Critical Security Alert
Critical Security Risk
AI fabric vulnerabilities lead to complete infrastructure compromise—every single time you ignore the warning signs, cascading failures ripple through your systems in ways you never anticipated, destroying millions in training investments before you even notice the attack unfolding beneath the surface.
Recent CVE-2025-4287 Impact: This vulnerability targets PyTorch's NCCL implementation in RoCE fabrics. Specifically. Directly. Organizations using AI fabrics must assess their exposure to timing manipulation attacks immediately—not tomorrow, not next quarter, but right now before attackers exploit the microsecond-level windows that make these systems so devastatingly vulnerable to coordinated precision strikes.
Criminals used deepfakes to steal $25.6 million from Arup in 2024.
They exploited human psychology. But the next wave of AI attacks? It goes deeper—much, much deeper into the infrastructure itself.
These attacks target the fabric, the specialized networks that make modern AI possible, and when they fail, consequences cascade through entire organizations in ways most security teams never anticipated or planned for in their traditional threat models.
The Great Network Divide: Why AI Changed Everything
Large-scale AI created something unprecedented. A fundamental split.

AI fabric networks aren't just faster enterprise networks or bigger pipes—they represent a complete paradigm shift, engineered from first principles for unforgiving computation that tolerates zero deviation from perfect synchronization across thousands of processing nodes operating in perfect harmony.
Think about your typical corporate network for a moment. It handles email. File transfers. Web browsing. Thousands of small, independent tasks that come and go randomly, each one operating on its own timeline without caring what happens to the packets traveling beside it through the switching fabric.
Some packets can wait.
Others take alternate routes, and the network adapts and recovers gracefully, using statistical probability to ensure that most traffic gets through most of the time without anyone noticing the occasional retry or slight delay in transmission.
Now imagine a different world entirely—a world where every microsecond counts and every packet matters.
In AI fabrics, thousands of GPUs synchronize their computations down to the microsecond, and when a single delayed packet doesn't just slow one process but cascades through an entire training run worth millions of dollars in compute time, you start to understand why these networks demand perfection in ways that would seem absurd to traditional network engineers.
When NVIDIA's latest H100 clusters communicate, they're not just moving data—they're orchestrating a distributed supercomputer where every component depends on every other component in real-time, creating a choreography so precise that even the smallest timing deviation destroys the entire performance envelope.
Network Security Reality Check
Traditional vs. AI Fabric Requirements: Enterprise networks tolerate 30-40% packet loss through retransmission. AI training jobs? They start failing catastrophically at just 0.01% loss rates—a 1000x stricter requirement that transforms the entire security landscape and renders traditional network monitoring approaches completely blind to the timing attacks that devastate distributed training operations.
This shift transforms networks fundamentally, evolving them from simple connectivity providers into integral components of distributed supercomputers where understanding the design philosophy, specialized hardware, unique topologies, and traffic patterns becomes prerequisite knowledge for anyone attempting to secure these environments against the unique, amplified vulnerabilities they face.
The numbers tell the story.
Traditional enterprise networks operate with latency tolerance measured in milliseconds. AI fabrics demand microsecond precision—a thousand times stricter. Enterprise networks handle 30-40% packet loss gracefully through retransmission, but AI training jobs start failing catastrophically at just 0.01% loss rates, creating a reliability requirement that most traditional network infrastructure simply cannot meet no matter how much you optimize or tune the underlying protocols.
Beyond Best-Effort: Why Traditional Network Paradigms Crumble Under AI Demands
Traditional networks evolved over decades. They handle one specific traffic pattern.
High-entropy mixes of small, short-lived, asynchronous flows create what network engineers call "mice and elephants" traffic—millions of independent user requests, database queries, and microservice API calls that generate statistically predictable randomness, randomness that network designers learned to leverage through statistical multiplexing that makes efficient use of expensive network infrastructure.
This approach works brilliantly for cost efficiency. You oversubscribe links knowing that not every user will download large files simultaneously. You build in redundancy assuming that temporary congestion won't break critical applications. The entire architecture embraces probabilistic thinking where "good enough" performance satisfies most use cases most of the time.
But AI workloads shatter these assumptions.
Completely. Utterly. Without mercy.
The Synchronization Imperative
When you deploy large language models at scale, you encounter barrier synchronization patterns where every GPU in a training cluster must complete its computation portion before any GPU can proceed to the next step, creating a lockstep coordination that makes the entire cluster only as fast as its slowest component.
This creates traffic patterns that look nothing like traditional network flows—patterns that violate every assumption built into conventional network design over the past forty years of networking research and development.
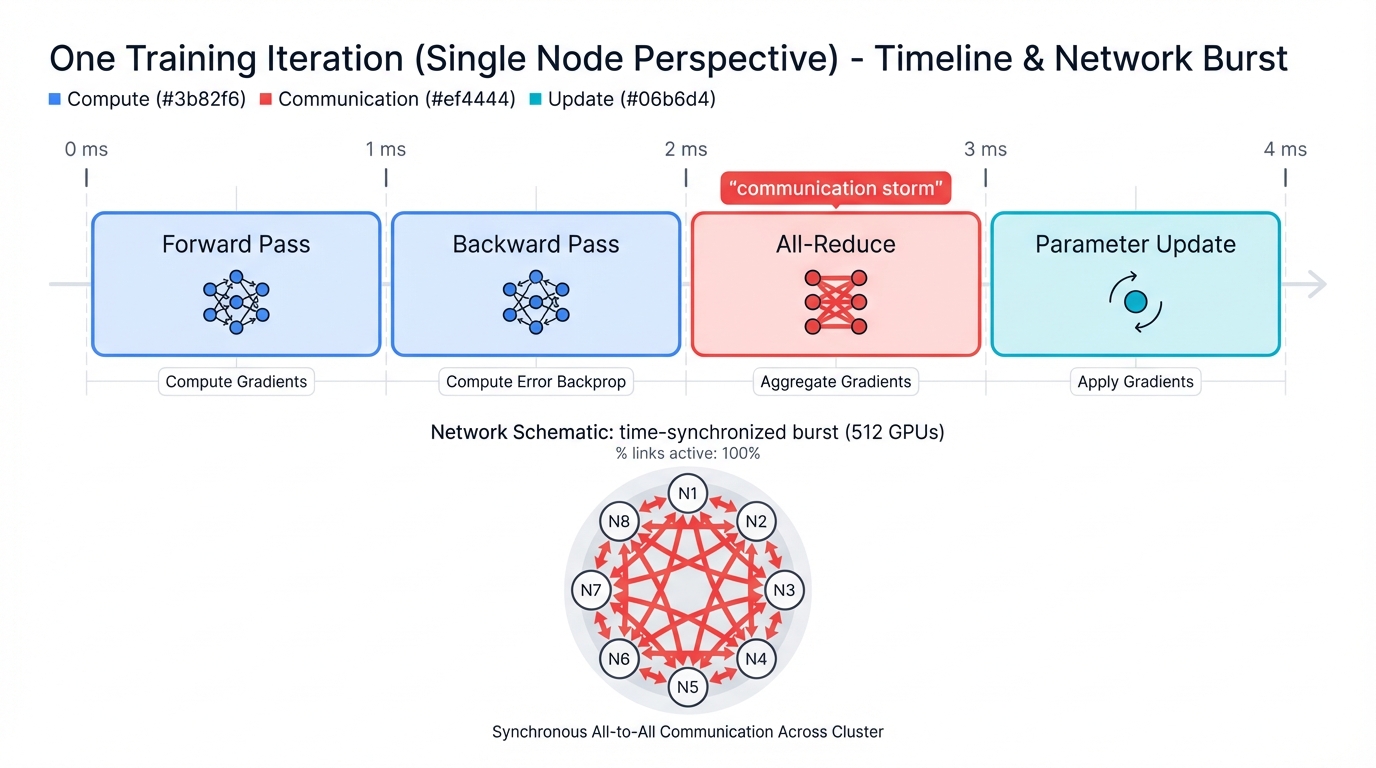
Consider a typical training iteration on a 512-GPU cluster running GPT-4 scale models, where the computational choreography unfolds in precisely timed phases:
- Forward Pass: All GPUs compute activations simultaneously
- Backward Pass: Gradients flow back through the network
- All-Reduce Communication: Every GPU must share its gradients with every other GPU
- Parameter Update: All GPUs update their model weights simultaneously
Attack Vector Alert: Communication Storms
Synchronization Vulnerability: During all-reduce phases, networks experience time-synchronized communication storms. Every node communicates with every other node. Simultaneously. Traditional security controls designed for random traffic patterns become completely ineffective against coordinated timing attacks that exploit the mathematical precision required for gradient synchronization across thousands of processing nodes.
