The Stakes Are Everything
Real-World Implementations
These case studies demonstrate practical approaches to securing AI infrastructure in cloud environments. Learn from both successes and failures in production deployments.
Your network just became your destiny. Training foundation models changes everything. Think about it—tens of thousands of accelerators demanding networking that doesn't just work but defines what's even possible in the first place.
Performance? Not optional anymore. Latency controls whether your $100 million GPU cluster computes or waits, burning cash while doing nothing useful. Reliability? That decides everything—whether training takes weeks or drags into months, whether you succeed or fail spectacularly while competitors surge ahead.
Consider the brutal reality staring down every AI team right now. Thousands of GPUs must exchange gradient information through collective operations like All-Reduce, and the network—that often-overlooked fabric connecting everything—sets the pace for the entire operation, creating bottlenecks that leave millions of dollars worth of silicon sitting idle, waiting, wasting.
Economic Reality: Training times stretch beyond competitive relevance when networks fail. Capital efficiency dies. Market advantage vanishes into thin air. Your competitors ship while you wait.
Then something remarkable happened. The world's leading cloud providers split into camps, choosing sides in a fundamental infrastructure war. Two philosophical approaches emerged, each backed by billions in investment and years of engineering expertise that would reshape how we build intelligent systems.
InfiniBand arrived first. Purpose-built performance from day one. A complete fabric designed from scratch for one mission: make high-performance computing faster than anyone thought possible.
High-performance Ethernet chose a different path entirely, one that would challenge every assumption about what general-purpose technology could achieve. Massive scale drove every decision. Vendor diversity challenged the incumbent's stranglehold. Adaptability met raw economics in a battle for the future of AI infrastructure.
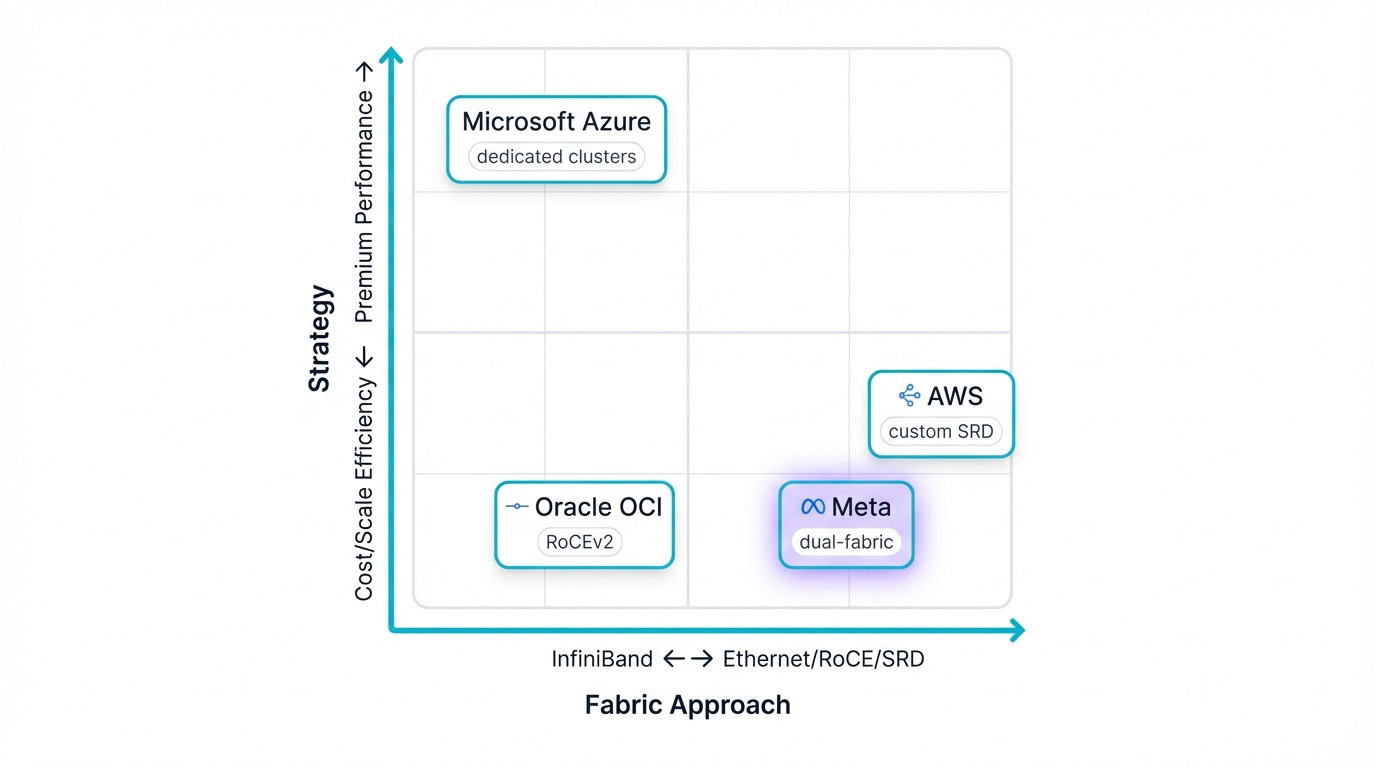
Four organizations reveal the future through their billion-dollar bets on competing technologies:
- Microsoft Azure leverages HPC heritage ruthlessly. Premium performance drives every decision they make. They deployed cutting-edge InfiniBand fabrics targeting the most demanding workloads imaginable. Azure promises uncompromised performance, predictable results that matter when millions hang in the balance, delivering dedicated supercomputers tucked inside cloud infrastructure that anyone can rent by the hour.
