Table of Contents
- The Challenge of Adapting Foundation Models
- Adapters: A Paradigm of Parameter-Efficient Specialization
- Strategic Advantages of the Adapter-Based Approach
- Adapters in Practice: A Cross-Domain Survey
- Creating Multiple Personalities: Multi-Task Learning
- Comparative Analysis of Model Adaptation Techniques
Section 1: The Challenge of Adapting Foundation Models
1.1 The Era of Large Pre-trained Models: Capabilities and Costs
We live in the age of giants. BERT. GPT. Vision Transformers. These massive foundation models have fundamentally rewritten the rules of AI development, demonstrating extraordinary capabilities across virtually every task you can imagine. The recipe sounds simple enough: pre-train enormous neural networks on web-scale datasets, letting them absorb a broad, generalizable understanding of language, vision, or both, then adapt them for specific tasks.
Simple? Hardly. The cost is staggering. Training a foundation model from scratch demands millions of dollars, consumes vast amounts of energy, and requires computational infrastructure most organizations will never possess. This isn't just expensive—it's prohibitively exclusive, concentrating cutting-edge AI development in the hands of a privileged few tech giants with bottomless budgets and massive server farms.
Key Insight: Parameter-efficient techniques aren't just technical optimizations. They're a democratizing force, breaking down barriers and empowering smaller teams, academic labs, and startups to build upon and specialize these powerful AI systems without burning through millions of dollars.
1.2 The Fine-Tuning Dilemma: Performance vs. Practicality
Full fine-tuning has ruled for years. Take your pre-trained model, update all its parameters with new task-specific data, and watch it achieve state-of-the-art performance. The entire network adjusts its internal representations to master the nuances of your specific task. Maximum performance. Gold standard results.
But here's the catch. That performance costs you dearly. Full fine-tuning creates a brutal tradeoff between what works best and what you can actually afford:
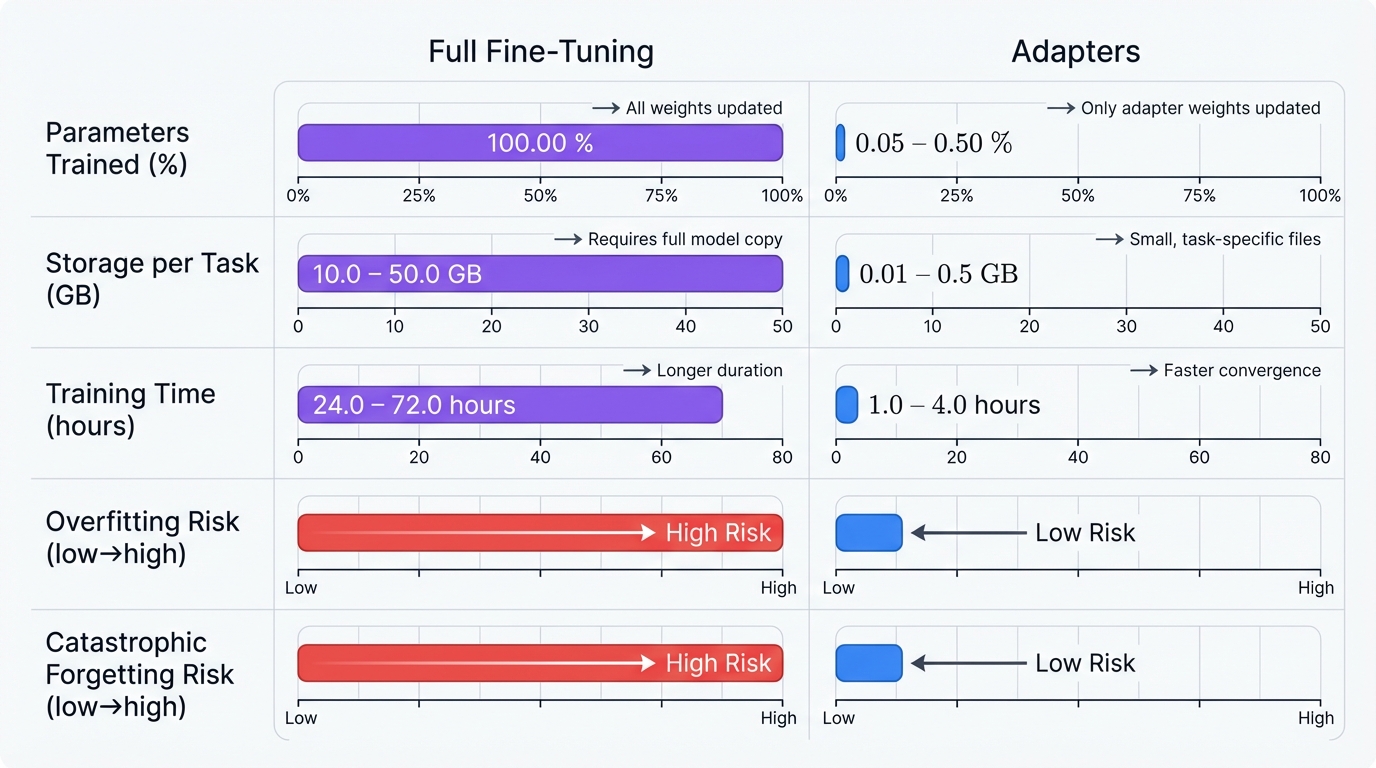
- Parameter-inefficiency: Every single task demands its own complete copy of your multi-billion parameter model. Got ten tasks? Store ten complete models. The storage costs spiral out of control fast.