During the all-reduce phase, networks experience communication storms—instead of random, distributed traffic, you get highly coordinated bursts, time-synchronized bursts where every node communicates with every other node simultaneously, creating traffic patterns that look more like a carefully orchestrated symphony than the random noise that traditional networks expect.
Traditional networks built for statistical multiplexing collapse under this load. The statistical assumptions break down. When traffic becomes perfectly correlated rather than randomly distributed, all the clever optimization techniques that worked for decades suddenly fail in spectacular and expensive ways.
Latency Amplification Effects
Here's where AI fabrics reveal their true brittleness, their fundamental vulnerability to even microscopic timing deviations.
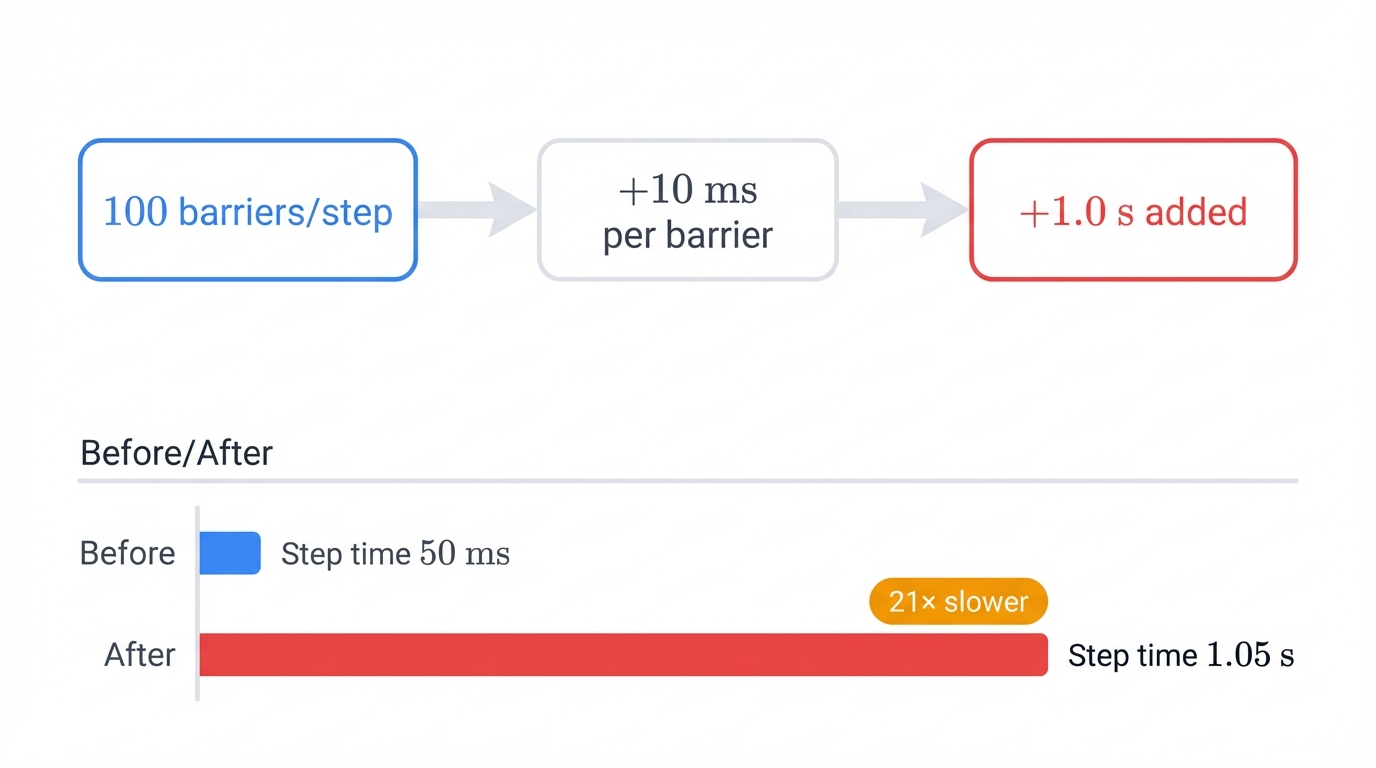
In traditional networks, adding 10 milliseconds to a web request creates minor user degradation—maybe a slightly longer page load that most users won't even notice. In AI training, that same delay gets amplified through every synchronization point, multiplying across hundreds or thousands of coordination events until small inefficiencies become catastrophic performance failures.
A modern transformer model might perform 100 synchronization barriers per training step. If each barrier adds 10 milliseconds due to congestion, your training step transforms from 50 milliseconds to 1.05 seconds—a 21x slowdown that transforms a 2-week training job into a 10-month ordeal that costs millions in additional compute time and potentially destroys your competitive window for model deployment.
This amplification effect explains why AI engineers obsess over network latency in ways that seem extreme to traditional IT professionals who are accustomed to measuring performance in human-perceptible units rather than the microsecond precision that distributed training demands.
Traffic Pattern Evolution
AI workloads also create entirely new traffic categories. Traditional network designs never anticipated these patterns. Never planned for them. Never built mechanisms to handle them efficiently.
Collective Communication Patterns: All-reduce, all-gather, and reduce-scatter operations generate highly structured, predictable traffic that can overwhelm traditional switching fabrics designed for the random patterns of human-driven applications where users click, browse, and download in unpredictable sequences that spread load naturally across network infrastructure.
Memory Bandwidth Patterns: Modern AI models exceed single-GPU memory limits. They require constant streaming of model parameters and activations across the fabric, creating sustained, high-bandwidth flows that persist for hours rather than the bursty patterns traditional networks expect, flows that monopolize network resources in ways that traditional quality-of-service mechanisms struggle to manage effectively.
Fault Intolerance: Unlike web applications that gracefully degrade with packet loss, AI training jobs exhibit cliff effects—small increases in network errors cause complete training failure, not gradual performance degradation but sudden catastrophic collapse that wastes all the compute invested up to the failure point.
Economic Impact Data
Stanford & NVIDIA Research (2024): Network inefficiencies alone increase AI training costs by 40x compared to optimal conditions. This isn't just about performance or engineering elegance—it's about economic viability and competitive survival in AI-driven markets where being second to deploy a breakthrough model means capturing a fraction of the market value that the first-mover claims.
According to research from Stanford and NVIDIA in 2024, network inefficiencies alone increase AI training costs by 40x compared to optimal conditions—forty times more expensive, not because of hardware costs or electricity prices, but purely due to network performance problems that traditional monitoring tools often fail to detect until massive amounts of compute time have already been wasted.
Architectural Foundations: The Hardware Reality Behind AI Fabrics
Understanding AI fabric vulnerabilities requires diving deep into specialized hardware ecosystems that make these networks possible.
This isn't just about faster switches. Bigger cables. More bandwidth.
Every component gets redesigned from silicon up to meet demands that traditional networking hardware simply cannot handle, demands that push the boundaries of what's physically possible within the constraints of current semiconductor technology and the laws of physics governing electromagnetic signal propagation.
Silicon-Level Innovations
Modern AI fabrics rely on specialized switching chips that operate fundamentally differently from traditional networking ASICs—Broadcom's Tomahawk 5 and NVIDIA's Spectrum-4 represent different approaches to the same challenge of moving massive amounts of data with microsecond-level precision while maintaining perfect reliability.
Traditional Ethernet switches use store-and-forward architectures with deep packet buffers to handle traffic bursts, buffers designed to smooth out the random variations in network load that characterize human-driven applications where traffic arrives in unpredictable patterns determined by user behavior rather than algorithmic precision.