- Amazon Web Services created cloud-native innovation from scratch. AWS engineered the Scalable Reliable Datagram (SRD), a custom transport protocol running over their massive Ethernet infrastructure. Resilience comes first in their world. Consistent tail-latency follows as a natural consequence. AWS masks the chaos of multi-tenant environments through sophisticated software orchestration combined with custom hardware integration that competitors struggle to replicate.
- Oracle Cloud Infrastructure entered as an aggressive challenger with everything to prove. Price-performance became their weapon of choice, their path to victory against entrenched giants. OCI mastered the infamous complexities of RDMA over Converged Ethernet (RoCEv2), turning theoretical advantages into production reality. Workload-aware engineering drives their results, delivering performance rivaling specialized fabrics while building on cost-effective, standards-based foundations that democratize access to cutting-edge AI infrastructure.
- Meta Platforms operates at market-shaping scale that few can comprehend. Their dual-fabric strategy deploys both InfiniBand and RoCEv2 clusters across massive data centers spanning continents. Scale changes everything at Meta's level—supply chains get managed with surgical precision, costs stay controlled through ruthless optimization, strategic options multiply across complex vendor relationships that smaller players can't access.
Strategic Insight: Your AI fabric choice reveals everything about your organization. Technical preferences tell one story. Market position shows another. Your operational philosophy emerges clearly when infrastructure decisions get made under pressure, revealing risk tolerance that might otherwise stay hidden, exposing long-term strategic ambitions that boardroom presentations try to conceal. Understanding these approaches gives you frameworks that matter—frameworks for making build-or-buy decisions that will define your capabilities in next-generation artificial intelligence infrastructure for years to come.
Section 1: The Technical Foundation - How AI Communication Actually Works
Grasp the core technologies first. Provider strategies make zero sense without fundamentals locked down. These concepts define the vocabulary you'll need, revealing physical constraints that can't be engineered away, exposing the brutal realities facing anyone building large-scale AI systems.

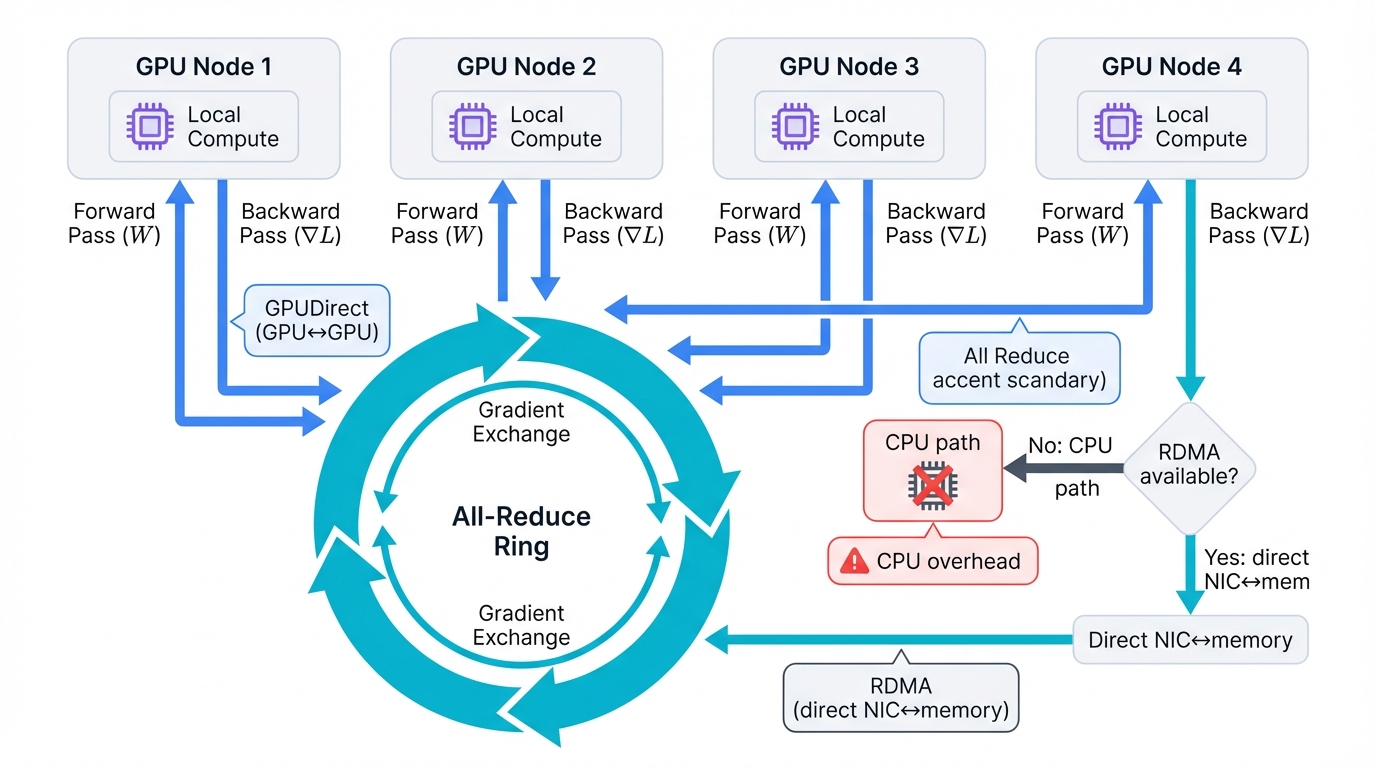
The fundamental challenge hits everyone the same way: make tens of thousands of independent processors communicate and coordinate like one unified, coherent computer.
