Section 1: Fundamental Concepts
Ensemble Learning Power
AdaBoost shows us something remarkable: weak learners become prediction powerhouses when you combine them intelligently. Want to build robust machine learning systems? You need to understand boosting algorithms.
1995. Two researchers solved a puzzle. The machine learning community had been stuck on this problem for years, and their solution—AdaBoost—didn't just answer a theoretical question but sparked a revolution that changed how we build intelligent systems.
Look at your phone right now—when you use face detection on your device or get approved for a loan online, there's a good chance you're benefiting from AdaBoost's core insight, a powerful idea that weak learners, when combined intelligently, can outperform any individual strong learner, transforming the entire landscape of practical machine learning applications.
1.1 The Principle of Boosting: From Weak to Strong Learners
Your worst student becomes your best teacher. That's what AdaBoost does.
What's a weak learner? Imagine a simple rule that's right 51% of the time in binary classification—barely better than random guessing. Useless on its own, right? Wrong. Dead wrong. AdaBoost takes hundreds of these barely-adequate rules and orchestrates them into a prediction system that rivals the most sophisticated algorithms ever created.
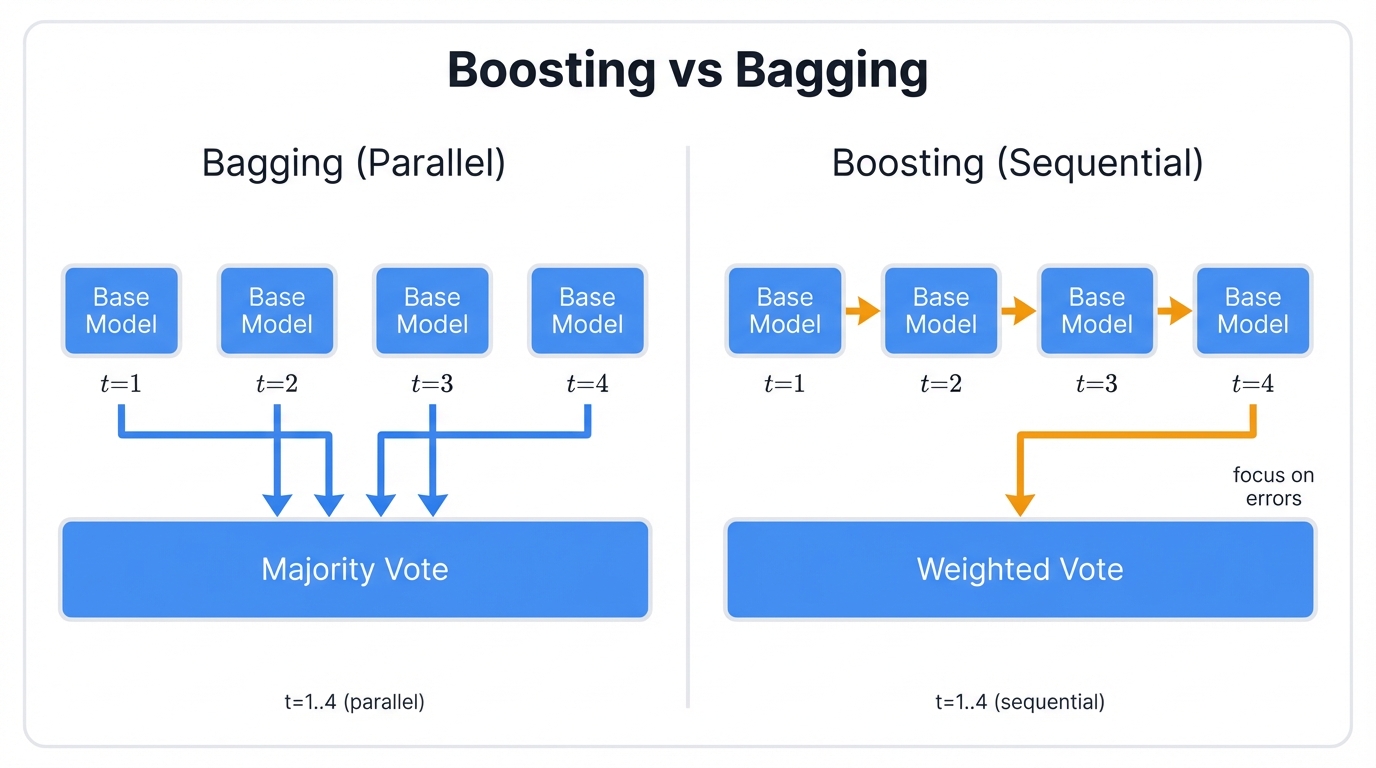
The key difference comes down to timing and focus. Random Forest trains models independently in parallel, each one working solo without knowing what the others are doing. AdaBoost trains them sequentially, and here's where the magic happens: each new model explicitly focuses on the mistakes of its predecessors, learning from their failures and building on their weaknesses.