- Computational expense: Updating billions of parameters devours GPU memory and time, turning rapid experimentation into a slow, expensive slog that kills innovation momentum.
- Risk of overfitting: Small datasets become deadly. With limited training examples, your model starts memorizing specific samples instead of learning the underlying patterns—the classic overfitting trap that destroys generalization.
1.3 Introducing Catastrophic Forgetting: The Peril of Sequential Learning
Cost isn't the only problem. Full fine-tuning reveals a fundamental flaw in how neural networks learn: catastrophic forgetting. The phenomenon is brutal in its simplicity. Teach your model Task B, and it forgets Task A. Completely. The new knowledge overwrites the old, erasing capabilities like a hard drive being reformatted.
Why does this happen? Knowledge in neural networks lives in weight configurations—specific patterns across millions or billions of parameters. When you fine-tune for Task B, the optimizer adjusts these weights to minimize Task B's error. Those adjustments destroy the precise configuration that Task A needed. The model's memory of Task A? Gone. Erased. Replaced by Task B's requirements.
Critical Challenge: Catastrophic forgetting isn't just inconvenient. For lifelong learning applications—autonomous robots, personalized agents, continuously adapting systems—it's a critical failure mode that can render your entire system unreliable and unusable.
Section 2: Adapters: A Paradigm of Parameter-Efficient Specialization
2.1 Defining Adapter-Based Tuning: Core Principles
Enter adapters. Small, trainable neural network modules strategically inserted into larger pre-trained models. The core principle? Brilliant simplicity. Freeze the foundation model's billions of parameters—the massive "backbone" stays untouched. Only train the tiny adapter modules on your new task data.