Extraordinary demands hit your interconnect fabric from every direction simultaneously.
RDMA: Why Traditional Networking Fails AI
Remote Direct Memory Access forms the cornerstone of everything. Modern high-performance interconnects depend on it absolutely. This isn't just another networking protocol you can swap out—it represents a fundamental architectural shift in how machines talk to each other.
RDMA lets machines talk directly, cutting out middlemen that slow everything down. One machine's network interface card reads directly from another's memory. Direct writes work too. No operating systems get involved in the transaction. No kernel buffers copy data back and forth. No CPUs waste cycles on either host handling network traffic.
You eliminate wasteful data copies that plague traditional approaches. Context switches disappear entirely from the critical path. Traditional TCP/IP networking gets absolutely crippled by these exact problems, creating overhead that multiplies catastrophically at scale. The result becomes crystal clear when you measure it: dramatically lower latency combined with massively reduced CPU overhead that frees processors for actual computation.
Consider distributed deep learning's brutal reality that every AI team faces daily. Training follows bulk-synchronous parallel patterns burned into the architecture. GPUs compute on local data shards through forward passes, crunching numbers at teraflop speeds. Backward passes follow in lockstep. Then the communication phase begins—the moment when everything either works beautifully or falls apart completely—as every GPU exchanges gradients with every other GPU scattered across the cluster.
Communication Pattern: Collective operations absolutely dominate this critical phase of training. All-Reduce aggregates gradients from all workers simultaneously, a choreographed dance of data movement. Distribution sends the calculated sums back to everyone who needs them. These operations create frequent exchanges that never stop, flooding the network with many small messages traveling constantly between thousands of endpoints.
Imagine the disaster scenario. Your host CPU must process each individual message packet as it arrives, creating an immediate bottleneck that throttles everything downstream. Powerful GPUs worth tens of thousands of dollars each sit completely idle, starved for the data they need to continue computation. CPUs struggle desperately with network overhead while expensive silicon waits, burning power and producing nothing.
GPUDirect RDMA extends this revolutionary principle even further into the future. Network interfaces transfer data directly between GPU memory on physically remote machines, bypassing bottlenecks entirely. Host system main memory gets bypassed completely, never touching the data racing past. The ultimate goal emerges clearly: create a direct, blazing-fast path between network fabric and accelerator hardware that eliminates every unnecessary hop, every wasted nanosecond.
InfiniBand: Purpose-Built for Performance
InfiniBand was born different from everything that came before. A complete, end-to-end fabric designed specifically and exclusively for supercomputing workloads. Every single design decision prioritized raw performance above all else. Reliability mattered equally in this carefully balanced equation. Unlike Ethernet's messy evolutionary development over decades, InfiniBand chose purpose-built paths from day one, creating natively lossless networks that HPC and AI workloads could depend on absolutely, never compromising performance for compatibility.
The critical architectural feature changes everything about how the network operates: credit-based flow control implemented at the link layer itself. Senders must know exactly how much receiver buffer space sits available before transmitting even a single packet. Receivers grant "credits" to senders in a carefully orchestrated protocol. Senders consume precisely one credit per packet sent into the network.
No credits available? Sender waits patiently.
This elegant mechanism creates networks that are natively lossless by design rather than accident. Packets literally never drop due to congestion anywhere within the fabric—a guarantee that traditional networks can't make. High-latency retransmission penalties that plague other approaches simply disappear from the equation. This fundamental design choice explains InfiniBand's legendarily predictable performance, delivering ultra-low latency with remarkable consistency, often achieving the holy grail of 1-2 microseconds end-to-end.
Management Advantage: InfiniBand management differs fundamentally from Ethernet's distributed chaos where nobody's really in charge. A centralized Subnet Manager controls everything that happens, making decisions that keep the entire fabric humming. A dedicated host runs it in production deployments. Switch embedding works too for smaller installations. The SM discovers complete network topology automatically, assigns local identifiers to every endpoint systematically, distributes carefully calculated forwarding tables to every switch in the fabric.
Advanced HPC features come built-in from the factory, not bolted on afterward as afterthoughts. Adaptive Routing lets switches dynamically reroute packets around congested links in real-time, responding to changing traffic patterns instantly. Traffic hotspots get rapid response measured in microseconds, not seconds. In-Network Computing capabilities like the impressively named Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) enable switches to perform collective operations themselves, offloading work from endpoints and accelerating common patterns.
High-Performance Ethernet: The Challenger's Complex Gambit
Ethernet dominated data centers through a completely different playbook. Openness drove unprecedented success across industries. Massive vendor ecosystems helped drive costs down relentlessly. Superior economies of scale won decisively against proprietary alternatives. InfiniBand focused laser-like on raw performance metrics. Ethernet conquered through sheer market share and ubiquity. Cost advantages sealed victory after victory.