This sequential training makes all the difference. Boosting stands apart from bagging. Random Forest trains models independently. They work in parallel. Boosting trains models one after another, with each new model explicitly correcting errors from previous models—this sequential dependency drives boosting's power.
The process slashes bias at its core. Decision stumps—trees with just one split—make overly simplistic assumptions about your data, like someone trying to diagnose illness by asking just one yes/no question, which sounds ridiculous until you understand what happens next.
AdaBoost gets clever here by forcing each new stump to focus on the ensemble's current failures, gradually building a complex understanding from simple parts where each stump asks a different question and together they form a sophisticated diagnostic system that can handle nuanced, complex patterns.
Think about bagging methods like Random Forest—they're like polling diverse experts who each study different parts of the problem independently, then you take a majority vote where each expert works alone and you average their opinions without any collaboration or learning from each other's mistakes.
AdaBoost works differently. It's more like assembling a specialist medical team where the first doctor examines the patient, the second doctor focuses specifically on cases the first doctor struggled with, and the third doctor tackles the cases that stumped the first two—each specialist learns from the previous one's limitations, creating a collaborative system that gets progressively smarter.
This collaborative, sequential approach lets the ensemble progressively refine its understanding, systematically eliminating its own blind spots through a process that creates two fundamentally different ensemble strategies with distinct strengths and weaknesses that solve different types of problems in machine learning.
1.2 The Core Mechanism: Adaptive Weighting
The "adaptive" in AdaBoost. It refers to dynamic weight adjustment. This is the algorithm's most crucial innovation—every training example gets a weight that changes throughout learning.
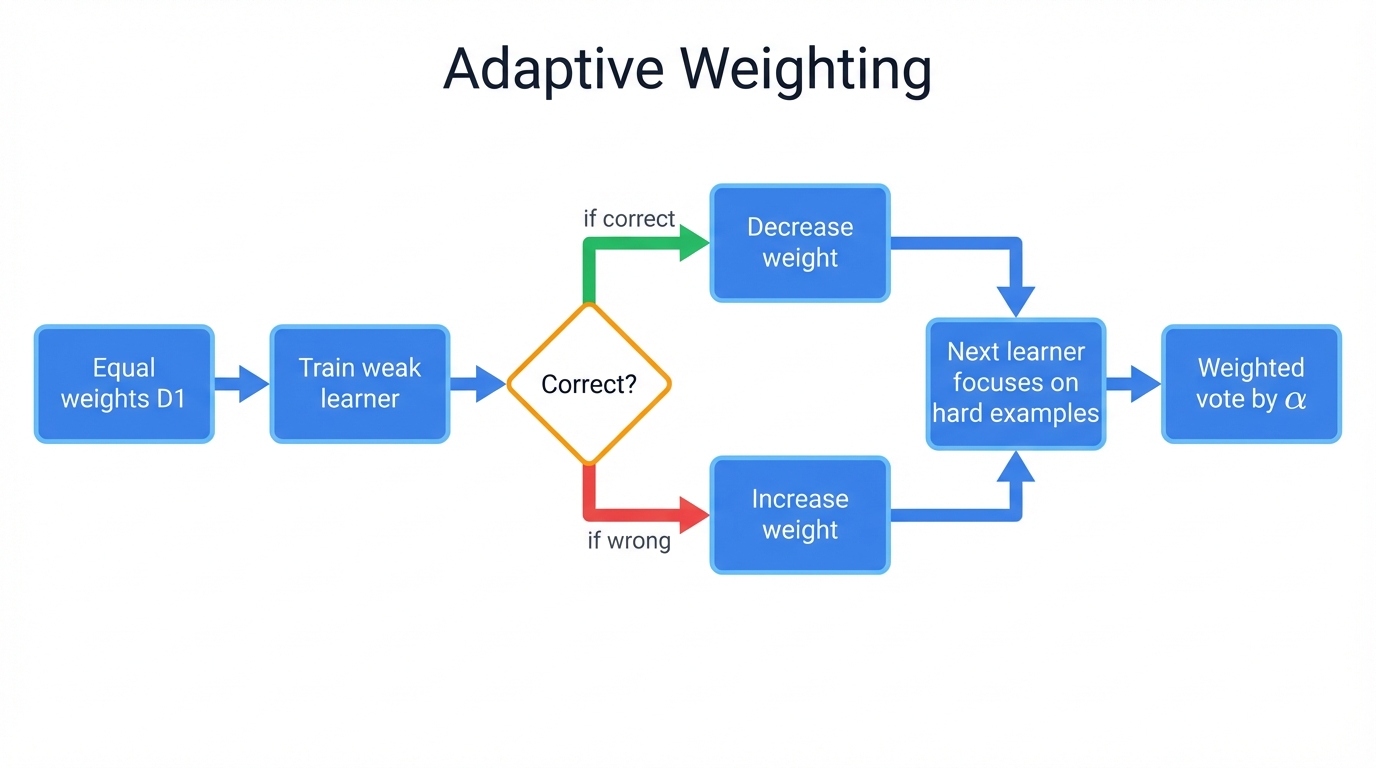
Watch how it works: you start with equal weights for all training examples, then you train your first weak learner on this uniformly weighted dataset, and after evaluation, the adaptive mechanism kicks in with a simple but powerful rule.
