Table of Contents
- Introduction
- Part I: Foundation of Risk
- Part II: Performance Mechanisms as Weapons
- Part III: Impact and Defense
- Comprehensive Attack Taxonomy
Introduction
Picture this. You run a critical AI training job on a shared cluster—thousands of GPUs working in synchronized harmony, processing your proprietary model worth millions in development costs. Everything looks normal. Your monitoring dashboards glow green. Network utilization appears reasonable.
Yet your training crawls.
What you miss: a malicious tenant three racks away weaponizes the very performance mechanisms your cluster depends on, exploiting congestion control protocols, poisoning network telemetry, establishing covert channels through shared hardware—all while flying completely under your security radar.
Critical Security Alert
This isn't science fiction. It's the reality of multi-tenant AI infrastructure right now, unfolding in production environments worldwide as attackers discover that your cluster's performance mechanisms are attack vectors waiting to be exploited.
AI and high-performance computing converged to create specialized network fabrics that prioritize raw speed above everything else. These fabrics—the nervous system of modern AI clusters—achieve ultra-low latency and massive bandwidth through sophisticated protocols like DCQCN, specialized hardware like RDMA-capable NICs, and advanced telemetry systems monitoring every packet's journey through the infrastructure.
But here's the uncomfortable truth nobody discusses openly. These performance-optimized systems carry security assumptions from a bygone era of cooperative, single-tenant supercomputing environments where everyone played by the rules. Layer multi-tenant economic pressures on top of these trust assumptions and you create a perfect storm of vulnerabilities where the very mechanisms enabling AI performance transform into sophisticated attack vectors targeting the foundation of your computational infrastructure.
This analysis examines security architecture challenges facing modern AI fabrics with unflinching precision. We explore how congestion control mechanisms morph into precision weapons, how network telemetry transforms into reconnaissance tools, how shared hardware creates covert communication channels invisible to traditional security monitoring systems.
More critically, you'll discover defensive strategies and emerging technologies capable of securing these complex systems without sacrificing the performance making modern AI possible in the first place.
The Foundation of Risk: Understanding AI Fabric Architecture and Its Trust Assumptions
Your journey toward AI excellence led you down a specific technological path where each decision made perfect sense in isolation. You chose high-speed interconnects for massive parallel processing capabilities. You embraced multi-tenancy for economic efficiency and resource utilization. You designed fabric management protocols optimized for single-user environments where cooperation was assumed.
Yet these choices, reasonable individually, combine to create a security architecture fundamentally misaligned with adversarial realities.
From Proprietary Islands to Open Standards: The Evolution That Introduced Complexity
High-performance interconnects transformed dramatically over the past decade, telling a story of democratization—and unintended consequences that security teams now grapple with daily.
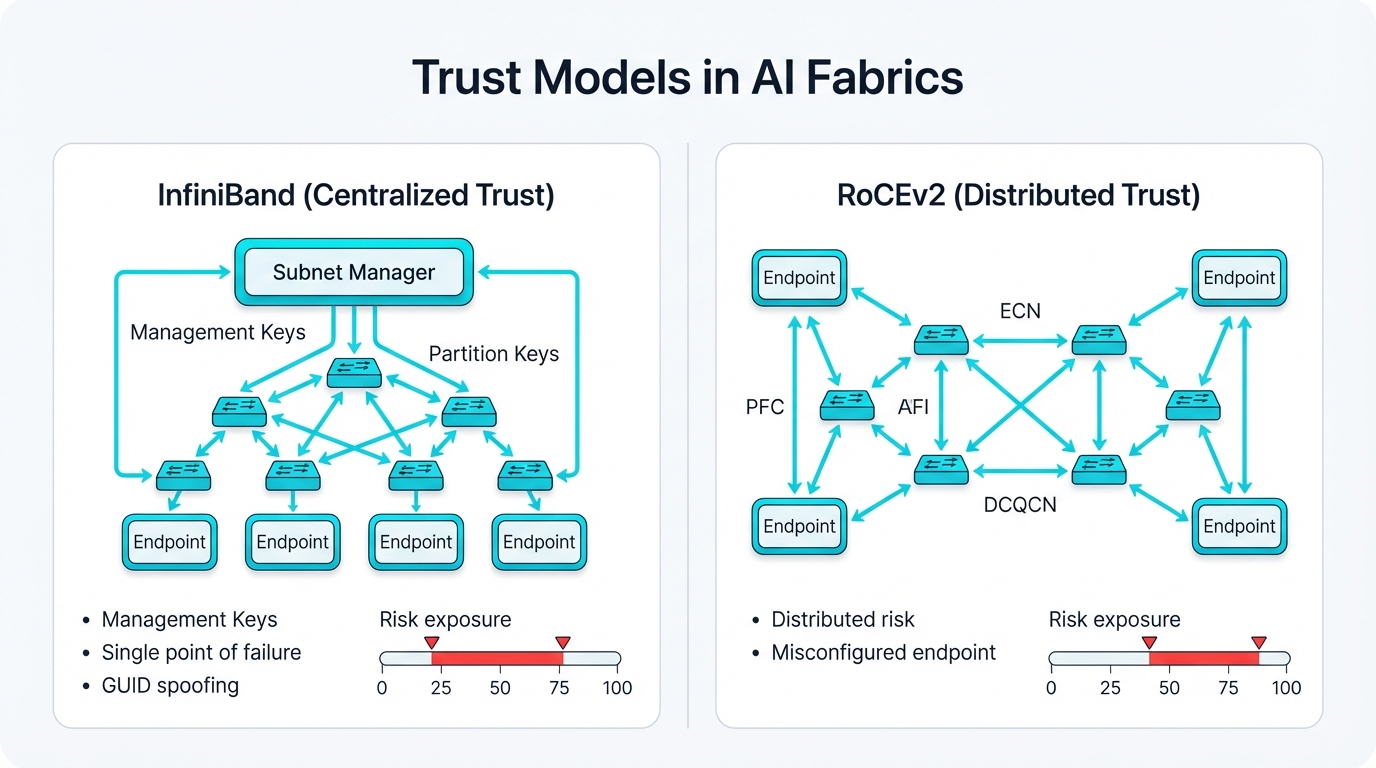
InfiniBand represents the old guard. It delivers everything AI workloads crave: extremely low latency, massive throughput, native Remote Direct Memory Access support moving data with minimal CPU overhead. Security in InfiniBand follows a straightforward model where the Subnet Manager acts as the network's single source of truth, configuring routing, partitioning, and access control across the entire fabric.
This centralization simplifies trust. You trust the SM or you don't have a network.
But InfiniBand costs exceed mere financial considerations. Vendor lock-in limits flexibility and strategic options. Complex host-level software layers handle multi-tenant resource isolation—often inadequately, as security audits repeatedly reveal. When core components fail, the blast radius affects entire fabric sections, taking down massive computational resources in cascading failures.
Enter RoCEv2—RDMA over Converged Ethernet version 2—representing the industry's movement toward open standards and cost efficiency through commodity hardware. Instead of requiring specialized InfiniBand infrastructure with its associated costs and limitations, RoCEv2 delivers RDMA performance over standard Ethernet networks using equipment you already own and understand.
The Challenge: Replicating InfiniBand's "lossless" behavior demands a delicate dance between multiple protocols working in concert. Priority Flow Control provides hop-by-hop pause mechanisms preventing buffer overflow. Explicit Congestion Notification handles end-to-end signaling about network conditions. Data Center Quantized Congestion Notification orchestrates these components into what should be a cohesive system.
This complexity spawns the vulnerabilities we'll explore throughout this analysis, creating attack surfaces that didn't exist in simpler architectural models.
Here's the fundamental tension every AI infrastructure architect faces daily: raw RDMA performance must somehow coexist with robust multi-tenant resource isolation in shared environments. Neither InfiniBand nor standard Ethernet solves this inherently—the architectural approaches simply can't provide both simultaneously without significant engineering effort and security-focused design decisions that often conflict with performance optimization goals.