This flips the entire paradigm. Instead of retraining billions of parameters for each task, you add lightweight modules and train just those. The foundation model preserves everything it learned from massive pre-training. The adapters specialize it for your specific needs, creating a powerful combination of broad knowledge and focused expertise without the catastrophic costs of full fine-tuning.
2.2 Architectural Deep Dive: The Bottleneck Structure and Residual Connections
Adapter architecture is engineered for maximum parameter efficiency. The secret? A bottleneck structure with three components:
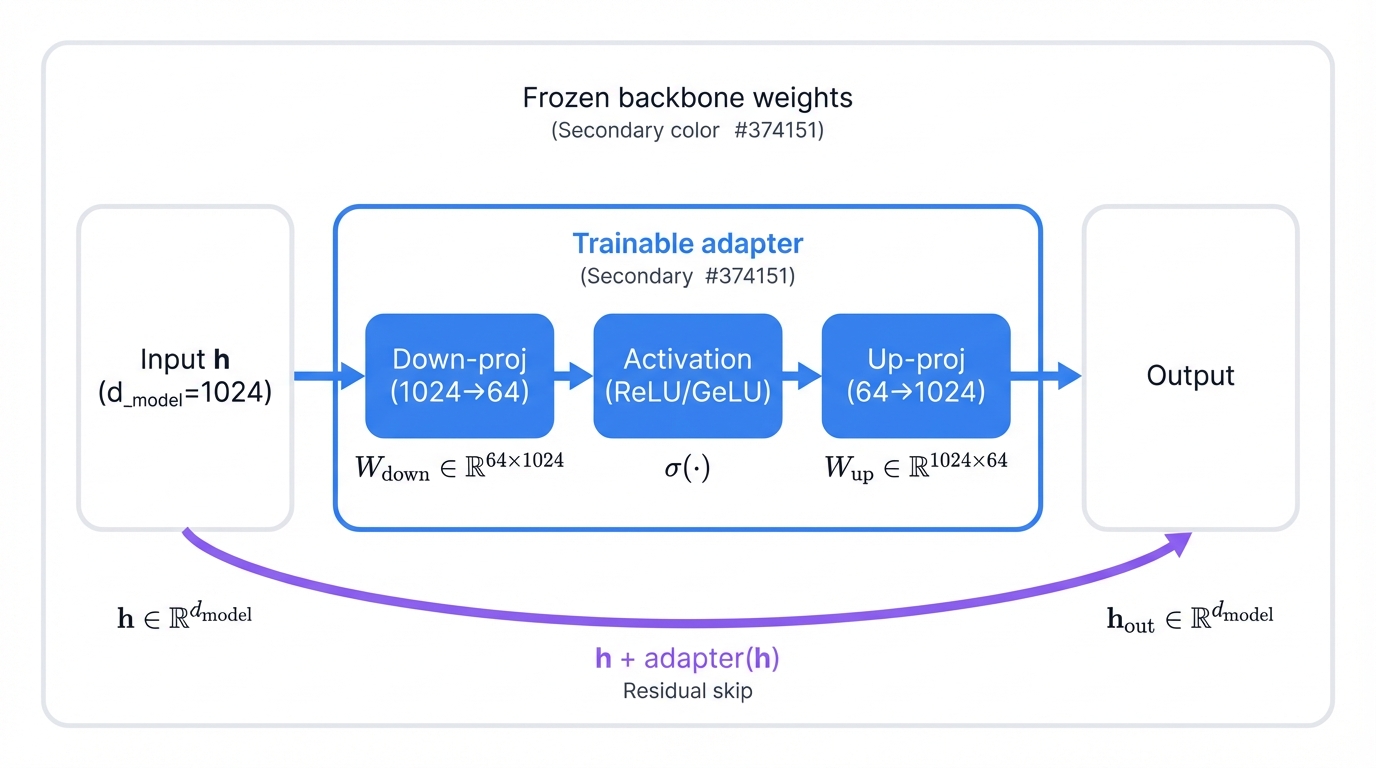
- A down-projection linear layer
- A non-linear activation function (ReLU or GeLU)
- An up-projection linear layer
All wrapped in a residual connection. Here's how it transforms a hidden state:
# Adapter transformation with residual connection
def adapter_forward(h, W_down, W_up, activation):
"""
Apply adapter transformation to hidden state h
Args:
h: Input hidden state
W_down: Down-projection weight matrix
W_up: Up-projection weight matrix
activation: Non-linear activation function
Returns:
Transformed hidden state with residual connection
"""
# Down-project to bottleneck dimension
bottleneck = activation(W_down @ h)
# Up-project back to original dimension
adapter_output = W_up @ bottleneck
# Apply residual connection
return h + adapter_output
Watch what happens. Large Transformer models work with high-dimensional hidden states—768, 1024, sometimes more. The down-projection squeezes this into a tiny intermediate dimension, maybe 64 or 128. Compression. The non-linear transformation happens in this compact space. Then the up-projection expands it back to the original dimension, ensuring perfect compatibility with the frozen foundation model layers that follow.
The bottleneck isn't just efficient—it's elegant. By forcing information through a narrow passage, it creates a highly compressed representation where task-specific learning happens with minimal parameters. Maximum impact, minimum overhead.
