Table of Contents
- The Problem With "Just Use a Vector Store"
- From Memory Types to Memory Architecture
- Graph Memory
- Hierarchical and Tiered Memory
- Temporal Memory
- Reflective and Self-Editing Memory
- Consolidation and Compression
- Retrieval Strategies and Tradeoffs
- Benchmarks and a Reality Check
- Hard Problems, and a Security Note
- A Reference Architecture and Decision Guide
The Problem With "Just Use a Vector Store"
The default recipe for agent memory is three lines long: embed every turn, store the vectors, and at query time pull back the top-k most similar. It is easy, it demos well, and for a short conversation it is genuinely fine. Then the agent runs for a few hundred sessions and the cracks show.
The trouble is that flat vector similarity is a storage layer wearing a memory system's clothes. It fails for long-horizon agents on four predictable fronts:
- It loses structure. Relationships, provenance, and multi-hop chains flatten into a bag of independent passages. "Which service owned by Maria's team calls the billing API?" is not a similarity question; it is a traversal, and a pile of embeddings cannot traverse.
- It has no model of time. A stale fact and its current replacement are nearly identical in embedding space, so cosine similarity cannot tell a contradiction from a duplicate. Measured directly, that discrimination runs barely above chance. An agent that cannot tell "the customer's plan was Pro" from "the customer's plan is now Enterprise" will confidently cite the wrong one.
- It degrades as it grows. More stored context is not more memory. Every frontier model loses accuracy as the retrieved set gets longer and busier, the effect now widely called context rot. A memory that never forgets eventually buries the signal it was meant to surface.
- It is lossy at the wrong moment. Systems that extract "facts" at ingestion throw away exactly the detail a future, unforeseen query will need. You cannot re-derive what you discarded.
So this article is about the layer above storage: the architectures that give memory structure, a sense of time, and a lifecycle. Memory is not a place you put vectors; it is a system that decides what to keep, how to relate it, when it stops being true, and what to surface right now. The honest version of the thesis, which the rest of the article keeps coming back to, is that structure has to earn its keep: a strong long-context model reading raw history still wins on pure recall, so the structured approaches justify themselves through multi-hop reasoning, temporal correctness, cost, latency, and auditability, not by always scoring higher.
From Memory Types to Memory Architecture
An earlier piece in this series laid out the four memory types: working, episodic, semantic, and procedural. That taxonomy answers what an agent stores. This one answers how it is organized, and the two are orthogonal. Semantic memory can live in a vector index, a relational table, or a knowledge graph; episodic memory can be a flat log or a temporally-structured event store. The architecture is the data-structure-and-policy choice underneath each type.
Five architectural patterns dominate current practice, and real systems combine them: graph memory, hierarchical (tiered) memory, temporal memory, reflective and self-editing memory, and consolidation. We take them in turn, then look at how retrieval, evaluation, and lifecycle policy tie them together.
Graph Memory
Graph memory stores entities and the typed relationships between them, not just passages. Instead of "here are five chunks that mention the billing service," it holds nodes (services, people, teams, customers) and edges (owns, calls, reports-to, upgraded-from) that an agent can walk.
The payoff is multi-hop reasoning and sense-making. HippoRAG borrows from how the brain indexes memories, running Personalized PageRank over a knowledge graph so that a query activates not just directly-similar nodes but the connected neighborhood that matters. Microsoft's GraphRAG builds community summaries over the graph and supports both local search (start at an entity, expand) and global search (reason over whole-corpus themes), which is what lets it answer "what are the recurring risk patterns across all incidents this quarter" that flat retrieval cannot. A-MEM takes a self-organizing approach, writing Zettelkasten-style atomic notes that link themselves into an evolving network as new memories arrive.
For an enterprise agent, the graph is often the difference between useful and useless. An onboarding assistant that knows OAuth2 is the auth standard, that the payments service runs on AWS and is owned by the platform team, and that the platform team's on-call rotates weekly can answer a question that touches all three. A vector store would return three unrelated paragraphs and leave the joining to luck.
The cost is construction. Extracting clean entities and relations is fragile, graphs drift as they grow, and a badly built graph is worse than no graph. Production systems (Cognee and others) wrap this in an extract-cognify-load pipeline precisely because the building is the hard part.