Multi-Tenancy: Where Economic Logic Collides With Security Reality
Multi-tenancy lets multiple users, teams, or customers share physical infrastructure. The economic incentives prove powerful and difficult to resist. You achieve economies of scale that spreadsheets love. Expensive resources like GPUs and high-performance fabrics reach maximum utilization rates that CFOs celebrate. Multiple independent AI workloads run concurrently, sharing network fabric resources in ways that optimize financial returns.
Yet economics and security rarely align.
The "noisy neighbor" problem emerges first—resource-intensive workloads from one tenant monopolize shared resources, degrading performance for everyone else in ways that SLAs can't adequately capture or compensate. This extends far beyond accidental interference into something more sinister: malicious tenants who understand the system's weaknesses and exploit them deliberately for competitive advantage or destructive purposes.
In hard multi-tenancy environments—public clouds or large enterprises with competing business units—you can't assume cooperative behavior. Consider tenants untrusting and potentially adversarial, because some of them are exactly that.
- Malicious tenants actively disrupt competing workloads to gain advantage in market races or performance benchmarks
- They exfiltrate sensitive data like proprietary models, training datasets, or architectural innovations worth millions
- They manipulate fabric behavior to secure unfair resource allocations or create denial-of-service conditions
Critical Assumption: This threat model demands you assume hostile intent as the baseline security posture, not an edge case to be considered later. Strong, verifiable tenant isolation becomes mandatory at every infrastructure layer—network, compute, storage, memory—or you risk catastrophic security breaches that destroy customer trust and regulatory compliance simultaneously.
The Trust Assumptions That Create Security Gaps
High-performance fabric management and data planes operate on implicit trust models designed for cooperative environments where everyone benefits from collective good behavior. These legacy assumptions create vulnerabilities when applied to adversarial multi-tenancy where some participants actively work against system goals.
InfiniBand: Centralized Trust and Single Points of Catastrophic Failure
InfiniBand embodies centralized trust. The Subnet Manager holds ultimate authority over everything that happens in the fabric. Security relies entirely on SM integrity and proper access control enforcement through Management Keys for configuration changes and Partition Keys for communication isolation between tenants.
These mechanisms provide substantial protection when implemented correctly. But they're not infallible—security audits and penetration tests reveal recurring weaknesses:
- Single Point of Failure: A compromised SM becomes a single point of control for attackers targeting the entire fabric
- GUID Spoofing: Rogue devices spoofing their Global Unique Identifiers to the SM undermine security policies completely
- Key Management Weaknesses: Compromised or weak keys bypass partition isolation trivially, as default configurations often demonstrate
RoCEv2: Distributed Trust Creates Distributed Risks
RoCEv2 fabrics present different challenges entirely. They exhibit distributed trust models introducing distributed risks that multiply rather than divide. Control doesn't flow from a central authority but emerges from cooperative behavior between endpoints—RNICs—and switches throughout the infrastructure. Every device must correctly implement PFC, ECN, and DCQCN protocols consistently, reliably, continuously.
This distributed responsibility creates vulnerabilities attackers exploit. A single misconfigured or malicious tenant endpoint disrupts the entire system's delicate balance, triggering cascading failures that monitoring systems struggle to attribute correctly.
The RDMA Kernel Bypass Paradox
Perhaps the most profound trust assumption lies in RDMA itself, at the very foundation of high-performance AI computing. Offloading the entire network stack to NICs and bypassing the host operating system delivers unparalleled performance that makes modern AI training economically viable.
Yet kernel bypass opposes multi-tenant security principles fundamentally.
Traditional multi-tenant isolation relies on hypervisors or host operating systems mediating access to hardware resources, enforcing security policies at every transaction. RDMA subverts this entire model by design, creating a direct path from application to hardware that bypasses the security controls operating systems provide.
Security Paradox: RDMA's performance-enabling feature—the kernel bypass that makes it valuable for AI workloads—simultaneously makes it inherently insecure in shared environments without specialized hardware-aware defenses that most deployments lack entirely.
When Performance Mechanisms Become Weapons: Exploiting Congestion Control
Congestion control algorithms maintain network stability and ensure fair resource allocation under heavy load conditions that AI workloads create constantly. Their complexity in lossless RDMA fabrics creates sophisticated attack surfaces that malicious actors weaponize with devastating effectiveness. They don't just manipulate these algorithms for unfair advantage—they transform them into precision weapons for targeted denial-of-service attacks, bandwidth starvation campaigns, and widespread performance degradation affecting entire data centers.
The weapons already exist in your network, waiting to be fired.
The Fragile Dance of RoCEv2: When PFC, ECN, and DCQCN Turn Adversarial
RoCEv2 networks achieve lossless transport through precise orchestration of three technologies working in concert. Priority Flow Control, Explicit Congestion Notification, and Data Center Quantized Congestion Notification were designed to prevent network collapse through cooperative behavior where all participants work toward system stability.
Their complex interplay weaponizes when cooperation stops.
Inside the Mechanism: How DCQCN Balances Network Forces
Understanding vulnerabilities requires understanding mechanics at the protocol level. Think of these protocols as a three-way conversation designed to prevent network meltdown through continuous feedback and adjustment.
Priority Flow Control—defined in IEEE 802.1Qbb—provides link-level, hop-by-hop flow control on specific traffic classes. When switch ingress buffers for PFC-enabled priority classes exceed predefined thresholds that network engineers configure, switches transmit PAUSE frames to immediate upstream neighbors, commanding them to halt transmissions for specific priority classes for set durations measured in microseconds, preventing buffer overflow and packet drops that would devastate RDMA performance.
Explicit Congestion Notification—specified in RFC 3168—provides more granular, end-to-end signaling about network conditions. Instead of pausing entire links indiscriminately, ECN-capable switches mark packets with Congestion Experienced bits in IP headers when egress queue depths surpass configured thresholds. When marked packets reach destinations, receiving NICs send Congestion Notification Packets back to original senders, informing them about path congestion conditions they should respond to by reducing transmission rates.
DCQCN connects these mechanisms through a three-party protocol involving the sender—called Reaction Point or RP—switch—called Congestion Point or CP—and receiver—called Notification Point or NP. DCQCN uses ECN as an early warning system for proactive congestion management rather than reactive crisis response. Upon receiving CNPs indicating congestion, sender NICs reduce injection rates using carefully tuned algorithms designed to maximize throughput while minimizing congestion.
The Fatal Flaw: This elegant system assumes all participants act in good faith toward collective stability goals. That assumption breaks catastrophically in adversarial environments where economic incentives or malicious intent drive behavior instead.
Attack Vector: Weaponizing PFC for Cascading Network Collapse
PFC's brute-force nature creates the primary vulnerability malicious tenants exploit with devastating effectiveness and minimal resource investment. The attack methodology proves both simple to execute and catastrophic in impact, requiring only basic understanding of protocol mechanics and network topology.
PFC operates on entire priority classes, not individual flows—a design choice that made sense for simplicity but creates security nightmares. Attackers craft traffic weaponizing this mechanism deliberately. They trigger PAUSE frames halting not just their own traffic, but innocent victim tenant traffic sharing the same priority queues throughout the network fabric.