Misclassified examples? Heavier weights. Correctly classified examples? Lighter weights.
This forces the next weak learner to focus on "hard" examples—those the current ensemble struggles with, and it's like the algorithm saying, "These cases are tricky, pay more attention to them," which creates a progressive refinement process that zeros in on the most challenging patterns.
Final predictions aren't simple majority votes either. Each weak learner gets weighted by its performance. High-performing learners? Bigger voices in the final decision. Learners performing no better than random chance? They get zero weight—effectively silenced so they can't pollute the prediction.
This dual weighting system—for both training samples and weak learners—drives AdaBoost's remarkable effectiveness across diverse datasets and problem domains.
1.3 Historical Origins: The Algorithm That Won Computer Science's Highest Honor
Yoav Freund and Robert Schapire had one goal. They wanted to answer a theoretical question. They weren't trying to revolutionize machine learning—they were trying to solve a puzzle that had bothered researchers for years.
The late 1980s brought a fascinating challenge from Michael Kearns and Leslie Valiant: can you systematically boost a barely-adequate learning algorithm into an arbitrarily accurate one, transforming an algorithm that's just slightly better than random guessing into a prediction powerhouse through some principled, repeatable process?
Robert Schapire proved it was theoretically possible in 1990. But his initial algorithm had problems—too slow, too complex for real-world use, elegant on paper but impractical for actual applications.
1995 changed everything. Freund and Schapire's breakthrough with AdaBoost didn't just prove boosting could work—it made boosting work beautifully in practice. Their algorithm was elegant, efficient, and immediately useful.
The impact? Profound. In 2003, they received the Gödel Prize—theoretical computer science's equivalent of a Nobel Prize. The citation praised AdaBoost for solving a fundamental theoretical problem while creating lasting practical impact on machine learning and AI, bridging the gap between theory and application in a way few algorithms ever achieve.
1.4 A Meta-Algorithm That Enhances Other Algorithms
AdaBoost does supervised learning. It needs labeled training data to learn the input-to-output mapping. But here's what makes it special—AdaBoost isn't really an algorithm in the traditional sense.
