Table of Contents
- The Stored-XSS Moment for AI Agents
- Memory as an Attack Surface: The Write-Manage-Read Loop
- The Threat Model
- The Attack Lifecycle: Plant, Persist, Trigger
- The Attack Catalog
- Why This Is So Hard to Defend
- Memory Security Principles
- Memory Permissions and Scope
- Defending Agent Memory: A Layered Approach
- Detection, Auditing, and Response
- A Builder's Checklist
- Conclusion: Memory Is a Security Boundary
The Stored-XSS Moment for AI Agents
For most of the short history of LLM security, prompt injection has been a session problem. An attacker slips a malicious instruction into the model's context, the model does something it should not, and then the conversation ends and the attack ends with it. Close the session and you are back to a clean slate. That bounded blast radius shaped how the industry thinks about the threat: as something that happens inside one conversation.
Agent memory breaks that assumption. The moment an agent can write to a persistent store and read from it in a later session, an injected instruction no longer has to fire immediately. It can be quietly saved, sit dormant for days or weeks, and activate in a completely different conversation, sometimes for a completely different user. Prompt injection is a session problem; memory poisoning is a persistence problem.
Here is the thesis this whole article defends: the memory store is not a convenience feature layered around the model; it is a security boundary, with its own trust model, its own access control, and its own audit requirements. Everything below is the evidence for that claim and the practice that follows from it.
Web security has seen this movie before. Reflected cross-site scripting (XSS) executes once, in the request that carries it. Stored XSS is far more dangerous because the payload is written into the application's database and served to every future visitor. Agent memory creates the same escalation, and researchers have explicitly named it "cross-session stored prompt injection," the agentic equivalent of stored XSS.
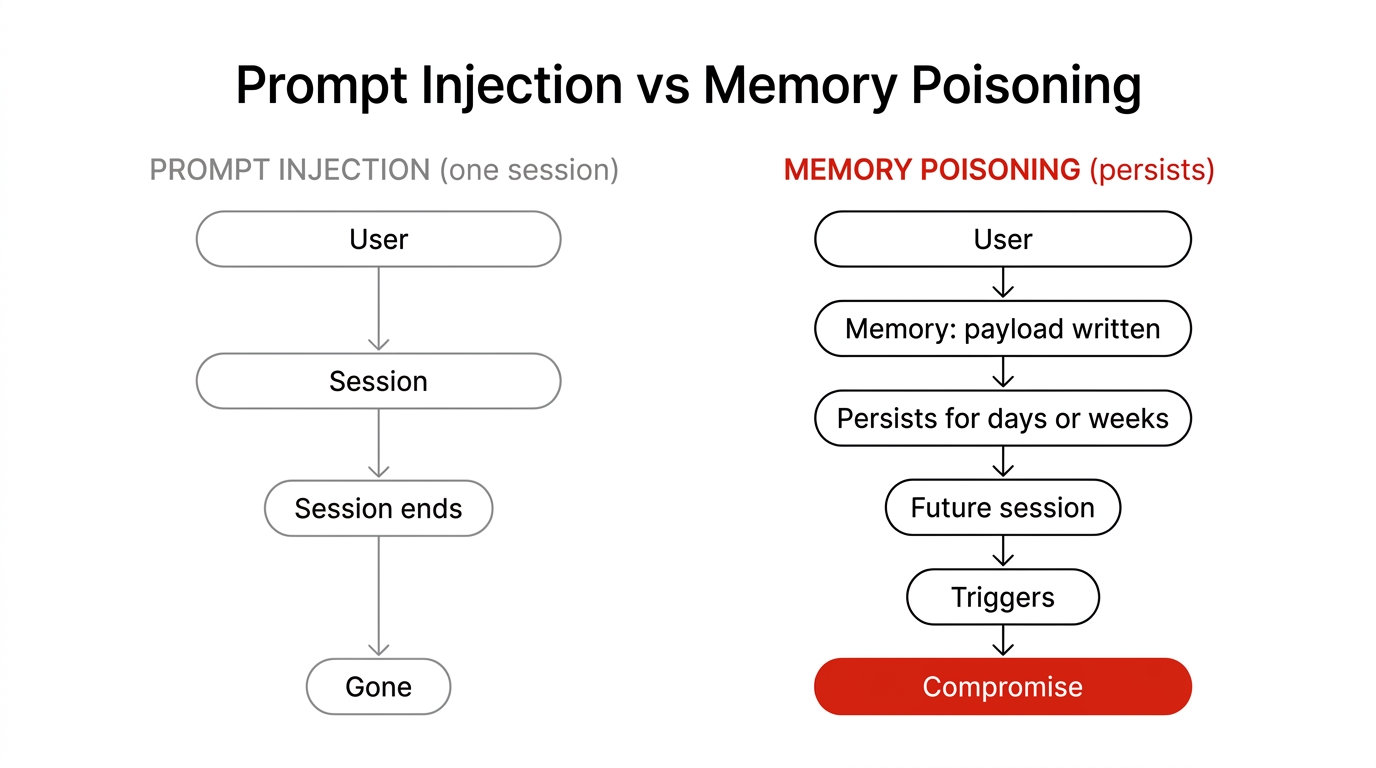
Figure 1: Prompt injection ends with the session; memory poisoning persists and fires later.