AI fabric switches eliminate most buffering to minimize latency. They accept the trade-off that congestion causes immediate performance degradation rather than graceful queuing, choosing low latency over the fault tolerance that traditional networks prioritize.
Critical Vulnerability: Buffer Exhaustion Attacks
Silicon-Level Security Risk: With minimal buffering available in AI fabric switches, even small amounts of malicious traffic cause immediate packet drops. Drops that cascade into training job failures. Traditional DDoS protection becomes ineffective against precision timing attacks that exploit the minimal buffering to create synchronized disruptions across the entire fabric topology.
This architectural choice creates the first major vulnerability category in AI fabrics: buffer exhaustion attacks that exploit the minimal buffering available to cause immediate packet drops, drops that cascade into training job failures far more severe than the original attack traffic volume would suggest based on traditional network engineering principles.
InfiniBand vs. Ethernet: The Great Divide
The choice between InfiniBand and Ethernet for AI fabrics represents more than vendor preference—it reflects fundamental security trade-offs that most organizations don't fully understand when they make purchasing decisions based primarily on performance benchmarks and upfront hardware costs.
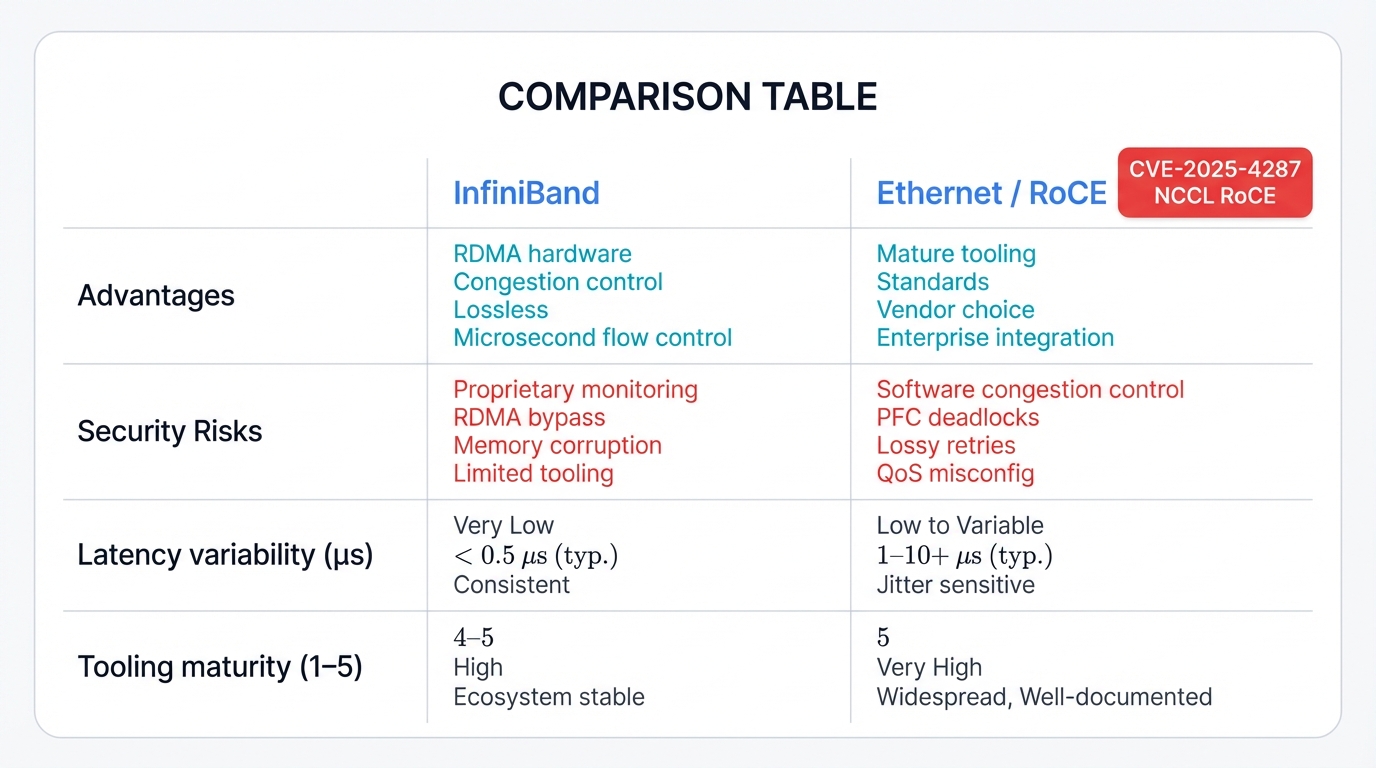
InfiniBand Advantages:
- Hardware-accelerated RDMA eliminates CPU overhead
- Built-in congestion control prevents network-level cascading failures
- Lossless fabric ensures no packet drops under normal conditions
- Hardware-level flow control provides microsecond response times
InfiniBand Security Vulnerabilities:
- Proprietary protocols complicate security monitoring and intrusion detection
- RDMA bypasses traditional operating system security controls
- Direct memory access creates potential for memory corruption attacks
- Limited security tooling compared to mature Ethernet ecosystems
Ethernet with RoCE:
- Leverages mature Ethernet security tooling and monitoring
- Standards-based protocols enable better security integration
- More vendor choices prevent vendor lock-in scenarios
- Better integration with existing enterprise security infrastructure
Ethernet/RoCE Security Challenges:
- Software-based congestion control introduces latency variability
- Priority Flow Control can be exploited to create network-wide deadlocks
- Lossy network behavior requires complex retry mechanisms
- Quality of Service configuration errors create attack vectors
CVE-2025-4287: Real-World Impact
PyTorch NCCL Vulnerability: The 2024 emergence of CVE-2025-4287 demonstrates how protocol choice impacts vulnerability patterns in ways that become apparent only after production deployment at scale, when this exploit specifically targeted RoCE's flow control mechanisms to disrupt distributed training jobs, causing millions in compute cost overruns for affected organizations who learned the hard way that performance benchmarks don't capture security risks.
The 2024 emergence of CVE-2025-4287 demonstrates how protocol choice impacts vulnerability patterns—it affected PyTorch's NCCL implementation, and the exploit specifically targeted RoCE's flow control mechanisms to disrupt distributed training jobs, causing millions in compute cost overruns for affected organizations who discovered too late that their fabric choices created exploitable attack surfaces.
Topology Considerations: Fat-Tree vs. DragonFly
AI fabric topology selection creates distinct vulnerability profiles. Security teams must understand these. Plan for them. Design defenses around them.