The attack scales catastrophically through several mechanisms:
- Head-of-Line Blocking: Single malicious flows stall numerous benign workloads competing for the same resources
- PFC Storms: PAUSE frames propagate backward through networks hop by hop, switch by switch, creating cascading congestion
- PFC Deadlocks: Cyclic buffer dependencies create permanent traffic gridlock requiring human intervention to resolve
Attack Vector: The LoRDMA Precision Strike
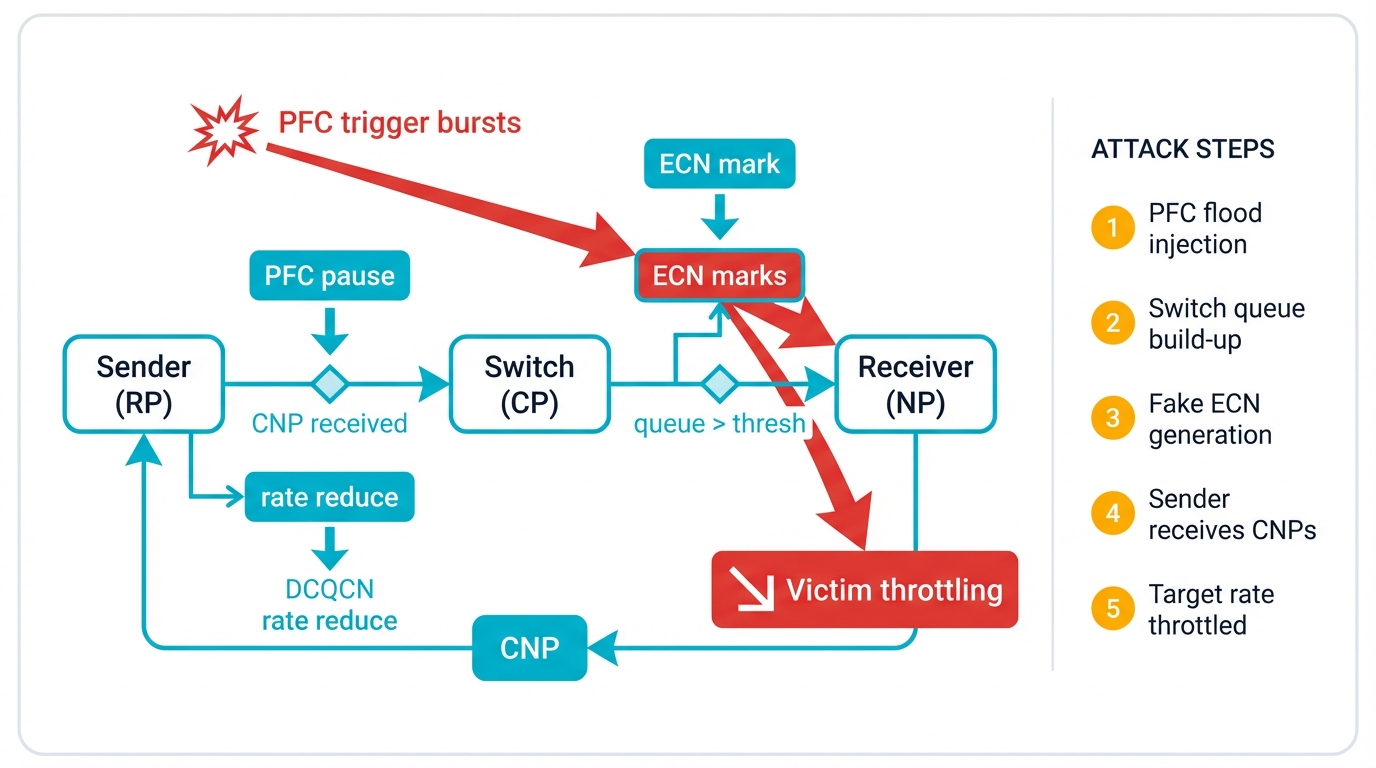
The most sophisticated attacks exploit emergent behavior from multiple control system interactions creating vulnerabilities that individual protocol analysis can't predict. LoRDMA—Low-rate DoS in RDMA—weaponizes the PFC-DCQCN interplay for highly effective, stealthy denial-of-service campaigns operating nearly invisible to traditional monitoring infrastructure.
LoRDMA represents multi-step attack choreography hijacking network control loops with surgical precision:
- Step 1: PFC Triggering - Attackers use compromised nodes sending short, intense, line-rate traffic bursts to targeted switch egress ports
- Step 2: Congestion Propagation - PFC PAUSE frames travel to immediate upstream switches, causing egress queue buildup there
- Step 3: DCQCN Deception - DCQCN algorithms observe queue buildup without knowing downstream PFC backpressure causes it
- Step 4: Victim Throttling - ECN-marked packets reach destinations, triggering CNPs back to victim senders who reduce rates
- Step 5: Asymmetric Recovery - Attackers cease bursts instantly, but DCQCN's recovery takes 60+ milliseconds—creating windows for repeated attacks
Force Multiplication: Real-world simulations demonstrate that as few as 2% of network nodes—just a handful of compromised endpoints in a large cluster—can degrade nearly all network flows by 53% and NCCL collective communication operations by 18-56%, effectively crippling distributed AI training workloads worth thousands of dollars per hour.
InfiniBand: When Centralized Control Becomes a Single Point of Failure
InfiniBand's centralized architecture presents different attack surfaces than Ethernet's distributed model. Rather than exploiting distributed protocol interactions across many devices, attacks focus on subverting central authority—the all-powerful Subnet Manager—or manipulating the routing mechanisms it controls throughout the fabric.
Attack Vector: Traffic Engineering for Competitive Advantage
Adaptive Routing improves overall performance by dynamically selecting paths based on current network conditions. But it enables sophisticated manipulation by malicious tenants who understand how routing decisions get made. These actors control multiple endpoints strategically positioned throughout the fabric and generate carefully crafted traffic patterns intentionally congesting specific network paths while leaving others clear.
The attack exploits AR's reactive nature. By creating artificial hotspots through coordinated traffic bursts, attackers trick Adaptive Routing algorithms into diverting other tenants' traffic onto suboptimal routes with higher latency or lower bandwidth, securing competitive advantage in shared resource environments.
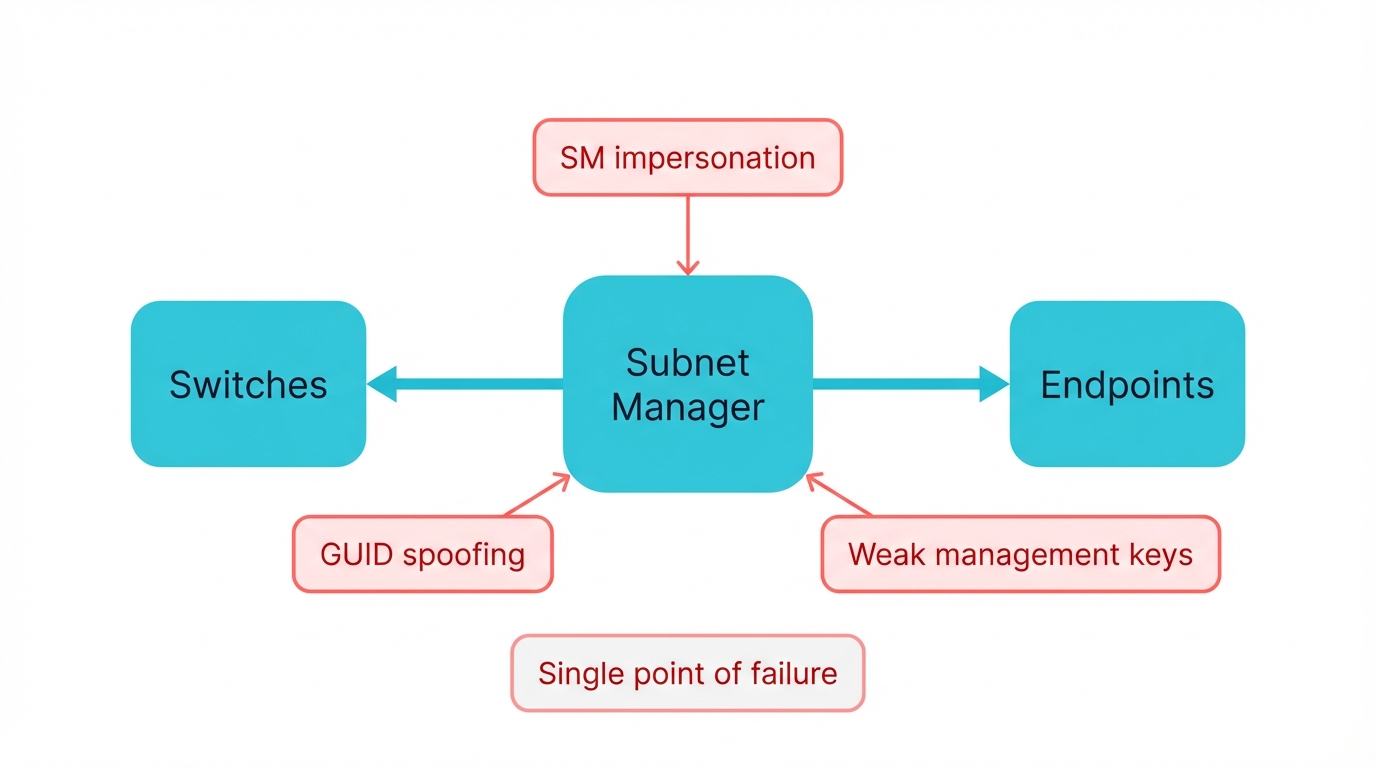
Attack Vector: Compromising the Crown Jewels
The ultimate InfiniBand attacks target the Subnet Manager itself or bypass key-based security entirely through several attack vectors:
- Subnet Manager Impersonation: Spoofing legitimate SM identities or injecting malicious Subnet Management Packets that reconfigure the fabric
- GUID Spoofing: Programming malicious devices to report legitimate victim GUIDs, impersonating authorized endpoints
- Key Management Weaknesses: Exploiting weak or misconfigured Management Keys that default configurations often leave vulnerable
The Double-Edged Sword: When Network Telemetry Becomes an Attack Platform
Network telemetry—collecting measurement data from network devices—provides essential capabilities for performance monitoring, troubleshooting complex issues, and resource management in AI fabrics spanning thousands of devices. These operational visibility streams transform into potent adversarial tools when viewed through a security lens that considers hostile actors as participants rather than theoretical threats.