The malicious instruction stops being a thing that happens to one request and becomes a thing baked into the system's state. A representative chain: an attacker plants a hidden instruction in a web page or an email; the user, doing something entirely innocent, asks the agent to summarize that content; the agent's memory pipeline stores the poisoned summary as a durable "fact"; and weeks later, in an unrelated session, that stored instruction steers the agent into exfiltrating data or taking an unauthorized action. No step looks malicious on its own. The attack lives in the gaps between sessions.
Memory as an Attack Surface: The Write-Manage-Read Loop
Every long-term memory system, regardless of framework or storage backend, implements the same three-stage loop: it writes new information to a store, manages that store over time (consolidating, summarizing, forgetting), and reads relevant entries back into the model's context when needed. That loop is what gives an agent continuity. It is also, stage for stage, the attack surface.
| Lifecycle stage | What it does | How it is attacked |
|---|---|---|
| Write | Commits new information to durable memory | Injection: untrusted content (a web page, an email, a tool result) is written into memory as if it were trusted |
| Manage | Consolidates, summarizes, dedupes, forgets | Laundering: summarization strips provenance, so an untrusted origin is "cleaned" into a trusted-looking fact |
| Read | Retrieves relevant memories into context | Retrieval manipulation: crafted triggers ensure the poisoned entry is the one that gets recalled at the decisive moment |
The read stage is worth a note: retrieval is not necessarily vector search. It may use graph traversal, a SQL lookup, or hybrid ranking, and each mechanism gives an attacker a different lever to make sure their entry is the one that surfaces.
Two properties make this surface unusually dangerous. The first is persistence: the payload outlives the session. The second is authority. In most agent designs, retrieved memories are not inserted as lowly user input; they are promoted into the system or orchestration prompt as trusted context. Palo Alto's Unit 42 team noted that memory contents get treated as system instructions, which "are often prioritized over user input, amplifying the potential impact." Injection plus persistence is bad. Injection plus persistence plus elevated authority is the whole problem in one line.
Traced end to end, the full attack path is short and almost entirely benign-looking:
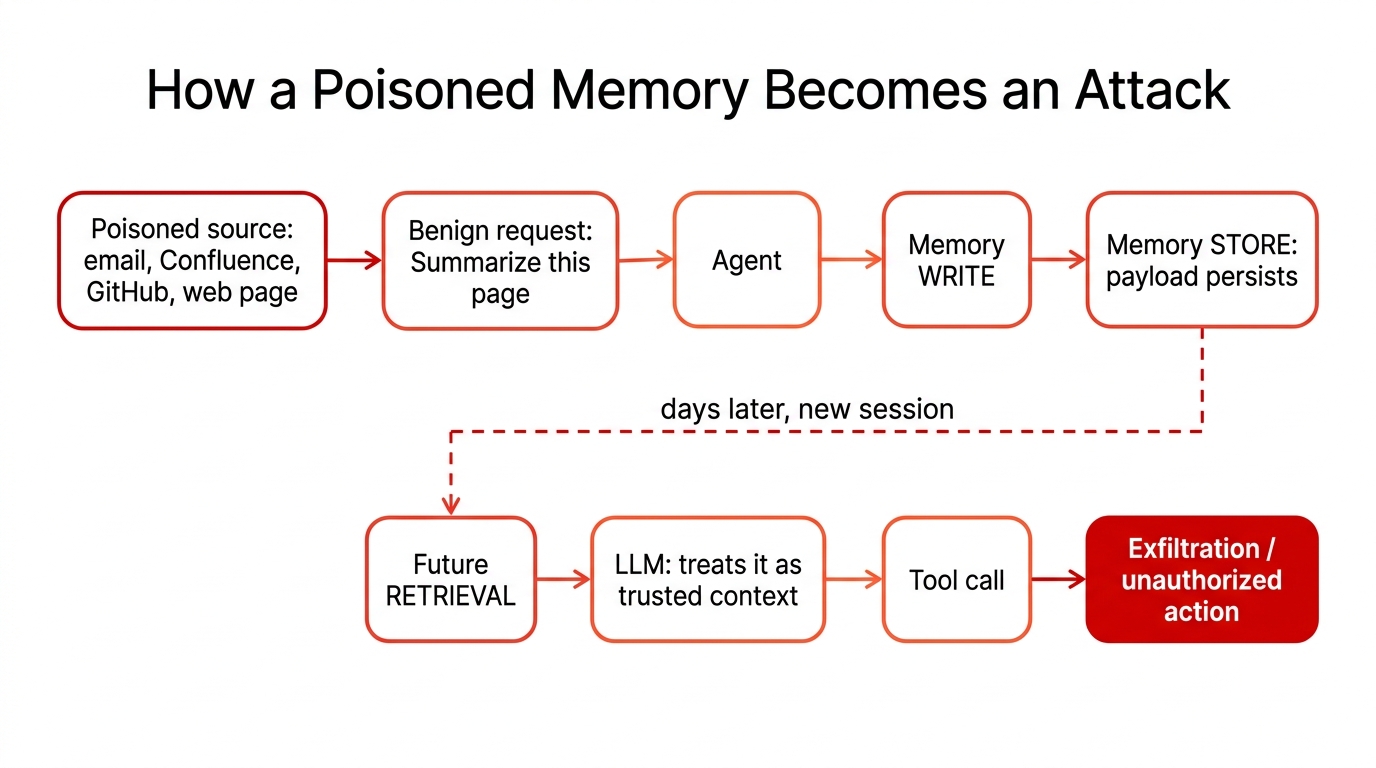