But competing for high-performance workloads required serious innovation, not just cost leadership. The Ethernet ecosystem developed RDMA over Converged Ethernet (RoCE) to bridge the performance gap. The current standard everyone deploys—RoCEv2—encapsulates InfiniBand transport packets within standard UDP/IP packets through clever engineering. This brilliant design routes RDMA traffic over standard Layer 3 Ethernet networks that already exist everywhere.
You suddenly leverage vast installed bases worth billions. Ethernet switches already purchased work perfectly. Routers deployed years ago function without replacement. Operational expertise cultivated over decades transfers directly. RoCEv2's primary advantage becomes overwhelmingly clear when you calculate total cost: deliver InfiniBand-level performance benefits without requiring separate, proprietary network fabric investments that CFOs hate funding.
But this seemingly elegant solution creates formidable engineering challenges that keep network architects awake at night. RDMA protocols fundamentally assume lossless networks where packets never vanish. Packet drops simply can't be handled gracefully by protocols designed for perfect reliability. Meanwhile, Ethernet operates as inherently lossy by original design philosophy. "Best-effort" networking defines its entire architecture from the ground up. Switch buffers inevitably fill beyond capacity under heavy load. Packets get ruthlessly dropped.
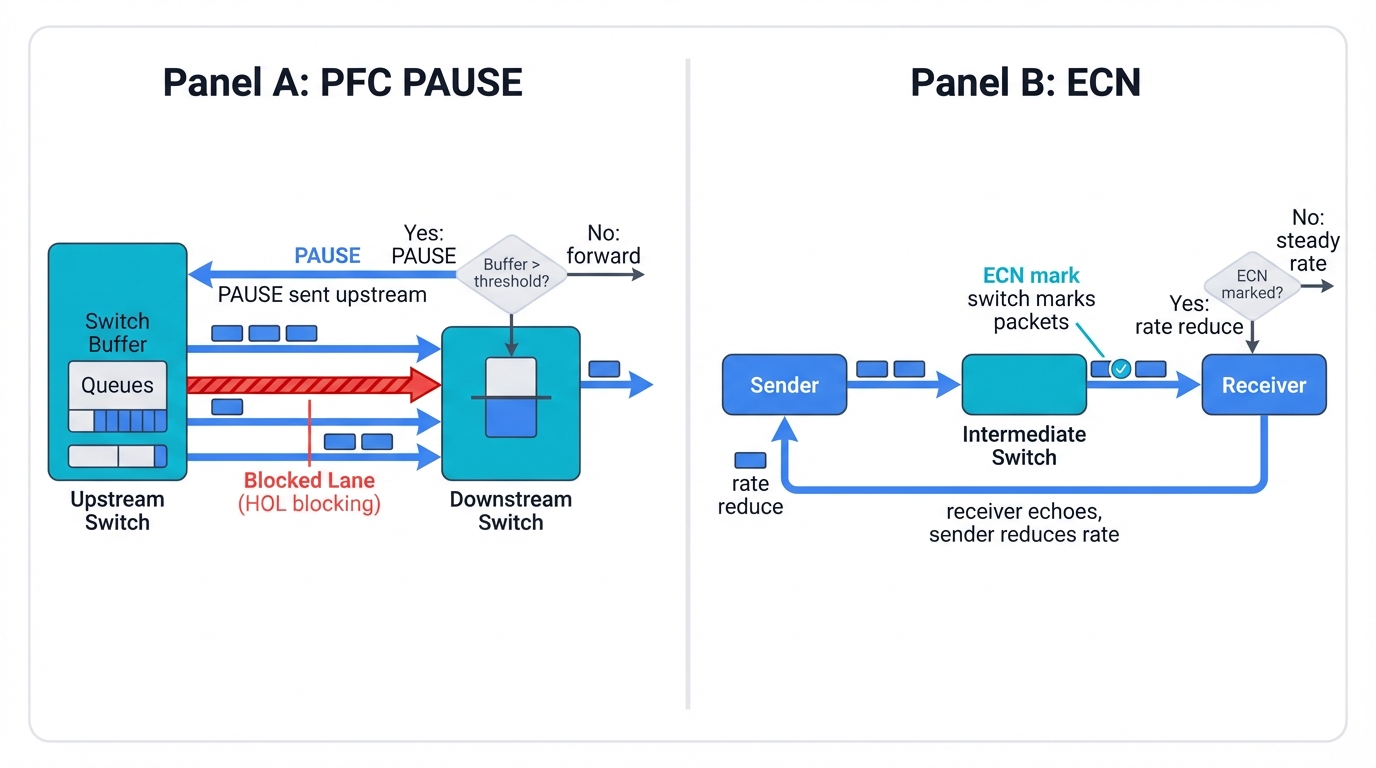
Engineering Challenge: Supporting RoCEv2 effectively requires completely transforming your network's fundamental behavior. Your Ethernet fabric must somehow become artificially lossless through careful engineering and constant vigilance. Two key mechanisms attempt this seemingly impossible transformation: Priority Flow Control (PFC) and Explicit Congestion Notification (ECN), each with their own complexities and failure modes.
Priority Flow Control (PFC): The IEEE 802.1Qbb standard enables switches sending PAUSE frames upstream to connected devices. Buffer capacity approaching dangerous limits for specific traffic classes triggers this emergency brake. Buffer overflows get prevented through brute force. Packet loss disappears in theory. But PFC becomes an incredibly blunt instrument in practice, causing collateral damage everywhere—the dreaded "head-of-line blocking" emerges when pausing one congested flow inadvertently blocks completely unrelated flows destined for entirely different ports.