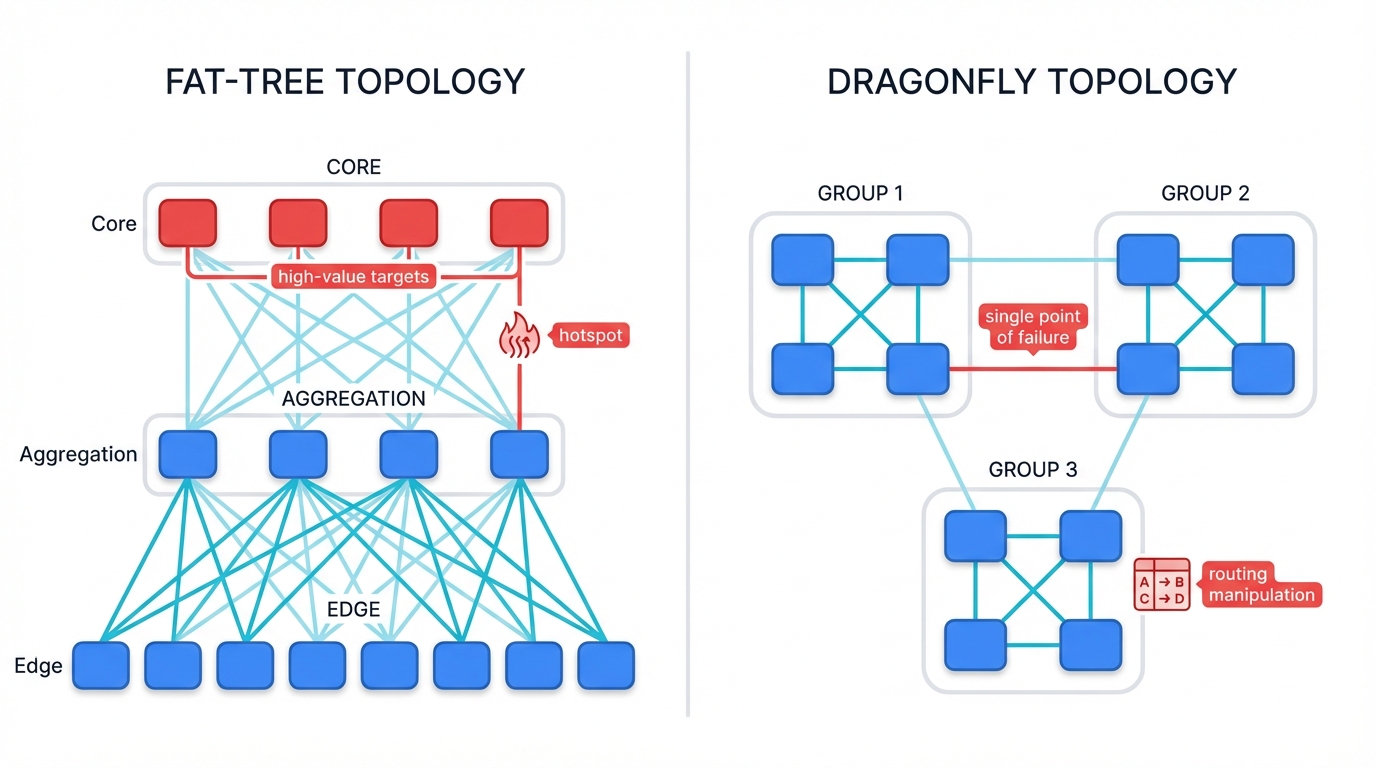
Fat-Tree Topologies provide multiple paths between any two nodes, offering redundancy and load distribution that traditional network engineering principles favor for fault tolerance and performance optimization, but they create adversarial routing opportunities where attackers can manipulate traffic flows to create congestion hotspots that overwhelm specific links while leaving others underutilized.
The hierarchical structure means compromising core switches provides disproportionate impact compared to edge compromises, creating high-value targets that sophisticated attackers prioritize for maximum disruption with minimal effort.
DragonFly Topologies maximize bandwidth efficiency through direct connections between switch groups, but they create single points of failure where targeted attacks on inter-group links can partition the fabric into disconnected components that cannot coordinate gradient synchronization across the artificial boundaries created by the attack.
The complex routing algorithms required for optimal performance in DragonFly networks also introduce computational attack vectors where routing table manipulation can cause widespread performance degradation without directly disrupting any data flows.
Infrastructure Readiness Crisis
MIT & Google Research: 69% of enterprise leaders acknowledge their legacy network infrastructure cannot handle AI workload demands—a stunning admission that forces rapid architectural changes that bypass established security review processes, creating systemic vulnerabilities that attackers actively exploit while organizations rush to deploy AI capabilities before their competitors beat them to market.
Recent research from MIT and Google indicates that 69% of enterprise leaders acknowledge their legacy network infrastructure cannot handle AI workload demands, a reality that forces rapid architectural changes that bypass established security review processes in the rush to remain competitive.
Network Interface Card Evolution
Modern AI fabrics depend on specialized Network Interface Cards that fundamentally change the security landscape in ways that traditional security teams may not fully understand or appreciate.
NVIDIA's ConnectX-7 and Intel's E810 series represent different approaches to the same challenge: providing ultra-low latency connectivity while maintaining security in environments where every microsecond counts and traditional security mechanisms introduce unacceptable overhead.
These advanced NICs include features that traditional security teams may not fully understand:
Hardware Offload Engines: Cryptographic operations, packet processing, and protocol handling move from software to dedicated silicon. While this improves performance dramatically, it also moves security-critical operations outside traditional monitoring and control mechanisms that rely on software instrumentation to detect anomalous behavior.
SR-IOV Virtualization: Single physical NICs present as multiple virtual NICs. To enable efficient GPU sharing. However, SR-IOV creates new attack vectors where compromised virtual functions can potentially access memory spaces belonging to other virtual functions through exploitation of subtle hardware isolation failures.
GPUDirect Technology: Direct memory transfers between NICs and GPUs bypass system memory and CPU involvement entirely, eliminating latency but also bypassing many traditional security controls that rely on CPU-mediated access controls to enforce security policies on memory operations.
The Vulnerability Landscape: Where AI Fabrics Break
AI fabric vulnerabilities don't just mirror traditional network security problems at larger scale.
They create entirely new categories of attacks that exploit the fundamental architectural differences between AI fabrics and traditional networks, attacks that target the synchronization requirements, timing precision, and collective communication patterns that make distributed training possible in the first place.
Synchronization Disruption Attacks
The most dangerous attacks against AI fabrics target synchronization requirements. The precise timing that makes distributed training possible.
These attacks don't need to compromise data or systems directly—they just need to introduce enough timing variability to make training economically impossible, forcing organizations to abandon training runs after investing millions in compute time without producing usable models.
Gradient Poisoning Through Timing
Advanced Persistent Threat: Attackers inject carefully crafted delays into specific communication patterns. Delays that cause gradient updates to arrive out of sequence. Modern optimizers like Adam and RMSprop depend on precise ordering—timing attacks can steer model training toward attacker-controlled outcomes without directly modifying any data, creating backdoors that survive into production deployments where they wait for activation triggers.
Gradient Poisoning Through Timing: Attackers inject carefully crafted delays into specific communication patterns, causing gradient updates to arrive out of sequence in ways that corrupt the mathematical operations that depend on precise ordering of gradient contributions from different processing nodes.
Modern optimizers like Adam and RMSprop depend on precise ordering of gradient updates, and when timing attacks cause updates to arrive in wrong order, they can steer model training toward attacker-controlled outcomes without directly modifying any data that integrity checking mechanisms would flag as suspicious.
Barrier Synchronization Exploits: By introducing microsecond-level delays at specific synchronization points, attackers cause training jobs to hang indefinitely, waiting for all participants to reach the barrier in a coordination that never completes because one node perpetually lags behind the others by just enough to prevent progress.
Unlike traditional denial-of-service attacks that require overwhelming traffic volumes, barrier synchronization exploits achieve maximum impact with minimal attack traffic that often evades detection by volume-based security monitoring systems.
Clock Skew Amplification: AI fabrics depend on precise clock synchronization across all nodes, and attackers who can introduce small amounts of clock skew can cause cascading failures as different nodes fall out of synchronization with each other, creating an expanding wave of timing misalignment that eventually paralyzes the entire cluster.
The precision time protocol implementations used in AI fabrics lack the security hardening found in traditional NTP deployments. Often. Critically.
Flow Control Weaponization
Modern AI fabrics use Priority Flow Control and Quantized Congestion Notification to prevent packet loss in lossless fabrics.
However, these mechanisms create new attack vectors.
Attack vectors that don't exist in traditional networks, vectors that exploit the very mechanisms designed to ensure perfect reliability to instead create catastrophic failures that paralyze entire training clusters in ways that traditional network security tools cannot detect or prevent.
PFC Deadlock Attacks: Attackers craft specific traffic patterns that cause circular dependencies in flow control messages—when switch A pauses traffic to switch B, which pauses traffic to switch C, which pauses traffic back to switch A, the entire fabric can deadlock in a state where no traffic flows because every switch waits for permission that never arrives.
Unlike software deadlocks that affect single systems, fabric deadlocks can freeze entire AI clusters simultaneously, creating organization-wide training outages.
Congestion Control Manipulation: By sending spoofed congestion notification messages, attackers cause senders to artificially throttle their transmission rates, and in AI training workloads where all participants must maintain synchronized progress, forcing even one node to slow down causes the entire training job to operate at the reduced speed, amplifying the attack impact across the full cluster.