2.3 The Mechanism of Integration: Injecting Adapters into Transformer Layers
Transformers are composed of repeated identical layers. Where do adapters go? The standard strategy injects them twice per layer:
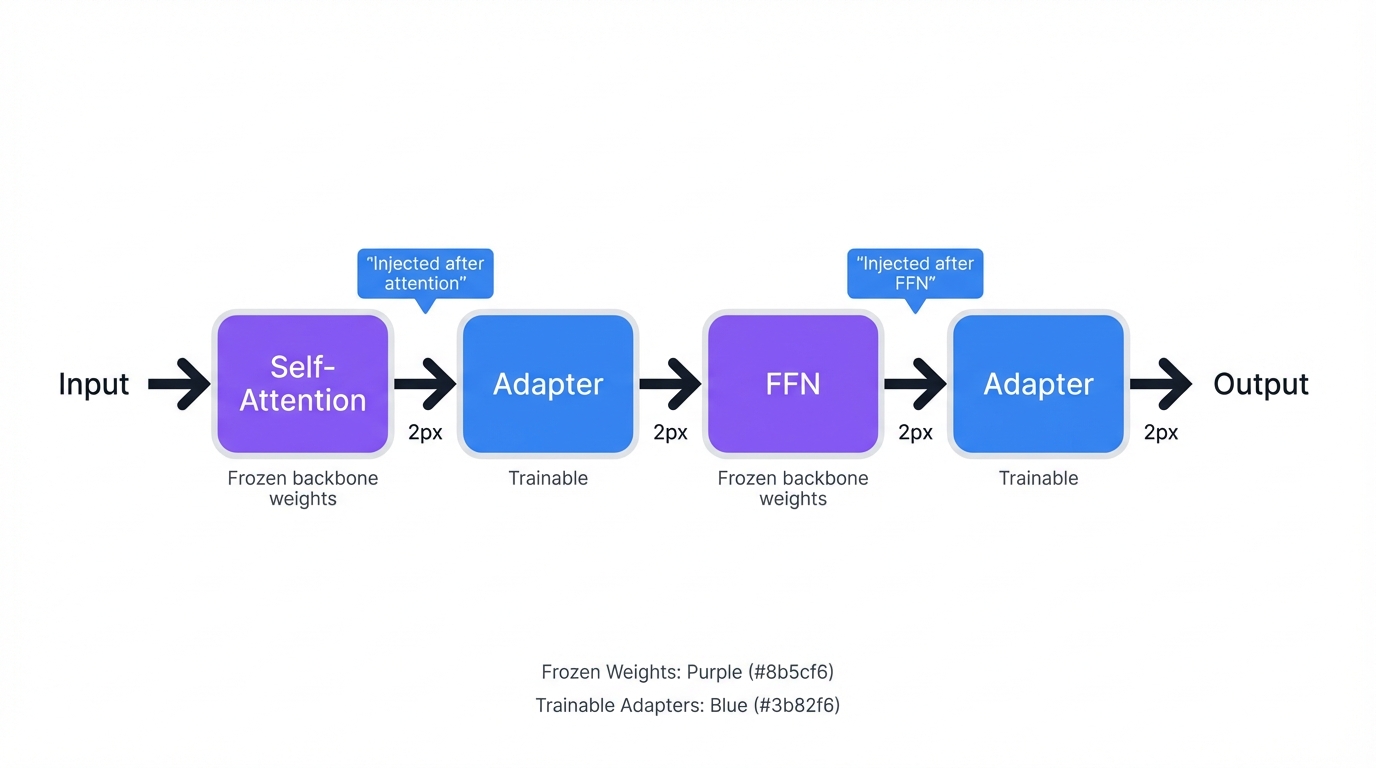
- One module right after the multi-head self-attention sub-layer
- Another after the position-wise feed-forward network (FFN) sub-layer
This placement is strategic. Adapters modulate the two primary computational blocks where Transformers process and refine information. Most implementations use sequential post-layer insertion, though parallel configurations exist where adapters run alongside the main path and their outputs get summed together.
2.4 The Role of Near-Identity Initialization in Preserving Pre-trained Knowledge
Here's an elegant detail. When you first insert adapters, they need to start at zero impact. Why? Your pre-trained model has carefully calibrated information flow and powerful representations built through expensive pre-training. You can't disrupt that.
The solution: near-identity initialization. Initialize adapters so their output is a zero vector. How? Set the down-projection matrix to small random values. Set the up-projection weight matrix to all zeros. Result? The adapter's bottleneck path outputs zero regardless of input. The residual connection passes through: 0 + h = h. Perfect identity function at initialization.
The adapter starts invisible. As training progresses, it gradually learns task-specific adjustments while the foundation model's knowledge remains intact. Smooth. Elegant. Effective.
Section 3: The Strategic Advantages of the Adapter-Based Approach
3.1 Radical Parameter Efficiency: Quantifying the Reduction
The numbers tell the story. Adapters add just 0.2% to 6% of the original model's parameters per task. That's it. The massive base model stays frozen. Only the tiny adapter modules train on your new data.