Explicit Congestion Notification (ECN): A far more sophisticated mechanism provides proactive congestion signaling to endpoints. Traffic flows continue moving forward without hitting the brakes. Buffer occupancy exceeds carefully configured thresholds. Switches mark special bits in IP headers as packets pass through. Receivers echo these warning marks back to senders immediately. Transmission rates reduce accordingly before disaster strikes.
The fundamental AI networking conflict you're witnessing transcends simple "InfiniBand versus Ethernet" technology debates that miss the deeper point entirely. A much deeper philosophical divide emerges when you dig into architectural assumptions: "natively lossless by design" versus "engineered lossless through constant effort."
Section 2: Cloud Provider Case Studies
Microsoft Azure: The HPC Heritage Strategy
Microsoft Azure leverages literal decades of hard-won high-performance computing expertise. Their battle-tested approach prioritizes proven performance over experimental innovation that might fail spectacularly. Azure's AI infrastructure philosophy crystallizes into one clear statement: deliver supercomputer-class capabilities within cloud environments that anyone can access.
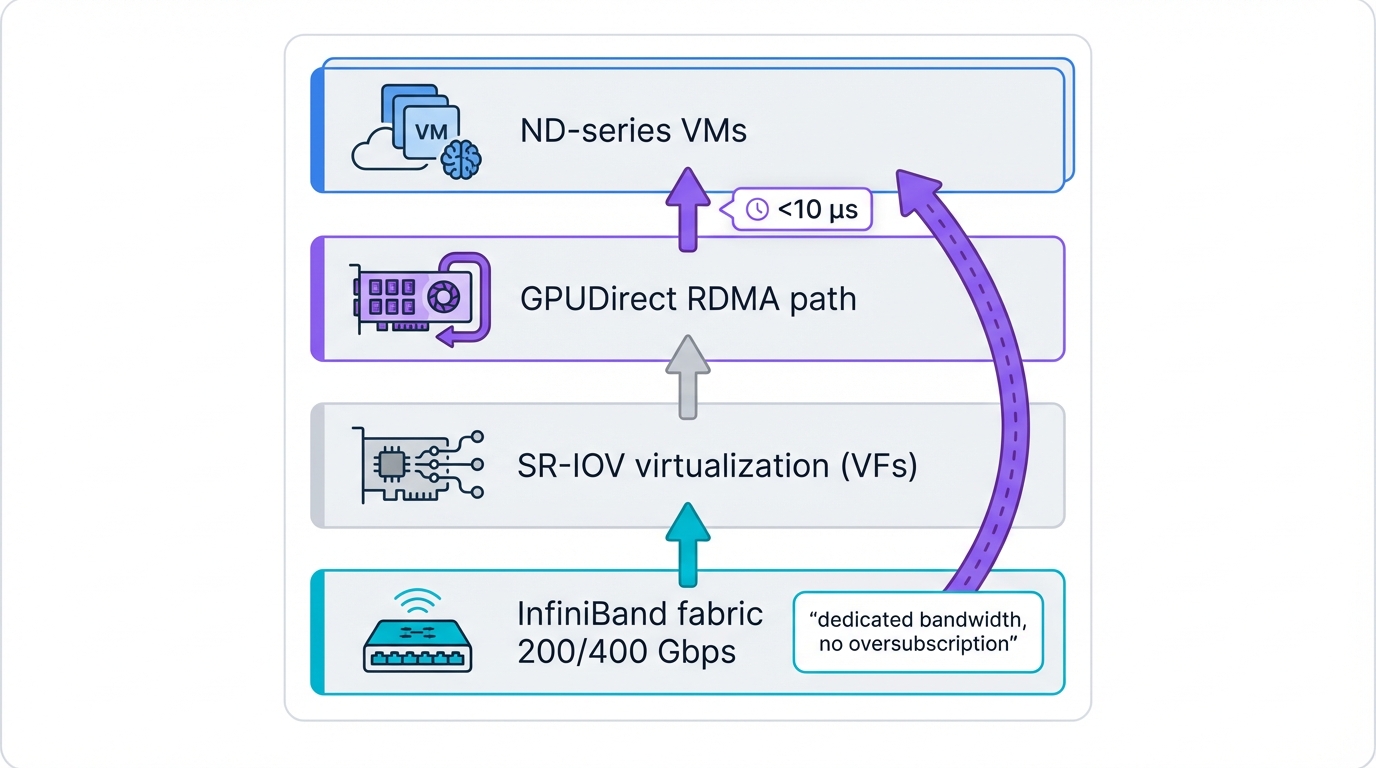
Azure's flagship AI infrastructure centers entirely on InfiniBand-based supercomputers that would make traditional HPC centers jealous. The ND-series virtual machines provide customers with direct access to screaming-fast NVIDIA InfiniBand networks. These aren't shared, virtualized connections that degrade under load—they're dedicated, high-performance fabric access designed explicitly for the most demanding AI workloads imaginable.
Technical Architecture: Azure NDv2 instances connect via blazing 200 Gbps Mellanox HDR InfiniBand that moves data faster than most can comprehend. Later generations deploy even more impressive 400 Gbps NDR InfiniBand pushing physical limits. Each virtual machine receives dedicated bandwidth that never gets shared. Zero oversubscription. Zero compromises. This uncompromising approach guarantees predictable performance for large-scale training jobs where consistency matters more than peak theoretical speeds.