Buffer Overflow Cascades: With minimal buffering in AI fabric switches, small amounts of attack traffic cause buffer overflows that propagate through the fabric topology as each switch that drops packets triggers retransmissions that create additional load on upstream switches, potentially creating failure cascades that affect the entire fabric in an expanding wave of congestion-induced packet loss.
RDMA Security Exploits
Remote Direct Memory Access capabilities in AI fabrics create attack vectors that bypass traditional operating system security controls entirely.
Memory Scraping Attacks
Direct Memory Exposure: RDMA operations can access GPU memory directly without OS mediation, creating a direct path from network to memory that bypasses every security control designed to protect sensitive data from unauthorized access. Attackers who compromise RDMA credentials can potentially read training data, model parameters, or intermediate activations directly from GPU memory across the network—data that never touches persistent storage where traditional data loss prevention tools could detect the exfiltration.
Memory Scraping Attacks: RDMA operations access GPU memory directly without OS mediation, and attackers who compromise RDMA credentials can read training data, model parameters, or intermediate activations directly from GPU memory across the network in ways that leave no trace in traditional file system audit logs.
Unlike traditional data breaches that require file system access and leave forensic evidence of file operations, RDMA attacks extract data that never touches persistent storage, making detection extremely difficult without specialized memory access monitoring that most organizations don't deploy.
Parameter Corruption: By writing malicious data directly to GPU memory through RDMA, attackers corrupt model parameters during training without leaving traditional forensic evidence—the corruption appears as training instability rather than obvious security compromise, and debugging efforts focus on hardware failures or software bugs rather than active attacks.
This makes detection extremely difficult. Extremely. Frustratingly so.
Side-Channel Information Disclosure: RDMA timing patterns leak information about model architectures, batch sizes, and training progress that sophisticated attackers can reconstruct into detailed intelligence about proprietary AI models by analyzing network timing patterns without ever accessing the actual model data or stealing any files.
Fabric-Wide Denial of Service
Traditional DDoS attacks focus on overwhelming single targets with traffic volume.
AI fabric attacks achieve disproportionate impact through precise targeting of fabric-wide dependencies that amplify small disruptions into catastrophic training failures.
Topology-Aware Attacks: By understanding fabric topology, attackers identify critical links whose failure partitions the fabric into disconnected components, and targeting these links with relatively small amounts of attack traffic can disable entire AI clusters in ways that simple traffic volume flooding could never achieve.
Collective Operation Disruption: AI training relies on collective communication operations that involve every node simultaneously—all-reduce, broadcast, scatter-gather operations where attacks that disrupt any participant in collective operations cause the entire operation to fail, amplifying attack impact across the full cluster through the mathematical requirements of distributed gradient synchronization.
Quality of Service Manipulation: AI fabrics use complex QoS policies to prioritize different traffic classes, and attackers who can manipulate QoS markings can cause critical AI traffic to receive lower priority than background tasks, effectively denying service through priority inversion rather than traffic volume in attacks that sophisticated QoS-aware intrusion detection systems struggle to identify as malicious.
Supply Chain and Hardware Vulnerabilities
The specialized nature of AI fabric hardware creates concentration risks that don't exist in traditional networking environments.
Firmware Manipulation: AI fabric switches and NICs require frequent firmware updates to optimize performance for evolving AI workloads, and the rapid update cycle combined with performance pressure leads to abbreviated security review processes that attackers can exploit to install persistent backdoors in fabric infrastructure that survive hardware reboots and software reinstallations.
Hardware Implants: The small number of vendors capable of producing AI fabric-capable silicon creates opportunities for state-sponsored attackers to introduce hardware-level compromises, and unlike traditional network equipment where multiple vendors provide alternatives, AI fabric deployments depend on single-source components that concentrate risk in ways that procurement policies designed for traditional IT equipment fail to address.
Driver and Software Stack Exploits: AI fabrics require specialized driver stacks and user-space libraries like NVIDIA's CUDA and NCCL that integrate tightly with both networking hardware and AI frameworks, creating software stacks that are complex, rapidly evolving, and deployed with elevated privileges that provide rich attack surfaces for sophisticated adversaries.
CVE-2025-23266: NVIDIAScape Vulnerability
CVSS 9.0 Critical: The recent discovery of CVE-2025-23266 (NVIDIAScape) allows attackers to escape GPU containers and access fabric credentials, potentially compromising entire AI training clusters through a single container compromise that provides lateral movement capabilities far beyond what traditional container escape vulnerabilities enable in conventional computing environments.
The recent discovery of CVE-2025-23266 (NVIDIAScape) with a CVSS score of 9.0 demonstrates this vulnerability category perfectly—the Container Toolkit vulnerability allows attackers to escape GPU containers and access fabric credentials, potentially compromising entire AI training clusters through a single container compromise that provides network-level access to systems the container should never have been able to reach.
Case Study: The 2024 AI Training Facility Attack
In November 2024, a major cloud provider's AI training facility experienced what initially appeared to be random training failures.
Multiple customer training jobs began failing with cryptic gradient synchronization timeout errors that defied explanation.
The failures seemed random—some jobs completed successfully while others with identical configurations failed repeatedly, creating a pattern that suggested intermittent hardware problems rather than systematic attacks that traditional security monitoring would have flagged as suspicious activity requiring investigation.
Initial investigation focused on hardware problems. Engineers replaced GPUs. Switches. Cables. They updated firmware and drivers. Nothing helped. The pattern defied explanation through traditional network troubleshooting approaches that assume problems stem from component failures rather than coordinated attacks.
Attack Detection Breakthrough
Microsecond-Level Precision Attack: The breakthrough came when security analysts noticed microsecond-level timing anomalies in network telemetry data that traditional monitoring tools aggregate away as insignificant noise. Someone was injecting precisely timed delays into barrier synchronization operations—not enough to trigger network error conditions that would alert operations teams, but sufficient to cause training jobs to exceed their synchronization timeouts and fail with errors that appeared to indicate software bugs rather than active attacks.
The breakthrough came when security analysts noticed microsecond-level timing anomalies in network telemetry data. Someone was injecting precisely timed delays into barrier synchronization operations. Not enough to trigger network error conditions. But sufficient to cause training jobs to exceed their synchronization timeouts in ways that appeared to be random performance problems rather than coordinated attacks.
Attack Vector: The attackers had compromised a single container in the cluster's shared storage system, and from there, they gained access to the fabric management network where they began sending spoofed Priority Flow Control pause frames that targeted the timing-critical control plane communications coordinating barrier synchronization across thousands of GPUs.
The pause frames didn't target training traffic directly. They targeted the control plane. Specifically. Precisely.
Impact: Over 6 weeks, the attack caused 47 training jobs to fail, resulting in $12.3 million in wasted compute costs, and more critically, three customer AI models fell behind competitive timelines, causing additional business impact estimated at over $50 million in lost market opportunities and competitive positioning that money alone cannot recover.
Detection Challenges: Traditional network monitoring missed the attack because traffic volumes remained normal and no packets were dropped—the attack succeeded by exploiting the gap between traditional network metrics that focus on throughput and loss versus AI-specific performance requirements that depend on microsecond-precision timing that standard monitoring tools don't measure or report.
Resolution: The attack stopped only after implementing AI-workload-specific monitoring that tracked synchronization timing patterns rather than traditional network health metrics, and the organization deployed fabric-scheduled Ethernet with hardware-enforced timing controls to prevent future timing manipulation attacks that exploit the statistical nature of conventional congestion control mechanisms.
Key Learning
Traditional Network Security Falls Short: This incident demonstrates how AI fabric attacks require completely different detection and response strategies compared to traditional network security threats—standard monitoring tools are blind to the microsecond-precision timing attacks that devastate AI workloads, and organizations must invest in specialized monitoring infrastructure designed specifically for distributed training environments.
This incident demonstrates how AI fabric attacks require completely different detection and response strategies compared to traditional network security threats.
Quantifying the Risk: Performance Impact Analysis
Understanding AI fabric vulnerabilities requires precise measurement of how network problems translate to training performance degradation and business impact.
The relationships are neither linear nor intuitive. Making risk assessment challenging for traditional security teams.