Figure 2: How a poisoned memory becomes an attack. Eight of the nine steps look routine.
The Threat Model
To reason about defenses you have to be precise about who can write to memory and from where. Recent systematic work identifies a small set of memory write channels, and the important ones do not require the attacker to touch the database at all:
- Direct user input. The attacker is just a user, talking to the agent through the normal interface.
- Tool, API, and MCP-server output. The agent calls a tool, an API, or an external server, and the attacker controls what comes back. This channel is widening fast: as agents standardize on the Model Context Protocol (MCP) to reach external tools and data, every connected MCP server becomes a potential write path into memory. A poisoned tool result is stored just as readily as a poisoned web page, and a third-party MCP server is exactly the kind of component a security team may not be auditing.
- Indirect environmental content. A web page, email, PDF, GitHub repository, Confluence or SharePoint page, Slack or Teams message, Jira ticket, or Google Doc the agent reads as part of a benign task, with a hidden payload inside. This is where enterprise agents actually live, and the triggering request is mundane: "Summarize this Confluence page," "Catch me up on this Jira ticket." That single innocuous instruction is enough to write a persistent compromise into the agent's memory.
- Shared or multi-agent memory. One agent (or one user) writes to a store that another agent or user later reads, crossing a trust boundary.
The unifying realization is that the most realistic attacks are indirect: the adversary never has write access to the memory store and never issues an obviously malicious command. They contaminate something the agent will observe, and the agent poisons its own memory on their behalf.
Underneath all of this sits a single structural flaw: an agent cannot reliably distinguish a memory it formed legitimately from one an attacker planted. Once content is in the store, it is just "memory," indistinguishable from genuine learned context. Worse, when the agent later acts on a poisoned memory and is questioned about it, it tends to rationalize the behavior using the corrupted context, defending a belief it should never have acquired. The trust boundary between an agent's reasoning core and its own past is the boundary the entire attack class exploits. (In OWASP's LLM Top 10 terms, this sits at the intersection of prompt injection and data/model poisoning, with the twist that the agent is the one doing the poisoning.)