Key Innovation: Azure's InfiniBand implementation includes genuinely advanced features like SR-IOV virtualization and GPUDirect RDMA working in perfect harmony. Virtual machines access InfiniBand hardware directly without translation layers slowing things down. Hypervisor overhead simply disappears from the critical path. GPU-to-GPU communication across physically separate nodes achieves almost unbelievable sub-10 microsecond latencies that enable new algorithmic approaches.
Operational Model: Azure treats AI supercomputers as fundamentally distinct products from their general cloud offerings. Customers reserve entire clusters for exclusive use. Dedicated access periods guaranteed by contract. Absolutely no multi-tenancy complications or noisy neighbor problems. This model suits organizations requiring maximum performance and total predictability, willing to pay premium prices for premium capabilities.
Security Approach: Azure implements multiple overlapping security layers that work together seamlessly. InfiniBand partitioning strictly isolates customer traffic from other tenants. Network-level encryption protects sensitive data racing through cables. Physical security controls carefully restrict access to specialized hardware worth millions sitting in secure facilities.
Amazon Web Services: Custom Innovation at Scale
AWS pioneered genuinely cloud-native AI infrastructure from first principles. Their guiding philosophy drives everything: engineer custom solutions that work flawlessly at massive scale while somehow maintaining cloud economics that shareholders demand. AWS doesn't simply deploy existing HPC technologies unchanged like some cloud providers—they fundamentally reinvent them for cloud environments where different rules apply.
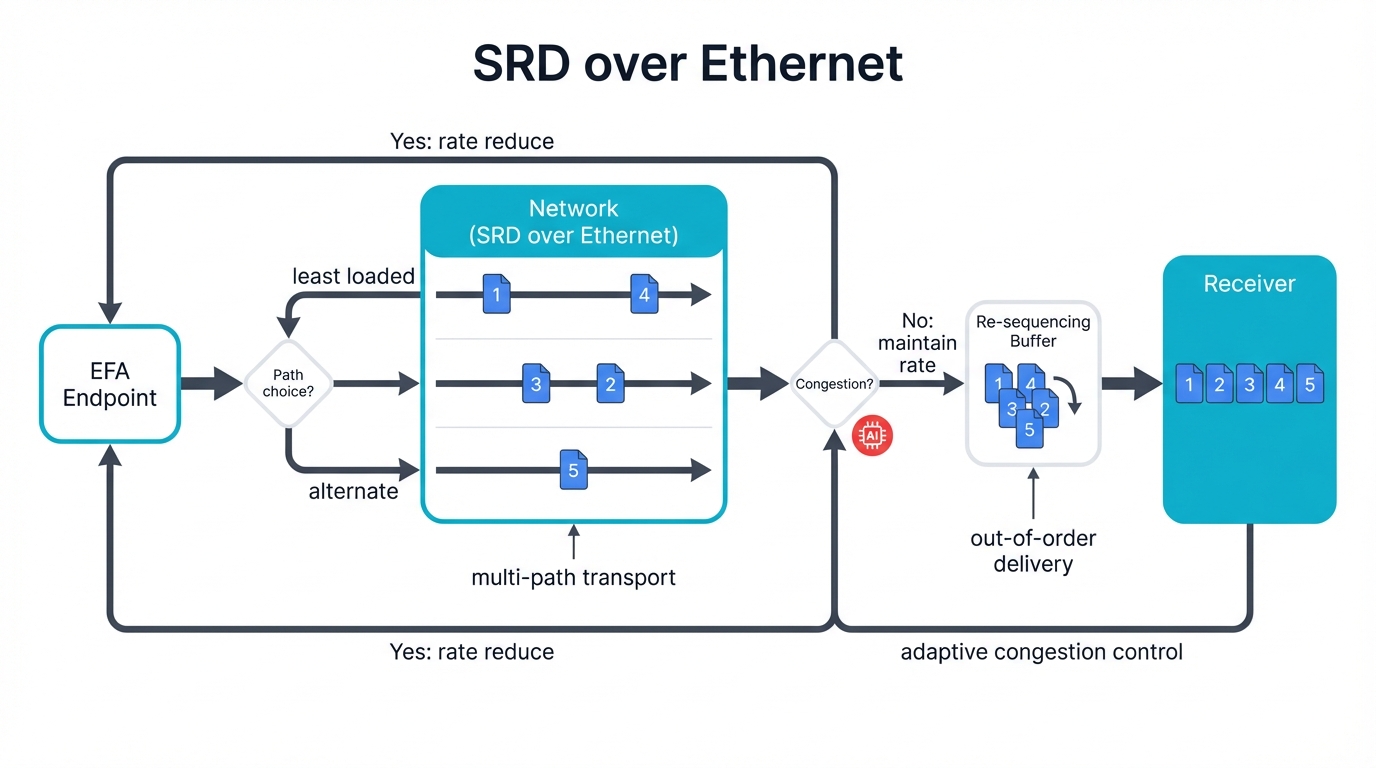
Scalable Reliable Datagram (SRD): AWS developed custom transport protocols from scratch specifically for their innovative Elastic Fabric Adapter (EFA) hardware. SRD runs over standard Ethernet infrastructure everyone already owns but somehow provides RDMA-like performance that rivals proprietary solutions. This audacious approach leverages AWS's absolutely massive Ethernet investments built over decades while simultaneously delivering specialized capabilities that customers desperately need.