Challenging in ways that lead to systematic underestimation of the threats these systems face from adversaries who understand the mathematical amplification effects that traditional security frameworks ignore.
Latency Amplification Mathematics
In distributed AI training, network latency gets amplified through mathematical relationships that don't exist in traditional applications where latency impacts individual transactions rather than coordinated operations spanning thousands of processing nodes.
Consider a transformer model training scenario with specific parameters that illustrate the amplification effect:
Base Case: 512-GPU cluster, 96-layer model, 100 synchronization points per training step
- Network latency per synchronization: 50 microseconds
- Total synchronization overhead per step: 5 milliseconds
- Compute time per step: 100 milliseconds
- Total step time: 105 milliseconds
Attack Scenario: Attacker adds 10 microseconds latency per synchronization
- Network latency per synchronization: 60 microseconds
- Total synchronization overhead per step: 6 milliseconds
- Total step time: 106 milliseconds
- Performance degradation: 0.95% per step
Economic Impact Calculation
Compound Attack Effects: This seems minimal until you consider training duration and the mathematical compounding that transforms small per-step overhead into massive total impact. A model that requires 1 million training steps now takes 1.01 million steps worth of time, extending a 2-week training job by 3.4 days and increasing compute costs by $340,000 for a typical large-scale training run—money wasted not on breakthrough research or competitive advantage but on recovering from attack-induced inefficiency.
This seems minimal until you consider training duration. A model that requires 1 million training steps now takes 1.01 million steps worth of time. Extending a 2-week training job by 3.4 days.
This increases compute costs by $340,000 for a typical large-scale training run—money that disappears into the void of wasted cycles.
Congestion-Induced Training Failures
Unlike traditional applications that gracefully degrade under network stress, AI training exhibits cliff effects where small increases in congestion cause complete training failure.
Measurement from Production Deployments (based on anonymized data from major cloud providers):
| Packet Loss Rate | Training Completion Rate | Average Time to Failure |
|---|---|---|
| 0.000% | 99.2% | N/A |
| 0.001% | 87.4% | 16.3 hours |
| 0.005% | 23.1% | 4.7 hours |
| 0.010% | 5.8% | 1.2 hours |
| 0.050% | 0.0% | 18 minutes |
These numbers reveal the extreme sensitivity of AI workloads to network reliability in ways that traditional enterprise applications never experience. Traditional enterprise applications operate acceptably with 0.1% packet loss. AI training becomes economically impossible at 0.01% loss—a 10x higher reliability requirement that demands completely different network architectures than conventional enterprise infrastructure can provide.
Economic Impact Modeling
The economic impact of AI fabric attacks extends far beyond immediate compute costs. Organizations must consider multiple impact categories.
Direct Training Costs: GPU time, electricity, cooling, and facility overhead for failed training runs where, for large language models, costs range from $500,000 to $5 million per training attempt that produces no usable output when attacks or infrastructure failures cause premature termination.
Opportunity Costs: Delayed model releases impact competitive positioning in ways that financial models struggle to capture. Research from McKinsey indicates that AI models released 6 months late capture 63% less market value than planned—a devastating competitive disadvantage that can determine which companies survive and which fade into irrelevance.
Cascading Development Impacts: Failed training runs delay downstream development activities where model optimization, safety testing, and deployment preparation all get pushed back, multiplying the initial delay through complex project dependencies that amplify schedule slips exponentially.
Competitive Intelligence Value: Training logs and intermediate model checkpoints contain valuable intellectual property, and the average value of stolen AI training data exceeds $2.4 million per incident according to 2024 breach cost studies that capture only the direct costs while ignoring the long-term competitive impacts of leaked proprietary architectures.
Vulnerability Surface Expansion
AI fabrics create vulnerability surfaces that grow non-linearly with cluster size in ways that traditional network security models fail to account for.
Traditional Networks: Adding 100 servers to a traditional network increases attack surface roughly linearly where each server represents one additional compromise target that attackers must breach independently.
AI Fabrics: Adding 100 GPUs to an AI fabric creates attack surface that grows quadratically—each new GPU must communicate with every existing GPU, creating N×(N-1)/2 communication paths that attackers can potentially exploit through timing manipulation, gradient poisoning, or collective operation disruption.
Exponential Attack Surface Growth
Quadratic Vulnerability Scaling: For a 1000-GPU cluster, this means approximately 500,000 individual communication channels, each representing potential attack vectors for timing manipulation, flow control exploitation, or collective operation disruption—a fundamentally different security challenge than traditional network protection where attack surface grows linearly with system size rather than exploding quadratically as distributed training demands increase.
For a 1000-GPU cluster, this means approximately 500,000 individual communication channels. Each representing potential attack vectors. For timing manipulation. Flow control exploitation. Collective operation disruption.
Detection and Monitoring: Seeing the Invisible
Traditional network monitoring approaches fail catastrophically when applied to AI fabrics.
The metrics that matter don't appear in conventional network management systems that measure throughput, packet loss, and link utilization while remaining blind to the microsecond-level timing precision, collective operation coordination, and gradient synchronization patterns that determine whether distributed training succeeds or fails.
AI-Specific Monitoring Requirements
Effective AI fabric security requires monitoring categories that don't exist in traditional networking:
Synchronization Timing Analysis: Track the precise timing of barrier synchronization operations across all training participants where deviations of more than 100 microseconds indicate attack activity or hardware degradation that traditional network monitoring tools aggregate away as insignificant statistical noise.
Collective Communication Pattern Analysis: Monitor all-reduce, broadcast, and scatter-gather operations for anomalous timing patterns that attackers create when they target these operations because they involve all training participants simultaneously, amplifying the impact of small disruptions across the entire cluster.
Gradient Flow Monitoring: Track the statistical properties of gradient updates flowing through the fabric where gradient poisoning attacks create detectable statistical anomalies in gradient magnitude and direction distributions that diverge from the expected patterns of legitimate training progress.
Memory Access Pattern Monitoring: For RDMA-enabled fabrics, monitor direct memory access patterns to detect unauthorized memory scraping or parameter corruption attempts that bypass traditional file system monitoring and leave no traces in conventional audit logs.
Implementing Fabric-Aware Intrusion Detection
Traditional network intrusion detection systems operate by analyzing packet headers and payload content.
AI fabric IDS systems must analyze timing patterns, mathematical relationships, and distributed system behaviors that packet inspection cannot reveal.
Advanced Detection Techniques
Hardware Timestamping: Deploy hardware timestamping capabilities at every fabric switch to create microsecond-precision timing telemetry that software-based monitoring cannot achieve. Machine learning models trained on normal training timing patterns can detect timing manipulation attacks that wouldn't appear in packet-level analysis focused on protocol violations or traffic volume anomalies.
Timing-Based Anomaly Detection: Deploy hardware timestamping capabilities at every fabric switch to create microsecond-precision timing telemetry, and machine learning models trained on normal training timing patterns can detect timing manipulation attacks that wouldn't appear in packet-level analysis focused on protocol compliance rather than timing precision.
Collective Operation Integrity Checking: Implement cryptographic verification of collective communication operations where each participant signs its contribution to collective operations, enabling detection of attacks that inject false data or disrupt operation completion through spoofed participation claims.
Fabric Topology Mapping: Continuously map actual traffic flows against expected fabric topology because attackers create unexpected traffic patterns that reveal compromise attempts or reconnaissance activities even when the traffic itself appears legitimate based on protocol analysis alone.
Cross-Layer Correlation: Correlate fabric-level events with training framework logs, GPU telemetry, and application performance metrics because many attacks create subtle signatures that only become visible when analyzing multiple data sources simultaneously through sophisticated correlation engines that traditional security tools lack.
Real-Time Response Capabilities
AI fabric security requires response times measured in microseconds rather than the minutes or hours acceptable for traditional network security.
Hardware-Accelerated Response: Deploy programmable switches or SmartNICs that implement security responses in hardware without software mediation, and when attacks are detected, hardware-level responses can isolate compromised nodes or reroute traffic faster than software-based systems that must traverse operating system network stacks and process scheduling overhead.