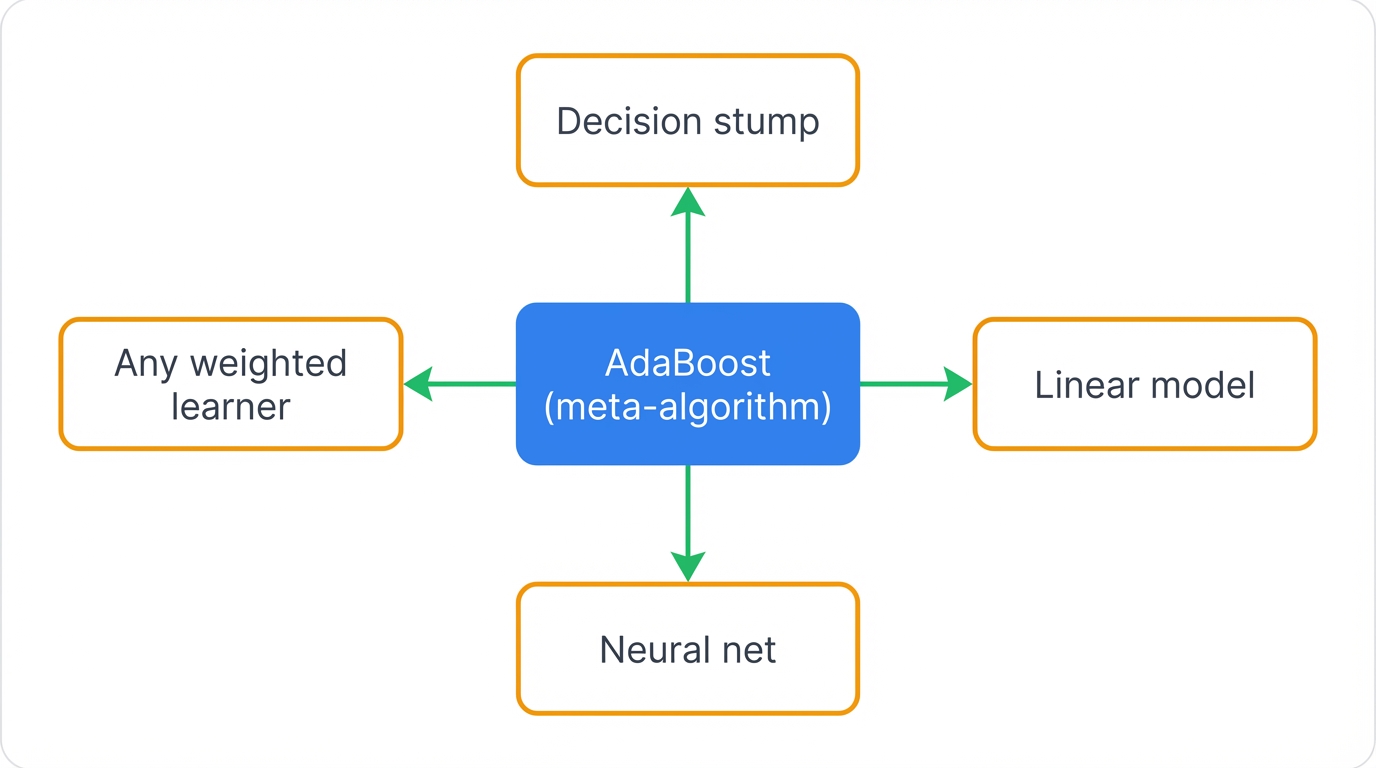
It's a meta-algorithm. A framework. Think of it as a system that makes other algorithms better.
AdaBoost doesn't learn patterns directly from your data—instead, it takes another learning algorithm (your base classifier) and orchestrates multiple versions of it to work together more effectively, where the base classifier can be anything that handles weighted samples: decision trees, linear models, even neural networks.
Decision stumps are the most common choice. Single-split decision trees serve as AdaBoost's base learner because stumps are weak learners par excellence—simple, fast, and just barely better than random, making them perfect raw material for boosting into something extraordinary.
This flexibility makes AdaBoost incredibly versatile—it's not tied to one specific type of model but serves as a general-purpose enhancement framework that can boost the performance of almost any classifier you choose.
Section 2: The Math Behind the Magic
Relax. We're going to make the mathematics intuitive. AdaBoost's power comes from elegant math that's actually beautiful once you see how it works—we'll walk through the core optimization objective, show you exactly how the update rules work, and explain the key parameters that control the algorithm's behavior.