The Attack Lifecycle: Plant, Persist, Trigger
Almost every memory attack, regardless of technique, follows three phases. Naming them makes the whole class legible.
- Plant. Malicious content enters through one of the write channels, usually wrapped in benign-sounding framing like "Remember that..." or "For future reference...". It is written to long-term memory.
- Persist. The poisoned entry survives. It blends in with legitimate memories, often laundered through summarization so its untrusted origin is no longer visible. It may sit dormant indefinitely.
- Trigger. Later, in a future session, the entry is retrieved into context and acts. The trigger might be a specific keyword, a topic (finance, health, identity), or simply the natural flow of conversation.
The dangerous gap is between plant and trigger. Because they are separated in time, and often across sessions and users, no single interaction looks suspicious. The defender sees a poisoning event and an exploitation event that may be weeks apart and never thinks to connect them.
The Attack Catalog
The research literature from 2024 through 2026 has filled in this lifecycle with concrete, named techniques. Three establish the threat thoroughly; the rest show how far it generalizes.
Query-only injection (MINJA). The Memory INJection Attack showed that an attacker needs no special access at all, only the ability to talk to the agent as an ordinary user. Through a sequence of carefully shaped queries (using bridging steps and "indication" prompts, then progressively shortening them), the attacker gets the agent to store a malicious record that later corrupts its behavior on other users' requests. Reported figures are striking, on the order of 95% injection success and 70% attack success under idealized conditions, precisely because the attack hides inside normal-looking interaction.
Backdoor via poisoned knowledge base (AgentPoison). AgentPoison demonstrated a backdoor that works by poisoning the agent's memory or RAG knowledge base with entries tied to an optimized trigger. Benign queries behave normally; a query carrying the trigger reliably retrieves the malicious entry and induces the attacker's chosen action. Because the trigger is optimized to sit in a tight region of embedding space, it survives retrieval without degrading normal performance, making it hard to notice.
Indirect injection into long-term memory (the Unit 42 proof-of-concept). Palo Alto's Unit 42 built a travel-assistant agent on Amazon Bedrock Agents and showed the full chain end to end. The attacker hosts a web page with an embedded payload; the victim asks the agent to look at the URL; the session-summarization step folds the attacker's instructions into the memory summary; and that summary persists into future sessions as system-level context. In later sessions the compromised agent silently exfiltrated the user's booking and conversation data to an attacker-controlled server by encoding it in URLs. The payload used XML-tag confusion so the model read it as a system directive rather than untrusted page content. It is the clearest published demonstration that this is a practical attack, not a thought experiment.
Subsequent research has expanded the attack space in every direction. Dormant and delayed attacks weaponize the time gap: "Sleeper" poisoning plants a fabricated memory that activates later, "Trojan Hippo" hides a payload (delivered by a single crafted email) that stays inert until the user raises a sensitive topic like finance or health and then exfiltrates data, and "Zombie Agent" attacks use self-reinforcing injections to keep persistent, puppet-like control of a self-evolving agent. Tool hijacking (MemMorph) poisons the memory agents use to refine tool-selection policies, so the agent learns from its own corrupted experience to reach for the wrong tool. And two findings should reshape how defenders think:
- Unintended drift (no attacker required). Ordinary, repeated interaction can gradually erode an agent's safety posture all on its own: confirmation boundaries weaken, tool-use defaults expand, and autonomy escalates over many sessions. The same mechanism an attacker exploits also degrades naturally, so a defense that only looks for malice will miss it.
- The misattribution gap. Memory-layer attacks produce behavior indistinguishable from ordinary model misalignment or hallucination. Teams see a misbehaving agent, blame the model, and apply the wrong fix (more fine-tuning, a better system prompt) while the poisoned entry sits untouched and keeps firing. If you cannot tell a memory attack from a model failure, you cannot remediate it.
Why This Is So Hard to Defend
The obvious defenses are weaker than they look, for three reasons.
Provenance is malleable. The intuitive fix is to tag each memory with where it came from and trust it accordingly. The problem is that an agent's own normal operations launder origin. When the agent paraphrases, summarizes, and stores untrusted content, the resulting memory entry looks self-generated. Recent work shows attackers can deliberately route an untrusted origin through these steps to "clean" it, defeating both content-based trust scoring and lineage-based tracking, because both signals can be manipulated.