Predictive Isolation: Use machine learning models to predict which nodes are likely to experience security issues based on early indicators, and proactively isolating nodes before complete compromise prevents attacks from spreading through fabric interconnections that provide lateral movement opportunities to sophisticated adversaries.
Graceful Degradation Strategies: Unlike traditional networks where security responses involve blocking traffic, AI fabrics require responses that maintain training continuity through strategies that isolate compromised nodes while redistributing their work to healthy nodes without disrupting the synchronized progress of distributed gradient computation.
Telemetry and Observability Architecture
AI fabric monitoring requires fundamentally different telemetry architectures compared to traditional networks:
Hardware Timestamping: Every packet must include hardware-generated timestamps accurate to nanosecond precision because software-based timestamping introduces timing variability that obscures attack signatures in ways that make precision timing attacks impossible to detect reliably.
Distributed Correlation: Telemetry data from thousands of nodes must be correlated in real-time to detect distributed attacks, requiring streaming analytics platforms capable of processing millions of events per second with millisecond correlation windows that can identify coordinated attacks spanning multiple systems.
Mathematical Validation: Monitor the mathematical properties of distributed training operations where attackers who manipulate training create detectable mathematical inconsistencies in gradient updates, parameter synchronization, or convergence patterns that diverge from the expected mathematical relationships governing distributed optimization algorithms.
Mitigation Strategies: Building Resilient AI Fabrics
Securing AI fabrics requires moving beyond traditional network security approaches toward integrated strategies.
Strategies that address the unique vulnerabilities created by tightly coupled, high-performance distributed computing environments where conventional security controls introduce unacceptable performance overhead that makes them impractical for production deployment.
Network Architecture Hardening
Fabric Segmentation: Implement microsegmentation strategies designed specifically for AI workloads where, unlike traditional network segmentation that focuses on preventing lateral movement, AI fabric segmentation must maintain the collective communication patterns essential for training while isolating different projects or security domains through carefully designed gateway controls.
Deploy dedicated fabric segments for different training phases:
- Data Ingestion Segment: Isolated fabric for loading and preprocessing training data
- Training Computation Segment: Ultra-high performance segment for gradient synchronization
- Model Checkpointing Segment: Separate segment for saving and loading model states
- Inference Segment: Isolated segment for production model serving
Each segment implements different security controls appropriate to its function while maintaining necessary interconnections through controlled, monitored gateways that enforce security policies without introducing the latency overhead that would degrade training performance.
Hardware-Enforced Security
Cryptographic Isolation: Leverage SR-IOV and hardware virtualization capabilities to create cryptographically isolated virtual fabrics on shared physical infrastructure. Unlike software-based VLANs that attackers can bypass through protocol manipulation, hardware-enforced isolation provides cryptographic guarantees even when software stacks are compromised through zero-day exploits or insider threats.
Hardware-Enforced Isolation: Leverage SR-IOV and hardware virtualization capabilities to create cryptographically isolated virtual fabrics on shared physical infrastructure, and unlike software-based VLANs that can be bypassed through protocol manipulation, hardware-enforced isolation provides cryptographic guarantees even when software stacks are compromised through sophisticated attacks.
Redundant Fabric Topologies: Deploy dual fabrics with different vendors, protocols, and topologies where the primary fabric handles normal training traffic while the secondary fabric provides both backup capability and attack detection through traffic pattern comparison, and discrepancies between fabric behaviors indicate compromise attempts that single-fabric deployments cannot detect.
Authentication and Access Control
Hardware-Based Identity: Implement cryptographic identity systems anchored in hardware roots of trust where each GPU, switch, and NIC contains unique cryptographic credentials burned into silicon during manufacturing, and these credentials enable mutual authentication for all fabric communications without software-mediated trust relationships that attackers can compromise.
Dynamic Credential Rotation: Unlike traditional network credentials that remain static for months, AI fabric credentials must rotate continuously to prevent credential harvesting attacks, and automated systems rotate fabric authentication credentials every few minutes while maintaining training continuity through seamless credential handoff protocols.
Zero-Trust Fabric Architecture: Apply zero-trust principles specifically adapted for AI fabrics where every communication flow requires authentication, authorization, and encryption even between components in the same physical rack, preventing lateral movement attacks and containing breaches to minimal fabric segments.
Collective Operation Security
Cryptographic Verification: Implement cryptographic verification for all collective communication operations. Each participant signs its contribution to all-reduce, broadcast, and scatter-gather operations. Recipients verify signatures before incorporating data into local computations. Preventing gradient poisoning and parameter corruption attacks.
Consensus-Based Synchronization: Replace vulnerable barrier synchronization with consensus-based protocols adapted from distributed systems research where, rather than requiring all participants to reach synchronization points simultaneously, consensus protocols tolerate small numbers of failed or compromised participants while maintaining training progress.
Gradient Authentication: Deploy cryptographic systems that verify gradient authenticity without impacting training performance, and lightweight cryptographic schemes detect gradient manipulation attempts while adding minimal computational overhead to training operations that already consume billions of floating-point operations per second.
Traffic Engineering and QoS Hardening
Deterministic Traffic Scheduling: Implement time-sensitive networking protocols that provide deterministic, guaranteed bandwidth and latency for critical AI communications, and TSN prevents timing manipulation attacks by enforcing hardware-level scheduling that cannot be disrupted through software-based attacks that traditional congestion control mechanisms remain vulnerable to.
Attack-Resistant Congestion Control: Deploy congestion control algorithms specifically designed to resist manipulation where, unlike traditional TCP congestion control that responds to congestion signals, AI fabric congestion control systems use cryptographically verified feedback and distributed consensus to prevent spoofed congestion messages from disrupting training operations.
Priority Protection: Implement hardware-enforced priority queues that cannot be manipulated through software attacks where critical AI synchronization traffic receives guaranteed priority even when attackers compromise application software or operating systems through privilege escalation or container escape exploits.
Monitoring and Response Integration
Continuous Training Integrity Verification: Deploy systems that continuously verify the mathematical correctness of distributed training operations, systems that detect attacks manipulating gradients, corrupting parameters, or disrupting convergence without requiring knowledge of specific attack techniques that signature-based detection systems miss.
Automated Attack Response: Implement automated response systems that isolate compromised fabric segments and redistribute training workloads within milliseconds of attack detection, and unlike traditional security responses that focus on forensics and recovery, AI fabric responses prioritize maintaining training continuity while containing attacks.
Machine Learning for Anomaly Detection: Deploy ML-based anomaly detection systems trained specifically on AI fabric traffic patterns that can detect novel attacks that don't match known attack signatures by identifying deviations from normal collective communication patterns that indicate malicious activity even when attackers use zero-day exploits.
Supply Chain Security
Hardware Verification: Implement comprehensive hardware verification programs for all fabric components including cryptographic verification of firmware integrity, hardware security module verification of component authenticity, and continuous monitoring for hardware-level compromises that supply chain attacks could introduce during manufacturing or shipping.
Trusted Component Sourcing: Establish trusted supplier relationships with comprehensive security requirements that require suppliers to provide cryptographic proofs of component integrity, manufacturing process security, and supply chain transparency that gives visibility into every step from silicon fabrication to final deployment.
Firmware Security Programs: Develop comprehensive firmware security programs that include secure development practices, cryptographic signing, and automated vulnerability scanning where firmware updates undergo rigorous security review before deployment in production AI fabrics that cannot tolerate the instability that malicious firmware could introduce.
The Road Ahead: Emerging Threats and Future Directions
The AI fabric security landscape continues evolving rapidly.
Both attackers and defenders adapt to new technologies. Threat vectors. Defensive capabilities.
Understanding emerging trends becomes crucial for organizations planning long-term AI infrastructure investments that will determine competitive positioning for the next decade of AI-driven business transformation.
Quantum-Resistant Cryptography Integration
Current AI fabric security relies heavily on classical cryptographic primitives that quantum computers could potentially break within the next decade, and organizations deploying AI infrastructure today must plan for post-quantum cryptographic transitions that won't disrupt training operations or require complete infrastructure replacement.