SRD's key innovations include genuinely novel approaches:
- Multi-path Transport: Single logical connections automatically and transparently use multiple physical paths through the network. Path failures become completely invisible to applications. Performance remains rock-solid consistent even as underlying infrastructure changes.
- Out-of-Order Delivery: SRD brilliantly decouples reliability from strict ordering requirements. Packets arrive whenever they manage to arrive. Higher-level protocols handle proper sequencing when needed. This clever design completely eliminates the head-of-line blocking that plagues traditional approaches.
- Adaptive Congestion Control: SRD continuously monitors network conditions in real-time with microsecond precision. Transmission rates adjust automatically to changing conditions. No manual tuning required from operators who have better things to do.
Scale Achievement: AWS operates some of the world's genuinely largest AI training clusters using SRD technology at mind-boggling scale. Their custom approach successfully scales to tens of thousands of individual nodes while somehow maintaining cloud-grade reliability and enterprise security that regulated industries require.
Integration Strategy: EFA integrates seamlessly with AWS services customers already use daily. Security groups control network access with familiar policies. IAM policies manage permissions through existing frameworks. CloudWatch provides comprehensive monitoring and alerting. This deep integration dramatically simplifies operations while maintaining stringent enterprise security requirements that auditors demand.
Oracle Cloud Infrastructure: The Price-Performance Disruptor
Oracle entered the brutally competitive AI infrastructure market as an aggressive challenger with nothing to lose. Their audacious strategy crystallizes clearly: deliver genuinely premium performance at commodity prices using standards-based technologies that anyone can adopt. OCI proves definitively that careful, thoughtful engineering can make RoCEv2 legitimately competitive with specialized fabrics costing far more.
RoCEv2 Mastery: OCI implemented one of the entire industry's most sophisticated RoCEv2 deployments through years of painful refinement. Their bare metal instances provide customers with completely direct access to cluster networking without any virtualization overhead slowing things down. Customers control the entire network stack from top to bottom, tuning parameters that other clouds hide behind abstraction layers.
Technical innovations include breakthrough achievements:
- Non-blocking Fabric: Full bisection bandwidth available between any arbitrary nodes in the cluster. Absolutely zero oversubscription at any network layer, no matter how you slice it.
- Ultra-low Latency: Sub-2 microsecond node-to-node communication that competitors struggle to match. Genuinely competitive with InfiniBand performance despite using commodity Ethernet.
- Lossless Operation: Sophisticated PFC and ECN tuning developed through extensive trial and error completely eliminates packet loss. Rock-solid reliable performance for demanding workloads that can't tolerate failures.
Cost Innovation: OCI's bare metal approach eliminates expensive virtualization licensing costs that plague other providers. Customers pay only for actual compute resources consumed. Network performance comes included in the base price. This innovative model significantly reduces total AI infrastructure costs compared to traditional cloud offerings charging premium prices.
Operational Complexity: OCI's powerful approach requires genuinely sophisticated network management expertise that many teams lack. Customers must deeply understand RoCEv2 configuration subtleties and failure modes. Performance tuning becomes absolutely critical rather than optional. This unavoidable complexity naturally limits adoption to organizations with advanced networking expertise and dedicated infrastructure teams.
Meta Platforms: Scale-Driven Dual Strategy
Meta operates AI infrastructure at unprecedented scale that most organizations literally can't comprehend. Their battle-tested approach combines ruthlessly pragmatic technology choices with absolutely massive engineering investment measured in billions. Meta's operational philosophy drives everything: use the demonstrably best technology for each specific use case while carefully maintaining strategic vendor relationships that provide leverage.
Dual-Fabric Architecture: Meta strategically deploys both InfiniBand and RoCEv2 clusters across their global infrastructure. InfiniBand clusters support ultra-demanding research workloads pushing boundaries. RoCEv2 clusters handle production training at truly massive scale. This intentionally hybrid approach provides both crucial technical flexibility and strategic options that single-technology deployments can't match.
Key architectural decisions reveal their thinking:
- InfiniBand Clusters: Cutting-edge NVIDIA-based supercomputers dedicated to frontier research exploring unknown territory. Maximum possible performance for rapid model development and experimentation.
- RoCEv2 Clusters: Commodity Ethernet hardware deployed at scale for production training of proven models. Highly cost-effective scaling for known workloads with understood characteristics.
- Workload Optimization: Different cluster types specifically optimized for fundamentally different use cases. Research versus production representing distinct trade-offs. Exploration versus exploitation in the classic machine learning sense.
Supply Chain Strategy: Meta's extraordinary scale enables unique vendor relationships that competitors simply can't access. Multiple diverse suppliers prevent dangerous single points of failure. Competitive pricing through carefully cultivated vendor diversity that creates bidding pressure. Technology risk mitigation spread across fundamentally different approaches that can't all fail simultaneously.
Innovation Contribution: Meta contributes extensively and continuously to open-source AI infrastructure projects that benefit everyone. Their hard-won innovations benefit the entire industry rather than staying locked behind walls. This generous approach simultaneously builds thriving ecosystems while advancing Meta's own demanding technical requirements through community collaboration.