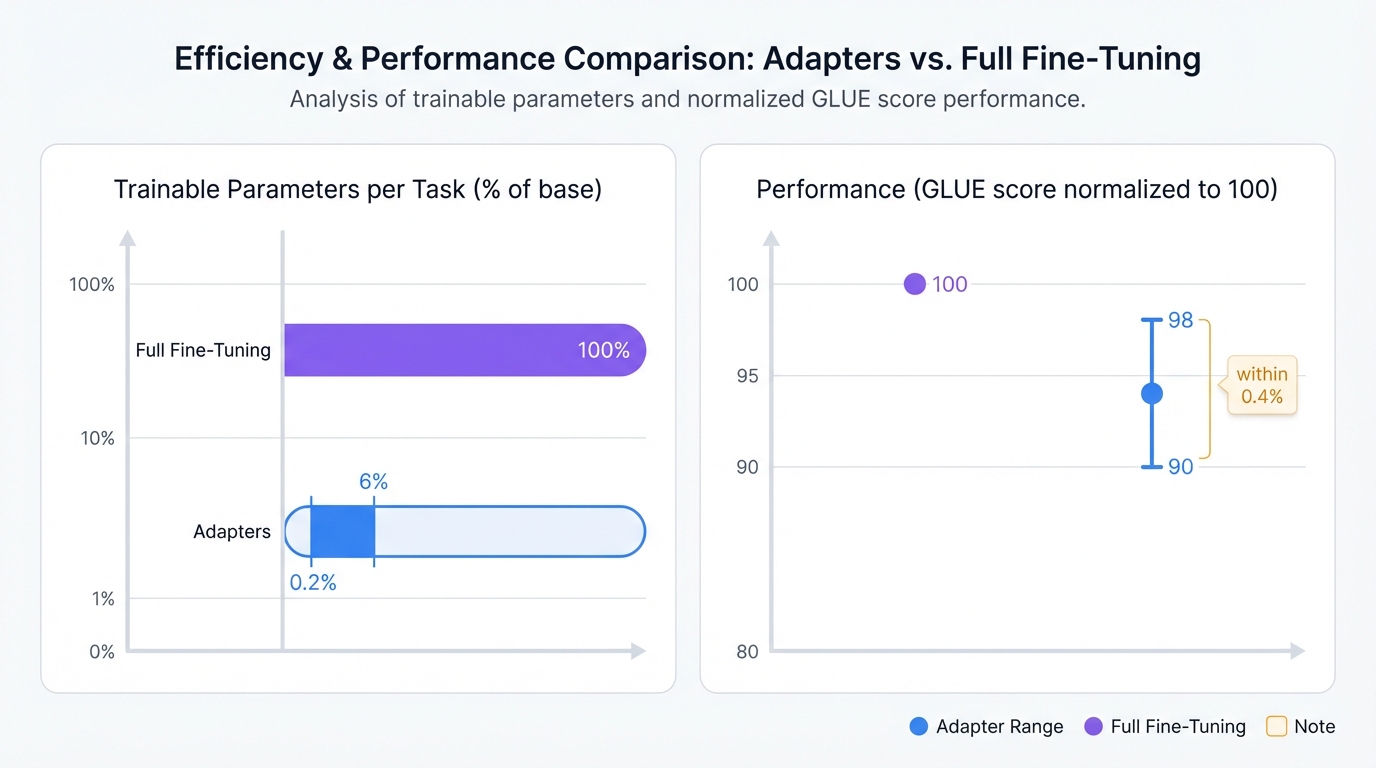
Real-world proof? Look at early GLUE benchmark work with BERT. Adapters matched full fine-tuning performance—within 0.4%—while adding only 3.6% of the model's parameters per task. Compare that to full fine-tuning's requirement: 100% of parameters for every single task. The efficiency gain is staggering, and the implications ripple through every aspect of model deployment, from storage costs to training time to environmental impact.
3.2 Economic and Computational Impact: Reducing Costs, Memory, and Training Time
Parameter efficiency translates directly to dollars saved. Money. Time. Energy. All reduced dramatically. The cascading benefits reshape what's economically viable:
- Lower memory requirements: The optimizer only tracks adapter parameters, not billions of base model weights. Suddenly you can fine-tune massive models on accessible hardware instead of requiring expensive, high-end GPU clusters that most teams can't afford.
- Reduced training time: Fewer parameters mean faster convergence. Each optimization step processes less. Larger batch sizes become feasible. Training that once took days can complete in hours.
- Sustainable AI development: Less computation means lower energy consumption and smaller carbon footprints. Adapters make AI development more environmentally responsible without sacrificing capability.
For businesses and research institutions, this isn't just technical optimization—it's the difference between viable and impossible, between innovation and stagnation.