Hybrid Cryptographic Approaches: Implement cryptographic systems that provide both classical and quantum-resistant security during transition periods, and systems maintain compatibility with existing infrastructure while providing quantum-resistant protection for new deployments that will operate long enough to face quantum cryptanalytic threats.
Performance-Optimized Post-Quantum Schemes: Traditional post-quantum cryptography introduces significant computational and bandwidth overhead that AI fabrics cannot tolerate, requiring specialized post-quantum schemes optimized for high-throughput, low-latency environments where every microsecond of additional overhead compounds into massive performance degradation.
Key Management Evolution: Post-quantum cryptography requires larger key sizes and different key lifecycle management approaches, and AI fabric key management systems must evolve to handle these requirements without impacting training performance through increased key exchange overhead or cryptographic operation latency.
Federated Learning Security Implications
As AI training shifts toward federated learning models, fabric security must extend beyond single-organization boundaries to distributed fabrics that coordinate training across multiple organizations and geographical locations with different security policies and threat models.
Cross-Organization Trust Establishment: Federated AI training requires establishing cryptographic trust relationships between organizations that may be competitors, and security protocols must enable collaboration while protecting proprietary training data and model parameters from exposure to partners who might exploit the information for competitive advantage.
Distributed Attack Detection: Attacks against federated learning systems may span multiple organizations' infrastructure where detection systems must coordinate across organizational boundaries while respecting privacy and competitive sensitivity requirements that limit information sharing about internal security events.
Regulatory Compliance Coordination: Federated learning across jurisdictional boundaries creates complex regulatory compliance requirements, and AI fabric security must provide audit trails and compliance verification capabilities that satisfy multiple regulatory frameworks simultaneously without creating performance overhead that makes compliance cost-prohibitive.
Edge AI Fabric Evolution
AI training and inference increasingly occur at edge locations with limited infrastructure and security resources.
Edge AI fabrics require security approaches adapted for resource-constrained, physically accessible environments where traditional data center security controls cannot be deployed due to power, cooling, or physical security limitations.
Lightweight Security Protocols: Edge AI fabrics cannot support the comprehensive security infrastructure available in cloud data centers, and security protocols must provide strong protection with minimal computational and bandwidth overhead that fits within the constraints of edge deployment environments.
Physical Tamper Resistance: Edge AI infrastructure faces physical attack risks not present in secured data centers where hardware security modules and tamper-resistant enclosures become essential components of edge fabric security that can detect and respond to physical intrusion attempts.
Intermittent Connectivity Adaptation: Edge AI fabrics must operate securely despite intermittent connectivity to central security infrastructure, requiring autonomous security decision-making capabilities for edge deployments that may operate disconnected from central management for extended periods during network outages or intentional isolation.
Regulatory and Compliance Evolution
Regulatory frameworks for AI security continue evolving rapidly, creating compliance requirements that significantly impact fabric architecture and security approaches.
AI Governance Integration: Emerging AI governance frameworks require detailed audit trails of training processes, data usage, and model behaviors, and AI fabric security must provide comprehensive logging and monitoring capabilities that satisfy governance requirements without impacting performance through excessive telemetry overhead.
Cross-Border Data Protection: AI training involves data from multiple jurisdictions with different privacy and protection requirements, and fabric security must enforce jurisdiction-appropriate protections while maintaining training efficiency through intelligent data routing and selective encryption.
Algorithmic Accountability: Regulatory frameworks increasingly require organizations to explain AI decision-making processes, and AI fabric security must provide audit capabilities that enable algorithmic accountability while protecting proprietary model architectures from disclosure to regulators who might inadvertently leak competitive intelligence.
Economic Impact Projections
The economic implications of AI fabric security continue expanding as AI becomes more central to business operations across industries.
Economic Threat Scale
$10.5 Trillion Global Impact by 2025: As AI training clusters grow larger and more expensive, the economic impact of successful attacks scales proportionally where a single successful attack against a large language model training run can cause economic damage exceeding $50 million when including direct costs, competitive impacts, and opportunity costs that compound over time. Current projections indicate global AI cyberattack impacts could reach $10.5 trillion by 2025 as attacks become more sophisticated and AI infrastructure becomes more critical to business operations across every industry sector.
Attack Cost Scaling: As AI training clusters grow larger and more expensive, the economic impact of successful attacks scales proportionally—a single successful attack against a large language model training run can cause economic damage exceeding $50 million when including direct costs, competitive impacts, and opportunity costs that ripple through development timelines and market positioning.
Current projections from cybersecurity research indicate that global AI cyberattack impacts could reach $10.5 trillion by 2025 as attacks become more sophisticated and AI infrastructure becomes more critical to business operations.
Insurance Market Evolution: Cyber insurance markets rapidly evolve to address AI-specific risks, and organizations must understand how AI fabric security investments impact insurance coverage, premiums, and claims processes that increasingly treat AI infrastructure security as a separate risk category from traditional IT security.
Competitive Advantage Through Security: Organizations that successfully implement comprehensive AI fabric security gain significant competitive advantages through reduced training failures, improved model development velocity, and enhanced intellectual property protection that competitors struggling with security problems cannot match.
Conclusion: The Security Imperative for AI's Future
AI fabrics represent more than technological evolution.
They embody a fundamental shift in how we build and secure distributed computing systems, a shift that demands new thinking about security, performance, and the trade-offs between them.
The vulnerabilities we've explored aren't edge cases or theoretical problems—they're active threats facing every organization deploying AI at scale, threats that cost millions when they succeed and create competitive disadvantages that persist long after the immediate security incidents are resolved.
The Stakes Are Clear
Economic Reality: Network inefficiencies increase AI training costs by 40x. Small business cyberattacks average $254,445 in damages. For AI infrastructure, these costs multiply exponentially when attacks target the fabric itself rather than individual systems, and the challenge extends beyond immediate security concerns—AI fabrics are becoming the backbone of modern economic competitiveness where organizations that fail to secure their infrastructure don't just face security breaches but fundamental limitations on their ability to compete in AI-driven markets.
The numbers speak clearly and without ambiguity. Network inefficiencies increase AI training costs by 40x. Small business cyberattacks average $254,445 in damages. For AI infrastructure, these costs multiply exponentially when attacks target the fabric itself rather than individual systems.
But the challenge extends beyond immediate security concerns—AI fabrics are becoming the backbone of modern economic competitiveness, and organizations that fail to secure their AI infrastructure don't just face security breaches but fundamental limitations on their ability to compete in AI-driven markets where model quality and development velocity determine market leadership.
The path forward requires abandoning traditional network security approaches in favor of integrated strategies that address the unique requirements of tightly coupled, high-performance distributed computing.
This means implementing hardware-based authentication. Cryptographic verification of collective operations. Microsecond-precision monitoring. Automated response systems that maintain training continuity while containing attacks.
Most critically, it requires recognizing that AI fabric security isn't a traditional IT security problem with traditional IT solutions—it's a new category of challenge that sits at the intersection of network engineering, distributed systems, applied cryptography, and business strategy, demanding expertise that few organizations currently possess.
The Competitive Advantage of Security
Early Adoption Benefits: Organizations that master AI fabric security early will gain sustained competitive advantages through reliable training operations that consistently deliver breakthrough models on schedule. Those that don't will find themselves increasingly vulnerable to attacks that cause millions in immediate damage while compromising their long-term ability to compete in AI-driven markets where security failures compound into strategic disadvantages.
Organizations that master AI fabric security early will gain sustained competitive advantages. Those that don't? They'll find themselves increasingly vulnerable to attacks that cause millions in immediate damage while compromising their long-term ability to compete in AI-driven markets.
The brittle fabric can be strengthened, but it requires moving beyond conventional thinking toward security approaches designed specifically for the realities of AI-scale distributed computing.
The time for that transition is now.
Before the costs of delayed action become prohibitive, before competitors establish insurmountable leads, before the next major breach demonstrates that traditional security approaches fail catastrophically when applied to AI fabrics that demand perfection in ways that conventional networks never imagined.
Your AI infrastructure is only as strong as its most vulnerable fabric connection, and in a world where AI capabilities determine competitive success, fabric security isn't just a technical requirement—it's a business imperative that will separate winners from losers in the AI economy ahead.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score