Hierarchical and Tiered Memory
The most useful mental model for tiered memory is the memory hierarchy in a computer: registers, cache, RAM, disk, archive, each larger, slower, and cheaper than the one above. MemGPT (now Letta) made the analogy concrete for agents, treating the context window like RAM and external stores like disk, with the agent itself paging information in and out through function calls. It splits memory into a small always-in-context core, a recall store for conversation history, and a deep archival store, and lets the agent decide what to load.
The sharp framing that has taken hold is that the context window is L1 cache, not memory. It is the fast, scarce, expensive tier you stage things into, not the place things live. Treating it as memory (stuffing ever more in) is the cache-thrashing of agent design. Recent work measuring this finds a surprising amount of the context budget wasted on structural overhead rather than useful content, which is exactly what you would expect from using your fastest tier as a junk drawer. MemOS and similar designs push the OS analogy further, giving memory first-class scheduling and movement between tiers.
The lesson for builders: decide deliberately what earns a place in the always-loaded tier, what is one page-fault away, and what lives in cold storage. Most teams over-load the top tier and pay for it in both latency and context rot.
Temporal Memory
Most memory systems quietly assume the world is static. It is not. Customers change plans, policies get revised, people change teams, prices move. A memory that overwrites the old value loses history, and a memory that keeps both without a time model cannot tell which is true now.
Temporal knowledge graphs fix this with bi-temporal modeling: every fact carries both its valid time (when it was true in the world) and its ingestion time (when the system learned it). When a newer fact contradicts an older one, the system does not delete the old edge; it invalidates it, marking the interval over which it held. Zep's Graphiti engine is the best-known implementation, and it is what lets an agent answer "what plan was this customer on in March" and "what plan are they on now" from the same store without confusion.
This is also where the field is most honest about how far it has to go. Conflict resolution, deciding that a new fact supersedes an old one and acting on it, is largely unsolved: on benchmarks built specifically to test fact consolidation, even strong temporal systems score in the single-digit-to-low percentages. Knowing that time matters is settled; reliably reconciling contradictions over time is not. For any agent that acts on facts that change (which is most enterprise agents), this is the architecture to take seriously and the failure mode to test hardest.
Reflective and Self-Editing Memory
The architectures so far store and retrieve what happened. Reflective memory adds a step: the agent periodically reviews its own history, synthesizes higher-level insights, and writes those back. Stanford's Generative Agents introduced reflection as a way for simulated characters to form abstract beliefs ("Klaus is passionate about his research") from streams of concrete observations. Reflexion applied the same idea to task-solving, having an agent write a verbal post-mortem of its failures and keep it as guidance for next time. This is how an agent learns from experience without retraining a single weight.
It is powerful and it is dangerous, and an honest treatment has to say both. Self-editing memory can entrench error: an agent that reflects its way to a confident but wrong conclusion will then retrieve and act on its own mistaken belief, defending it more firmly each cycle. Recent work documents this "honest lying" failure, where self-generated memory becomes a source of durable, sincere misinformation. Reflection needs the same scrutiny as any other write path: where did this insight come from, and what happens if it is wrong?
Consolidation and Compression
If context rot is the disease, consolidation is the treatment. Borrowing again from biology, several recent systems add an offline "sleep-time" phase: between or during sessions, a background process reorganizes memory, summarizes clusters of related episodes into durable facts, promotes repeated patterns, and evicts the low-value remainder. SleepGate and Auto-Dreamer are representative of this consolidation-as-a-phase approach; structured eviction work focuses on the harder half, deciding what to forget without losing what matters.
The point of consolidation is not just to save space. It is to keep the signal density of memory high, so that retrieval surfaces a small, relevant set instead of a large, noisy one. A memory system that only ever appends will, given enough time, defeat its own retrieval. Forgetting, done well, is a feature of the architecture, not a failure of it.
Retrieval Strategies and Tradeoffs
The architecture determines what you can retrieve; the retrieval strategy determines what you do. Four broad options, in rough order of sophistication:
- Vector search. Fast, simple, good for fuzzy semantic recall. The baseline, and fine for a lot of cases.