3.3 Modularity and Extensibility: Building on a Frozen Foundation
Adapters create a plug-and-play ecosystem. One frozen foundation model. Unlimited specialized skills. Each adapter is self-contained, independent, swappable. Need a new task? Train a new adapter. The base model never changes. Previous adapters remain untouched.
The implications are profound. Cloud services can load one base model into memory, then dynamically swap in whichever tiny adapter file an incoming request needs. Translation? Load the translation adapter. Sentiment analysis? Swap to the sentiment adapter. Medical image segmentation? Legal document summarization? Just plug in the right skill module.
This architecture scales beautifully. A single foundation model supports hundreds or thousands of specialized tasks without retraining, without interference, without the storage nightmare of maintaining complete model copies for every single capability. Extensibility without complexity—exactly what large-scale AI platforms demand.
3.4 Preserving Knowledge: How Adapters Mitigate Catastrophic Forgetting
Remember catastrophic forgetting? Adapters solve it architecturally. The base model's weights freeze. They never change. Ever. New task learning happens entirely within dedicated adapter modules that are physically separate from both the foundation model and other task adapters.
Each task gets its own knowledge container. Task A's adapter stores Task A's expertise. Task B's adapter stores Task B's expertise. No overlap. No interference. No destructive weight updates erasing previous capabilities.
The system has perfect memory. When you train Task C, Tasks A and B remain intact because their parameters never get touched. Sequential learning without forgetting—exactly what continual learning applications need but traditional fine-tuning could never deliver.
Section 4: Adapters in Practice: A Cross-Domain Survey
4.1 Applications in Natural Language Processing (NLP)
NLP is adapter territory. This is where they were born, where they matured, where they proved their transformative power across multiple breakthrough applications:
Cross-lingual Transfer
Multilingual models like XLM-R adapt to new languages with brutal efficiency using language-specific adapters. Want zero-shot cross-lingual transfer? Train your model on a task in English, then test it on a low-resource language it's never seen for that task. Combine language adapters with task adapters. Watch the magic happen. Adapters consistently beat full fine-tuning in these zero-shot scenarios, proving that modularity isn't just efficient—it's more effective.
Low-Resource Adaptation
Small datasets? Adapters shine. When you have scarce training data—fewer than 10,000 examples—adapters outperform full fine-tuning consistently. Why? Regularization. By constraining updates to a tiny parameter subset, adapters resist overfitting. They preserve the robust, generalizable knowledge from pre-training instead of memorizing limited examples. The result is better generalization and more reliable performance on real-world data distributions.
Domain Adaptation and Knowledge Infusion
Adapters excel at domain specialization. Take a general-purpose language model and adapt it for biomedical literature, legal documents, or financial reports. The base model's linguistic competency stays intact. The adapter adds domain expertise.
Knowledge infusion gets more sophisticated. The K-Adapter framework injects factual and commonsense knowledge from external knowledge graphs directly into pre-trained models. Enhanced factual accuracy. Preserved linguistic capabilities. No catastrophic interference. Adapters make it possible to augment models with structured knowledge without destroying what they already know.
4.2 Applications in Computer Vision (CV)
NLP proved the concept. Computer Vision extended it. The core principle—inserting lightweight modules into frozen backbones—transfers beautifully, but the optimal implementation depends heavily on the visual modality's unique characteristics.
Vision-Specific Adapter Architectures
Conv-Adapter was built for Convolutional Neural Networks like ResNet. It uses depth-wise separable convolutions in its bottleneck structure—an efficient operator perfectly suited for processing spatial feature maps. Performance? Matches or beats full fine-tuning across image classification, object detection, and semantic segmentation tasks. Same efficiency gains. Visual domain mastery.
ST-Adapter (Spatio-Temporal Adapter) solves a different challenge: enabling image models to understand videos. Static image pre-training gives you spatial reasoning. Videos demand temporal understanding. ST-Adapter efficiently extracts and models temporal information, bridging that gap with minimal parameters. Action recognition and video understanding become possible without retraining the entire visual backbone.
4.3 Bridging Modalities: Adapters in Vision-Language Models
Multi-modal models like CLIP possess rich, shared embedding spaces for both vision and language. Adapters unlock their specialization for downstream vision-and-language tasks with extraordinary parameter efficiency.
Visual Question Answering? Image captioning? Complex multi-modal reasoning? Adapter-based methods match full fine-tuning performance while updating just 3-4% of total parameters. That's not a tradeoff—it's a breakthrough. You get state-of-the-art multi-modal capabilities without the computational nightmare of fine-tuning massive vision-language models end-to-end.