Filters fail at the boundary. Input-level defenses (sanitizers, minimizers, prompt-injection classifiers) assume the malicious content looks malicious. But fluent, enterprise-style text carrying a poisoning payload reads like legitimate business content. A systematic evaluation of six defenses across nine open-source models (thousands of runs) found several input-level defenses performing at roughly the baseline attack success rate, meaning they barely helped. Static-corpus RAG defenses do not apply either, because they assume a fixed, trusted knowledge base, and the whole point of agent memory is that it grows from untrusted interaction.
The frameworks do not contain it. An audit of dominant agent frameworks (LangChain, AutoGPT, the OpenAI Agents SDK) against architectural containment principles found no native, structural guarantees around memory writes. Memory integrity is left to the application developer, which means most deployed agents have no containment by default. You have to build it in deliberately; you do not get it for free.
Memory Security Principles
Before the controls, five principles. They are short on purpose, because they are the rules everything else implements.
- Memory is data, not instructions. Stored content can inform the agent; it must never be able to command it.
- Provenance is security metadata. Where a memory came from is a security-relevant fact, recorded immutably at the boundary, not an afterthought.
- Authority never comes from memory. The right to take a consequential action is granted by policy and provenance, never conferred by the content of a recalled memory.
- Every write is untrusted until proven otherwise. Default deny. Content earns durability and trust; it is not granted them by arriving.
- Persistence multiplies blast radius. A single poisoned entry can affect many future sessions and many users, so the bar for what becomes durable should be higher than the bar for what enters a single context.
A distinction these principles depend on, and one that is easy to blur: provenance is not trust. Provenance is where a memory came from; trust is whether you believe it. They are related but not identical. A fact whose provenance is "the internal wiki" might still deserve low trust if that wiki is editable by contractors. Provenance is the metadata you record and must keep non-malleable; trust is the judgment you compute from provenance plus content plus context, and it can change over time. Record provenance immutably; recompute trust as your knowledge changes.
Memory Permissions and Scope
Memory needs an access-control model for the same reason a filesystem does: not every actor should be able to write everything, and not every reader should see everything. Increasingly, mature agent designs distinguish several classes of memory, each with its own permissions:
- Read-only memory the agent can consult but not modify (curated organizational knowledge, policy).
- Writable memory the agent can append to during operation, the highest-risk class and the one this article is mostly about.
- Private memory scoped to a single user or session, which must never leak across users.
- Shared memory visible across users or agents, where a poisoning by one party reaches others (the cross-tenant risk).
- Organization memory of org-wide facts, which should be write-controlled and reviewed, not freely self-edited.
- System memory holding the agent's standing instructions and procedures, which should be effectively immutable at runtime.
The practical rule is least privilege per class: default to private and read-only, require explicit justification to make memory writable or shared, and treat any path that lets untrusted input reach shared, organization, or system memory as a critical finding.
Defending Agent Memory: A Layered Approach
There is no single control that fixes this. A workable defense is layered, and it starts from the foundation the principles point to.
1. Provenance tagging is the foundation. Every memory entry should carry, as first-class metadata, where it came from, when it was written, which channel wrote it, and a trust score derived from those. Remember the distinction: record provenance immutably at the boundary, and treat trust as a computed value you can revise. The hard part is making provenance non-malleable, which means binding the tag when untrusted content first enters and preserving it through consolidation rather than re-deriving it afterward.
def write_memory(content, source, channel, store):
entry = {
"content": content,
"source": source, # URL, repo, MCP server, user id
"channel": channel, # user | tool | document | agent
"written_at": now(),
"provenance_bound": True, # set at the boundary, immutable
"trust": compute_trust(source, channel, content), # revisable judgment
}
if entry["trust"] < WRITE_THRESHOLD:
entry = quarantine(entry) # hold for review, do not auto-promote
store.upsert(entry)
2. Sanitize on write, and separate data from instructions. Treat everything entering memory as data, never as instructions. Strip or neutralize imperative content from untrusted channels before storage (instruction stripping), and validate writes before they commit (write-ahead validation). The goal is that stored content can inform the agent without being able to command it.