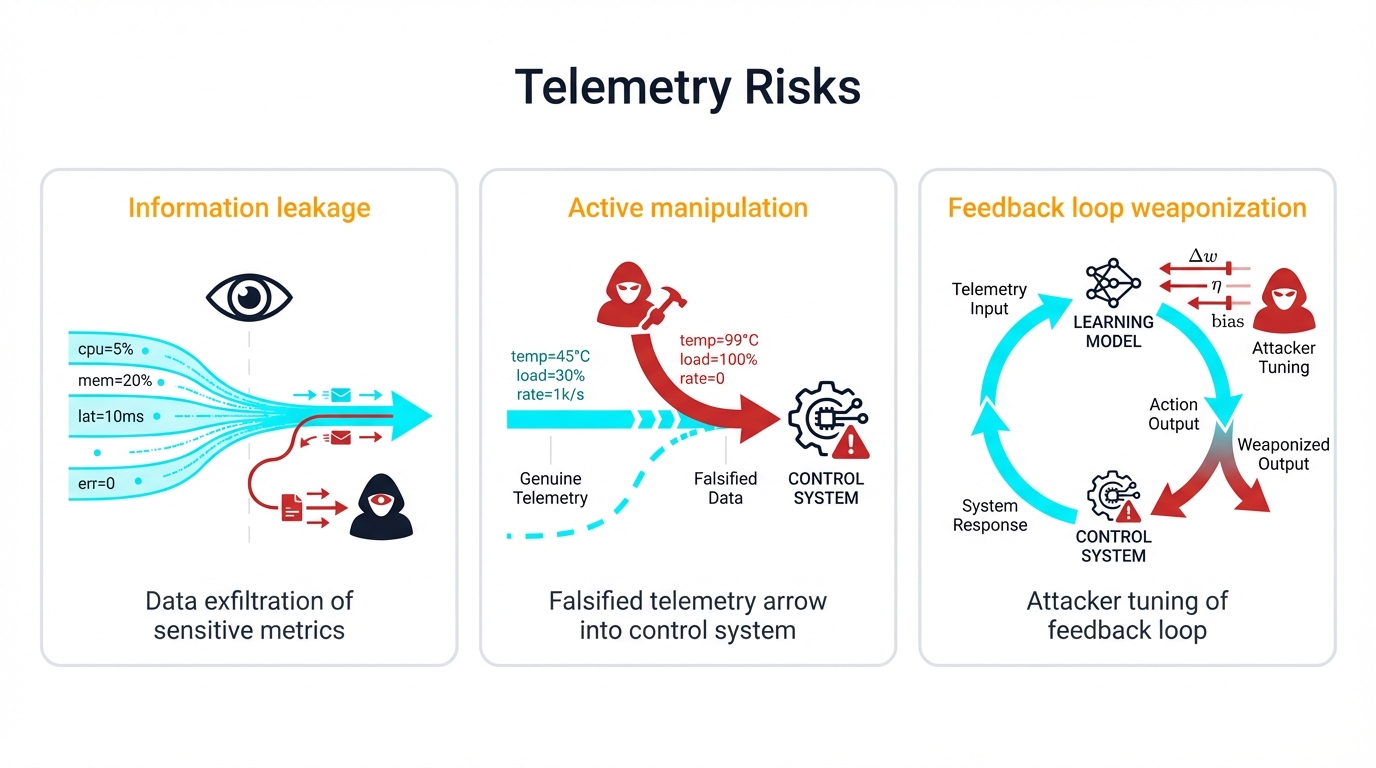
Attackers don't just consume telemetry passively for reconnaissance purposes. They actively manipulate it to deceive control systems or leverage it as high-fidelity feedback for orchestrating sophisticated attacks with surgical precision against specific targets.
Reality Check: Your monitoring infrastructure becomes their weapon, and your investment in visibility capabilities directly funds attacker reconnaissance and attack optimization capabilities you never intended to provide.
The Information Leakage Problem: When Monitoring Reveals Too Much
Even correctly functioning telemetry systems inadvertently leak valuable information about tenant activity patterns, workload characteristics, and infrastructure topology. This creates significant confidentiality and operational security risks in multi-tenant environments where competitors or adversaries share the same physical infrastructure.
Sampling-Based Intelligence: Reading the Tea Leaves of Network Traffic
sFlow samples packet header information at regular intervals configured by network administrators, exporting these samples to central collectors for analysis and visualization. This scalable approach suits high-speed networks perfectly—but at a significant cost to security.
Sampled headers lack full payload data—that's encrypted and protected. But they contain rich metadata including source and destination IP addresses, port numbers, protocol information, packet sizes, and timing data that reveals patterns and correlations across the fabric.
In multi-tenant settings where adversaries access or intercept telemetry streams through compromised monitoring systems or shared dashboards, this metadata becomes competitive intelligence worth far more than its collection cost.
Analyzing communication patterns systematically, attackers build detailed "signatures" of victim tenant AI workloads:
- Architectural Inference: Source and destination IP patterns reveal distributed training job topology, parameter server locations, data pipeline structure
- Workload Phase Detection: Traffic volume fluctuations betray current phase of AI jobs—data loading, forward pass, backward pass, gradient synchronization
- Model Fingerprinting: Different neural network architectures generate unique communication fingerprints attackers correlate with known models
Timing Side-Channels: The Precision Weapon of Latency Analysis
Side-channel attacks leverage information leakage through non-functional system properties that designers never intended as communication channels. In shared network fabrics, malicious tenants actively probe network paths or shared resources while precisely measuring response latency with microsecond accuracy using standard tools.
This technique extracts highly sensitive AI workload information with surgical precision that encryption can't prevent:
- Leaking Input Data Attributes: Response times correlate with input data characteristics like text length or image complexity
- Leaking LLM Responses: Packet size sequences correspond to token sizes being transmitted in encrypted channels
Research Finding: By feeding token length sequences extracted from encrypted network traffic into language models trained on public datasets, researchers successfully reconstructed 29% of AI assistant responses word-for-word and correctly inferred response topics 55% of the time—all without breaking encryption protocols or violating TLS security properties at all.
Active Manipulation: When Telemetry Becomes a Control System
Security risks escalate dramatically when telemetry transitions from passive observation of network conditions to active network control influencing traffic management decisions. In-band Network Telemetry represents this fundamental shift—and its lack of inherent security mechanisms creates direct opportunities for malicious fabric behavior manipulation.
The INT Revolution: Per-Packet Network Visibility
INT provides revolutionary per-packet visibility into data plane operations with granularity traditional monitoring can't match. As packets traverse the network along their forwarding paths, INT-capable switches append metadata blocks to packet headers automatically in hardware at line rate. These blocks contain switch identifiers, ingress and egress port information, timestamps with nanosecond precision, and critically, current queue occupancy levels revealing congestion conditions.
When packets reach destinations, receiving systems strip the metadata "trails" automatically, aggregate the reports, and send them to telemetry collectors for analysis. This provides complete hop-by-hop records of the exact path each packet took through the fabric and the precise conditions it encountered at every switch along that path.