2.1 The Mathematical Framework: Why Exponential Loss Works
Here's something fascinating about AdaBoost's origin story: the creators developed it based on intuition about sample weighting and classifier voting, not from rigorous mathematical derivation, and the deeper mathematical understanding came later when researchers realized AdaBoost was actually optimizing something specific—the exponential loss function.
This discovery was huge. It showed that AdaBoost wasn't just an ad-hoc procedure but a principled optimization algorithm that connects to fundamental statistical learning theory.
The final strong classifier, H(x), combines all weak learners using weighted voting:
$H(x) = \sum_{t=1}^T \alpha_t h_t(x)$
T represents the total number of weak learners. α_t represents the weight given to the t-th weak learner. For binary classification, you take the sign of this sum to get the final prediction. We encode labels as y ∈ {-1, +1} to make the math cleaner.
The exponential loss function for a single data point (x_i, y_i) is:
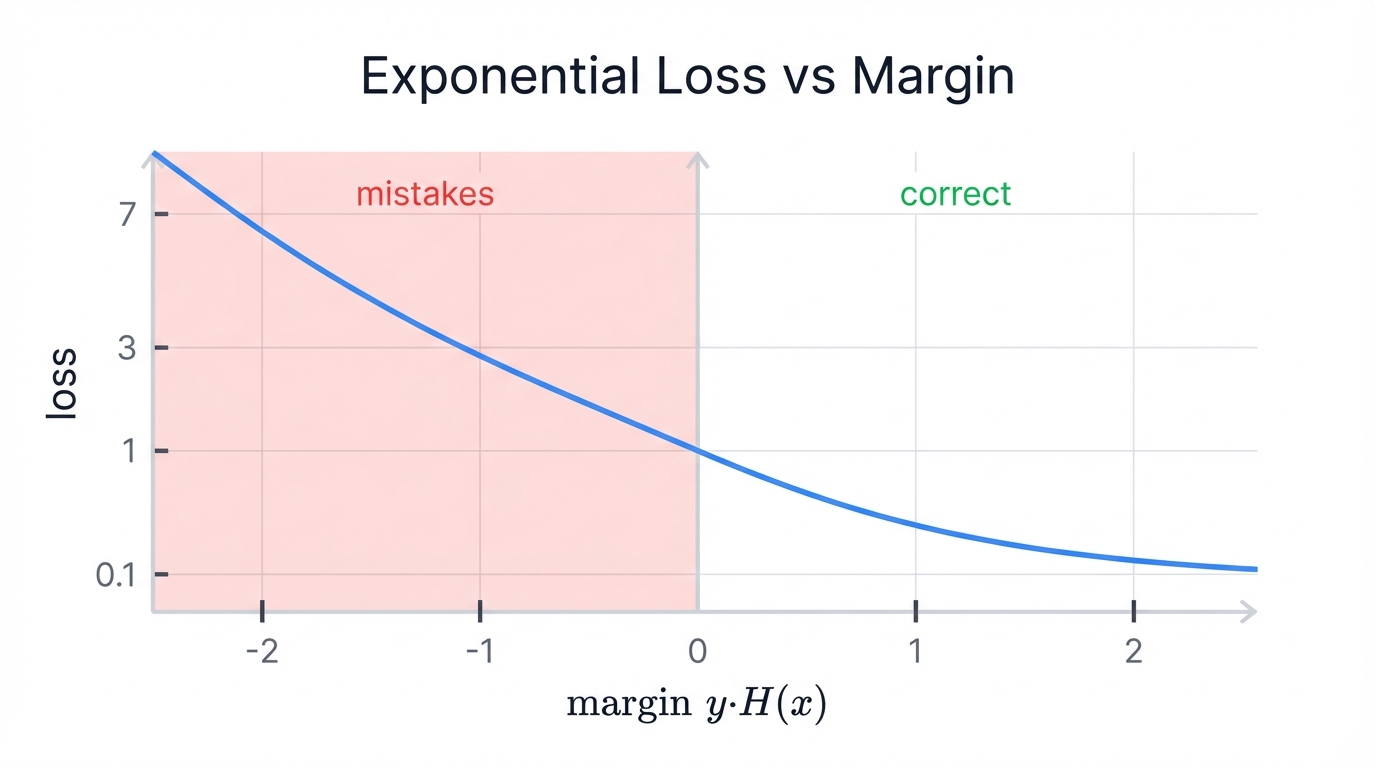
$L(y_i, H(x_i)) = e^{-y_i H(x_i)}$
The term y_i H(x_i) gets called the margin. When your prediction is correct, y_i and H(x_i) have the same sign, making the margin positive, which gives you a small loss (less than 1). When you're wrong? The margin becomes negative, and the loss explodes to a large value (greater than 1).