- Graph traversal. Follows relationships; wins on multi-hop and structural questions; needs a graph to walk.
- Hybrid (the production default). Combine vector and keyword (and often graph) candidates, fuse them (reciprocal rank fusion is the common choice), then re-rank. Most serious systems have converged here because no single signal is enough.
- Agentic / iterative retrieval. The agent issues multiple retrievals, reasons over partial results, and refines, trading latency and tokens for harder questions.
Two tradeoffs dominate the engineering. The first is accuracy versus cost and latency: extraction-and-consolidation systems report large savings (one widely-cited system claims roughly 90 percent fewer tokens and comparable latency reductions at query time) by not shoving raw history at the model, at the price of ingestion-time work and some lossiness. The second is ingestion-time versus retrieval-time processing: do the expensive structuring up front (cheaper queries, lossy) or keep everything verbatim and pay at read time (faithful, slower). There is no universal answer; there is a right answer per workload. One trap to name: the "static graph fallacy," where fixed edge weights set at build time drift, over-favor a few hub nodes, and quietly degrade retrieval as the graph grows.
Benchmarks and a Reality Check
How do you know an architecture is better? Two benchmarks anchor the conversation. LOCOMO tests long conversational memory; LongMemEval is more diagnostic, probing five distinct abilities including knowledge updates over time and abstention (knowing when the answer is not in memory). Both are more honest than a single accuracy number because they separate the abilities that flat retrieval fakes from the ones it fails.
Now the reality check, and it matters for anyone reading vendor comparisons. Recent reproduction work finds that memory-system leaderboard numbers do not hold across harnesses: the same system scores very differently depending on implementation details, and competing vendor claims (system A at ~67 percent versus system B at ~84 percent on the same benchmark) should be read as marketing, not measurement, until reproduced. The robust finding underneath the noise is not which product wins; it is where everything struggles: temporal reasoning, knowledge updates, and abstention. If you are evaluating memory for your own agent, test those, on your own data, in your own harness.
Hard Problems, and a Security Note
A few problems are genuinely open, and a builder should plan around them rather than assume they are solved:
- Conflict resolution over time is the big one, as the temporal-memory numbers showed. Detecting and correctly acting on a superseded fact remains unreliable.
- Self-editing drift can entrench confident errors, so reflection needs provenance and review.