Attack Vector: Poisoning the Data Stream
Standard INT implementations suffer from a critical vulnerability that deployment guides rarely acknowledge. They lack authentication and integrity protection for packet telemetry data flowing through the network. Malicious on-path actors—attackers compromising switches or network devices—intercept packets, modify their INT metadata fields arbitrarily, and forward them normally toward destinations.
This enables "telemetry poisoning" attacks with devastating impact. Attackers forge congestion signals by artificially inflating queue_depth or hop_latency values in victim packet INT headers before forwarding them. When advanced congestion control algorithms like HPCC—High Precision Congestion Control—receive these forged reports, they interpret them as evidence of severe network congestion requiring immediate response.
Critical Impact: Attackers feed false data directly into network control loops through carefully poisoned telemetry, corrupting the reactive behavior of congestion management systems designed to optimize performance but now weaponized to degrade it instead.
Attack Vector: Masking Malicious Activity Through Spoofing
The inverse attack proves equally insidious and harder to detect through statistical analysis. Attackers launching genuine congestion attacks can simultaneously use their on-path positions or compromised devices to modify their own packet INT data in real-time, setting queue_depth fields to zero and hop_latency to minimal values that suggest perfect network conditions.
This "cleans" the telemetry trail, making the network appear healthy to monitoring systems despite ongoing attacks degrading performance dramatically. Operational staff relying on telemetry dashboards for situational awareness see no indication of problems, delaying or preventing effective responses until customer complaints or SLA violations force manual investigation.
The Feedback Loop Weaponization: Turning Monitoring Into Attack Optimization
Modern telemetry's detailed performance data becomes a high-value asset for adversaries planning sophisticated campaigns rather than opportunistic attacks. Attackers seeking to conduct efficient campaigns need precise models of network behavior including topology understanding, traffic pattern analysis, switch buffer characteristics, and control algorithm response characteristics.
sFlow and INT provide this data with unparalleled granularity unavailable through external observation. Malicious tenants passively collect this information over hours or days to train what researchers call "adversarial network twins"—machine learning models simulating fabric behavior with high fidelity matching production systems.
These digital twins enable attackers to discover optimal attack strategies offline through simulation and experimentation. They determine the precise timing, rates, target selection, and coordination patterns for attacks like LoRDMA before launching perfectly tuned campaigns against live systems with predictable outcomes.
Defense Paradox: The defensive monitoring infrastructure you invested in transforms into a powerful offensive reconnaissance and weaponization platform funding attacker capability development. Every improvement in telemetry granularity and accuracy simultaneously improves attack precision and effectiveness—creating an arms race where defenders inadvertently arm attackers.
Breaking Boundaries: Cross-Domain Attacks and Covert Communication
The most sophisticated threats to shared AI fabrics transcend traditional security boundaries entirely, operating across multiple domains simultaneously. They exploit interactions between network protocols, hardware microarchitecture, and software systems to create novel attack vectors bypassing conventional network-centric defenses that monitor packets but miss the real channels attackers use.
These cross-domain attacks establish covert channels for stealthy data exfiltration—particularly dangerous in environments handling sensitive AI models and proprietary training data worth millions to competitors.
The Hidden Battlefield: Shared Hardware Microarchitecture
Network-level Quality of Service mechanisms aim to provide performance isolation between tenants through bandwidth allocation and priority queuing. But they remain completely blind to a critical battleground operating beneath network abstraction layers: the internal microarchitecture of shared Remote Network Interface Cards processing traffic for multiple tenants simultaneously.
When multiple tenants share physical RNICs through virtualization or time-slicing, they share far more than network bandwidth. They directly contend for finite on-chip resources including command processing queues, memory translation caches, protection domain lookup tables, and internal communication buses connecting NIC components.
This shared microarchitecture creates potent attack surfaces invisible to traditional monitoring systems watching network traffic. Malicious tenants craft specific RDMA operation sequences designed not to maximize network throughput legitimately, but to intentionally exhaust internal RNIC resources affecting co-resident tenants.
Dramatic Impact: Academic research demonstrates scenarios where victim tenants received guaranteed allocations of 50 Gbps bandwidth that network-level QoS enforced perfectly. Well-behaved workloads from other tenants had no measurable impact on these performance guarantees. Yet malicious tenants launching carefully designed attack streams consuming just 1 Gbps—a tiny fraction of available bandwidth—plummeted victim throughput to as low as 2 Gbps, a 96% reduction violating performance guarantees catastrophically.
Establishing Invisible Communication: Covert Channels in High-Speed Fabrics
Covert channels exploit shared media not intended for information transfer to transmit data clandestinely between parties who shouldn't be able to communicate. In high-performance computing environments, any shared resource exhibiting contention becomes potentially modulatable by senders and observable by receivers, enabling bit encoding and decoding through careful timing and resource manipulation.
RDMA-Based Covert Channels: The Bankrupt Attack
The Bankrupt attack demonstrates sophisticated cross-node RDMA covert channels operating entirely within memory subsystems, bypassing network monitoring completely. In this attack, senders—malicious spies—and receivers operate as completely separate, non-communicating tenants that both establish RDMA connections to third intermediary machines they don't control directly.
Both parties allocate private memory regions on these intermediary systems through normal RDMA APIs. Through careful reconnaissance using timing measurements and statistical analysis, attackers discover memory addresses within their allocated regions mapping to the same physical DRAM banks as addresses in the receiver's memory region—a side-channel leak from memory controller behavior.
The attack mechanism operates with elegant simplicity:
- Transmit '1' bit: Senders barrage RDMA requests to bank-mapped addresses, causing memory bank contention visible as latency
- Transmit '0' bit: Senders remain idle, allowing normal memory access patterns
- Receive: Receivers continuously probe their own bank-mapped addresses while measuring access latency with microsecond precision
This establishes high-bandwidth, clandestine communication channels completely bypassing all sender-receiver network firewalls, monitoring systems, and isolation mechanisms that security teams rely on.
NVLink-Based Covert Channels: GPU-to-GPU Stealth Communication
NVLink's proprietary GPU-to-GPU interconnect creates another powerful covert channel medium often overlooked in security assessments. In multi-tenant environments, workloads from different tenants running on different server GPUs share the same NVLink fabric infrastructure connecting GPUs within servers and sometimes across servers in NVSwitch topologies.
Attackers exploit this shared bus contention to transmit information between supposedly isolated GPU domains assigned to different tenants. Research demonstrates practical covert channels achieving up to 70 Kbps bandwidth—sufficient for exfiltrating model parameters, hyperparameters, or training data over time.
The timing channel mechanism works with elegant simplicity. Senders transmit '1' bits by executing cudaMemcpyPeer() operations over NVLink, creating measurable bus contention affecting other GPU-to-GPU transfers. They transmit '0' bits by remaining idle. Receivers on other GPUs continuously time small memory copy operations between their own GPU memory spaces, observing latency variations caused by sender activity.
PCIe-Based Covert Channels: Exploiting System Bus Contention
Even the PCIe buses connecting GPUs and NICs to host CPUs become exploitable for covert communication through contention analysis. Multiple devices sharing PCIe switches—a common configuration in dense GPU servers—create opportunities for traffic congestion analysis revealing activity patterns.
Attackers operating on one device—such as RDMA NICs they control legitimately—infer victim process activity on other devices—such as GPUs processing sensitive workloads—by measuring the latency of their own PCIe operations with microsecond precision.
Attack Chain Synthesis: From Reconnaissance to Exfiltration
Individual attack vectors prove powerful when used alone, but sophisticated adversaries chain them together into multi-stage campaigns maximizing impact while evading detection through careful operational security. Consider this plausible attack lifecycle targeting proprietary AI models in shared infrastructure:
- Stage 1: Reconnaissance - Passively collect network telemetry data over days to map topology and identify high-value victims running large training jobs
- Stage 2: Weaponization - Build offline network models—"adversarial twins"—simulating the target environment with high fidelity, testing attack strategies safely
- Stage 3: Disruption and Degradation - Launch low-and-slow disruptive campaigns using LoRDMA attacks timed to maximize business impact during critical training phases
- Stage 4: Exfiltration and Command & Control - Activate covert channels through RDMA memory contention for stealthy model parameter theft and attack coordination
Defense Challenge: This synthesized attack chain highlights the inadequacy of siloed defense strategies that treat network security, host security, and hardware security as separate concerns. Network traffic volume monitoring solutions completely miss low-rate DoS attacks and covert channel communications operating through contention. Host-based security systems miss network protocol exploitation and hardware-level attacks targeting shared microarchitecture.