This loss function is clever—it heavily penalizes mistakes while rewarding confident, correct predictions. The more confident and correct you are, the lower your loss drops.
AdaBoost's goal? Minimize the total exponential loss across all training examples:
$\sum_{i=1}^N e^{-y_i H(x_i)}$
AdaBoost tackles this optimization greedily at each iteration t—it adds a new weak learner α_t h_t(x) to the existing ensemble H_{t-1}(x) without changing the previous learners, picking the pair (α_t, h_t) that best reduces the total loss at that stage.
Think of this as functional gradient descent—each new weak learner points in the direction that most reduces the loss in function space, like gradient descent but instead of adjusting parameters you're adding new functions to progressively reduce the overall prediction error.
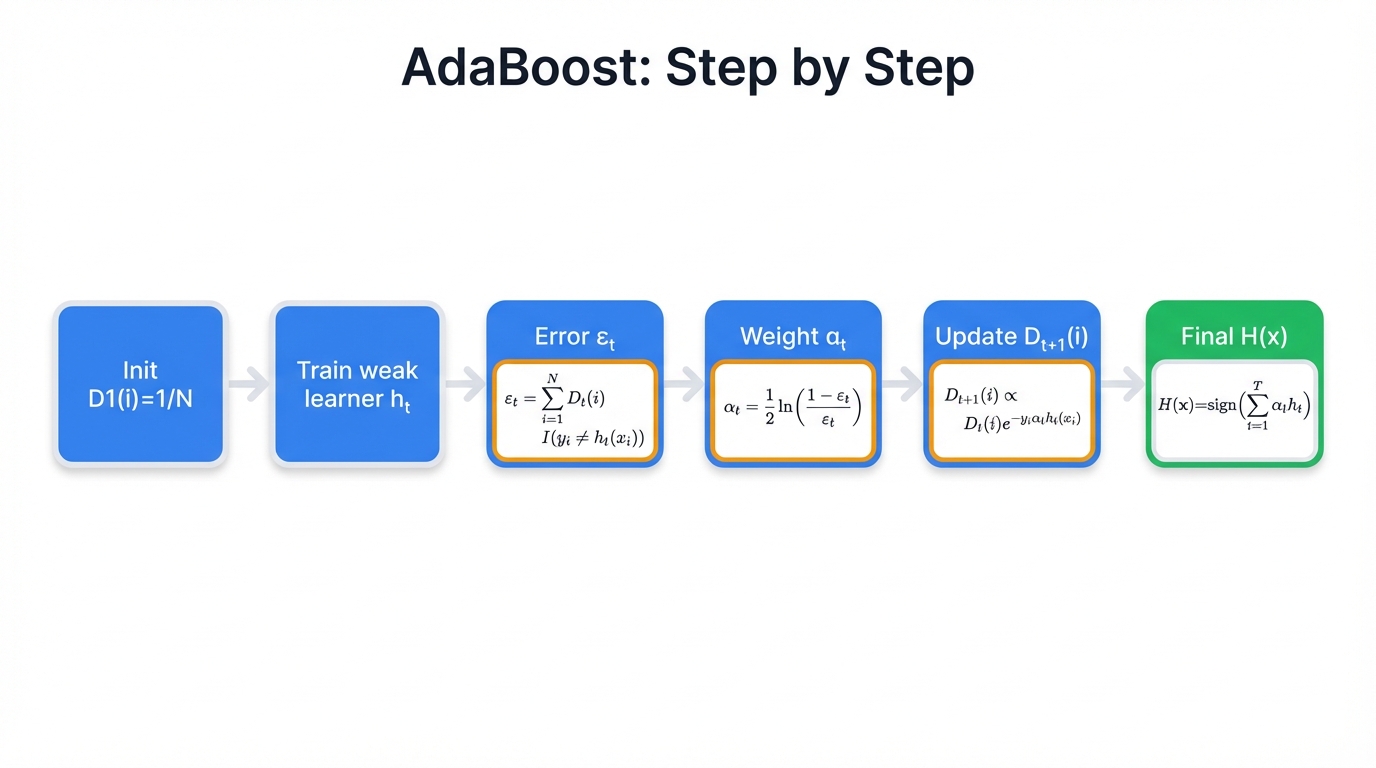
2.2 The AdaBoost Algorithm: Step by Step
Now we'll walk through AdaBoost's exact mechanics. Here's how the algorithm transforms weak learners into prediction powerhouses:
Starting point: you have N labeled training examples {(x_1, y_1), ..., (x_N, y_N)}, where x_i represents your features and y_i ∈ {-1, +1} is the class label.