Section 5: Creating "Multiple Personalities": Multi-Task Learning with Adapters
5.1 The One-Model, Many-Tasks Vision
One foundation model. Multiple personalities. The vision is elegant: maintain a single large pre-trained base model, then train separate lightweight adapters for each skill you need. Translation? Plug in the translation adapter. Sentiment analysis? Swap to the sentiment adapter. Medical image segmentation? Legal document summarization? Just load the right personality for the job.
Dynamic, modular, efficient. Your application loads the base model once, then plugs in whichever specialized adapter the current task demands. No retraining. No catastrophic forgetting. Just pure skill-swapping convenience.
5.2 Inherent Challenges: Task Interference, Negative Transfer, and Scaling
Beautiful theory. Messy practice. The plug-and-play vision hits serious obstacles when tasks need to learn or execute concurrently. Simple adapter isolation prevents catastrophic forgetting beautifully—but it's suboptimal for multi-task learning.
Negative transfer strikes hard. Task interference. When you train multiple adapters simultaneously or try composing their functionalities, learning objectives clash. Features that help coarse-grained classification can actively hurt fine-grained classification. The conflict degrades performance across one or all tasks compared to training them individually. Isolation protects against forgetting but sacrifices beneficial knowledge sharing and creates destructive conflicts during concurrent learning.
5.3 Architectural Innovations for Multi-Task Mastery
Researchers aren't accepting these limitations. Sophisticated frameworks are emerging that balance task specialization against knowledge sharing more intelligently:
Modeling Shared vs. Independent Knowledge
VMT-Adapter for computer vision splits the difference brilliantly. Shared projection layers common to all tasks enhance cross-task interaction. Independent task-specific modules extract specialized knowledge. The unified framework learns both task-generic and task-specific representations simultaneously, capturing synergies without destructive interference.
Learning Task Affinities
Why assume task relationships? Learn them. Task-Adapted Attention mechanisms condition transformer self-attention on learned similarity metrics between tasks. The model discovers which tasks relate to each other and should share information, which tasks conflict and need isolation. Automatic relationship discovery guides intelligent knowledge sharing without manual engineering.
Dynamic Routing and Selection
Adapter Selector (AS) introduces a dedicated middleman. This specialized adapter analyzes each input, identifies its domain and task, then selects the appropriate specialist adapter for final processing. Smart routing based on learned patterns.
OrchMoE (Orchestrated Mixture of Experts) goes further. Each adapter becomes a fundamental skill set. The framework determines the optimal combination of skills needed to solve each problem, composing capabilities dynamically instead of using fixed adapter assignments. True skill orchestration emerges.
5.4 Verdict: Are Adapters the Optimal Path to Multi-Skilled Models?
Yes and no. Adapters are crucial but insufficient in their simplest form. One independent adapter per task gives you a strong baseline—multi-skilled models without catastrophic forgetting. Clean. Efficient. Modular.
But simple isolation ignores task interference and misses knowledge sharing benefits. Real-world optimal solutions build sophisticated orchestration frameworks on top of foundational adapter modules. Systems that learn task relationships, dynamically route inputs, and compose skills intelligently represent the current state-of-the-art in truly versatile, multi-skilled AI.
The future isn't just adapters. It's intelligent adapter orchestration that knows when to share, when to isolate, and how to compose capabilities for maximum effectiveness.
Section 6: A Comparative Analysis of Model Adaptation Techniques
6.1 Situating Adapters in the PEFT Landscape
Adapters belong to a larger family: Parameter-Efficient Fine-Tuning (PEFT). Three main categories define how these techniques achieve efficiency:

- Additive Methods: Freeze the original model, add new trainable parameters. Adapters fit here.
- Selective Methods: Unfreeze and fine-tune a small subset of existing parameters. No new parameters added.
- Reparameterization Methods: Reparameterize weight matrices to reduce trainable parameters. LoRA leads this category.
6.2 Adapters vs. Full Fine-Tuning: The Fundamental Trade-off
This comparison defines PEFT's entire value proposition:
- Full Fine-Tuning: Maximum possible performance. Deep adaptation of the entire knowledge base. But the cost? Extreme parameter inefficiency, massive computational and storage requirements, high catastrophic forgetting risk, and brutal overfitting on small datasets.
- Adapters: Comparable performance—typically 90-98% of full fine-tuning results. Trainable parameters slashed by over 90%. Catastrophic forgetting mitigated. Modular, extensible systems enabled. Practical. Efficient. Scalable.