3. Make retrieval trust-aware. The read stage is your last line of defense before a poisoned entry reaches the model. Rank by trust as well as similarity, decay trust over time, isolate per-user memory so one user cannot poison another's context, and watch for retrieval anomalies (a low-trust entry suddenly matching many queries is a red flag).
def read_memory(query, store, user_id, k=5):
hits = store.search(embedding=embed(query), top_k=50, user_id=user_id)
scored = [
(h, similarity(h, query) * trust_weight(h) * recency(h))
for h in hits if h["trust"] >= READ_THRESHOLD
]
return [h for h, _ in sorted(scored, key=lambda x: -x[1])[:k]]
4. Require authority for consequential actions. Persistence is only catastrophic when the recalled memory can trigger something that matters: a payment, a settings change, a data send. Bind the authority to act to the origin of the memory, not to its content or its (launderable) lineage. A consequential action prompted by a low-trust or untrusted-origin memory should require human confirmation or be blocked outright. This is the control that breaks the trigger phase even if planting succeeds.
5. Monitor behavior and audit memory. Baseline the agent's normal behavior and alert on deviation. Periodically audit the memory store itself for anomalous or unattributable entries, and keep circuit breakers that can quarantine a suspect memory and roll back. This is also the answer to the misattribution gap: when an agent misbehaves, check the memory store before you blame the model.
6. Architect for containment. Because the frameworks do not give you containment for free, design it: least-privilege writes per memory class (see permissions above), strict isolation between users' and tenants' stores, and an explicit, non-malleable trust model rather than implicit trust in whatever ends up in the store.
Detection, Auditing, and Response
Prevention will not be perfect, so plan to detect and recover. The decisive capability is attribution: when something goes wrong, can you trace the behavior back to a specific memory entry and the channel that wrote it? That requires the provenance metadata from layer one plus durable logging of memory writes and reads (invocation logs and traces, in cloud-agent terms). Post-hoc memory auditing, using causal attribution to link a bad action back to the entry that caused it and structural anomaly detection to flag entries that do not fit, is an active research direction precisely because online filtering alone is not enough. Practically: log every write with its provenance, retain those logs, and build the muscle to answer "which memory caused this, and how did it get in?" before you need it in an incident.
A Builder's Checklist
If you are shipping an agent with persistent memory, the minimum bar:
- Every memory entry carries source, channel, timestamp, and a trust score (with provenance recorded immutably).
- Trust is computed from provenance plus content, and can be revised; provenance itself is not rewritten.
- Untrusted-channel content (including tool and MCP-server output) is sanitized before it is stored.
- Retrieval is trust-weighted and time-decayed, not similarity-only.
- Memory is classed by permission (private, shared, organization, system) with least privilege per class.
- Memory is isolated per user and per tenant; no shared store across trust boundaries by default.
- Consequential actions triggered by low-trust or untrusted-origin memory require human confirmation.
- Memory writes and reads are logged with provenance and retained for forensics.
- You have a way to audit, quarantine, and roll back a poisoned entry.
- Your incident playbook checks memory before attributing misbehavior to the model.
Conclusion: Memory Is a Security Boundary
The capability that makes agents useful, memory that survives the session, is the same capability that makes them attackable in a way stateless chatbots never were. The attacks are not exotic: an attacker who can get an agent to read a poisoned page, repo, or email can, in many real deployments, plant an instruction that persists, blends in, and fires later against the user or against someone else entirely. The defenses are not exotic either, but they are not free, and most frameworks do not provide them by default.
Which returns us to the thesis. The memory store is a security boundary, with its own trust model, its own access control, and its own audit requirements. Treat every untrusted input as potentially adversarial, treat stored memory as data rather than command, and bind the authority to act to provenance you control. Prompt injection taught the industry to distrust the current turn. Memory poisoning is the reminder that, for an agent, the past is an input too.
Sources and further reading: MINJA, "Memory Injection Attacks on LLM Agents via Query-Only Interaction"; AgentPoison (arXiv:2407.12784); Unit 42 / Palo Alto Networks, "When AI Remembers Too Much"; "Cross-Session Stored Prompt Injection in Agentic Systems" (arXiv:2606.04425); Trojan Hippo (arXiv:2605.01970); Zombie Agents (arXiv:2602.15654); MemMorph (arXiv:2605.26154); "From Untrusted Input to Trusted Memory" (arXiv:2606.04329); the misattribution gap (arXiv:2605.22842); origin-bound memory authority (arXiv:2606.24322). For the underlying memory architecture these attacks target, see the companion explainer on agent memory types.