Step 1: Give Every Example Equal Weight
AdaBoost starts simple. Every training example gets the same importance:
$D_1(i) = \frac{1}{N}$
for i=1,...,N where D_t(i) is the weight of sample i at iteration t.
Step 2: The Learning Loop (Repeat T Times)
The magic happens here. For each round t from 1 to T:
Train the Next Weak Learner: Take your weak learning algorithm and train it on the data, but use the current sample weights D_t, looking for classifier h_t(x) that minimizes weighted classification error.
Measure Performance: Calculate how badly this weak learner failed on the weighted data:
$\epsilon_t = \sum_{i=1}^N D_t(i) \cdot I(h_t(x_i) \neq y_i)$
I(⋅) equals 1 when the classifier gets it wrong. It equals 0 when it gets it right. Since weights sum to 1, ε_t falls between 0 and 1.
Calculate Classifier's Voice in the Final Vote: How much should this weak learner contribute to the final decision? AdaBoost uses this elegant formula:
$\alpha_t = \frac{1}{2} \ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right)$
This isn't random math—it emerges directly from exponential loss minimization. The ratio (1-ε_t)/ε_t represents odds: how many times the classifier is right versus wrong.
Random guessing? When ε_t = 0.5, you get α_t = 0. The classifier gets no voice in the final decision. A perfect classifier? When ε_t → 0, you get α_t → ∞, giving it huge influence over predictions. An always-wrong classifier? When ε_t → 1, you get α_t → -∞. This creates a negative vote that's actually helpful since you can invert its predictions.
Reweight the Training Examples: Now comes AdaBoost's signature move. Update sample weights for the next round:
$D_{t+1}(i) = \frac{1}{Z_t} D_t(i) \cdot e^{-y_i\alpha_th_t(x_i)}$
Z_t normalizes weights so they sum to 1:
$Z_t = \sum_{i=1}^N D_t(i) \cdot e^{-y_i\alpha_th_t(x_i)}$
The exponential term -y_iα_th_t(x_i) drives the adaptive behavior through a simple but powerful mechanism: for a correct prediction where y_ih_t(x_i) = 1, the weight gets multiplied by e^(-α_t), causing it to decrease and reducing emphasis on this already-solved example, while for a wrong prediction where y_ih_t(x_i) = -1, the weight gets multiplied by e^(α_t), causing it to increase and forcing future learners to pay more attention to this challenging case.
Misclassified examples become more important. They get heavier. The next learner focuses on them.
Step 3: Make Final Predictions
After T rounds, you have T weak learners, each with weight α_t. For any new input x, combine their votes:
$H(x) = \text{sign}\left(\sum_{t=1}^T \alpha_th_t(x)\right)$
This weighted majority vote produces your final prediction.
Section 10: Curated Learning Resources
You want to go deeper? This section provides a curated list of high-quality resources for readers who want to explore the theory, application, and implementation of AdaBoost in much greater detail, ranging from foundational academic papers to practical tutorials and code repositories that bring the concepts to life.