Understanding the Stakes: How Network Attacks Devastate AI Workloads
Network attacks against AI infrastructure create tangible, severe consequences for workload performance, operational costs, and computational correctness—not abstract security concerns relegated to compliance checkboxes. The synchronized, communication-intensive nature of distributed AI training makes these systems exceptionally vulnerable to network degradation caused by congestion abuse and telemetry manipulation that traditional enterprise applications tolerate easily.
The Achilles' Heel: Collective Communication Sensitivity
Distributed training—the cornerstone of modern large-scale AI development—relies heavily on collective communication operations that synchronize state across hundreds or thousands of accelerators. These primitives including AllReduce, Broadcast, and All-to-All enable groups of GPUs to exchange and synchronize data in coordinated fashion essential for producing accurate models.
AllReduce operations dominate. They aggregate gradients calculated by individual GPUs across the entire cluster, producing globally updated models reflecting learning from all training data. These operations typically block execution—no GPU can proceed to the next training iteration until all GPUs complete their communication phases and reach synchronization barriers.
Critical Vulnerability: This synchronous nature makes AI workloads acutely vulnerable to network jitter—packet delay variation measured in microseconds. High average latency proves detrimental to training throughput, but high jitter often causes even more catastrophic damage to training performance and convergence properties.
In collective operations involving hundreds or thousands of GPUs working together, overall operation completion time depends entirely on the last-arriving packets in the communication pattern. Single delayed network flows to any one GPU create "stragglers" forcing all other GPUs in the collective operation to remain idle at synchronization barriers, wasting expensive compute cycles and electricity.
Real-world benchmark results produce stark evidence of this sensitivity that should concern every AI infrastructure team:
- Baseline (0 microseconds jitter): 12.0 minutes completion time for standard training workload
- 20 microseconds jitter: 18.4 minutes—53% performance degradation from tiny network variation
- 50 microseconds jitter: 31.1 minutes—159% performance degradation making training economically infeasible
- 100 microseconds jitter: Unstable convergence leading to training failures producing no usable model
Parallelization Strategy Vulnerabilities: Different Targets, Different Sensitivities
Different approaches to large model training parallelization exhibit unique sensitivities to network degradation, creating diverse attack targets for sophisticated adversaries who understand these architectural differences.
Data Parallelism: The All-Reduce Bottleneck
Data parallelism represents the most common approach where each GPU maintains a complete copy of the model while processing different subsets of training data in parallel. After completing forward and backward passes for training steps, gradients must synchronize across all GPUs using high-bandwidth AllReduce operations aggregating updates.
This gradient exchange phase creates the primary communication bottleneck limiting linear scaling performance as cluster size grows. Attacks introducing fabric congestion or latency directly impact these critical communication paths, slowing every single training iteration proportionally.
The mathematical relationship proves unforgiving. If gradient synchronization takes twice as long due to network attack, training takes twice as long—there's no buffering or asynchronous processing to hide the impact or amortize costs over time.
Model and Pipeline Parallelism: The Pipeline Bubble Problem
When models grow too large for single GPU memory—increasingly common with trillion-parameter models—they get partitioned across multiple devices through model parallelism. Each GPU becomes responsible for different layers or model segments, creating computational pipelines with sequential data flow between stages connected by network links.
These communication patterns are primarily point-to-point between adjacent pipeline stages rather than collective operations, but they're highly latency-sensitive to microsecond variations. Delays or jitter between any pipeline stages create "pipeline bubbles"—periods where downstream stages stall while waiting for delayed data from upstream stages, creating idle GPU time that represents pure waste.
Parameter Server Architectures: Centralized Vulnerability
In parameter server architectures, centralized servers maintain authoritative copies of model parameters serving as coordination points. Worker nodes compute gradients from their data subsets and send them to parameter servers, which aggregate updates and return new parameters to workers for the next iteration.
Network links connecting to parameter servers become natural chokepoints in these architectures representing single points of failure. Attackers focus congestion attacks on these specific links to create system-wide performance bottlenecks affecting all workers simultaneously—force multiplication through architectural understanding.
The Economics of Attack: From Performance Degradation to Business Impact
Direct Financial Costs
AI infrastructure costs get measured in GPU-hours, making training delays translate directly into wasted resources and increased operational expenses appearing on quarterly reports. Even minor 3-5% jitter-induced performance delays amount to thousands of dollars in additional cloud computing bills for large training runs spanning weeks.
Consider the scale of modern AI development. GPT-3 training reportedly consumed an estimated 355 GPU-years of computation at massive financial cost. A conservative 5% network-induced performance delay would represent nearly 18 additional GPU-years of wasted resources—creating non-trivial financial and environmental costs that shareholders and regulators increasingly scrutinize.
Convergence Failure Risks
Severe or prolonged network degradation doesn't just slow training—it can prevent models from converging to accurate solutions entirely, wasting all invested resources. High timing variability experiments show that extreme jitter levels—100+ microseconds—lead to unstable training dynamics causing processes to stall or fail completely without producing usable models.
Critical Insight: The result isn't just slower training that completes eventually—it's failed training that produces no usable model despite consuming significant computational resources, electricity, and engineering time. Months of work disappear because network security was treated as a separate concern from AI infrastructure reliability.
The Reliability Assumption Problem
Reliable, high-performance network behavior gets baked into AI model design and training software architectures as a fundamental assumption. Communication libraries like NVIDIA Collective Communications Library—NCCL—assume near-perfect, lossless transport with minimal error recovery capabilities because recovery mechanisms hurt performance.
When network attacks introduce packet loss or severe delays exceeding designed tolerances, they trigger failure modes AI applications can't handle gracefully or recover from automatically. Traditional distributed systems design for network failures as normal conditions—AI systems design for network perfection as the baseline assumption.
Building Fortress Networks: Defensive Architectures and Mitigation Strategies
Defending shared AI fabrics against sophisticated cross-layer attacks demands multi-faceted strategies extending far beyond traditional network security approaches focused on perimeter defense and traffic filtering. Robust defensive architecture must harden fabric infrastructure against manipulation attempts, secure telemetry data streams against poisoning, and proactively detect anomalous behavior patterns indicating attacks in progress.
Critical Reality: No single defense suffices against the attack vectors we've examined throughout this analysis. Success requires defense-in-depth approaches specifically designed for the unique challenges of high-performance, multi-tenant AI environments where performance requirements often conflict with security controls that traditional enterprise networks implement routinely.
Hardening the Foundation: Advanced Isolation and Quality of Service
First-line defenses enforce performance isolation directly within network fabrics, ensuring that tenant actions—whether malicious or simply resource-intensive—cannot unfairly impact other users' operations through congestion or resource exhaustion.
The Limitations of Traditional QoS in High-Speed Environments
Quality of Service manages network resources through foundational traffic classification and policy enforcement mechanisms network engineers configure. Traffic gets classified into priority levels with specific policies governing guaranteed minimum bandwidth allocations or enforced maximum transmission rates preventing resource monopolization.
Where Traditional QoS Succeeds: Standard QoS mechanisms effectively provide coarse-grained fairness, preventing simple resource monopolization attacks where individual tenants attempt to saturate network links with high-volume traffic floods easily detected by rate monitoring.
Where It Fails: Current RDMA hardware QoS capabilities prove fundamentally insufficient for true multi-tenant security isolation in adversarial environments. RDMA NICs support minimal numbers of hardware-enforced virtual lanes or priority queues—typically up to 15 in InfiniBand implementations. This inadequately provides fine-grained per-tenant isolation in cloud environments serving hundreds or thousands of infrastructure-sharing tenants competing for resources.