- Construction fragility means a graph or typed store is only as good as its extraction pipeline.
There is also a security consequence worth flagging, because it connects this series' educational and security tracks. The same consolidation and compaction that fight context rot can silently drop things you needed, including in-context safety constraints. Recent work on "governance decay" shows that when an agent compacts its context, the safety instructions can be summarized away along with the noise, quietly loosening the agent's guardrails over a long session. Memory architecture is not security-neutral: how you forget is itself a security decision, which is the bridge to the security-engineering piece in this series.
A Reference Architecture and Decision Guide
Put together, the mature pattern is not one structure but a hybrid, layered system governed by lifecycle policy:
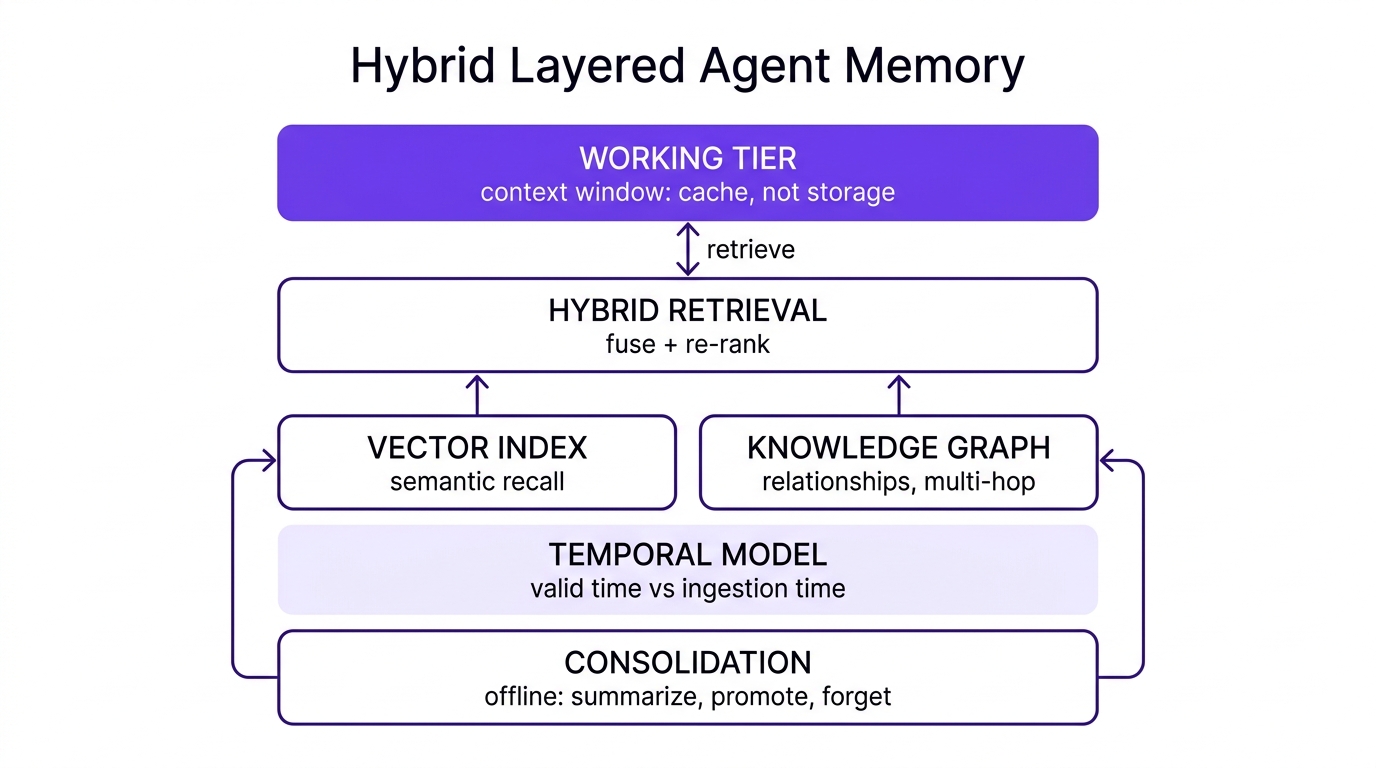
Figure 1: A hybrid, layered memory architecture. The working tier is cache; structure, time, and consolidation live below it.
- A small, deliberately-curated working tier (the context window) treated as cache, not storage.
- A hybrid retrieval layer over both a vector index (semantic recall) and a knowledge graph (relationships, multi-hop), fused and re-ranked.
- A temporal model on the facts that change, so the agent can reason about now versus then.
- A consolidation phase that runs offline to summarize, promote, and forget, keeping signal density high.
- Reflection where the agent genuinely benefits from learned insights, with provenance on what it writes.
The decision guide is simpler than the menu suggests. Start with hybrid retrieval; you almost always want it. Add a graph when your questions are relational or multi-hop. Add a temporal model when your facts change and being wrong about "now" is costly. Add consolidation as soon as the agent runs long enough to accumulate noise. Add reflection last, and only where the value is clear, because it is the write path most able to hurt you. And measure on your own workload, because the leaderboards will not tell you which of these your agent actually needs.
The shift in thinking is the whole point. A vector store answers "what looks like this?" A memory architecture answers "what is related, what is still true, what matters now, and what should I forget?" The first is a feature. The second is what turns a model with a database into an agent with a memory.
Sources and further reading: HippoRAG (arXiv:2405.14831); Microsoft GraphRAG (arXiv:2404.16130); A-MEM (arXiv:2502.12110); MemGPT/Letta (arXiv:2310.08560); MemOS (arXiv:2505.22101); Zep/Graphiti (arXiv:2501.13956); Generative Agents (arXiv:2304.03442); Reflexion (arXiv:2303.11366); LOCOMO (arXiv:2402.17753); LongMemEval (arXiv:2410.10813). Companion pieces: the agent memory explainer, the agent-memory attack-surface article, and the secure-memory engineering guide.