10.1 Foundational Academic Papers
Want deep, theoretical understanding of AdaBoost? You need to engage with the primary literature—these papers form the intellectual foundation of everything you've learned here, and the following curated collection highlights the most influential papers in chronological order:
| 📜 Paper Title | 👥 Authors | 📅 Year | 🎆 Significance & Impact |
|---|---|---|---|
| 🏆 A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting | Freund, Y., & Schapire, R. E. | 1997 | 🟠 FOUNDATIONAL - The seminal journal paper that formally introduced and analyzed the AdaBoost algorithm, establishing its theoretical properties and winning the Gödel Prize. |
| 📊 Additive Logistic Regression: A Statistical View of Boosting | Friedman, J., Hastie, T., & Tibshirani, R. | 2000 | 🔵 THEORETICAL - Landmark paper that re-framed AdaBoost from a statistical perspective, showing its equivalence to a stagewise additive model minimizing exponential loss. |
| 📱 The Boosting Approach to Machine Learning: An Overview | Schapire, R. E. | 2003 | 🟢 EDUCATIONAL - Accessible and intuitive overview of the boosting paradigm written by one of AdaBoost's creators. Perfect entry point for newcomers. |
| 👁️ Robust Real-Time Face Detection | Viola, P., & Jones, M. | 2004 | 🔴 APPLIED - The classic paper detailing the Viola-Jones object detection framework using AdaBoost cascades. Most famous real-world application. |
| 🔮 Multi-class AdaBoost | Zhu, J., Rosset, S., Zou, H., & Hastie, T. | 2009 | 🟡 EXTENSION - Introduced SAMME and SAMME.R algorithms, providing principled extension of AdaBoost to multi-class classification problems. |
| 🧠 Explaining AdaBoost | Schapire, R. E. | 2013 | 🟣 ANALYSIS - Comprehensive review of theoretical perspectives on AdaBoost's effectiveness, particularly its surprising resistance to overfitting via margin theory. |
10.2 Recommended Tutorials and Courses
These resources provide more accessible explanations. They offer practical guidance for learning and applying AdaBoost.
Online Courses from major learning platforms deliver comprehensive AdaBoost education—Coursera, Udemy, and DataCamp feature numerous machine learning courses covering ensemble methods with detailed AdaBoost modules and practical coding assignments. Look for courses titled "Ensemble Learning," "Machine Learning with Python," or "Classification Algorithms" for comprehensive coverage.
Video Tutorials provide visual learning opportunities, with StatQuest's Josh Starmer creating what many consider the best intuitive explanation available in "AdaBoost, Clearly Explained"—this YouTube video uses clear visuals and step-by-step approaches to demystify weight updates and classifier voting mechanics in a way that makes complex concepts suddenly obvious.
Written Tutorials offer detailed explanations with McCormickML's "AdaBoost Tutorial" providing clear, formal algorithm definitions and walking through classifier weight and sample weight update mathematics with helpful graphs and intuition, while platforms like GeeksforGeeks, Analytics Vidhya, and Towards Data Science host numerous high-quality tutorials providing both conceptual explanations and step-by-step Python implementation guides using popular datasets.
10.3 Annotated Code Repositories
Want hands-on learning? You need to explore code implementations. These resources provide both high-level library usage and from-scratch implementations that reveal the algorithmic details.
Official Library Documentation provides authoritative implementation guidance—Scikit-learn's documentation for sklearn.ensemble.AdaBoostClassifier and AdaBoostRegressor serves as the definitive practitioner resource, including detailed API reference, comprehensive user guides, and numerous gallery examples demonstrating usage across various datasets and base estimators.
GitHub Repositories for From-Scratch Implementation offer educational opportunities for understanding algorithmic mechanics, with TannerGilbert/Machine-Learning-Explained containing clear, concise from-scratch Python implementation using NumPy and Scikit-learn's DecisionTreeClassifier with excellent comments that closely follow standard algorithm descriptions, while jaimeps/adaboost-implementation provides another straightforward Python implementation for binary classification demonstrating core algorithmic logic with classic dataset examples.
Example Implementation
# Example: Model training with security considerations
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def train_secure_model(X, y, validate_inputs=True):
"""Train model with input validation"""
if validate_inputs:
# Validate input data
assert X.shape[0] == y.shape[0], "Shape mismatch"
assert not np.isnan(X).any(), "NaN values detected"
# Split data securely
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train with secure parameters
model = RandomForestClassifier(
n_estimators=100,
max_depth=10, # Limit to prevent overfitting
random_state=42
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
return model, score