The tradeoff favors adapters in most real-world scenarios. You sacrifice a few percentage points of peak performance. You gain deployability, cost-effectiveness, and system flexibility that full fine-tuning can't match.
6.3 Adapters vs. LoRA: A Detailed Comparison
LoRA and classic Houlsby-style adapters dominate PEFT. Both use low-rank projections. Both deliver impressive efficiency. But their implementations differ fundamentally:
Mechanism Differences
- Adapters: Additive approach. Insert entirely new bottleneck layers between frozen Transformer layers. New computational blocks in the graph.
- LoRA: Reparameterization approach. No new layers. Models weight matrix updates ΔW as the product of two low-rank matrices: ΔW = B × A. Original architecture unchanged.
Inference Latency
Critical difference. Adapters add layers to the computational graph. Small latency overhead. Non-zero cost.
LoRA wins decisively here. After training completes, the learned update matrix merges mathematically back into the original weight matrix. Result? Zero additional inference latency. No performance penalty. The efficiency benefits persist during deployment without speed costs.
6.4 Adapters vs. Prompt-Based Tuning
Prompt tuning takes a radically different approach:
- Adapters: Modify internal processing through new computational layers.
- Prompt Tuning: Leave architecture and weights completely frozen. Learn small continuous "soft prompt" vectors prepended to input embeddings.
Prompt tuning achieves extreme parameter efficiency—often under 0.01% of model parameters. But its deep domain adaptation capacity is limited. Adapters modify representations at every layer, enabling more robust performance across diverse model sizes and task complexities. Prompt tuning works brilliantly for light behavioral conditioning. Adapters handle deeper specialization.
6.5 An Integrated View: When to Use Which Technique
No universal winner exists. Choose based on your specific constraints:
- Full Fine-Tuning: Flagship single-task models demanding maximum performance. Massive domain shifts. Large data and computational budgets. Performance over everything else.
- LoRA: Default choice for single-task fine-tuning. Excellent performance-efficiency balance. Zero inference latency clinches it for deployment-focused applications.
- Adapters (Houlsby-style): Modular multi-task systems where skill separation prevents interference. Continual learning scenarios where catastrophic forgetting mitigation is paramount. Plug-and-play ecosystems.
- Prompt Tuning: Rapid prototyping. Light behavioral conditioning. API-gated models where weight modification is impossible. Extreme parameter constraints.
Match technique to requirements. The best method is the one that solves your specific problem within your specific constraints.
Conclusion: Synthesis and Future Directions
Recapitulation of Adapters' Role in Sustainable and Democratized AI
Adapters aren't just convenient. They're foundational. This technology reshapes applied AI's entire landscape by tackling the brutal realities of modern foundation models: prohibitive training costs, inefficient storage, catastrophic forgetting. Specializing massive models now costs minimal computational resources, making state-of-the-art AI practical, affordable, and sustainable for organizations beyond tech giants.
The paradigm shift is profound. Monolithic single-purpose models are giving way to modular, composable AI ecosystems. One powerful foundation model becomes a shared resource. A growing library of lightweight adapters provides unlimited specialized skills. This modularity democratizes AI development—smaller teams, academic labs, and businesses can now participate in cutting-edge work without burning millions of dollars on infrastructure.
Emerging Trends and the Future of Modular Deep Learning
PEFT is evolving fast. Several trends are shaping modular deep learning's future:
- Hybrid approaches: Why choose one PEFT method? Combine their strengths. Practitioners are building systems that blend adapters, LoRA, and prompt tuning within unified architectures, exploiting each technique's advantages for different components or tasks.
- Automated selection: AutoPEFT and similar techniques eliminate manual configuration. These systems automatically search the vast PEFT method space to find optimal setups for specific tasks and datasets. Machine learning choosing its own learning strategy.
- Model compositionality: Dynamic multi-adapter frameworks point toward true model compositionality. Models that reason about novel problems, identify required skills, and assemble capabilities on the fly. Adaptive intelligence that constructs itself based on task demands.
- Beyond pure efficiency: Next-generation methods target controllability, robustness, and interpretability while maintaining parameter efficiency. Efficiency was phase one. Phase two adds safety, reliability, and explainability to the efficiency foundation.
Adapters pioneered this revolution. They remain a central building block as modular deep learning and sustainable AI development accelerate toward a future where specialized intelligence is accessible, composable, and efficient. The age of democratized AI has arrived, and adapters helped build it.