Advanced Isolation Models: Learning from Research
Academic researchers have proposed sophisticated RDMA performance isolation models recognizing and addressing traditional QoS limitations through innovative approaches:
Justitia: This software-based, end-host solution intercepts RDMA commands before they reach hardware and applies intelligent scheduling algorithms achieving better flow isolation between latency-sensitive and bandwidth-sensitive applications sharing infrastructure. Justitia significantly improves both latency and throughput characteristics for well-behaved applications, requiring no hardware modifications for deployment in existing infrastructure.
Harmonic: This hardware/software co-design approach directly addresses microarchitectural attack vectors through programmable intelligent PCIe switches positioned between host CPUs and RNICs. Harmonic systems monitor internal RNIC resource usage on a per-tenant basis with microsecond granularity, while software components repurpose RNIC built-in rate limiting capabilities to provide fine-grained performance isolation that hardware alone can't achieve.
Future Direction: The future of AI fabric security lies in programmable hardware solutions—intelligent NICs and switches that can enforce security policies and monitor behavioral patterns directly within data paths at line-rate speeds without performance penalties that software enforcement imposes.
Securing Information Flows: Authenticated Telemetry and Encrypted Control Planes
Countering telemetry manipulation and control message attacks requires cryptographic protection of data streams throughout their lifecycle from generation to consumption.
Authenticated Telemetry: Preventing Data Poisoning
INT poisoning threats where attackers modify in-flight telemetry data require authentication and integrity protection mechanisms operating at line rate. Research efforts like SecureINT propose lightweight Message Authentication Codes using algorithms like SipHash to generate cryptographic tags for INT metadata blocks that switches append to packets.
These systems can be implemented efficiently in programmable switch data planes using languages like P4, enabling line-rate integrity verification without significant performance overhead or increased latency. While this approach successfully prevents tampering attacks by detecting modifications, it requires deployment of new hardware capabilities and doesn't address the fundamental problem of passive information leakage from legitimate telemetry data that authorized parties collect.
Preventing Passive Data Leakage
Defending against passive information leakage requires fundamentally different approaches than integrity protection against active attacks. Multi-tenant environments need strict logical separation of telemetry streams preventing cross-tenant visibility, tenant-specific encryption keys for sensitive data protecting confidentiality, and robust access control mechanisms with fine-grained permissions limiting who can view what telemetry data.
AI-specific risks have spawned emerging gateway solutions that inspect prompts and responses in real-time, detecting and redacting sensitive information like personal data or proprietary information before potential leakage occurs through side channels or logging systems.
Proactive Defense: AI-Driven Behavioral Anomaly Detection
Stealthy modern attack techniques necessitate proactive, behavior-based defensive approaches that identify threats before they cause catastrophic damage. AI-driven anomaly detection systems use machine learning models to establish baselines of "normal" network behavior under various conditions, automatically flagging significant deviations as potential security threats requiring investigation.
Detection Capabilities: These systems can potentially identify novel zero-day attacks that signature-based systems miss entirely and low-and-slow campaign patterns that evade traditional threshold-based detection systems focused on volume anomalies.
The Double-Edged Challenge: AI-based detection systems create their own vulnerabilities that attackers exploit. High false positive rates cause security team alert fatigue, reducing overall security effectiveness as teams learn to ignore alerts. More concerning, defensive AI systems become high-value targets for adversarial attacks designed to blind detection capabilities through carefully crafted traffic that looks normal to models but enables malicious activity.
Redesigning Core Protocols: Secure Congestion Control Algorithms
Forward-looking defensive strategies involve redesigning fundamental congestion control mechanisms to incorporate inherent security features and manipulation resistance rather than bolting security onto existing vulnerable protocols.
AI-Driven Network Management
Emerging research applies artificial intelligence and machine learning not just for detecting anomalies, but for actively managing network operations in real-time. These systems create predictive congestion control mechanisms anticipating traffic hotspots based on historical patterns and real-time telemetry analysis, proactively rerouting traffic or adjusting transmission rates before congestion develops into performance problems.
Potential Benefits: Truly proactive, intelligent congestion control offers superior performance characteristics compared to reactive systems responding to problems after they occur. These approaches can potentially be trained to recognize and automatically isolate malicious traffic patterns through learned behavioral models, providing integrated security and performance optimization that traditional systems can't match.
Implementation Challenges: The field remains in its infancy from a deployment perspective despite promising research results. Building and validating the complexity of these systems represents an immense engineering challenge requiring expertise spanning networking, machine learning, and security domains simultaneously.
The Defense-in-Depth Imperative
Robust AI fabric defensive postures cannot rely on any single solution approach regardless of how advanced that solution appears. Defense-in-depth strategies combining multiple complementary security layers are mandatory, but simply layering multiple defenses proves insufficient against sophisticated adversaries who study defensive architectures to find gaps.
Key Insight: Defense effectiveness depends not just on individual component strength measured in isolation, but on the security properties of component interactions and emergent system behaviors that integration creates—the whole must be greater than the sum of its parts or attackers will exploit the seams between components.
The Bleeding Edge: Security Challenges in Next-Generation Interconnects
As AI workloads continue their exponential growth in scale and complexity, underlying network fabrics evolve rapidly to meet escalating performance demands. The industry transition to 400 Gbps, 800 Gbps, and 1.6 Tbps Ethernet coupled with new memory-semantic interconnects like NVLink and Compute Express Link promises unprecedented performance levels enabling breakthrough AI capabilities.
But next-generation technologies amplify existing security risks while introducing entirely new vulnerability paradigms that current security models can't adequately address.
Ultra-High-Speed Ethernet: When Faster Becomes More Fragile
Evolution to higher-speed Ethernet isn't merely incremental bandwidth increases—it fundamentally changes physical and logical properties of network systems with profound security implications that architects must consider.
Amplified Physical Layer Vulnerabilities
At 224 Gbps per lane and beyond, signal integrity becomes absolutely paramount for reliable data transmission across copper or optical media. System sensitivity to electrical jitter, electromagnetic noise, and crosstalk increases dramatically as signal-to-noise ratios approach fundamental physical limits imposed by Shannon's theorem.
This heightened sensitivity makes previously infeasible subtle, low-level physical attacks practical as error-inducing or side-channel attack vectors exploiting electromagnetic emanations.
Shrinking Reaction Windows
A critical trend in switch hardware design creates new attack opportunities that protocols can't fully compensate for. Buffer memory capacity doesn't scale proportionally with link bandwidth due to cost and power constraints. Buffer-to-link-speed ratios steadily decrease as speeds increase, creating more brittle network behavior with less resilience to traffic bursts.
Mathematical Reality: When buffer depth remains constant but link speed increases 8x from 100 Gbps to 800 Gbps, attack windows shrink by the same factor—attackers need to trigger conditions 8x faster, but defenders also have 8x less time to detect and respond to attacks before buffers overflow and packets drop.
Memory-Semantic Fabrics: Blurring the Security Boundaries
Beyond traditional Ethernet evolution, emerging interconnect technologies blur traditional boundaries between networking, memory access, and computation, creating unified memory-semantic fabrics where load and store instructions transparently access remote resources.
Compute Express Link: Revolutionary Performance, Revolutionary Risks
CXL represents a revolutionary open standard enabling cache-coherent memory sharing between CPUs, accelerators, and memory devices over high-speed fabric connections that look like memory to applications.
Built-in Security Features: CXL 2.0 includes robust security capabilities addressing known threats, notably Integrity and Data Encryption—IDE. CXL.mem and CXL.cache traffic receives FLIT-level 256-bit AES-GCM encryption, providing comprehensive confidentiality, integrity, and replay protection against on-path snooping and data manipulation attacks at the physical layer.
New Attack Surfaces: Despite IDE protection preventing eavesdropping, CXL introduces substantial new avenues for performance-based attacks that encryption can't prevent. CXL devices sharing critical resources like memory controllers with host CPU DRAM create significant opportunities for interference-based attacks affecting both performance and availability.
Research using real CXL hardware demonstrates that contention between CXL devices and main memory can cause up to 93.2% performance degradation for CXL-dependent applications through carefully orchestrated memory access patterns.
The Semantic Gap Vulnerability
Memory-semantic fabrics create what security researchers term "semantic gap" vulnerabilities between application intent and network enforcement capabilities. Traditional network security mechanisms like firewalls and deep packet inspection systems operate by examining well-defined network packets with IP headers, TCP sessions, and application protocols they understand.