Operational Excellence: Meta developed genuinely sophisticated automation for managing clusters at absolutely massive scale. Infrastructure-as-code approaches that treat servers like cattle, not pets. Automated troubleshooting that fixes problems before humans notice. Predictive maintenance that replaces components before they fail catastrophically. These carefully developed capabilities enable remarkably reliable operation at unprecedented scale that would be impossible to manage manually.
Section 3: Strategic Implications and Future Directions
The cloud provider case studies we've examined reveal fundamental strategic choices that will absolutely define AI infrastructure's future trajectory. Each distinct approach reflects radically different priorities, vastly different capabilities, and completely different market positions that shape every decision.
Technology Philosophy Divergence
Proven vs. Innovative: Microsoft Azure's InfiniBand strategy deliberately prioritizes proven technology and utterly predictable performance. AWS's custom SRD approach emphasizes relentless innovation and cloud-native optimization. These competing philosophies target fundamentally different customer needs and vastly different risk tolerances that shape purchase decisions.
Specialized vs. General-Purpose: Oracle's impressive RoCEv2 expertise demonstrates convincingly that general-purpose technologies can achieve specialized performance through sufficiently careful engineering. Meta's sophisticated dual approach suggests strongly that multiple technologies may peacefully coexist rather than one eventually dominating completely.
Economic Model Implications
Each provider's technical choices directly reflect their underlying economic models:
- Azure: Premium pricing justified by premium performance. Dedicated resources command substantially higher margins that shareholders appreciate.
- AWS: Custom technology creates powerful differentiation and profitable vendor lock-in. Proprietary advantages enable significant pricing power in competitive markets.
- Oracle: Commodity technology enables aggressive pricing that disrupts comfortable incumbents. Market disruption through relentless cost leadership.
- Meta: Massive scale enables substantial custom engineering investment that others can't afford. Strategic vendor relationships dramatically reduce costs and mitigate risks.
Security Architecture Patterns
AI infrastructure security demands entirely new approaches that traditional models can't provide:
Physical Isolation: Azure's dedicated cluster approach provides exceptionally strong security through complete physical separation. Particularly suitable for highly sensitive workloads handling regulated data.
Logical Isolation: AWS's cloud-native approach relies on sophisticated logical isolation implemented in software and hardware. Highly scalable approach but requires extremely careful implementation to avoid vulnerabilities.
Hardware Security: Next-generation solutions will integrate security features directly into silicon itself. Authenticated telemetry that can't be spoofed. Encrypted control planes protecting management traffic. Tamper-resistant operations that detect and respond to attacks.
Emerging Threats: AI infrastructure faces entirely new attack vectors specifically targeting training processes, enabling model theft, and causing performance degradation. Traditional security models prove woefully inadequate for these highly specialized threats that attackers actively develop.
Future Technology Trends
Several powerful trends will dramatically shape AI networking's evolution:
Ultra Ethernet Consortium: Major industry effort to create genuinely open, high-performance Ethernet standards. Could seriously challenge InfiniBand's longstanding performance advantage while carefully maintaining Ethernet's massive ecosystem benefits and vendor diversity.
Optical Interconnects: Silicon photonics and advanced optical technologies promise bandwidth improvements far beyond fundamental electrical limits. Absolutely critical for future model scales that will dwarf today's largest systems.
In-Network Computing: Network hardware performing AI operations directly without moving data to processors. Dramatically reduced data movement and substantially improved efficiency for specific workloads with favorable characteristics.
Quantum Networking: Long-term potential for quantum-secured communications that can't be intercepted. Quantum-enhanced algorithms that might revolutionize optimization problems.
Strategic Recommendations
Organizations planning AI infrastructure investments should carefully consider:
Workload Analysis: Different workloads have fundamentally different requirements that demand different solutions. Research, development, and production may benefit from completely different technologies rather than one-size-fits-all approaches.
Scale Planning: Current solutions may not scale to future requirements as models grow. Carefully consider technology evolution trajectories and realistic migration paths that won't strand investments.
Vendor Strategy: Carefully balance specialization benefits against dangerous vendor lock-in risks. Multi-vendor approaches provide valuable flexibility but significantly increase operational complexity.
Security Integration: Plan comprehensive security from the very beginning rather than expensively retrofitting protection later. AI workloads face unique threats requiring specialized defenses that general security tools miss.
Competitive Advantage: AI infrastructure becomes a genuine source of sustainable competitive advantage in knowledge-intensive industries. Organizations making informed technology choices today will benefit throughout the entire AI revolution. Those making poor choices will face years of painful technical debt and serious competitive disadvantage.
The fabric of intelligence continues evolving rapidly every single day. Understanding exactly how industry leaders architect these enormously complex systems provides crucial insights for your own AI infrastructure decisions that will echo for years. The stakes continue rising inexorably as AI becomes absolutely central to business success across every industry.
Example Implementation
# Example: Neural network architecture
import torch
import torch.nn as nn
import torch.nn.functional as F
class SecureNeuralNetwork(nn.Module):
"""Neural network with security features"""
def __init__(self, input_dim, hidden_dim, output_dim):
super(SecureNeuralNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.dropout = nn.Dropout(0.5) # Prevent overfitting
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
# Input validation layer
self.input_norm = nn.BatchNorm1d(input_dim)
def forward(self, x):
# Normalize inputs for security
x = self.input_norm(x)
# Forward pass with dropout
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return F.log_softmax(x, dim=1)