution, and maintaining the flexibility to adapt as both AI capabilities and attack techniques advance.
The Path Forward
The $100 billion battle for cluster control represents just the opening skirmish in a much larger conflict that will define competitive advantage in the AI economy. As AI models become more valuable and attackers become more sophisticated, the organizations that truly understand these challenges and address them comprehensively will maintain decisive advantages over competitors who treat network security as an afterthought. Those that ignore network-level threats or assume traditional security approaches suffice will inevitably become victims of their own infrastructure vulnerabilities, watching helplessly as training runs fail mysteriously, intellectual property leaks to competitors, and expensive infrastructure becomes unreliable.
Success requires much more than writing checks for technology purchases and hoping vendors solve your problems. It demands fundamental shifts in how we think about network security in high-performance environments, in how we structure operational practices around continuous monitoring and threat hunting, and in how we approach risk management for assets worth billions but protected by security models designed for much smaller stakes. The economic and strategic importance of AI infrastructure continues rising relentlessly as AI becomes central to competitive strategy across industries and to national competitiveness in the global economy.
The choice facing organizations is stark and the window for decision narrows daily: invest comprehensively in AI infrastructure security today, accepting the costs and complexity that effective protection requires, or face the inevitable consequences of attacks tomorrow when competitors or adversaries exploit the vulnerabilities that you knew existed but chose not to address. The battle for cluster control will ultimately determine which organizations thrive in the AI economy and which become cautionary tales—examples of how brilliant AI capabilities and massive infrastructure investments can be undermined by network security failures that seemed unlikely until they became inevitable.
Final Insight: The unprecedented convergence of trillion-parameter AI models requiring massive distributed training and sophisticated attack techniques exploiting performance optimization mechanisms creates challenges and opportunities unlike anything the technology industry has previously encountered. Organizations that master both the technical intricacies of high-performance AI networking and the security dimensions of protecting these systems from determined adversaries will define the future of artificial intelligence and capture the enormous economic value that AI leadership provides. The window for making critical architectural decisions continues narrowing as the AI landscape matures with breathtaking speed, making today's choices about infrastructure security potentially decisive for the next decade of competitive positioning.
Example Implementation
# Example: Neural network architecture
import torch
import torch.nn as nn
import torch.nn.functional as F
class SecureNeuralNetwork(nn.Module):
"""Neural network with security features"""
def __init__(self, input_dim, hidden_dim, output_dim):
super(SecureNeuralNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.dropout = nn.Dropout(0.5) # Prevent overfitting
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
# Input validation layer
self.input_norm = nn.BatchNorm1d(input_dim)
def forward(self, x):
# Normalize inputs for security
x = self.input_norm(x)
# Forward pass with dropout
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return F.log_softmax(x, dim=1)