In CXL-based fabrics, application load and store instructions transparently translate into CXL.mem protocol packets at the hardware level below operating system visibility. Network security appliances lack the application context necessary to distinguish between benign and malicious memory access patterns targeting sensitive data structures.
Critical Open Research Questions
The evolving AI fabric threat landscape presents fundamental open research questions that must be addressed for next-generation secure, high-performance infrastructure supporting trillion-parameter models.
Holistic Cross-Layer Security Models
Current security approaches remain largely siloed, focusing independently on network security, host security, or hardware security isolation without considering interactions. The convergence of networking, memory, and compute in AI fabrics demands new unified security models encompassing entire AI workload data paths from storage through network to accelerator memory.
Verifiably Secure Control Planes
LoRDMA attacks demonstrate how vulnerabilities emerge from unexpected interactions between well-intentioned protocol components that testing didn't anticipate. The security community needs formal verification approaches applied to combined PFC, ECN, and congestion control systems that can mathematically prove freedom from exploitable emergent behaviors rather than relying on testing alone.
Practical Covert Channel Mitigation
Most existing timing-based and storage-based covert channel defenses impose performance overhead that proves prohibitive for latency-sensitive AI fabric environments where microseconds matter. Urgent research needs focus on developing low-overhead, practical mitigation techniques that real-world deployments can actually implement without destroying the performance AI workloads require.
Confidential Computing for Distributed AI
Confidential computing using hardware Trusted Execution Environments protects sensitive data from compromised host operating systems through hardware-enforced isolation. However, current approaches focus on single-node protection within individual servers.
The challenge lies in creating "distributed TEEs" protecting AI model data and parameters not just at rest in storage or during single CPU processing, but throughout fabric transit and during remote shared GPU computation across clusters.
The Autonomous Security Arms Race
As network complexity increases beyond human management capacity, defenders increasingly turn to AI-powered anomaly detection and self-managing network systems handling operational complexity automatically. Inevitably, attackers will employ AI techniques to devise sophisticated, stealthy attacks adapting to defensive countermeasures in real-time.
Recursive Challenge: Securing AI fabrics becomes inseparable from broader AI system security challenges, creating recursive security problems where AI systems must secure AI systems—a philosophical and practical challenge that the industry has barely begun to address systematically.
Design Principles for Future-Secure AI Fabrics
Future AI fabric architectures must treat security as a foundational design principle rather than an afterthought or add-on capability bolted onto performance-optimized systems. The increasing convergence of networking and memory systems, shrinking control loop response times measured in nanoseconds, and growing sophistication of adversaries demand paradigm shifts toward hardware-rooted, formally verified, and holistically designed security solutions that consider interactions from the start.
The era of retrofitting security onto performance-optimized systems is ending whether we're ready or not. The next generation of AI infrastructure must be secure by design, performant by architecture, and resilient by default—or it simply won't survive contact with adversaries who understand these systems at least as well as the engineers who built them.
Comprehensive Attack Taxonomy: Understanding the Threat Landscape
| Attack Class | Specific Vector | Target Component | Required Access | Primary Impact | Detection Difficulty | Research Status |
|---|---|---|---|---|---|---|
| Congestion Manipulation | LoRDMA | PFC/ECN/DCQCN | Co-resident Tenant | Targeted DoS, Performance Degradation | Low (appears as normal bursts) | Active Research |
| Intentional PFC Deadlock | PFC Buffer Dependencies | Multi-endpoint Control | Complete Fabric Lockup | Medium (mimics hardware failure) | Demonstrated | |
| RNIC Resource Exhaustion | NIC Microarchitecture | Shared Host Access | Severe Performance Impact | Very Low (minimal bandwidth usage) | Academic Proof-of-Concept | |
| Information Warfare | sFlow Traffic Analysis | Network Monitoring | Telemetry Access | IP Theft, Competitive Intelligence | Minimal (legitimate monitoring) | Industry Concern |
| INT Data Poisoning | In-band Telemetry | On-path Access | Control System Manipulation | Low (requires deep inspection) | Emerging Threat | |
| Side-Channel Exploitation | LLM Token Length Analysis | TLS Packet Patterns | Network Observation | Content Reconstruction | Statistical Detection Only | Published Research |
| ADNN Timing Analysis | Response Latency | Query Access | Input Attribute Inference | Statistical Detection Only | Academic Study | |
| Covert Communication | NVLink Bus Contention | GPU Interconnect | Multi-GPU Host | Model IP Exfiltration | Undetectable (hardware noise) | Research Demonstration |
| RDMA Bankrupt Channel | Memory Bank Sharing | RDMA Access | Data Exfiltration | Undetectable (bypasses network monitoring) | Academic Publication | |
| PCIe Bus Analysis | System Interconnect | Device Access | Process Activity Inference | Undetectable (system noise) | Research Publication |
This taxonomy reveals sophistication and diversity of attack vectors facing modern AI fabrics in stark detail. Notice how the most dangerous attacks—those with highest impact and lowest detectability—target hardware and protocol layers where performance optimizations create security blind spots that monitoring systems can't see and traditional defenses can't protect.
Key Insight: The pattern is clear and undeniable. As AI systems push the boundaries of performance to achieve breakthrough capabilities, they inevitably push the boundaries of attackable surface area in ways that create entirely new security challenges. The future belongs to those who can secure these systems without sacrificing the performance making modern AI possible—a challenge that demands fundamental rethinking of security architecture rather than incremental improvements to existing approaches.
Conclusion
Security challenges facing multi-tenant AI fabrics represent one of the most complex and urgent problems in modern computing infrastructure. As we've explored throughout this analysis, performance optimizations enabling breakthrough AI capabilities simultaneously create sophisticated attack surfaces that traditional security models can't adequately address through standard perimeter defenses and traffic monitoring.
High-speed networking, specialized hardware, and economic pressures toward multi-tenancy converged to create a perfect storm. From LoRDMA attacks weaponizing congestion control protocols to covert channels exploiting shared microarchitectural resources, the attack landscape proves both diverse and deeply technical—requiring security expertise spanning networking, hardware architecture, and AI system design simultaneously.
Perhaps most concerning, these attacks often operate below detection thresholds of conventional monitoring systems while causing severe performance degradation and security breaches. The stealthy nature of modern fabric attacks combined with their potential for massive force multiplication makes them particularly dangerous for organizations operating critical AI infrastructure supporting business-critical workloads or competitive advantage.
However, this analysis also reveals a path forward through the complexity. By understanding fundamental mechanisms underlying these vulnerabilities at protocol and hardware levels, we can design defensive architectures addressing security at the foundational level rather than as an afterthought bolted onto finished systems. The future of AI fabric security lies in hardware-rooted, formally verified solutions treating security as a first-class design constraint equal in importance to performance optimization and cost efficiency.
Key Takeaways for AI Infrastructure Teams:
- Assume Adversarial Multi-Tenancy: Design security models accounting for hostile, sophisticated attackers as baseline threat, not edge case
- Monitor Cross-Layer Interactions: Traditional network monitoring proves insufficient—security must span hardware, protocols, and applications simultaneously
- Invest in Hardware-Aware Security: Software-only solutions can't address microarchitectural attack vectors targeting shared resources
- Plan for Emergent Behaviors: Protocol interactions create vulnerabilities that individual component analysis can't reveal through testing
- Prepare for Next Generation: Memory-semantic fabrics and ultra-high-speed interconnects will amplify existing challenges exponentially
The race between attackers and defenders in AI fabric security is just beginning—we're in the early innings of a long game. Those who understand these challenges today and invest in principled, defense-in-depth approaches will be best positioned to secure the AI infrastructure of tomorrow when attacks become more sophisticated and widespread. The stakes involving security of some of humanity's most valuable intellectual property and computational resources could not be higher—failure means compromised models, stolen data, and destroyed competitive advantage.
Understanding these attacks isn't just academic exercise for security researchers—it's the foundation for building defensive architectures protecting the next generation of AI infrastructure from sophisticated adversaries who understand that the network has become the battlefield where competitive advantage gets won or lost.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score